Il y a environ un an, mes collègues et moi avons été chargés de trier à l'aide du système de surveillance d'infrastructure réseau populaire - Zabbix. Après avoir étudié la documentation, nous avons immédiatement procédé au test de charge: nous voulions évaluer le nombre de paramètres que Zabbix peut fonctionner sans baisse notable des performances. Seul PostgreSQL a été utilisé comme SGBD.
Au cours des tests, certaines caractéristiques architecturales de la disposition de la base de données et le comportement du système de surveillance lui-même ont été identifiés, ce qui par défaut ne permet pas au système de surveillance d'atteindre sa puissance maximale. En conséquence, certaines mesures d'optimisation ont été développées, menées et testées principalement en termes de réglage de la base de données.
Je veux partager les résultats du travail effectué dans cet article. Cet article sera utile pour les administrateurs DBA Zabbix et PostgreSQL, ainsi que pour tous ceux qui souhaitent mieux comprendre et comprendre le SGBD PosgreSQL populaire.
Un petit spoiler: sur une machine faible avec une charge de 200 000 paramètres par minute, nous avons réussi à réduire le CPU iowait de 20% à 2%, réduire le temps d'enregistrement par portions aux tables de données primaires de 250 fois et aux tables de données agrégées de 32 fois, réduire la taille des index 5 à 10 fois et accélérer la réception d'échantillons historiques dans certains cas jusqu'à 18 fois.
Test de charge
Les tests de charge ont été effectués selon le schéma: un serveur Zabbix, un proxy Zabbix actif, deux agents. Chaque agent a été configuré pour fournir 50 tonnes de paramètres entiers et 50 tonnes de paramètres de chaîne par minute (pour un total de 200 agents, 200 tonnes de paramètres par minute ou 3333 paramètres par seconde). Pour générer des paramètres d'agent, nous avons utilisé un
plug-in pour Zabbix. Pour vérifier le nombre maximum de paramètres qu'un agent peut générer, vous devez utiliser un
script spécial du même auteur de plug-in zabbix_module_stress . L'administrateur Web de Zabbix a des difficultés à enregistrer de gros modèles, nous avons donc divisé les paramètres en 20 modèles avec 5 tonnes de paramètres (2500 numériques et 2500 chaînes).
Modèle de générateur de script pour les tests de charge en pythonimport argparse """ . 20 5000 ( 2500 : echo, ; ping, ) """ TEMP_HEAD = """ <?xml version="1.0" encoding="UTF-8"?> <zabbix_export> <version>2.0</version> <date>2015-08-17T23:15:01Z</date> <groups> <group> <name>Templates</name> </group> </groups> <templates> <template> <template>Template Zabbix Srv Stress {count} passive {char}</template> <name>Template Zabbix Srv Stress {count} passive {char}</name> <description/> <groups> <group> <name>Templates</name> </group> </groups> <applications/> <items> """ TEMP_END = """</items> <discovery_rules/> <macros/> <templates/> <screens/> </template> </templates> </zabbix_export> """ TEMP_ITEM = """<item> <name>{k}</name> <type>0</type> <snmp_community/> <multiplier>0</multiplier> <snmp_oid/> <key>{k}</key> <delay>1m</delay> <history>3</history> <trends>365</trends> <status>0</status> <value_type>{t}</value_type> <allowed_hosts/> <units/> <delta>0</delta> <snmpv3_contextname/> <snmpv3_securityname/> <snmpv3_securitylevel>0</snmpv3_securitylevel> <snmpv3_authprotocol>0</snmpv3_authprotocol> <snmpv3_authpassphrase/> <snmpv3_privprotocol>0</snmpv3_privprotocol> <snmpv3_privpassphrase/> <formula>1</formula> <delay_flex/> <params/> <ipmi_sensor/> <data_type>0</data_type> <authtype>0</authtype> <username/> <password/> <publickey/> <privatekey/> <port/> <description/> <inventory_link>0</inventory_link> <applications/> <valuemap/> <logtimefmt/> </item> """ TMP_FNAME_DEFAULT = "Template_App_Zabbix_Server_Stress_{count}_passive_{char}.xml" chars = "ABCDEFGHIJKLMNOPQRSTUVWXYZ" if __name__ == "__main__": parser = argparse.ArgumentParser( description=' zabbix') parser.add_argument('--items', dest='items', type=int, default=1000, help='- (default: 1000)') parser.add_argument('--templates', dest='templates', type=int, default=1, help=f'- [1-{len(chars)}] (default: 1)') args = parser.parse_args() items_count = args.items tmps_count = args.templates if not (tmps_count >= 1 and tmps_count <= len(chars)): sys.exit(f"Templates must be in range 1 - {len(chars)}") for i in range(tmps_count): fname = TMP_FNAME_DEFAULT.format(count=items_count, char=chars[i]) with open(fname, "w") as output: output.write(TEMP_HEAD.format(count=items_count, char=chars[i])) for k,t in [('stress.ping[{}-I-{:06d}]',3), ('stress.echo[{}-S-{:06d}]',4)]: for j in range(int(items_count/2)): output.write(TEMP_ITEM.format(k=k.format(chars[i],j),t=t)) output.write(TEMP_END)
La métrique iostat du processeur est un bon indicateur des performances de Zabbix - elle reflète la fraction de l'unité de temps pendant laquelle le processeur attend l'accès au disque. Plus il est élevé, plus le disque est occupé par des opérations de lecture et d'écriture, ce qui affecte indirectement la dégradation des performances du système de surveillance dans son ensemble. C'est-à-dire c'est un signe certain que quelque chose ne va pas avec la surveillance. Soit dit en passant, sur les espaces ouverts du réseau, la question plutôt populaire est «comment supprimer le déclencheur iostat dans Zabbix», donc c'est un point sensible, car il existe de nombreuses raisons d'augmenter la valeur de la métrique iowait.
