
Salut, lecteurs de Habr. Avec cet article, nous ouvrons un cycle qui parlera du système hyperconvergé AERODISK vAIR que nous avons développé. Au départ, nous voulions que le premier article raconte tout sur tout, mais le système est assez complexe, nous allons donc manger un éléphant en plusieurs parties.
Commençons l'histoire par l'histoire du système, approfondissons le système de fichiers ARDFS, qui est le fondement de vAIR, et parlons également un peu du positionnement de cette solution sur le marché russe.
Dans les prochains articles, nous parlerons davantage des différents composants architecturaux (cluster, hyperviseur, équilibreur de charge, système de surveillance, etc.), du processus de configuration, nous soulèverons des problèmes de licence, afficherons séparément les tests de plantage et, bien sûr, écrirons sur les tests de charge et dimensionnement. Nous consacrerons également un article séparé à la version communautaire de vAIR.
Un airdisc est-il une histoire de stockage? Ou pourquoi avons-nous même commencé à hyperconverger?
Au départ, l'idée de créer notre propre hyperconvergent nous est venue vers 2010. Ensuite, il n'y avait pas d'Aerodisk et de solutions similaires (systèmes commerciaux hyperconvergés en boîte) sur le marché. Notre tâche était la suivante: à partir d'un ensemble de serveurs avec des disques locaux connectés par une interconnexion via Ethernet, nous devions faire un stockage étendu et exécuter des machines virtuelles et un réseau logiciel au même endroit. Tout cela devait être mis en œuvre sans systèmes de stockage (car il n'y avait tout simplement pas d'argent pour le stockage et son regroupement, et nous n'avions pas encore inventé notre propre système de stockage).
Nous avons essayé de nombreuses solutions open source et avons toujours résolu ce problème, mais la solution était très compliquée et difficile à répéter. De plus, cette décision appartenait à la catégorie «Works? Ne touchez pas! " Par conséquent, après avoir résolu ce problème, nous n'avons pas développé l'idée de transformer le résultat de notre travail en un produit à part entière.
Après cet incident, nous nous sommes éloignés de cette idée, mais nous avions toujours le sentiment que cette tâche était complètement résoluble, et les avantages d'une telle solution étaient plus qu'évidents. Par la suite, les produits HCI des sociétés étrangères qui ont été libérés n'ont fait que confirmer ce sentiment.
Ainsi, mi-2016, nous sommes revenus sur cette tâche dans le cadre de la création d'un produit à part entière. Ensuite, nous n'avions pas encore de relations avec les investisseurs, nous avons donc dû acheter un stand de développement pour notre argent pas très gros. Après avoir tapé sur les serveurs et commutateurs Avito BU-shyh, nous nous sommes mis au travail.

La principale tâche initiale était de créer votre propre, bien que simple, mais votre propre système de fichiers, qui serait capable de distribuer automatiquement et uniformément les données sous forme de blocs virtuels sur le nième nombre de nœuds de cluster interconnectés via Ethernet. Dans ce cas, le FS doit être bien et facilement mis à l'échelle et indépendant des systèmes adjacents, c'est-à-dire être aliéné de vAIR sous forme de «stockage juste».

VAIR First Concept

Nous avons intentionnellement refusé d'utiliser des solutions open source prêtes à l'emploi pour organiser un stockage étendu (ceph, gluster, lustre et similaires) en faveur de notre développement, car nous avions déjà une grande expérience de projet avec eux. Bien sûr, ces solutions elles-mêmes sont merveilleuses et avant de travailler sur Aerodisk, nous avons implémenté plus d'un projet d'intégration avec elles. Mais c'est une chose de réaliser la tâche spécifique d'un client, de former le personnel et, éventuellement, d'acheter du support pour un grand fournisseur, et c'est tout autre chose de créer un produit facilement reproductible qui sera utilisé pour diverses tâches, que nous, en tant que fournisseur, pouvons même nous connaître. nous ne le ferons pas. Pour le deuxième objectif, les produits open source existants ne nous convenaient pas, nous avons donc décidé de voir nous-mêmes le système de fichiers distribué.
