Il n'est pas nécessaire de représenter spécifiquement la base FIAS:

Vous pouvez le télécharger en cliquant sur le
lien , cette base de données est ouverte et contient toutes les adresses des objets en Russie (registre d'adresses). L'intérêt pour cette base de données est dû au fait que les fichiers qu'elle contient sont assez volumineux. Ainsi, par exemple, le plus petit est de 2,9 Go. Il est proposé de s'y arrêter et de voir si les pandas peuvent y faire face si vous travaillez sur une machine avec seulement 8 Go de RAM. Et si vous ne pouvez pas faire face, quelles sont les options pour alimenter les pandas dans ce fichier.
La main sur le cœur, je n'ai jamais rencontré cette base et c'est un obstacle supplémentaire, car le format des données qui y sont présentées n'est pas du tout clair.
Après avoir téléchargé l'archive fias_xml.rar avec la base, nous en obtenons le fichier - AS_ADDROBJ_20190915_9b13b2a6-b3bd-4866-bd1c-7ab966fafcf0.XML. Le fichier est au format xml.
Pour un travail plus pratique dans les pandas, il est recommandé de convertir xml en csv ou json.
Cependant, toutes les tentatives de conversion de programmes tiers et de python lui-même entraînent une erreur ou un arrêt "MemoryError".
Hm. Et si je coupe le fichier et le convertis en plusieurs parties? C’est une bonne idée, mais tous les "cutters" essaient également de lire l’ensemble du fichier en mémoire et de le bloquer, le python lui-même, qui suit le chemin des "cutters", ne le coupe pas. 8 Go ne suffisent évidemment pas? Voyons voir.
Programme Vedit
Vous devrez utiliser un programme vedit tiers.
Ce programme vous permet de lire un fichier xml de 2,9 Go et de travailler avec lui.
Il vous permet également de le diviser. Mais il y a un petit truc.
Comme vous pouvez le voir lors de la lecture d'un fichier, celui-ci a, entre autres, une balise AddressObjects d'ouverture:

Ainsi, en créant des parties de ce gros fichier, vous ne devez pas oublier de le fermer (tag).
Autrement dit, le début de chaque fichier xml sera comme ceci:
<?xml version="1.0" encoding="utf-8"?><AddressObjects>
et se terminant:
</AddressObjects>
Coupez maintenant la première partie du fichier (pour les autres parties, les étapes sont les mêmes).
Dans le programme vedit:
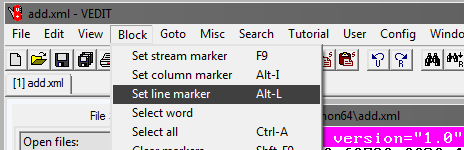
Ensuite, sélectionnez Goto et Line #. Dans la fenêtre qui s'ouvre, écrivez le numéro de ligne, par exemple 1 000 000:

Ensuite, vous devez ajuster le bloc sélectionné afin qu'il capture à la fin l'objet dans la base de données avant la balise de fermeture:
Ce n'est pas grave s'il y a un léger chevauchement sur l'objet suivant.
Ensuite, dans le programme vedit, enregistrez le fragment sélectionné - Fichier, Enregistrer sous.
De la même manière, nous créons les parties restantes du fichier, marquant le début du bloc de sélection et la fin par incréments de 1 million de lignes.
Par conséquent, vous devriez obtenir le 4e fichier xml d'une taille d'environ 610 Mo.
Nous finalisons les parties xml
Vous devez maintenant ajouter des balises dans les fichiers xml nouvellement créés afin qu'ils se lisent au format xml.
Ouvrez les fichiers dans vedit un par un et ajoutez au début de chaque fichier:
<?xml version="1.0" encoding="utf-8"?><AddressObjects>
et à la fin:
</AddressObjects>
Ainsi, nous avons maintenant 4 parties xml du fichier source divisé.
Xml-à-csv
Maintenant, traduisez xml en csv en écrivant un programme python.
Code de programme
.
En utilisant le programme, vous devez convertir les 4 fichiers en csv.
La taille du fichier diminuera, chacune sera de 236 Mo (contre 610 Mo en xml).
En principe, vous pouvez désormais déjà travailler avec eux, via excel ou notepad ++.
Cependant, les fichiers sont toujours 4e au lieu d'un, et nous n'avons pas atteint l'objectif - traiter le fichier dans les pandas.
Coller des fichiers en un
Sous Windows, cela peut s'avérer être une tâche difficile, nous allons donc utiliser l'utilitaire de console en python appelé csvkit. Installé en tant que module python:
pip install csvkit
* En fait, il s'agit d'un ensemble complet d'utilitaires, mais un sera nécessaire à partir de là.
Après avoir entré le dossier avec les fichiers à coller dans la console, nous effectuerons le collage en un seul fichier. Étant donné que tous les fichiers sont sans en-têtes, nous attribuerons les noms de colonnes standard lors du collage: a, b, c, etc.:
csvstack -H fias-0-10.csv fias-10-20.csv fias-20-30.csv fias-30-40.csv > joined2.csv
La sortie est un fichier csv terminé.
Travaillons dans les pandas pour optimiser l'utilisation de la mémoire
Si vous téléchargez immédiatement le fichier sur pandas
import pandas as pd import numpy as np gl = pd.read_csv('joined2.csv',encoding='ANSI',index_col='a') print (gl.info(memory_usage='deep'))
et vérifiez combien de mémoire cela prendra, le résultat peut désagréablement surprendre:

3 Go! Et cela malgré le fait que lors de la lecture des données, la première colonne «est passée» en tant que colonne d'index *, et donc le volume serait encore plus important.
* Par défaut, pandas définit son propre index de colonne.
Nous effectuerons l'optimisation en utilisant les méthodes du
post et de l'
article précédents:
- objet dans la catégorie;
- int64 dans uint8;
- float64 dans float32.
Pour ce faire, lors de la lecture du fichier, ajoutez des dtypes et la lecture des colonnes dans le code ressemblera à ceci:
gl = pd.read_csv('joined2.csv',encoding='ANSI',index_col='a', dtype ={ 'b':'category', 'c':'category','d':'category','e':'category', 'f':'category','g':'category', 'h':'uint8','i':'uint8','j':'uint8', 'k':'uint8','l':'uint8','m':'uint8','n':'uint16', 'o':'uint8','p':'uint8','q':'uint8','t':'uint8', 'u':'uint8','v':'uint8','w':'uint8','x':'uint8', 'r':'float32','s':'float32', 'y':'float32','z':'float32','aa':'float32','bb':'float32', 'cc':'float32' })
Maintenant, en ouvrant le fichier pandas, l'utilisation de la mémoire serait judicieuse:

Il reste à ajouter au fichier csv, si vous le souhaitez, les noms des colonnes réelles pour que les données aient un sens:
AOID,AOGUID,PARENTGUID,PREVID,FORMALNAME,OFFNAME,SHORTNAME,AOLEVEL,REGIONCODE,AREACODE,AUTOCODE,CITYCODE,CTARCODE,PLACECODE,STREETCODE,EXTRCODE,SEXTCODE,PLAINCODE,CODE,CURRSTATUS,ACTSTATUS,LIVESTATUS,CENTSTATUS,OPERSTATUS,IFNSFL,IFNSUL,OKATO,OKTMO,POSTALCODE
* Vous pouvez remplacer les noms de colonne par cette ligne, mais vous devez ensuite changer le code.
Enregistrez les premières lignes du fichier des pandas
gl.head().to_csv('out.csv', encoding='ANSI',index_label='a')
et voyez ce qui s'est passé dans Excel:

Code de programme pour une ouverture optimisée d'un fichier csv avec une base de données:
code import os import time import pandas as pd import numpy as np # : object-category, float64-float32, int64-int gl = pd.read_csv('joined2.csv',encoding='ANSI',index_col='a', dtype ={ 'b':'category', 'c':'category','d':'category','e':'category', 'f':'category','g':'category', 'h':'uint8','i':'uint8','j':'uint8', 'k':'uint8','l':'uint8','m':'uint8','n':'uint16', 'o':'uint8','p':'uint8','q':'uint8','t':'uint8', 'u':'uint8','v':'uint8','w':'uint8','x':'uint8', 'r':'float32','s':'float32', 'y':'float32','z':'float32','aa':'float32','bb':'float32', 'cc':'float32' }) pd.set_option('display.notebook_repr_html', False) pd.set_option('display.max_columns', 8) pd.set_option('display.max_rows', 10) pd.set_option('display.width', 80) #print (gl.head()) print (gl.info(memory_usage='deep')) # def mem_usage(pandas_obj): if isinstance(pandas_obj,pd.DataFrame): usage_b = pandas_obj.memory_usage(deep=True).sum() else: # , , usage_b = pandas_obj.memory_usage(deep=True) usage_mb = usage_b / 1024 ** 2 # return "{:03.2f} " .format(usage_mb)
En conclusion, voyons la taille de l'ensemble de données:
gl.shape
(3348644, 28)
3,3 millions de lignes, 28 colonnes.
Conclusion: avec la taille initiale du fichier csv de 890 Mo, «optimisé» pour travailler avec des pandas, il occupe 1,2 Go de mémoire.
Ainsi, avec un calcul approximatif, on peut supposer qu'un fichier de 7,69 Go peut être ouvert dans les pandas, après l'avoir "optimisé".