Il semble que le domaine de la publicité en ligne devrait être aussi technologique et automatisé que possible. En effet, des géants et des experts dans leur domaine comme Yandex, Mail.Ru, Google et Facebook y travaillent. Mais, il s'est avéré qu'il n'y a pas de limite à la perfection et qu'il y a toujours quelque chose à automatiser.
 Source
SourceLe groupe de communication
Dentsu Aegis Network Russia est le plus grand acteur du marché de la publicité numérique et investit activement dans la technologie, en essayant d'optimiser et d'automatiser ses processus commerciaux. L'un des problèmes non résolus du marché de la publicité en ligne était la tâche de collecter des statistiques sur les campagnes publicitaires de différents sites en ligne. La solution à ce problème a finalement abouti à la création du produit
D1.Digital (lu comme DiVan), dont nous voulons parler de développement.
Pourquoi?
1. Au moment du démarrage du projet, il n'y avait pas un seul produit fini sur le marché qui ait résolu la tâche d'automatiser la collecte de statistiques sur les campagnes publicitaires.
Cela signifie que personne d'autre que nous ne fermera nos besoins.Des services tels que Improvado, Roistat, Supermetrics, SegmentStream, offrent une intégration avec des sites, des réseaux sociaux et Google Analitycs, et offrent également la possibilité de créer des tableaux de bord analytiques pour une analyse et un contrôle pratiques des campagnes publicitaires. Avant de commencer à développer notre produit, nous avons essayé d'utiliser certains de ces systèmes dans notre travail pour collecter des données à partir de sites, mais, malheureusement, ils n'ont pas pu résoudre nos problèmes.
Le principal problème était que les produits testés étaient repoussés des sources de données, affichant des statistiques de placements dans les sections par sites, et ne permettaient pas l'agrégation de statistiques sur les campagnes publicitaires. Cette approche n'a pas permis de voir les statistiques de différents sites en un seul endroit et d'analyser l'état de la campagne dans son ensemble.
Un autre facteur était qu'au début, les produits étaient orientés vers le marché occidental et ne soutenaient pas l'intégration avec des sites russes. Et pour les sites avec lesquels l'intégration a été mise en œuvre, toutes les métriques nécessaires avec suffisamment de détails n'étaient pas toujours téléchargées, et l'intégration n'était pas toujours pratique et transparente, surtout lorsqu'il était nécessaire d'obtenir quelque chose qui n'était pas dans l'interface système.
En général, nous avons décidé de ne pas nous adapter aux produits tiers, mais nous avons commencé à développer le nôtre ...
2. Le marché de la publicité en ligne croît d'année en année et, en 2018, il a traditionnellement dépassé le plus grand marché de la publicité télévisée en termes de budgets publicitaires.
Il y a donc une échelle .
3. Contrairement au marché de la publicité télévisée, où la vente de publicité commerciale est monopolisée, la masse des propriétaires individuels de matériel publicitaire de différentes tailles avec leurs régies publicitaires travaille sur Internet. Étant donné que la campagne publicitaire, en règle générale, s'exécute sur plusieurs sites à la fois, afin de comprendre l'état de la campagne publicitaire, il est nécessaire de collecter les rapports de tous les sites et de les regrouper en un seul grand rapport qui montrera l'image entière.
Il y a donc un potentiel d'optimisation.4. Il nous a semblé que les propriétaires de l'inventaire publicitaire sur Internet disposaient déjà d'une infrastructure pour collecter des statistiques et les afficher dans les régies publicitaires, et ils pouvaient fournir une API pour ces données.
Il y a donc une faisabilité technique. Nous dirons tout de suite que ce n'était pas si simple.
En général, toutes les conditions préalables à la mise en œuvre du projet étaient évidentes pour nous, et nous avons couru pour mettre en œuvre le projet ...
Grand plan
Tout d'abord, nous avons formé une vision d'un système idéal:
- Il devrait charger automatiquement les campagnes publicitaires du système d'entreprise 1C avec leurs noms, périodes, budgets et emplacements sur diverses plates-formes.
- Pour chaque emplacement dans la campagne publicitaire, toutes les statistiques possibles des sites sur lesquels l'emplacement est en cours doivent être téléchargées automatiquement, telles que le nombre d'impressions, de clics, de vues, etc.