Voici l'image de la métrique du processeur iowait que nous avons obtenue trois jours plus tard initialement:
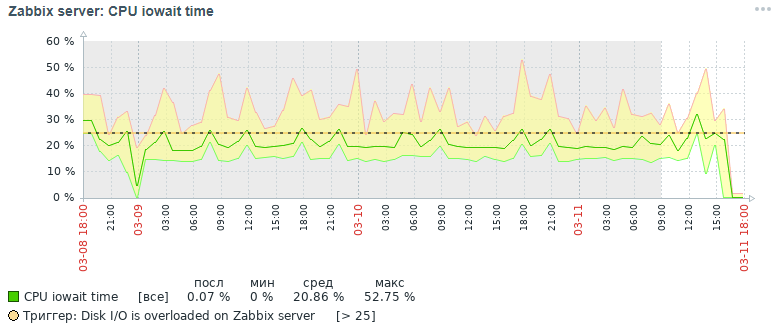
Mais quelle image pour la même mesure, nous avons également obtenu dans les trois jours à la fin après toutes les mesures d'optimisation qui ont été faites, qui seront discutées ci-dessous:
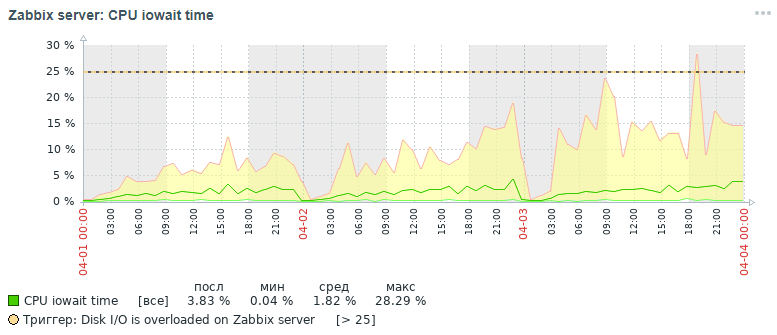
Comme le montrent les graphiques, l'indicateur cpu iowait est passé de près de 20% à 2%, ce qui a indirectement accéléré le temps d'exécution de toutes les demandes d'ajout et de lecture de données. Voyons maintenant pourquoi, avec les paramètres de base de données standard, les performances globales du système de surveillance diminuent et comment y remédier.
Raisons de la baisse des performances de Zabbix
Avec l'accumulation de plus de 10 millions de valeurs de paramètres dans chaque tableau de données primaires, il a été constaté que les performances du système de surveillance diminuent fortement, pour les raisons suivantes:
- la métrique iowait pour le processeur du serveur est augmentée de plus de 20%, ce qui indique une augmentation du temps pendant lequel le processeur attend l'accès aux opérations de lecture et d'écriture sur le disque
- index des tableaux dans lesquels les données de surveillance sont fortement gonflées
- la métrique d'utilisation est augmentée à 100% pour un disque avec des données de surveillance, ce qui indique la pleine charge du disque avec des opérations de lecture et d'écriture
- les valeurs obsolètes n'ont pas le temps d'être supprimées des tables d'historique lors du nettoyage selon le planning de la femme de ménage
La situation est aggravée au début de chaque heure, lorsque, en plus de cela, des statistiques horaires agrégées sont calculées - tout en lisant et en écrivant activement les pages d'index du disque, en supprimant les données obsolètes de l'historique, ce qui conduit au même résultat - une baisse des performances de la base de données et une augmentation du temps d'exécution demandes (dans la limite, une demande pouvant aller jusqu'à 5 minutes a été notée!).
Un peu d'aide pour organiser un entrepôt de données de surveillance dans Zabbix. De plus, il stocke les données primaires et les données agrégées dans différentes tables avec la séparation des types de paramètres. Chaque table stocke un champ itemid (une référence implicite à un élément de données enregistré dans le système), un horodatage pour enregistrer la valeur d'horloge au format d'horodatage unix (millisecondes dans une colonne séparée) et une valeur dans une colonne séparée (l'exception est la table de journal, elle a plus de champs - semblable au journal des événements) ):
Activités d'optimisation
Pour améliorer les performances de la base de données PostgreSQL, différentes mesures d'optimisation ont été effectuées, dont les principales sont le partitionnement et la modification des index. Cependant, il convient de mentionner quelques mots sur quelques mesures importantes et utiles qui peuvent accélérer le travail de toute base de données sous le système de gestion de base de données PostgreSQL.
Remarque importante. Au moment de collecter le matériel de l'article, nous utilisions Zabbix version 4.0, bien que la version 4.2 ait déjà été publiée et que la version 4.4 soit en cours de préparation. Pourquoi est-il important de le mentionner? Parce qu'à partir de la version 4.2, Zabbix a commencé à prendre en charge une extension puissante spéciale pour travailler avec les séries temporelles TimescaleDB, mais jusqu'à présent en mode expérimental: pour tous les avantages de l'utilisation de cette extension, on pense que certaines demandes ont commencé à fonctionner plus lentement et il y a encore des problèmes de performances non résolus (il y aura résolu dans la version 4.4) -
lisez cet article .
Dans le prochain article, je prévois d'écrire sur les résultats des tests de charge utilisant déjà l'extension TimescaleDB par rapport à ce cas de solution. La version PostgreSQL a été utilisée 10, mais toutes les informations fournies sont pertinentes pour les versions 11 et 12 (nous attendons!).
