Le développement a beaucoup changé ces dernières années. Au lieu d'applications monolithiques, des microservices et des fonctions sont venus. Les bases de données de monstres industriels universels sont devenues étroitement ciblées. Docker a changé d'avis sur le déploiement. Mais notre idée des journaux a-t-elle changé?
L'un des gros problèmes de Yandex.Verticals était les journaux - 18 To par jour et 250 000 journaux par seconde, tout est écrit dans des fichiers. Les journaux sont hétérogènes car il existe de nombreux langages: Scala, Java, Python, Go. Ensuite, ils sont collectés par Fluent Bit, écrit en Kafka, les gestionnaires travaillent sur une machine à repasser, assemblent à partir de Kafka et écrivent tout sur le disque. De plus, il s'agit de la deuxième version des journaux.

En conséquence, un long problème de recherche se pose. Ces journaux sont recherchés à l'aide de grep. Sur certains services, grep peut atteindre des heures. Si vous rencontrez des problèmes de production, vous ne rechercherez pas vos journaux pendant des heures. Pour résoudre le problème, Yandex a décidé d'écrire son propre vélo de livraison de journaux pour la recherche. Ce qui en est
ressorti , le dira
Alexei Danilov (
danevge ) - le développeur de l'équipe d'infrastructure de Yandex.Verticals. Développe, écrit et prend en charge les projets auto.ru et Yandex.Real Estate.
Clause de non-responsabilité. L'article parle de développement moderne et convient à l'architecture de microservices. Divers produits sont présentés ici - ce sont des outils utilisés dans Yandex.Verticals. Dans d'autres conditions, les analogues sont possibles avec plus de succès, mais ils remplissent presque les mêmes fonctions. Remarque L'article est une version étendue du rapport d'Alexey Danilov «Les journaux ne sont pas nécessaires» à RIT ++ 2019 DevOps Conf, qui est stylistiquement modifié et complété par de nouveaux éléments. Vous pouvez trouver l'enregistrement vidéo du discours d'Alexey sur le lien sur notre chaîne YouTube.
L'équipe Yandex.Vertical compte 300 personnes, dont une centaine de développeurs. En développement, nous ne sommes pas différents de la plupart des entreprises qui créent leurs propres solutions de produits. Microservices, tout le monde vit à Docker, un monolithe en PHP recueille la poussière dans un coin sombre, déployé via Hashicorp Nomad et nous gardons un zoo de langages: Scala, Java, Go, Node.js, Python.
L'un des gros problèmes d'infrastructure dans Yandex.Verticals est le journal des applications. Lorsque nous avons sérieusement abordé ce problème, nous avons utilisé la troisième version de leur collecte et de leur traitement. Simplifié, cela a fonctionné comme ceci:
- applications écrites dans des fichiers;
- Fluent Bit a lu des fichiers et les a envoyés ligne par ligne dans le fichier Kafka;
- Sur une machine à repasser dédiée, il y avait une application qui lisait le sujet Kafka et écrivait dans des fichiers sur le disque.
Pendant la saison chaude, nous avions 18 To de journaux par jour, soit 250 000 lignes par seconde. C'est une très grande quantité, ce qui complique le travail avec ces données. La seule façon d'analyser cela est grep, car tout est stocké dans des fichiers. Pour les grandes applications, l'analyse peut prendre des heures. Pour les problèmes de production, vous n'avez pas ce temps.
Les solutions toutes faites ne correspondaient pas au prix, aux ressources ou à la vitesse. Ils ne pouvaient pas gérer de manière acceptable notre flux. Il est même difficile de compter le nombre de tentatives de cuisson d'Elasticsearch. Je suppose que nous ne savons pas comment le faire cuire. Mais ce n'est pas ce dont nous avons besoin, si pour l'utiliser comme référentiel de journaux, des capacités (compétences) spéciales sont requises.
Dans cette situation, nous avons décidé de mettre en place notre propre système de collecte et d'analyse des journaux.
Vélo
 Remarque: Si le prochain vélo n'est pas intéressant, passez immédiatement à la section "Typification".