Deux ans plus tard, plusieurs développeurs (qui combinaient le travail sur vAIR avec le travail sur le moteur de stockage classique) ont atteint un certain résultat.
En 2018, nous avions écrit le système de fichiers le plus simple et l'avons complété avec la liaison nécessaire. Le système a intégré des disques physiques (locaux) de différents serveurs dans un pool plat via une interconnexion interne et les a coupés en blocs virtuels, puis des périphériques de bloc avec différents degrés de tolérance aux pannes ont été créés à partir de blocs virtuels, sur lesquels des hyperviseurs KVM virtuels ont été créés et exécutés voitures.
Nous ne nous sommes pas souciés du nom du système de fichiers et l'avons appelé succinctement ARDFS (devinez comment il déchiffre))
Ce prototype avait l'air bien (pas visuellement, bien sûr, il n'y avait pas de conception visuelle à l'époque) et a montré de bons résultats en termes de performances et de mise à l'échelle. Après le premier résultat réel, nous avons fixé le cap pour ce projet, après avoir organisé un environnement de développement à part entière et une équipe distincte qui n'était engagée que dans vAIR.
À ce moment-là, l'architecture générale de la solution était arrivée à maturité et n'avait jusqu'à présent pas subi de changements majeurs.
Plonger dans le système de fichiers ARDFS
ARDFS est la base de vAIR, qui fournit un stockage de basculement distribué de l'ensemble du cluster. Une (mais pas la seule) caractéristique distinctive d'ARDFS est qu'il n'utilise pas de serveurs dédiés supplémentaires pour la méta et la gestion. Il s'agissait à l'origine de simplifier la configuration de la solution et de sa fiabilité.
Structure de stockage
Dans tous les nœuds de cluster, ARDFS organise un pool logique à partir de tout l'espace disque disponible. Il est important de comprendre qu'un pool n'est pas encore des données et pas de l'espace formaté, mais simplement du balisage, c'est-à-dire tous les nœuds sur lesquels vAIR est installé lorsqu'ils sont ajoutés au cluster sont automatiquement ajoutés au pool ARDFS partagé et les ressources de disque sont automatiquement partagées sur l'ensemble du cluster (et disponibles pour le stockage futur des données). Cette approche vous permet d'ajouter et de supprimer des nœuds à la volée sans aucun impact sérieux sur un système déjà en cours d'exécution. C'est-à-dire le système est très facile à mettre à l'échelle avec des «briques», en ajoutant ou supprimant des nœuds dans le cluster si nécessaire.
Des disques virtuels (objets de stockage pour les machines virtuelles) sont ajoutés au-dessus du pool ARDFS, qui sont construits à partir de blocs virtuels de 4 mégaoctets. Les disques virtuels stockent directement les données. Au niveau du disque virtuel, un schéma de tolérance aux pannes est également défini.
Comme vous l'avez peut-être deviné, pour la tolérance aux pannes du sous-système de disques, nous n'utilisons pas le concept de RAID (tableau redondant de disques indépendants), mais utilisons RAIN (tableau redondant de nœuds indépendants). C'est-à-dire la tolérance aux pannes est mesurée, automatisée et gérée en fonction des nœuds et non des disques. Les disques, bien sûr, sont également un objet de stockage, ils sont, comme tout le reste, surveillés, vous pouvez effectuer toutes les opérations standard avec eux, y compris la création de RAID matériel local, mais le cluster fonctionne avec des nœuds.
Dans une situation où vous voulez vraiment du RAID (par exemple, un scénario qui prend en charge plusieurs échecs sur de petits clusters), rien ne vous empêche d'utiliser des contrôleurs RAID locaux et de faire du stockage étendu et une architecture RAIN par-dessus. Ce scénario est assez vivant et est pris en charge par nous, nous en parlerons donc dans un article sur les scénarios typiques d'utilisation de vAIR.
