Ce guide et les guides suivants vous guideront tout au long du processus de création d'une solution basée sur le projet Discovery.js . Notre objectif est de créer un inspecteur pour les dépendances NPM, c'est-à-dire une interface pour examiner la structure de node_modules .
Remarque: Discovery.js est à un stade précoce de développement, donc au fil du temps, quelque chose se simplifiera et deviendra plus utile. Si vous avez des idées pour améliorer quelque chose, écrivez-nous .
Annotation
Vous trouverez ci-dessous un aperçu des concepts clés de Discovery.js. Vous pouvez apprendre l'intégralité du code manuel dans le référentiel sur GitHub , ou vous pouvez essayer comment cela fonctionne en ligne .
Conditions initiales
Tout d'abord, nous devons choisir un projet à analyser. Il peut s'agir d'un projet fraîchement créé ou d'un projet existant, l'essentiel est qu'il contient node_modules (l'objet de notre analyse).
Tout d'abord, installez le package core discoveryjs et ses outils de console:
npm install @discoveryjs/discovery @discoveryjs/cli
Ensuite, lancez le serveur Discovery.js:
> npx discovery No config is used Models are not defined (model free mode is enabled) Init common routes ... OK Server listen on http://localhost:8123
Si vous ouvrez http://localhost:8123 dans le navigateur, vous pouvez voir ce qui suit:

Il s'agit d'un mode sans modèle, c'est-à-dire un mode lorsque rien n'est configuré. Mais maintenant, en utilisant le bouton "Charger les données", vous pouvez sélectionner n'importe quel fichier JSON, ou simplement le faire glisser sur la page et démarrer l'analyse.
Cependant, nous avons besoin de quelque chose de spécifique. En particulier, nous devons avoir une idée de la structure node_modules . Pour ce faire, ajoutez la configuration.
Ajouter une configuration
Comme vous l'avez peut-être remarqué, le message No config is used s'affichait au démarrage du serveur. Créons un fichier de configuration .discoveryrc.js avec le contenu suivant:
module.exports = { name: 'Node modules structure', data() { return { hello: 'world' }; } };
Remarque: si vous créez un fichier dans le répertoire de travail actuel (c'est-à-dire à la racine du projet), rien d'autre n'est requis. Sinon, vous devez transmettre le chemin d'accès au fichier de configuration à l'aide de l'option --config ou définir le chemin d'accès dans package.json :
{ ... "discovery": "path/to/discovery/config.js", ... }
Redémarrez le serveur pour que la configuration soit appliquée:
> npx discovery Load config from .discoveryrc.js Init single model default Define default routes ... OK Cache: DISABLED Init common routes ... OK Server listen on http://localhost:8123
Comme vous pouvez le voir, maintenant le fichier que nous avons créé est utilisé. Et le modèle par défaut que nous décrivons est appliqué (la découverte peut fonctionner dans le mode de nombreux modèles, nous parlerons de cette fonctionnalité dans les manuels suivants). Voyons ce qui a changé dans le navigateur:
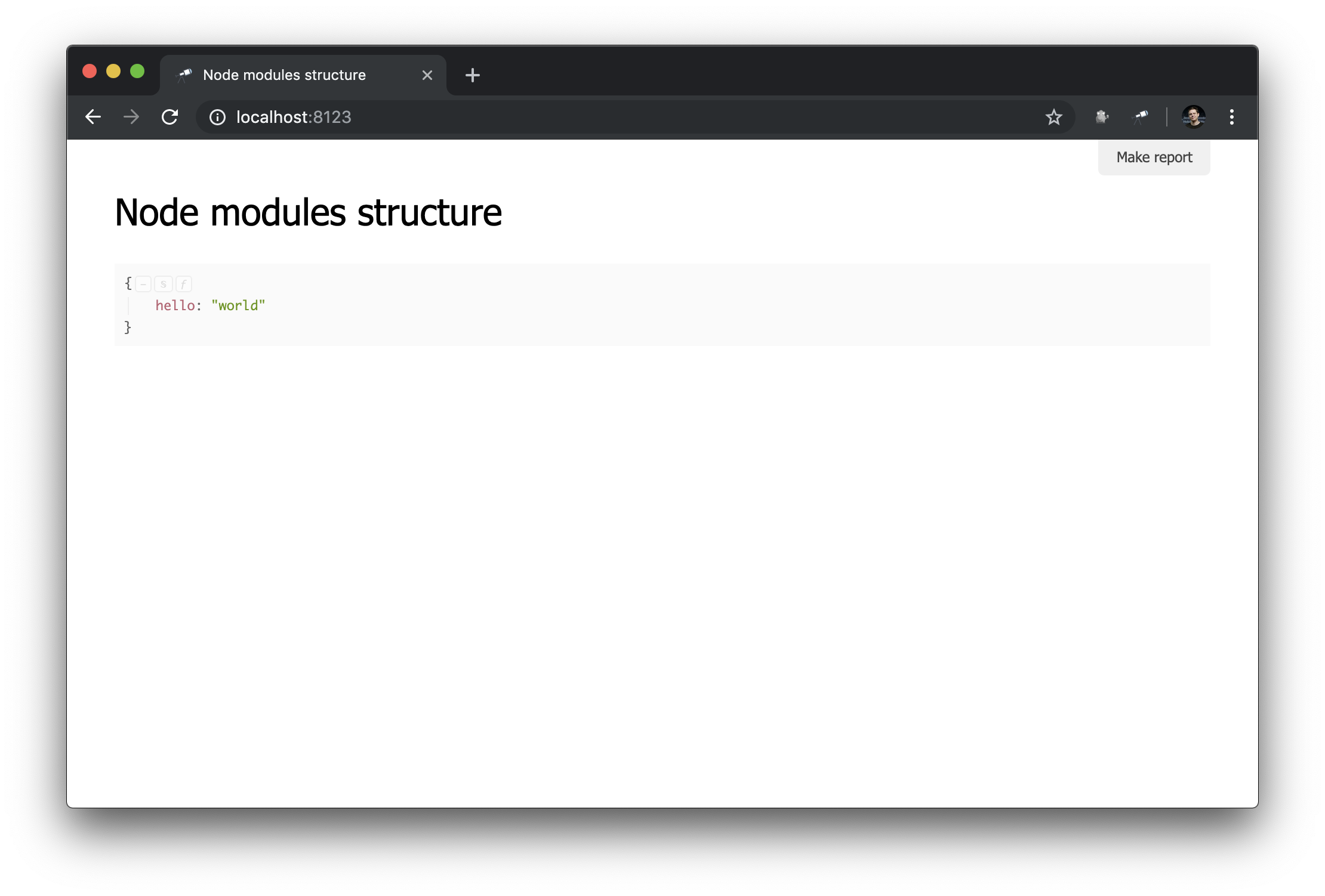
Que peut-on voir ici:
name utilisé comme titre de page;- le résultat de l'appel de la méthode de
data est affiché comme contenu principal de la page.
Remarque: la méthode de data doit renvoyer des données ou Promise, qui se résout en données.
Les paramètres de base sont définis, vous pouvez continuer.
Contexte
Regardons la page du rapport personnalisé (cliquez sur Make report ):
À première vue, ce n'est pas très différent de la page d'accueil ... Mais ici, vous pouvez tout changer! Par exemple, nous pouvons facilement recréer l'apparence de la page de démarrage:
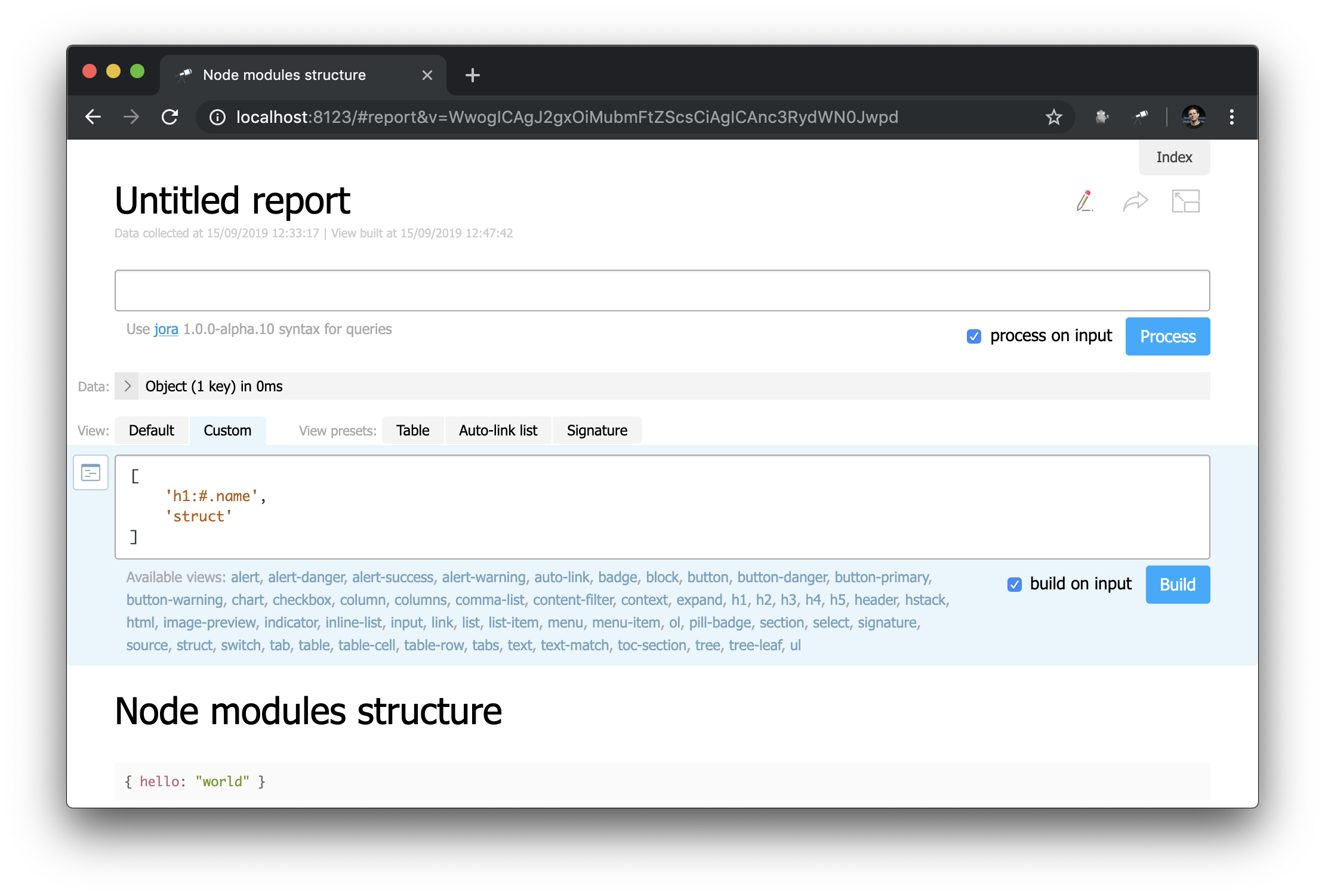
Remarquez comment l'en-tête est défini: "h1:#.name" . Il s'agit de l'en-tête de premier niveau avec le contenu de #.name , qui est une demande Jora . # Fait référence au contexte de la demande. Pour afficher son contenu, entrez simplement # dans l'éditeur de requête et utilisez l'affichage par défaut:
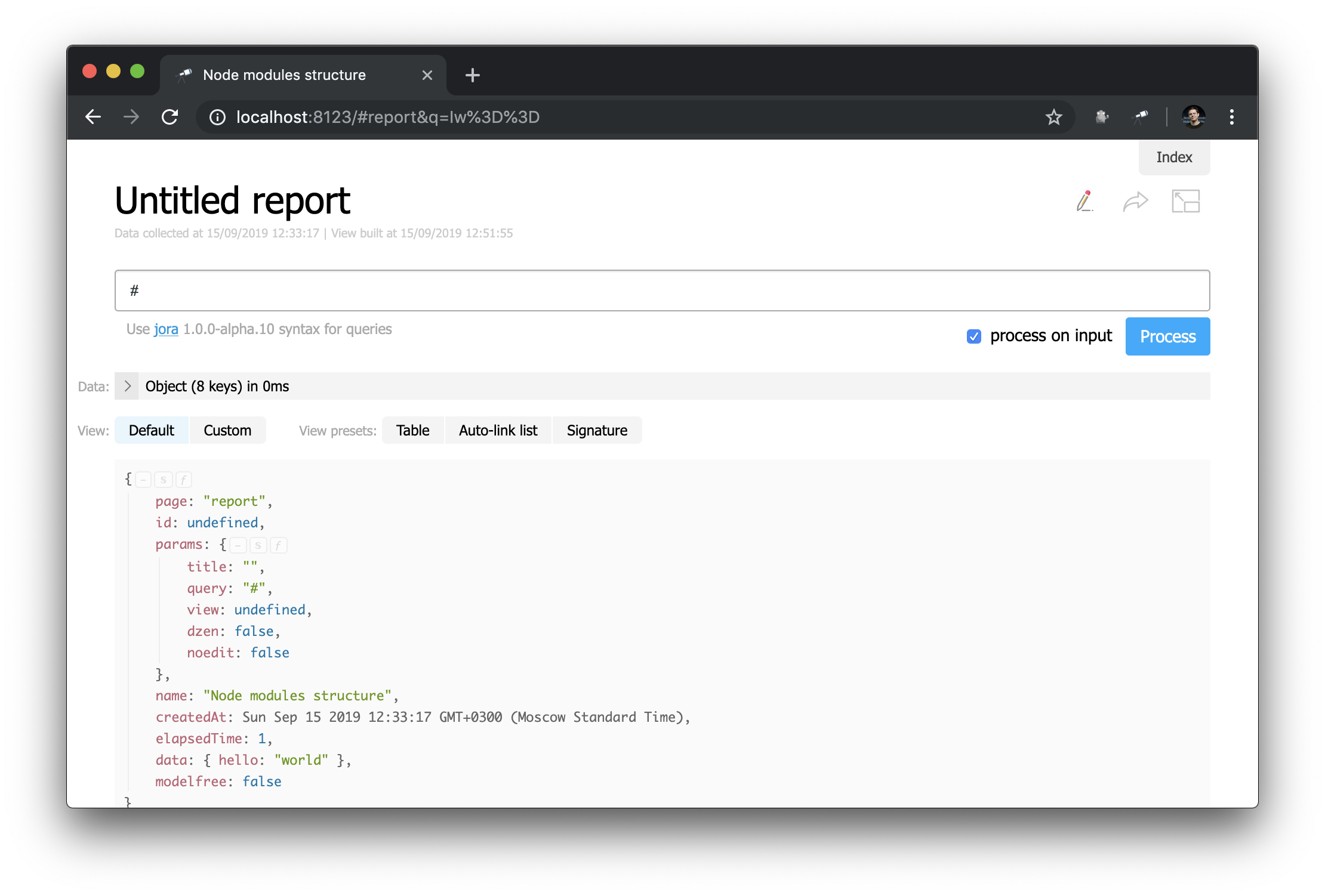
Vous savez maintenant comment obtenir l'ID de la page actuelle, ses paramètres et d'autres valeurs utiles.
Collecte de données
Maintenant, nous utilisons un stub dans le projet au lieu de vraies données, mais nous avons besoin de vraies données. Pour ce faire, créez un module et modifiez la valeur des data dans la configuration (au fait, après ces modifications, il n'est pas nécessaire de redémarrer le serveur):
module.exports = { name: 'Node modules structure', data: require('./collect-node-modules-data') };
Le contenu de collect-node-modules-data.js :
const path = require('path'); const scanFs = require('@discoveryjs/scan-fs'); module.exports = function() { const packages = []; return scanFs({ include: ['node_modules'], rules: [{ test: /\/package.json$/, extract: (file, content) => { const pkg = JSON.parse(content); if (pkg.name && pkg.version) { packages.push({ name: pkg.name, version: pkg.version, path: path.dirname(file.filename), dependencies: pkg.dependencies }); } } }] }).then(() => packages); };
J'ai utilisé le package @discoveryjs/scan-fs , qui simplifie l'analyse du système de fichiers. Un exemple d'utilisation du package est décrit dans son fichier Lisezmoi, j'ai pris cet exemple comme base et finalisé au besoin. Nous avons maintenant quelques informations sur le contenu de node_modules :
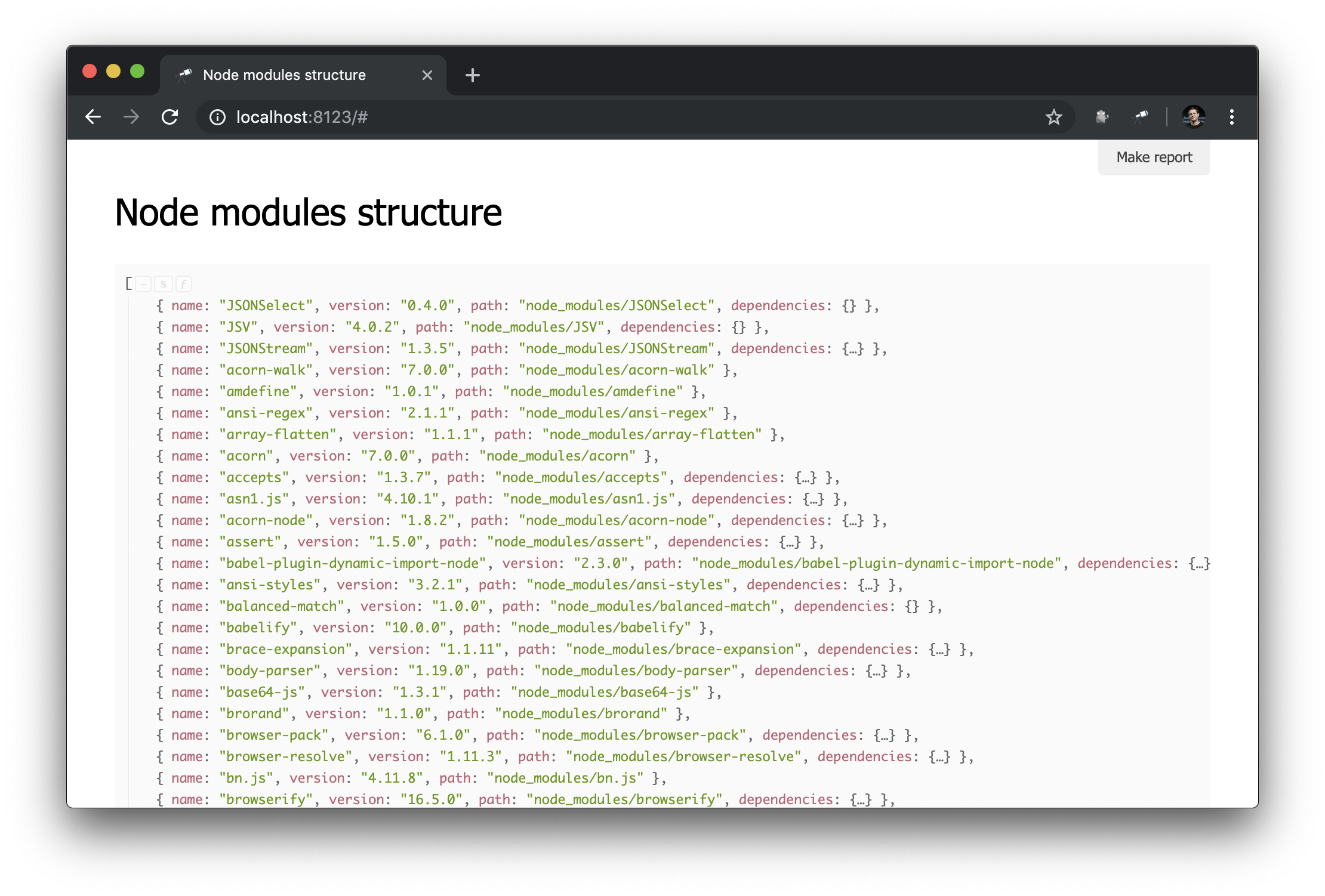
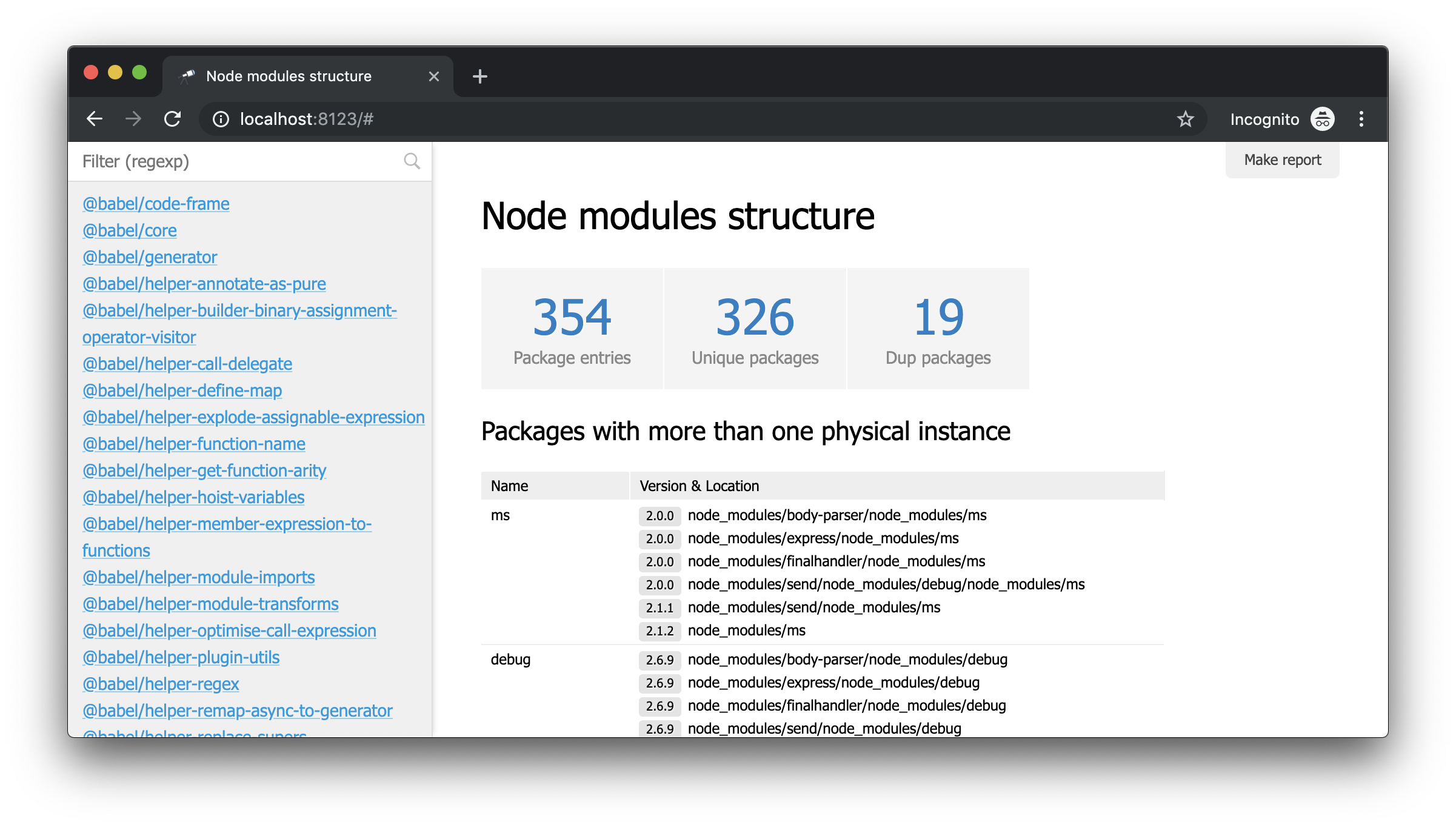
Ce dont vous avez besoin! Et malgré le fait qu'il s'agit d'un JSON ordinaire, nous pouvons déjà l'analyser et tirer des conclusions. Par exemple, en utilisant la fenêtre contextuelle de la structure de données, vous pouvez connaître le nombre de paquets et savoir combien d'entre eux ont plus d'une instance physique (en raison de la différence de versions ou de problèmes de déduplication).
