Vous n'aimez pas Java? Oui, vous ne savez pas comment le faire cuire! Mani Sarkar nous invite à faire connaissance avec l'outil Valohai, qui vous permet de mener des recherches de modèles en Java.
Avis de non-responsabilité du traducteurJ'espère que ce n'est pas une publication publicitaire. Je ne suis pas affilié à Valohai. Je viens de traduire l'article auquel je renvoie le lien. Si maladroitement traduit - coup de pied PM. Si nécessaire, je peux supprimer des liens et mentionner d'autres ressources externes. Merci pour votre compréhension.
Présentation
Il y a quelque temps, je suis tombé sur un service cloud appelé Valohai, et j'étais satisfait de son interface utilisateur et de la simplicité de conception et de mise en page. J'ai demandé le service d'un des membres de Valohai et j'ai reçu une version de démonstration. Avant cela, j'ai écrit un simple pipeline utilisant GNU Parallel, JavaScript, Python et Bash - et un autre qui utilise uniquement GNU Parallel et Bash.
J'ai également pensé à utiliser des outils de gestion des tâches / flux de travail prêts à l'emploi comme Jenkins X, Jenkins Pipeline, Concourse ou Airflow, mais pour diverses raisons, j'ai décidé de ne pas le faire.
J'ai remarqué que de nombreux exemples et documentation Valohai sont basés sur Python et R et leurs cadres et bibliothèques respectifs. J'ai décidé de ne pas rater l'occasion et je veux corriger le manque d'exemples et de documentation.
Valohai m'a poussé à implémenter quelque chose en utilisant la célèbre bibliothèque Java appelée
DL4J - Deep Learning for Java .
Ma première expérience avec Valohai m'a fait bonne impression après avoir ressenti sa conception, sa mise en page et son flux de travail. Les créateurs ont déjà pris en compte divers aspects des workflows du développeur et de l'infrastructure. Dans notre monde, le processus de développement des infrastructures est principalement contrôlé par les équipes DevOps ou SysOps, et nous connaissons les nuances et les points douloureux qui y sont associés.
De quoi avons-nous besoin et comment?
Dans tout projet d'apprentissage automatique, il y a deux composants importants (d'un point de vue de haut niveau) - un code qui fonctionnera avec le modèle et un code qui fonctionnera avec l'infrastructure, dans lequel tout le cycle de vie du projet sera exécuté.
Bien sûr, il y aura des étapes et des composants nécessaires avant, pendant et après, mais pour simplifier, disons, nous avons besoin de code et d'infrastructure.
Code
Pour le code, j'ai choisi un exemple complexe utilisant DL4J, il s'agit d'un
projet MNist avec un ensemble de formation de 60 000 images et un ensemble de test de 10 000 images de chiffres manuscrits. Cet ensemble de données est disponible via la bibliothèque DL4J (tout comme Keras).
Avant de commencer, il est recommandé de consulter le code source que nous utiliserons. La classe Java principale s'appelle
org.deeplearning4j.feedforward.mnist.MLPMnistSingleLayerRunner .
L'infrastructure
Nous avons décidé d'essayer l'exemple Java en utilisant Valohai comme infrastructure pour mener des expériences (formation et évaluation de modèles). Valohai reconnaît les référentiels git et s'y connecte directement, ce qui nous permet d'exécuter notre code indépendamment de la plate-forme ou du langage - nous verrons donc comment cela fonctionne. Cela signifie également que si vous utilisez GitOps ou Infrastructure-As-Code, tout fonctionnera également pour vous.
Pour ce faire, nous avons juste besoin d'un compte chez Valohai. Après avoir créé un compte gratuit, nous avons accès à plusieurs instances de différentes configurations. Pour ce que nous aimerions faire, Free-Tier est plus que suffisant.
Deep Learning pour Java et Valohai
Nous fournirons toutes les dépendances à l'image Docker et l'utiliserons pour compiler notre application Java, former le modèle et l'évaluer sur la plateforme Valohai à l'aide d'un simple fichier
valohai.yaml situé dans le dossier racine du référentiel du projet.
Deep Learning pour Java: DL4J
La partie la plus simple. Nous n'avons pas à faire grand-chose, il suffit de collecter le bocal et de charger l'ensemble de données dans le conteneur Docker. Nous avons une image Docker pré-créée qui contient toutes les dépendances nécessaires pour créer une application Java. Nous avons mis cette image dans le Docker Hub, et vous pouvez la trouver en recherchant dl4j-mnist-single-layer (nous utiliserons une balise spéciale telle que définie dans le fichier YAML). Nous avons décidé d'utiliser GraalVM 19.1.1 comme environnement Java de génération et d'exécution pour ce projet, et il est intégré à l'image Docker.