- Certaines campagnes publicitaires sont surveillées par un contrôle tiers par les systèmes dits de publicité, tels que Adriver, Weborama, DCM, etc. Il existe également un compteur Internet industriel en Russie - Mediascope. Selon notre idée, les données de surveillance indépendante et industrielle devraient également être automatiquement téléchargées dans les campagnes publicitaires correspondantes.
- La plupart des campagnes publicitaires sur Internet visent certaines actions ciblées (achat, appel, enregistrement pour un essai routier, etc.), qui sont suivies à l'aide de Google Analytics, et des statistiques sur lesquelles sont également importantes pour comprendre l'état de la campagne et doivent être téléchargées sur notre outil .
La première crêpe est grumeleuse
Compte tenu de notre engagement envers des principes flexibles de développement de logiciels (agile, tout), nous avons décidé de développer MVP d'abord, puis de progresser vers l'objectif prévu de manière itérative.
Nous avons décidé de construire MVP sur la base de notre produit
DANBo (Dentsu Aegis Network Board) , qui est une application web avec des informations générales sur les campagnes publicitaires de nos clients.
Pour MVP, le projet a été simplifié au maximum en termes de mise en œuvre. Nous avons sélectionné une liste limitée de sites à intégrer. Ce sont les principales plates-formes, telles que Yandex.Direct, Yandex.Display, RB.Mail, MyTarget, Adwords, DBM, VK, FB et les principaux systèmes de publicité Adriver et Weborama.
Pour accéder aux statistiques sur les sites via l'API, nous avons utilisé un seul compte. Le responsable du groupe client, qui souhaitait utiliser la collecte automatique de statistiques sur la campagne publicitaire, a d'abord dû déléguer l'accès au compte de la plateforme aux campagnes publicitaires nécessaires sur les sites.
De plus, l'utilisateur du système
DANBo devait télécharger un fichier d'un certain format dans le système Excel, dans lequel toutes les informations sur le placement (campagne publicitaire, site, format, période de placement, indicateurs prévus, budget, etc.) et les identifiants des campagnes publicitaires correspondantes sur les sites étaient écrits et les compteurs dans les systèmes de publicité.
C'était franchement terrifiant:

Les données téléchargées ont été stockées dans la base de données, puis les services individuels ont collecté des identifiants de campagne auprès des sites et téléchargé des statistiques à leur sujet.
Un service Windows distinct a été écrit pour chaque site, qui une fois par jour passait sous un compte de service dans l'API du site et téléchargeait des statistiques sur les identifiants de campagne spécifiés. La même chose s'est produite avec les systèmes de publicité.
Les données téléchargées ont été affichées sur l'interface sous la forme d'un petit tableau de bord auto-écrit:
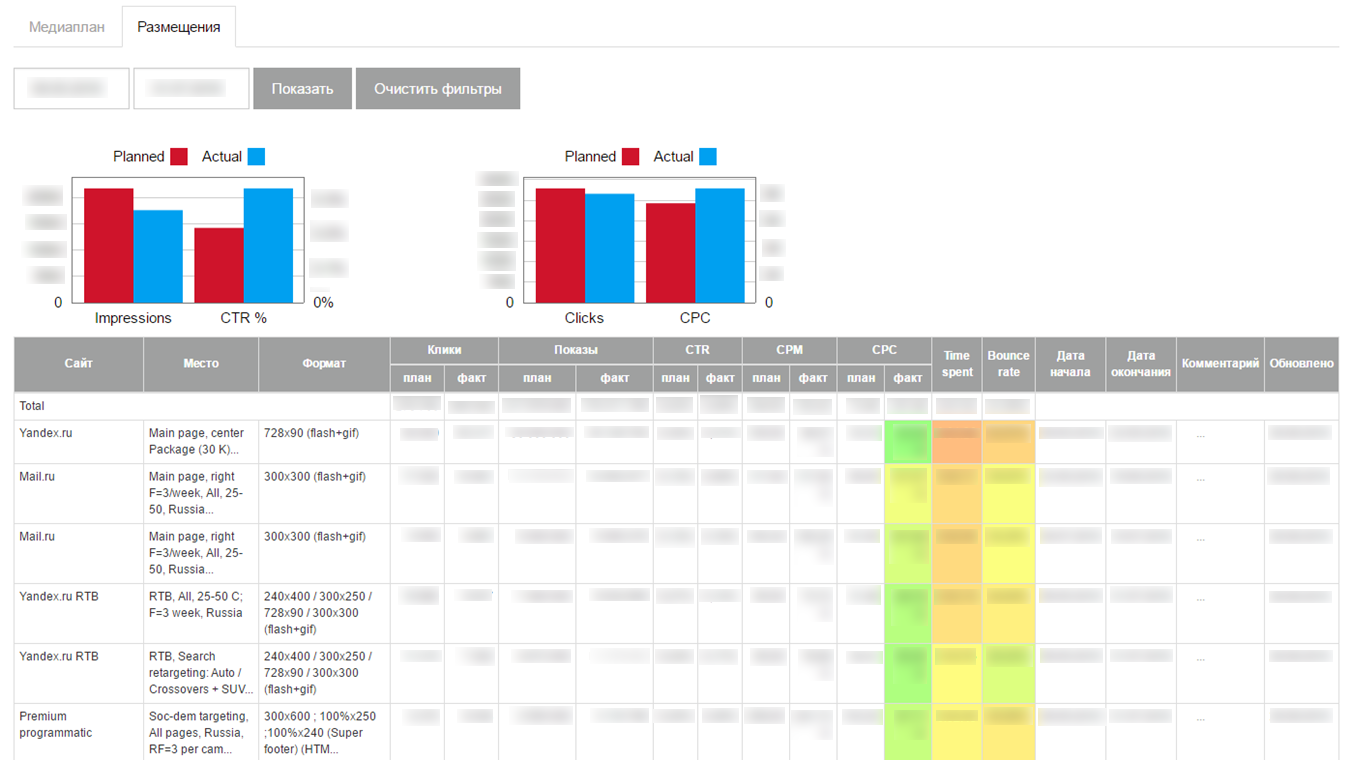
