Parfois, cela se produit comme ceci:
- Venez, nous sommes tombés. Si vous ne le soulevez pas maintenant, il sera diffusé à la télévision.
Et nous allons. La nuit. De l'autre côté du pays.
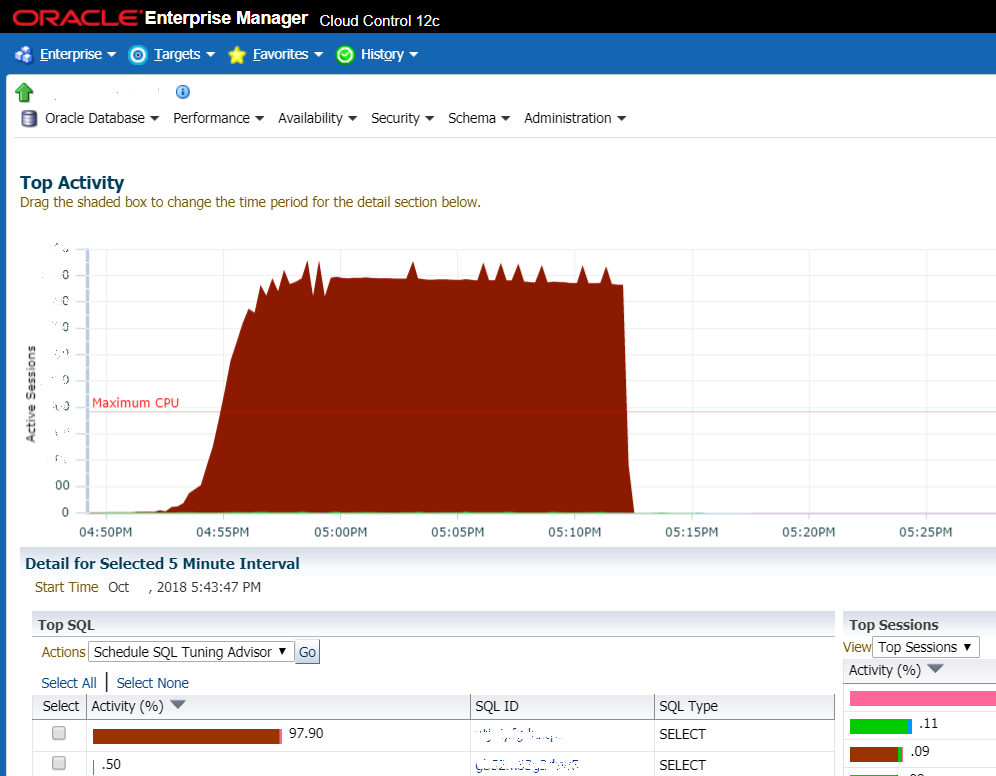 La situation quand pas de chance: le graphique montre une forte augmentation de la charge sur le SGBD. Très souvent, c'est la première chose que les administrateurs système regardent et c'est le premier signe qu'un âne est venu
La situation quand pas de chance: le graphique montre une forte augmentation de la charge sur le SGBD. Très souvent, c'est la première chose que les administrateurs système regardent et c'est le premier signe qu'un âne est venuMais le plus souvent, nous parlons de choses typiques. Par exemple, un client est confronté à un système de workflow médiocre. Les lundis et mardis, le système s'est écrasé, ils ont redémarré le serveur, puis tout s'est amélioré. La base de données s'étouffait. Ils voulaient acheter du matériel (qui est long et cher), ils nous ont appelés pour calculer le devis. Nous avons calculé l'estimation pour eux et en même temps proposé de comprendre ce qui ralentit exactement. En trois à quatre heures, la source du problème a été localisée. Nous avons découvert qu'il s'agit de requêtes de base de données lentes et de schémas d'indexation sous-optimaux. Nous avons créé les index manquants, fouillé avec l'optimiseur de requêtes dans Oracle, certains problèmes nécessitaient de changer le code - nous avons changé les conditions de recherche (sans changer la fonctionnalité), remplacé certaines des demandes par l'utilisation de vues pré-calculées. S'ils avaient une personne normale dans la base de données - ils pourraient faire de même eux-mêmes. Mais au lieu d'une personne normale, la base de données a été auditée tous les six mois par des oracleistes sympas - ils ont émis des recommandations générales sur les paramètres et le matériel.