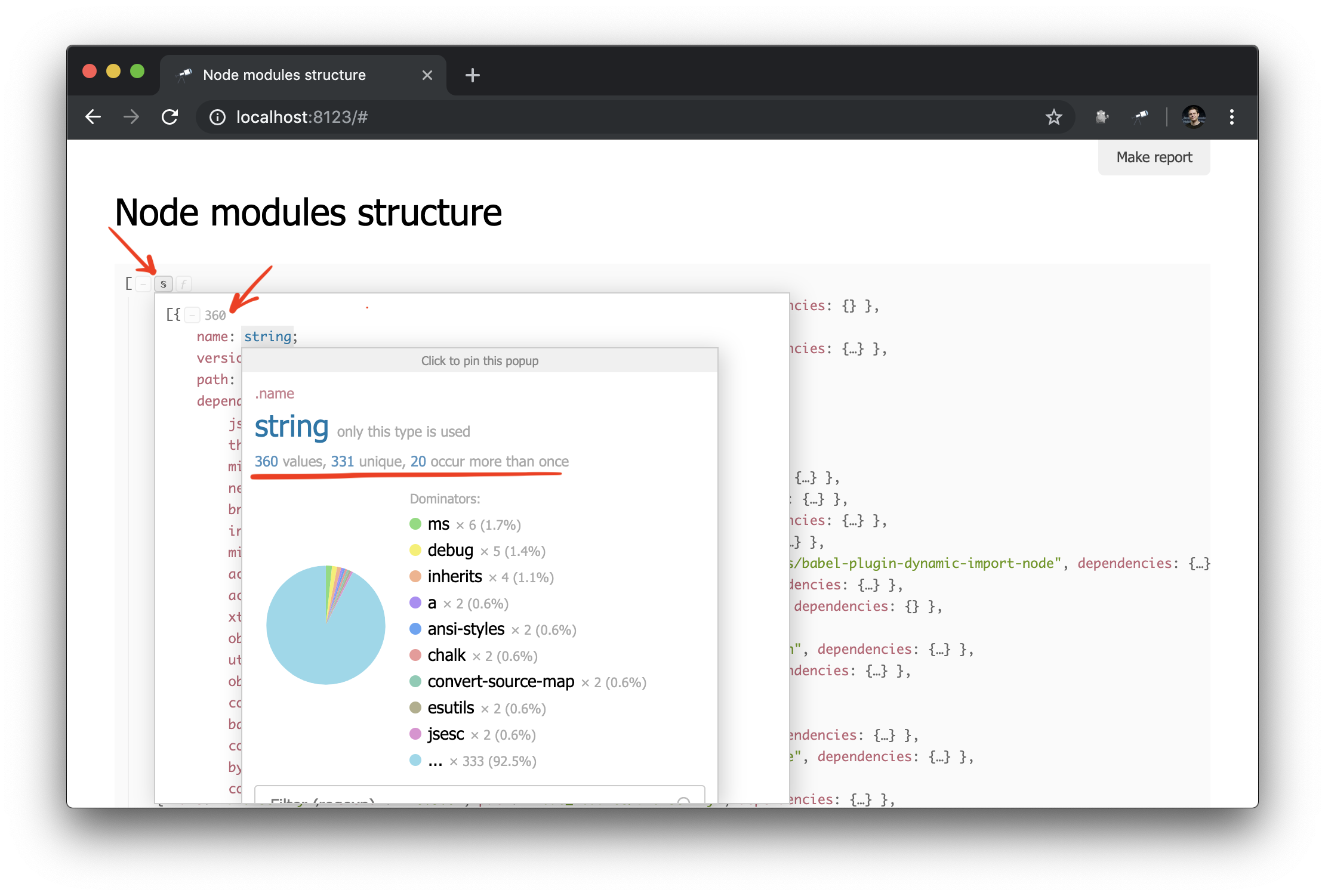
Malgré le fait que nous ayons déjà quelques données, nous avons besoin de plus de détails. Par exemple, il serait intéressant de savoir quelle instance physique résout chacune des dépendances déclarées d'un module particulier. Cependant, les travaux sur l'amélioration de l'extraction des données dépassent le cadre de ce guide. Par conséquent, nous allons le remplacer par le package @discoveryjs/node-modules (qui est également basé sur @discoveryjs/scan-fs ) pour récupérer les données et obtenir les détails nécessaires sur les packages. En conséquence, collect-node-modules-data.js grandement simplifié:
const fetchNodeModules = require('@discoveryjs/node-modules'); module.exports = function() { return fetchNodeModules(); };
Maintenant, les informations sur node_modules ressemblent à ceci:
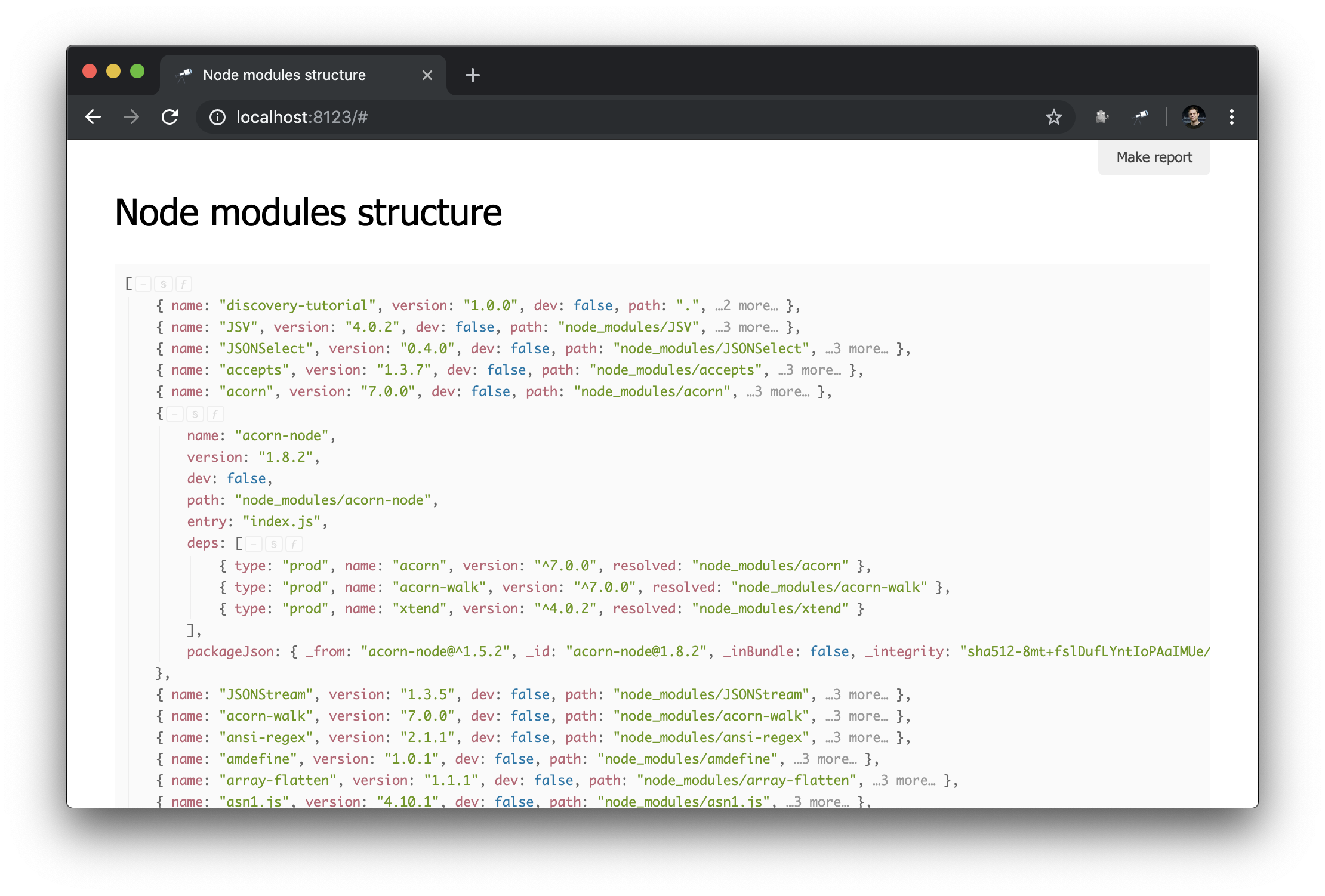
Script de préparation
Comme vous pouvez le voir, quelques - uns des objets décrivant les paquets contiennent deps - la liste des dépendances. Chaque dépendance a un champ resolved dont la valeur est une référence à une instance physique du package. Un tel lien est la valeur de path de l'un des packages, il est unique. Pour résoudre le lien vers le package, vous devez utiliser du code supplémentaire (par exemple, #.data.pick(<path=resolved>) ). Et bien sûr, il serait beaucoup plus pratique que ces liens soient déjà résolus en références d'objets.
