
Bonjour à tous! Récemment, un webinaire ouvert
"Fournir un stockage tolérant aux pannes" a été organisé . Il a examiné les problèmes qui se posent dans la conception des architectures, pourquoi une panne de serveur n'est pas une excuse pour un crash de serveur et comment réduire au minimum les temps d'arrêt. Le webinaire a été organisé par
Ivan Remen , responsable du développement des serveurs chez Citimobil et enseignant du cours
«High Load
Architect» .
Pourquoi s'embêter avec la résilience du stockage?
La réflexion sur la résilience du stockage évolutif et la compréhension des problèmes de mise en cache de base devraient être
au stade du démarrage . Il est clair que lorsque vous écrivez une startup, vous faites au tout début la version minimale du produit. Mais plus vous vous développez, plus vite vous atteignez la productivité, ce qui peut conduire à un arrêt complet de l'entreprise. Et si vous obtenez de l'argent des investisseurs, alors, bien sûr, ils auront également besoin d'une croissance constante et de nouvelles fonctionnalités commerciales. Pour trouver le bon équilibre, vous devez choisir entre vitesse et qualité. En même temps, vous ne pouvez sacrifier ni l'un ni l'autre, et si vous sacrifiez - alors consciemment et dans certaines limites. Cependant, il n'y a pas de recettes universelles ici, ainsi que des solutions idéales.
On se repose contre la base pour lire
Ceci est le premier scénario. Imaginez que nous ayons 1 serveur, dont la charge sur le processeur ou le disque dur est de 99%. Dans ce cas:
- 90% des demandes sont lues;
- 10% des demandes sont un record.
La meilleure solution dans cette situation est de penser aux répliques. Pourquoi? C'est la solution la moins chère et la plus simple.
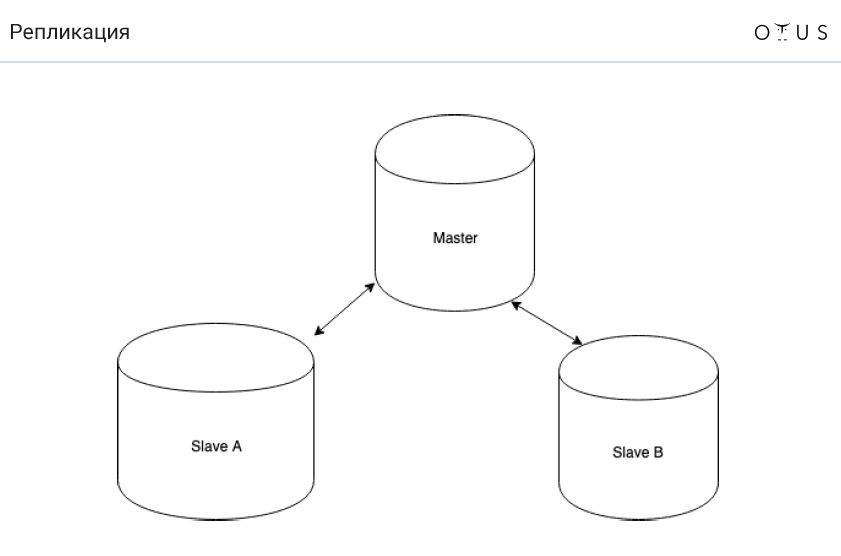
La réplication est classée:
1. Par synchronisation:
- synchrone;
- asynchrone;
- semi-synchrone.
2. Selon les données portables:
- logique (basée sur les lignes, basée sur les instructions, mixte);
- physique.
3. Par le nombre de nœuds par enregistrement:
- maître / esclave;
- maître / maître.
4. Par initiateur:
Et maintenant, la
tâche concerne un seau d'eau . Imaginez que nous ayons MySQL et la réplication maître-esclave asynchrone. Le nettoyage est en cours dans le DC, à la suite de quoi le nettoyeur trébuche et verse un seau d'eau sur le serveur avec la base principale. L'automatisation fait passer avec succès l'un des derniers esclaves en mode maître. Et tout continue de fonctionner. Où est le hic?
La réponse est simple: nous perdons des transactions que nous n'avons pas réussi à reproduire. Par conséquent, la propriété D de l'ACID est violée.
Parlons maintenant du fonctionnement de la réplication asynchrone (MySQL):
- enregistrer une transaction dans le moteur de stockage (InnoDB);
- enregistrer une transaction dans un journal binaire;
- achèvement de la transaction dans le moteur de stockage;
- confirmation de retour au client;
- transférer une partie du journal vers la réplique;
- exécution d'une transaction sur une réplique (p. 1-3).
Et maintenant, la question est de savoir ce qui doit être changé dans les paragraphes ci-dessus pour que nous ne nous retrouvions jamais avec la réplication?
Et seuls deux points doivent être échangés: 4ème et 5ème ("transfert d'une partie du journal vers la réplique" et "retour de confirmation au client"). Ainsi, si le nœud maître s'envole, nous aurons toujours un journal des transactions quelque part (point 2). Et si la transaction est enregistrée dans le journal binaire, la transaction se produira également à un moment donné.
En conséquence, nous obtenons une réplication semi-synchrone (MySQL), qui fonctionne comme suit:
- enregistrer une transaction dans le moteur de stockage (InnoDB);
- enregistrer une transaction dans un journal binaire;
- achèvement de la transaction dans le moteur de stockage;
- transférer une partie du journal vers la réplique;
- confirmation de retour au client;
- exécution d'une transaction sur une réplique (p. 1-3).