Schémas de basculement du stockage
Il peut y avoir deux schémas de résilience de disque virtuel vAIR:
1) Facteur de réplication ou simplement réplication - cette méthode de tolérance aux pannes est simple «comme un bâton et une corde». La réplication synchrone entre les nœuds avec un facteur 2 (2 copies par cluster) ou 3 (3 copies, respectivement) est effectuée. RF-2 permet à un disque virtuel de résister à une défaillance d'un nœud dans un cluster, mais «mange» la moitié du volume utilisable, et RF-3 résistera à une défaillance de 2 nœuds dans un cluster, mais il réservera 2/3 du volume utilisable à ses besoins. Ce schéma est très similaire à RAID-1, c'est-à-dire qu'un disque virtuel configuré dans RF-2 est résistant à la défaillance de l'un des nœuds du cluster. Dans ce cas, les données seront correctes et même les E / S ne s'arrêteront pas. Lorsqu'un nœud tombé redevient opérationnel, la récupération / synchronisation automatique des données commence.
Les exemples suivants illustrent la distribution des données RF-2 et RF-3 en mode normal et en situation de panne.
Nous avons une machine virtuelle d'une capacité de 8 Mo de données uniques (utiles) qui s'exécute sur 4 nœuds vAIR. Il est clair qu'en réalité, il est peu probable qu'il y ait une si petite quantité, mais pour un schéma qui reflète la logique des ARDFS, cet exemple est le plus compréhensible. AB sont des blocs virtuels de 4 Mo contenant des données de machine virtuelle uniques. Avec RF-2, deux copies de ces blocs A1 + A2 et B1 + B2 sont créées, respectivement. Ces blocs sont «disposés» par des nœuds, en évitant l'intersection des mêmes données sur le même nœud, c'est-à-dire que la copie A1 ne sera pas sur la même note que la copie A2. Avec B1 et B2, c'est similaire.
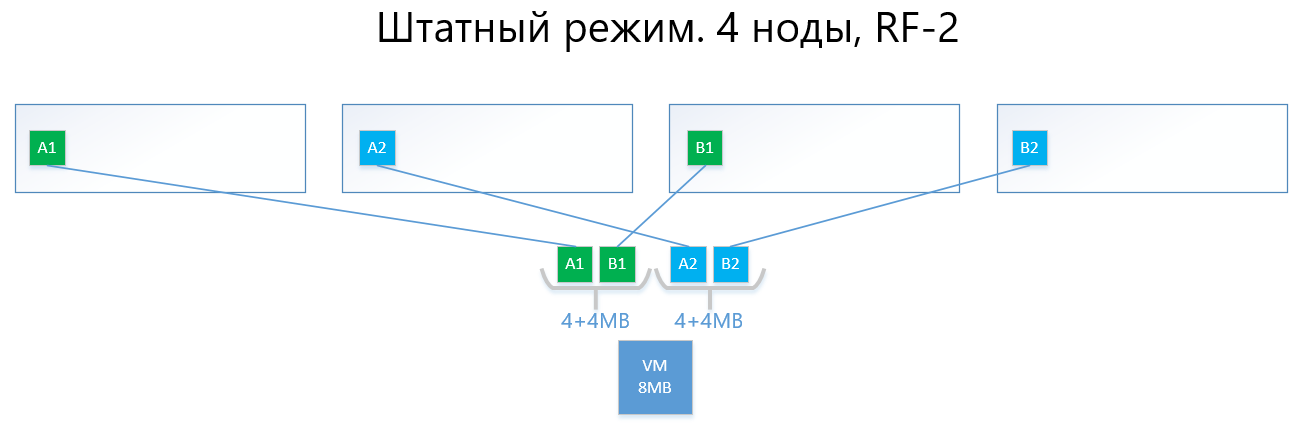
En cas de défaillance de l'un des nœuds (par exemple, le nœud 3, qui contient une copie de B1), cette copie est automatiquement activée sur le nœud où il n'y a pas de copie de sa copie (c'est-à-dire la copie B2).
