
Il s'agit d'une instruction étape par étape pour la classification des images multispectrales du satellite Landsat 5. Aujourd'hui, dans un certain nombre de domaines, l'apprentissage profond domine comme un outil pour résoudre des problèmes complexes, y compris géospatiaux. J'espère que vous connaissez les jeux de données satellitaires, en particulier Landsat 5 TM. Si vous êtes un peu familier avec les algorithmes d'apprentissage automatique, cela vous aidera à apprendre rapidement ce manuel. Et pour ceux qui ne comprennent pas, il suffira de savoir qu'en fait, le machine learning consiste à établir des relations entre plusieurs caractéristiques (un ensemble d'attributs X) d'un objet avec son autre propriété (valeur ou étiquette, la variable cible Y). Nous alimentons le modèle avec de nombreux objets pour lesquels les caractéristiques et la valeur de l'indicateur / classe cible de l'objet (données étiquetées) sont connues et le formons afin qu'il puisse prédire la valeur de la variable cible Y pour les nouvelles données (non marquées).
Quel est le principal problème de l'imagerie satellite?
Deux ou plusieurs classes d'objets (par exemple, bâtiments, terrains vacants et puits de fondation) dans les images satellite peuvent avoir les mêmes caractéristiques spectrales de la valeur, par conséquent, au cours des vingt dernières années, leur classification a été une tâche difficile.