Comment ça se passe
Les détails sont un peu modifiés à la demande de sécurité. Il existe un système de gestion des documents dans des centaines d'installations industrielles. Elle tombe parfois et le travail augmente. Autrement dit, les objets peuvent fonctionner, mais aucun document ne passe et n'est pas signé. Et cela, en particulier, l'expédition des matières premières, les salaires et les commandes, quoi et combien produire par quart de travail. Chaque chute est une douleur, des larmes, du cognac pour le CIO, car c'est dur pour lui: beaucoup de pertes.
Le réalisateur, d'ailleurs, n'a que six mois à cet endroit après le passé. Et l'année dernière a duré. Et tous deux travaillent sur un système que le réalisateur a présenté il y a trois générations. Le deuxième de la fin a tenté de présenter le sien, mais n'a pas eu le temps avant le licenciement. La situation est très réaliste.
À première vue, pas assez de performances. Le profil de chargement est verrouillé (classe d'attente "Application"). Autrement dit, la concurrence pour les lignes. Nous commençons à enquêter sur l'incident. Une session est ouverte pour chaque transaction utilisateur. Il passe rapidement à l'état de blocage de l'ordre, selon lequel les tâches et les instructions d'exécution sont écrites, car l'utilisateur doit mettre au minimum un visa «Familier».
Le dernier cas - ils ont élaboré une nouvelle norme sur la fréquence à laquelle les employés doivent subir un examen médical. L'officier supérieur du personnel a écrit un ordre et l'a envoyé à toutes les organisations. Autrement dit, chaque employé de chaque production. Des dizaines de milliers d'utilisateurs ont reçu des transactions de visa. Ils ont commencé à ouvrir des commandes presque simultanément, à mettre une longue chaîne de verrous dans la base de données. En raison du code non optimal, un «petit» débordement s'est produit et tout a été obstrué. Environ 40 000 utilisateurs ne fonctionnent pas. À partir du schéma de sauvegarde - uniquement les téléphones et le courrier. La production ne s'arrête pas, mais l'efficacité diminue fortement, ce qui entraîne des pertes financières spécifiques. Et puis les appels commencent personnellement de chaque entreprise au directeur informatique avec un discours. En pratique, ils ont un SLA, mais il n'y a pas encore d'accord. Et la situation reprend les derniers traits de l'histoire purement russe.
Le problème de résolution rapide a été résolu par le profilage, l'analyse de la logique de blocage des objets, l'élimination des objets inutiles sur lesquels le verrou a été défini, bien que cela n'ait pas été nécessaire car l'objet n'a pas changé (par exemple, répertoires, droits d'accès, etc.). Puis, en quelques mois, les principales sections du code ont été refactorisées.
Comment ces sections de code sont-elles recherchées?
En plus des outils standard (vidages de threads, journaux, métriques, AWR, données des représentations du système, etc.), nous utilisons davantage d'outils civils, y compris commerciaux.
Exemple 1: journal des transactions lentesDes plaintes d'utilisateurs ont été reçues concernant la lenteur du fonctionnement du journal (problème connu et fréquent).
Nous trouvons la vue du problème, puis nous recherchons la demande dans les opérations de la vue deal_journal_view. Nous recherchons toutes les transactions où il y a une telle demande à l'intérieur.

Pour chacune des opérations, vous pouvez consulter ses détails et trouver la demande elle-même avec les paramètres d'exécution, ce qui vous permet d'analyser le fonctionnement de la demande, de valider et d'ajuster le plan. Trouvé une demande lente spécifique.

