Nous voulons décrire en termes généraux les premières réalisations de l'apprentissage en profondeur dans l'animation de personnages pour notre programme
Cascadeur .
En travaillant sur
Shadow Fight 3 , nous avons accumulé beaucoup d'animation de combat - environ 1100 mouvements avec une durée moyenne d'environ 4 secondes. Il nous a semblé il y a longtemps que cela pourrait être un bon ensemble de données pour former une sorte de réseau neuronal.
Une fois que nous avons remarqué que lorsque les animateurs réalisent les premières esquisses d’idées sur papier, il leur suffit de dessiner un homme littéralement bâton pour imaginer la pose du personnage. Nous avons pensé qu'un animateur expérimenté pouvant bien poser une pose selon un schéma simple, il est fort possible que le réseau neuronal puisse la gérer. De cette observation, une idée simple est née: prenons seulement 6 points clés de chaque pose - poignets, chevilles, bassin et base du cou. Si le réseau neuronal ne connaît que les positions de ces points, peut-il prédire le reste de la pose - la position des 37 points restants du personnage?
Comment organiser le processus d'apprentissage, c'était clair dès le début: à l'entrée, le réseau reçoit les positions de 6 points d'une pose spécifique, à la sortie il donne les positions des 37 points restants, et nous les comparons avec les positions qui étaient dans la position initiale. Dans la fonction d'évaluation, vous pouvez utiliser la méthode des moindres carrés pour les distances entre les positions prévues des points et la source.
Pour l'ensemble de données d'entraînement, nous avons eu tous les mouvements des personnages de Shadow Fight 3. Nous avons pris des poses de chaque image, et nous avons obtenu environ 115 000 poses. Mais cet ensemble était spécifique - le personnage regardait presque toujours le long de l'axe X, et la jambe gauche était toujours devant au début du mouvement. Pour résoudre ce problème, nous avons artificiellement élargi l'ensemble de données en générant des poses en miroir et en faisant également tourner aléatoirement chaque pose dans l'espace. Cela nous a également permis d'augmenter l'ensemble de données à deux millions de poses. Nous avons utilisé 95% de notre ensemble de données pour la formation du réseau et 5% pour le paramétrage et les tests.
Nous avons pris une architecture de réseau neuronal assez simple - un réseau à cinq couches entièrement connecté avec une fonction d'activation et une méthode d'initialisation des
réseaux de neurones auto-normalisants . Sur la dernière couche, l'activation n'est pas utilisée. Ayant 3 coordonnées pour chaque nœud, nous obtenons une couche d'entrée de 6 * 3 éléments et une couche de sortie de 37 * 3 éléments. Nous avons recherché l'architecture optimale pour les couches cachées et opté pour une architecture à cinq couches avec le nombre de neurones de 300, 400, 300, 200 sur chaque couche cachée, cependant, les réseaux avec moins de couches cachées ont également produit de bons résultats.
La régularisation L2 des paramètres réseau a également été très utile, elle a rendu les prévisions plus fluides et plus continues.
Un réseau de neurones avec de tels paramètres prédit la position des points avec une erreur moyenne de 3,5 cm. C'est une erreur très élevée, mais les spécificités du problème doivent être prises en compte. Pour un ensemble de valeurs d'entrée, il peut y avoir de nombreuses valeurs de sortie possibles. Par conséquent, le réseau neuronal a finalement appris à émettre les prédictions moyennes les plus probables. Cependant, lorsque le nombre de points d'entrée est passé à 16, l'erreur a diminué de moitié, ce qui en pratique a donné une prédiction très précise de la pose.
Mais en même temps, le réseau neuronal ne pouvait pas donner une pose complètement correcte, préservant la longueur de tous les os et les articulations correctes. Par conséquent, nous lançons également un processus d'optimisation qui aligne tous les corps solides et les articulations de notre modèle physique.
En pratique, les résultats ont été assez convaincants - vous pouvez les voir dans notre vidéo. Mais il y a aussi une spécificité du fait que l'ensemble de données d'entraînement est des animations de combat issues d'un jeu de combat avec des armes. Par exemple, un personnage semble supposer qu'il se tourne avec une épaule vers l'ennemi, comme dans une position de combat, et tourne en conséquence ses pieds et sa tête. Et lorsque vous étirez sa main, la brosse ne tourne pas comme si elle était frappée avec un poing, mais comme lorsqu'elle est frappée par une épée.
