AI sur le fer domestique
Nous parlons de la façon dont nous avons porté notre cadre pour les réseaux de neurones et le système de reconnaissance faciale sur les processeurs Elbrus russes.
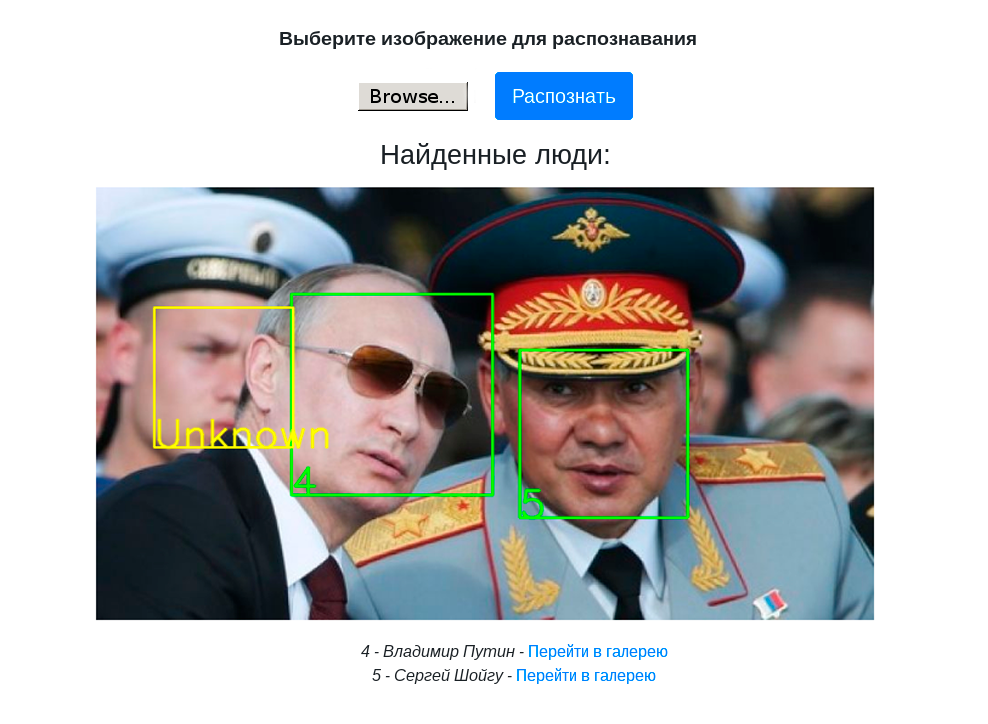
C'était une tâche intéressante, au printemps 2019, nous en avons parlé au bureau de Yandex lors de la grande réunion sur Elbrus, que nous partageons maintenant avec Habr.
En bref - qu'est-ce que Elbrus
Il s'agit d'un processeur russe avec sa propre architecture, développé au
MCST . Maxim Gorshenin parle bien de lui sur sa chaîne:
www.youtube.com/watch?v=H8eBgJ58EPYEn bref - qu'est-ce que PuzzleLib
Il s'agit de notre plateforme pour les réseaux de neurones, que nous développons et utilisons depuis 2015. Analogue de Google TensorFlow et Facebook PyTorch. Fait intéressant, PuzzleLib prend en charge non seulement les processeurs NVIDIA et Intel, mais également les cartes vidéo AMD.
Bien que nous ayons une petite bibliothèque (TensorFlow a environ 2 millions de lignes, nous en avons 100 000), nous sommes meilleurs en vitesse - un peu, mais mieux =)
Nous ne sommes pas encore en open source, la bibliothèque est utilisée pour nos projets. La bibliothèque est complète: elle prend en charge à la fois la phase d'apprentissage et la phase d'inférence des réseaux de neurones. Vous pouvez créer des réseaux de neurones convolutifs récurrents, il existe également une interface pour créer des graphiques arbitraires de calculs.
PuzzleLib a
- Modules d'assemblage de réseaux de neurones (Activation (Sigmoid, Tanh, ReLU, ELU, LeakyReLU, SoftMaxPlus), AvgPool (1D, 2D, 3D), BatchNorm (1D, 2D, 3D, ND), Conv (1D, 2D, 3D, ND) , CrossMapLRN, Deconv (1D, 2D, 3D, ND), Dropout (1D, 2D), etc.)
- Optimiseurs (AdaDelta, AdaGrad, Adam, Hooks, LBFGS, MomentumSGD, NesterovSGD, RMSProp, etc.)
- Réseaux de neurones prêts à l'emploi (Resnet, Inception, YOLO, U-Net, etc.)
Ce sont les blocs familiers, familiers à tous ceux qui sont impliqués dans les réseaux de neurones, pour les concepteurs de réseaux de neurones (puisque tous les cadres sont des constructeurs composés de blocs de calcul et d'algorithmes typiques).
