Comment savoir avec certitude ce qu'il y a à l'intérieur du chignon?
Peut-être l'avalez-vous, et à l'intérieur c'est une rivière? © Tanya Zadorozhnaya
Ce qu'est la Data Science aujourd'hui, semble-t-il, non seulement les enfants, mais aussi les animaux de compagnie le savent. Demandez à n'importe quel chat, et il vous dira: statistiques, Python, R, BigData, apprentissage automatique, visualisation et bien d'autres mots, selon les qualifications. Mais tous les chats, ainsi que ceux qui souhaitent devenir un spécialiste de la science des données, ne savent pas exactement comment le projet Data Science est structuré, en quelles étapes il se compose et comment chacun d'eux affecte le résultat final, à quel point chaque étape du projet est gourmande en ressources. La méthodologie est généralement utilisée pour répondre à ces questions. Cependant, la plupart des formations consacrées à la science des données ne disent rien sur la méthodologie, mais révèlent simplement plus ou moins de manière cohérente l'essence des technologies mentionnées ci-dessus, et chaque débutant de Data Scientist apprend la structure du projet à partir de sa propre expérience (et ratisser). Mais personnellement, j'aime aller en forêt avec une carte et une boussole, et j'aime bien imaginer à l'avance le plan de l'itinéraire que vous empruntez. Après quelques recherches, j'ai réussi à trouver une bonne méthodologie chez IBM, un fabricant bien connu de guides et de méthodes pour gérer quoi que ce soit.
Ainsi, dans le projet Data Science, il y a 3 blocs de 3 étapes dans chacun, un total de 9 étapes. En bref, le projet consiste à travailler avec les exigences métier, les données et le modèle lui-même.
Travailler avec les exigences de l'entreprise
À ce stade, nous ne savons rien des données dont nous disposons. Nous devons nous plonger dans l'énoncé du problème, comprendre quel résultat est nécessaire pour obtenir du projet, tout savoir sur les participants et les parties prenantes. En outre, conformément à une tâche spécifique, nous devons décider par quelle méthode le problème sera résolu. Le résultat de cette étape sera les besoins en données: ok, la tâche est claire, la méthode a été choisie, maintenant nous allons réfléchir à ce dont nous pourrions avoir besoin pour une solution réussie?
Travailler avec des données
À la deuxième étape, nous commençons à rechercher des données pour résoudre le problème: nous découvrons quelles sources sont à notre disposition et formons un échantillon avec lequel nous continuerons de travailler. Après la collecte des données, il est nécessaire de mener une série d'études afin de mieux comprendre comment l'échantillon est organisé: pour étudier la position centrale et la variabilité, pour identifier les corrélations entre les caractéristiques et pour construire des graphiques de distribution. Après cette étape, vous pouvez commencer à préparer les données. En règle générale, cette étape est la plus exigeante en main-d'œuvre et peut prendre jusqu'à 90% du temps total du projet, mais le succès de l'ensemble du projet dépend de sa réussite.
Développement et mise en œuvre
Enfin, la troisième étape. Une fois les données prêtes, vous pouvez procéder au développement et à la mise en œuvre réels. Nous programmons le modèle, le plaçons sur l'échantillon de formation, le vérifions sur celui de test, si le résultat est satisfaisant, puis le démontrons au client, le mettons en œuvre, assemblons les commentaires et ... vous pouvez tout recommencer.
L'ensemble du processus est présenté sous la forme d'un cercle vicieux: dans le bon sens, un projet DS ne peut jamais être considéré comme finalisé (à peu près, comme une réparation, qui, comme vous le savez, ne peut pas être terminée, mais peut seulement être arrêtée):
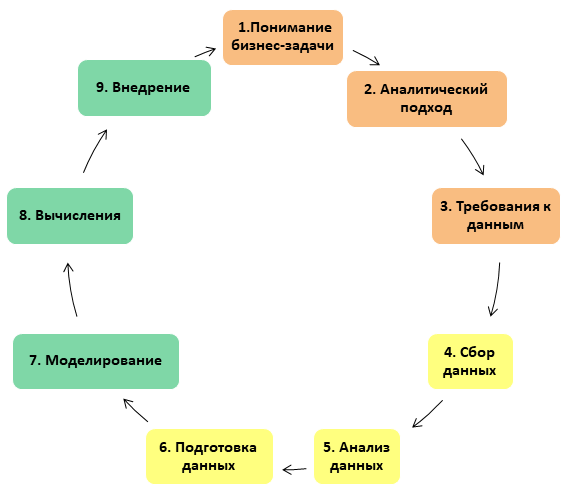
Allons plus en détail sur chacune des étapes.
1. Comprendre le défi commercial
Cette étape est le fondement de tous les travaux ultérieurs: sans elle, vous ne pouvez rien construire. Il est nécessaire de définir clairement le but de l'étude: quel est le problème? Pourquoi le problème devrait-il être résolu? Qui est concerné par le problème? Quelles sont les alternatives? Et le plus important: par quelles mesures le succès du projet sera-t-il mesuré?
En d'autres termes, il est nécessaire d'identifier clairement l'objectif du client. Par exemple, un propriétaire d'entreprise demande: pouvons-nous réduire le coût d'une certaine activité? Besoin de clarifier: l'objectif est-il d'augmenter l'efficacité de cette activité? Ou augmenter les revenus de l'entreprise?
Une fois l'objectif défini, vous pouvez passer à l'étape suivante.
