En novembre 2018, un département de soutien à l'information a été créé en Lituanie et a invité
Andrei Yumashev à diriger. L'année dernière, le département aide l'entreprise à travailler et à se développer et à garder toute l'infrastructure sous contrôle. Mais cela n'a pas toujours été le cas. Avant de commencer à travailler, Andrei était confronté à des ruines: Nagios à moitié mort, des cactus vivants et des marionnettes comateuses, un Wiki mort de 120 pages, des tables de tâches et une liste de fer incohérentes, une architecture obsolète, 340 cœurs inactifs, 2 To de RAM et 17 To l'espace disque qui, pour une raison quelconque, n'a pas été enregistré dans les tables d'inventaire. Des plans qui ne fonctionnent pas, des délais qui dépassent, un environnement de travail et des outils qui ne sont pas là - tout cela attendait Andrei dans un nouveau projet.

Lors de
DevOpsConf 2019, Andrei a fait un rapport dans lequel il a montré sur des exemples en direct ce qui vaut et ce qui ne devrait pas être fait lorsque vous entrez dans un projet que vous n'avez pas vu ou que vous connaissez mal. Sous la coupe se trouve une version mise à jour de l'histoire - comment analyser correctement la gamme de problèmes et construire un plan d'activité, comment calculer correctement les KPI et quand s'arrêter à temps.
Andrey Yumashev est le propriétaire de ses propres sociétés de développement dans divers domaines (en ligne et hors ligne), un consultant sur la construction de processus et le chef du département de support de l'information chez LiteRes.
Un peu plus sur LiteRes. Il s'agit du plus grand fournisseur de livres électroniques et audio en Russie, d'une maison d'édition et de nombreux projets de partenariat. Ce sont des centaines de milliers de lignes de Perl, plusieurs clusters de bases de données et référentiels. Cela représente 2 Go de trafic sortant par seconde, des centaines de milliers de demandes uniques par jour, plusieurs racks dans différents centres de données et plus de 100 serveurs. Dans l'ensemble, ce n'est pas seulement une librairie électronique.
Premiers pas
J'avais l'habitude de travailler dans LiteRes à la pièce. L'entreprise pratique le développement des effectifs avec l'enregistrement des employés à distance dans l'État.
Le système d'exécution des tâches en litres fonctionne sur le principe d'une «vente aux enchères». Dans le tracker de tâches interne, les gestionnaires et les architectes décrivent les tâches des projets internes et les évaluent en monnaie locale. La devise est «champignons, herbe et arbre».
Commence alors la «vente aux enchères facile» - tout développeur peut prendre la tâche ou négocier. Bravo - vous êtes payé. Je ne travaillais pas du tout - vous ne comprenez pas. De façon ludique, les gens sont intéressés à accomplir des tâches. Pour en savoir plus sur ce système, voir la
présentation de Dmitry Gribov.
 Travaillez pour les champignons.
Travaillez pour les champignons.Le système me convenait - j'ai soutenu l'expérience de programmation Perl, travaillé quand c'était pratique et n'y ai pas passé trop de temps. Dans ce mode, j'ai passé quelques années jusqu'en novembre de l'année dernière et j'ai pensé comprendre la structure de l'écosystème.
J'avais tort
J'ai été invité dans l'entreprise et informé que mes services en tant que développeur Perl n'étaient pas nécessaires, et on m'a proposé de diriger un nouveau département. En novembre 2018, je suis devenu chef du service information.
Devant moi se trouvaient des espaces ouverts: plusieurs racks avec du fer dans plusieurs centres de données à Moscou, une architecture dépassée, des ressources étrangères et l’absence presque complète de documentation pertinente pour tout cela. L'introduction sonnait quelque chose comme ceci: "Maintenant, c'est votre patrimoine, améliorez, ne cassez pas et soutenez." Il y avait une liste de tâches prête à l'emploi et des plans approximatifs pour l'année à venir. Il fallait comprendre tout cela et le mettre sous une forme humaine.
Il y avait un sentiment que je regardais dans l'abîme, et l'abîme me regardait.
L'expérience des dernières années m'a beaucoup aidé lorsque j'ai développé une position claire en travaillant avec un inconnu ou incompréhensible. Il s'agit tout d'abord d'une étude approfondie et d'un plan d'action minimal. C'est là que j'ai commencé.