Par conséquent, tout d'abord:
- configuration d'un fichier de configuration à l'aide de l'utilitaire pgtune
- placer la base de données sur un disque physique distinct
- partitionnement des tables d'historique avec pg_pathman
- modification des types d'index des tables d'historique en brin (horloge) et btree-gin (itemid)
- collecte et analyse des statistiques d'exécution des requêtes pg_stat_statements
- définition des paramètres de surveillance du disque physique
- amélioration des performances matérielles
- création d'un cluster distribué (matériel au-delà de la portée de cet article)
Configuration d'un fichier de configuration à l'aide de l'utilitaire pgtune
En fait, PostgreSQL est un SGBD assez léger. Son fichier de configuration par défaut est configuré de manière à ce que, comme le dit mon collègue, "même travailler sur la machine à café", c'est-à-dire sur un fer très modeste. Par conséquent, il est nécessaire de configurer PostgreSQL pour la configuration du serveur, en tenant compte de la quantité de mémoire, du nombre de processeurs, du type d'utilisation prévue de la base de données, du type de disque (HDD ou SSD) et du nombre de connexions.
Hélas, il n'y a pas de formule unique pour régler tous les SGBD, mais il existe certaines règles et modèles qui conviennent à la plupart des configurations (un réglage plus fin est déjà le travail d'un expert). Pour simplifier la vie de DBA, l'utilitaire
pgtune a été écrit, qui a été complété par la
version web par
le0pard , l'auteur d'un livre intéressant et utile sur l'administration de PostgreSQL.
Un exemple d'exécution de l'utilitaire dans la console avec 100 connexions (Zabbix a un administrateur Web exigeant) pour le type d'application «Data Warehouses»:
pgtune -i postgresql.conf -o new_postgresql.conf -T DW -c 100
Les paramètres de configuration que l'utilitaire pgtune modifie avec une description de l'objectif (les valeurs sont données à titre d'exemple) # Version DB: 11
# Type de système d'exploitation: linux
# Type de base de données: web
# Mémoire totale (RAM): 8 Go
# CPUs num: 1
# Nombre de connexions: 100
# Stockage de données: hdd
max_connections = 100 # nombre maximum de connexions de base de données simultanées
shared_buffers = 2 Go # de mémoire pour différents tampons (principalement cache de blocs de table et blocs d'index) en mémoire partagée
effective_cache_size = 6 Go # taille maximale de mémoire requise pour l'exécution des requêtes à l'aide d'index
maintenance_work_mem = 512 Mo # affecte la vitesse des opérations VACUUM, ANALYZE, CREATE INDEX
checkpoint_completion_target = 0.7 # temps cible pour terminer la procédure de point de contrôle
wal_buffers = 16 Mo de mémoire utilisée par la mémoire partagée pour gérer les journaux de transactions
default_statistics_target = 100 # quantité de statistiques collectées par la commande ANALYZE - lors de l'augmentation, l'optimiseur crée des requêtes plus lentement, mais mieux
random_page_cost = 4 # coût conditionnel d'accès à l'index pour les pages de données - affecte la décision d'utiliser l'index
effective_io_concurrency = 2 # nombre d'opérations d'E / S asynchrones que le SGBD tentera d'effectuer dans une session distincte
work_mem = 10485kB # la quantité de mémoire utilisée pour le tri et les tables de hachage avant d'utiliser des fichiers temporaires sur le disque
min_wal_size = 1 Go # limite en dessous du nombre de fichiers WAL qui seront recyclés pour une utilisation future
max_wal_size = 2 Go # limite au-dessus le nombre de fichiers WAL qui seront recyclés pour une utilisation future
Quelques options de configuration postgresql utiles # gestion des gestionnaires de demandes simultanées
max_worker_processes = 8 # le nombre maximum de processus d'arrière-plan - au moins un par base de données
max_parallel_workers_per_gather = 4 # nombre maximum de processus parallèles au sein d'une même requête
max_parallel_workers = 8 # le nombre maximum de processus de travail que le système peut prendre en charge pour les opérations parallèles
# paramètres de journalisation (un moyen simple de connaître le temps d'exécution des requêtes sans utiliser l'extension pg_stat_statements)
log_min_duration_statement = 3000 # écrire dans les journaux la durée de l'exécution de toutes les commandes dont le temps de fonctionnement> = de la valeur spécifiée en ms
log_duration = off # enregistre la durée de chaque commande terminée
log_statement = 'none' # quelles commandes SQL écrire dans le journal, valeurs: none (désactivé), ddl, mod et all (toutes les commandes)
debug_print_plan = off # sortie de l'arborescence du plan de requête pour une analyse plus approfondie
# extrayez le maximum de la base de données et soyez prêt à l'obtenir en cas d'échec (pour les plus réprimés, qui ignorent l'existence de ssd et d'un cluster distribué)
#fsync = off # écriture physique sur le disque des modifications, la désactivation de fsync donne un gain de vitesse, mais peut entraîner des échecs permanents
#synchronous_commit = off # vous permet de répondre au client avant même que les informations de transaction ne soient dans le WAL - une alternative presque sûre à la désactivation de fsync
#full_page_writes = off # l'arrêt accélère les opérations normales, mais peut entraîner une corruption des données ou une corruption des données en cas de panne du système
Liste d'une base de données sur un disque physique distinct
Cet élément est facultatif et constitue plutôt une solution de transition vers un cluster distribué à part entière, mais il sera utile de connaître cette possibilité. Pour accélérer la base de données, vous pouvez la placer sur un disque séparé. Nous avons monté l'intégralité du disque dans le répertoire de base, où toutes les bases de données PostgreSQL sont stockées, mais en général, cela peut être fait différemment: créer une nouvelle base de données et transférer la base de données (ou même seulement une partie - les tables de données de surveillance principales et agrégées) vers cette base de données sur un disque séparé.
