Qu'est-ce que la reconnaissance vocale End2End et pourquoi est-elle nécessaire? Quelle est sa différence avec l'approche classique? Et pourquoi, pour former un bon modèle basé sur End2End, nous avons besoin d'une énorme quantité de données - dans notre article d'aujourd'hui.
L'approche classique de la reconnaissance vocale
Avant de parler de l'approche End2End, vous devez d'abord parler de l'approche classique de la reconnaissance vocale. Comment est-il?

Extraction de fonctionnalités
En fait, ce n'est pas une séquence complètement linéaire de blocs d'action. Arrêtons-nous sur chaque bloc plus en détail. Nous avons une sorte de discours d'entrée, il tombe sur le premier bloc - Extraction de fonctionnalités. Il s'agit d'un bloc qui tire les signes de la parole. Il ne faut pas oublier que la parole elle-même est une chose assez compliquée. Vous devez pouvoir l'utiliser d'une manière ou d'une autre, il existe donc des méthodes standard pour isoler les entités de la théorie du traitement du signal. Par exemple, les coefficients Mel-cepstral (MFCC) et ainsi de suite.
Modèle acoustique
Le composant suivant est le modèle acoustique. Il peut être basé sur des réseaux de neurones profonds, ou sur la base de mélanges de distributions gaussiennes et de modèles de Markov cachés. Son objectif principal est d'obtenir à partir d'une section du signal acoustique les distributions de probabilité des différents phonèmes de cette section.
Vient ensuite le décodeur, qui recherche le chemin le plus probable dans le graphique en fonction du résultat de la dernière étape. La recotation est la touche finale de reconnaissance, dont la tâche principale est de repeser les hypothèses et de produire le résultat final.
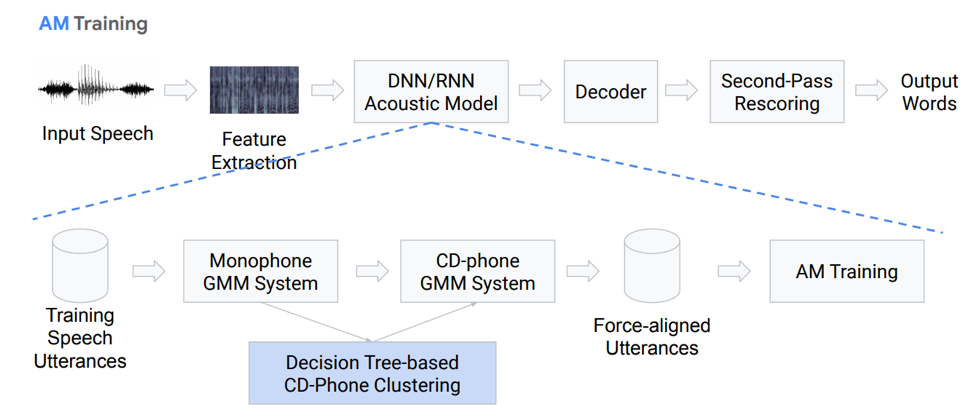
Arrêtons-nous plus en détail sur le modèle acoustique. Comment est-elle? Nous avons des enregistrements vocaux qui entrent dans un certain système basé sur GMM (mélange monausal gausovy) ou HMM. Autrement dit, nous avons des représentations sous forme de phonèmes, nous utilisons des monophones, c'est-à-dire des phonèmes indépendants du contexte. Plus loin, nous faisons des mélanges de distributions gaussiennes basées sur des phonèmes contextuels. Il utilise le clustering basé sur des arbres de décision.
Ensuite, nous essayons de construire l'alignement. Une telle méthode tout à fait non triviale nous permet d'obtenir un modèle acoustique. Cela ne semble pas très simple, en fait c'est encore plus compliqué, il y a beaucoup de nuances, de fonctionnalités. Mais en conséquence, un modèle formé sur des centaines d'heures est très bien capable de simuler l'acoustique.