La propreté est la clé de la santé
L'ordre est avant tout.
Pour le premier mois a réussi à trouver:
- Google Sheets dispersés avec les tâches en cours et une pincée d'informations utiles;
- documents épars: Word, textes, bouts de vieilles pages Wiki 120;
- Nagios à demi mort;
- surveillance conditionnelle en direct des cactus;
- marionnette très ancienne avec de rares signes de vie.
Toutes ces ruines ont également collecté 400 métriques.
 Les ruines que j'ai trouvées le premier mois.
Les ruines que j'ai trouvées le premier mois.J'étais un peu amusant, j'ai tout lu couramment et je suis resté fidèle aux processus Trello. Il lui a transféré les tâches actuelles de ses collègues et a commencé à rêver - à rédiger un plan pour le trimestre et l'année.
Première erreur
Aucun plan jusqu'à ce que vous exploriez la région.
Le plan brillait de chaleur et de santé, mais ne tenait pas compte de la réalité. C'était beau et simple: implémenter la surveillance, analyser les journaux et transférer le déploiement sur CI / CD. Quelque part à la fin, il y a eu une «analyse des faiblesses du projet» languissante. Premiers pas classiques.
J'ai oublié l'essentiel. Ma première priorité n'est pas de mettre en place des outils pour la mise en place d'outils, mais d'assurer la viabilité et la stabilité du service dans son ensemble.
Pendant que j'écrivais le plan et tourmenté par les questions de mes collègues, les premiers problèmes sont arrivés. L'un des nœuds d'un des clusters de cluster a manqué d'espace et le SSD dans son ensemble s'est terminé sur l'autre nœud du même cluster. J'ai acheté de toute urgence de nouveaux disques plus gros et notre service a rapidement acquis de l'expérience dans le remplacement de ces disques en copiant le système d'un disque à l'autre. Après avoir remplacé les disques, nous avons construit le cluster à partir de zéro via SST. Le cluster est construit sur Percona et Galera, et un tel divertissement ne lui revient pas pour rien.
Pendant que je voyageais entre les centres de données, les
premiers germes du doute sur le plan sont nés.
 Ahhhhhh!
Ahhhhhh!En même temps, l'intensité du travail noir était si élevée que je ne pensais même pas à recueillir des antécédents médicaux complets, mais j'ai simplement pris quelques photos pour une étude plus approfondie.
En parallèle, une autre introduction est apparue. En litres, il existe des versions audio des livres. Pour que l'auditeur ne rembobine pas l'enregistrement à chaque fois, nous avons un mécanisme qui suit le moment de l'arrêt. La prochaine fois que vous écoutez, la version audio est lue à partir de la section souhaitée. Pour cette tâche, il a fallu trouver environ 500 cœurs plus rapidement, un téraoctet de RAM et un peu d'analyse en Java.
J'ai commencé à informer Azure, Google, DigitalOcean et tout le reste fourni par les solutions de droplet. La conteneurisation demande, pourquoi ne pas la mettre en œuvre joyeusement? De plus, dans le "grand" plan, il y avait un point distinct à ce sujet.
Un mois s'est écoulé dans la correspondance et les enchères, tout a été ajouté aux tâches de Trello, dont j'ai généré une part importante, mais le résultat n'a pas progressé. Je me demandais si j'allais là-bas. Avant moi, tout a fonctionné d'une manière ou d'une autre et ne va pas s'arrêter, peu importe la quantité d'activité vide que je montre. Je me suis assis soigneusement pour étudier petit à petit l'inventaire que j'ai réussi à collecter. Puis il s'est levé et s'est rendu au deuxième tour des centres de données.
La deuxième visite sereine des centres de données a tout remis à sa place. Quand j'ai vu tout cela pas dans la console, pas dans Excel, mais vivant, ma conscience de la réalité a radicalement changé. J'ai réalisé que je ne suis pas du tout occupé par ce que je devrais. Parce que vous devez d'abord comprendre avec quoi je travaille.
Jusqu'à ce que je comprenne avec quoi je travaille, tous les plans sont une perte de temps.