Malheureusement, au stade de la collecte des données, nous ne pouvons pas résoudre les liens, car cela conduira à des connexions circulaires, ce qui créera le problème de transfert de ces données sous forme de JSON. Cependant, il existe une solution: il s'agit d'un script de prepare spécial. Il est défini dans la configuration et appelé chaque fois qu'une nouvelle donnée est affectée à l'instance Discovery. Commençons par la configuration:
module.exports = { ... prepare: __dirname + '/prepare.js',
Définissez prepare.js :
discovery.setPrepare(function(data) {
Dans ce module, nous avons défini la fonction prepare pour l'instance Discovery. Cette fonction est appelée à chaque fois avant d'appliquer des données à l'instance de découverte. C'est un bon endroit pour autoriser les valeurs dans les références d'objet:
discovery.setPrepare(function(data) { const packageIndex = data.reduce((map, pkg) => map.set(pkg.path, pkg), new Map()); data.forEach(pkg => pkg.deps.forEach(dep => dep.resolved = packageIndex.get(dep.resolved) ) ); });
Ici, nous avons créé un index de package dans lequel la clé est la valeur du path du package (unique). Ensuite, nous parcourons tous les packages et leurs dépendances, et dans les dépendances, nous remplaçons la valeur resolved par une référence à l'objet package. Résultat:
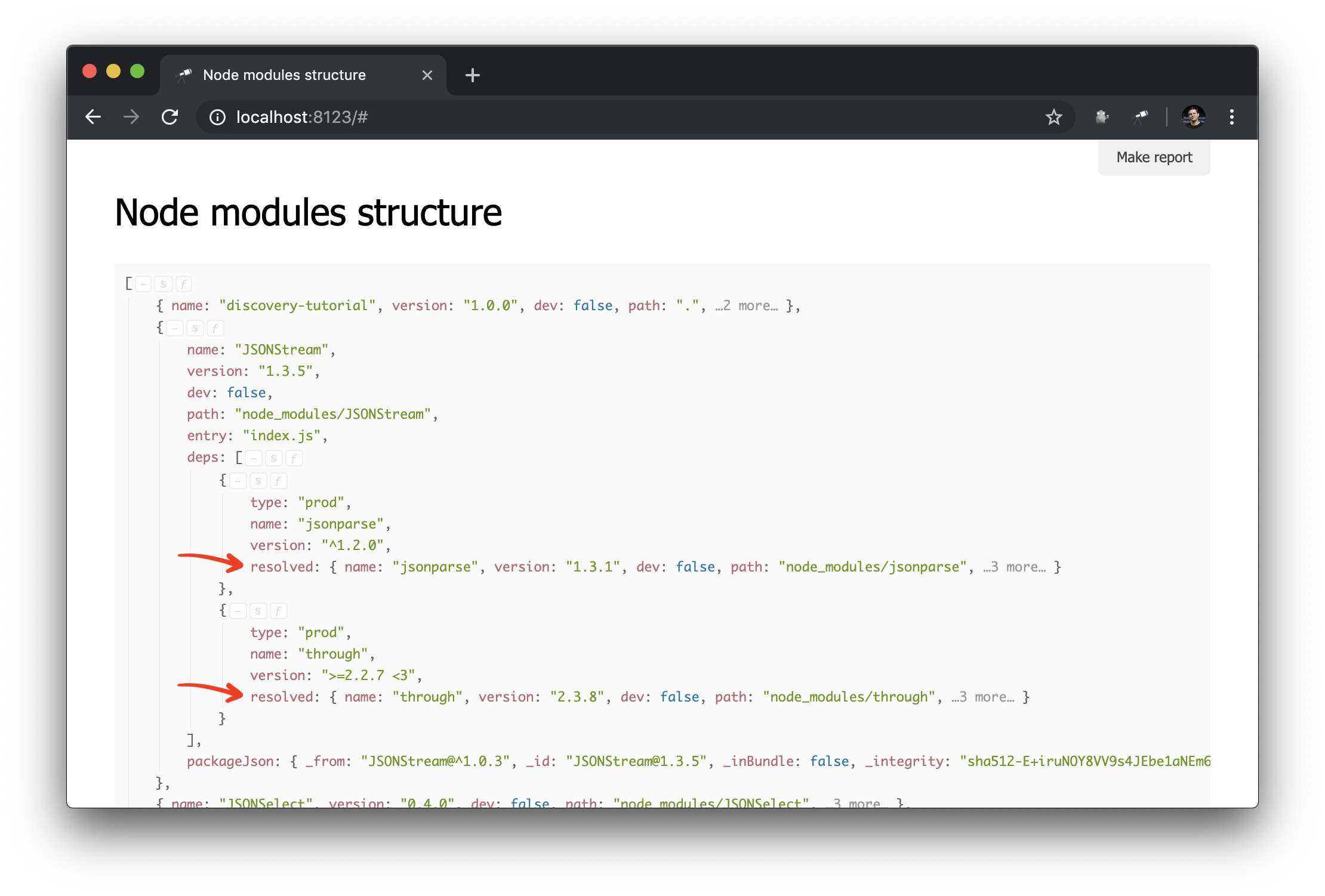
Maintenant, il est beaucoup plus facile de faire des requêtes de graphe de dépendance. Voici comment obtenir un cluster de dépendances (c'est-à-dire les dépendances, les dépendances de dépendances, etc.) pour un package spécifique:
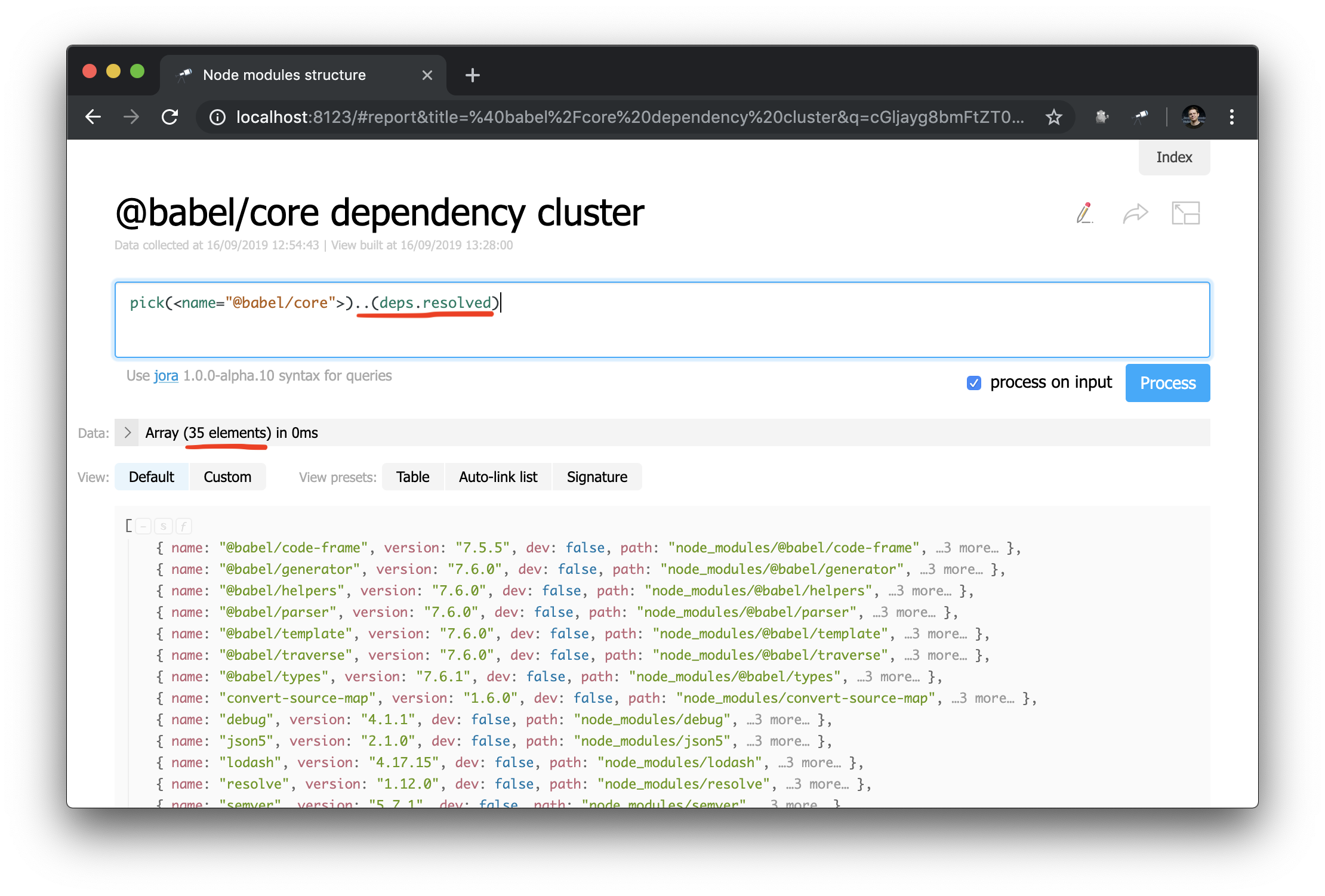
Une réussite inattendue: en étudiant les données lors de la rédaction du manuel, j'ai découvert un problème dans @discoveryjs/cli (en utilisant la requête .[deps.[not resolved]] ), qui avait une faute de frappe dans peerDependencies. Le problème immédiatement a été corrigé . Le cas est un bon exemple de la façon dont ces outils aident.