Nous avons eu l'idée de lancer notre bibliothèque sur l'architecture Elbrus.
Pourquoi voulions-nous soutenir Elbrus?
- Ceci est le seul processeur russe, je voulais comprendre comment les choses vont avec, comment c'est facile de travailler avec.
- Nous avons pensé qu'il pourrait être intéressant pour les organisations étatiques que le logiciel russe que nous développons fonctionne sur du matériel russe.
- Et bien sûr, nous étions simplement intéressés, car Elbrus est un processeur VLIW , c'est-à-dire un processeur avec de longues instructions, et il n'y a pas de tels processeurs polyvalents à part entière dans le monde.
Tout a commencé avec le fait que nous avons rencontré le MCST, discuté et prêté l'ordinateur
Elbrus 401 pour le développement.
Ce que j'ai aimé : Linux fonctionne sur Elbrus, il y a du python dans ce Linux, et cela ne fonctionne pas en mode d'émulation - c'est un python natif à part entière, assemblé pour Elbrus. Il existe également un ensemble de bibliothèques python standard, par exemple numpy, que tous les développeurs adorent beaucoup.
Il y avait certaines tâches pour lesquelles nous devions également collecter des bibliothèques: par exemple, dans PuzzleLib, nous utilisons le format hdf pour stocker les poids des réseaux de neurones, et, en conséquence, nous avons dû construire les bibliothèques libhdf et h5py à l'aide du compilateur lcc. Mais nous n'avons eu aucun problème d'assemblage.
La bibliothèque de vision par ordinateur OpenCV était également déjà compilée, mais il n'y avait aucune liaison pour python - nous l'avons construite séparément.
La célèbre bibliothèque dlib est également assez facile à compiler. Il n'y a eu que des difficultés mineures: certains fichiers de ce projet open source étaient sans bom-marker pour déterminer utf-8, ce qui a bouleversé le lexer lcc. En fait, il y avait simplement un format de fichier incorrect, qui devait être corrigé dans la source.
Nous avons décidé de commencer par la reconnaissance faciale. Il s'agit d'un cas d'utilisation compréhensible pour beaucoup, où cette technologie est utilisée. PuzzleLib, comme d'autres bibliothèques, a une partie backend assez grande, c'est-à-dire une base de code spécifique aux différentes architectures de processeur.
Nos backends:- CUDA (NVIDIA)
- Ouvert CL + MI Ouvert (AMD)
- mlkDNN (Intel)
- CPU (numpy)
Sur Elbrus, nous avons lancé un backend numpy, ce qui était très simple, car la plateforme nécessite un minimum de tout:
Plateforme -> compilateur c90 -> python -> numpyNous avons une bibliothèque sans complication (par exemple, sans aucun système d'assemblage spécial) - en plus du fait que nous devions collecter certains classeurs. Nous avons effectué les tests, tout fonctionne - les grilles convolutives et récurrentes. La reconnaissance faciale que nous avons lancée est assez simple, basée sur Inception-ResNet.
Premiers résultats de travailSur Intel Core i7 7700, le temps de traitement pour une image était de 0,1 seconde, et ici - 15. Il fallait optimiser.
Bien sûr, espérer que numpy fonctionnerait bien à la volée serait faux.
Comment nous avons optimisé l'informatique
Nous avons mesuré la vitesse d'inférence à travers le profileur python et découvert que presque tout le temps était consacré à la multiplication des matrices en numpy. Pour l'échantillon, ils ont écrit la multiplication manuelle la plus simple de la matrice, et elle s'est déjà avérée plus rapide, même si on ne savait pas pourquoi.
Il semblerait que numpy.dot aurait dû être écrit un peu moins naïf qu'une multiplication aussi simple. Néanmoins, nous avons convaincu, vérifié - cela s'est avéré plus rapide (12 secondes par image au lieu de 15).
Ensuite, nous avons découvert la bibliothèque d'algèbre linéaire EML, qui est en cours de développement à ICST, et avons remplacé les appels np.dot par cblas_sgemm. Il est devenu 10 fois plus rapide (1,5 seconde) - nous avons été très satisfaits.
Cela a été suivi de plusieurs optimisations pas à pas. Étant donné que nous n'utilisons que la reconnaissance des visages, et non des données généralement arbitraires, nous avons décidé d'affiner nos opérations uniquement sous les tenseurs 4d et de faire de Fusion - après quoi le temps de traitement a diminué de 2 fois - à 0,75 seconde.
Explication: La fusion est lorsque plusieurs opérations sont combinées en une seule, par exemple, la convolution, la normalisation et l'activation. Au lieu de faire une passe en trois cycles, une passe est effectuée.