J'ai étudié les racks, comparé la réalité aux listes, effectué des modifications et suis tombé sur une semi-unité à 20 lames. Sur 20, seulement 4 ont fonctionné, j'ai secoué les lames et j'ai réalisé que nous n'avions pas besoin de gouttelettes pour la solution. Parce que j'ai trouvé 340 cœurs dormants, 2 téraoctets de RAM et 17 téraoctets d'espace disque! Ce sont de vieux backends, de vieux nœuds de clusters qui ont tout simplement cessé d'utiliser, et le temps a effacé la mémoire de leur existence. J'ai roulé Kubernetes sur ces lames et me suis débarrassé d'une tâche majeure.
Première sortie d'erreur
Analyser et étudier. Sans une analyse préliminaire de la situation, le train ne bouge pas.
Grâce à un voyage réfléchi sur le terrain, j'avais déjà entre les mains un plan assez pertinent pour l'équipement et l'architecture globale du système. Dans la cour était en janvier. J'ai passé deux mois là-dessus, dont la moitié je me suis précipité d'un côté à l'autre. Je ne savais pas quel type d’incendie éteindre en premier, quel problème résoudre en premier - la routine avec assistance n’allait nulle part.
En parallèle, j'ai déduit trois règles. Ce sont les conséquences de la première erreur.
 Trois corollaires.
Trois corollaires.Deuxième plan
J'ai retiré les tâches secondaires du premier plan - l'analyse du journal et la mise en œuvre de CI / CD. À l'échelle d'une catastrophe générale, ces petites choses n'ont pas d'importance. Litres a fonctionné pendant des années et a développé ses propres logiques pour travailler avec des journaux, et a acquis un démon roulant autodidacte. J'ai poussé dans le cinquième plan ce qui a fonctionné et n'a pas nécessité d'intervention.
Le deuxième plan ressemblait à quelque chose comme ça.
Gérez la surveillance . Dans sa forme actuelle, elle ne reflétait pas au moins un tiers des problèmes, même si cela fonctionnait.
Décrivez la logique générale des litres entiers . Les noms de serveur sont excellents, mais les ensembles de clés sont des connaissances essentielles: quoi, où, où, pourquoi et pourquoi. L'erreur précédente a clairement montré que sans cela en aucune façon.
Mise à l'échelle . Presque les dernières ressources gratuites ont pris Kubernetes. Selon des estimations minimales, il était censé terminer l'ensemble du travail en six mois.
Inventaire et état du matériel . Dans le cadre du voyage, j'ai littéralement nettoyé un site Web à partir d'un certain nombre de serveurs qui ont fait peur avec leurs balises - «sauvegarde», «abonnement», «bgp». Encore une fois, des disques, des disques tombants.
Adapter les guides à la réalité . La plupart des instructions sont obsolètes ou incomplètes.
Les six premiers mois sont passés inaperçus dans le chiffre d'affaires, l'achat de matériel et les ennuis, et je me suis finalement installé dans la deuxième erreur.
Deuxième erreur
Ne sous-estimez pas.
Tout terme qui me vient à l'esprit est sous-estimé . Bien sûr, vous pouvez rapidement bénéficier du projet. Mais pour maximiser les rendements, multipliez le temps prévu par
au moins deux fois . Surtout sur un projet complexe et très chargé, dont le trafic augmente régulièrement de plus de 100% par an.
Pourquoi au moins deux fois? Si le projet est instable et non recherché, préparez-vous au fait que toute activité donnera lieu à d'autres activités dans les lieux voisins. Il semblerait que le remplacement des disques - ce qui est plus facile? La procédure est simple jusqu'à ce que vous tombiez sur un achat, puis la planification du temps pour des nœuds spécifiques d'indisponibilité, puis l'entretien après le remplacement d'un disque. J'ai estimé cette opération simple par semaine. En fin de compte, cela a pris deux semaines et demie - même avec un simple système d'approvisionnement.
Un autre exemple est l'achat et l'installation de nouveaux équipements. Acheter et coller, qu'est-ce qui est si difficile? Je n'ai pas pris plus d'un mois pour cela sans tenir compte du délai de livraison. En fait, l'un des trois châssis est toujours debout devant mon bureau. C'est parce que l'équipement n'avait tout simplement pas assez d'espace - nous avons calculé la place dans les trous entre l'installation actuelle. Lorsque nous sommes arrivés dans l'un des centres de données avec l'intention de secouer le rack, nous avons soudain réalisé que les deux serveurs étaient «intouchables». Le premier est l'hôte, et il n'est tout simplement pas sûr de le toucher. Le second est un panier de 16 disques, en cours de fermeture qui est semé d'un tas de tas de données. Les pailles n'ont pas été posées, l'analyse n'a pas été effectuée et il est bon qu'ils aient pu en coller deux sur trois.