Ils ont eux-mêmes analysé et proposé des options d'optimisation. Et seulement alors, pour suivre ce groupe d'opérations commerciales (afficher le journal des transactions), créer un type de transaction et configurer des alertes.
 Exemple 2: trouver les raisons de la lenteur du travail des utilisateurs 1
Exemple 2: trouver les raisons de la lenteur du travail des utilisateurs 1L'utilisateur 1 a reçu des plaintes concernant le lent fonctionnement de l'application. Nous regardons:

Toutes les opérations des utilisateurs ont été recherchées et triées par durée. Ensuite, les opérations les plus lentes ont été analysées et des requêtes lentes vers le système externe (SAP) ont été détectées.

Il l'a pointé vers l'équipe adjacente, l'a corrigé.
Exemple 3: un autre utilisateur se plaint du lent fonctionnement de l'applicationNous regardons de la même manière. Cette fois, nous voyons un grand nombre d'appels vers un service de signature externe. Il s'est avéré que, sous certaines conditions, ils ont signé deux fois certains documents. Corrigé.
 Exemple 4: quand il n'y a pas assez de détails
Exemple 4: quand il n'y a pas assez de détailsParfois, pour analyser des parties plus complexes du code, nous avons recours à des profileurs personnalisés, qui nous permettent d'étudier plus en profondeur le comportement de l'application. Par exemple, comme ici: beaucoup de logique incompréhensible lors du fonctionnement de la logique dans le système. Nous avons compris la logique, ajouté quelques caches, optimisé les requêtes.
 Exemple 5: plus de freins
Exemple 5: plus de freinsL'utilisateur s'est plaint de la lenteur du travail avec les cartes de contrat.

Les opérations lentes des utilisateurs (paramètre = 'userlogin = ”...”') pendant une semaine sont analysées. La plupart des problèmes concernaient les requêtes de recherche sous contrat, mais des opérations avec une carte de document ont également été trouvées. La plupart du temps est consacré à la création d'un grand nombre de tâches sur les affectations. Des identifiants ont été trouvés (la colonne Valeur du paramètre dans la capture d'écran) des tâches stockées et l'heure de leur sauvegarde.
