
Il y a deux ans, en allumant accidentellement la télévision, j'ai vu une histoire intéressante dans le programme Vesti. Il a été dit que le Département des technologies de l'information de Moscou crée un réseau de neurones qui lira les relevés des compteurs d'eau à partir de photographies. Dans l'histoire, le présentateur de télévision a demandé aux habitants de la ville d'aider le projet et d'envoyer des photos de leurs compteurs au portail mos.ru afin de former un réseau de neurones sur eux.
Si vous êtes un département de Moscou, publier une vidéo sur la chaîne fédérale et demander aux gens d'envoyer des images de compteurs n'est pas un très gros problème. Mais que faire si vous êtes une petite startup et que vous ne pouvez pas faire de publicité sur une chaîne de télévision? Comment obtenir 50 000 images de compteurs dans ce cas? Yandex.Toloka vient à la rescousse!
Yandex.Toloka est une plateforme de crowdsourcing sur laquelle des personnes du monde entier effectuent des tâches simples, recevant de l'argent pour cela. Par exemple, les tolokers peuvent trouver des piétons dans l'image, former des assistants vocaux, etc. En même temps, non seulement les employés de Yandex, mais tous ceux qui le souhaitent peuvent publier des tâches sur Toloka.
Énoncé du problème
Donc, nous voulons créer un réseau de neurones, qui à partir de la photo déterminera les lectures des compteurs. Par où commencer, de quelles données avons-nous besoin?
Après avoir consulté des collègues, nous concluons que pour créer MVP, nous avons besoin de 1000 images de compteur. De plus, pour chaque compteur, nous voulons connaître les lectures actuelles, ainsi que les coordonnées de la fenêtre avec des nombres. 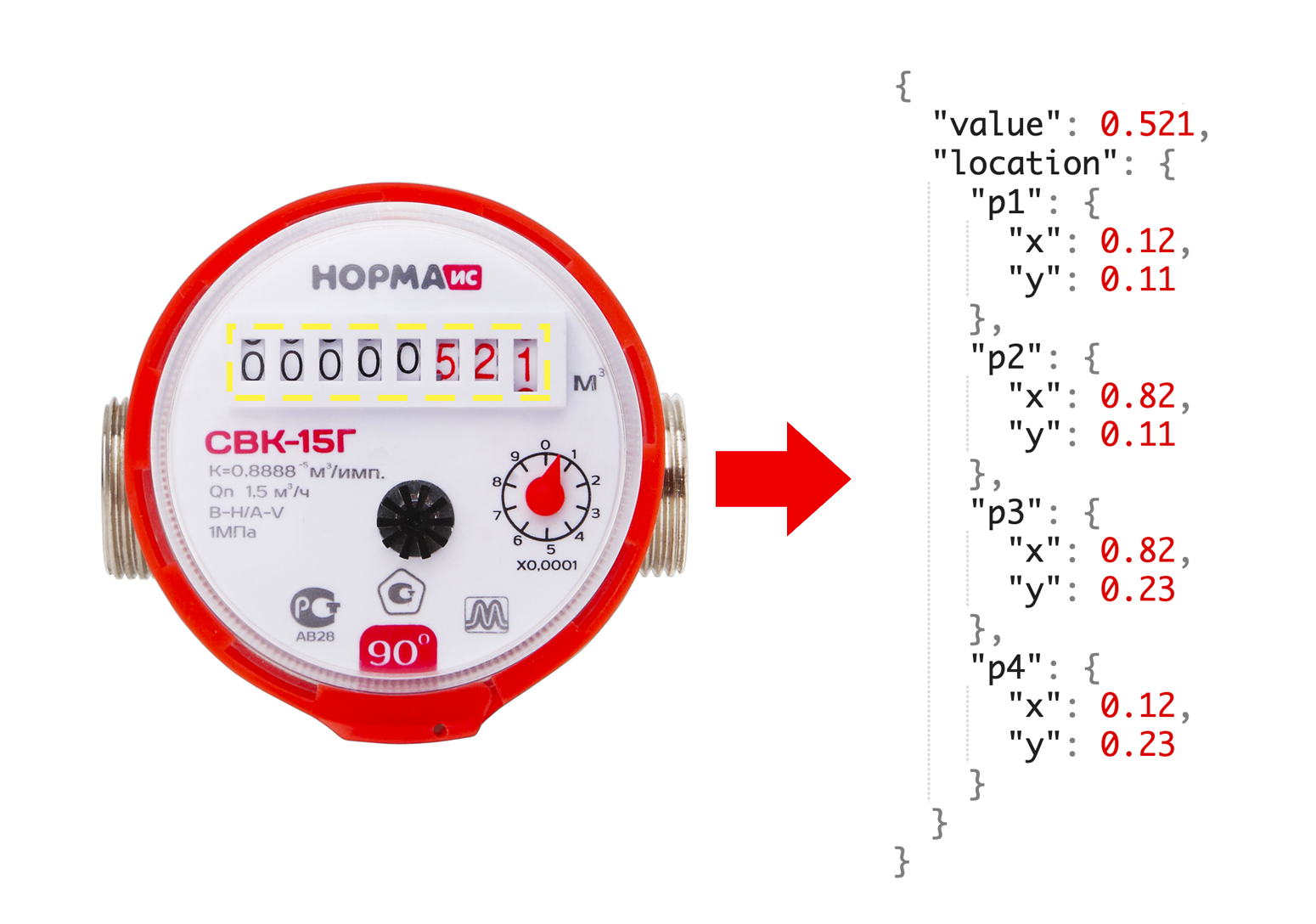
Si vous n'avez jamais travaillé avec Toloka, je vous conseille de lire l' article que j'ai écrit il y a un an. Étant donné que l'article actuel sera techniquement plus compliqué, je vais omettre certains points décrits en détail dans l'article précédent.
RemerciementsL'article précédent est devenu TOP-2 dans le classement des articles de la communauté ODS . Merci d'avoir commenté et mis les pros!)