Remarque: Si le prochain vélo n'est pas intéressant, passez immédiatement à la section "Typification".Format
Nous utilisons plusieurs PL et aimons les microservices. Pour travailler avec les journaux, nous avons uniformément formé notre propre format JSON. Il couvre la plupart des besoins de travaux supplémentaires avec les journaux.
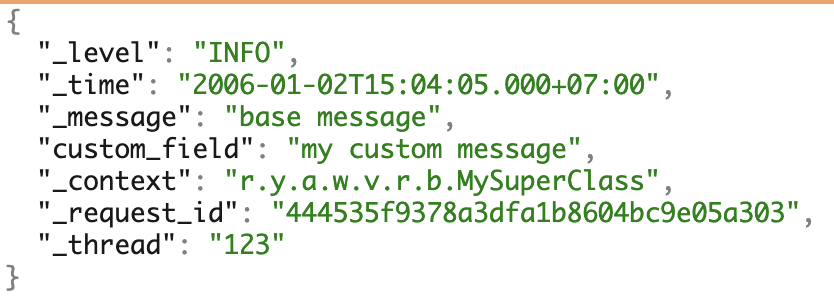 Un exemple de journaux avec tous les champs possibles.
Un exemple de journaux avec tous les champs possibles.Pilote de journal Docker
Pour collecter les journaux, nous avons écrit notre propre
pilote de journal Docker - une application sur Go. Il est assemblé d'une manière spéciale, livré par les commandes du plugin docker, stocké dans le registre et s'exécute dans une seule instance exécutant Docker.
Étant donné que tout problème avec le pilote de journal peut affecter négativement tout le travail, nous avons essayé d'écrire une implémentation minimale. Notre chauffeur écoute la sortie standard du conteneur et transmet immédiatement les journaux à l'application qui se trouve à proximité. Il traite déjà de la partie la plus complexe de la livraison.
Les problèmes
Je mentionnerai séparément les problèmes de mise à jour de la version du pilote de journal docker.
 Capture d'écran du Grafana interne.
Capture d'écran du Grafana interne.À gauche, le rapport entre les versions installées et les machines. Maintenant, trois versions sont installées sur tout le matériel - aucune voiture n'est perdue nulle part et il n'y a aucune installation inutile. À droite, le nombre de conteneurs qui utilisent telle ou telle version.
Le pilote docker ne peut pas aller mettre à jour immédiatement. Pour ce faire, vous devrez redémarrer tous les conteneurs et tous les services, ce qui pourrait entraîner des problèmes. Par conséquent, pour installer la nouvelle version, nous attendons simplement que tous les conteneurs se mettent à jour.
Schéma général
Considérez le schéma général d'un nouveau système de collecte et de livraison des journaux. D'autres détails ne sont pas si intéressants.
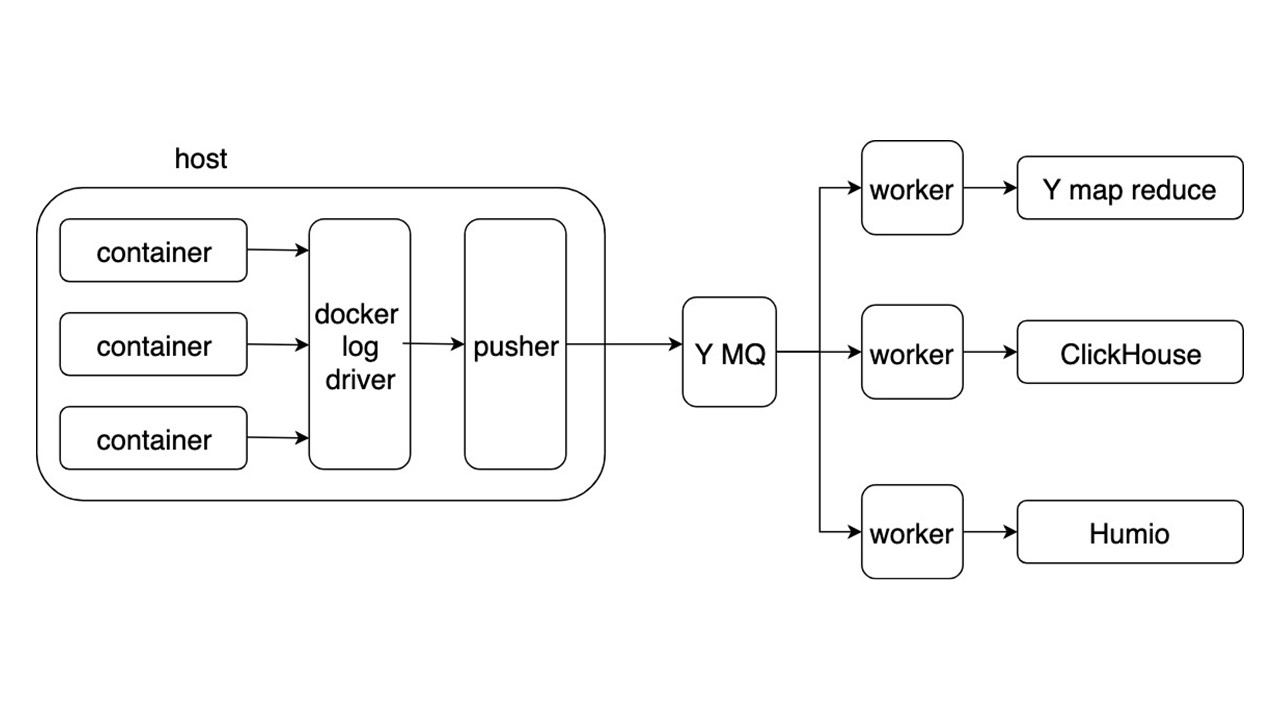
Les applications écrivent des journaux au format JSON dans stdout. Docker écoute le tuyau depuis le conteneur et le redirige vers le pilote Docker. Le pilote Docker lit et refond de manière asynchrone tout dans Pusher.