Décodeur
Qu'est-ce qu'un décodeur? C'est le module qui sélectionne le chemin de transition le plus probable selon le graphique HCLG, qui se compose de 4 parties:
Module H basé sur HMM
Module de dépendance du contexte C
Module de prononciation L
Module de modèle de langage G
Nous construisons un graphe sur ces quatre composantes, à partir duquel nous décoderons nos caractéristiques acoustiques en certaines constructions verbales.
Plus ou moins, il est clair que l'approche classique est plutôt lourde et difficile, elle est difficile à former, car elle se compose d'un grand nombre de parties distinctes, pour chacune desquelles vous devez préparer vos propres données pour la formation.
II Approche End2End
Qu'est-ce que la reconnaissance vocale End2End et pourquoi est-elle nécessaire? Il s'agit d'un certain système, qui est conçu pour refléter directement la séquence de signes acoustiques dans la séquence de graphèmes (lettres) ou de mots. Vous pouvez également dire qu'il s'agit d'un système qui optimise les critères qui affectent directement la métrique finale de l'évaluation de la qualité. Par exemple, notre tâche est spécifiquement le taux d'erreur sur les mots. Comme je l'ai dit, il n'y a qu'une seule motivation - présenter ces composants complexes à plusieurs étapes comme un composant simple qui affichera directement, produira des mots ou des graphèmes à partir de la parole d'entrée.
Problème de simulation
Ici, nous avons tout de suite un problème: la parole sonore est une séquence, et à la sortie, nous devons également donner une séquence. Et jusqu'en 2006, il n'y avait aucun moyen adéquat de modéliser cela. Quel est le problème de la modélisation? Il fallait que chaque enregistrement crée un balisage complexe, ce qui implique à quelle seconde nous prononçons un son ou une lettre en particulier. Il s'agit d'une configuration complexe très lourde et, par conséquent, un grand nombre d'études sur ce sujet n'ont pas été menées. En 2006, un article intéressant d'Alex Graves «Classification temporelle connexionniste» (CTC) a été publié, dans lequel ce problème est, en principe, résolu. Mais l'article a été publié et il n'y avait pas assez de puissance de calcul à l'époque. Et de vrais algorithmes de reconnaissance vocale fonctionnels sont apparus beaucoup plus tard.
Au total, nous avons: l'algorithme CTC a été proposé par Alex Graves il y a treize ans, comme un outil qui vous permet de former / former des modèles acoustiques sans avoir besoin de ce balisage complexe - alignement des trames de séquence d'entrée et de sortie. Sur la base de cet algorithme, un travail est apparu initialement qui n'était pas terminé end2end; des phonèmes ont donc été émis. Il convient de noter que les phonèmes contextuels basés sur STS obtiennent l'un des meilleurs résultats dans la reconnaissance de la liberté d'expression. Mais il convient également de noter que cet algorithme, appliqué directement aux mots, reste quelque part en retard pour le moment.

Qu'est-ce que STS
Maintenant, nous allons parler un peu plus en détail de ce qu'est le STS, et pourquoi il est nécessaire, quelle fonction il remplit. STS est nécessaire pour former le modèle acoustique sans avoir besoin d'un alignement image par image entre le son et la transcription. L'alignement image par image, c'est quand on dit qu'une image particulière d'un son correspond à une telle image de la transcription. Nous avons un encodeur conventionnel qui accepte les signes acoustiques en entrée - il donne une sorte de dissimulation de l'état, sur la base de laquelle nous obtenons des probabilités conditionnelles en utilisant softmax. Le codeur se compose généralement de plusieurs couches de LSTM ou d'autres variantes de RNN. Il convient de noter que STS fonctionne en plus des caractères ordinaires avec un caractère spécial appelé caractère vide ou symbole vide. Afin de résoudre le problème qui se pose du fait que toutes les trames acoustiques n'ont pas de trame en transcription et vice versa (c'est-à-dire que nous avons des lettres ou des sons qui sonnent beaucoup plus longtemps et qu'il y a des sons courts, des sons répétitifs), et là ce symbole vierge.
