Récemment, un article au titre pas si intriguant, "
La reparamétérisation neuronale améliore l'optimisation structurelle ", a été téléchargé sur arXiv.org [arXiv: 1909.04240]. Cependant, il s'est avéré que les auteurs ont en fait trouvé et décrit une méthode très non triviale d'utilisation d'un réseau de neurones pour obtenir une solution au problème de l'optimisation structurelle / topologique des modèles physiques (bien que les auteurs eux-mêmes disent que la méthode est plus universelle). L'approche est très curieuse, productive et semble être complètement nouvelle (cependant, je ne peux pas me porter garant de cette dernière, mais ni les auteurs de l'ouvrage, ni la communauté ODS, ni me rappeler des analogues), il peut donc être utile de savoir pour ceux qui souhaitent utiliser les réseaux de neurones, ainsi que la résolution de divers problèmes d'optimisation.
De quoi tu parles? Quelle est la tâche de l'optimisation topologique?
Imaginez simplement ce dont vous avez besoin, par exemple, pour concevoir un filet de pont, un bâtiment à plusieurs étages, une aile d'avion, une aube de turbine, etc. Habituellement, cela est résolu en trouvant un spécialiste, par exemple, un architecte qui, en utilisant ses connaissances de matan, sopromat, la zone cible, ainsi que son expérience, son intuition, la disposition des tests, etc. etc. créerait le projet souhaité. Il est important ici que ce projet reçu ne soit bon que pour le meilleur de ce spécialiste. Et cela n'est évidemment pas toujours suffisant. Par conséquent, lorsque les ordinateurs sont devenus suffisamment puissants, nous avons commencé à leur confier de telles tâches. Car
il est évident ce qu'un ordinateur peut garder en mémoire et court-circuiter ... pourquoi pas?
Ces tâches sont appelées "problèmes d'optimisation structurelle", c'est-à-dire générer une conception optimale des structures mécaniques porteuses [1]. Une sous-section des problèmes d'optimisation structurelle sont
des problèmes d'optimisation topologique (en fait, le travail en question est spécifiquement axé sur eux, mais ce n'est absolument pas le point, et plus sur cela plus tard). Un problème d'optimisation topologique typique ressemble à ceci: pour un concept donné (pont, maison, etc.) dans l'espace en deux ou trois dimensions, ayant des limitations spécifiques sous la forme de matériaux, de technologies et d'autres exigences, ayant des charges externes, vous devez concevoir Une structure optimale qui supportera les charges et satisfera aux contraintes.
- «Concevoir» signifie essentiellement trouver / décrire un sous-espace de l'espace source qui doit être rempli de matériaux de construction.
- L'optimalité peut être exprimée, par exemple, sous la forme d'une exigence de minimiser le poids total de la structure sous des restrictions sous la forme des contraintes maximales admissibles dans le matériau et des déplacements possibles à des charges données.
Pour résoudre ce problème sur un ordinateur, l'espace de solution cible est échantillonné dans un ensemble d'éléments finis (pixels pour 2D et voxels pour 3D) puis, à l'aide d'un algorithme, l'ordinateur décide de remplir cet élément individuel avec du matériel ou de le laisser vide?

(Image tirée de "Développements en topologie et optimisation de formes", Chau Hoai Le, 2010)
Ainsi, déjà d'après l'énoncé du problème, il est clair que sa solution est un gros éclat pour les scientifiques. Je peux offrir à ceux qui souhaitent quelques détails, par exemple, en regarder un très ancien (2010, ce qui est encore beaucoup pour un domaine en développement actif), mais une dissertation Chau Hoai Le assez détaillée et facile à consulter intitulée "Développements en topologie et optimisation de forme" [2] J'ai volé les photos du haut et du bas.
