Je m'appelle Azat Razetdinov, je suis chez Yandex depuis 12 ans, je gère le service de développement d'interfaces chez Y. Real Estate. Aujourd'hui, je voudrais parler d'un monorepositaire. Si vous n'avez qu'un seul référentiel au travail - félicitations, vous vivez déjà dans un seul référentiel. Maintenant pourquoi les autres en ont besoin.
Selon Marina Pereskokova, chef du service de développement d'API Yandex.Mart, mon grand-père a planté un monorepa, et un monorepa est devenu grand, gros.
- Chez Yandex, nous avons essayé différentes façons de travailler avec plusieurs services et nous avons remarqué - dès que vous avez plus d'un service, des parties communes commencent inévitablement à apparaître: modèles, utilitaires, outils, morceaux de code, modèles, composants. La question est: où mettre tout ça? Bien sûr, vous pouvez copier-coller, nous pouvons le faire, mais je le veux magnifiquement.
Nous avons même essayé une entité comme SVN externals pour ceux qui s'en souviennent. Nous avons essayé les sous-modules git. Nous avons essayé les packages npm lorsqu'ils sont apparus. Mais tout cela était en quelque sorte long, ou quelque chose. Vous prenez en charge n'importe quel package, recherchez une erreur, apportez des corrections. Ensuite, vous devez publier une nouvelle version, passer par les services, mettre à niveau vers cette version, vérifier que tout fonctionne, exécuter les tests, rechercher l'erreur, revenir au référentiel de la bibliothèque, corriger l'erreur, publier la nouvelle version, parcourir les services, mettre à jour et ainsi de suite cercle. Cela s'est juste transformé en douleur.

Ensuite, nous avons réfléchi à l'opportunité de nous réunir dans un seul référentiel. Prenez tous nos services et bibliothèques, transférez et développez dans un seul référentiel. Il y avait beaucoup d'avantages. Je ne dis pas que cette approche est idéale, mais du point de vue de l'entreprise et même du département de plusieurs groupes, des avantages significatifs apparaissent.
Pour moi personnellement, la chose la plus importante est l'atomicité des commits, qu'en tant que développeur, je peux réparer la bibliothèque, contourner tous les services, apporter des modifications, exécuter des tests, vérifier que tout fonctionne, la pousser dans le maître, et tout cela avec une seule modification. Pas besoin de reconstruire, publier, mettre à jour quoi que ce soit.
Mais si tout va si bien, pourquoi tout le monde n'est-il pas encore passé au mono-référentiel? Bien sûr, il y a aussi des inconvénients.

Selon Marina Pereskokova, chef du service de développement d'API Yandex.Map, mon grand-père a planté un monorepa, et un monorepa est devenu grand, gros. C'est un fait, pas une blague. Si vous collectez de nombreux services dans un seul référentiel, il se développe inévitablement. Et si nous parlons de git, qui extrait tous les fichiers ainsi que leur historique complet pour toute l'existence de votre code, c'est un espace disque assez grand.
Le deuxième problème est l'injection dans le maître. Vous avez préparé une demande de pool, effectué un examen, vous êtes prêt à la fusionner. Et il s'avère que quelqu'un a réussi à vous devancer et que vous devez résoudre les conflits. Vous avez résolu les conflits, encore une fois prêt à affluer, et encore une fois, vous n'avez pas eu le temps. Ce problème est en train d'être résolu, il existe des systèmes de file d'attente de fusion, lorsqu'un robot spécial automatise ce travail, demande des pools de voies, tente de résoudre les conflits, s'il le peut. S'il ne le peut pas, il appelle l'auteur. Cependant, un tel problème existe. Il existe des solutions qui le nivellent, mais vous devez en tenir compte.
Ce sont des points techniques, mais aussi organisationnels. Supposons que vous ayez plusieurs équipes qui fournissent plusieurs services différents. Lorsqu'ils migrent vers un seul référentiel, leur responsabilité commence à s'éroder. Parce qu'ils ont fait une sortie, déployé en production - quelque chose s'est cassé. Nous commençons le débriefing. Il s'avère que c'est un développeur d'une autre équipe qui a commis quelque chose dans le code général, nous l'avons retiré, non publié, ne l'avons pas vu, tout s'est cassé. Et il n'est pas clair qui est responsable. Il est important de comprendre et d'utiliser toutes les méthodes possibles: tests unitaires, tests d'intégration, linter - tout ce qui est possible pour réduire ce problème de l'influence d'un code sur tous les autres services.
Fait intéressant, qui d'autre que Yandex et d'autres joueurs utilise le mono-référentiel? Beaucoup de gens. Ce sont React, Jest, Babel, Ember, Meteor, Angular. Les gens comprennent - il est plus facile, moins cher, plus rapide de développer et de publier des packages npm à partir d'un référentiel unique que de plusieurs petits référentiels. La chose la plus intéressante est qu'avec ce processus, des outils pour travailler avec un monorepositaire ont commencé à se développer. Juste à propos d'eux et je veux parler.
Tout commence par la création d'un monorepositaire. L'outil frontal le plus célèbre au monde est appelé lerna.