Peut-être que le moment est venu de montrer sur la page d'accueil plusieurs numéros et packages avec des prises.
Personnaliser la page de démarrage
Tout d'abord, nous devons créer un module de page, par exemple, pages/default.js . Nous utilisons default , car il s'agit de l'identifiant de la page de démarrage, que nous pouvons remplacer (dans Discovery.js, vous pouvez remplacer beaucoup). Commençons par quelque chose de simple, par exemple:
discovery.page.define('default', [ 'h1:#.name', 'text:"Hello world!"' ]);
Maintenant, dans la configuration, vous devez connecter le module de page:
module.exports = { name: 'Node modules structure', data: require('./collect-node-modules-data'), view: { assets: [ 'pages/default.js'
Vérifiez dans le navigateur:
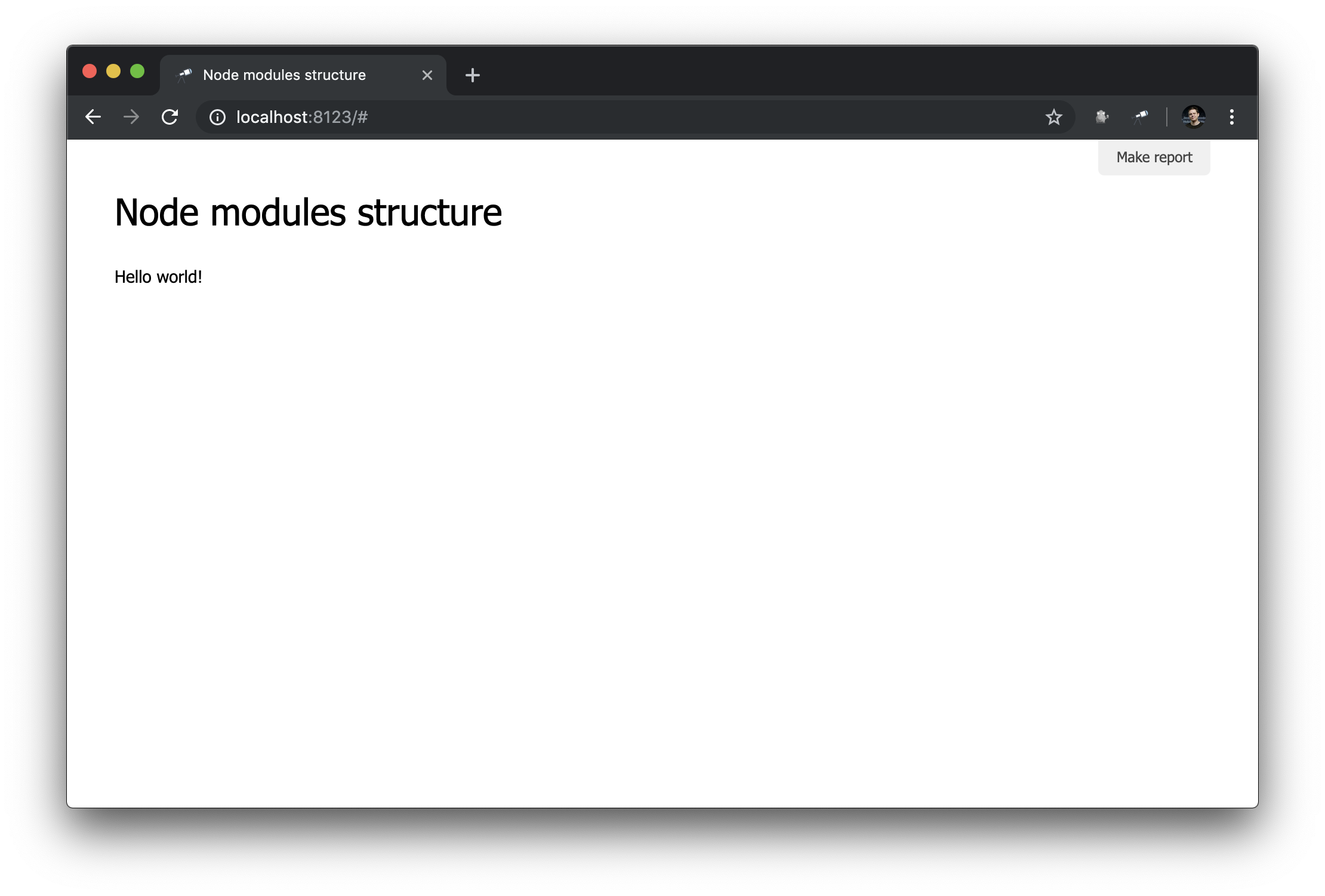
Ça marche!
Maintenant, prenons quelques compteurs. Pour ce faire, modifiez pages/default.js :
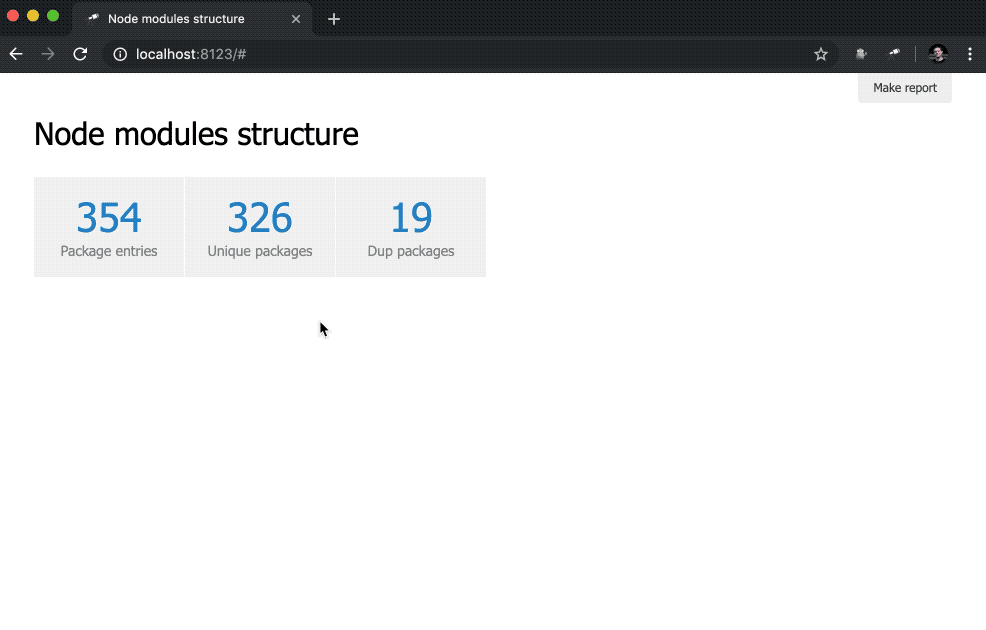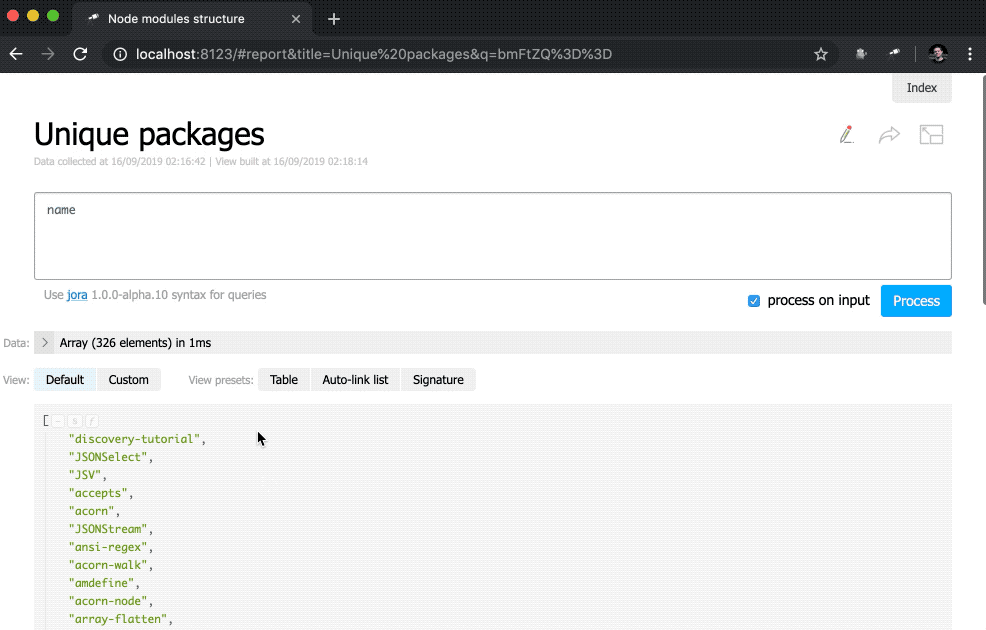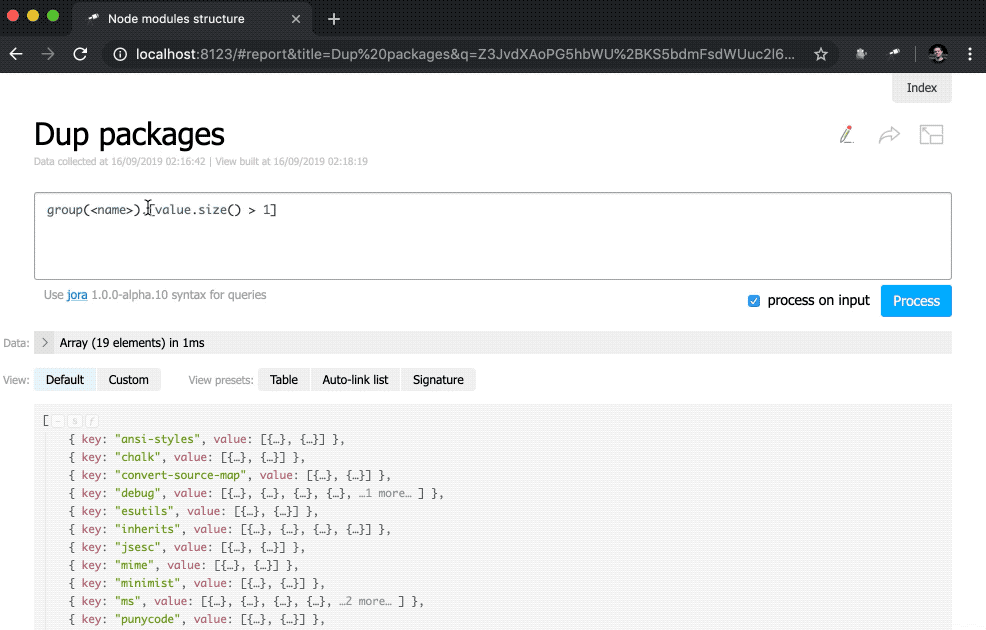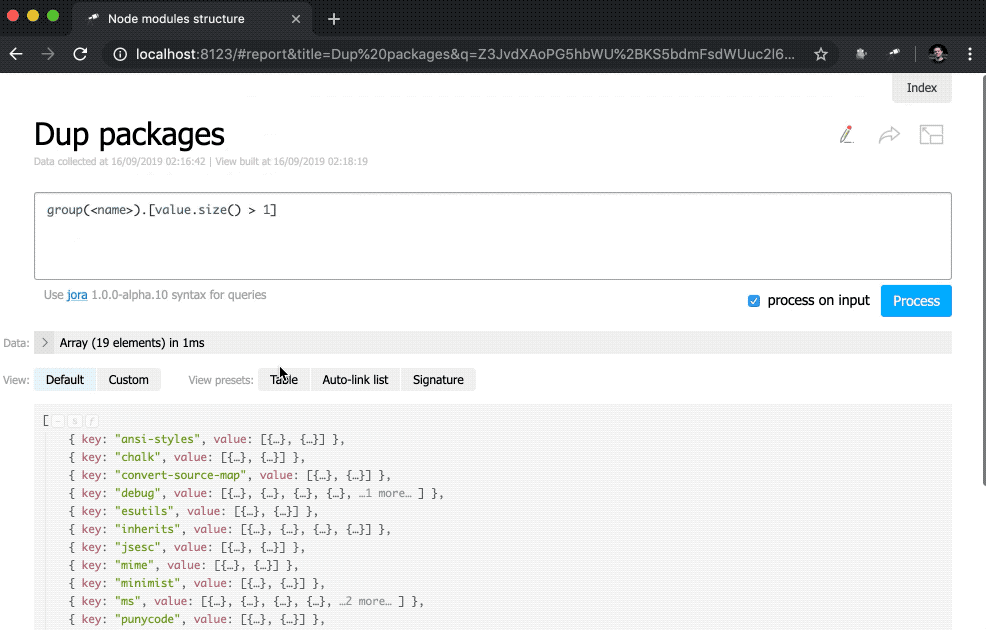
discovery.page.define('default', [ 'h1:#.name', { view: 'inline-list', item: 'indicator', data: `[ { label: 'Package entries', value: size() }, { label: 'Unique packages', value: name.size() }, { label: 'Dup packages', value: group(<name>).[value.size() > 1].size() } ]` } ]);
Nous définissons ici une liste en ligne d'indicateurs. La valeur des data est une requête Jora qui crée un tableau d'enregistrements. La liste des packages (racine des données) est utilisée comme base pour les requêtes, nous obtenons donc la longueur de la liste ( size() ), le nombre de noms de packages uniques ( name.size() ) et le nombre de noms de packages qui ont des doublons ( group(<name>).[value.size() > 1].size() ).