Partie 1. Acquisition d'images
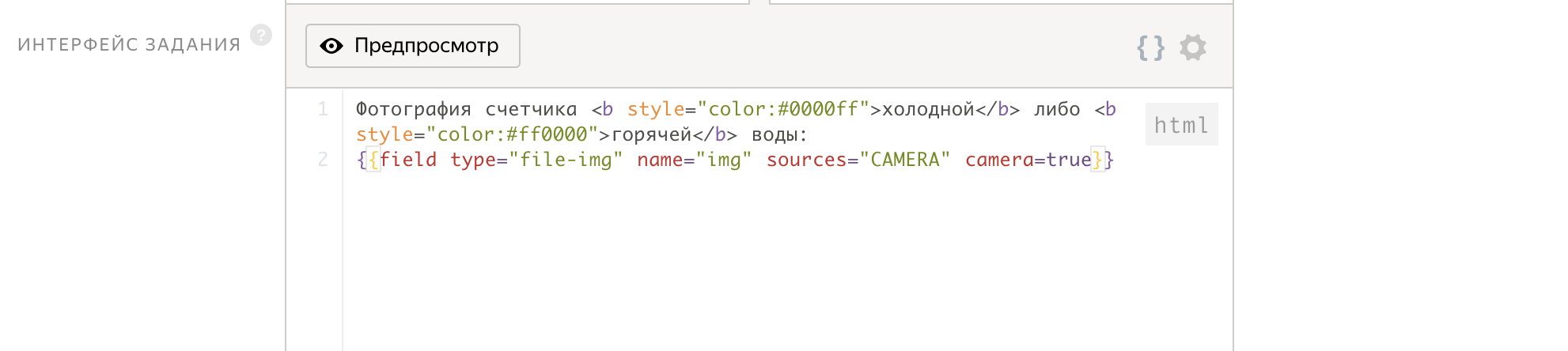
Quoi de plus simple? Il suffit de demander à la personne d'ouvrir l'application Yandex.Tolok sur son téléphone et de prendre une photo de son compteur. Si je ne travaillais pas avec Toloka depuis plusieurs années, mon instruction serait: "Vous devez photographier votre compteur d'eau (chaud ou froid) et nous envoyer une image . "
Malheureusement, avec une telle déclaration du problème, un bon ensemble de données ne peut pas être collecté. Le fait est que les gens peuvent interpréter ce savoir traditionnel de différentes manières, car les instructions n'ont pas de critères clairs pour une tâche correctement exécutée. Les Tolockers peuvent envoyer:
- images floues;
- Images qui ne montrent aucune preuve
- Images avec plusieurs compteurs.
Le blog Toloka a un excellent tutoriel sur la façon d'écrire des instructions. Après lui, j'ai reçu cette instruction: 
En tant que paramètres d'entrée, nous transmettons l'id de la tâche, et à la sortie, nous obtenons le fichier img, qui contiendra l'image du compteur.

L'interface de travail est écrite en seulement 2 lignes!
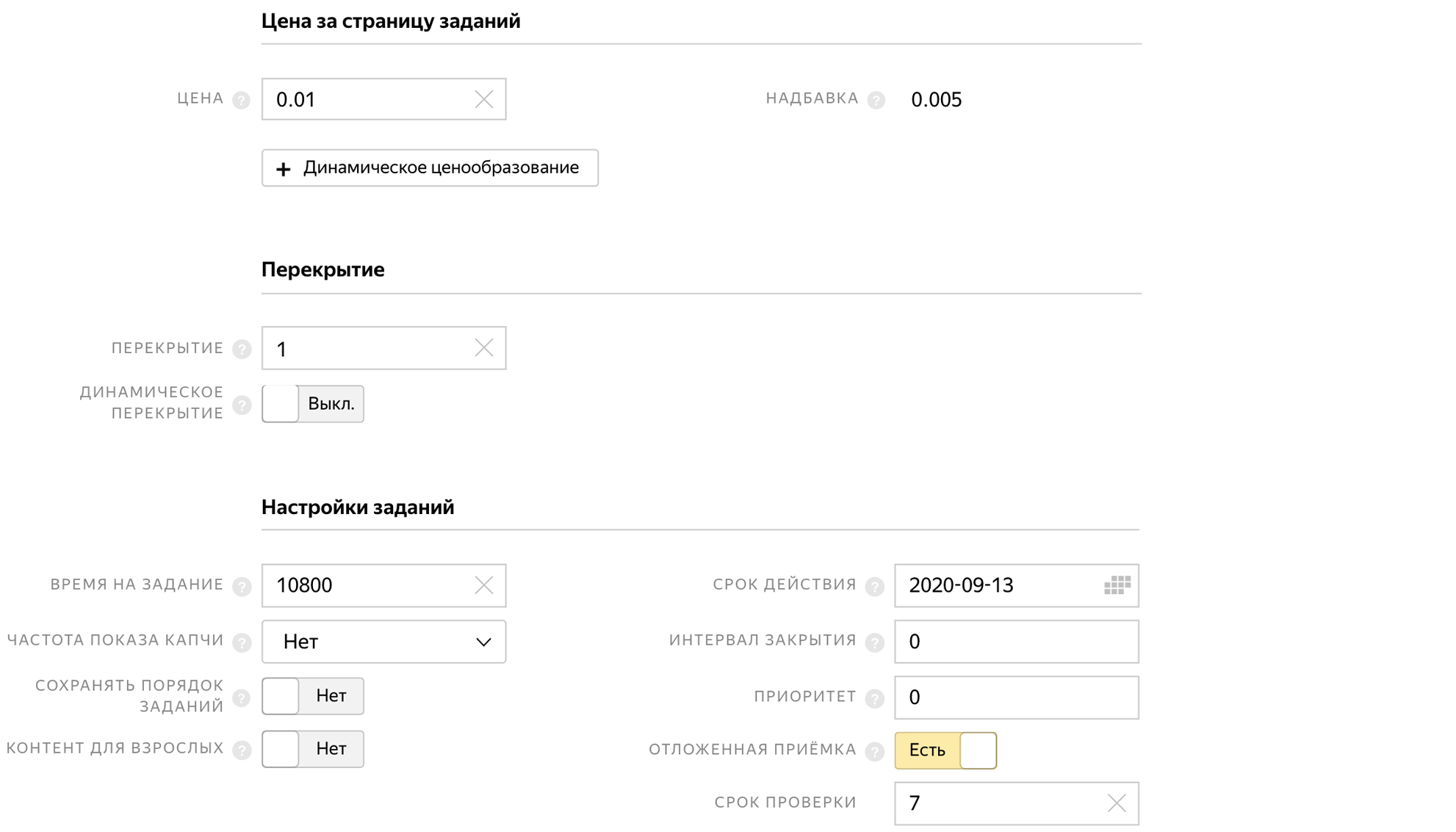
Lors de la création d'un pool, nous indiquons le temps de réalisation de la tâche, l'acceptation différée et le prix de la tâche 0,01 $.
Et pour que les gens ne terminent pas la tâche plusieurs fois et n'envoient pas les mêmes photos, nous interdisons l'exécution répétée de la tâche dans le bloc de contrôle qualité.