Pour cette raison, il est possible d'utiliser des modèles classiques d'apprentissage automatique avec et sans professeur, mais leur qualité sera loin d'être idéale. Ils ont toujours les mêmes inconvénients. Prenons un exemple:

Si vous utilisez une ligne verticale comme classificateur et la déplacez le long de l'axe X, la classification des images de maisons ne sera pas facile. Les données sont réparties de sorte qu'il est impossible de les séparer en classes en utilisant une seule ligne verticale (dans de tels cas, il est dit que "les objets de classes différentes ne sont pas linéairement séparables"). Mais cela ne signifie pas que les maisons ne peuvent pas du tout être classées!
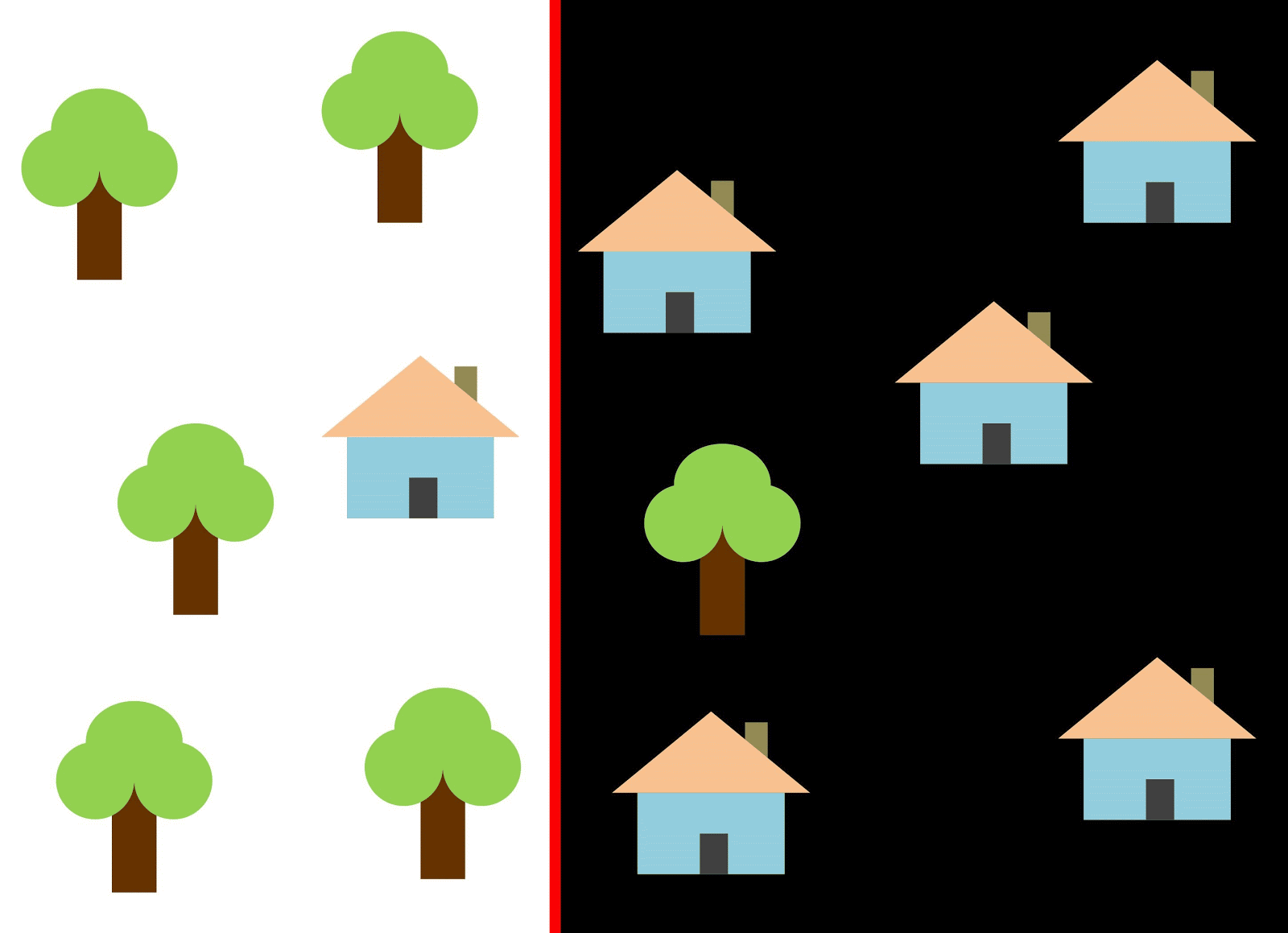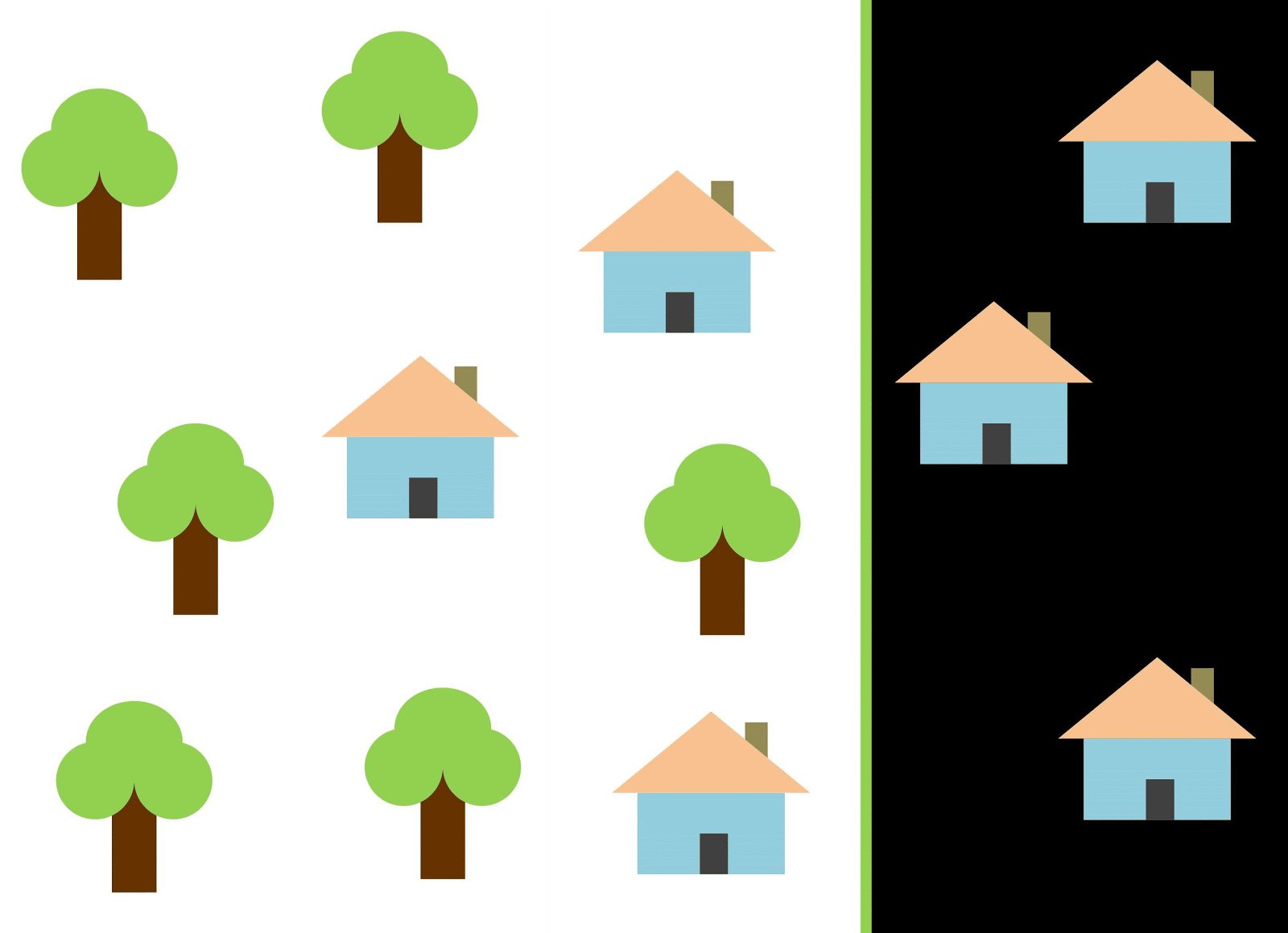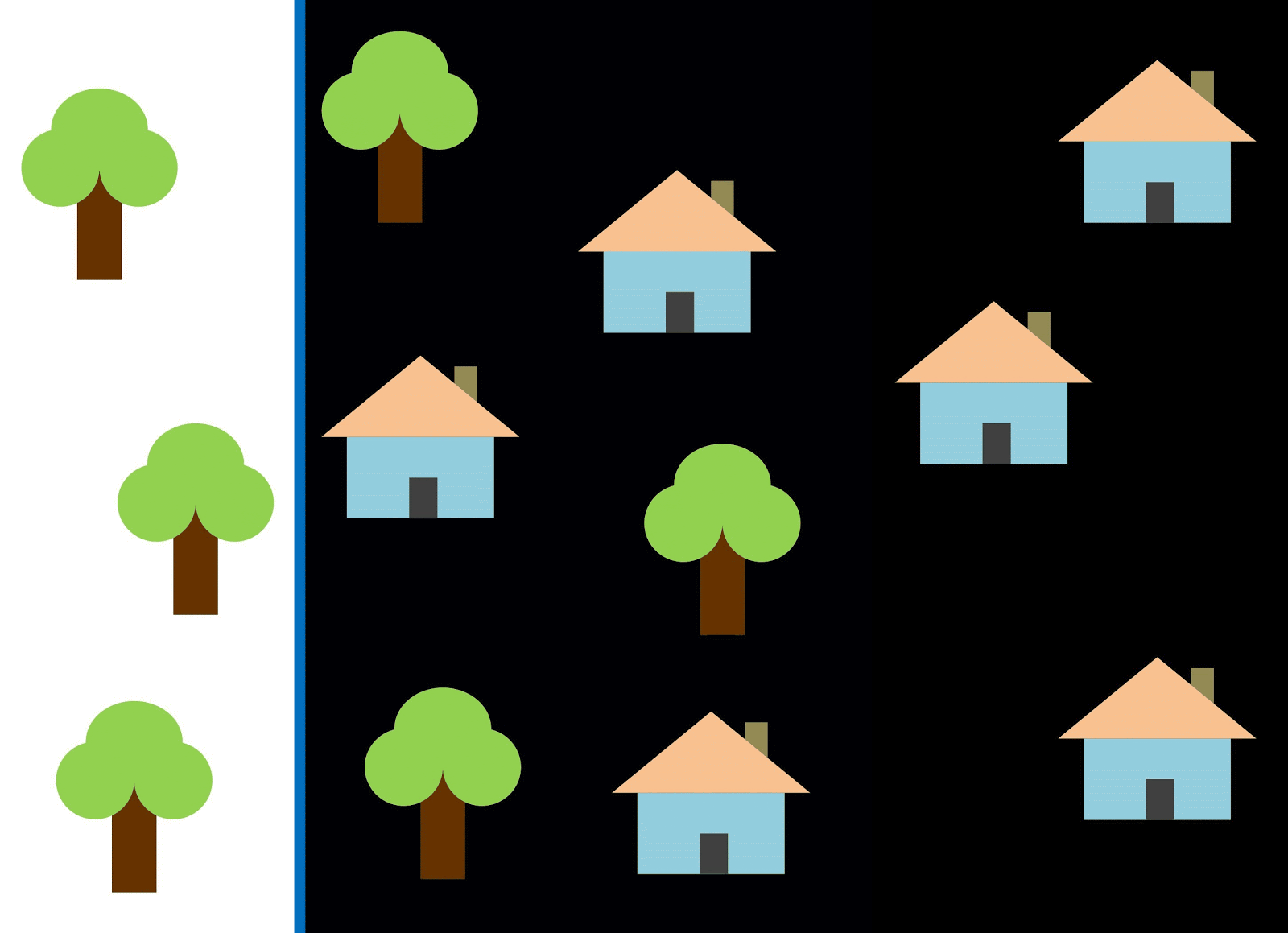
Utilisons la ligne rouge pour séparer les deux classes. Dans ce cas, le classificateur a identifié la plupart des maisons, mais une maison n'a pas été affectée à sa classe et trois autres arbres ont été attribués par erreur aux "maisons". Afin de ne manquer aucune maison, vous pouvez utiliser le classificateur sous la forme d'une