Lorsque le uber jar est appelé à partir de la ligne de commande, nous créons la classe MLPMnistSingleLayerRunner, qui nous indique l'action prévue, en fonction des paramètres passés à:
public static void main(String[] args) throws Exception { MLPMnistSingleLayerRunner mlpMnistRunner = new MLPMnistSingleLayerRunner(); JCommander.newBuilder() .addObject(mlpMnistRunner) .build() .parse(args); mlpMnistRunner.execute(); }
Les paramètres passés à uber jar sont acceptés par cette classe et traités par la méthode execute ().
Nous pouvons créer un modèle à l'aide du paramètre --action train et évaluer le modèle créé à l'aide du paramètre --action assess transmis à l'application Java.
Les principales parties de l'application Java qui effectue ce travail se trouvent dans les deux classes Java mentionnées dans les sections ci-dessous.
Formation modèle
Appeler
./runMLPMnist.sh --action train --output-dir ${VH_OUTPUTS_DIR} or java -Djava.library.path="" \ -jar target/MLPMnist-1.0.0-bin.jar \ --action train --output-dir ${VH_OUTPUTS_DIR}
Cette commande crée un modèle nommé mlpmnist-single-layer.pb dans le dossier spécifié par le paramètre --output-dir passé au début de l'exécution. Du point de vue de Valohai, il devrait être placé dans $ {VH_OUTPUTS_DIR}, ce que nous faisons (voir le fichier
valohai.yaml ).
Pour le code source, consultez la classe
MLPMNistSingleLayerTrain.java .
Évaluation du modèle
Appeler
./runMLPMnist.sh --action evaluate --input-dir ${VH_INPUTS_DIR}/model or java -Djava.library.path="" \ -jar target/MLPMnist-1.0.0-bin.jar \ --action evaluate --input-dir ${VH_INPUTS_DIR}/model
Il est supposé que le modèle (créé pendant la phase de formation) avec le nom mlpmnist-single-layer.pb sera présent dans le dossier spécifié dans le paramètre --input-dir transmis lors de l'appel de l'application.
Pour le code source, consultez la classe
MLPMNistSingleLayerEvaluate.java .
J'espère que cette courte illustration clarifie le fonctionnement d'une application Java qui enseigne et évalue un modèle.
C'est tout ce qui nous est demandé, mais n'hésitez pas à jouer avec le reste des
sources (avec
README.md et les scripts bash) et à satisfaire votre curiosité et votre compréhension de la façon dont cela se fait!
Valohai
Valohai nous permet de lier librement notre runtime, notre code et notre jeu de données, comme vous pouvez le voir dans la structure de fichier YAML ci-dessous. Ainsi, divers composants peuvent se développer indépendamment les uns des autres. Par conséquent, seuls les composants d'assemblage et d'exécution sont emballés dans notre conteneur Docker.
Au moment de l'exécution, nous collectons le JAR Uber dans un conteneur Docker, le chargeons dans un stockage interne ou externe, puis utilisons l'autre étape d'exécution pour charger le JAR Uber et le jeu de données à partir du stockage (ou d'un autre endroit) pour commencer la formation. Ainsi, les deux étapes d'exécution sont déconnectées; par exemple, nous pouvons compiler un pot une fois et effectuer des centaines d'étapes de formation sur un seul pot. Étant donné que les environnements d'assemblage et d'exécution n'ont pas à changer si souvent, nous pouvons les mettre en cache et le code, les ensembles de données et les modèles peuvent être accessibles dynamiquement lors de l'exécution.