Ouvrez simplement votre dépôt, exécutez npx lerna init, il vous posera des questions suggestives et ajoutera quelques entités à votre copie de travail. La première entité est la configuration lerna.json, qui indique au moins deux champs: la version de bout en bout de tous vos packages et l'emplacement de vos packages dans le système de fichiers. Par défaut, tous les packages sont ajoutés au dossier packages, mais vous pouvez le configurer à votre guise, vous pouvez même les ajouter à la racine, lerna peut également le récupérer.
La prochaine étape est de savoir comment ajouter vos référentiels au référentiel mono, comment les transférer?
Que voulons-nous réaliser? Très probablement, vous avez déjà une sorte de référentiel, dans ce cas A et B.

Il s'agit de deux services, chacun dans son propre référentiel, et nous souhaitons les transférer vers le nouveau mono-référentiel dans le dossier packages, de préférence avec un historique des validations, afin que vous puissiez rendre git blame, git log, etc.

Il existe un outil d'importation lerna pour cela. Vous spécifiez simplement l'emplacement de votre référentiel et lerna le transfère à votre monorepo. Dans le même temps, elle prend d'abord une liste de toutes les validations, modifie chaque validation, change le chemin d'accès aux fichiers de la racine en packages / nom_package, et les applique les unes après les autres, les impose dans votre mono-référentiel. En fait, chaque commit se prépare, en changeant les chemins d'accès aux fichiers. Essentiellement, lerna fait de la magie pour vous. Si vous lisez le code source, les commandes git sont simplement exécutées dans une certaine séquence.
C’est la première façon. Cela a un inconvénient: si vous travaillez dans une entreprise où il y a des processus de production, où les gens écrivent déjà une sorte de code et que vous allez les traduire en un monorep, vous ne le ferez probablement pas en une journée. Vous devrez comprendre, configurer, vérifier que tout démarre, tester. Mais les gens n'ont pas de travail, ils continuent de faire quelque chose.