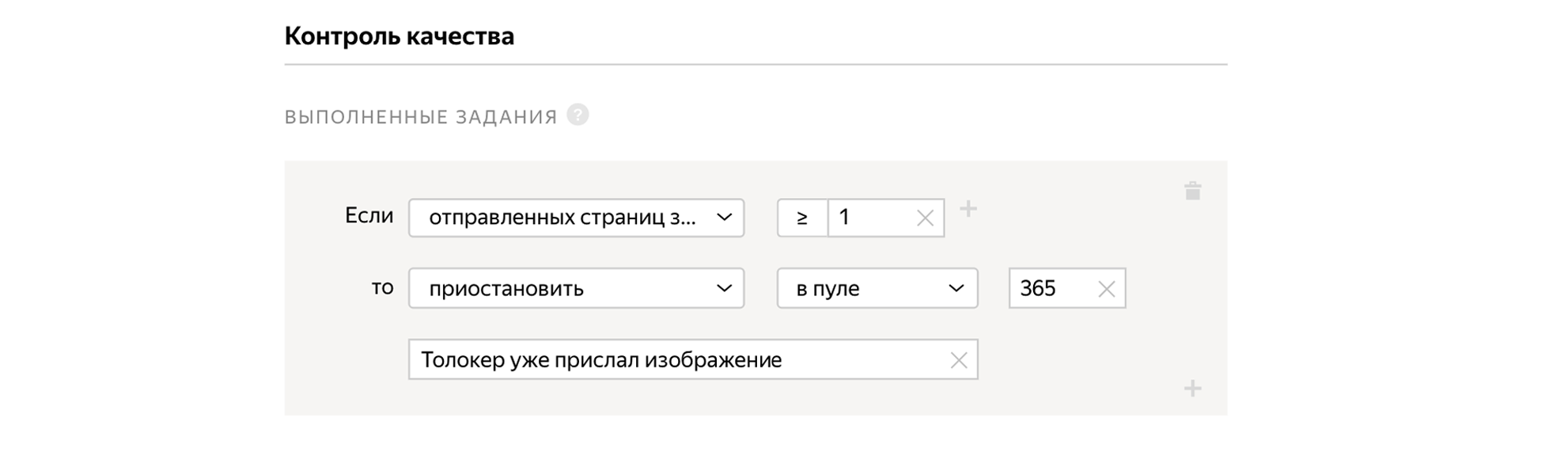
Nous indiquons que nous avons besoin d'utilisateurs russophones qui accomplissent la tâche via l'application mobile Yandex.Tolok.
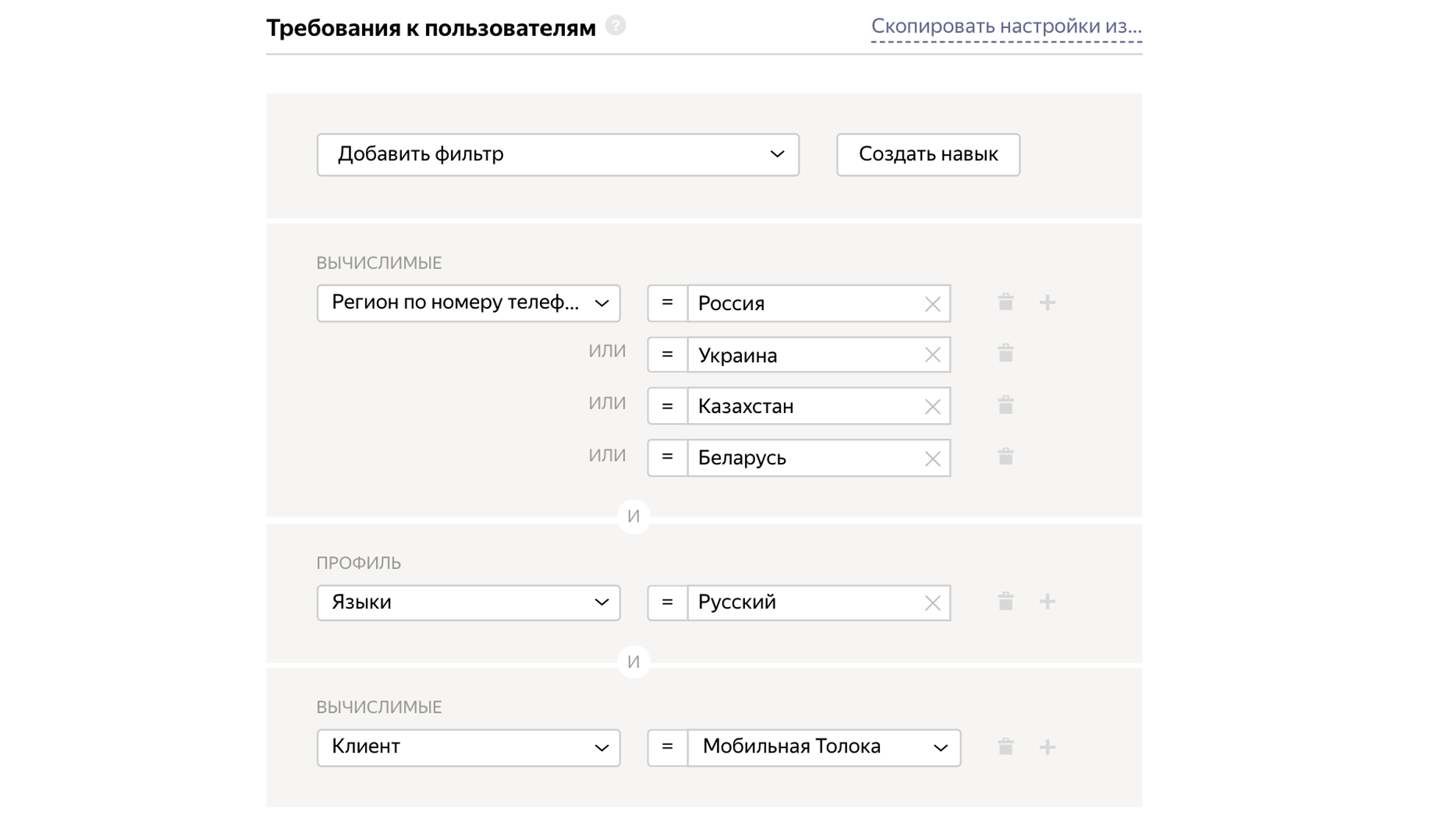
Téléchargement de tâches dans le pool.
Nous commençons la piscine, réjouissons-nous et attendons les réponses des utilisateurs! Voici à quoi ressemble notre tâche du côté du toloker:
Partie 2. Acceptation des tâches
Après avoir attendu quelques heures, nous voyons que les tolkers ont terminé la tâche. Étant donné qu’en cas d’acceptation tardive, l’attribution n’est pas versée immédiatement à l’entrepreneur, mais est gelée dans le bilan du client, nous devons maintenant vérifier toutes les images envoyées. Pour que les artistes de bonne foi acceptent des tâches, et pour les artistes qui ont envoyé des images inappropriées pour les critères, refusez et écrivez la raison du refus.