valohai.yamlL'intégration de notre projet Java à l'infrastructure Valohai consiste principalement à déterminer l'ordre des étapes d'exécution dans le fichier valohai.yaml situé à la racine de votre dossier de projet. Notre valohai.yaml ressemble à ceci:
--- - step: name: Build-dl4j-mnist-single-layer-java-app image: neomatrix369/dl4j-mnist-single-layer:v0.5 command: - cd ${VH_REPOSITORY_DIR} - ./buildUberJar.sh - echo "~~~ Copying the build jar file into ${VH_OUTPUTS_DIR}" - cp target/MLPMnist-1.0.0-bin.jar ${VH_OUTPUTS_DIR}/MLPMnist-1.0.0.jar - ls -lash ${VH_OUTPUTS_DIR} environment: aws-eu-west-1-g2-2xlarge - step: name: Run-dl4j-mnist-single-layer-train-model image: neomatrix369/dl4j-mnist-single-layer:v0.5 command: - echo "~~~ Unpack the MNist dataset into ${HOME} folder" - tar xvzf ${VH_INPUTS_DIR}/dataset/mlp-mnist-dataset.tgz -C ${HOME} - cd ${VH_REPOSITORY_DIR} - echo "~~~ Copying the build jar file from ${VH_INPUTS_DIR} to current location" - cp ${VH_INPUTS_DIR}/dl4j-java-app/MLPMnist-1.0.0.jar . - echo "~~~ Run the DL4J app to train model based on the the MNist dataset" - ./runMLPMnist.sh {parameters} inputs: - name: dl4j-java-app description: DL4J Java app file (jar) generated in the previous step 'Build-dl4j-mnist-single-layer-java-app' - name: dataset default: https://github.com/neomatrix369/awesome-ai-ml-dl/releases/download/mnist-dataset-v0.1/mlp-mnist-dataset.tgz description: MNist dataset needed to train the model parameters: - name: --action pass-as: '--action {v}' type: string default: train description: Action to perform ie train or evaluate - name: --output-dir pass-as: '--output-dir {v}' type: string default: /valohai/outputs/ description: Output directory where the model will be created, best to pick the Valohai output directory environment: aws-eu-west-1-g2-2xlarge - step: name: Run-dl4j-mnist-single-layer-evaluate-model image: neomatrix369/dl4j-mnist-single-layer:v0.5 command: - cd ${VH_REPOSITORY_DIR} - echo "~~~ Copying the build jar file from ${VH_INPUTS_DIR} to current location" - cp ${VH_INPUTS_DIR}/dl4j-java-app/MLPMnist-1.0.0.jar . - echo "~~~ Run the DL4J app to evaluate the trained MNist model" - ./runMLPMnist.sh {parameters} inputs: - name: dl4j-java-app description: DL4J Java app file (jar) generated in the previous step 'Build-dl4j-mnist-single-layer-java-app' - name: model description: Model file generated in the previous step 'Run-dl4j-mnist-single-layer-train-model' parameters: - name: --action pass-as: '--action {v}' type: string default: evaluate description: Action to perform ie train or evaluate - name: --input-dir pass-as: '--input-dir {v}' type: string default: /valohai/inputs/model description: Input directory where the model created by the previous step can be found created environment: aws-eu-west-1-g2-2xlarge
Fonctionnement de Build-dl4j-mnist-single-layer-java-app
À partir du fichier YAML, nous voyons que nous définissons cette étape, en utilisant d'abord l'image Docker, puis en exécutant le script pour construire le JAR Uber. Notre image Docker a la personnalisation des dépendances de l'environnement de construction (par exemple GraalVM JDK, Maven, etc.) pour créer une application Java. Nous ne fournissons aucune entrée ou paramètre, car il s'agit de la phase d'assemblage. Une fois la construction réussie, nous copions le pot uber nommé MLPMnist-1.0.0-bin.jar (nom d'origine) dans le dossier / valohai / sorties (représenté par $ {VH_OUTPUTS_DIR}). Tout dans ce dossier est automatiquement enregistré dans le stockage de votre projet, par exemple, dans la corbeille AWS S3. Enfin, nous définissons notre travail pour AWS.
RemarqueLe compte gratuit Valohai n'a pas accès au réseau depuis le conteneur Docker (ceci est désactivé par défaut), veuillez contacter le support pour activer cette option (j'ai dû faire de même), sinon nous ne pourrons pas télécharger notre Maven et d'autres dépendances pendant l'assemblage.
Fonctionnement de Run-dl4j-mnist-single-layer-train-model
La sémantique de la définition est similaire à l'étape précédente, sauf que nous spécifions deux entrées: une pour le pot uber (MLPMnist-1.0.0.jar) et l'autre pour l'ensemble de données (décompressé dans le dossier $ {HOME} /. Deeplearning4j). Nous passerons deux paramètres - --action train et --output-dir / valohai / sorties. Le modèle créé à cette étape est intégré dans / valohai / outputs / model (représenté par $ {VH_OUTPUTS_DIR} / model).
RemarqueDans les champs de saisie de l'onglet Exécution de l'interface Web de Valohai, nous pouvons sélectionner la sortie des exécutions précédentes en utilisant le numéro d'exécution, c'est-à-dire # 1 ou # 2, en plus d'utiliser les données: // ou http: / URL /, la saisie de quelques lettres du nom du fichier permet également de rechercher dans la liste entière.
Fonctionnement de Run-dl4j-mnist-single-layer -valu-model
Encore une fois, cette étape est similaire à l'étape précédente, sauf que nous passerons deux paramètres --action evaluation et --input-dir / valohai / inputs / model. De plus, nous avons à nouveau indiqué dans l'entrée: les sections définies dans le fichier YAML avec le nom dl4j-java-app et le modèle sans la valeur par défaut pour les deux. Cela nous permettra de sélectionner le pot uber et le modèle que nous voulons évaluer - qui a été créé à l'aide de l'étape Run-dl4j-mnist-single-layer-train-model en utilisant l'interface Web.