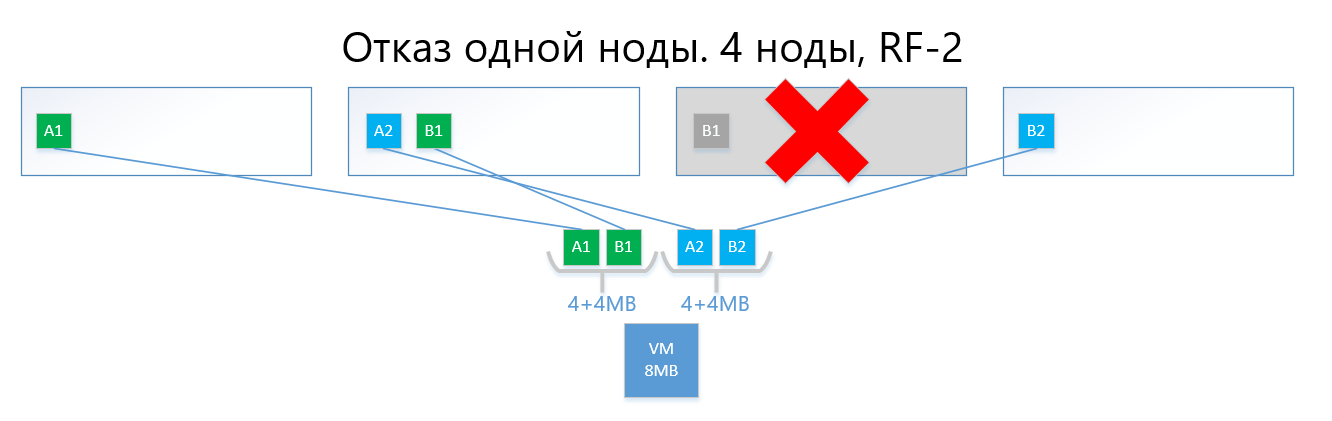
Ainsi, le disque virtuel (et les VM, respectivement) survivra facilement à la défaillance d'un nœud dans le schéma RF-2.
Un circuit avec réplication, avec sa simplicité et sa fiabilité, souffre de la même plaie que RAID1 - il y a peu d'espace utilisable.
2) Le codage d'effacement ou de suppression (également connu sous le nom de «codage redondant», «codage d'effacement» ou «code de redondance») n'existe que pour résoudre le problème ci-dessus. EC est un schéma de redondance qui offre une haute disponibilité des données avec moins de surcharge de disque par rapport à la réplication. Le principe de fonctionnement de ce mécanisme est similaire à RAID 5, 6, 6P.
Lors de l'encodage, le processus EC divise le bloc virtuel (4 Mo par défaut) en plusieurs «morceaux de données» plus petits selon le schéma EC (par exemple, un schéma 2 + 1 divise chaque bloc de 4 Mo en 2 morceaux de 2 Mo chacun). En outre, ce processus génère des «morceaux de parité» pour des «éléments de données» d'au plus une des parties précédemment séparées. Lors du décodage, l'EC génère les pièces manquantes, lisant les données «survivantes» sur l'ensemble du cluster.
Par exemple, un disque virtuel avec un schéma EC 2 + 1, implémenté sur 4 nœuds d'un cluster, peut facilement résister à une défaillance de nœud unique dans un cluster de la même manière que RF-2. Dans le même temps, les frais généraux seront inférieurs, en particulier, le facteur de capacité avec RF-2 est de 2 et avec EC 2 + 1, il sera de 1,5.
S'il est plus facile à décrire, le résultat inférieur est que le bloc virtuel est divisé en 2-8 (pourquoi de 2 à 8 voir ci-dessous) "morceaux", et pour ces morceaux les "morceaux" de parité du même volume sont calculés.