Exemple de montageVous devez d'abord formater le disque avec le système de fichiers ext4 et le connecter au serveur. Montez le disque de la base de données avec l'étiquette noatime:
mount / dev / sdc1 / var / lib / pgsql / 10 / data / base -o noatime
Pour un montage permanent, ajoutez la ligne au fichier / etc / fstab:
# où UUID est l'identifiant du disque, vous pouvez le voir en utilisant l'utilitaire blkid
UUID = 121efe29-70bf-410b-bc71-90704568ce3b / var / lib / pgsql / 10 / data / base ext4 par défaut, noatime 0 0
Partitionnement des tables d'historique avec pg_pathman
L'un des problèmes rencontrés lors des tests de résistance de Zabbix - PostgreSQL ne parvient pas à supprimer les données obsolètes de la base de données. En utilisant le partitionnement, vous pouvez diviser la table en ses parties constituantes, réduisant ainsi la taille des index et des parties constitutives de la super table, ce qui affecte positivement la vitesse de la base de données dans son ensemble.
Le partitionnement résout deux problèmes à la fois:
1. accélérer la suppression des données obsolètes en supprimant des tables entières
2. indices de fractionnement pour chaque table composite
Il existe quatre mécanismes de partitionnement dans PostgreSQL:
1.exclusion_contrainte_standard
2. extension pg_partman (
ne pas confondre avec pg_pathman )
3. extension
pg_pathman4. créer et maintenir manuellement des partitions par nous-mêmes
La solution de partitionnement la plus pratique, fiable et optimisée, à notre avis, est l'extension
pg_pathman . Avec cette méthode de partitionnement, le planificateur de requêtes détermine de manière flexible dans quelles partitions rechercher les données.
La rumeur veut que dans la 12e version de PostgreSQL, il y aura déjà une excellente partition prête à l'emploi.Ainsi, nous avons commencé à écrire les données de surveillance pour chaque jour dans une table héritée distincte du supertable et la suppression des valeurs de paramètres obsolètes a commencé à se produire par la suppression de toutes les tables obsolètes à la fois, ce qui est beaucoup plus facile pour un SGBD en raison des coûts de main-d'œuvre. La suppression a été effectuée en appelant la fonction utilisateur de la base de données en tant que paramètre de surveillance du serveur Zabbix à 2 heures du matin avec une indication de la plage acceptable de stockage des statistiques.
Installer et configurer le partitionnement pour PostgreSQL 10Installez et configurez l'extension
pg_pathman à partir du référentiel OS standard (pour obtenir des instructions sur la création de la dernière version de l'extension à partir des sources, recherchez dans le même référentiel sur github):
yum install pg_pathman10
nano /var/pgsqldb/postgresql.conf
shared_preload_libraries = 'pg_pathman' # important - ici, écrivez pg_pathman en dernier dans la liste
Nous redémarrons le SGBD, créons l'extension pour la base de données et configurons le partitionnement (1 jour pour les données de surveillance principales et 3 jours pour les données de surveillance agrégées - cela pourrait être fait pendant 1 jour):
systemctl restart postgresql-10.service
psql -d zabbix -U postgres
CRÉER UNE EXTENSION pg_pathman;
# configurer un jour pour les tables de données de surveillance principales
# 1552424400 - Compte à rebours comme horodatage Unix, 86400 - secondes en jours
sélectionnez create_range_partitions ('historique', 'horloge', 1552424400, 86400);
sélectionnez create_range_partitions ('history_uint', 'clock', 1552424400, 86400);
sélectionnez create_range_partitions ('history_text', 'clock', 1552424400, 86400);
sélectionnez create_range_partitions ('history_str', 'clock', 1552424400, 86400);
sélectionnez create_range_partitions ('history_log', 'clock', 1552424400, 86400);
# configurer pendant trois jours pour les tableaux de données de surveillance agrégés
# 1552424400 - Compte à rebours comme horodatage Unix, 259200 - secondes en trois jours
sélectionnez create_range_partitions ('tendances', 'horloge', 1545771600, 259200);
sélectionnez create_range_partitions ('trends_uint', 'clock', 1545771600, 259200);
S'il n'y a pas encore de données dans l'une des tables, alors lors de l'appel de la fonction create_range_partitions, un autre argument supplémentaire p_count = 0_ doit être passé.Requêtes utiles pour surveiller et gérer les partitions:
# liste générale des tables partitionnées, stockage de la configuration principale:
sélectionnez * dans pathman_config;
# représentation avec toutes les sections existantes, ainsi que leurs parents et limites de plage:
sélectionnez * dans pathman_partition_list;
# paramètres supplémentaires qui remplacent le comportement standard de pg_pathman:
sélectionnez * dans pathman_config_params;
# copiez le contenu dans la table parent et supprimez les partitions:
sélectionnez drop_partitions ('table_name' :: regclass, false);
Script utile pour visualiser les statistiques sur le nombre et la taille des partitions:
SELECT nspname AS schemaname, relname, relkind, cast (reltuples as int), pg_size_pretty(pg_relation_size(C.oid)) AS "size" FROM pg_class C LEFT JOIN pg_namespace N ON (N.oid = C.relnamespace) WHERE nspname NOT IN ('pg_catalog', 'information_schema') and (relname like 'history%' or relname like 'trends%') and relkind = 'r'
Réglage automatique de la suppression des partitions obsolètes (ahtung - une grande fonction SQL)Pour configurer la suppression automatique des partitions, vous devez créer une fonction dans la base de données
(texte large, j'ai donc dû supprimer la coloration syntaxique):
CRÉER OU REMPLACER LA FONCTION public.delete_old_partitions (entier history_days, entier trends_days, entier str_days)
RETOURNE le texte
LANGUAGE plpgsql
AS $ function $
/ *
La fonction supprime toutes les partitions antérieures au nombre de jours spécifié:
history_days - pour les partitions history_x, history_uint_x
trends_days - pour les partitions trends_x, trends_uint_x