Pour une transition plus fluide vers le mono-rap, il existe un outil tel que git subtree. C'est une chose plus sophistiquée, mais en même temps native de git, qui vous permet non seulement d'importer des référentiels individuels dans un référentiel mono par une sorte de préfixe, mais aussi d'échanger des modifications dans les deux sens. Autrement dit, l'équipe qui fournit le service peut être facilement développée davantage dans son propre référentiel séparé, tandis que vous pouvez extraire leurs modifications via git subtree pull, apporter vos propres modifications et les repousser via git subtree push. Et vivez comme ça dans la période de transition aussi longtemps que vous le souhaitez.
Et lorsque vous avez tout configuré, vérifié que tous les tests sont en cours d'exécution, que le déploiement fonctionne, que l'ensemble du CI / CD est configuré, vous pouvez dire qu'il est temps de passer à autre chose. Pour la période de transition, une excellente solution, je recommande.
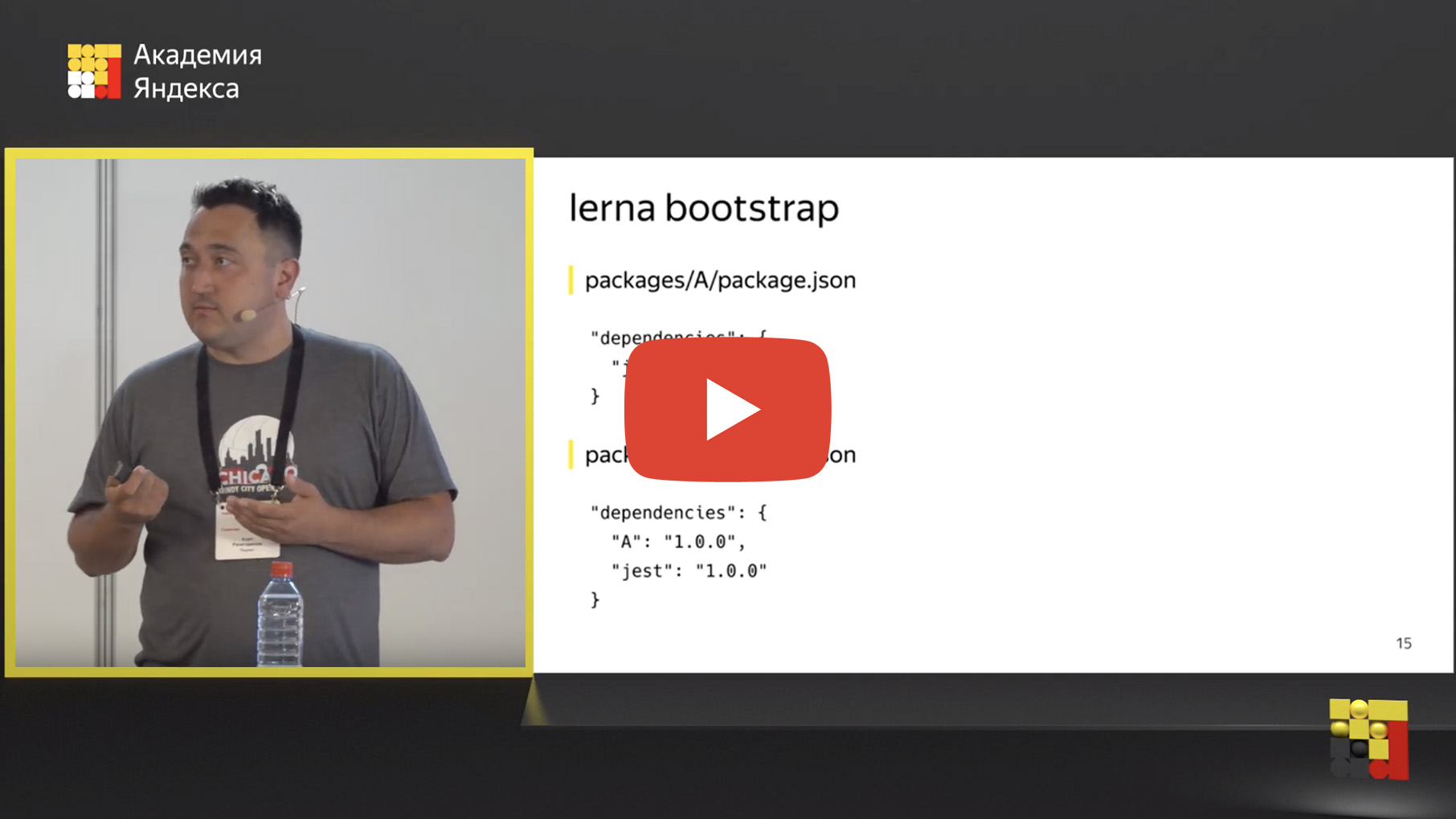
Eh bien, nous avons déplacé nos référentiels dans un mono-référentiel, mais où est la magie quelque part? Mais nous voulons mettre en évidence les parties communes et les utiliser d'une manière ou d'une autre. Et pour cela, il existe un mécanisme de «liaison de dépendance». Qu'est-ce que la dépendance de liaison? Il existe un outil d'amorçage lerna, une commande similaire à npm install, qui exécute simplement npm install dans tous vos packages.