J'espère que cela explique les étapes du fichier de définition ci-dessus, mais si vous avez besoin d'aide, n'hésitez pas à consulter la
documentation et les
didacticiels .
Interface Web Valohai
Après avoir reçu le compte, nous pouvons nous connecter et continuer à créer le projet avec le nom mlpmnist-single-layer et associer git repo
github.com/valohai/mlpmnist-dl4j-example au projet et enregistrer le projet.
Vous pouvez maintenant terminer l'étape et voir comment cela se passe!
Créer une application Java DL4J
Accédez à l'onglet «Exécution» dans l'interface Web et copiez l'exécution existante ou créez-en une à l'aide du bouton [Créer exécution]. Tous les paramètres par défaut nécessaires seront remplis. Sélectionnez Étape Build-dl4j-mnist-single-layer-java-app.
Pour l'
environnement, j'ai sélectionné AWS eu-west-1 g2.2xlarge et cliqué sur le bouton [Créer l'exécution] en bas de la page pour voir le début de l'exécution.
Formation modèle
Accédez à l'onglet «Exécution» dans l'interface Web et procédez de la même manière qu'à l'étape précédente, puis sélectionnez Run-dl4j-mnist-single-layer-train-model. Vous devrez sélectionner l'application Java (entrez simplement le pot dans le champ) créée à l'étape précédente. L'ensemble de données a déjà été prérempli à l'aide du fichier valohai.yaml:
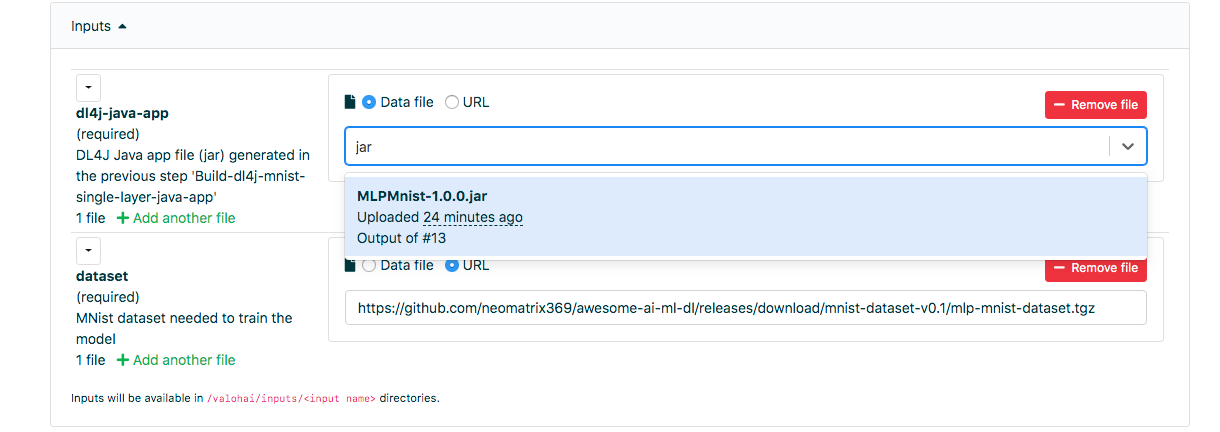
Cliquez sur [Créer exécution] pour démarrer.