S'il n'y avait pas beaucoup d'images, nous pourrions voir et vérifier toutes les images envoyées nous-mêmes. Mais nous voulons obtenir des milliers et des dizaines de milliers d'images! La vérification de ce volume de tâches nécessitera un temps considérable. De plus, ce processus nécessite notre participation directe.
Toloka revient à la rescousse! Nous pouvons créer une nouvelle tâche "Vérification des images de compteur" et demander à d'autres tolkers de répondre si l'image correspond à nos critères ou non. En configurant le processus une fois, nous obtenons une collecte et une validation des données entièrement automatiques! Dans le même temps, la collecte de données est facilement évolutive, et si nous devons augmenter la taille de l'ensemble de données plusieurs fois, il suffit de cliquer sur quelques boutons.
Cela semble incroyable et grandiose, non?
Il est alors temps de mettre l'idée en pratique!
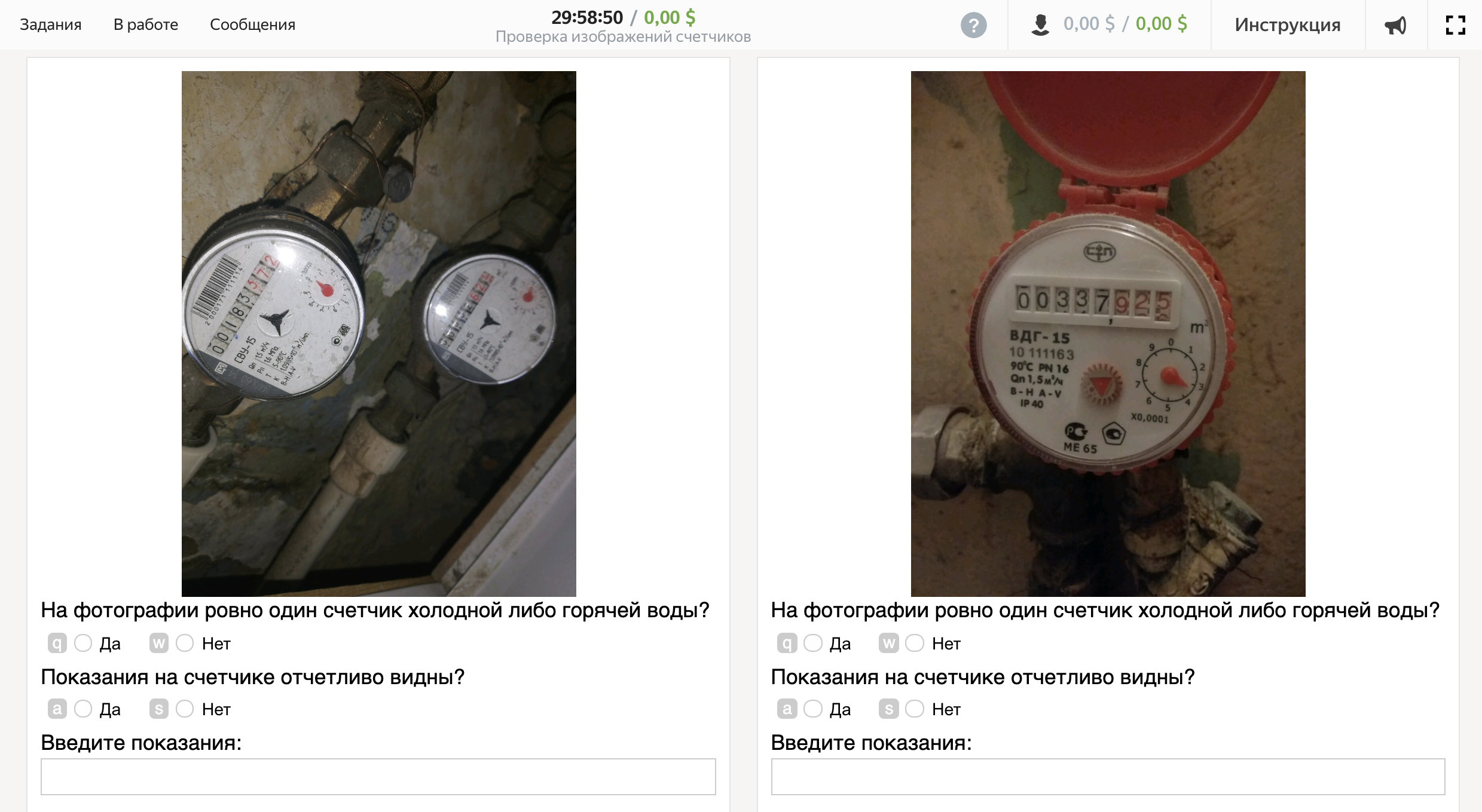
Tout d'abord, nous définirons les critères selon lesquels nous considérerons la photo comme bonne.
Une photo est bonne si:
- Sur la photo, il y a exactement un compteur d'eau froide ou chaude;
- Les lectures sur le comptoir sont clairement visibles.
Dans d'autres cas, la photo est considérée comme mauvaise.
Nous avons trié les critères, maintenant nous écrivons une instruction! 