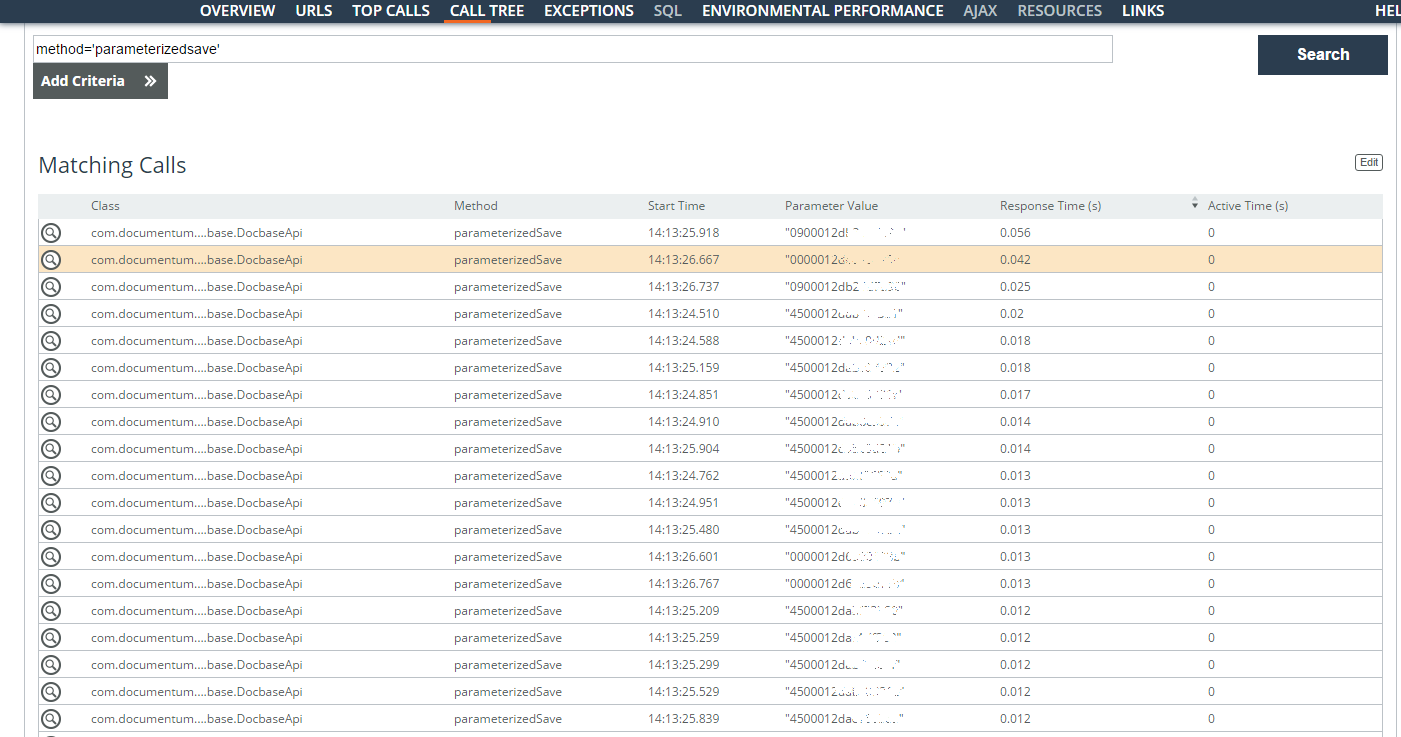
Logiquement, lorsqu'ils peuvent être créés de manière asynchrone, mais maintenant ils sont mis en file d'attente et nécessitent des verrous exceptionnels. Ici, vous devez déjà approfondir l'architecture.
C'est aussi simple que cela: vous devez trouver un goulot d'étranglement - et c'est tout?
Non.
Et encore une fois, non.
C'est tout un traitement pour les symptômes.
Il est juste de sauver rapidement la situation, qui est maintenant en feu. Et puis mettez les processus. Il est rare que les gens qui travaillent avec un système ne comprennent pas ce qu'ils font. C’est juste qu’ils doivent justifier les moyens de réduire la dette technique (et personne ne les croit), ou changer les processus pour des processus plus modernes (pour lesquels il n’y a pas de ressources non plus), ou faire autre chose comme ça.
En général, nous venons du plus haut niveau et voyons de la douleur chez le client. Ensuite, nous attrapons le goulot d'étranglement. Parfois, cela se termine par l'introduction d'un système de surveillance. Et si le client comprend qu'il est nécessaire de changer les processus de développement logiciel, alors l'étape commence "longue, coûteuse et même pas du tout impressionnante".
Nous regardons deux ou trois projets, sélectionnons tous les documents, référentiels, interviewons les gens. Ensuite, nous préparons des modèles pour de nouveaux documents, préparons des procédures, examinons des outils pour gérer les exigences, tester. Et nous aidons à mettre en œuvre. Parfois, il suffit juste de donner une opinion sur ce qu'il faut changer, et le DSI ailé avec du papier obtient un budget. Parfois, il est nécessaire d'injecter directement du sang et des larmes.
Tout peut s'avérer pénible, allant du mauvais choix d'architecture à certaines fonctionnalités du workflow.
Ces exemples concernent les processus de jeu dans différentes entreprises du pays.