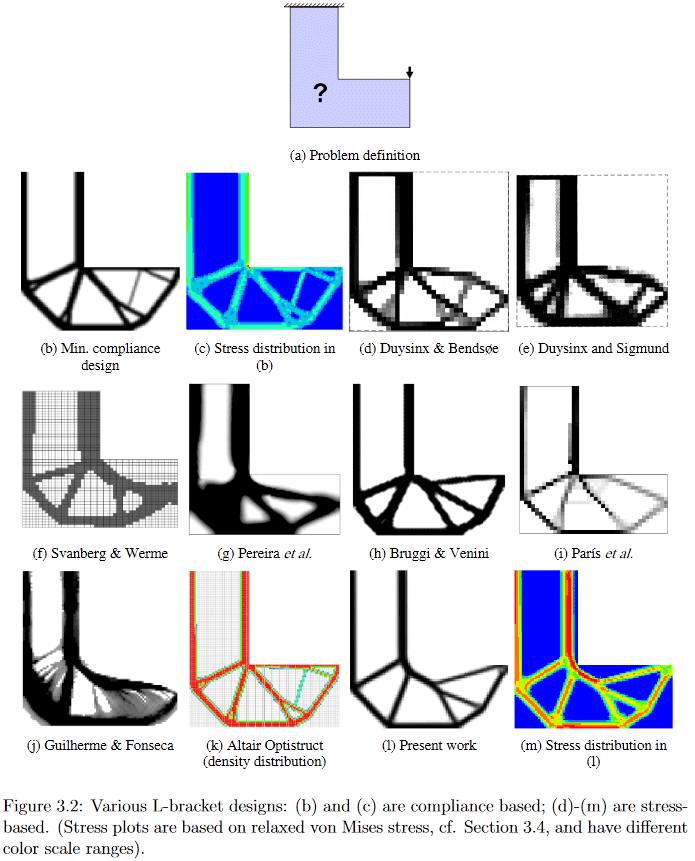
(Image tirée de "Développements en topologie et optimisation de formes", Chau Hoai Le, 2010)
À titre d'exemple, dans cette image, vous pouvez clairement voir comment différents algorithmes génèrent une solution au problème de conception apparemment simple de la suspension en forme de L.
Revenons donc maintenant au travail en question.
Les auteurs ont très spirituellement suggéré de résoudre ces problèmes d'optimisation en générant une solution candidate par un réseau de neurones et l'évolution ultérieure de la solution par des méthodes de descente de gradient par rapport à la fonction de conformité objective. La conformité de la structure résultante est estimée à l'aide d'un modèle physique différenciable, qui, en fait, permet d'utiliser la descente de gradient. Selon eux (les auteurs ont publié les
codes sources de [5]), cela donne soit le même résultat que les meilleurs algorithmes traditionnels pour les problèmes simples, soit le meilleur de ces algorithmes utilisés comme références, pour les complexes.
La méthode
Ensuite, je vais essayer de décrire quoi et comment exactement les auteurs ont proposé de faire, mais je préviens immédiatement que je ne garantis pas l'exactitude à 100%, car en plus de mon érudition extrêmement rouillée sur le terrain, je devrais ajouter, en plus de la brièveté extrêmement maigre de la description, une certaine «immaturité» générale de l'article, qui, à en juger par la présence de deux éditions en 4 jours, est en cours de finalisation (
ajouté: pour le moment, je crois qu'au moins, fondamentalement, tout est décrit correctement).
Les auteurs, en général, suivent l'approche de résolution de ces problèmes d'optimisation, appelée «méthode SIMP modifiée», et décrite en détail dans [3] «Optimisation efficace de la topologie dans MATLAB en utilisant 88 lignes de code». La préimpression de ce travail et le code qui lui est associé peuvent être trouvés à
http://www.topopt.mek.dtu.dk/Apps-and-software/Efficient-topology-optimization-in-MATLAB . Ce travail est souvent utilisé pour commencer à enseigner aux étudiants les problèmes d'optimisation topologique, par conséquent, afin de mieux le comprendre, il est recommandé de le connaître.
En «SIMP modifié», la solution est optimisée directement en modifiant les pixels de l'image des densités physiques. Les auteurs de l'article n'ont pas proposé de modifier l'image directement (bien qu'un tel algorithme, toutes choses étant égales par ailleurs, soit un contrôle), mais de changer les paramètres et l'entrée du réseau neuronal convolutif qui génère une image des densités physiques. Voici à quoi ressemble la méthode dans son ensemble:

(Image de la publication en question)
Étape 1, générer un candidat
Un réseau de neurones (ci-après dénommé NS) utilisant le vecteur d'entrée primaire aléatoire _beta (il, comme le poids du réseau, est un paramètre entraîné), génère (une) image de la solution (fonctionne avec 2D, mais en 3D, je pense, il peut également être distribué ) La partie de suréchantillonnage de l'architecture U-Net bien connue est utilisée comme générateur NS.