S'il semble que tout sera simple, vous aurez bientôt des problèmes . Cette installation a soulevé une nouvelle question - si tout va si mal avec l'endroit, alors comment allons-nous nous développer? Une petite tâche a maintenant engendré une sueur géante. En 2020, selon le plan, le transfert d'un data center à un autre et l'extension du reste par des racks. Cela signifie une migration au sein du centre de données entre les modules. La migration a été complétée par la restructuration du réseau et son transfert vers la 10G.
Ne sous-estimez pas le calendrier, le seuil d'entrée et les conséquences.
Concepts de base
Bien sûr, l'essence des erreurs est déjà décrite dans le wiki comme des concepts de base.
Tout processus bureaucratique dure au moins un mois . Cela s'applique à l'approvisionnement, à la conclusion de nouvelles conditions avec un centre de données ou d'autres entrepreneurs - à tout. Prenez-le comme un fait.
Après la conclusion du contrat et le paiement, toute livraison dure au moins une semaine et demie , des disques aux processeurs. Apprenez à négocier avec les fournisseurs pour les dates de pré-livraison. Par exemple, les disques nous sont expédiés par petits lots maintenant jusqu'au paiement et même avant l'approbation de la demande.
Bien qu'il n'y ait pas de compréhension claire de la mise en œuvre, tout plan pour mettre en œuvre quelque chose reste un plan. Plus les étapes sont courtes, mieux c'est.
Par exemple, pour passer de MySQL à ClickHouse, une large étape ressemble à ceci: "Remplissons un serveur, puis dessinons un ticket pour la réintégration et volons!" En fait, une étude détaillée du problème a conduit à de nouvelles étapes: achat supplémentaire d'équipements, par exemple, processeurs et disques, tickets détaillés pour changer la logique du traqueur de comportement des utilisateurs, maintien de l'intégration inverse, serveurs de files d'attente et bien d'autres.
Plus le plan est détaillé, mieux c'est. Écrire avec un coup de pinceau large est une garantie de 100% d'erreur dans le délai.
Soumettez tout plan à un maximum de critiques et attendez-vous à un risque maximum . Assurez-vous de regarder le plan d'un point de vue commercial - quel profit chaque étape apportera.
Nous avons dû réaliser des implémentations obligatoires: monitoring, Ansible, mais nous n'avons pas oublié la composante métier.
- En modifiant l'architecture du réseau, nous pourrons accepter du trafic supplémentaire et résoudre de nombreux problèmes actuels.
- En changeant le type de stockage de contenu, nous réduirons le nombre de bogues avec le retour des livres et augmenterons la vitesse de travail avec les données.
- Déplacez le backend vers le cloud - adaptez instantanément la charge lors des campagnes marketing.
- La traduction du suivi dans ClickHouse est une opportunité pour les analystes de mieux comprendre les besoins de nos lecteurs et auditeurs bien-aimés.
La meilleure façon de faire face à une situation où vous êtes mal familiarisé avec le sujet est de demander l'aide de spécialistes, pas de débordement de pile . Le contact vocal résout le problème plusieurs fois plus rapidement qu'une longue correspondance ou la lecture de documentation.
Six mois plus tard
Malgré le fait que les tâches de base sur lesquelles je me reposais au début dérapaient encore, grâce aux recherches et aux corrections, quelque chose de bien est apparu dans mes mains.
Outil auto-écrit pour l'inventaire des réseaux et des adresses. Il tapait régulièrement tous nos sous-réseaux et vérifiait en outre les données avec la configuration BIND. Cela a rendu facile et rapide la mise en service de nouveaux services et la compréhension de la charge réelle des pools de réseaux. Je ne voulais vraiment pas y consacrer du temps, mais je ne pouvais pas trouver d'alternative toute faite, et trouver une adresse à allouer à une nouvelle ressource prenait beaucoup de temps. Lors de la rédaction de l'outil, la première ébauche du plan est apparue sur le réseau.