Le STS lui-même est destiné à maximiser la probabilité finale de séquences de caractères et à généraliser l'alignement possible. Puisque nous voulons utiliser cet algorithme dans les réseaux de neurones, il est entendu que nous devons comprendre comment fonctionnent ses modes de fonctionnement avant et arrière. Nous ne nous attarderons pas sur la justification mathématique et les caractéristiques du fonctionnement de cet algorithme, sinon cela prendra très longtemps.
Qu'avons-nous: le premier ASR basé sur l'algorithme STS apparaît en 2014. Encore une fois, Alex Graves a présenté une publication basée sur le STS caractère par caractère qui affiche directement le discours d'entrée dans une séquence de mots. L'un des commentaires qu'ils ont fait dans cet article est qu'il est important d'utiliser un modèle de son externe pour obtenir un bon résultat.
5 façons d'améliorer l'algorithme
Il existe de nombreuses variantes et améliorations de l'algorithme ci-dessus. Voici, par exemple, les cinq plus populaires récemment.
• Le modèle de langage est inclus dans le décodage lors de la première passe
o [Hannun et al., 2014] [Maas et al., 2015]: décodage direct de premier passage avec un LM par opposition à un nouveau scoring comme dans [Graves & Jaitly, 2014]
o [Miao et al., 2015]: cadre EESEN pour le décodage avec WFST, boîte à outils open source
• Formation à grande échelle sur le GPU; Augmentation des données plusieurs langues
o [Hannun et al., 2014; DeepSpeech] [Amodei et al., 2015; DeepSpeech2]: formation GPU à grande échelle; Augmentation des données; Mandarin et anglais
• Utilisation d'unités longues: des mots au lieu de caractères
o [Soltau et al., 2017]: cibles CTC de niveau Word, formées sur 125 000 heures de discours. Des performances proches ou supérieures à un système conventionnel, même sans utiliser de LM!
o [Audhkhasi et al., 2017]: Modèles Direct Acoustics-to-Word sur Switchboard
Il convient de prêter attention à la mise en œuvre de DeepSpeach comme un bon exemple de solution CTC end2end et à une variation qui utilise un niveau verbal. Mais il y a une mise en garde: pour former un tel modèle, vous avez besoin de 125 000 heures de données étiquetées, ce qui est en fait beaucoup dans les dures réalités.
Ce qui est important à noter sur STS
- Problèmes ou omissions. Pour l'efficacité, il est important de faire des hypothèses sur l'indépendance. C'est-à-dire que le STS suppose que la sortie du réseau dans différentes trames est conditionnellement indépendante, ce qui est en fait incorrect. Mais cette hypothèse est faite pour simplifier, sans elle, tout devient beaucoup plus compliqué.
- Pour obtenir de bonnes performances à partir du modèle STS, l'utilisation d'un modèle de langage externe est requise, car le décodage gourmand direct ne fonctionne pas très bien.
Attention
Quelle alternative avons-nous pour ce STS? Ce n'est probablement un secret pour personne qu'il existe une chose telle que l'Attention ou «Attention», qui a révolutionné dans une certaine mesure et qui est directement passé des tâches de traduction automatique. Et maintenant, la plupart des décisions de modélisation séquence-séquence sont basées sur ce mécanisme. Comment est-il? Essayons de le comprendre. Pour la première fois sur l'attention dans les tâches de reconnaissance vocale, des publications sont parues en 2015. Quelqu'un Chen et Cherowski ont publié deux publications similaires et dissemblables en même temps.
Arrêtons-nous sur le premier - il s'appelle écouter, assister et épeler. Dans notre simulation classique, dans la séquence où nous avons un encodeur et un décodeur, un autre élément est ajouté, qui est appelé attention. L'echnoder remplira les fonctions que le modèle acoustique utilisait auparavant. Sa tâche est de transformer le discours d'entrée en fonctionnalités acoustiques de haut niveau. Notre décodeur effectuera les tâches que nous avons précédemment effectuées le modèle de langue et le modèle de prononciation (lexique), il prédira de manière autorégressive chaque jeton de sortie, en fonction des précédents. Et l'attention elle-même dira directement quelle trame d'entrée est la plus pertinente / importante pour prédire cette sortie.