De façon inattendue pour nous, MVP a gagné et commencé à télécharger des statistiques actuelles sur les campagnes publicitaires sur Internet. Nous avons implémenté le système sur plusieurs clients, mais lorsque nous avons essayé de nous adapter, nous avons rencontré de sérieux problèmes:
- Le principal problème était la difficulté de préparer les données à charger dans le système. De plus, les données de placement devaient être réduites à un format strictement fixe avant le téléchargement. Dans le fichier à charger, il était nécessaire d'enregistrer les identifiants des entités de différents sites. Nous sommes confrontés au fait qu'il est très difficile pour des utilisateurs techniquement inexpérimentés d'expliquer où trouver ces identifiants sur le site et où les mettre dans le fichier. Compte tenu du nombre d'employés dans les divisions menant des campagnes sur les sites, et du chiffre d'affaires, cela s'est traduit par un énorme soutien de notre côté, ce qui ne nous convenait absolument pas.
- Un autre problème était que toutes les plateformes publicitaires ne disposaient pas de mécanismes pour déléguer l'accès à des campagnes publicitaires à d'autres comptes. Mais même si le mécanisme de délégation était disponible, tous les annonceurs n'étaient pas disposés à fournir un accès à un compte tiers à leurs campagnes.
- Un facteur important a été l'indignation qui a amené les utilisateurs à ce que tous les indicateurs planifiés et les détails de placement qu'ils contribuent déjà à notre système comptable 1C soient à nouveau saisis dans DANBo .
Cela nous a donné l'idée que la principale source d'informations sur l'emplacement devrait être notre système 1C, dans lequel toutes les données sont saisies avec précision et à temps (le fait est que sur la base des données 1C, des comptes sont formés, par conséquent, la saisie correcte des données dans 1C est pour tout le monde dans KPI). Un nouveau concept de système est donc apparu ...
Concept
La première chose que nous avons décidé de faire était de séparer le système de collecte de statistiques sur les campagnes publicitaires sur Internet en un produit distinct -
D1.Digital .
Dans le nouveau concept, nous avons décidé de charger des informations sur les campagnes publicitaires et les emplacements qu'elles
contiennent de 1C à
D1.Digital , puis de tirer des statistiques des sites et des systèmes AdServing vers ces emplacements. Cela était censé simplifier considérablement la vie des utilisateurs (et, comme d'habitude, ajouter du travail aux développeurs) et réduire la quantité de support.
Le premier problème que nous avons rencontré était de nature organisationnelle et était lié au fait que nous ne pouvions pas trouver une clé ou un attribut permettant de comparer des entités de différents systèmes avec des campagnes et des placements de 1C. Le fait est que le processus dans notre entreprise est organisé de manière à ce que les campagnes publicitaires soient introduites dans différents systèmes par différentes personnes (lecteurs multimédias, achats, etc.).