Pusher se tient sur chaque voiture en fer. Il prépare, sature, retourne et pousse les journaux dans Yandex Message Queue. Le flux de journaux de MQ est analysé par trois types de travailleurs et écrit dans les référentiels.
Il existe trois référentiels pour l'enregistrement des journaux.
- Yandex mapReduce pour stocker et analyser les journaux sur une longue période de temps. Ceci est un analogue de Hadoop.
- Cliquez sur Maison pour stocker les journaux le dernier jour.
- Humio (à titre expérimental) pour stocker les journaux du dernier jour.
Bénéfice
Le format général vous permet d'écrire et de traiter les journaux de la même manière. La collecte des journaux est automatique, sans utiliser de disque, et la livraison se fait en quelques secondes. Recherche de clé de 2 secondes à 5 secondes. Stockage et récupération sur une longue période.
Pour les volumes plus petits, envisagez des alternatives: Humio, Splunk et Elastic. Les deux derniers ont des pilotes Docker officiels. Si vous vivez dans AWS, c'est Amazon CloudWatch.
Amazon cloudwatch
Amazon CloudWatch gère les métriques, les événements et les journaux. Il ne recherche pas ce dernier, ne donne pas d'éléments de super-recherche et ne les traite pas sous la forme habituelle. Amazon CloudWatch traite les journaux, les analyses, les filtres et les affichages sur les graphiques.
 Amazon CloudWatch convertit les journaux en métriques et graphiques.
Amazon CloudWatch convertit les journaux en métriques et graphiques.Que faire des journaux?
Revenons à notre vélo - satisfait-il tous les cas? Non, notre solution vous permet de retrouver les logs, mais ils nécessitent une hétérogénéité beaucoup plus grande des informations et de leurs types. Les journaux sont utilisés dans beaucoup plus de cas.
Dès que vous collectez les journaux, la phrase suivante sera: "Analysons quelque chose, le traitons d'une manière ou d'une autre, l'écrivons quelque part et commençons à l'afficher sur des graphiques, sur des tableaux de bord." C'est le chemin de l'enfer. Surtout si nous parlons d'outils communs.
Si vous imaginez les journaux comme un certain chaos ou journal d'événements de toutes les données, ils ne fonctionneront pas.
Ce sera un gros gâchis d'informations qui ne peuvent pas être traitées. Un jeu va commencer dans la formalisation des logs: "Écrivons ces lignes dans un format spécial pour qu'il soit plus pratique de les analyser plus tard!" Ça ne marche pas non plus. Croyez-nous, nous avons essayé.