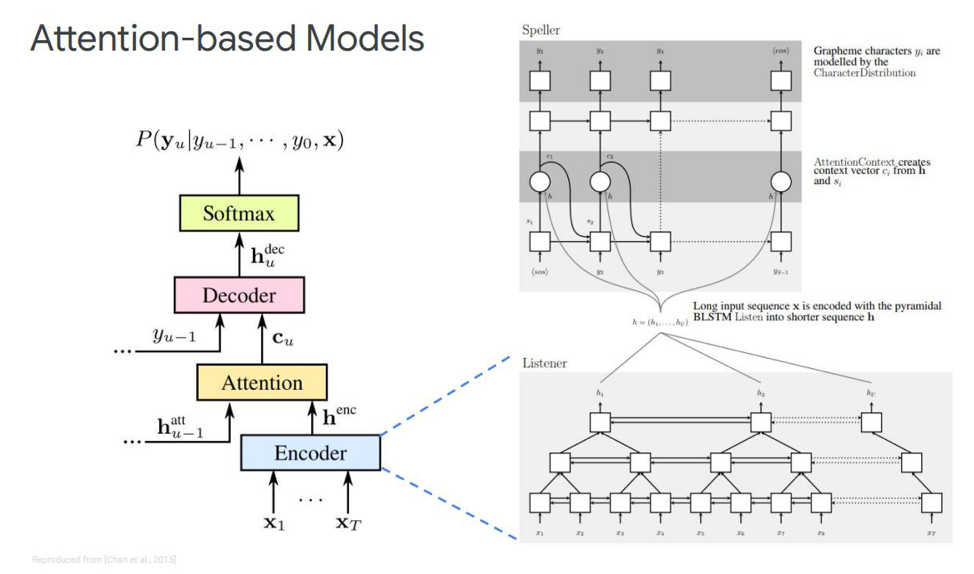
Quels sont ces blocs? L'éco-encodeur dans l'article est décrit comme un auditeur, c'est un RNN bidirectionnel classique basé sur des LSTM ou autre chose. En général, rien de nouveau - le système simule simplement la séquence d'entrée en fonctionnalités complexes.
L'attention, d'autre part, crée un certain vecteur de contexte C à partir de ces vecteurs, ce qui aidera à décoder correctement le décodeur directement, le décodeur lui-même, qui est, par exemple, également certains LSTM qui seront décodés dans la séquence d'entrée de cette couche d'attention, qui a déjà mis en évidence les signes d'état les plus importants, une séquence de sortie de caractères.
Il existe également différentes représentations de cette Attention elle-même - ce qui fait la différence entre ces deux publications publiées par Chen et Charowski. Ils utilisent une attention différente. Chen utilise Attention produit par points, et Charowski utilise Attention Additive.

Où aller ensuite?
Il s'agit d'un avantage ou d'un inconvénient pour toutes les principales réalisations obtenues à ce jour en matière de reconnaissance vocale non en ligne. Quelles améliorations sont possibles ici? Où aller ensuite? Le plus évident est l'utilisation d'un modèle sur des morceaux de mots au lieu d'utiliser directement des graphèmes. Il peut s'agir de morphèmes distincts ou d'autre chose.
Quelle est la motivation pour utiliser des tranches de mots? Typiquement, les modèles linguistiques du niveau verbal ont beaucoup moins de perplexité que le niveau du graphème. La modélisation de morceaux de mots vous permet de construire un décodeur plus fort du modèle de langage. Et la modélisation d'éléments plus longs peut améliorer l'efficacité de la mémoire dans un décodeur basé sur des LSTM. Il vous permet également de vous souvenir potentiellement de l'occurrence des mots de fréquence. Des éléments plus longs permettent un décodage en moins d'étapes, ce qui accélère directement l'inférence de ce modèle.
En outre, un modèle sur des morceaux de mots nous permet de résoudre le problème des mots OOV (hors vocabulaire) qui se posent dans un modèle de langage, car nous pouvons modéliser n'importe quel mot avec des morceaux de mots. Et il convient de noter que ces modèles sont formés pour maximiser la probabilité d'un modèle de langage sur un ensemble de données de formation. Ces modèles dépendent de la position et nous pouvons utiliser l'algorithme gourmand pour le décodage.