Par conséquent, les données et la parité sont réparties uniformément sur tous les nœuds du cluster. En même temps, comme pour la réplication, ARDFS répartit automatiquement les données entre les nœuds de manière à empêcher le stockage des mêmes données (copies des données et leur parité) sur un nœud afin d'éliminer le risque de perte de données du fait que les données et leur la parité se retrouvera soudainement sur le même nœud de stockage, ce qui échouera.
Voici un exemple, avec la même machine virtuelle à 8 Mo et 4 nœuds, mais déjà avec le schéma EC 2 + 1.
Les blocs A et B sont divisés en deux morceaux de 2 Mo chacun (deux parce que 2 + 1), c'est-à-dire A1 + A2 et B1 + B2. Contrairement à la réplique, A1 n'est pas une copie de A2, c'est un bloc virtuel A, divisé en deux parties, également avec le bloc B. Au total, nous obtenons deux ensembles de 4 Mo, chacun contenant deux pièces de deux mégaoctets. De plus, pour chacun de ces ensembles, la parité est calculée avec un volume ne dépassant pas une pièce (c'est-à-dire 2 Mo), nous obtenons un + 2 pièces de parité supplémentaires (AP et BP). Au total, nous avons des données 4x2 + parité 2x2.
Ensuite, les pièces sont «disposées» par des nœuds afin que les données ne se chevauchent pas avec leur parité. C'est-à-dire A1 et A2 ne se trouveront pas sur le même nœud avec AP.

En cas de défaillance d'un nœud (par exemple, également le troisième), le bloc B1 tombé sera automatiquement restauré à partir de la parité BP, qui est stockée sur le nœud n ° 2, et sera activé sur le nœud où il n'y a pas de parité B, c'est-à-dire morceaux de BP. Dans cet exemple, il s'agit du nœud n ° 1

Je suis sûr que le lecteur a une question:
"Tout ce que vous avez décrit a longtemps été mis en œuvre par les concurrents et les solutions open source, quelle est la différence entre votre implémentation d'EC dans ARDFS?"
Et puis il y aura des caractéristiques intéressantes du travail d'ARDFS.
Codage d'effacement en mettant l'accent sur la flexibilité
Initialement, nous avons fourni un schéma EC X + Y plutôt flexible, où X est égal à un nombre de 2 à 8, et Y est égal à un nombre de 1 à 8, mais toujours inférieur ou égal à X. Un tel schéma est fourni pour la flexibilité. L'augmentation du nombre de données (X) dans lesquelles l'unité virtuelle est divisée permet de réduire la surcharge, c'est-à-dire d'augmenter l'espace utilisable.
Une augmentation du nombre de morceaux de parité (Y) augmente la fiabilité du disque virtuel. Plus la valeur Y est élevée, plus les nœuds du cluster peuvent tomber en panne. Bien sûr, l'augmentation de la parité réduit la quantité de capacité utilisable, mais c'est une charge pour la fiabilité.
La dépendance des performances vis-à-vis des circuits EC est presque directe: plus il y a de «pièces», plus les performances sont faibles, ici, bien sûr, vous avez besoin d'un look équilibré.
Cette approche offre aux administrateurs le moyen le plus flexible de configurer un stockage étendu. Au sein du pool ARDFS, vous pouvez utiliser tous les schémas de tolérance aux pannes et leurs combinaisons, ce qui est également, à notre avis, très utile.
Le tableau ci-dessous compare plusieurs (pas tous possibles) circuits RF et EC.