Dactylographie
Si vous divisez les journaux en types et les traitez séparément, vous pouvez trouver des outils qui faciliteront leur utilisation. Ne fonctionnant plus comme avec les journaux, mais comme avec les données utiles - un tel travail est plus transparent et plus pratique. Certains types de journaux peuvent être supprimés.
Juste au cas où
Ce type de journaux «à être» est mon préféré. S'il est impossible de dire clairement pourquoi telle ou telle ligne est nécessaire, alors ils le sont. Ce type peut également être appelé "journaux au cas où".
// validate customer func Validate(customer Customer) { // ??? log.debug(“Validate customer %v”, customer) … log.Error(“Customer not valid %v. Reason: %s”, ...) …. }
Les journaux ne sont pas des commentaires qui peuvent être supprimés. Cela fait partie du code qui est plus difficile à modifier, à maintenir et encore plus à supprimer.
Dans le meilleur des cas, un tel journal peut se transformer en débogage ou en trace. Ce type
encombre le code . En raison de la journalisation irréfléchie, je peux y récupérer des données personnelles, des mots de passe et des cookies d'utilisateurs.
La bonne façon est de les
jeter et de les oublier . Mais alors nous sommes confrontés à un nouveau problème. Comment analyser la situation avec une erreur?
Erreur fatale / critique
Pour commencer, nous ne considérons que les erreurs critiques. Ce sont des erreurs dues aux utilisateurs et aux développeurs. Le premier - quand ils ne peuvent pas terminer l'opération. La seconde - lorsque vous devez effectuer des corrections à la main.
Pourquoi les bûches ne correspondent pas?
Pas de réponse rapide . Si l'équipe de développement apprend l'erreur des utilisateurs via l'assistance ou via Twitter, il est temps de changer quelque chose.
Il n'y a pas de contexte . Une ligne distincte du journal des erreurs est inutile. Nous devons collecter le contexte petit à petit. Néanmoins, cela peut ne pas être suffisant, car c'est le contexte du processus, pas l'erreur.
Il n'y a pas de grande image . Pas de réponse aux questions:
- combien de fois une telle erreur se produit;
- il s'est produit sur les répliques restantes du service;
- c'était avant?
Pour résoudre ces problèmes, utilisez un outil approprié, par exemple,
sentry.io . Il vous permet de travailler avec des informations d'erreurs représentatives et complètes (contextuelles) avec une
alerting rule personnalisable.
Le site Web sentry décrit les différences dans les journaux par rapport à l'utilisation de sentry.io.
Erreur non critique
Nous avons jeté des erreurs fatales et critiques et maintenant elles sont écrites dans Sentry. Mais il y avait des erreurs internes - diverses bibliothèques ou des réponses de services tiers.
Un bon exemple est une nouvelle tentative réussie. Supposons que le service A se soit tourné vers le service B mais, en raison de problèmes de réseau, n'a pas pu obtenir de réponse. Après l'erreur, le service A s'est à nouveau tourné vers le service B et a reçu une réponse valide. L'erreur au premier appel est-elle critique? Non. Dans ce cas, le processus s'est terminé avec succès et l'utilisateur a pu utiliser le service.
Si de telles erreurs ne sont pas critiques pour que le service fonctionne et qu'elles n'affectent pas l'utilisateur avec une répétition rare, alors ce ne sont pas du tout des erreurs. Il s'agit d'une dégradation du service, bien que la réponse de l'utilisateur soit arrivée 50 ms plus tard. Ce type de journal fait référence aux avertissements - Avertissement.
Avertissement
Les alertes sont des informations sur la dégradation d'un service.
Nous verrons ici les mêmes problèmes inhérents aux erreurs critiques, mais avec une réserve. La réaction à un événement individuel n'est pas importante - leur quantité dans le temps est importante.
Prenons un exemple où un service ne peut pas récupérer une entrée de cache et accède au stockage à froid. Si cela se produit une fois par minute, cela peut être pris pour le fonctionnement normal du service.
Les émissions rares ne sont pas importantes .