Quelles autres améliorations que le modèle de morceaux de mots peuvent être? Il existe un mécanisme appelé attention multi-têtes. Il a été décrit pour la première fois en 2017 pour la traduction automatique. L'attention multi-têtes implique un mécanisme qui a plusieurs soi-disant têtes qui vous permettent de générer une distribution différente de cette même attention, ce qui améliore directement les résultats.
Modèles en ligne
Nous passons à la partie la plus intéressante - ce sont des modèles en ligne. Il est important de noter que LAS ne diffuse pas. Autrement dit, ce modèle ne peut pas fonctionner en mode de décodage en ligne. Nous considérerons les deux modèles en ligne les plus populaires à ce jour. Transducteur RNN et transducteur neuronal.
Le transducteur RNN a été proposé par Graves en 2012-2017. L'idée principale est de compliquer un peu notre modèle STS à l'aide d'un modèle récursif.
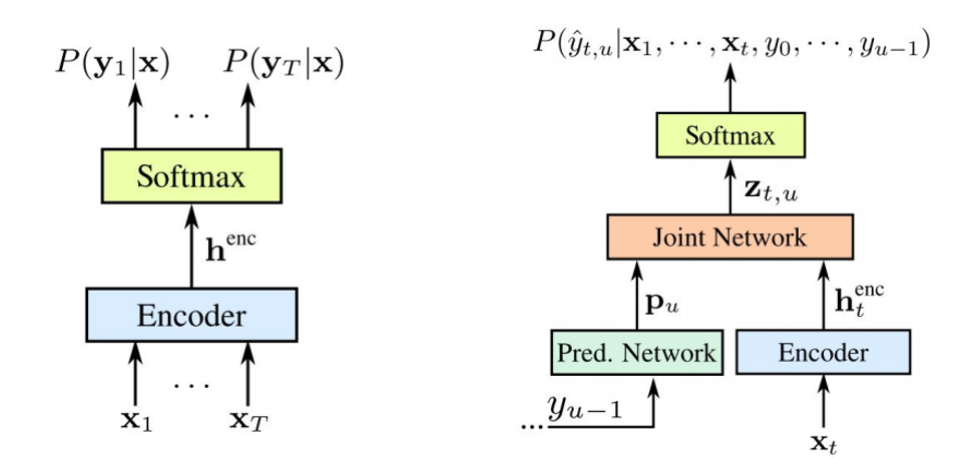
Il convient de noter que les deux composants sont entraînés ensemble sur les données acoustiques disponibles. Comme STS, cette approche ne nécessite pas d'alignement de trame dans l'ensemble de données d'apprentissage. Comme nous le voyons sur l'image: à gauche est notre STS classique, et à droite est le transducteur RNN. Et nous avons deux nouveaux éléments: le
réseau prédit et le
réseau Join .
L'encodeur STS est exactement le même - c'est le niveau d'entrée RNN, qui détermine la distribution sur tous les alignements avec toutes les séquences de sortie ne dépassant pas la longueur de la séquence d'entrée - cela a été décrit par Graves en 2006. Cependant, la tâche de telles conversions texte-parole est également exclue, où la séquence d'entrée plus longue que la séquence d'entrée du STS ne modélise pas la relation entre les sorties. Le transducteur étend ce STS très, en déterminant la distribution des séquences de sortie de toutes longueurs et en modélisant conjointement la dépendance de l'entrée-sortie et de la sortie-sortie.
Il s'avère que notre modèle est finalement capable de gérer les dépendances de la sortie de l'entrée et de la sortie de la sortie de la dernière étape.
Alors, qu'est-ce qu'un
réseau prédit ou un réseau prédictif? Elle essaie de modéliser chaque élément en tenant compte des précédents, par conséquent, il est similaire au RNN standard avec la prévision de l'étape suivante. Seulement avec la possibilité supplémentaire de faire des hypothèses nulles.