str_days - pour les partitions history_str_x, history_text_x, history_log_x
* /
déclarer clock_today_start int;
déclarer clock_delete_less_history int = 0;
déclarer clock_delete_less_trends int = 0;
déclarer clock_delete_less_strings int = 0;
clock_delete_less int = 0;
déclarer l'itérateur int = 0;
declare result_str text = '';
déclarer le texte buf_table_size;
déclarer le texte buf_table_len;
déclarer le texte nom_partition;
déclarer le texte de clock_max;
déclarer le texte err_detail;
déclarer t_start timestamp = clock_timestamp ();
déclarer l'horodatage t_end;
commencer
si $ 1 <= 0 retourne alors 'ups, quelque chose de mal: l'argument history_days doit être une valeur entière positive'; fin si;
si $ 2 <= 0 retourne alors 'ups, quelque chose de mal: l'argument trends_days doit être une valeur entière positive'; fin si;
si $ 3 <= 0 retourne alors 'ups, quelque chose de mal: l'argument str_days doit être une valeur entière positive'; fin si;
clock_today_start = extract (epoch from date_trunc ('day', now ())) :: int;
clock_delete_less_history = extract (epoch from date_trunc ('day', now ()) - ($ 1 :: text || 'days') :: interval) :: int;
clock_delete_less_trends = extract (epoch from date_trunc ('day', now ()) - ($ 2 :: text || 'days') :: interval) :: int;
clock_delete_less_strings = extract (epoch from date_trunc ('day', now ()) - ($ 3 :: text || 'days') :: interval) :: int;
clock_delete_less = moins (clock_delete_less_history, clock_delete_less_trends, clock_delete_less_strings);
- avis de montée 'clock_today_start% (%)', to_timestamp (clock_today_start), clock_today_start;
- avis de montée 'clock_delete_less_history% (%)% days', to_timestamp (clock_delete_less_history), clock_delete_less_history, $ 1;
--raise notice 'clock_delete_less_trends% (%)% days', to_timestamp (clock_delete_less_trends), clock_delete_less_trends, $ 2;
- avis de montée 'clock_delete_less_strings% (%)% days', to_timestamp (clock_delete_less_strings), clock_delete_less_strings, $ 3;
pour nom_partition, horloge_max dans la partition sélectionnée, plage_max de pathman_partition_list où
range_max :: int <= le plus grand (clock_delete_less_history, clock_delete_less_trends, clock_delete_less_strings) et
(partition :: texte comme 'history%' ou partition :: texte comme 'trends%') ordre par partition asc
boucle
if (nom_partition ~ 'history_uint_ \ d' et clock_max :: int <= clock_delete_less_history)
ou (nom_partition ~ 'history_ \ d' et clock_max :: int <= clock_delete_less_history)
ou (nom_partition ~ 'trends_ \ d' et clock_max :: int <= clock_delete_less_trends)
ou (nom_partition ~ 'history_log_ \ d' et clock_max :: int <= clock_delete_less_strings)
ou (nom_partition ~ 'history_str_ \ d' et clock_max :: int <= clock_delete_less_strings)
ou (nom_partition ~ 'history_text_ \ d' et clock_max :: int <= clock_delete_less_strings)
alors
itérateur = itérateur + 1;
augmenter l'avis '%', format ('!!! supprimer% s% s', nom_partition, horloge_max);
sélectionnez max (reltuples :: int), pg_size_pretty (sum (pg_relation_size (pg_class.oid))) comme "taille" dans pg_class où relname comme nom_partition || '%' dans buf_table_len strict, buf_table_size;
si result_str! = '' alors result_str = result_str || ','; fin si;
result_str = result_str || format ('% s (dt <% s, len% s,% s)', partition_name, to_char (to_timestamp (clock_max :: int), 'YYYY-MM-DD'), buf_table_len, buf_table_size);
exécuter le format ('supprimer la table s'il existe% s', nom_partition);
fin si;
boucle de fin;
si itérateur = 0, alors result_str = format ('il n'y a pas de partitions à supprimer plus anciennes, alors% s date', to_char (to_timestamp (clock_delete_less), 'YYYY-MM-DD'));
else result_str = format ('partitions% s supprimées en% s secondes:', itérateur, trunc (extrait (secondes de (clock_timestamp () - t_start)) :: numérique, 3)) || result_str;
fin si;
--raise notice '%', result_str;
return result_str;
exception quand d'autres alors
obtenir des diagnostics empilés err_detail = PG_EXCEPTION_CONTEXT;
format de retour ('ups, quelque chose de mal:% s [code d'erreur% s],% s', sqlerrm, sqlstate, err_detail);
fin;
$ function $;
Pour appeler automatiquement la fonction de partition de nettoyage automatique, vous devez créer un élément de données pour l'hôte du serveur zabbix du type "Database Monitor" avec les paramètres suivants:
- type: moniteur de base de données
- nom: delete_old_history_partitions
- clé: db.odbc.select [delete_old_history_partitions, zabbix]
- expression sql: sélectionnez delete_old_partitions (3, 30, 30);
# ici, les paramètres de l'appel de la fonction delete_old_partitions indiquent la durée de stockage en jours
# pour les valeurs numériques, les valeurs numériques agrégées et les valeurs de chaîne
- type de données: texte
- intervalle de mise à jour: 0
- intervalle utilisateur: prévu en h2
- période de stockage de l'historique: 90 jours
- groupe d'éléments de données: base de données
Par conséquent, nous obtiendrons des statistiques sur le nettoyage des partitions d'environ le type suivant:
2019-09-16 02:00:00, supprimé 3 partitions en 0,024 seconde: trends_78 (dt <2019-08-17, len 1, 48 kB), history_193 (dt <2019-09-13, len 85343, 9448 kB ), history_uint_186 (dt <2019-09-13, len 27969, 3480 kB)
Important! Après avoir configuré la suppression automatique des partitions via l'élément de données et la fonction utilisateur, vous devez désactiver l'historique et le nettoyage des tendances dans le planificateur de tâches de femme de ménage Zabbix:
via l'élément de menu zabbix, sélectionnez «Administration» -> «Général» -> sélectionnez «Effacer l'historique» dans la liste dans le coin -> désactiver toutes les cases à cocher des sections «Historique» et «Dynamique des changements». Modification des types d'index des tables d'historique en brin (horloge) et btree-gin (itemid)
Un merci spécial à
erogov pour l'
excellente série d'articles de
présentation sur les
index PostgreSQL .