Étape 2, application de restrictions et conversion d'un candidat à un cadre de modèle physique
Les valeurs des pixels sont converties en densités physiques en deux étapes:
- Tout d'abord, en une seule étape, le problème de la normalisation des valeurs non normalisées des pixels générés est résolu (le NS est conçu pour qu'il génère les soi-disant logits - valeurs dans la plage (-inf, + inf)) et en appliquant des restrictions sur la quantité totale de la solution résultante. Pour cela, une sigmoïde est appliquée élément par élément à l'image, dont l'argument est décalé d'une constante en fonction de l'image transformée et du volume de la solution souhaitée (la valeur de cette constante de biais est sélectionnée par recherche binaire de sorte que le volume total des densités ainsi obtenues serait égal à un certain volume prédéterminé V0). Une analyse détaillée de cette étape, voir le commentaire );
- En outre, l'image normalisée résultante des densités de la structure est traitée par ce que l'on appelle un filtre de densité avec un rayon de 2. En termes plus connus, ce filtre n'est rien de plus qu'une moyenne pondérée normale des points voisins de l'image. Les poids dans ce filtre (noyau de filtre) peuvent être représentés comme les valeurs de la hauteur des points situés à la surface d'un cône régulier, qui se trouve avec la base sur le plan de sorte que son sommet soit au point actuel, donc les auteurs l'appellent filtre à cône (plus en détail sur ce sujet voir la description du filtre de densité au chapitre 2.3 Filtrage de [3]).
En bref, l'essence de toute l'étape 2 est que la sortie non normalisée d'un NS complètement ordinaire se transforme en un cadre correctement normalisé et légèrement lissé du modèle physique (un ensemble de densités physiques d'éléments), auquel les restrictions a priori nécessaires ont déjà été appliquées (c'est la quantité de matière utilisée).
Étape 3, évaluation du modèle physique de trame résultant
L'ossature résultante passe par un moteur physique différenciable pour obtenir le vecteur (/ tenseur?) Du déplacement structurel sous charge (y compris la gravité) U. La clé ici est la différentiabilité du moteur, qui nous permet d'obtenir des gradients (je rappelle que le gradient de la fonction est généralement tenseur composé de dérivées partielles d'une fonction par rapport à tous ses arguments. Le gradient montre la direction et le taux de changement de la fonction au point courant, donc, le sachant, vous pouvez «tordre» les arguments pour que le changement souhaité se produise avec la fonction - il a diminué ou augmenté). Un tel moteur physique différenciable n'a pas besoin d'être écrit à partir de zéro - il existe depuis longtemps et est bien connu. Les auteurs avaient seulement besoin de faire leur appariement avec des packages de calcul de réseau neuronal, tels que TensorFlow / PyTorch.
Étape 4, calcul de la valeur de la fonction objectif pour le filaire / candidat
La fonction objectif scalaire c (x) à minimiser est calculée, qui décrit la conformité (c'est l'inverse de la rigidité) du cadre résultant. La fonction de compliance dépend du vecteur de décalage U obtenu à la dernière étape et de la matrice de rigidité de la structure K (je n'ai pas suffisamment de connaissances en optimisation topologique pour comprendre d'où vient K - je suppose qu'il semble être directement pris en compte à partir du framework).
/ *
voir aussi les commentaires
(1) de
kxx et
(2) de
350 Stealth , bien que l'illumination de base vaille la peine de fonctionner [3].
* /
Et puis c'est fait. Puisque tout est créé dans un environnement avec différenciation automatique, à ce stade, nous obtenons automatiquement tous les gradients de la fonction objectif, qui sont poussés en raison de la différentiabilité de toutes les transformations à chaque pas vers les poids et le vecteur d'entrée du réseau neuronal générateur. Les poids et le vecteur d'entrée, respectivement, avec leurs dérivées partielles, changent, provoquant le changement nécessaire - minimisant la fonction objectif. Ensuite, un nouveau cycle de passage direct à travers la NS se produit -> application de restrictions -> calcul du modèle physique -> calcul de la fonction objectif -> nouveaux gradients et mise à jour des poids. Et ainsi de suite jusqu'à la convergence d'Algo.
Un point important, dont je n'ai pas trouvé les descriptions dans l'ouvrage, est de savoir comment le volume total de la construction V0 est sélectionné, à l'aide duquel la solution candidate est convertie dans le cadre de l'étape 2. Évidemment, les propriétés de la solution résultante dépendent extrêmement de son choix. Par des indications indirectes (tous les exemples des solutions obtenues [4] ont plusieurs instances différant précisément dans la limitation de volume), je suppose qu'ils fixent simplement V0 sur une certaine grille de la plage [0,05, 0,5] puis ils regardent les solutions obtenues avec des yeux différents V0. Eh bien, pour un travail conceptuel, cela, en général, suffit, bien que, bien sûr, il serait terriblement intéressant de voir l'option avec la sélection de ce V0 également, mais, cela ira probablement à la prochaine étape de développement du travail.