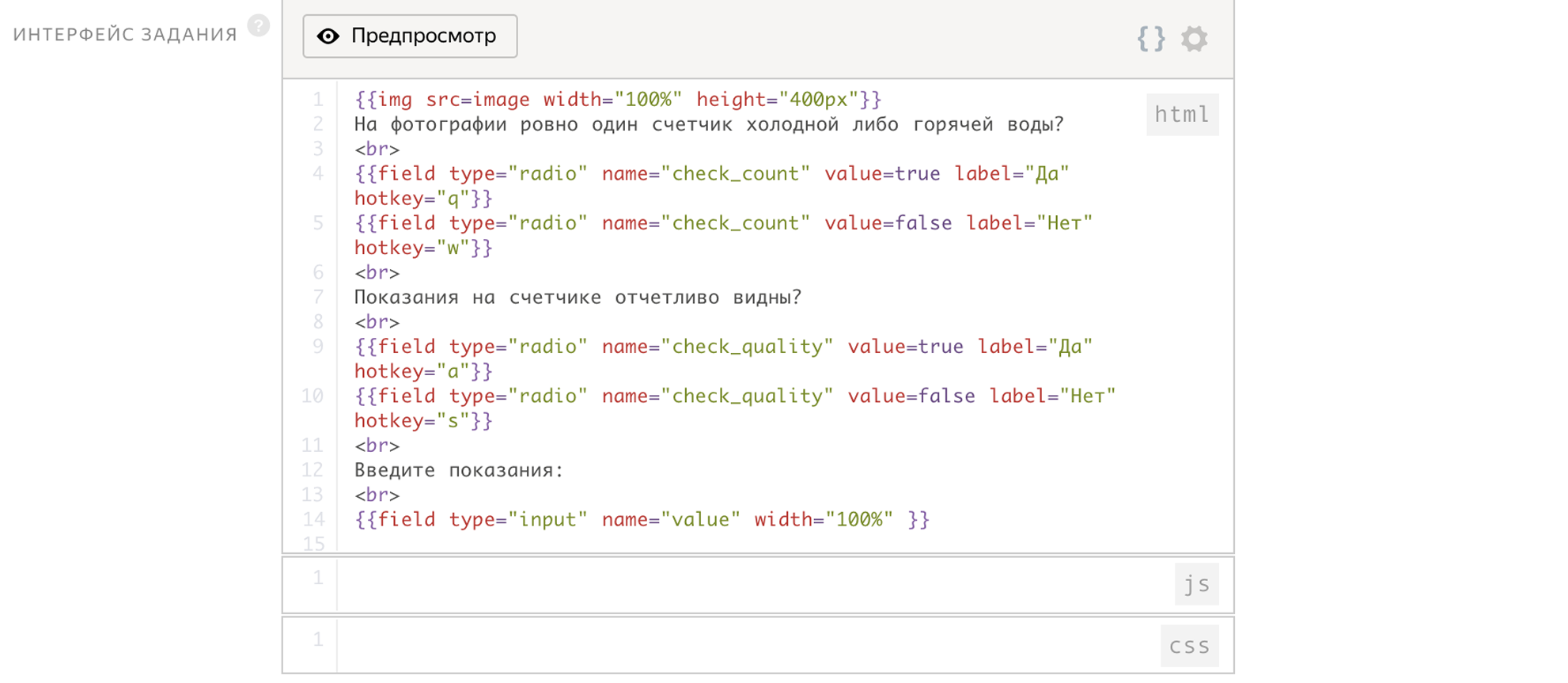
En tant que paramètres d'entrée, nous transmettons le lien à l'image. La sortie sera deux drapeaux:
- check_count - réponse à la première question
- check_quality - réponse à la deuxième question
Le compteur sera écrit dans la variable de valeur.
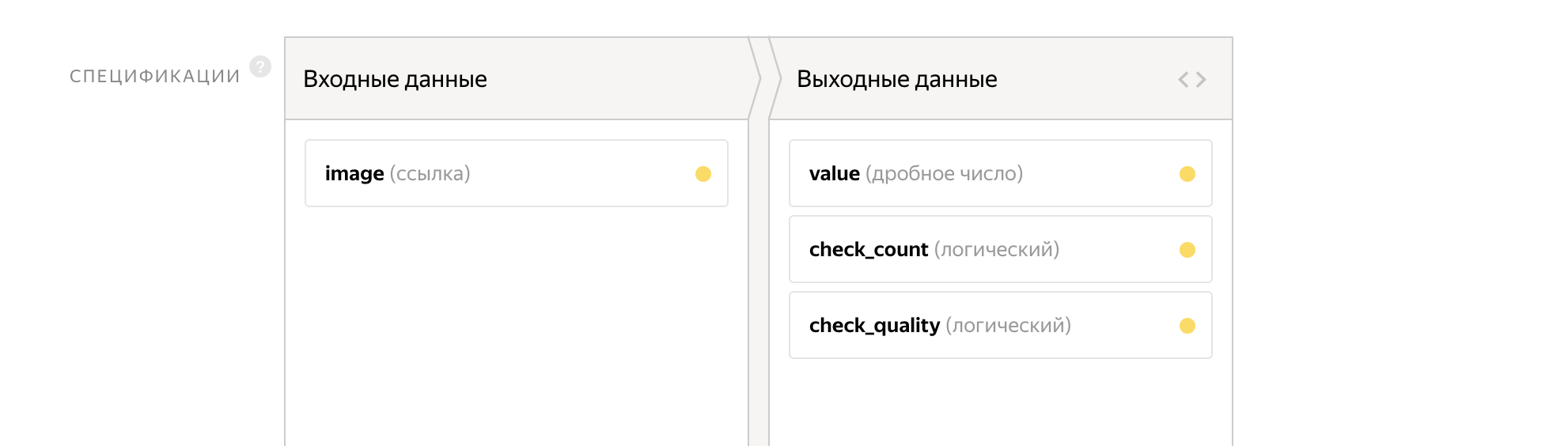
L'interface de cette tâche prend déjà 14 lignes.
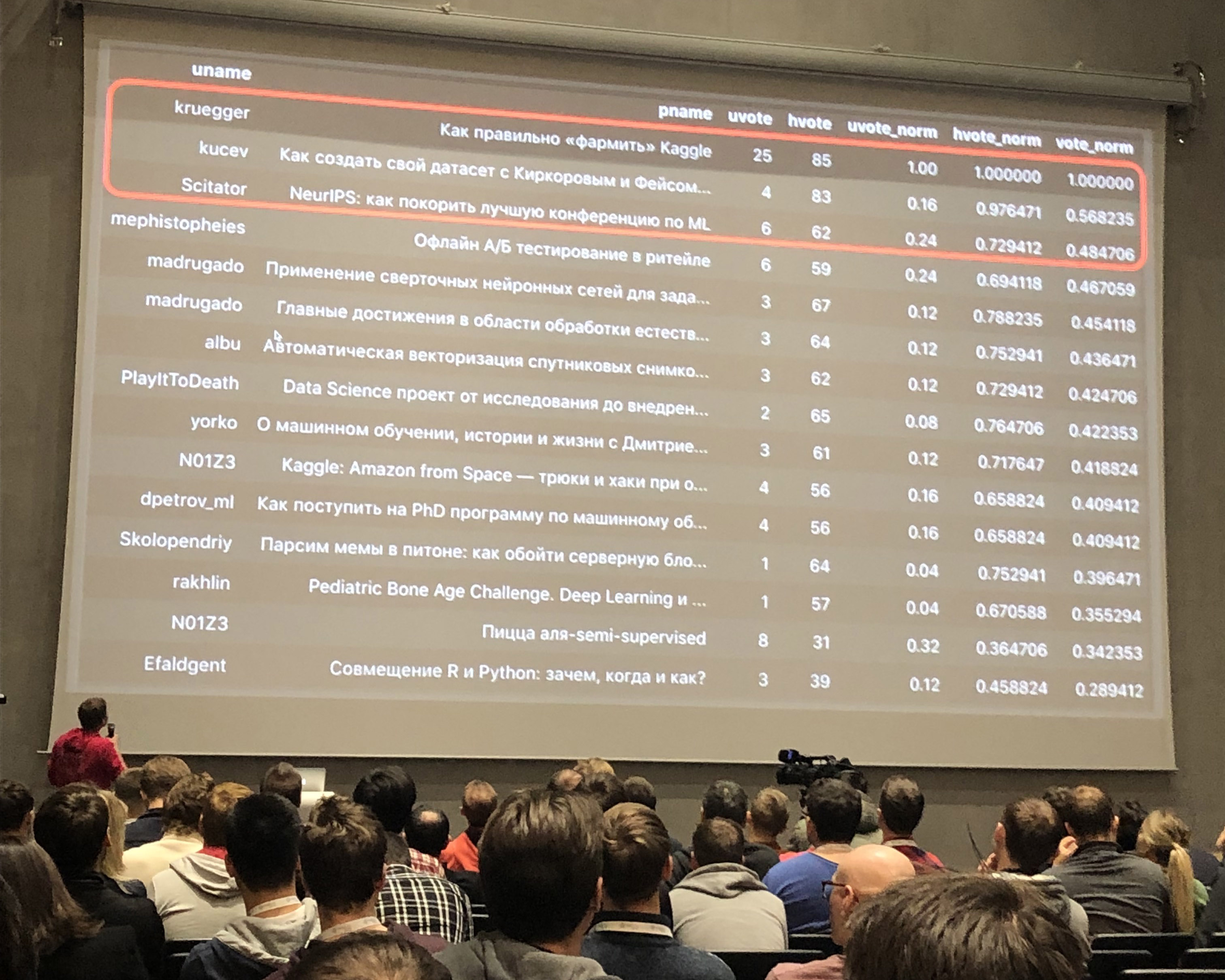
Pour augmenter la précision, une image sera vérifiée indépendamment par 5 tolokers, pour cela nous allons mettre un chevauchement de 5. Après cela, nous verrons comment 5 personnes ont répondu et supposons que la bonne réponse est celle pour laquelle la majorité a voté. Cette tâche n'aura plus retardé l'acceptation.