Et en effet toute l'équipe PostgresPRO.Impressionnés par ces articles, nous avons joué avec différents types d'index sur les tableaux de données de surveillance et sommes parvenus à la conclusion quels types d'index sur quels champs donneraient le maximum de performances.Il a été remarqué que l'index composite btree (itemid, horloge) est créé par défaut sur toutes les tables de données de surveillance - il est rapide pour la recherche, en particulier pour les valeurs ordonnées de façon monotone, mais il «gonfle» sur le disque quand il y a beaucoup de données - plus de 10 millions.Sur les tables Par défaut, les statistiques agrégées toutes les heures, un index unique est généralement créé, bien que ces tables de stockage et d'unicité des données soient fournies ici au niveau du serveur d'applications, et qu'un index unique ne fait que ralentir l'insertion des données.Au cours des tests de divers indices, la combinaison d'indices la plus réussie a été révélée: l'indice de brin sur le champ d'horloge et l'indice btree-gin sur le champ itemid pour toutes les tables de données de surveillance.L'indice de brin est idéal pour augmenter de façon monotone des données, telles que l'horodatage du fait d'un événement, c'est-à-dire pour les séries chronologiques. Et l'index btree-gin est essentiellement un index gin sur les types de données standard, qui est généralement beaucoup plus rapide que l'indice btree classique car L'index gin n'est pas reconstruit lors de l'ajout de nouvelles valeurs, mais seulement complété par celles-ci. L'index btree-gin est mis comme une extension de PostgreSQL.Une comparaison de la vitesse d'échantillonnage pour cette stratégie d'indexation et pour les index dans la base de données Zabbix par défaut est donnée ci-dessous. Lors des tests de charge, nous avons accumulé des données pendant trois jours pour trois partitions:Pour évaluer les résultats, trois types de requêtes ont été effectuées:- pour un itemid de paramètre spécifique, les données du dernier mois, en fait les trois derniers jours (total 1660 enregistrements)
expliquer analyser sélectionner * dans history_uint où itemid = 313300
et horloge> = extraire (époque du '2019-03-09 00:00:00' :: horodatage) :: int
et clock <= extract (epoch from '2019-04-09 12:00:00' :: timestamp) :: int;
- pour une donnée de paramètre spécifique pour 12 heures d'une journée (649 entrées au total)
expliquer analyser sélectionner * dans history_text où itemid = 310650
et horloge> = extraire (époque du '2019-04-09 00:00:00' :: horodatage) :: int
et clock <= extract (epoch from '2019-04-09 12:00:00' :: timestamp) :: int;
- pour une donnée de paramètre spécifique pendant une heure (61 enregistrements au total):
expliquer analyser sélectionner le nombre (*) de history_text où itemid = 336540
et horloge> = extraire (époque du '2019-04-08 11:00:00' :: horodatage) :: int
et clock <= extract (epoch from '2019-04-08 12:00:00' :: timestamp) :: int;
Les résultats des tests ont été tabulés ci-dessous:* la taille en Mo est indiquée au total pour trois partitions** demande de type 1 - données pour 3 jours, demande de type 2 - données pour 12 heures, demande de type 3 - données pour une heureDans le tableau de comparaison, on peut voir que pour les grands tableaux de données avec le nombre d'enregistrements plus de 100 millions, on voit clairement que le changement de l'index composite standard btree en deux indices brin et btree-gin a un effet bénéfique sur la réduction de la taille des index et l'accélération du temps d'exécution des requêtes.L'efficacité de l'indexation et du partitionnement est illustrée ci-dessous sur l'exemple d'une demande d'ajout de nouveaux enregistrements aux tables history_uint et trends_uint (les ajouts se produisent en moyenne 2000 valeurs par requête).En résumant les résultats des tests de diverses configurations d'index pour les tableaux de données de surveillance du système zabbix, nous pouvons dire qu'un changement similaire dans l'index standard pour les tableaux de données de surveillance du système zabbix affecte positivement les performances globales du système, ce qui se ressent surtout lorsque des volumes de données de plus de 10 millions sont accumulés. vous devez oublier l'effet indirect du «gonflement» de l'index btree standard par défaut - les reconstructions fréquentes de l'index multi-gigaoctets entraînent une lourde charge du disque dur (métrique utiliz ation), ce qui augmente finalement le temps des opérations sur le disque et le temps d’attendre l’accès au disque à partir du CPU (métrique iowait).Mais pour que l'index btree-gin puisse fonctionner avec le type de données bigint (in8), qui est la colonne itemid, vous devez enregistrer une famille d'opérateurs bigint pour l'index btree-gin.Enregistrement d'une famille d'opérateurs bigint pour l'index btree-gin/*
gin biginteger integer .