Le deuxième point important, que je n'ai pas compris, est de savoir comment ils imposent des restrictions / exigences sur le type spécifique de solution. C'est-à-dire si vous pouvez toujours séparer le pont du bâtiment grâce au modèle physique (le bâtiment a un support complet et le pont est uniquement aux extrémités de la frontière), alors comment séparer, disons, un bâtiment de 3 étages d'un bâtiment de 4 étages?
Comment ça marche?
Il s'est avéré que pour les petits problèmes (en termes de taille de l'espace de solution = nombre de pixels), la méthode donne ± la même qualité de résultats que les meilleures méthodes traditionnelles d'optimisation topologique, mais sur les grands (taille de grille de 2 ^ 15 pixels ou plus, c'est-à-dire , par exemple, à partir de 128 * 256 et plus), l'obtention de solutions de haute qualité par la méthode est plus probable que la meilleure solution traditionnelle (sur 116 problèmes testés, la méthode a donné une solution préférée dans 99 problèmes, contre 66 préférés dans la meilleure solution traditionnelle).
De plus, ici commence quelque chose de particulièrement intéressant. Les méthodes traditionnelles d'optimisation topologique dans les grands problèmes souffrent du fait qu'au début des travaux, elles forment rapidement une nappe à petite échelle, ce qui interfère alors avec le développement de structures à grande échelle. Cela conduit au fait que le résultat obtenu est difficile / impossible à mettre en œuvre physiquement. Par conséquent, de force, il existe une direction entière dans les problèmes d'optimisation de la topologie qui étudie / propose des méthodes pour rendre les solutions résultantes plus pratiques sur le plan technologique.
Ici, apparemment, grâce au réseau de convolution, l'optimisation se produit simultanément à plusieurs échelles spatiales en même temps, ce qui permet d'éviter / de réduire fortement le "web" et d'obtenir des solutions plus simples, mais de haute qualité et technologiquement conviviales!
De plus, toujours grâce à la convolution du réseau, des solutions fondamentalement différentes sont obtenues par rapport aux méthodes classiques traditionnelles.
Par exemple, dans les conceptions:
- La méthode des poutres en porte-à-faux a trouvé une solution de seulement 8 composants, tandis que la meilleure traditionnelle - 18.
- la méthode du pont de support mince a choisi un support avec un motif de ramification en forme d'arbre, tandis que le traditionnel - deux supports
- La méthode du toit utilise des colonnes, tandis que la méthode traditionnelle utilise un modèle de branchement. Etc.
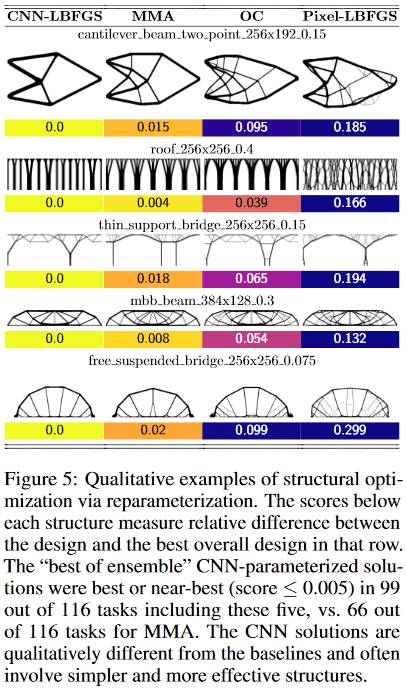
(Image de la publication en question)
Quelle est la particularité de ce travail?
Je n'ai jamais vu une telle utilisation d'un réseau neuronal. En règle générale, les réseaux de neurones sont utilisés pour obtenir une fonction très délicate et complexe y = F (x, thêta) (où x est un argument et thêta sont des paramètres personnalisés), ce qui peut faire quelque chose d'utile. Par exemple, si x est une image prise par l’appareil photo d’une voiture, la valeur y de la fonction peut, par exemple, indiquer si un piéton se trouve dangereusement près de la voiture. C'est-à-dire il est important ici que le type particulier de fonction lui-même, qui est utilisé à plusieurs reprises pour résoudre un problème, soit précieux.