ligne bleue. Ensuite, tout sera couvert à la maison, c'est-à-dire que nous disons que la métrique de rappel (plénitude) est élevée. Cependant, toutes les valeurs classifiées ne se sont pas avérées être des maisons, c'est-à-dire qu'en même temps, nous avons obtenu une faible valeur de la métrique de précision. Si nous utilisons la ligne verte, alors toutes les images classées comme maisons seront vraiment des maisons, c'est-à-dire que le classificateur affichera une grande précision. Dans ce cas, la plénitude sera moindre, car les trois maisons ne seront pas comptabilisées. Dans la plupart des cas, nous devons trouver un compromis entre précision et exhaustivité.
Ce problème des maisons et des arbres est similaire au problème des bâtiments, des terrains vagues et des fosses. La priorité des mesures de classification de l'imagerie satellite peut varier selon la tâche. Par exemple, si vous devez vous assurer que tous les territoires bâtis sont classés comme des bâtiments sans exception, et que vous êtes prêt à accepter la présence de pixels d'autres classes avec des signatures similaires, qui seront également classés comme des bâtiments, alors vous aurez besoin d'un modèle avec une grande exhaustivité. Et s'il est plus important pour vous de classer un bâtiment, sans ajouter de pixels d'autres classes, et que vous êtes prêt à abandonner la classification des territoires mixtes, choisissez alors un classifieur de grande précision. Dans le cas des maisons et des arbres, le modèle habituel utilisera la ligne rouge, en maintenant un équilibre entre précision et exhaustivité.
Données utilisées
Comme signes, nous utiliserons les valeurs de six plages (bande 2 - bande 7) de l'image de Landsat 5 TM, et essayer de prédire la classe de développement binaire. Pour la formation et les tests, des données multispectrales (images et couche avec une classe de construction binaire) avec Landsat 5 pour 2011 pour Bangalore seront utilisées. Et pour la prédiction seront utilisées les données multispectrales Landsat 5 obtenues en 2005 à Hyderabad.
Puisque nous utilisons des données balisées pour l'enseignement, cela s'appelle l'enseignement avec l'enseignant.
 Données d'entraînement multispectrales et couche binaire correspondante avec développement.
Données d'entraînement multispectrales et couche binaire correspondante avec développement.Pour créer un réseau de neurones, nous utiliserons Python - la bibliothèque Google Tensorflow. Nous aurons également besoin de ces bibliothèques:
- pyrsgis - pour lire et écrire GeoTIFF.