La marionnette n'est plus aussi morte et confuse . J'étais armé d'une conclusion de l'erreur numéro un et je n'ai même pas essayé de passer à Ansible, ce qui est plus confortable pour moi.
Nagios plus ou moins truqué . Je l'ai déplacé du bureau vers le centre de données et l'ai distribué en trois points. C'était beaucoup plus rapide et moins cher que l'implémentation de Zabbix. Nous avons bouché un trou avec des alertes incorrectes dans le temps et les événements, une simple reconfiguration des règles et l'introduction de nœuds de contrôle supplémentaires.
Comprendre la maintenance des clusters de bases de données utilisés.
Wiki fortement gonflé . Elle a "grossi" à partir de commentaires et d'instructions sur l'utilisation des environnements.
Trois châssis HP que nous avons achetés pour une future installation.
Comprendre le chemin vers le reste de 2019 dans une approximation plus claire.
Écosystème recyclé pour le travail du département.
Pendant ces six mois, j'ai travaillé presque seul. Les employés qui ont hérité étaient davantage d'administrateurs système. Ils n'étaient pas vraiment impatients de se plonger dans l'essence de DevOps.
Avec beaucoup de difficulté, j'ai trouvé deux spécialistes dans l'équipe - junior et middle. J'ai rassemblé le maximum de connaissances, d'apparences et de mots de passe des administrateurs actuels et je me suis séparé d'eux avec le cœur lourd.
Système de travail, environnement et outils
Je vais vous parler de l'importance d'introduire un écosystème et un environnement de travail. J'ai déjà mentionné Trello, mais je n'ai pas dit pourquoi et pourquoi je l'ai mis en œuvre. Aucun travail ne sera construit sans fixer des objectifs et des données structurées. Cela est partiellement démontré par la première erreur - collectez tout ce qui est.
Prenez tout, ne donnez rien.
Le processus est le moteur du progrès . Par conséquent, pendant tout ce temps, j'ai travaillé sur le système, malgré l'obstruction de la recherche et du flux de travail. Grâce au système, six mois plus tard, j'ai mis la locomotive à vapeur du département sur des rails stables.
L'introduction d'outils de support et un court cours sur son utilisation permettent de gagner beaucoup de temps pour vous et vos collègues. Surtout si vous, même au sommet, comprenez dans la gestion et un peu capable de maintenir l'ordre sur le bureau et dans la vie.
Nous ne compliquons pas les outils, nous partons du simple et introduisons le nécessaire . Au début de l'année, j'ai pensé au tracker qui nous conviendrait. A immédiatement licencié Jira et Redmine - trop de contrôle. Nous passerions du temps à remplir les formulaires, pas les tâches. Google Sheets - Je pense que cela ne vaut pas la peine d'expliquer pourquoi.
Trello était parfait . Quelques colonnes simples: «Backlog» - où toutes les erreurs ou tâches constatées pour le futur s'additionnent, «À la fin» - les principales tâches à effectuer et «Terminer». Un peu plus tard, il y avait cinq colonnes: «Backlog», «Pause», «Sprint», «Finish» et «Study».
Dans la "pause", des choses qui ont perdu leur pertinence dans le processus de sprint. Dans «Learning» - tâches qui nécessitaient des recherches et ne devraient pas être perdues jusqu'au moment de la compréhension et du transfert des connaissances vers le Wiki. Le sprint est devenu la preuve que nous sommes passés au système de sprint. — 2 . , .
.
— , Trello. . , , . 2-3 , . , .
. — Puppet, Nagios, DNS — SVN GitLab. Jenkins. DNS , Puppet - . , 1Password. .
, .
: , , . , .
— . . , , . , — «.».
( ) - DDoS- . , , DDoS. DNS , 10 DNS . , — , , — . , 20 .
Cloudflare . Anti-DDoS . , Cloudflare . . , DDoS' , .