Mais en même temps, vous avez besoin d'un outil pour visualiser la situation dans son ensemble, vous avez besoin d'
une analyse en temps réel . Pour suivre les changements sur une longue période, il serait bien d'avoir également une
analyse rétrospective . Une dégradation au-dessus d'un certain niveau (seuils) peut nuire aux utilisateurs - vous avez besoin d'une
réaction avec une dégradation sévère .
Nous n'avons pas besoin des journaux marqués Avertissement, mais des mesures de dégradation.
L'outil de collecte métrique le plus populaire est Prometheus, et vous pouvez utiliser Grafana pour la visualisation. Si vous avez besoin d'un contexte large (identique à l'erreur), la même Sentry fera l'affaire, mais avec des alertes désactivées. Cependant, dans la plupart des cas, le contexte sera suffisant. Il sera utilisé pour les graphiques - étiquettes Prometheus.
Exemples.
Trois événements se sont produits dans le service utilisateur conditionnel. Ils affectent le fonctionnement du service: une longue requête à la base de données, un accès répété à l'API du service
service_b et aucun droit utilisateur n'a été trouvé dans le cache. Les graphiques et les alertes seront configurés comme importants pour les développeurs du service, grâce au contexte.
Traçage
C'est la première chose à commencer si nous choisissons le chemin où vous devez analyser les journaux. En soi, ces informations dans les journaux sont inutiles, car vous devez créer des chaînes d'appels, voir les données à l'intérieur des demandes, les erreurs dans les chaînes d'appels, les temps de réponse, le nombre de RPS.
Il existe d'excellents outils de traçage - Jaeger ou Zipkin. Je recommande d'utiliser OpenTracing, qu'ils prennent tous les deux en charge.
Vous pouvez collecter le traçage à partir de trois sources.
- Si vous utilisez des équilibreurs partagés, analysez-en les journaux et envoyez-les à Jaeger.
- Services eux - mêmes , s'ils reçoivent des adresses via Service Discovery et y vont directement. Dans ce cas, la trace des services est envoyée directement à Jaeger.
- Maillage de service intelligent. Il sait comment collecter et envoyer une trace, par exemple Istio.
Information initiale
Ces informations concernent les appels de service API, le lancement de Cron, les requêtes de base de données ou les appels à d'autres services.
{ "_message": "Request: ...; request_id: ...,... ", "_level": "INFO", "_time": "2019-03-08T12:04:05.000+07:00", "_context": "ryawvcHandler", "_tread": "785534" }
Ces informations appartiennent au bloc «Juste au cas où», mais elles sont séparées car elles sont plus courantes. Ces informations sont nécessaires pour analyser l'erreur et
vous pouvez la jeter .
Si les informations sur les appels aux méthodes internes sont d'une importance cruciale et que vous ne pouvez pas vous en passer, même avec le contexte collecté en cas d'erreur, il vaut la peine d'instrumenter les appels de méthode comme trace.
Temps d'exécution
Ces informations concernent le temps d'exécution des méthodes, des API, des requêtes de base de données ou d'autres services.
{ "_message": "Get customer 12ms", "_level": "INFO", "_time": "2019-03-08T12:04:05.000+07:00", "_context": "ryawvcCustomerRepository", "_tread": "785534" }
Il n'y a aucune valeur dans les journaux, car vous devez analyser ces informations, les afficher sur des graphiques et configurer des seuils. Ce type de journaux doit être remplacé par des
métriques , par exemple, dans Prometheus.
Info entreprise
Ces informations sont nécessaires pour l'analyse commerciale, l'analyse du comportement des clients et les calculs financiers. À cet endroit, nous avons historiquement utilisé l'approche opposée - les journaux analysés. Mais c'est un bon exemple de ce que les journaux d'application peuvent dégénérer si vous travaillez avec eux de cette manière.
Pour les journaux contenant des données commerciales, des accords ont été conclus avec des champs fixes au format TSKV, qui sont nécessaires pour l'analyse. Les applications ont écrit des journaux d'entreprise dans un fichier dédié. Ensuite, les journaux ont été lus et envoyés ligne par ligne à MQ, et une application distincte les a traités et les a écrits dans la base de données. Ceci est un exemple de ce que toute analyse se transforme.