Pour résoudre ce problème, nous avons dû inventer une clé de hachage unique, DANBoID, qui relierait les entités de différents systèmes et qui pourrait être identifiée assez facilement et sans ambiguïté dans les ensembles de données chargés. Cet identifiant est généré dans le système interne 1C pour chaque emplacement individuel et se jette dans les campagnes, les emplacements et les compteurs sur tous les sites et dans tous les systèmes AdServing. La mise en œuvre de la pratique d'apposition de DANBoID sur tous les emplacements a pris du temps, mais nous l'avons fait :)
Ensuite, nous avons découvert que tous les sites ne disposent pas d'une API pour la collecte automatique de statistiques, et même ceux qui ont une API ne renvoient pas toutes les données nécessaires.
A ce stade, nous avons décidé de réduire considérablement la liste des sites à intégrer et de nous concentrer sur les principaux sites impliqués dans la grande majorité des campagnes publicitaires. Cette liste comprend tous les plus grands acteurs du marché publicitaire (Google, Yandex, Mail.ru), les réseaux sociaux (VK, Facebook, Twitter), les principaux systèmes de publicité et d'analyse (DCM, Adriver, Weborama, Google Analytics) et d'autres plateformes.
La plupart des sites que nous avons sélectionnés disposaient d'une API qui nous fournissait les mesures nécessaires. Dans les cas où l'API n'était pas là ou ne disposait pas des données nécessaires, nous avons utilisé des rapports qui arrivaient quotidiennement sur le courrier professionnel pour télécharger les données (dans certains systèmes, il est possible de configurer de tels rapports, dans d'autres, ils se sont mis d'accord sur le développement de ces rapports pour nous).
Lors de l'analyse des données de différents sites, nous avons constaté que la hiérarchie des entités n'est pas la même dans les différents systèmes. De plus, les informations provenant de différents systèmes doivent être chargées de manière différente.
Pour résoudre ce problème, le concept SubDANBoID a été développé. L'idée de SubDANBoID est assez simple, nous marquons l'essence principale de la campagne sur le site avec le DANBoID généré, et nous téléchargeons toutes les entités imbriquées avec des identifiants uniques du site et formons le SubDANBoID selon le principe DANBoID + identifiant de l'entité imbriquée de premier niveau + identifiant de l'entité imbriquée de deuxième niveau + ... Cette approche nous a permis de nous associer campagnes publicitaires dans différents systèmes et télécharger des statistiques détaillées à leur sujet.
Nous avons également dû résoudre le problème d'accès aux campagnes sur différents sites. Comme nous l'avons écrit ci-dessus, le mécanisme de délégation de l'accès à la campagne à un compte technique distinct n'est pas toujours applicable. Par conséquent, nous avons dû développer une infrastructure d'autorisation automatique via OAuth à l'aide de jetons et de mécanismes de mise à jour pour ces jetons.
Plus loin dans l'article, nous tenterons de décrire plus en détail l'architecture de la solution et les détails techniques de l'implémentation.
Architecture de solution 1.0
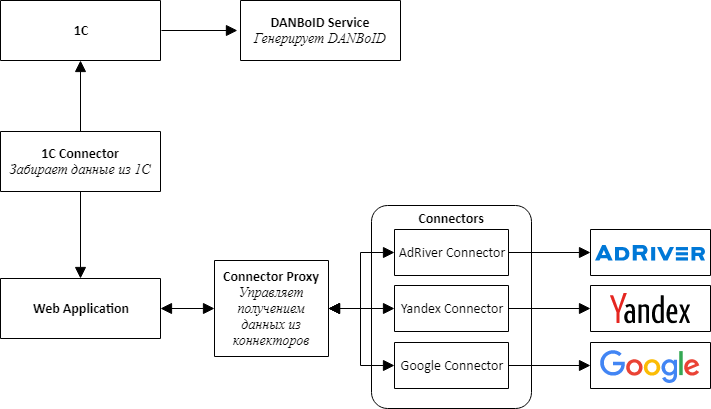
Dès la mise en place d'un nouveau produit, nous avons compris qu'il fallait immédiatement prévoir la possibilité de connecter de nouveaux sites, nous avons donc décidé de suivre la voie de l'architecture de microservices.