- scikit-learn - pour le prétraitement des données et l'évaluation de la précision.
- numpy - pour les opérations de base avec des tableaux.
Et maintenant, sans plus tarder, écrivons le code.
Placez les trois fichiers dans un répertoire, écrivez le chemin et les noms des fichiers d'entrée dans le script, puis lisez les fichiers GeoTIFF.
import os from pyrsgis import raster os.chdir("E:\\yourDirectoryName") mxBangalore = 'l5_Bangalore2011_raw.tif' builtupBangalore = 'l5_Bangalore2011_builtup.tif' mxHyderabad = 'l5_Hyderabad2011_raw.tif'
Le module
raster du package
pyrsgis lit les données de géolocalisation GeoTIFF et les valeurs numériques (DN) sous forme de tableaux NumPy séparés. Si vous êtes intéressé par les détails, lisez
ici .
Maintenant, nous affichons la taille des données lues.
print("Bangalore multispectral image shape: ", featuresBangalore.shape) print("Bangalore binary built-up image shape: ", labelBangalore.shape) print("Hyderabad multispectral image shape: ", featuresHyderabad.shape)
Résultat:
Bangalore multispectral image shape: 6, 2054, 2044 Bangalore binary built-up image shape: 2054, 2044 Hyderabad multispectral image shape: 6, 1318, 1056
Comme vous pouvez le voir, les images de Bangalore ont le même nombre de lignes et de colonnes que dans la couche binaire (correspondant au bâtiment). Le nombre de couches dans les images multispectrales à Bangalore et Hyderabad coïncide également. Le modèle apprendra à décider quels pixels appartiennent au bâtiment et lesquels ne le font pas, sur la base des valeurs correspondantes pour les 6 spectres. Par conséquent, les images multispectrales doivent avoir le même nombre de caractéristiques (plages) répertoriées dans le même ordre.
Maintenant, nous transformons les tableaux en deux dimensions, où chaque ligne représente un pixel distinct, car cela est nécessaire au fonctionnement de la plupart des algorithmes d'apprentissage automatique. Nous le ferons en utilisant le module de
pyrsgis paquet
pyrsgis .
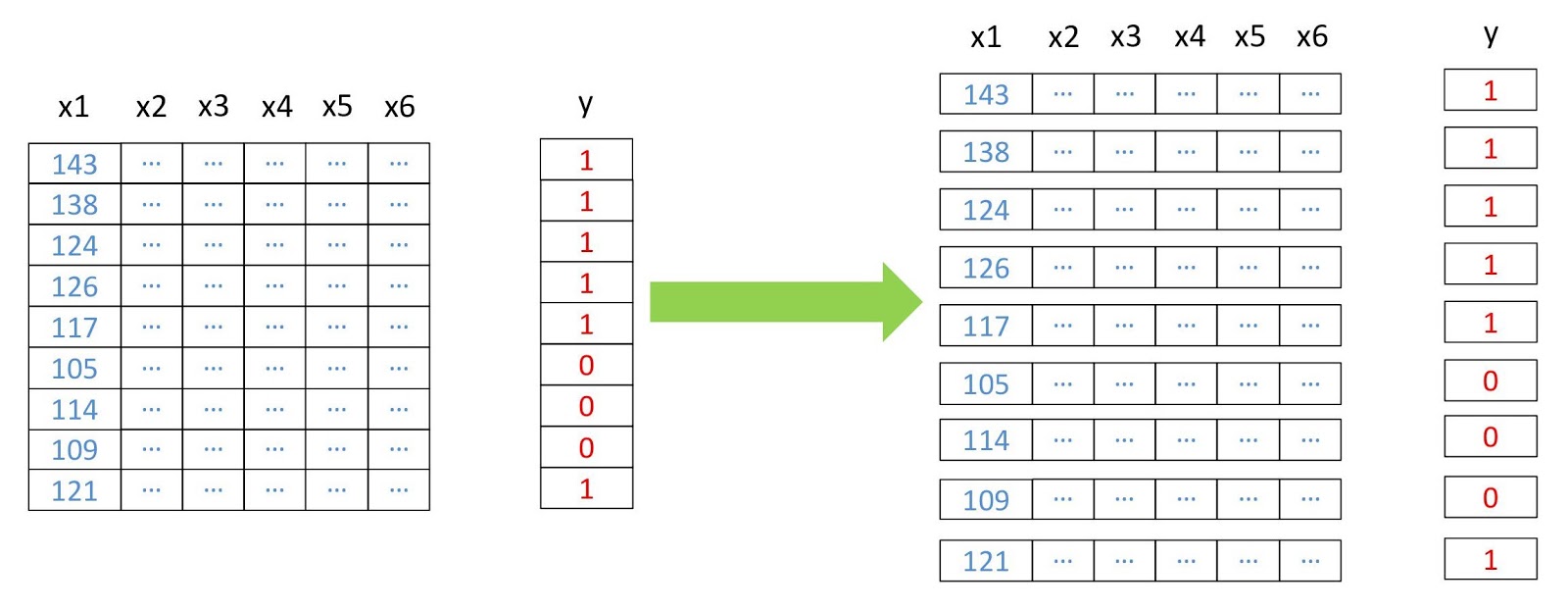
 Schéma de restructuration des données.