Concernant l'optimisation de la base de données, voici un exemple typique. Il y a un système médical (un de ceux qui sont tombés). Ils nous ont appelés pour regarder. Nous sommes arrivés alors qu'ils avaient déjà désactivé tous les modules, à l'exception du flux de travail des médecins, de sorte qu'au moins d'une manière ou d'une autre, les analyses se dérouleraient et l'enregistrement via le registre serait. L'enregistrement en ligne, en particulier, faisait partie des modules désactivés. J'ai réussi à tout réparer en une semaine. Initialement, le client pensait que les problèmes étaient sur la couche application: il y avait des échecs de timeout et des threads bloqués. Nous avons découvert que le problème venait de la base de données. Il y avait une structure complexe, un tas de sections par jour et par mois. Il s'est avéré qu'ils avaient oublié quelques index, les développeurs ne savaient pas complètement à quoi cela allait se transformer au fil du temps - et voici le résultat. Environ le même ensemble d'opérations plus les restrictions de recherche (lorsque vous devez décharger quelque chose dans une plage de dates, il serait bien de regarder entre ces dates, et non dans toute la base de données).
Il est clair qu'une telle optimisation ne résout pas toujours le problème. Par exemple, (par architecture) le secteur de l'énergie: le client demande à voir avec quoi le système raccroche. Et là, tout a volé à la livraison, mais après quelques années, il y avait beaucoup plus de documents, et tout a bien freiné. Le client s'est assis avec un chronomètre sur le lieu de travail de l'opérateur et a dit: cette opération prend maintenant 31 secondes, nous en voulons 3. Celle-ci est de 40 secondes, nous en voulons 2. Et ainsi de suite. Il est clair que mesurer de cette façon n'est pas très correct, mais la tâche est assez spécifique et peut être facilement présentée sous forme de critères objectifs. Nous n’avons pas tout fait, il a fallu environ six mois pour «nettoyer». Pour la plupart, la logique a été transférée en exécution asynchrone, certaines des bases de données ont été remplacées par noSQL, le moteur de recherche Solar a été installé, dans une section, il était nécessaire de sélectionner la base de données la plus chaude et de la mettre en mémoire. En conséquence, environ 90% des besoins ont été fermés, mais à certains endroits, ils n'ont pas pu réduire les retards. C'est le travail de bibliothèques tierces, les limitations physiques de la plate-forme, etc. Tout cela a été contrôlé par la surveillance et a pu prouver clairement où et ce qui ralentit.
Sinon, pourquoi une telle surveillance pourrait-elle être nécessaire?
Nous utilisons différents logiciels de surveillance pour trouver rapidement les processus inhibiteurs et les optimiser. L'équipe informatique de l'un des principaux clients a examiné la façon dont nous procédons et a demandé de la mettre en œuvre dans l'une des installations en tant qu'outil permanent. OK, surveillé tous les processus et nœuds, personnalisé leur système pour les tâches, travaillé pendant près de quatre mois, mais créé un ensemble d'outils pour les prendre en charge. Et il y a 80 mille utilisateurs, il y a les première et deuxième lignes à l'intérieur et souvent la troisième - avec des entrepreneurs ou aussi à l'intérieur.
Sur la deuxième ligne se trouve juste cet ensemble d'outils. Désormais, dans environ 50% des cas, ils utilisent la surveillance pour diagnostiquer, rechercher les goulots d'étranglement et les causes des gels, afin que leurs propres développeurs puissent voir, comprendre et optimiser. Beaucoup de temps d'assistance est économisé en identifiant rapidement la cause du problème. Après le pilote mis à l'échelle par transaction. C'est ce qui a pris quatre mois: il y a une opération commerciale pour toute action. L'ouverture d'une carte de document est une transaction commerciale. La signature dans un système de workflow est une transaction commerciale. Signalez également le téléchargement ou la recherche. 1 500 de ces opérations commerciales en quatre mois sont décrites pour comprendre où et ce qui fonctionne. La surveillance avant cela a vu les appels http et voit les méthodes et fonctions appelées, voit les demandes spécifiques. Avant cela, seuls les développeurs avaient compris qu'il s'agissait d'un accord d'accord ou d'une recherche. Afin que le système de surveillance affiche des données pertinentes pour différentes lignes d'assistance et pour les entreprises, nous avons mis en place tous ces bundles.

L'entreprise a également commencé à réduire les rapports sur son propre développement informatique. Plus d'informations sur les journaux, personne ne les choisit en particulier.