Lors de la conception de l'architecture, nous avons choisi des connecteurs de services distincts pour tous les systèmes externes - 1C, plates-formes publicitaires et systèmes de publicité.
L'idée principale est que tous les connecteurs des sites ont la même API et sont des adaptateurs qui amènent les API du site à notre interface pratique.
Au centre de notre produit se trouve une application Web, qui est un monolithe, qui est conçue pour pouvoir être facilement démontée en services. Cette application est chargée de traiter les données téléchargées, de comparer les statistiques de différents systèmes et de les présenter aux utilisateurs du système.
Pour communiquer les connecteurs avec une application Web, nous avons dû créer un service supplémentaire, que nous avons appelé Connector Proxy. Il remplit les fonctions de découverte de service et de planificateur de tâches. Ce service exécute des tâches de collecte de données pour chaque connecteur chaque nuit. Il était plus facile d'écrire une couche de service que de connecter un courtier de messages, et pour nous, il était important d'obtenir le résultat le plus rapidement possible.
Pour des raisons de simplicité et de rapidité de développement, nous avons également décidé que tous les services seraient une API Web. Cela a permis de monter rapidement une preuve de concept et de vérifier que la conception entière fonctionnait.
Une tâche distincte, plutôt difficile, consistait à configurer l'accès pour collecter les données de différentes armoires, qui, comme nous l'avons décidé, devraient être effectuées par les utilisateurs via une interface Web. Il se compose de deux étapes distinctes: d'abord, l'utilisateur via OAuth ajoute un jeton pour accéder au compte, puis configure la collecte de données pour le client à partir d'un compte spécifique. L'obtention d'un token via OAuth est nécessaire, car, comme nous l'avons déjà écrit, il n'est pas toujours possible de déléguer l'accès au cabinet souhaité sur le site.
Pour créer un mécanisme universel pour choisir une armoire à partir de sites, nous avons dû ajouter une méthode à l'API de connecteurs qui rend le schéma JSON, qui est rendu dans le formulaire à l'aide d'un composant JSONEditor modifié. Les utilisateurs ont donc pu choisir les comptes à partir desquels télécharger les données.
Pour respecter les limites de demande qui existent sur les sites, nous combinons la demande de paramètres dans le même jeton, mais nous pouvons traiter différents jetons en parallèle.
Nous avons choisi MongoDB comme référentiel de données téléchargeables pour une application Web et des connecteurs, ce qui nous a permis de ne pas trop nous soucier de la structure des données dans les premiers stades de développement, lorsque le modèle d'application change après une journée.
Bientôt, nous avons découvert que toutes les données ne s'intègrent pas bien dans MongoDB et, par exemple, les statistiques quotidiennes sont plus pratiques à stocker dans une base de données relationnelle. Par conséquent, pour les connecteurs dont la structure de données est plus adaptée à une base de données relationnelle, nous avons commencé à utiliser PostgreSQL ou MS SQL Server comme stockage.
L'architecture et la technologie sélectionnées nous ont permis de construire et de lancer relativement rapidement le produit D1.Digital. Au cours des deux années de développement de produits, nous avons développé 23 connecteurs de sites, acquis une expérience inestimable de travail avec des API tierces, appris à contourner les écueils de différents sites qui avaient chacun leurs propres, contribué au développement de l'API sur au moins 3 sites, téléchargé automatiquement des informations sur près de 15000 campagnes et dans plus de 80 000 emplacements, nous avons recueilli de nombreux commentaires des utilisateurs sur le produit et avons réussi à modifier le processus principal du produit plusieurs fois, sur la base de ces commentaires.
Architecture de la solution 2.0
Deux ans se sont écoulés depuis le début du développement de
D1.Digital . L'augmentation constante de la charge sur le système et l'émergence de nouvelles sources de données ont révélé progressivement des problèmes dans l'architecture de solution existante.
Le premier problème est lié à la quantité de données téléchargées depuis les sites. Nous étions confrontés au fait que la collecte et la mise à jour de toutes les données nécessaires des plus grands sites commençaient à prendre trop de temps. Par exemple, la collecte de données sur le système de publicité AdRiver, avec lequel nous suivons les statistiques pour la plupart des emplacements, prend environ 12 heures.