Schéma de restructuration des données. from pyrsgis.convert import changeDimension featuresBangalore = changeDimension(featuresBangalore) labelBangalore = changeDimension (labelBangalore) featuresHyderabad = changeDimension(featuresHyderabad) nBands = featuresBangalore.shape[1] labelBangalore = (labelBangalore == 1).astype(int) print("Bangalore multispectral image shape: ", featuresBangalore.shape) print("Bangalore binary built-up image shape: ", labelBangalore.shape) print("Hyderabad multispectral image shape: ", featuresHyderabad.shape)
Résultat:
Bangalore multispectral image shape: 4198376, 6 Bangalore binary built-up image shape: 4198376 Hyderabad multispectral image shape: 1391808, 6
Dans la septième ligne, nous avons extrait tous les pixels avec une valeur de 1. Cela permet d'éviter les problèmes avec les pixels sans information (NoData), qui ont souvent des valeurs extrêmement élevées ou faibles.
Nous allons maintenant diviser les données en échantillons d'apprentissage et de validation. Cela est nécessaire pour que le modèle ne voit pas les données de test et fonctionne aussi bien avec les nouvelles informations. Sinon, le modèle sera recyclé et ne fonctionnera bien que sur les données de formation.
from sklearn.model_selection import train_test_split xTrain, xTest, yTrain, yTest = train_test_split(featuresBangalore, labelBangalore, test_size=0.4, random_state=42) print(xTrain.shape) print(yTrain.shape) print(xTest.shape) print(yTest.shape)
Résultat:
(2519025, 6) (2519025,) (1679351, 6) (1679351,) test_size=0.4
signifie que les données sont divisées en formation et validation dans un rapport de 60/40.
De nombreux algorithmes d'apprentissage automatique, y compris les réseaux de neurones, ont besoin de données normalisées. Cela signifie qu'ils doivent être répartis dans une plage donnée (dans ce cas, de 0 à 1). Par conséquent, pour répondre à cette exigence, nous normalisons les symptômes. Cela peut être fait en extrayant la valeur minimale puis en la divisant par l'écart (la différence entre les valeurs maximale et minimale). Étant donné que l'ensemble de données Landsat est de huit bits, les valeurs minimale et maximale seront 0 et 255 (2
⁸ = 256 valeurs).
Notez que pour la normalisation, il est toujours préférable de calculer les valeurs minimale et maximale en fonction des données. Pour simplifier la tâche, nous respecterons la plage de huit bits par défaut.
Une autre étape du traitement préliminaire est la transformation de la matrice des signes de deux dimensions en trois dimensions, de sorte que le modèle perçoit chaque ligne comme un pixel séparé (un objet d'apprentissage séparé).