- gin int2, int4, int8,
bigint , bigint (<= 2147483647)
intger_ops, :
create index on tablename using gin(columnname int8_family_ops) with (fastupdate = false);
* /
-- btree_gin
CREATE EXTENSION btree_gin;
CREATE OPERATOR FAMILY integer_ops using gin;
CREATE OPERATOR CLASS int4_family_ops
FOR TYPE int4 USING gin FAMILY integer_ops
AS
OPERATOR 1 <,
OPERATOR 2 <=,
OPERATOR 3 =,
OPERATOR 4 >=,
OPERATOR 5 >,
FUNCTION 1 btint4cmp(int4,int4),
FUNCTION 2 gin_extract_value_int4(int4, internal),
FUNCTION 3 gin_extract_query_int4(int4, internal, int2, internal, internal),
FUNCTION 4 gin_btree_consistent(internal, int2, anyelement, int4, internal, internal),
FUNCTION 5 gin_compare_prefix_int4(int4,int4,int2, internal),
STORAGE int4;
CREATE OPERATOR CLASS int8_family_ops
FOR TYPE int8 USING gin FAMILY integer_ops
AS
OPERATOR 1 <,
OPERATOR 2 <=,
OPERATOR 3 =,
OPERATOR 4 >=,
OPERATOR 5 >,
FUNCTION 1 btint8cmp(int8,int8),
FUNCTION 2 gin_extract_value_int8(int8, internal),
FUNCTION 3 gin_extract_query_int8(int8, internal, int2, internal, internal),
FUNCTION 4 gin_btree_consistent(internal, int2, anyelement, int4, internal, internal),
FUNCTION 5 gin_compare_prefix_int8(int8,int8,int2, internal),
STORAGE int8;
ALTER OPERATOR FAMILY integer_ops USING gin add
OPERATOR 1 <(int4,int8),
OPERATOR 2 <=(int4,int8),
OPERATOR 3 =(int4,int8),
OPERATOR 4 >=(int4,int8),
OPERATOR 5 >(int4,int8);
ALTER OPERATOR FAMILY integer_ops USING gin add
OPERATOR 1 <(int8,int4),
OPERATOR 2 <=(int8,int4),
OPERATOR 3 =(int8,int4),
OPERATOR 4 >=(int8,int4),
OPERATOR 5 >(int8,int4);
Ce script redistribue tous les index de la base de données PostgreSQL pour Zabbix de la configuration par défaut à la configuration optimale décrite ci-dessus./*
* /
--
drop index history_1;
drop index history_uint_1;
drop index history_str_1;
drop index history_text_1;
drop index history_log_1;
-- PK
-- ( , )
alter table trends drop constraint trends_pk;
alter table trends_uint drop constraint trends_uint_pk;
-- bree-gin itemid
-- btree-gin bigint
-- https://habr.com/ru/company/postgrespro/blog/340978/#comment_10545932
-- create extension btree_gin;
create index on history using gin(itemid int8_family_ops) with (fastupdate = false);
create index on history_uint using gin(itemid int8_family_ops) with (fastupdate = false);
create index on history_str using gin(itemid int8_family_ops) with (fastupdate = false);
create index on history_text using gin(itemid int8_family_ops) with (fastupdate = false);
create index on history_log using gin(itemid int8_family_ops) with (fastupdate = false);
create index on trends using gin(itemid int8_family_ops) with (fastupdate = false);
create index on trends_uint using gin(itemid int8_family_ops) with (fastupdate = false);
-- bree-gin itemid
-- brin 128 ,
-- ,
-- https://habr.com/ru/company/postgrespro/blog/346460/
create index on history using brin(clock) with (pages_per_range = 128);
create index on history_uint using brin(clock) with (pages_per_range = 128);
create index on history_str using brin(clock) with (pages_per_range = 128);
create index on history_text using brin(clock) with (pages_per_range = 128);
create index on history_log using brin(clock) with (pages_per_range = 128);
create index on trends using brin(clock) with (pages_per_range = 128);
create index on trends_uint using brin(clock) with (pages_per_range = 128);
Pour l'indice de brin pour notre volume de données à une intensité de 100 tonnes de paramètres par minute (100 tonnes dans l'historique et 100 tonnes dans history_uint), il a été remarqué que l'index fonctionne sur les tables de données de surveillance primaires avec une taille de zone de 512 pages deux fois plus rapide qu'avec la taille standard de 128 pages, mais elle est individuelle et dépend de la taille des tables et de la configuration du serveur. Dans tous les cas, l'indice de brin prend très peu de place, mais sa vitesse peut être légèrement augmentée en ajustant avec précision la taille de la zone, mais à condition que le débit de données ne change pas beaucoup.Par conséquent, il convient de noter qu'il existe une limitation associée à l'architecture de Zabbix lui-même: sur l'onglet «Données récentes», les deux dernières valeurs pour chaque paramètre sont collectées en tenant compte du filtrage. Pour chaque paramètre, les valeurs sont demandées séparément dans la base de données. Par conséquent, plus ces paramètres sont sélectionnés, plus la requête s'exécutera longtemps. Les données les plus récentes sont recherchées lorsque l'index btree (itemid, clock desc) est défini sur des tables d'historique avec un tri inverse par heure, mais l'index lui-même «gonfle» sur le disque et ralentit généralement indirectement la base de données, ce qui provoque un problème, décrit ci-dessus.Par conséquent, il existe trois solutions:- « » 100 (.. , « » )
- Zabbix , , « »
- laissez les index tels qu'ils sont par défaut et limitez-vous au partitionnement uniquement pour obtenir des sélections assez importantes sur l'onglet Données récentes en même temps pour une variété de paramètres (cependant, il a été remarqué que le serveur Web Zabbix a toujours une limite sur le nombre de valeurs de paramètres affichées simultanément sur l'onglet "Données récentes" - donc, lorsque j'essaie d'afficher 5000 valeurs, la base de données a calculé le résultat, mais le serveur n'a pas pu préparer la page Web et afficher une telle quantité de données).