Mais ce n’est pas tout. De plus, elle recherche des dépendances internes. Vous pouvez en utiliser un autre dans un package à l'intérieur de votre référentiel. Par exemple, si vous avez le package A, qui dépend de Jest dans ce cas, il y a le package B, qui dépend de Jest et le package A. Si le package A est un outil commun, un composant commun, alors le package B est un service qui l'a utilise.
Lerna définit ces dépendances internes et remplace physiquement cette dépendance par un lien symbolique sur le système de fichiers.


Après avoir exécuté lerna bootstrap, juste à l'intérieur du dossier node_modules, au lieu du dossier physique A, un lien symbolique apparaît qui mène au dossier avec le package A. Ceci est très pratique car vous pouvez modifier le code dans le package A et vérifier immédiatement le résultat dans le package B , exécutez les tests, l'intégration, les unités, tout ce que vous voulez. Le développement est grandement simplifié, vous n'avez plus besoin de réassembler le package A, de publier, de connecter le package B. Il vient d'être corrigé ici, vérifié là.
Veuillez noter que si vous regardez les dossiers node_modules, et là et il y a de la plaisanterie, nous avons dupliqué le module installé. En général, il faut un certain temps lorsque vous démarrez lerna bootstrap, attendez que tout s'arrête, car il y a beaucoup de travaux répétés, des dépendances en double sont obtenues dans chaque package.
Pour accélérer l'installation des dépendances, le mécanisme d'augmentation des dépendances est utilisé. L'idée est très simple: vous pouvez apporter les dépendances générales à la racine node_modules.

Si vous spécifiez l'option --hoist (il s'agit d'une mise à niveau à partir de l'anglais), presque toutes les dépendances seront simplement déplacées vers les root node_modules. Et cela fonctionne presque toujours. Noda est tellement arrangée que si elle n'a pas trouvé les dépendances à son niveau, elle commence à chercher un niveau plus haut, sinon là, un autre niveau plus haut et ainsi de suite. Presque rien ne change. Mais en fait, nous avons pris et dédupliqué nos dépendances, transféré les dépendances à la racine.
En même temps, lerna est assez intelligente. S'il y a un conflit, par exemple, si le package A utilise Jest version 1 et le package B utilise la version 2, alors l'un d'eux apparaîtra et le second restera à son niveau. C'est à peu près ce que fait npm dans le dossier node_modules normal, il essaie également de dédupliquer les dépendances et de les porter au maximum à la racine.
Malheureusement, cette magie ne fonctionne pas toujours, surtout avec les outils, avec Babel, avec Jest. Il arrive souvent qu'il démarre, car Jest a son propre système de résolution de modules, Noda commence à traîner, lance une erreur. Surtout dans de tels cas où l'outil ne gère pas les dépendances qui sont allées à la racine, il existe l'option nohoist, qui vous permet de souligner que ces packages ne sont pas transférés à la racine, laissez-les en place.

Si vous spécifiez --nohoist = jest, toutes les dépendances à l'exception de jest iront à la racine et jest restera au niveau du paquet. Pas étonnant que j'aie donné un tel exemple - c'est une plaisanterie qui a des problèmes avec ce comportement, et nohoist aide à cela.
Un autre avantage de la récupération des dépendances:

Si auparavant vous aviez package-lock.json séparé pour chaque service, pour chaque package, alors quand vous êtes hoyed, tout monte, et le seul package-lock.json reste. Ceci est pratique du point de vue du déversement dans le maître, de la résolution des conflits. Une fois que tout le monde a été tué, et c'est tout.
Mais comment lerna y parvient-elle? Elle est assez agressive avec npm. Lorsque vous spécifiez hoist, il prend votre package.json à la racine, le sauvegarde, en substitue un autre, agrège toutes vos dépendances, exécute npm install, presque tout est placé à la racine. Ensuite, ce package.json temporaire supprime, restaure le vôtre. Si après cela, vous exécutez une commande avec npm, par exemple, npm remove, npm ne comprendra pas ce qui s'est passé, pourquoi toutes les dépendances sont soudainement apparues à la racine. Lerna viole le niveau d'abstraction, elle rampe dans l'outil, qui est en dessous de son niveau.
Les gars de Yarn ont été les premiers à remarquer ce problème et ont dit: qu'est-ce que nous tourmentons, laissez-nous tout faire pour vous nativement, afin que tout hors de la boîte fonctionne.