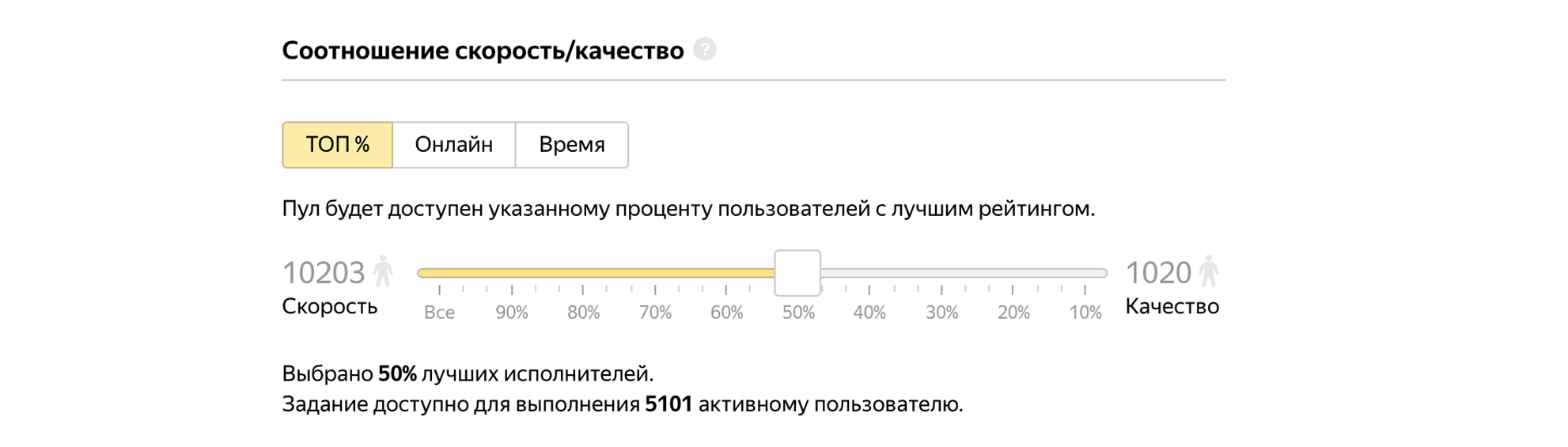
Admettons 50% des meilleurs interprètes à la tâche.
Dans les tâches sans acceptation retardée, tout le monde reçoit un paiement, qu'il exécute correctement ou non la tâche. Mais nous voulons que les tolokers lisent attentivement les instructions, essaient de terminer la tâche correctement. Comment y parvenir?
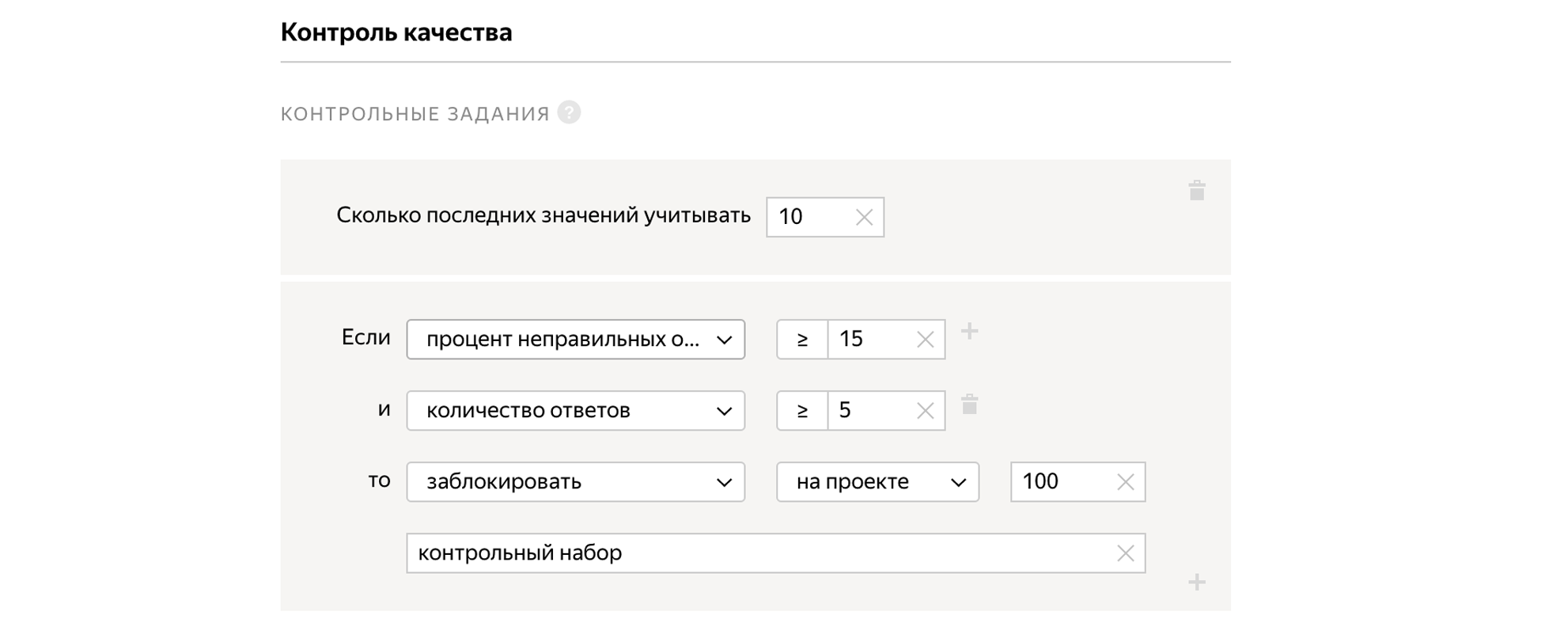
Il existe deux outils principaux dans Tolok qui vous permettent de maintenir une bonne qualité:
- La formation. Avant de terminer la tâche principale, nous pouvons demander aux formateurs de se former. Dans le pool de formation, les personnes se voient confier des tâches pour lesquelles nous connaissons à l'avance les bonnes réponses. Si une personne a répondu incorrectement, une erreur lui est montrée et lui explique comment répondre. Après avoir terminé la formation, nous voyons le pourcentage de tâches accomplies par l'interprète et nous ne pouvons autoriser que ceux qui ont bien fait à l'ensemble des tâches.