Comme nous le voyons dans l'image, nous avons un réseau prédit, qui reçoit la valeur précédente de la sortie, et il y a un encodeur, qui reçoit la valeur actuelle de l'entrée. Et à la sortie, nous avons à nouveau, telle a la valeur actuelle
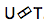
.
Transducteur neuronal . Il s'agit d'une complication de l'approche classique seq-2seq. La séquence acoustique d'entrée est traitée par le codeur pour créer des vecteurs d'état cachés à chaque pas de temps. Tout semble être comme d'habitude. Mais il y a un élément Transducteur supplémentaire qui reçoit un bloc d'entrées à chaque étape et génère jusqu'à M jetons de sortie en utilisant un modèle basé sur seq-2seq au-dessus de cette entrée. Le transducteur conserve son état dans des blocs en utilisant des connexions périodiques avec les pas de temps précédents.
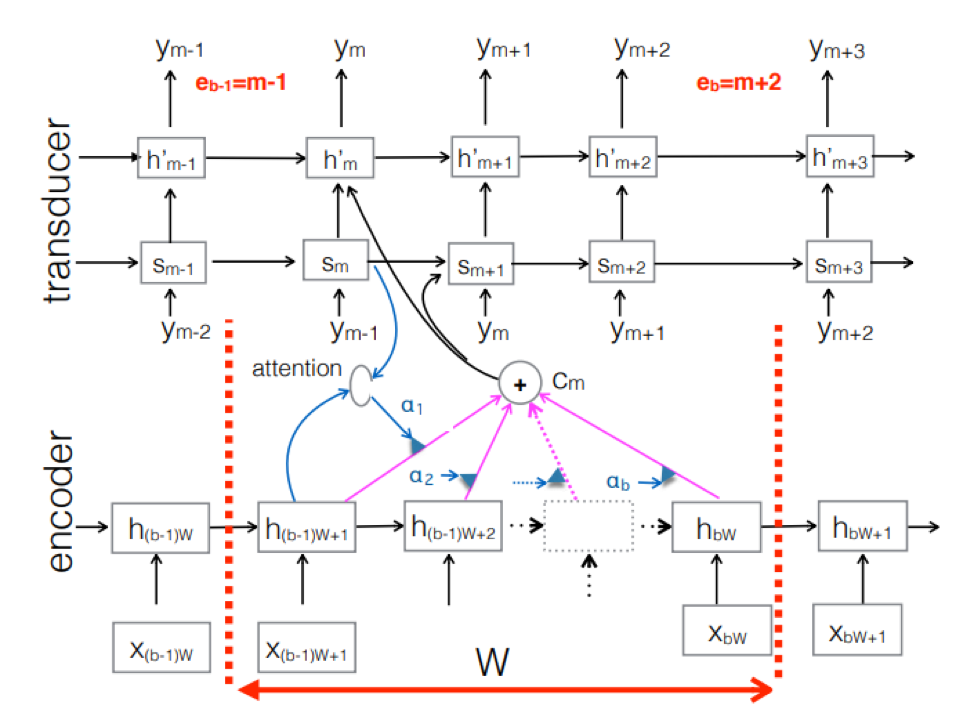 La figure montre le transducteur, produisant des jetons pour le bloc pour la séquence utilisée dans le bloc du Ym correspondant.
La figure montre le transducteur, produisant des jetons pour le bloc pour la séquence utilisée dans le bloc du Ym correspondant.Nous avons donc examiné l'état actuel de la reconnaissance vocale sur la base de l'approche End2End. Il convient de dire que, malheureusement, ces approches nécessitent aujourd'hui une grande quantité de données. Et les vrais résultats obtenus par l'approche classique, nécessitant de 200 à 500 heures d'enregistrements sonores balisés pour la formation d'un bon modèle basé sur End2End, nécessiteront plusieurs, voire des dizaines de fois plus de données. Maintenant, c'est le plus gros problème avec ces approches. Mais peut-être que bientôt tout changera.
Développeur principal du centre AI MTS Nikita Semenov.