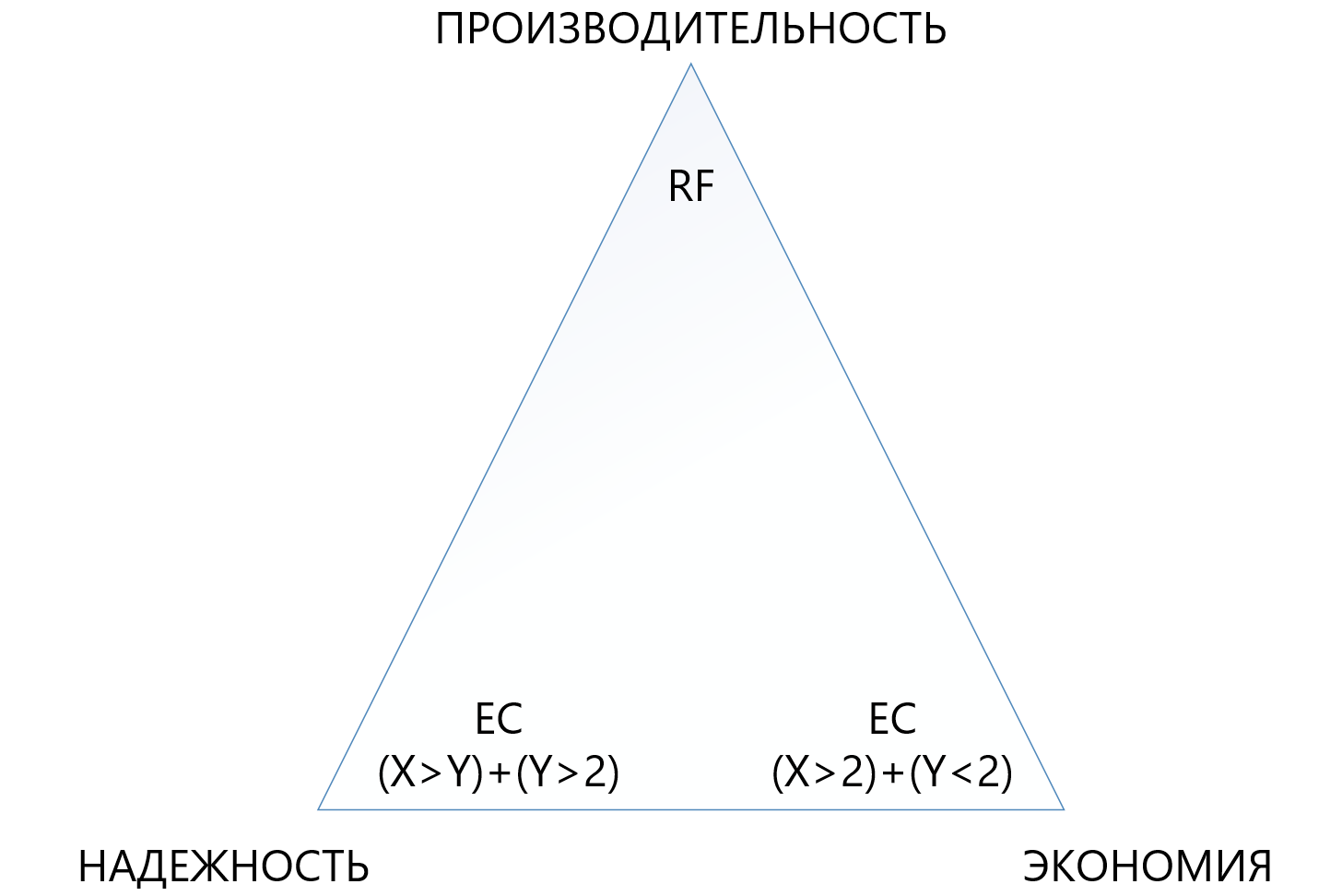
Le tableau montre que même la combinaison la plus «terry» d'EC 8 + 7, qui permet de perdre jusqu'à 7 nœuds à la fois dans un cluster, «consomme» moins d'espace utilisable (1 875 contre 2) que la réplication standard, et protège 7 fois mieux, ce qui rend ce mécanisme de protection, bien que plus complexe, mais beaucoup plus attractif dans les situations où vous avez besoin d'assurer une fiabilité maximale dans les conditions de manque d'espace disque. Dans le même temps, vous devez comprendre que chaque «plus» à X ou Y sera un surcoût supplémentaire pour la productivité, vous devez donc choisir très soigneusement dans le triangle entre fiabilité, économie et performances. Pour cette raison, nous consacrerons un article séparé au codage de suppression de dimensionnement.