- Blocs de contrôle qualité. Il peut y avoir une situation où le bassin d'entraînement de l'artiste était excellent, nous avons été autorisés à le faire, mais cinq minutes plus tard, il est parti jouer au football, laissant son frère de trois ans devant l'ordinateur. Heureusement, il existe de nombreuses méthodes dans Tolok qui vous permettent de suivre la façon dont les gens effectuent les tâches.
Avec le pool de formation, tout est simple: il suffit d'ajouter des tâches, de les marquer dans l'interface Yandex.Tolki et de spécifier le seuil de passage, à partir duquel nous autorisons les personnes à la tâche principale.
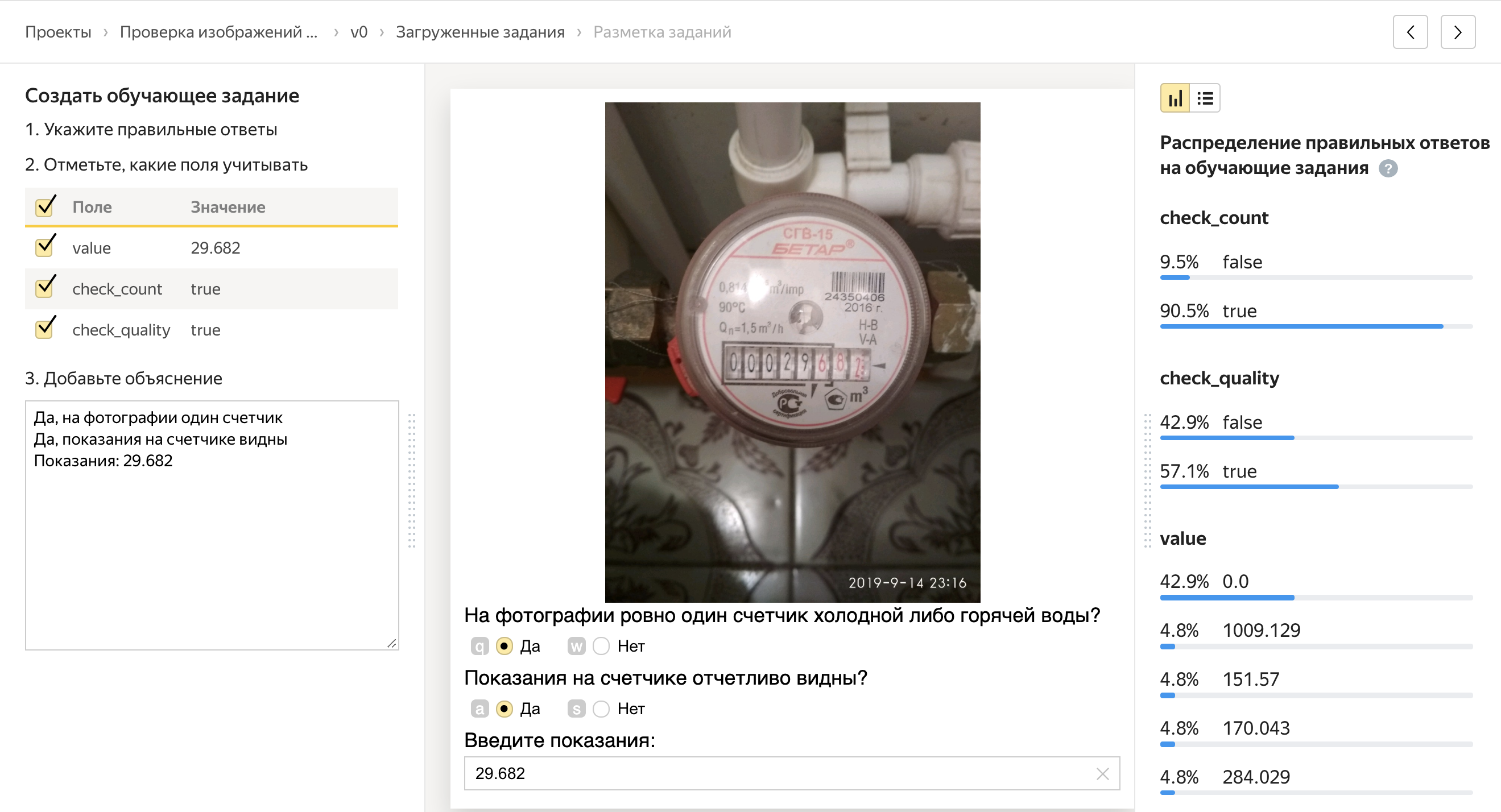
Avec les unités de contrôle qualité, tout est plus intéressant: il y en a beaucoup, mais je vais me concentrer sur les deux plus importantes.