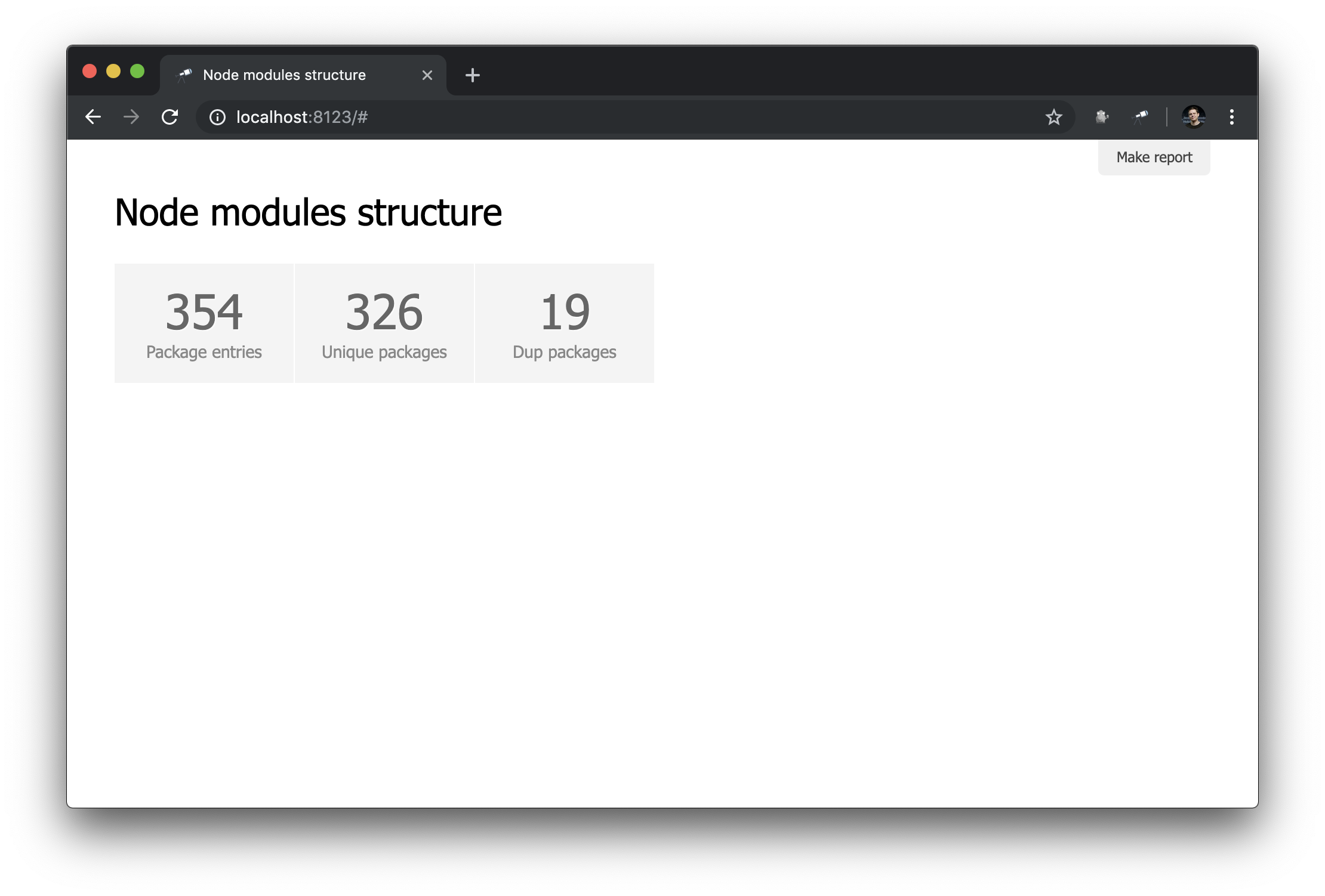
Pas mal. Néanmoins, il serait préférable d'avoir, en plus des numéros, des liens vers les échantillons correspondants:
discovery.page.define('default', [ 'h1:#.name', { view: 'inline-list', data: [ { label: 'Package entries', value: '' }, { label: 'Unique packages', value: 'name' }, { label: 'Dup packages', value: 'group(<name>).[value.size() > 1]' } ], item: `indicator:{ label, value: value.query(#.data, #).size(), href: pageLink('report', { query: value, title: label }) }` } ]);
Tout d'abord, nous avons changé la valeur des data , maintenant c'est un tableau régulier avec quelques objets. En outre, la méthode size() a été supprimée des demandes de valeur.
De plus, une sous-requête a été ajoutée à la vue des indicator . Ces types de requêtes créent un nouvel objet pour chaque élément dans lequel la value et le href sont calculés. Pour value , une requête est exécutée à l'aide de la méthode query() , à laquelle les données sont transférées du contexte, puis la méthode size() est appliquée au résultat de la requête. Pour href , la méthode pageLink() est utilisée, ce qui génère un lien vers la page de rapport avec une demande et un en-tête spécifiques. Après tous ces changements, les indicateurs sont devenus cliquables (notez que leurs valeurs sont devenues bleues) et plus fonctionnels.
Pour rendre la page de démarrage plus utile, ajoutez un tableau avec des packages contenant des doublons.
discovery.page.define('default', [
Le tableau utilise les mêmes données que l'indicateur des Dup packages . La liste des packages a été triée par taille de groupe dans l'ordre inverse. Les autres paramètres sont liés aux colonnes (au fait, ils n'ont généralement pas besoin d'être configurés). Pour la colonne Version & Location , nous avons défini une liste imbriquée (triée par version), dans laquelle chaque élément est une paire du numéro de version et du chemin d'accès à l'instance.