Yarn peut déjà faire la même chose hors de la boîte: dépendances de liens, s'il voit que le package B dépend du package A, il fera un lien symbolique pour vous, gratuitement. Il sait comment augmenter les dépendances, le fait par défaut, tout s'additionne à la racine. Comme lerna, il peut laisser le seul yarn.lock à la racine du référentiel. Tout le monde yarn.lock dont vous n'avez plus besoin.

Il est configuré de manière similaire. Malheureusement, yarn suppose que tous les paramètres sont ajoutés à package.json, je sais qu'il y a des gens qui essaient de supprimer tous les paramètres des outils à partir de là, ne laissant qu'un minimum. Malheureusement, yarn n'a pas encore appris à le spécifier dans un autre fichier, uniquement package.json. Il y a deux nouvelles options, une nouvelle et une obligatoire. Comme il est supposé que le référentiel racine ne sera jamais publié, yarn requiert private = true pour y être spécifié.
Mais les paramètres des espaces de travail sont stockés dans la même clé. Le paramètre est très similaire aux paramètres de lerna, il y a un champ packages où vous spécifiez l'emplacement de vos packages, et il y a une option nohoist, très similaire à l'option nohoist dans lerna. Spécifiez simplement ces paramètres et obtenez la même structure que dans lerna. Toutes les dépendances courantes sont allées à la racine et celles spécifiées dans la clé nohoist sont restées à leur niveau.

La meilleure partie est que lerna peut travailler avec du fil et ramasser ses paramètres. Il suffit de spécifier deux champs dans lerna.json, lerna comprendra immédiatement que vous utilisez du fil, allez dans package.json, obtenez tous les paramètres à partir de là et travaillez avec eux. Ces deux outils se connaissent déjà et fonctionnent ensemble.

Et pourquoi le support n'a-t-il pas encore été fait à npm si tant de grandes entreprises utilisent un mono-référentiel?

Ils disent que tout sera, mais dans la septième version. Support de base dans le septième, étendu - dans le huitième. Ce post a été publié il y a un mois, mais en même temps, la date n'est pas encore connue pour la sortie du septième npm. Nous attendons qu'il rattrape enfin le fil.
Lorsque vous avez plusieurs services dans un mono-référentiel, la question se pose inévitablement de les gérer pour ne pas aller dans chaque dossier, ne pas exécuter de commandes? Il y a des opérations massives pour cela.


Yarn possède une commande d'espace de travail Yarn, suivie du nom du package et du nom de la commande. Étant donné que le fil de la boîte, contrairement à npm, peut faire les trois choses: exécuter ses propres commandes, ajouter une dépendance à Jest, exécuter des scripts à partir de package.json, comme test, et peut également exécuter des fichiers exécutables à partir du dossier node_modules / .bin. Il vous enseignera à l'aide d'heuristiques il comprendra ce que vous voulez. Il est très pratique d'utiliser l'espace de travail de fil pour les opérations ponctuelles sur un seul paquet.
Il existe une commande similaire qui vous permet d'exécuter une commande sur tous les packages dont vous disposez.

Indiquez uniquement vos commandes avec tous les arguments.

De la part des pros, il est très pratique de diriger différentes équipes. Parmi les inconvénients, par exemple, il est impossible d'exécuter des commandes shell. Supposons que je veuille supprimer tous les dossiers des modules de nœuds, je ne peux pas exécuter les espaces de travail de fil run rm.
Il n'est pas possible de spécifier une liste de packages, par exemple, je souhaite supprimer la dépendance dans seulement deux packages, un seul à la fois ou séparément.
Eh bien, il se bloque à la toute première erreur. Si je veux supprimer la dépendance de tous les packages - et en fait, seulement deux d'entre eux l'ont, mais je ne veux pas penser où elle se trouve, mais je veux juste la supprimer - alors le fil ne le permettra pas, il plantera à la toute première situation où ce package n'est pas dans les dépendances. Ce n'est pas très pratique, parfois vous voulez ignorer les erreurs, parcourir tous les packages.