Collecte et analyse des statistiques d'exécution des requêtes pg_stat_statements
Pg_stat_statements est une extension pour collecter des statistiques sur les performances des requêtes sur l'ensemble du serveur. L'avantage de cette extension est qu'elle n'a pas besoin de collecter et d'analyser les journaux PostgreSQL.Utilisation de l'extension pg_stat_statementspsql:
CREATE EXTENSION pg_stat_statements;
postgresql.conf:
shared_preload_libraries = 'pg_stat_statements'
pg_stat_statements.max = 10000 # sql , ( );
pg_stat_statements.track = all # all - ( ), top - /, none -
pg_stat_statements.save = true #
:
SELECT pg_stat_statements_reset();
:
select substring(query from '[^(]*') as query_sub, sum(calls) as calls, avg(mean_time) as mean_time from pg_stat_statements where query ~ 'insert into' or query ~ 'update trends' group by substring(query from '[^(]*') order by calls desc
Pour surveiller les disques durs dans Zabbix, seuls les paramètres vfs.dev.read et vfs.dev.write sont fournis prêts à l'emploi. Ces options ne fournissent pas d'informations sur l'utilisation du disque. Les critères utiles pour trouver des problèmes avec les performances de vos disques durs sont le facteur d'utilisation, l'attente du temps de requête et la charge de la file d'attente de chargement du disque.En règle générale, une charge de disque élevée est en corrélation avec un intérêt élevé du processeur lui-même et avec une augmentation du temps d'exécution des requêtes SQL, qui a été trouvée lors des tests de charge d'un serveur zabbix avec une configuration standard sans partitionnement et sans configuration d'index alternatifs. Vous pouvez ajouter ces paramètres pour surveiller les disques durs en utilisant les étapes suivantes, qui ont été consultées dans un article d'un amilesovsky et amélioré: maintenant les paramètres iostat sont collectés séparément pour chaque disque dans le paramètre de temps json, d'où, selon les paramètres de post-traitement, ils sont déjà décomposés dans les paramètres de surveillance finaux.Pendant que la demande Pull est en attente, vous pouvez essayer d'étendre la surveillance des paramètres du disque selon les instructions détaillées via mon fork .Après toutes les étapes décrites, vous pouvez ajouter un graphique personnalisé avec le processeur iowait et les paramètres d'utilisation du disque système et du disque de la base de données (s'ils sont différents) au panneau de surveillance principal du serveur Zabbix. Le résultat peut ressembler à ceci (sda est le disque principal, sdc est le disque avec la base de données):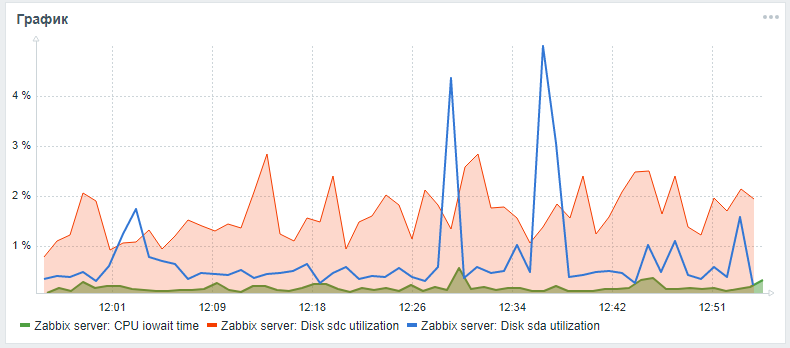
Amélioration des performances matérielles
Après avoir configuré le SGBD, l'indexation et le partitionnement, vous pouvez procéder à une mise à l'échelle verticale - pour améliorer les caractéristiques matérielles du serveur: ajoutez de la RAM, changez les disques en SSD et ajoutez des cœurs de processeur. Il s'agit d'une augmentation des performances garantie, mais il est préférable de le faire uniquement après l'optimisation du logiciel.Création d'un cluster distribué
Après une mise à l'échelle verticale modérée, vous devez démarrer horizontalement - créer un cluster distribué: partitionner ou répliquer l'esclave maître. Mais il s'agit d'un sujet et d'un matériau séparés d'un article séparé (comment mouler un cluster de merde et de bâtons) , ainsi qu'une comparaison de la technique d'optimisation de la base de données Zabbix décrite ci-dessus en utilisant pg_pathman et l'indexation avec la méthode d'application de l'extension TimescaleDB.En attendant, on ne peut qu'espérer que le contenu de cet article s'est avéré utile et instructif!