Résultat:
(2519025, 1, 6) (1679351, 1, 6) (1391808, 1, 6)
Tout est prêt, assemblons notre modèle avec des
keras . Pour commencer, utilisons le modèle séquentiel, en ajoutant des couches les unes après les autres. Nous aurons une couche d'entrée avec un nombre de nœuds égal au nombre de plages (
nBands ) - dans notre cas il y en a 6. Nous utiliserons également une couche cachée avec 14 nœuds et la
ReLu activation
ReLu . La dernière couche se compose de deux nœuds pour définir une classe de construction binaire avec la
softmax activation
softmax , qui convient pour afficher un résultat catégorisé. En savoir plus sur les fonctions d'activation
ici .
from tensorflow import keras
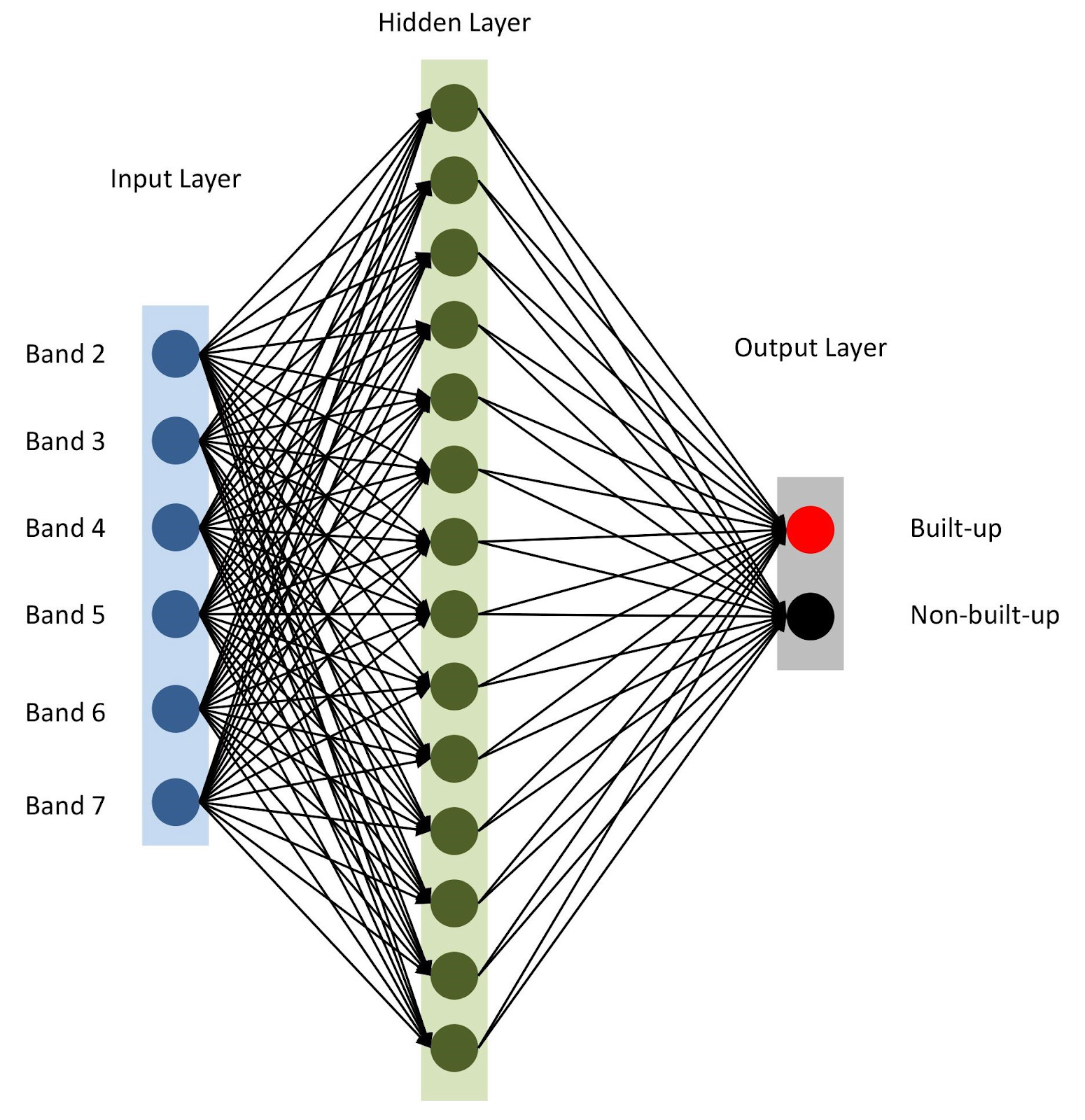 Architecture de réseau neuronal
Architecture de réseau neuronalComme mentionné à la ligne 10, nous spécifions
adam comme optimiseur de modèle (il y en a plusieurs
autres ). Dans ce cas, nous utiliserons l'entropie croisée comme fonction de perte (fr.