Vous verrez le résultat dans la console:
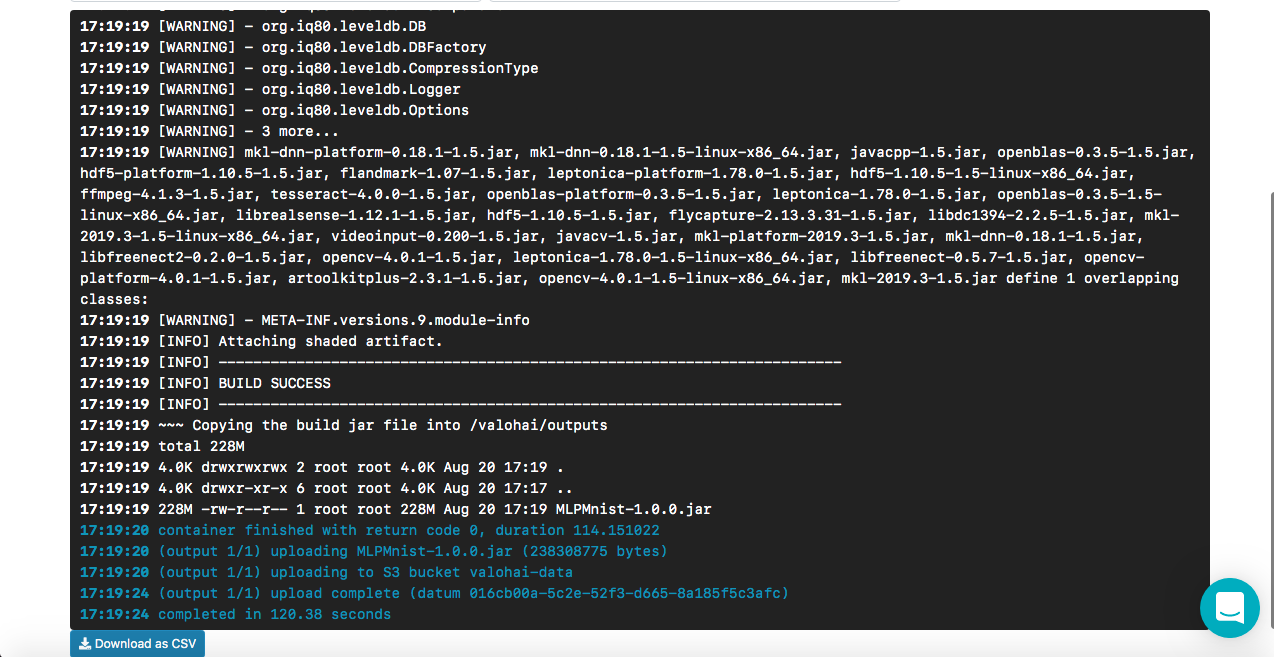
[<--- snipped --->] 11:17:05 ======================================================================= 11:17:05 LayerName (LayerType) nIn,nOut TotalParams ParamsShape 11:17:05 ======================================================================= 11:17:05 layer0 (DenseLayer) 784,1000 785000 W:{784,1000}, b:{1,1000} 11:17:05 layer1 (OutputLayer) 1000,10 10010 W:{1000,10}, b:{1,10} 11:17:05 ----------------------------------------------------------------------- 11:17:05 Total Parameters: 795010 11:17:05 Trainable Parameters: 795010 11:17:05 Frozen Parameters: 0 11:17:05 ======================================================================= [<--- snipped --->]
Les modèles créés peuvent être trouvés sur l'onglet «Sorties» de l'onglet principal «Exécution» pendant et après l'exécution:
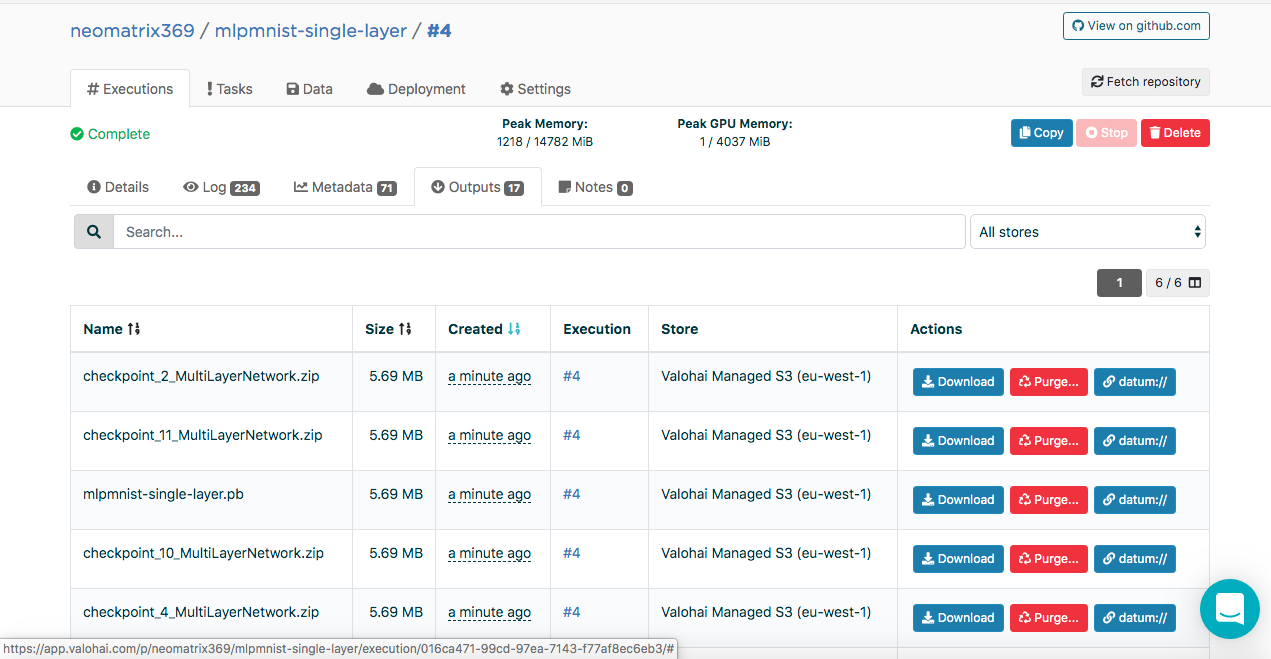
Vous pouvez remarquer plusieurs artefacts dans le sous-onglet Sorties. En effet, nous maintenons des points de contrôle à la fin de chaque ère. Regardons cela dans les journaux:
[<--- snipped --->] 11:17:14 odolCheckpointListener - Model checkpoint saved: epoch 0, iteration 469, path: /valohai/outputs/checkpoint_0_MultiLayerNetwork.zip [<--- snipped --->]
Le point de contrôle contient l'état du modèle dans trois fichiers:
configuration.json coefficients.bin updaterState.bin
Formation de modèle. Métadonnées
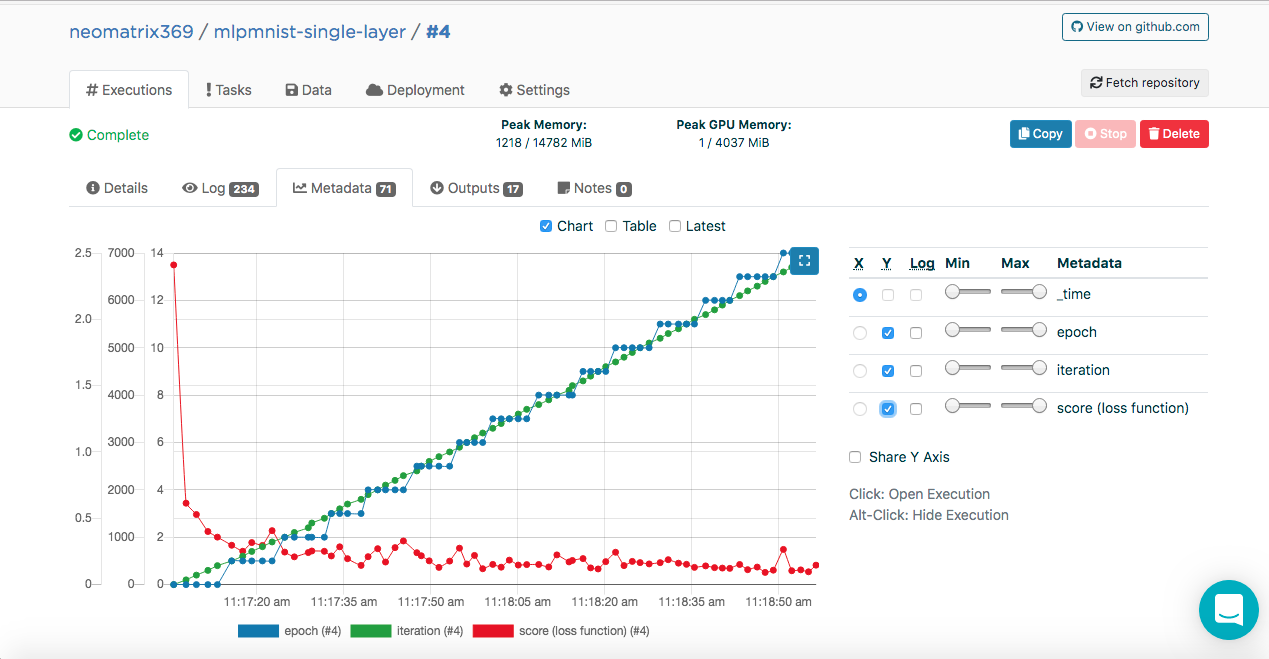
Vous avez peut-être remarqué ces entrées dans les journaux d'exécution:
[<--- snipped --->] 11:17:05 {"epoch": 0, "iteration": 0, "score (loss function)": 2.410047} 11:17:07 {"epoch": 0, "iteration": 100, "score (loss function)": 0.613774} 11:17:09 {"epoch": 0, "iteration": 200, "score (loss function)": 0.528494} 11:17:11 {"epoch": 0, "iteration": 300, "score (loss function)": 0.400291} 11:17:13 {"epoch": 0, "iteration": 400, "score (loss function)": 0.357800} 11:17:14 odolCheckpointListener - Model checkpoint saved: epoch 0, iteration 469, path: /valohai/outputs/checkpoint_0_MultiLayerNetwork.zip [<--- snipped --->]
Ces données permettent à Valohai d'obtenir ces valeurs (au format JSON) qui seront utilisées pour construire les métriques qui peuvent être vues pendant et après l'exécution sur l'onglet Métadonnées supplémentaire de l'onglet principal Exécutions:
Nous avons pu le faire en connectant la classe ValohaiMetadataCreator au modèle, de sorte que Valohai se réfère à cette classe pendant la formation. Dans le cas de cette classe, on dérive plusieurs époques, le nombre d'itérations et le Score (valeur de la fonction de perte). Voici un extrait de code de la classe:
public void iterationDone(Model model, int iteration, int epoch) { if (printIterations <= 0) printIterations = 1; if (iteration % printIterations == 0) { double score = model.score(); System.out.println(String.format( "{\"epoch\": %d, \"iteration\": %d, \"score (loss function)\": %f}", epoch, iteration, score) ); } }
Évaluation du modèle