Pour résoudre ce problème, nous avons commencé à utiliser toutes sortes de rapports pour télécharger des données à partir des sites, nous essayons de développer leurs API avec les sites afin que sa vitesse réponde à nos besoins et à paralléliser le chargement des données autant que possible.
Un autre problème est le traitement des données téléchargées. Maintenant, avec l'arrivée de nouvelles statistiques sur le placement, un processus à plusieurs étapes de recalcul des statistiques est lancé, qui comprend le chargement des données brutes, le calcul des statistiques agrégées pour chaque site, la comparaison des données provenant de différentes sources et le calcul des statistiques récapitulatives pour la campagne. Cela entraîne une charge importante sur l'application Web, qui effectue tous les calculs. Plusieurs fois, au cours du recomptage, l’application consomme toute la mémoire du serveur, environ 10 à 15 Go, ce qui a le plus d’effets sur le travail de l’utilisateur avec le système.
Les problèmes identifiés et les plans grandioses pour la poursuite du développement du produit nous ont conduit à la nécessité de réviser l'architecture de l'application.
Nous avons commencé avec les connecteurs.
Nous avons remarqué que tous les connecteurs fonctionnent selon le même modèle, nous avons donc construit un pipeline-convoyeur dans lequel pour créer le connecteur, il vous suffisait de programmer la logique des étapes, le reste était universel. Si un connecteur doit être amélioré, nous le transférerons immédiatement dans un nouveau cadre tout en finalisant le connecteur.
En parallèle, nous avons commencé à placer des connecteurs dans Docker et Kubernetes.
Nous avions prévu de passer à Kubernetes pendant longtemps, expérimenté avec les paramètres CI / CD, mais avons commencé à bouger uniquement lorsqu'un connecteur a commencé à consommer plus de 20 Go de mémoire sur le serveur en raison d'une erreur, tuant presque le reste des processus. Au cours de l'enquête, le connecteur a été déplacé vers le cluster Kubernetes, où il est finalement resté, même lorsque l'erreur a été corrigée.
Très rapidement, nous avons réalisé que Kubernetes était pratique et en six mois, nous avons déplacé 7 connecteurs et Proxy Connecteurs vers le cluster de production, qui consomme le plus de ressources.
Suite aux connecteurs, nous avons décidé de changer l'architecture du reste de l'application.
Le principal problème était que les données provenaient des connecteurs vers des proxys dans de grands ensembles, puis elles battaient sur DANBoID et étaient transférées vers une application Web centrale pour le traitement. En raison du grand nombre de recalculs de métriques, une charge importante sur l'application se produit.
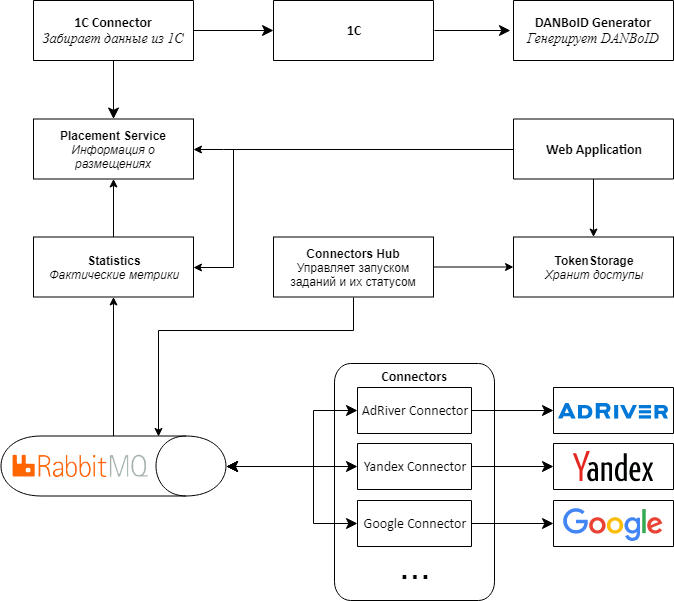
, , web , , , - .
2.0.
, Web API RabbitMQ MassTransit . Connectors Proxy, Connectors Hub. , , .
web , . .
Kubernetes, .
Proof-of-concept 2.0
D1.Digital . — 20 , , , , .
, API, .
, , adserving .
, web , Kubernetes. , , .
, MongoDB. SQL-, , , , .
, , :)
R&D Dentsu Aegis Network Russia: ( shmiigaa ), ( hitexx )