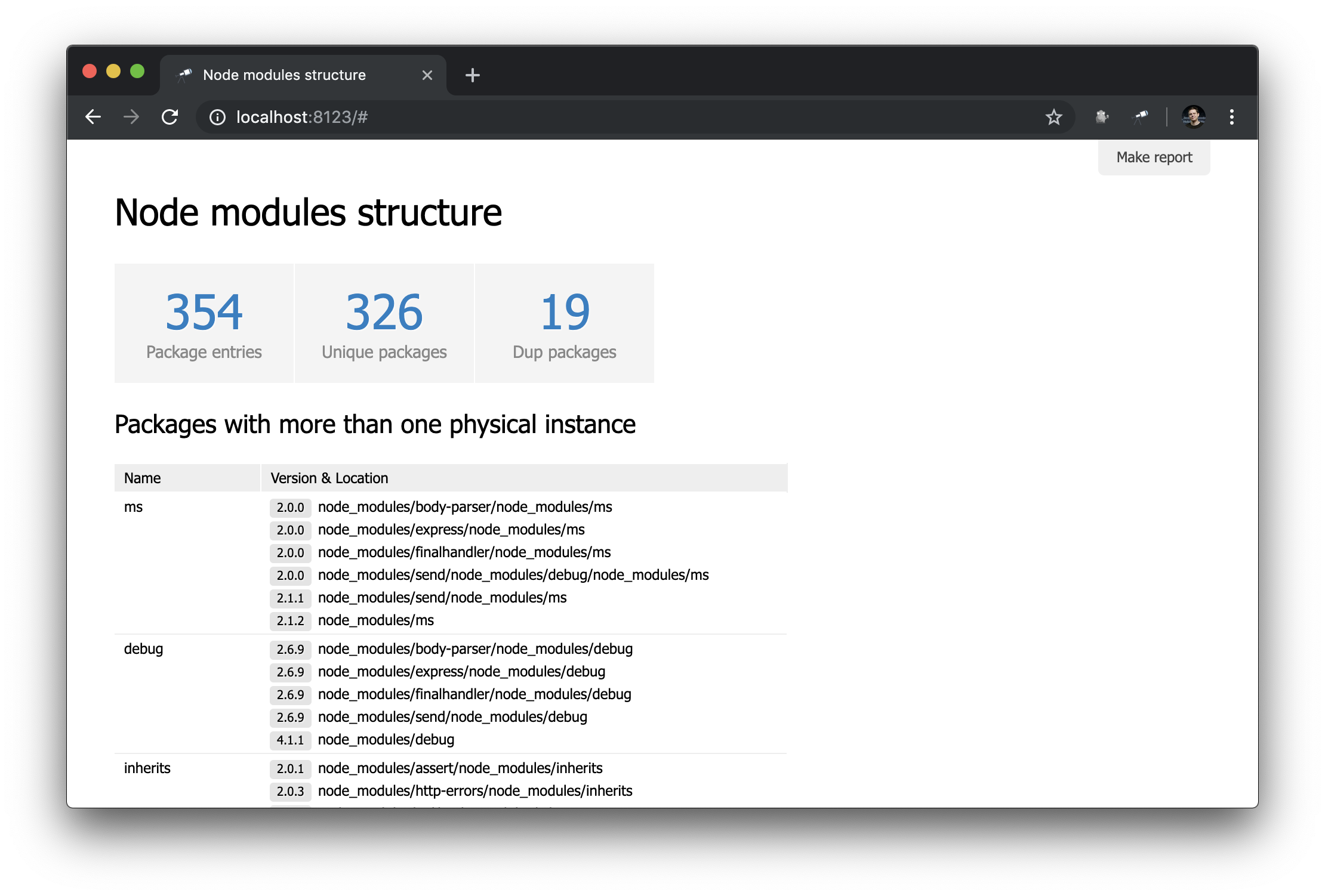
Page Package
Maintenant, nous n'avons qu'un aperçu général des packages. Mais il serait utile d'avoir une page avec des détails sur un paquet particulier. Pour ce faire, créez un nouveau module pages/package.js et définissez une nouvelle page:
discovery.page.define('package', { view: 'context', data: `{ name: #.id, instances: .[name = #.id] }`, content: [ 'h1:name', 'table:instances' ] });
Dans ce module, nous avons défini la page avec le package identifiant. Le composant de context été utilisé comme représentation initiale. Il s'agit d'un composant non visuel qui vous aide à définir des données pour les mappages imbriqués. Notez que nous avons utilisé #.id pour obtenir le nom du package, qui est récupéré à partir d'une URL comme celle-ci http://localhost:8123/#package:{id} .
N'oubliez pas d'inclure le nouveau module dans la configuration:
module.exports = { ... view: { assets: [ 'pages/default.js', 'pages/package.js'
Résultat dans le navigateur:
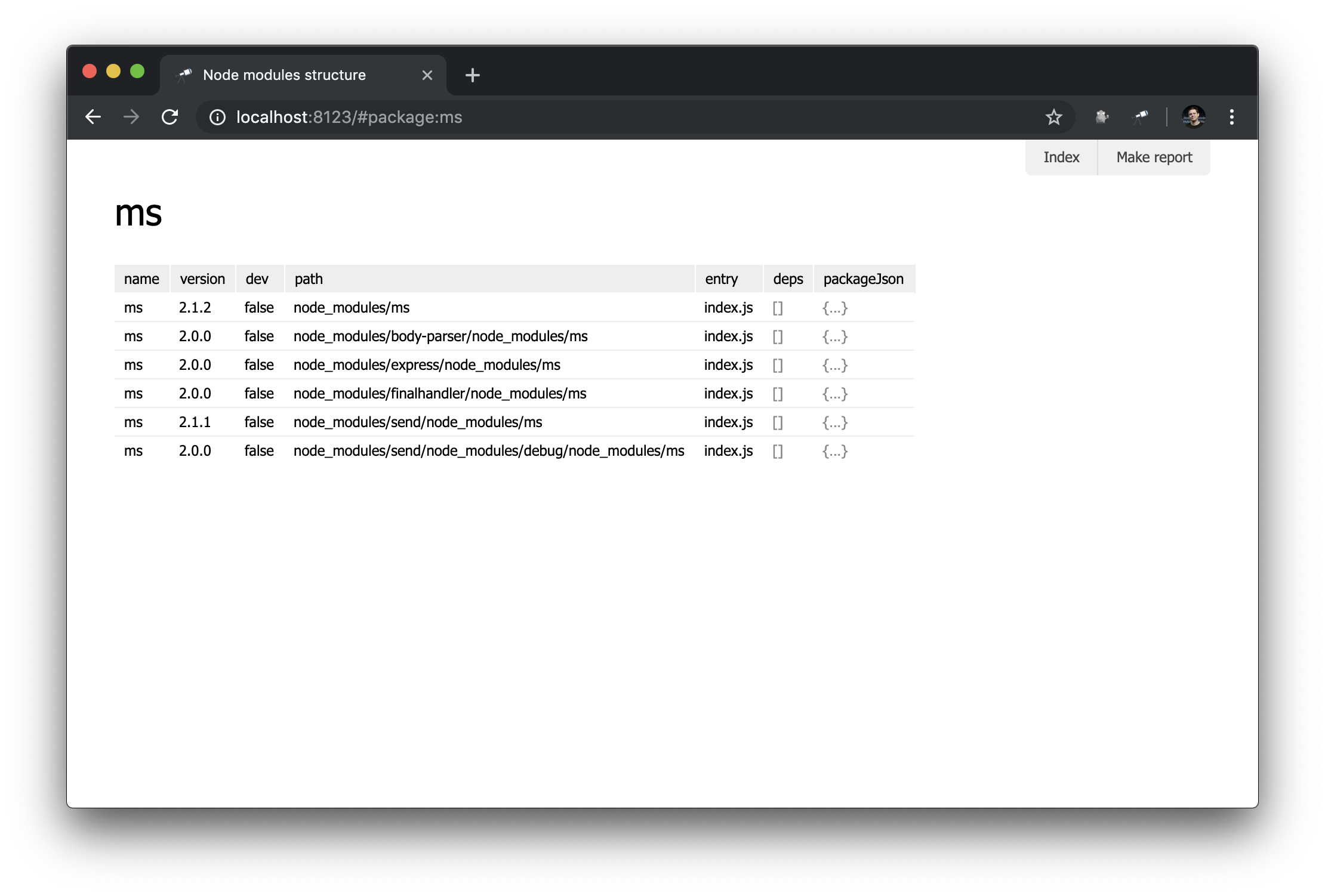
Pas trop impressionnant, mais pour l'instant. Nous créerons des mappages plus complexes dans les manuels suivants.
Panneau latéral
Comme nous avons déjà une page de package, il serait bien d'avoir une liste de tous les packages. Pour ce faire, vous pouvez définir une vue spéciale - sidebar , qui s'affiche si elle est définie (non définie par défaut). Créez un nouveau module views/sidebar.js :
discovery.view.define('sidebar', { view: 'list', data: 'name.sort()', item: 'link:{ text: $, href: pageLink("package") }' });
Nous avons maintenant une liste de tous les packages:
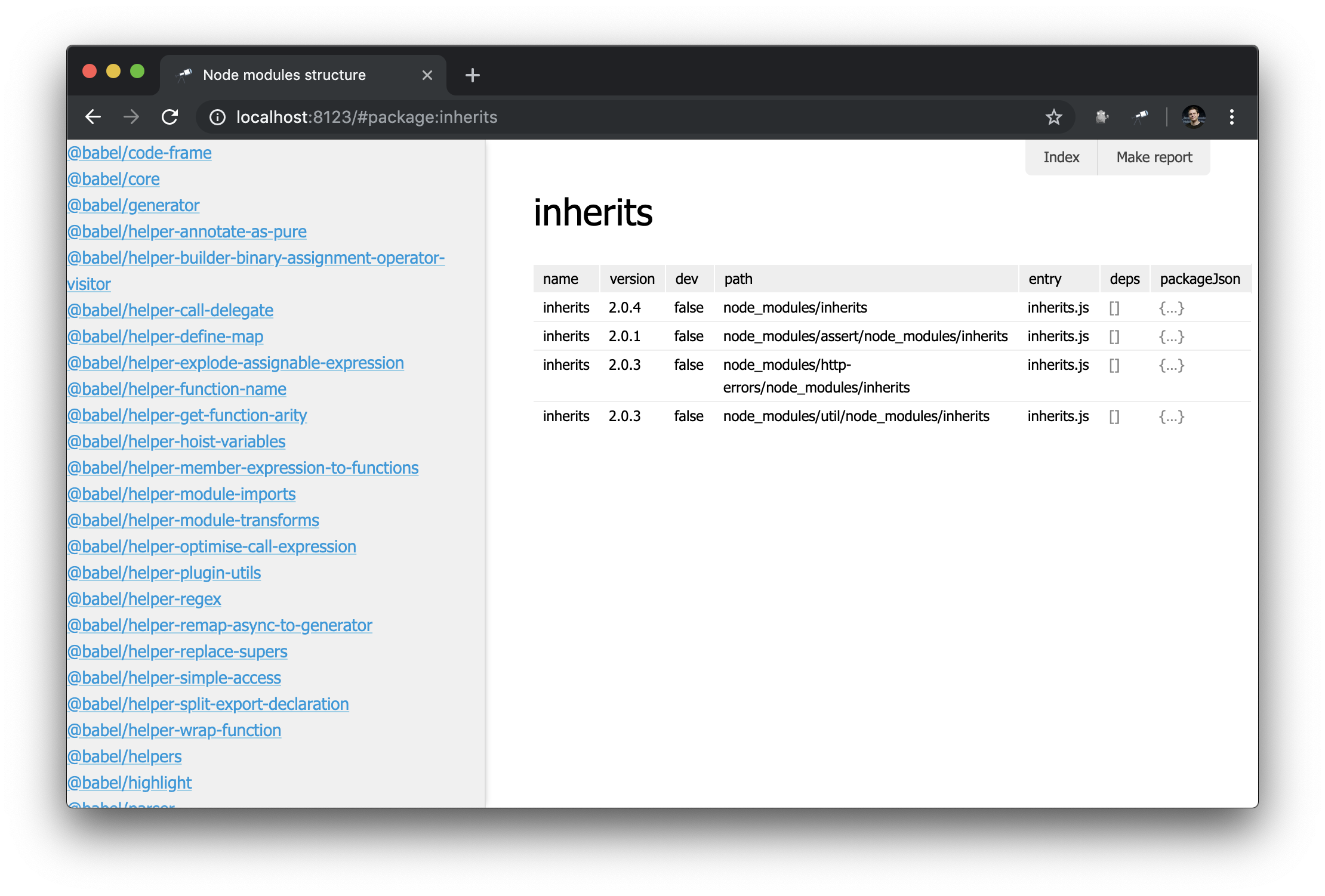
Ça a l'air bien. Mais avec un filtre, ce serait encore mieux. Nous élargissons la définition de la sidebar :
discovery.view.define('sidebar', { view: 'content-filter', content: { view: 'list', data: 'name.[no #.filter or $~=#.filter].sort()', item: { view: 'link', data: '{ text: $, href: pageLink("package"), match: #.filter }', content: 'text-match' } } });
Ici, nous avons enveloppé la liste dans un composant de content-filter qui convertit la valeur d'entrée dans le champ d'entrée en expressions régulières (ou null si le champ est vide) et l'enregistre en tant que valeur de filter dans le contexte (le nom peut être modifié avec l'option de name ). De plus, pour filtrer les données de la liste, nous avons utilisé #.filter . Enfin, nous avons appliqué le mappage de liens pour mettre en évidence les parties correspondantes avec text-match . Résultat:

Si vous n'aimez pas la conception par défaut, vous pouvez personnaliser les styles à votre guise. Disons que vous souhaitez modifier la largeur de la barre latérale, pour cela, vous devez créer un fichier de style (par exemple, views/sidebar.css ):
.discovery-sidebar { width: 300px; }
Et ajoutez un lien vers ce fichier dans la configuration, ainsi que vers les modules JavaScript:
module.exports = { ... view: { assets: [ ... 'views/sidebar.css',
Liens automatiques
Le dernier chapitre de ce guide est consacré aux liens. Plus tôt, en utilisant la méthode pageLink() , nous avons créé un lien vers la page du package. Mais en plus du lien, vous devez également définir le texte du lien. Mais comment pourrions-nous faciliter les choses?