Une fois le modèle créé avec succès à l'étape précédente, il doit être évalué. Nous créons une nouvelle exécution de la même manière que précédemment, mais cette fois, sélectionnez l'étape Run-dl4j-mnist-single-layer -valu-model. Nous devrons sélectionner à nouveau l'application Java (MLPMnist-1.0.0.jar) et le modèle créé (mlpmnist-single-layer.pb) avant de démarrer l'exécution (comme illustré ci-dessous):
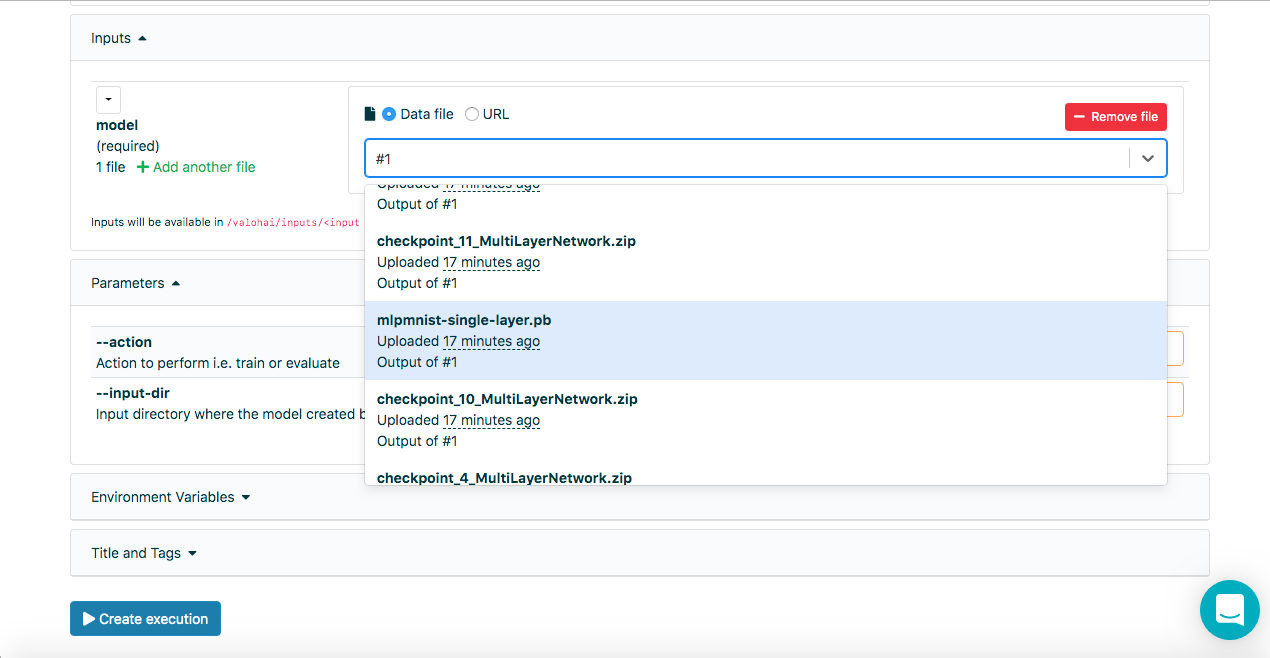
Après avoir sélectionné le modèle souhaité en entrée, cliquez sur le bouton [Créer exécution]. Il s'exécutera plus rapidement que le précédent, et nous verrons le résultat suivant:
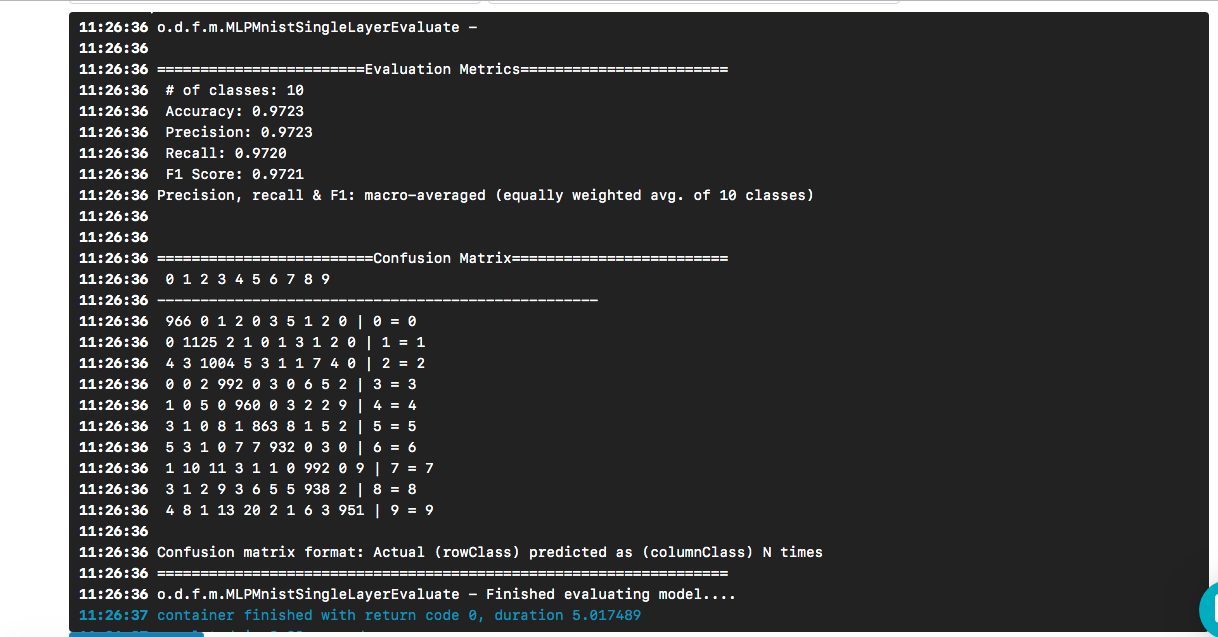
Nous voyons que notre "bonjour" a conduit à un modèle dont la précision est d'environ 97% sur la base d'un ensemble de données de test. La matrice de confusion aide à trouver les cas où un chiffre a été incorrectement prédit comme un autre chiffre.
La question demeure (et au-delà de la portée de cet article) - quelle est la qualité du modèle face à des données réelles?
Pour cloner un référentiel git, voici ce que vous devez faire:
$ git clone https://github.com/valohai/mlpmnist-dl4j-example
Ensuite, nous devons lier notre projet Valohai, créé via l'interface Web dans la section ci-dessus, avec le projet stocké sur notre machine locale (celle que nous venons de cloner). Exécutez les commandes suivantes pour ce faire:
$ cd mlpmnist-dl4j-example $ vh project --help ### to see all the project-specific options we have for Valohai $ vh project link
On vous montrera quelque chose comme ceci:
[ 1] mlpmnist-single-layer ... Which project would you like to link with /path/to/mlpmnist-dl4j-example? Enter [n] to create a new project.:
Sélectionnez 1 (ou celui qui vous convient) et vous devriez voir ce message:
Success! Linked /path/to/mlpmnist-dl4j-example to mlpmnist-single-layer.
Avant de continuer, assurez-vous que votre projet Valohai est synchronisé avec le dernier projet git en procédant comme suit:
$ vh project fetch
Maintenant, nous pouvons terminer les étapes de la CLI avec:
$ vh exec run Build-dl4j-mnist-single-layer-java-app
Une fois l'exécution terminée, nous pouvons le vérifier avec:
$ vh exec info $ vh exec logs $ vh exec watch
Conclusion
Comme nous l'avons vu, il est très pratique de travailler ensemble avec DL4J et Valohai. De plus, nous pouvons développer divers composants qui composent nos expériences (recherche), c'est-à-dire l'environnement de construction / d'exécution, le code et l'ensemble de données, et les intégrer dans notre projet.
Les exemples de modèles utilisés dans cet article sont un bon moyen de commencer à créer des projets plus complexes. Et vous pouvez utiliser l'interface Web ou la ligne de commande pour faire votre travail avec Valohai. Avec la CLI, vous pouvez également l'intégrer à vos installations et scripts (ou même aux travaux CRON ou CI / CD).
De plus, il est clair que si je travaille sur un projet lié à l'IA / ML / DL, je n'ai pas à me soucier de créer et de maintenir un pipeline de bout en bout (ce que beaucoup d'autres ont dû faire par le passé).
Les références
- Le projet mlpmnist-dl4j-examples sur GitHub
- Ressources AI / ML / DL impressionnantes
- Ressources Java AI / ML / DL
- Deep Learning et ressources DL4J
Merci de votre attention!