Il ne fonctionnera pas pour analyser l'intégralité du flux de journaux dans l'espoir que les données convergent.
Des conventions, des formats, des règles et des exigences de fiabilité font leur apparition. Cela ressemble déjà un peu aux journaux des applications. Dans ce cas, le journal devient la file d'attente de livraison de données avec toutes les exigences qui en découlent pour MQ. Il est à noter que le middleware sous forme de journal est ici superflu.
Une bonne solution consiste à envoyer ces données directement à MQ. Déjà là, ils seront traités, stockés dans le stockage approprié et utilisés par l'équipe d'analyse. Par exemple, pour l'affichage, nous utilisons Tableau.
Performances
Ce type de journal est rarement trouvé dans les journaux des applications et est plus souvent collecté en tant que métrique. Séparément, j'ajoute que pour collecter les métriques de base spécifiques à la langue, il suffit d'utiliser la bibliothèque Prometheus. Elle collectera par défaut tout ce qu'elle atteint. Le coût de l'ajout de ces mesures est faible.

Résultat de frappe
Après avoir trié les journaux par type, nous pouvons choisir des outils plus puissants pour travailler avec eux. Il n'y a pas de systèmes complexes ou de technologies spatiales comme Amazon, il n'y a rien qui ne puisse pas être soulevé demain. Vous avez probablement déjà certains de ces systèmes ou analogues: Sentry ramasse de la poussière quelque part, Prométhée travaille quelque part.

Le problème n'est pas dans la technologie, mais dans un piège cognitif lorsque nous faisons confiance aux journaux comme moyen de représentation fiable de l'état de notre système. Ce n'est pas le cas, les journaux sont un ensemble d'événements chaotiques.
Il existe une exception - les journaux de débogage, qui peuvent être utilisés dans de rares cas.
Journal de débogage
Les journaux de débogage doivent être des informations détaillées. Ils ne doivent pas reproduire ce qui est déjà envoyé aux systèmes que nous avons décrits ci-dessus. Ce type existe pour l'analyse des cas spéciaux. Par exemple, un bogue incompréhensible se produit en production et, pour le moment, les mesures ne permettent pas de savoir ce qui se passe.
Activez les journaux de débogage à chaud, sans redémarrer le service . Puisque nous parlons de plusieurs services, il n'y en aura pas beaucoup. Une infrastructure sophistiquée n'est pas nécessaire. Assez de pile ELK sans "préparation" compliquée. Il est également judicieux d'ajouter une alerte à Sentry avec tout le contexte nécessaire.
Les journaux de débogage peuvent être utilisés pour le développement . Mais ils sont parfaitement remplacés par le débogage.
Pour résumer
Nous avons écrit notre livraison de journal de vélo pour la recherche . Nous n'avons pas satisfait les clients du service - ils viennent tous chez nous pour les analyser, les collecter et les agréger quelque part. Cela peut être évité - des systèmes complexes de traitement des journaux ne sont pas nécessaires.
Les journaux bruts sont inutiles, mais ils peuvent être transformés en mesures utiles.
Il suffit de créer une infrastructure pour fournir des métriques et des données utiles autour des services. En conséquence, des métriques utiles apparaîtront qui parleront des services et montreront de manière transparente tout ce qui leur arrive.
Les erreurs doivent contenir le contexte de l'erreur elle-même.
Cela vous aidera à y faire face et à le corriger immédiatement.
Les erreurs et la dégradation doivent conduire à une action , afin que les développeurs
soient instantanément informés des problèmes et les résolvent même avant les demandes des utilisateurs en colère.
Les bons outils rendront le travail avec vos services plus agréable et transparent . Le débogage a sa place, mais vous devez être strict avec lui.
À HighLoad ++ 2019 en novembre, il y aura une section DevOps - 13 rapports sur les charges dans AWS, un système de surveillance à Lamoda, des convoyeurs pour la livraison des modèles, la vie sans Kubernetes, et bien plus encore. Voir la liste complète des sujets et résumés sur la page séparée « Rapports ». Et nous nous rencontrerons au DevOpsConf au printemps - inscrivez-vous à la newsletter , faites-nous savoir quand nous déterminerons les dates et le lieu.