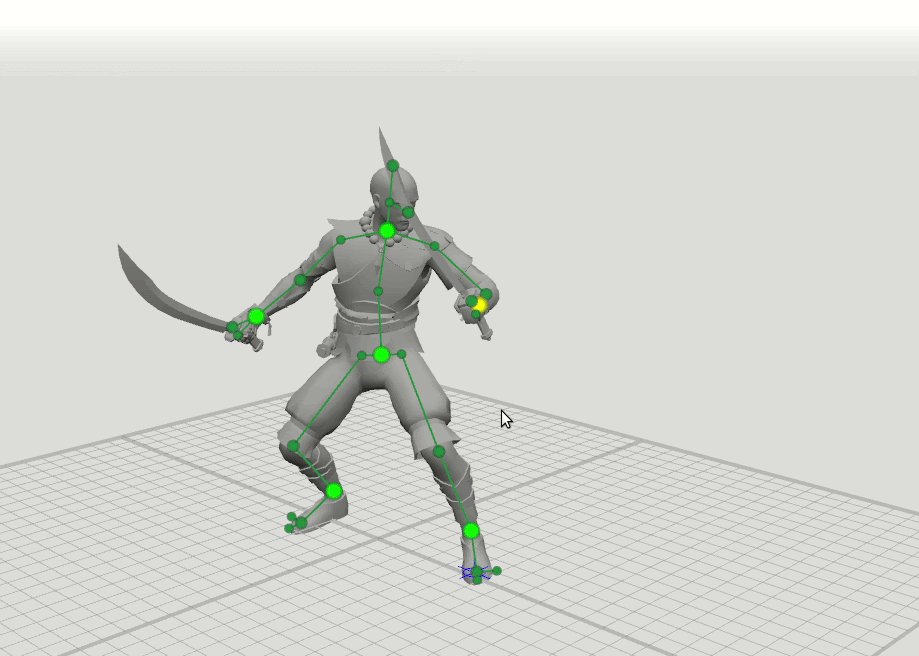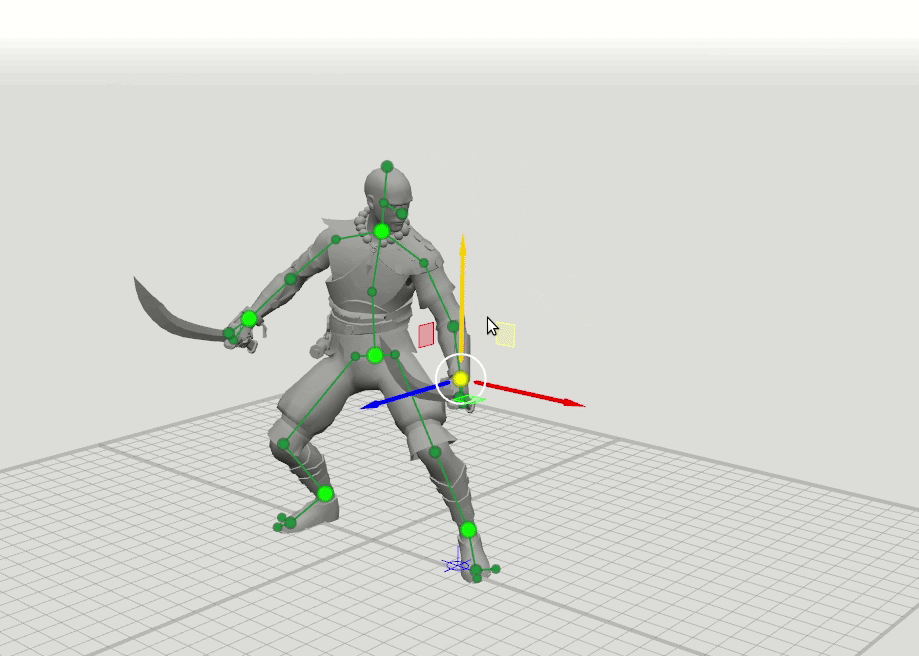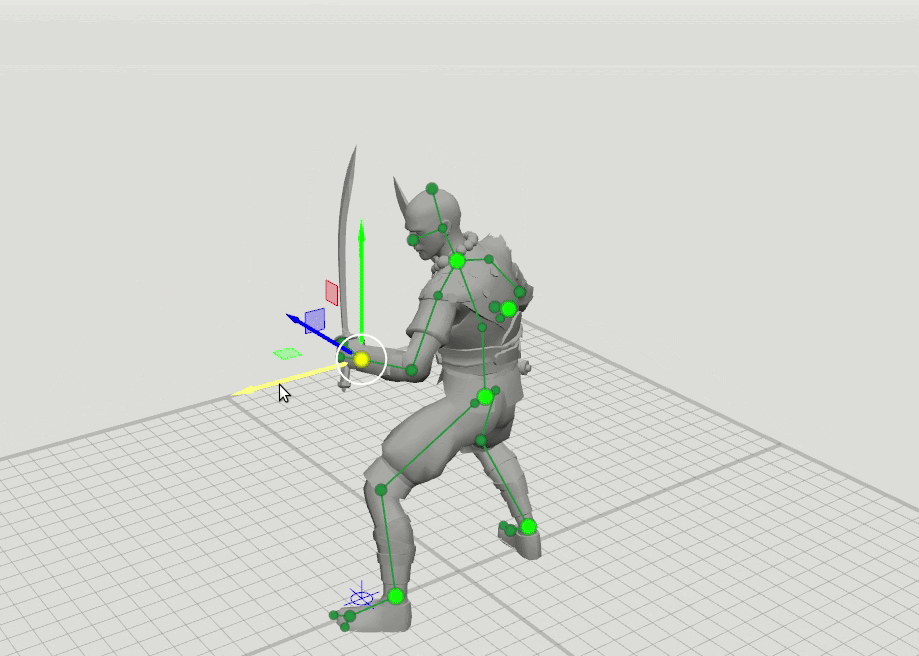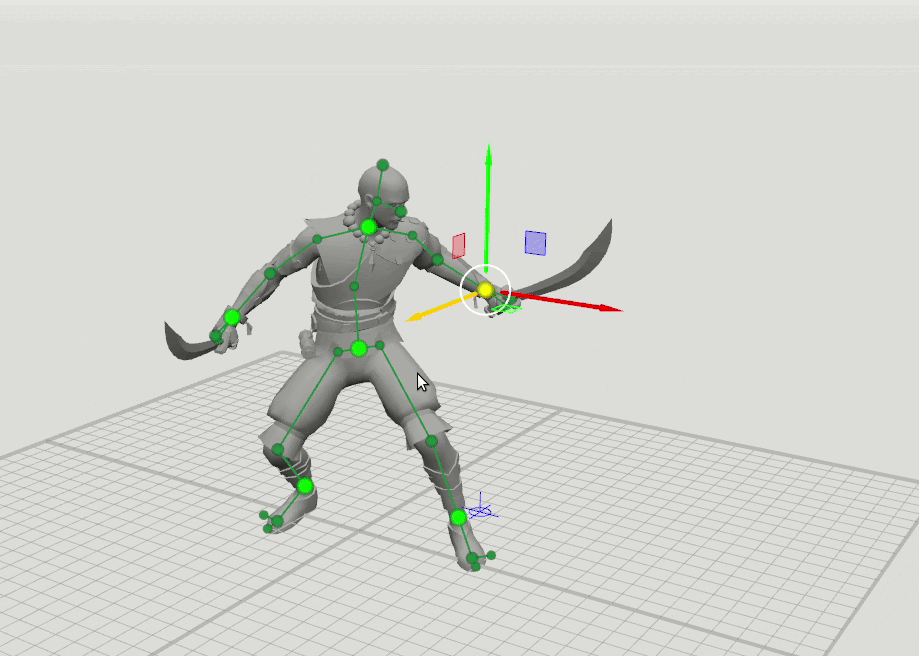
De là est venue l'idée logique de la prochaine étape - former quelques réseaux supplémentaires avec un ensemble élargi de points qui spécifient l'orientation des mains, des pieds et de la tête, ainsi que la position des genoux et des coudes. Nous avons ajouté des schémas de 16 et 28 points. Il s'est avéré que les résultats de ces réseaux peuvent être combinés afin que l'utilisateur puisse définir des positions sur un ensemble arbitraire de points. Par exemple, l'utilisateur a décidé de déplacer le coude gauche, mais n'a pas touché le droit. Ensuite, la position du coude droit et de l'épaule droite est prédite selon un schéma à 6 points, et la position de l'épaule gauche est prédite selon un schéma à 16 points.

Il semble que cela s'avère être un outil vraiment intéressant pour travailler avec la pose d'un personnage. Son potentiel n'a pas encore été révélé jusqu'à la fin, et nous avons des idées sur la façon de l'améliorer et de l'appliquer non seulement pour travailler avec une pose. La première version de cet outil est déjà disponible dans la version actuelle de Cascadeur. Vous pouvez l'essayer si vous vous inscrivez pour un test bêta fermé sur notre site Web
cascadeur.comNous serons heureux de connaître votre opinion et de répondre à vos questions.
L'équipe de Banzai Games a besoin d'un chercheur en apprentissage profond. En savoir plus sur l'offre d'emploi ici .