2. L'approche analytique
Vous devez maintenant choisir une approche analytique pour résoudre un problème commercial. Le choix de l'approche dépend du type de réponse que vous devez obtenir au final: si la réponse doit être oui / non, un classificateur Bayes naïf convient. Si vous avez besoin d'une réponse sous la forme d'un signe numérique, les modèles de régression conviennent. Les arbres de décision peuvent traiter à la fois des données numériques et catégorielles. Si la question est de déterminer les probabilités de certains résultats, il est nécessaire d'utiliser un modèle prédictif. Si des liens doivent être identifiés, une approche descriptive est utilisée.
3. Exigences en matière de données
Lorsque l'objectif de l'étude est clairement défini et que l'approche est choisie, c'est-à-dire que nous comprenons clairement quel type de réponse à la question que nous recherchons, il est nécessaire de déterminer quelles données nous permettront de donner la réponse souhaitée. Nous devons préparer les exigences en matière de données: contenu, formats et sources qui seront utilisés dans la prochaine étape du projet.
4. Collecte de données
À ce stade, nous collectons des données à partir des sources disponibles: nous nous assurons que les sources sont disponibles, fiables et peuvent être utilisées pour obtenir les données requises dans la qualité requise. Une fois la collecte de données initiale terminée, il est nécessaire de comprendre si nous avons reçu les données que nous souhaitions. À ce stade, vous pouvez réviser les exigences en matière de données et prendre des décisions sur le besoin de données supplémentaires (c'est-à-dire qu'il est probable que vous deviez revenir à l'étape 3). Les lacunes peuvent être identifiées dans les données et un plan peut être établi sur la façon de les fermer ou de trouver un remplaçant.
5. Analyse des données
L'analyse des données comprend tous les travaux de conception d'échantillonnage. À ce stade, il est nécessaire d'obtenir une réponse à la question: les données collectées sont-elles représentatives de la tâche?
Ici, nous avons besoin de statistiques descriptives. Elle s'applique à toutes les variables qui seront utilisées dans le modèle sélectionné: la position centrale (moyenne, médiane, mode) est examinée, les valeurs aberrantes sont recherchées et la variabilité est estimée (en règle générale, il s'agit de la magnitude, de la variance et de l'écart-type). Des histogrammes de la distribution des variables sont également construits. Les histogrammes sont un bon outil pour comprendre comment les valeurs des données sont distribuées et quel type de préparation est nécessaire pour que la variable soit la plus utile lors de la construction d'un modèle. D'autres outils de visualisation, tels que des boîtes à moustache, peuvent également être utiles.
Ensuite, des comparaisons par paires sont effectuées: des corrélations entre les variables sont calculées pour déterminer lesquelles sont liées et combien. S'il existe des corrélations significatives entre les variables, certaines d'entre elles peuvent être rejetées comme redondantes.
6. Préparation des données
Avec la collecte et l'analyse des données, la préparation des données est l'une des activités les plus gourmandes en ressources du projet: ces phases peuvent prendre 70, voire 90% du temps du projet. À ce stade, nous traitons les données de manière à ce qu'il soit pratique de les utiliser: supprimer les doublons, traiter les données manquantes ou incorrectes, vérifier et, si nécessaire, corriger les erreurs de formatage.
À ce stade également, nous construisons un ensemble de facteurs avec lesquels l'apprentissage automatique fonctionnera dans les étapes suivantes: nous extrayons et sélectionnons des fonctionnalités susceptibles d'aider à résoudre un problème commercial. Les erreurs à ce stade peuvent s'avérer critiques pour l'ensemble du projet, il convient donc d'y prêter une attention particulière: un nombre excessif d'attributs peut conduire à la reconversion du modèle et insuffisant à la sous-formation du modèle.
7. Construire un modèle
Le choix du modèle, comme vous pouvez le voir, est effectué au tout début du travail et dépend de la tâche commerciale. Ainsi, lorsque le type de modèle est déterminé et qu'il existe un échantillon d'apprentissage, l'analyste développe le modèle et vérifie comment il fonctionne sur l'ensemble des fonctionnalités créées à l'étape 6.
8. Application du modèle
L'application du modèle est étroitement liée à la construction réelle du modèle: les calculs alternent avec la configuration du modèle. À ce stade, nous devons répondre à la question de savoir si le modèle construit répond à la tâche métier.
Le calcul du modèle comporte deux phases: des mesures de diagnostic sont effectuées pour aider à comprendre si le modèle fonctionne comme prévu. Si un modèle prédictif est utilisé, un arbre de décision peut être utilisé pour comprendre que la sortie du modèle correspond au plan d'origine. Dans la deuxième phase, la signification statistique de l'hypothèse est vérifiée. Il est nécessaire de s'assurer que les données du modèle sont correctement utilisées et interprétées et que le résultat obtenu est au-delà de l'erreur statistique.
9. Mise en œuvre
Si le modèle nous donne une réponse satisfaisante à la question, cette réponse devrait commencer à être bénéfique. Lorsque le modèle est développé et que l'analyste est confiant dans le résultat de son travail, il est nécessaire de présenter au client l'outil développé. Il est logique d'attirer non seulement le propriétaire du produit, mais aussi d'autres parties intéressées: marketing, développeurs, administrateurs système: tous ceux qui peuvent en quelque sorte influencer l'utilisation future des résultats du projet. Ensuite, vous devez passer à la mise en œuvre. L'implémentation peut se produire par étapes, par exemple, pour un groupe limité d'utilisateurs ou dans un environnement de test. Il est également nécessaire de mettre en place un système de rétroaction afin de suivre dans quelle mesure le modèle développé réussit la tâche. Après un certain temps, cette rétroaction sera utile afin d'améliorer le modèle. De nouvelles sources de données, de nouvelles parties prenantes peuvent également apparaître, sans oublier le fait que la tâche métier elle-même peut être précisée. Ainsi, il n'y a pas de limite à la perfection: même un modèle embarqué ne peut jamais être considéré comme idéal.