Pour simplifier le travail des liens, nous devons définir une règle pour générer des liens. Il est préférable de le faire dans le script prepare :
discovery.setPrepare(function(data) { ... const packageIndex = data.reduce( (map, item) => map .set(item, item)
Nous avons ajouté une nouvelle carte (index) des packages et l'avons utilisée pour le résolveur d'entité. Le résolveur d'entité essaie, si possible, de convertir la valeur qui lui est transmise en un descripteur d'entité. Le descripteur contient:
type - type d'entitéid - une référence unique à une instance d'entité utilisée dans les liens comme IDname - utilisé comme texte de lien
Enfin, vous devez affecter ce type à une page spécifique (le lien doit mener quelque part, non?).
discovery.page.define('package', { ... }, { resolveLink: 'package'
La première conséquence de ces modifications est que certaines valeurs de la vue struct sont désormais marquées par un lien vers la page du package:
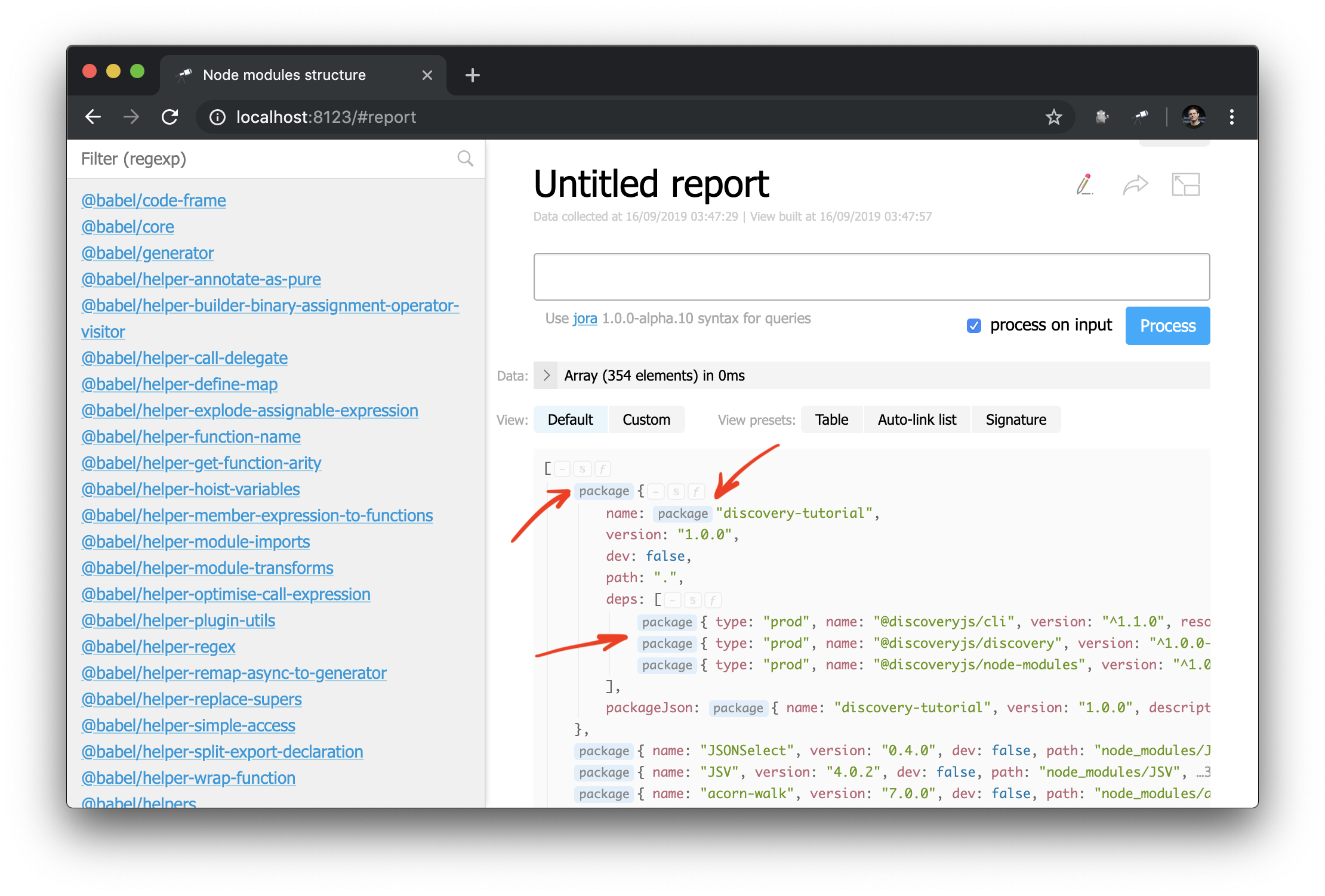
Et maintenant, vous pouvez également appliquer le composant de auto-link à un nom d'objet ou de package:
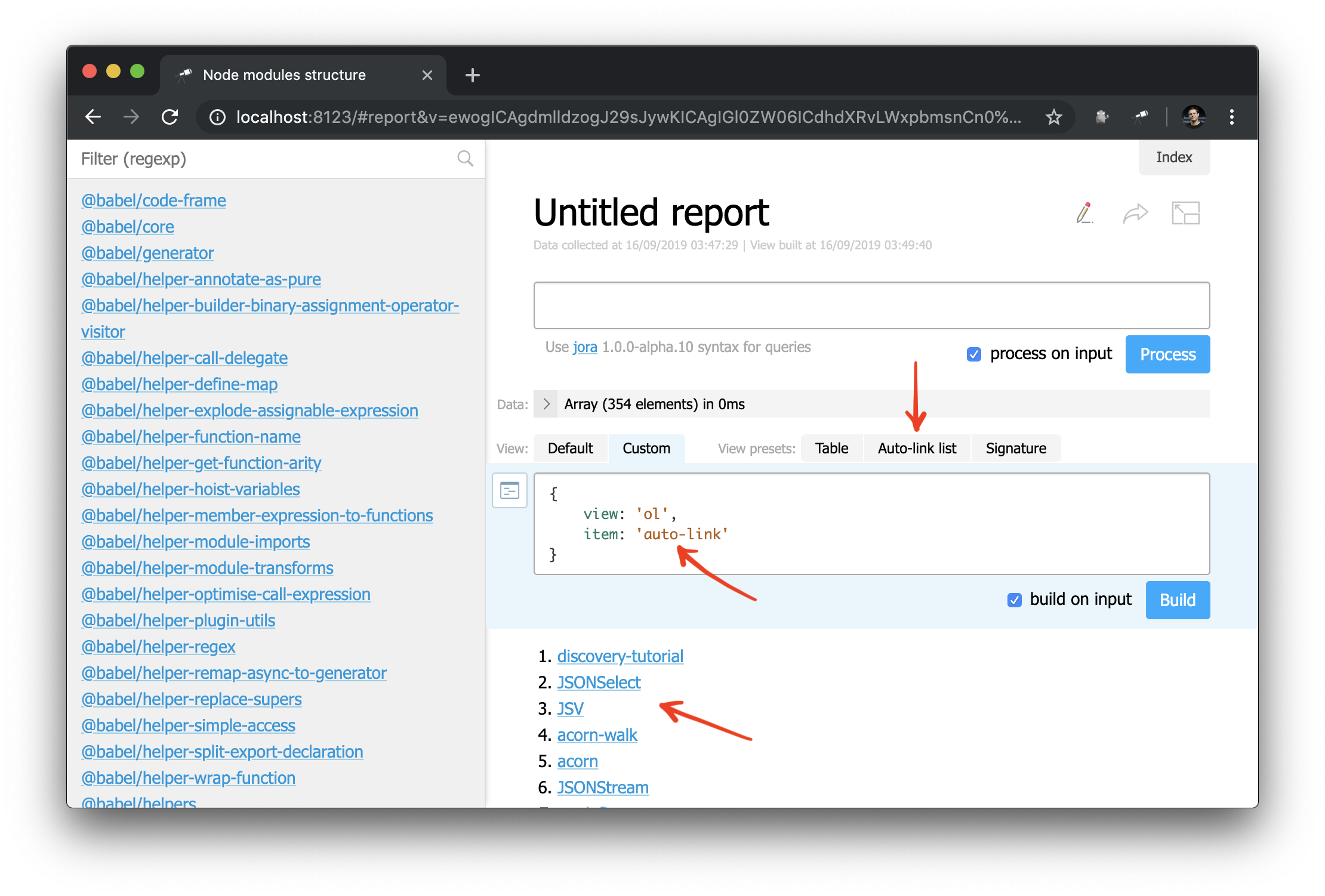
Et, à titre d'exemple, vous pouvez retravailler légèrement la barre latérale:
Conclusion
Vous avez maintenant une compréhension de base des concepts clés de Discovery.js . Dans les guides suivants, nous examinerons de plus près les sujets traités.
Vous pouvez voir l'intégralité du code source du guide dans le référentiel sur GitHub ou essayer son fonctionnement en ligne .
Suivez @js_discovery sur Twitter pour rester au courant des dernières nouvelles!