Fiabilité et autonomie du système de fichiers
ARDFS s'exécute localement sur tous les nœuds du cluster et les synchronise par ses propres moyens via des interfaces Ethernet dédiées. Un point important est que ARDFS synchronise indépendamment non seulement les données, mais aussi les métadonnées liées au stockage. Tout en travaillant sur ARDFS, nous avons étudié simultanément un certain nombre de solutions existantes et nous avons constaté que beaucoup effectuent la méta-synchronisation du système de fichiers en utilisant un SGBD distribué externe, que nous utilisons également pour synchroniser, mais uniquement les configurations, pas les métadonnées FS (à propos de cela et d'autres sous-systèmes connexes dans le prochain article).
La synchronisation des métadonnées FS à l'aide d'un SGBD externe est, bien sûr, une solution de travail, mais la cohérence des données stockées sur ARDFS dépendrait du SGBD externe et de son comportement (et elle, franchement, est une dame capricieuse), ce qui est mauvais à notre avis. Pourquoi? Si les métadonnées FS sont endommagées, les données FS elles-mêmes peuvent également être dites «au revoir», nous avons donc décidé d'emprunter un chemin plus compliqué mais fiable.
Nous avons créé le sous-système de synchronisation des métadonnées pour ARDFS indépendamment, et il vit complètement indépendamment des sous-systèmes adjacents. C'est-à-dire aucun autre sous-système ne peut corrompre les données ARDFS. À notre avis, c'est le moyen le plus fiable et le plus correct, et c'est vraiment le cas - le temps nous le dira. De plus, avec cette approche, un avantage supplémentaire apparaît. ARDFS peut être utilisé indépendamment de vAIR, tout comme le stockage étendu, que nous utiliserons certainement dans les futurs produits.
En conséquence, après avoir développé ARDFS, nous avons obtenu un système de fichiers flexible et fiable qui vous donne le choix où vous pouvez économiser sur la capacité ou tout donner sur les performances, ou rendre le stockage très fiable pour un prix modéré, mais en réduisant les exigences de performances.
Associé à une politique de licence simple et à un modèle de livraison flexible (à l'avenir, il est autorisé par vAIR par des nœuds et est livré soit par logiciel soit en tant que PAC), cela vous permet d'adapter très précisément la solution aux exigences les plus différentes des clients et, à l'avenir, il sera facile de maintenir cet équilibre.
Qui a besoin de ce miracle?
D'une part, on peut dire qu'il y a déjà des acteurs sur le marché qui ont des décisions sérieuses dans le domaine de l'hyperconvergence, et où nous allons réellement. Cette affirmation semble être vraie, MAIS ...
En revanche, en allant sur le terrain et en communiquant avec les clients, nous et nos partenaires constatons que ce n'est pas du tout le cas. Il y a beaucoup de problèmes pour les hyper convergents, quelque part les gens ne savaient tout simplement pas qu'il y avait de telles solutions, quelque part cela semblait cher, quelque part il y avait des tests infructueux de solutions alternatives, mais quelque part ils interdisaient généralement d'acheter, à cause des sanctions. En général, le champ n'était pas labouré, nous sommes donc allés élever les terres vierges))).
Quand le stockage est-il meilleur que GCS?
En travaillant avec le marché, on nous demande souvent quand il vaut mieux utiliser le schéma classique avec des systèmes de stockage, et quand est hyperconvergent? De nombreuses entreprises - fabricants de GCS (en particulier celles qui n'ont pas de stockage dans leur portefeuille) disent: "Le stockage est dépassé, seulement hyperconvergent!" C'est une déclaration audacieuse, mais elle ne reflète pas tout à fait la réalité.
En vérité, le marché du stockage nage en effet vers des solutions hyperconvergentes et similaires, mais il y a toujours un «mais».