Ces bibliothèques sont disponibles auprès de NVIDIA (
TensorRT ). Un graphe de calcul y est chargé et la bibliothèque produit un graphe optimisé et accéléré, en particulier du fait qu'elle peut regrouper les opérations en une seule. Intel en a également un similaire (nGraph et
OpenVINO ).
Ensuite, nous avons vu que, comme il y avait beaucoup de convolutions 1x1 dans Inception-ResNet, nous avions une copie de données supplémentaire. Nous avons décidé de nous spécialiser dans le fait que nous travaillons sur des lots à partir d'une photo (c'est-à-dire que nous ne traitons pas 100 photos par lots, mais fournissons le mode de streaming) - il existe de tels cas d'utilisation lorsque vous devez travailler non pas avec des archives, mais avec un flux (par exemple, pour la surveillance vidéo ou ACS). Nous avons créé un passage spécialisé sans
im2col (retiré les grandes copies) - il est devenu 0,45 seconde.
Ensuite, nous avons regardé à nouveau le profileur, nous avions tout de la même manière - bien que toutes les étapes aient diminué dans le temps, nous avons encore 80% du temps consacré au calcul des blocs d'inférence convolutionnels.
Nous avons réalisé que nous devions paralléliser le
gemm (multiplication matricielle générale). Ce gemme, qui en EML, s'est avéré être monothread. En conséquence, nous avons dû écrire nous-mêmes le gemm multi-thread. L'idée est la suivante: une grande matrice est divisée en sous-blocs, puis il y a une multiplication de ces petites matrices. Nous avons écrit un gemm avec OpenMP, mais cela n'a pas fonctionné, des erreurs se sont écrasées. Nous avons pris un pool manuel de threads, la parallélisation a donné 0,33 seconde par image.
Ensuite, nous avons eu accès à distance à un serveur plus puissant avec
Elbrus 8C , à une vitesse augmentée à 0,2 seconde par image.
La vidéo suivante montre le travail du stand de démonstration avec reconnaissance faciale sur un ordinateur Elbrus 401-PC avec un processeur Elbrus 4C:
Conclusions et plans futurs
- Nous travaillons non seulement la reconnaissance faciale, mais en principe un cadre de réseau de neurones, afin que nous puissions collecter tous les détecteurs, classificateurs et les exécuter sur Elbrus.
- Nous avons assemblé un stand de démonstration avec Web-UI pour démontrer la reconnaissance faciale sur PuzzleLib.
- La reconnaissance faciale sur Elbrus est déjà assez rapide pour les tâches pratiques, alors vous pouvez l'accélérer si nécessaire.
- Vous pouvez travailler avec Elbrus. Nous avions l'habitude de travailler avec des processeurs exotiques - par exemple, avec des processeurs tenseur russes encore en développement, avec des cartes vidéo AMD et leurs logiciels. Tout n'est pas si bon et simple là-bas. Autrement dit, si nous prenons la bibliothèque MI Open d'AMD, il s'agit d'une bibliothèque très mal écrite dans laquelle toutes les combinaisons de pas, de rembourrages et de tailles de filtre ne mènent pas à des calculs réussis. La qualité des outils d'Elbrus est bonne - si vous avez un projet en Python, C ou C ++, l'exécuter sur Elbrus n'est pas difficile du tout.
- Il convient également de noter que le travail d'optimisation étape par étape dont nous avons parlé n'est pas des opérations spécifiques pour travailler dans Elbrus. Il s'agit d'opérations de processeur multicœur standard. À notre avis, c'est un bon signe que le processeur peut être utilisé comme avec un processeur régulier d'Intel / NVIDIA.
Plans:
- Elbrus ayant la particularité d'être un processeur VLIW, certaines optimisations spécifiques à Elbrus peuvent être effectuées.
- Effectuez une quantification (en travaillant avec int8 au lieu de float32), ce qui économise de la mémoire et augmente la vitesse. Par conséquent, dans ce cas, bien sûr, il peut y avoir une baisse de la qualité des calculs - mais ce n'est peut-être pas le cas. Nous avons remarqué les deux cas dans la pratique.
Nous prévoyons de mieux comprendre et d'explorer les capacités du processeur VLIW. En fait, pour l'instant, nous venons de faire confiance au compilateur en ce sens que si nous écrivons du bon code, le compilateur l'optimise bien, car il connaît les fonctionnalités d'Elbrus.
En général, c'était intéressant, on comprendra mieux. Cela n'a pas pris beaucoup de temps - toutes les opérations de portage ont pris au total une semaine.
En janvier 2020, nous prévoyons de mettre PuzzleLib en open source, nous en écrirons plus ici =)
Merci de votre attention!