categorical-sparse-crossentropy entropie croisée
categorical-sparse-crossentropy - plus d'informations à ce sujet sont écrites
ici ). Pour évaluer la qualité du modèle, nous utiliserons la métrique de
accuracy .
Enfin, nous commencerons à former notre modèle pour deux époques (ou itérations) sur
xTrain et
yTrain . Cela prendra un certain temps, selon la taille des données et la puissance de traitement. Voici ce que vous verrez après la compilation:

Prédisons les valeurs des données de validation que nous stockons séparément et calculons diverses mesures de précision.
from sklearn.metrics import confusion_matrix, precision_score, recall_score
La fonction
softmax génère des colonnes séparées pour les valeurs de probabilité pour chaque classe. Nous utilisons uniquement les valeurs de la première classe ("il y a un bâtiment"), comme on peut le voir sur la sixième ligne du code ci-dessus. L'évaluation du travail des modèles d'analyse géospatiale n'est pas si simple, contrairement à d'autres problèmes classiques d'apprentissage automatique. Il sera injuste de s'appuyer sur une erreur totale généralisée. La clé d'un modèle réussi est la disposition spatiale. Ainsi, la matrice de confusion, la précision et l'exhaustivité peuvent donner une idée plus correcte de la qualité du modèle.
 Ainsi, la console affiche la matrice d'erreur, la précision et l'exhaustivité.
Ainsi, la console affiche la matrice d'erreur, la précision et l'exhaustivité.Comme vous pouvez le voir dans la matrice de confusion, il existe des milliers de pixels liés aux bâtiments, mais classés différemment, et vice versa. Cependant, leur part du volume total de données n'est pas trop importante. La précision et l'exhaustivité des données d'essai ont dépassé le seuil de 0,8.
Vous pouvez passer plus de temps et effectuer plusieurs itérations pour trouver le nombre optimal de couches cachées, le nombre de nœuds dans chaque couche cachée, ainsi que le nombre d'époques pour atteindre la précision souhaitée. Au besoin, des indices de télédétection comme NDBI ou NDWI peuvent être utilisés comme caractéristiques. Lorsque vous atteignez la précision souhaitée, utilisez le modèle pour prédire le développement en fonction des nouvelles données et exporter le résultat vers GeoTIFF. Pour de telles tâches, vous pouvez utiliser un modèle similaire avec des modifications mineures.
predicted = model.predict(feature2005) predicted = predicted[:,1]
Veuillez noter que nous exportons GeoTIFF avec des valeurs de probabilité prédites, et non avec leur version seuil binarisée. Plus tard dans l'environnement SIG, nous pouvons définir la valeur de seuil d'une couche de type float, comme indiqué dans la figure ci-dessous.
 Couche bâtie d'Hyderabad prévue par le modèle à partir de données multispectrales.
Couche bâtie d'Hyderabad prévue par le modèle à partir de données multispectrales.La précision du modèle a déjà été mesurée avec précision et rappel. Vous pouvez également effectuer des vérifications traditionnelles (par exemple, en utilisant le coefficient kappa) sur une nouvelle couche prédite. En plus des difficultés susmentionnées avec la classification des images satellite, d'autres limitations évidentes incluent l'impossibilité de prévoir des images basées sur des images prises à différents moments de l'année et dans différentes régions, car elles auront des signatures spectrales différentes.
Le modèle décrit dans cet article a l'architecture la plus simple pour les réseaux de neurones. De meilleurs résultats peuvent être obtenus avec des modèles plus complexes, y compris les réseaux de neurones convolutionnels. Le principal avantage d'une telle classification est son évolutivité (applicabilité) après la formation du modèle.
Les données utilisées et tout le code sont
ici .