Sync vs semi-sync et async vs semi-sync
Pour une raison quelconque, en Russie, la plupart des gens n'ont pas entendu parler de la réplication semi-synchrone. Soit dit en passant, il est bien implémenté dans PostgreSQL et pas très dans MySQL. En savoir plus à ce sujet
ici , mais la thèse peut être formulée comme suit:
- la réplication semi-synchrone est toujours en retard (mais pas autant) qu'asynchrone;
- nous ne perdons pas de transactions;
- il suffit d'amener les données à un seul esclave.
Soit dit en passant, la réplication semi-synchrone est utilisée sur Facebook.
Nous reposons contre la base record
Parlons d'un problème diamétralement opposé quand nous avons:
- 90% des demandes - enregistrement;
- 10% des demandes sont lues;
- 1 serveur;
- charge - 99% (processeur ou disque dur).
Le sharding bien connu vient à la rescousse ici. Mais maintenant, parlons d'autre chose:

Très souvent, dans de tels cas, ils commencent à utiliser master-master. Cependant,
cela n'aide pas dans cette situation . Pourquoi? C'est simple: l'enregistrement sur le serveur ne diminue pas. Après tout, la réplication implique qu'il existe des données sur tous les nœuds. Avec la réplication basée sur les instructions, en effet, SQL s'exécutera sur TOUS les nœuds. Basé sur la ligne C est un peu plus facile, mais toujours cher. Et aussi master-master a des problèmes avec les conflits.
En fait, il est logique d'utiliser master-master dans les situations suivantes:
- tolérance aux pannes en écriture (l'idée est que vous n'écrivez toujours que sur un seul maître). Vous pouvez implémenter en utilisant l'adresse IP virtuelle ;
- systèmes géo-distribués.
Cependant, n'oubliez pas que la réplication maître-maître est toujours difficile. Et souvent, master-master apporte plus de problèmes qu'il n'en résout.
Partage
Nous avons déjà mentionné le sharding. En bref, le sharding est un moyen infaillible de mettre un record à l'échelle. L'idée est que nous distribuons des données sur des serveurs indépendants (mais pas toujours). Chaque fragment peut se répliquer indépendamment.
La première règle de partage est que les données utilisées ensemble doivent être dans le même fragment. La
sharding_key -> shard_id fonctionne
sharding_key -> shard_id . Par conséquent,
sharding_key pour les données utilisées ensemble doit correspondre. La première difficulté est que si vous choisissez la mauvaise
sharding_key , il vous sera très difficile de tout réorganiser. Deuxièmement, si vous avez une sorte de
sharding_key , certaines requêtes seront très difficiles à exécuter. Par exemple, vous ne pouvez pas trouver la valeur moyenne.
Pour le démontrer, imaginons que nous avons deux fragments avec chacun trois valeurs: (1; 2; 3) (0; 0; 500). La valeur moyenne sera égale à (1 + 2 + 3 + 500) / 6 = 84,33333.
Imaginez maintenant que nous avons deux serveurs indépendants. Et recalculez la valeur moyenne séparément pour chaque fragment. Sur le premier d'entre eux, nous obtenons 2, sur le second - 166.66667. Et même si nous faisons ensuite la moyenne de ces valeurs, nous obtiendrons toujours un nombre qui sera différent du bon: (2 + 166,66667) / 2 = 86,33334.
Autrement dit, la
moyenne des moyens n'est pas égale à la moyenne de tout: avg(a, b, c, d) != avg(avg(a, b) + (avg(c, d))
Des calculs simples, mais il est important de se rappeler.
Tâche de partage
Supposons que nous ayons un système de dialogue dans un réseau social. Il ne peut y avoir que 2 personnes dans un dialogue. Tous les messages sont dans une table, dans laquelle il y a:
- ID du message
- ID de l'expéditeur
- ID du destinataire
- texte du message;
- date d'envoi du message;
- quelques drapeaux.
Quelle clé de partitionnement doit être choisie en fonction du fait que nous avons la première règle de partitionnement décrite ci-dessus?
Il existe plusieurs options pour résoudre ce problème classique:
- crc32 (id_src // id_dst);
- crc32 (1 // 2)! = crc32 (2 // 1);
- crc32 (de + à)% n;
- crc32 (min (de, à). max (de, à))% n.
Caches
Et quelques mots sur les caches. Nous pouvons dire que les
caches sont un contre-modèle , bien que l'on puisse contester cette affirmation (beaucoup de gens aiment utiliser des caches). Mais dans l'ensemble, les caches ne sont nécessaires que pour augmenter le taux de réponse. Et ils ne peuvent pas être réglés pour supporter la charge.
La conclusion est simple - nous devons vivre tranquillement sans caches. La seule raison pour laquelle ils peuvent être nécessaires est exactement la même raison pour laquelle ils sont nécessaires dans le processeur: pour augmenter la vitesse de réponse. Si la base de données ne résiste pas à la charge à la suite de la disparition du cache, c'est mauvais. Il s'agit d'un modèle architectural extrêmement infructueux, donc cela ne devrait pas l'être. Et quelles que soient les ressources dont vous disposez, un jour votre cache tombera sûrement, quoi que vous fassiez.
Les problèmes de cache sont la thèse:- commencez par une cache froide;
- problème d'invalidation du cache;
- cohérence du cache.
Si vous utilisez toujours des caches, un hachage cohérent vous aidera. Il s'agit d'un moyen de créer des tables de hachage distribuées, dans lequel la défaillance d'un ou plusieurs serveurs de stockage n'entraîne pas la nécessité d'une relocalisation complète de toutes les clés et valeurs stockées. Cependant, vous pouvez en savoir plus à ce sujet
ici .

Eh bien, merci d'avoir regardé! Afin de ne rien manquer de la dernière conférence, il est préférable de
regarder l'intégralité du webinaire .