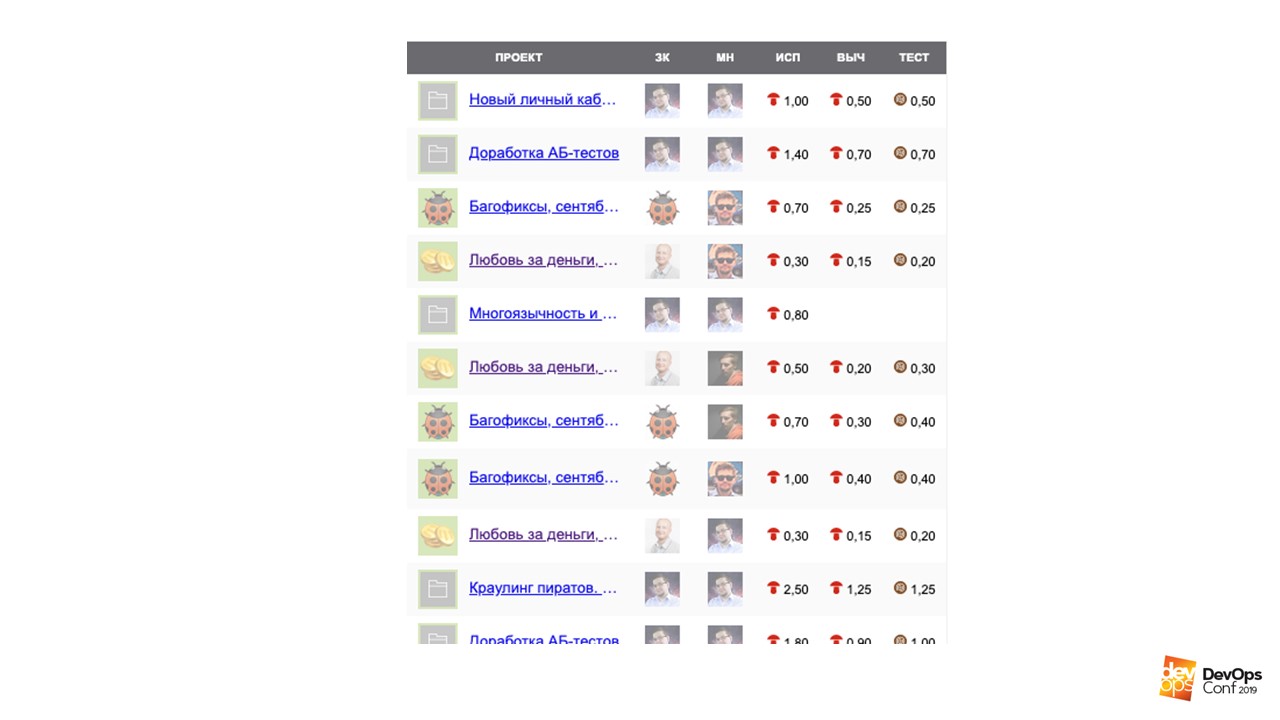
. KPI.
KPI
. . , , .
KPI. — .
- . — .
- Downtime. — .
- . , --, , . , .
KPI, — . , , KPI, .
. 90%. , . — , . . , .
-Nagios -Puppet Zabbix Grafana Ansible. « ».
Prometheus , Zabbix. Zabbix, Prometheus — . — . .
, , .
. ,
, . — . , .
. - -, - . , . . . . .
, .
2 . 3 « », — . .
. : , , , Ansible, .
. , . . .
.
— , , . .
. — , .
. , . . 2019. , , , — . .
. .
.
, - , . .
- , , .
- , .
- , , — .
- , , , — , .
. , - . , , , .
.
— , , . , , .

, — - . , .
« , ». , — , , , .
, , .
—
Ansible? , , Puppet ? — .

CI/CD? , . CI/CD , — .
., , . - ? , KPI? , -.
- — , , .
.
:La prochaine conférence professionnelle DevOpsConf aura lieu au printemps. Le programme est toujours en développement - inscrivez-vous à la newsletter , faites-nous savoir quand nous déterminons les dates et le lieu. Et la prochaine réunion des ingénieurs DevOps se tiendra à HighLoad ++ 2019 en novembre. La section DevOps contient 13 rapports sur les charges de travail dans AWS, un système de surveillance dans Lamoda, des convoyeurs pour la livraison de modèles, la vie sans Kubernetes, la vie avec Kubernetes, le minimalisme de Kubernetes et bien plus encore. Voir la liste complète des sujets et résumés sur la page séparée « Rapports » et réserver des billets . Cette année, HighLoad ++ se tiendra dans trois villes à la fois - à Moscou, Novossibirsk et Saint-Pétersbourg. En même temps. Comment ce sera et comment y arriver - découvrez-le sur une page de promo séparée événements.