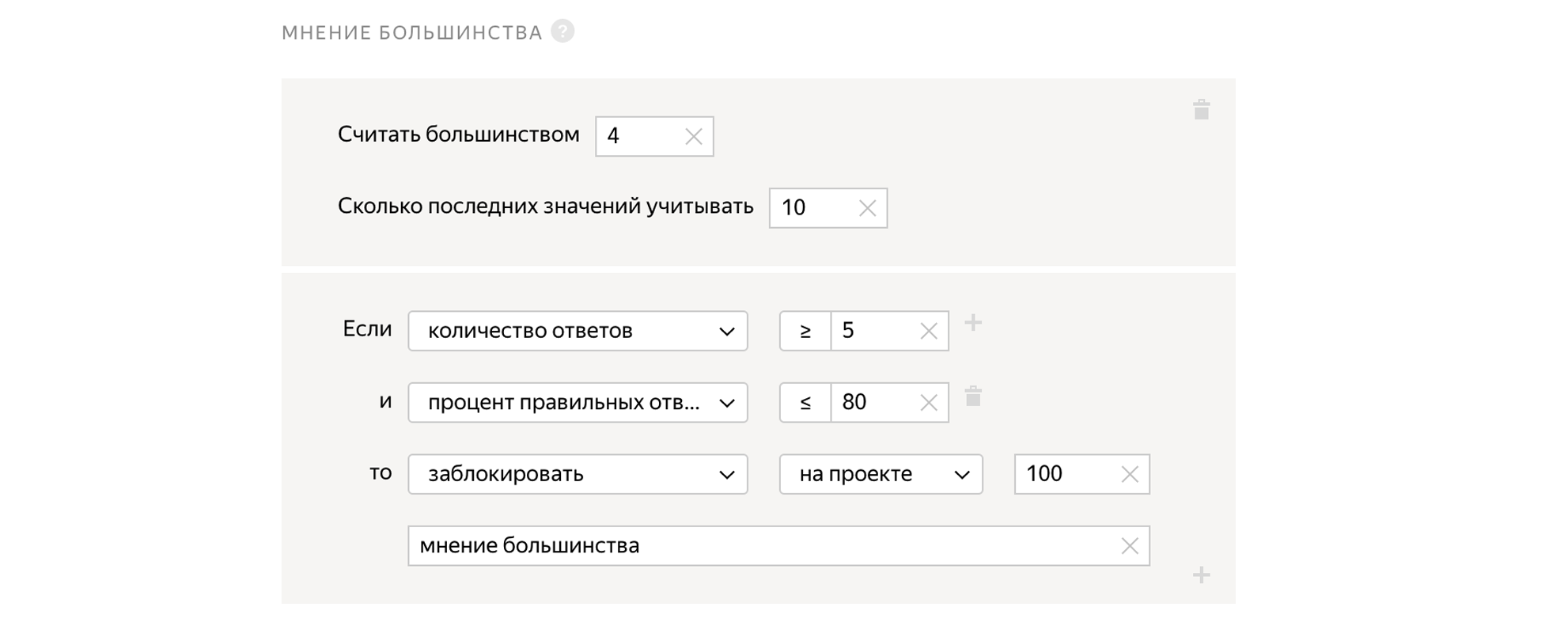
Opinion majoritaire
Nous confions la tâche à 5 personnes indépendantes. Et si quatre personnes répondent «Oui» à la question, et la cinquième répond «Non», alors la cinquième a probablement fait une erreur. Ainsi, nous pouvons voir comment les réponses de la personne sont cohérentes avec les réponses des autres personnes et bloquer les utilisateurs qui répondent différemment des autres.
Tâches de contrôle
Nous pouvons mélanger des tâches dans le pool, pour lesquelles nous connaissons à l'avance la bonne réponse. Dans le même temps, les tâches de contrôle qualité sont identiques aux tâches normales. En fonction du fait qu'une personne répond correctement aux tâches de contrôle, nous pouvons extrapoler et supposer, correctement ou non, qu'elle résout toutes les autres tâches pour lesquelles nous ne connaissons pas les réponses. Si une personne réagit mal aux tâches de contrôle, nous pouvons la bloquer, et si c'est bien, alors donnez un bonus.
Hourra, tâche créée! Voici à quoi ressemble l'interface de l'exécuteur:
Partie 3. Rejoindre des emplois
Super, les tâches sont prêtes! Mais la question se pose, comment connecter les tâches entre elles? Comment faire la deuxième manche après la première tâche?
Bien sûr, vous pouvez jouer avec un tambourin et le faire manuellement via l'interface Toloka, mais il existe un moyen plus simple et plus rapide! Yandex.Tolok a une API , utilisez-la et écrivez un script python!
Je sais que beaucoup d'entre vous n'aiment pas lire le code, donc je l'ai caché sous un spoilerimport pandas as pd import numpy as np import requests import boto3
Nous exécutons le code et voici le résultat tant attendu: l' ensemble de données de 871 images de compteur est prêt.

Prix
Évaluons la composante économique du projet.
Pour l'image envoyée dans la première tâche, nous offrons 0,01 $.
Malheureusement, si nous payons à l'interprète 0,01 $, nous devrons payer 0,018 $.
Comment cela se fait-il?
- La commission Yandex est min (0,005,20%). Pour une tâche au prix de 0,01 $, la commission sera de 50%;
- La TVA est de 20%.
Pour vérifier 10 images de compteurs, nous payons 0,01 $. Dans ce cas, une image est vérifiée 5 fois par des personnes indépendantes. Au total, nous donnons pour vérifier une image: (0,01 x 5/10) x 1,2 x 1,5 = 0,009 $.
Sur les 1 000 soumissions envoyées, 871 images ont été reçues et 129 ont été rejetées. Donc, pour obtenir un ensemble de données de 871 images, nous avons payé:
0,018 $ x 871 + 0,009 $ x 1000 = 25 $ et vous avez besoin de 92 000 roubles pour obtenir un ensemble de données de 50 000 images. C'est certainement moins cher que de commander des publicités sur la chaîne fédérale!
Mais ce chiffre peut en fait être réduit plusieurs fois. Vous pouvez:
- Suggérez dans la première tâche de prendre non pas une photo, mais plusieurs. En même temps, augmenter le prix, la commission Yandex ne sera pas de 50%, mais de 20%;
- Utilisez le chevauchement dynamique dans la deuxième tâche. Si 4 personnes sur 5 ont donné la même réponse, cela n'a aucun sens de confier la tâche à la cinquième personne;
- Travailler avec Toloka en tant qu'entité juridique étrangère. Dans ce cas, vous ne payez pas de TVA.
Puisqu'il y avait tellement de matériel, j'ai décidé de diviser l'article en deux parties. La prochaine fois, nous discuterons avec vous de la façon de sélectionner des objets dans des images à l'aide de Toloka et de créer des ensembles de données pour les tâches dans Computer Vision. Et pour ne rien manquer, abonnez-vous et aimez!
PS
Après avoir lu l'article, il peut vous sembler qu'il s'agit d'une publicité cachée de Yandex.Tolki, mais non, ce n'est pas le cas. Yandex ne m'a rien payé et ne paiera probablement pas. Je voulais juste montrer sur un exemple fictif, mais pertinent et intéressant, comment en utilisant ce service, vous pouvez rapidement et à moindre coût assembler un ensemble de données pour n'importe quelle tâche, que ce soit la tâche de reconnaître les chats ou de former des véhicules sans pilote.