Soit dit en passant, sur tout pourquoi les systèmes de classe
APM sont nécessaires et comment les choisir, nous parlerons lors d'un
webinaire le 1er octobre .
Quoi d'autre il y a des «prises» du côté technique?
Encore quelques exemples. Une grande banque étrangère avec des bureaux de représentation en Russie. Nous prenons en charge Oracle DB et Oracle Weblogic. Une baisse progressive de la productivité a été observée dans le système, les opérations commerciales ont été effectuées plus lentement, le travail de l'opérateur est devenu de moins en moins efficace, et pendant les périodes d'importations et de synchronisation avec l'INS, tout était complètement gelé. Dans de tels cas, nous utilisons des outils Java et Oracle standard pour collecter des données: nous collectons des vidages de threads, les analysons dans des services gratuits ou utilisons des outils d'analyse auto-écrits, examinons AWR, retracez l'exécution des requêtes SQL, analysons les plans et les statistiques d'exécution. En conséquence, en plus des choses standard, telles que l'optimisation de la composition des indices et l'ajustement des plans de requête, nous avons proposé d'introduire le partitionnement en divisant les données. Il s'est avéré deux segments: historique (les a laissés sur le disque dur) et opérationnel - placé sur le SSD. Avant cela, il était assez difficile de comprendre quelles données se rapportaient à quoi, car les données historiques devaient encore être régulièrement descendues, à la fois sur les longs rapports et dans les opérations ordinaires. En raison de la séparation correcte, plus de 98% des opérations principales ne sont pas entrées dans des données historiques lentes. Ce qui est important, il n'y a pas eu d'entrée dans le code système. Il arrive que certaines de nos recommandations nécessitent des modifications du code d'application, qui ne sont pas prises en charge par nous, alors nous sommes généralement d'accord.
Deuxième exemple: un fabricant international dans le domaine de l'industrie légère et du segment FMCG en général. Le temps d'arrêt du site principal coûte environ 20 millions de roubles. La charge moyenne sur la base est de 200 AS (sessions actives) avec des pics allant jusqu'à 800-1000. Il n'est pas rare qu'un optimiseur de requêtes perde sa tête, les plans commencent à flotter pour le mieux et la concurrence folle pour le cache de tampon commence. Personne n'est à l'abri de cela, mais vous pouvez réduire la probabilité: pendant deux mois, nous avons surveillé le système, analysé le profil de charge, éteint les incendies en cours de route, ajusté les schémas d'indexation et de partitionnement, la logique de traitement des données du côté du code PL / SQL. Ici, vous devez comprendre que dans un système vivant et en développement, un tel audit doit être effectué régulièrement, bien que les tests de résistance soient utiles, mais pas toujours. Et les entreprises effectuent des audits en invitant des oracleistes tiers, mais rarement aucune d'entre elles ne descend au niveau de la logique métier et est prête à se plonger dans les données tout en interagissant avec les développeurs. Nous le faisons.
Eh bien, je veux dire que le problème n'est pas toujours le manque de nettoyage régulier ou de soutien approprié. Souvent, les problèmes sont dans les processus.
Pourquoi avons-nous besoin de tels services avec leurs développeurs en direct?
Parce que les entreprises aiment les décisions, pas les processus. C'est la raison principale.
La seconde est que tout le monde ne peut pas allouer de ressources pour rechercher un goulot d'étranglement dans une application, surtout s'il s'agit d'une application tierce. Et loin d'être toujours dans une seule équipe, il y a des gens avec les compétences nécessaires. À l'heure actuelle, nous avons un ingénieur système, des ingénieurs réseau, des spécialistes d'Oracle et du 1C, des personnes capables d'optimiser Java et le frontend de notre équipe.
Eh bien, si vous êtes intéressé à plonger dans les détails, alors
le 1er octobre, il y aura notre webinaire sur ce que vous pouvez faire à l'avance, avant que tout ne tombe. Et voici mon courrier pour les questions - sstrelkov@croc.ru.