Lerna a une boîte à outils beaucoup plus intéressante, il y a deux commandes run et exec distinctes. Run peut exécuter des scripts à partir de package.json, et contrairement à yarn, il peut tout filtrer par packages, vous pouvez spécifier --scope, vous pouvez utiliser des astérisques, des globes, tout est assez universel. Vous pouvez exécuter ces opérations en parallèle, vous pouvez ignorer les erreurs via le commutateur --no-bail.

Exec est très similaire. Contrairement à Yarn, il vous permet non seulement d'exécuter des fichiers exécutables à partir de node_modules.bin, mais également d'exécuter des commandes shell arbitraires. Par exemple, vous pouvez supprimer node_modules ou exécuter une marque, comme vous le souhaitez. Et la même option est prise en charge.

Des outils très pratiques, quelques avantages. C'est le cas lorsque la lerne déchire le fil, est au bon niveau d'abstraction. C'est exactement ce dont lerna a besoin: simplifier le travail avec plusieurs packages en monorepe.
Avec les monoreps, il y a encore un inconvénient. Lorsque vous avez un CI / CD, vous ne pouvez pas l’optimiser. Plus vous avez de services, plus cela prend de temps. Supposons que vous commenciez à tester tous les services pour chaque demande de pool, et plus il y en a, plus le travail prend de temps. Des opérations sélectives peuvent être utilisées pour optimiser ce processus. Je nommerai trois façons différentes. Les deux premiers d'entre eux peuvent être utilisés non seulement en monorep, mais aussi dans vos projets, si pour une raison quelconque vous n'utilisez pas ces méthodes.
La première est lint-stages, qui vous permet d'exécuter linter, des tests, tout ce que vous voulez, uniquement sur les fichiers qui ont été modifiés ou seront validés dans ce commit. Exécutez l'intégralité de la charpie non pas sur l'ensemble de votre projet, mais uniquement sur les fichiers qui ont été modifiés.


La configuration est très simple. Mettez des crochets pelucheux, pré-validés et dites que lorsque vous modifiez un fichier js, vous devez exécuter eslint. Ainsi, la vérification de pré-validation est considérablement accélérée. Surtout si vous avez de nombreux services, un très grand référentiel mono. L'exécution d'eslint sur tous les fichiers est alors trop coûteuse et vous pouvez optimiser les crochets de pré-engagement sur lint de cette manière.

Si vous écrivez des tests sur Jest, il dispose également d'outils pour exécuter des tests de manière sélective.

Cette option vous permet de lui donner une liste de fichiers source et de trouver tous les tests qui d'une manière ou d'une autre affectent ces fichiers. Que peut-on utiliser en conjonction avec des peluches? Attention, ici je ne précise pas tous les fichiers js, mais seulement la source. Nous excluons les fichiers js eux-mêmes avec des tests à l'intérieur, nous ne regardons que la source. Nous commençons findRelatedTests et accélérons considérablement le fonctionnement de l'unité pour précommettre ou pré-pousser, comme vous le souhaitez.
Et la troisième méthode est associée aux monorepositoires. Il s'agit de lerna, qui peut déterminer quels packages ont changé par rapport à la validation de base. Il ne s'agit probablement pas de crochets, mais de votre CI / CD: Travis ou d'un autre service que vous utilisez.


Les commandes run et exec ont l'option since, qui vous permet d'exécuter n'importe quelle commande uniquement dans les packages qui ont changé depuis une sorte de commit. Dans les cas simples, vous pouvez spécifier un assistant si vous y versez tout. Si vous voulez plus de précision, il est préférable de spécifier la validation de base de votre demande de pool via votre outil CI / CD, alors ce sera un test plus honnête.
Puisque lerna connaît toutes les dépendances à l'intérieur des packages, il peut également détecter les dépendances indirectes. Si vous changez la bibliothèque A, qui est utilisée dans la bibliothèque B, qui est utilisée dans le service C, lerna le comprendra. , . , C — , . lerna .
, :
c lerna ,
yarn workspaces
.
, . , . . ? , , , . , , . , - . , Babel. , , . . , .
:
mishanga . , , . , .