Ici, le réseau neuronal est utilisé comme un astucieux dépositaire-modificateur-ajusteur de paramètres d'un modèle physique, qui, en raison de son architecture même, impose certaines restrictions sur les valeurs et les variations des changements de ces paramètres (en fait, les exemples sous la rubrique Pixel-LBFGS sont une tentative d'optimiser directement les pixels, non en utilisant un réseau de neurones pour les générer, les résultats sont visibles, la NS est importante). C’est là que la convolution du réseau de neurones utilisé devient critique, car son architecture vous permet de «capturer» le concept d’invariance de transfert et un peu de rotation (imaginez que vous reconnaissez le texte d’une image - il est important pour vous d’extraire le texte et peu importe qui parties de l'image, il est localisé et comment il est tourné - c'est-à-dire que vous avez besoin d'invariance dans le transfert et la rotation). Dans ce problème, une sorte de bâton physique, qui est une unité de structure et dont nous optimisons bon nombre, le reste, quelles que soient sa position et son orientation dans l'espace.
Un réseau classique entièrement connecté, par exemple, ne fonctionnerait probablement pas ici (tout aussi bien), car son architecture permet trop / petit (enfin, oui, un tel dualisme, comment regarder). Dans le même temps, malgré le fait que la NS reste ici la fonction très très délicate et complexe y = F (x, theta), dans cette tâche, nous ne nous soucions finalement pas à la fois de son argument x et de ses paramètres theta et comment la fonction sera utilisée. Nous ne nous préoccupons que de sa valeur unique y, qui est obtenue en optimisant une fonction objectif spécifique pour un modèle physique spécifique, dans lequel {x, theta} ne sont que des paramètres configurables!
À mon avis, c'est une idée génialement cool et nouvelle! (bien que, bien sûr, comme toujours, il se peut que Schmidhuber le décrive au début des années 90, mais attendez et voyez)
En général, le sens de la méthode rappelle quelque peu l'apprentissage renforcé - là, la NS est utilisée, en gros, comme un «référentiel d'expérience» d'un agent agissant dans un certain environnement, qui est mis à jour lorsque l'environnement reçoit des commentaires sur les actions de l'agent. Seulement là, ce même «référentiel d'expérience» est constamment utilisé pour prendre de nouvelles décisions par l'agent, et ici ce n'est qu'un référentiel de paramètres du modèle physique, à partir duquel nous ne nous intéressons qu'au seul résultat final de l'optimisation.
Eh bien, le dernier. Un moment intéressant a attiré mon attention.
Voici à quoi ressemblent les solutions optimales pour la tâche d'un bâtiment à plusieurs étages:
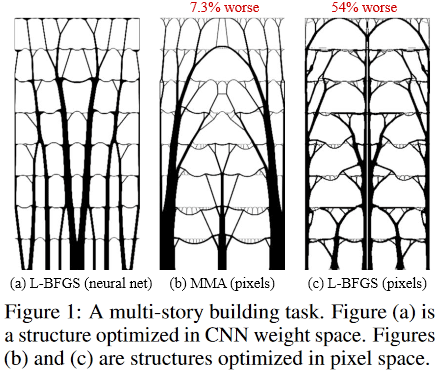
(Image de la publication en question)
Et donc:

situé à l'intérieur de la fantastique Sagrada Familia, le Temple de la Sainte Famille, situé à Barcelone, en Espagne, qui a été "conçu" par le brillant Antonio Gaudi.
Remerciements
Je remercie le premier auteur de l'article, Stephan Hoyer, pour son aide rapide à expliquer certains détails obscurs du travail, ainsi que les participants Habr qui ont fait leurs ajouts et / ou des idées provocatrices utiles.
[1]
option pour déterminer le problème d'optimisation structurelle / topologique[2]
"Développements en topologie et optimisation de forme"[3] Andreassen, E., Clausen, A., Schevenels, M., Lazarov, BS et Sigmund, O. Optimisation efficace de la topologie dans MATLAB utilisant 88 lignes de code. Structural and Multidisciplinary Optimization, 43 (1): 1–16, 2011. Une préimpression de ce travail et de ce code est disponible sur
http://www.topopt.mek.dtu.dk/Apps-and-software/Efficient-topology-optimization-in -MATLAB[4]
exemples de solutions de travail[5] Codes source de travail:
https://github.com/google-research/neural-structural-optimization
Voir aussi
Dernière mise à jour de cette publication 2020.01.23 09:18