Premièrement, les centres de données et les infrastructures informatiques construits selon le schéma classique avec des systèmes de stockage ne peuvent pas être facilement reconstruits comme cela, de sorte que la modernisation et l'achèvement de ces infrastructures sont encore un héritage de 5-7 ans.
Deuxièmement, les infrastructures qui sont en train d'être construites en grande partie (c'est-à-dire la Fédération de Russie) sont construites selon le schéma classique en utilisant des systèmes de stockage et non pas parce que les gens ne connaissent pas l'hyperconvergent, mais parce que le marché hyperconvergent est nouveau, les solutions et les normes n'ont pas encore été établies , Les employés des TI n'ont pas encore été formés, il y a peu d'expérience et nous devons construire des centres de données ici et maintenant. Et cette tendance se poursuit pendant 3 à 5 ans (puis un autre héritage, voir le paragraphe 1).
Troisièmement, il y a une limitation purement technique dans les petits retards supplémentaires de 2 millisecondes par écriture (à l'exclusion du cache local, bien sûr), qui sont des frais pour le stockage distribué.
Eh bien, n'oublions pas d'utiliser de grands serveurs physiques qui aiment la mise à l'échelle verticale du sous-système de disque.
Il existe de nombreuses tâches nécessaires et populaires où le système de stockage se comporte mieux que le GCS. Ici, bien sûr, les fabricants qui n'ont pas de systèmes de stockage dans leur portefeuille de produits seront en désaccord avec nous, mais nous sommes prêts à discuter raisonnablement. Bien sûr, nous, en tant que développeurs des deux produits dans l'une des futures publications, ferons certainement une comparaison des systèmes de stockage et de GCS, où nous démontrerons clairement ce qui est mieux dans quelles conditions.
Et où les solutions hyperconvergées fonctionneront-elles mieux que les systèmes de stockage?
Sur la base des thèses ci-dessus, il y a trois conclusions évidentes:
- Là où 2 millisecondes supplémentaires de retards d'enregistrement qui se produisent de manière stable dans n'importe quel produit (maintenant nous ne parlons pas de synthétiques, vous pouvez montrer des nanosecondes sur des synthétiques) ne sont pas critiques, hyper convergentes feront l'affaire.
- Là où la charge de grands serveurs physiques peut être transformée en de nombreux petits serveurs virtuels et distribuée par des nœuds, l'hyperconvergent fonctionnera également bien là-bas.
- Là où la mise à l'échelle horizontale est plus importante que la mise à l'échelle verticale, GCS fonctionnera également correctement.
Quelles sont ces solutions?
- Tous les services d'infrastructure standard (service d'annuaire, courrier, EDS, serveurs de fichiers, petits ou moyens systèmes ERP et BI, etc.). Nous appelons cela «l'informatique générale».
- L'infrastructure des fournisseurs de cloud, où il est nécessaire de développer rapidement et standardiser horizontalement et de «découper» facilement un grand nombre de machines virtuelles pour les clients.
- Virtual Desktop Infrastructure (VDI), où de nombreuses petites machines virtuelles d'utilisateurs sont lancées et «flottent» silencieusement à l'intérieur d'un cluster uniforme.
- Réseaux de succursales où, dans chaque succursale, vous avez besoin d'une infrastructure standard, tolérante aux pannes, mais en même temps économique de 15 à 20 machines virtuelles.
- Tout type d'informatique distribuée (services de Big Data, par exemple). Où la charge ne va pas «en profondeur», mais «en largeur».
- Environnements de test où de petits retards supplémentaires sont acceptables, mais il y a des contraintes budgétaires, car ce sont des tests.
Actuellement, c'est pour ces tâches que nous avons réalisé AERODISK vAIR et que nous nous concentrons sur elles (jusqu'à présent avec succès). Peut-être que cela changera bientôt. le monde ne reste pas immobile.
Alors ...
Ceci termine la première partie d'une grande série d'articles; dans le prochain article, nous parlerons de l'architecture de la solution et des composants utilisés.
Nous accueillons volontiers les questions, suggestions et différends constructifs.