Salut Je m'appelle Sosnin Ilya. Je travaille chez Lamoda développeur Android. Je peins des boutons, saute des listes et, malheureusement, j'écris des analyses ...
Lamoda est une entreprise pilotée par les données dans laquelle toutes les décisions sont prises en fonction du comportement des utilisateurs. Nous observons d'abord et ensuite nous tirons des conclusions. Par conséquent, il est facile de deviner que nous avons des analyses et nous en avons vraiment besoin.
En déchiffrant mon
rapport par mitap Mosdroid # 18 Argon, je vais vous dire comment fonctionne notre SDK et pourquoi la réflexion n'est pas toujours mauvaise. Et aussi je répondrai à la question principale de ce sujet: "Comment implémenter l'analytique et ne pas casser l'application?".

Pour commencer, je vais vous poser une question simple: "Comment pensez-vous, combien d'installations avons-nous sur Google Play?"
10 millions d'installations!
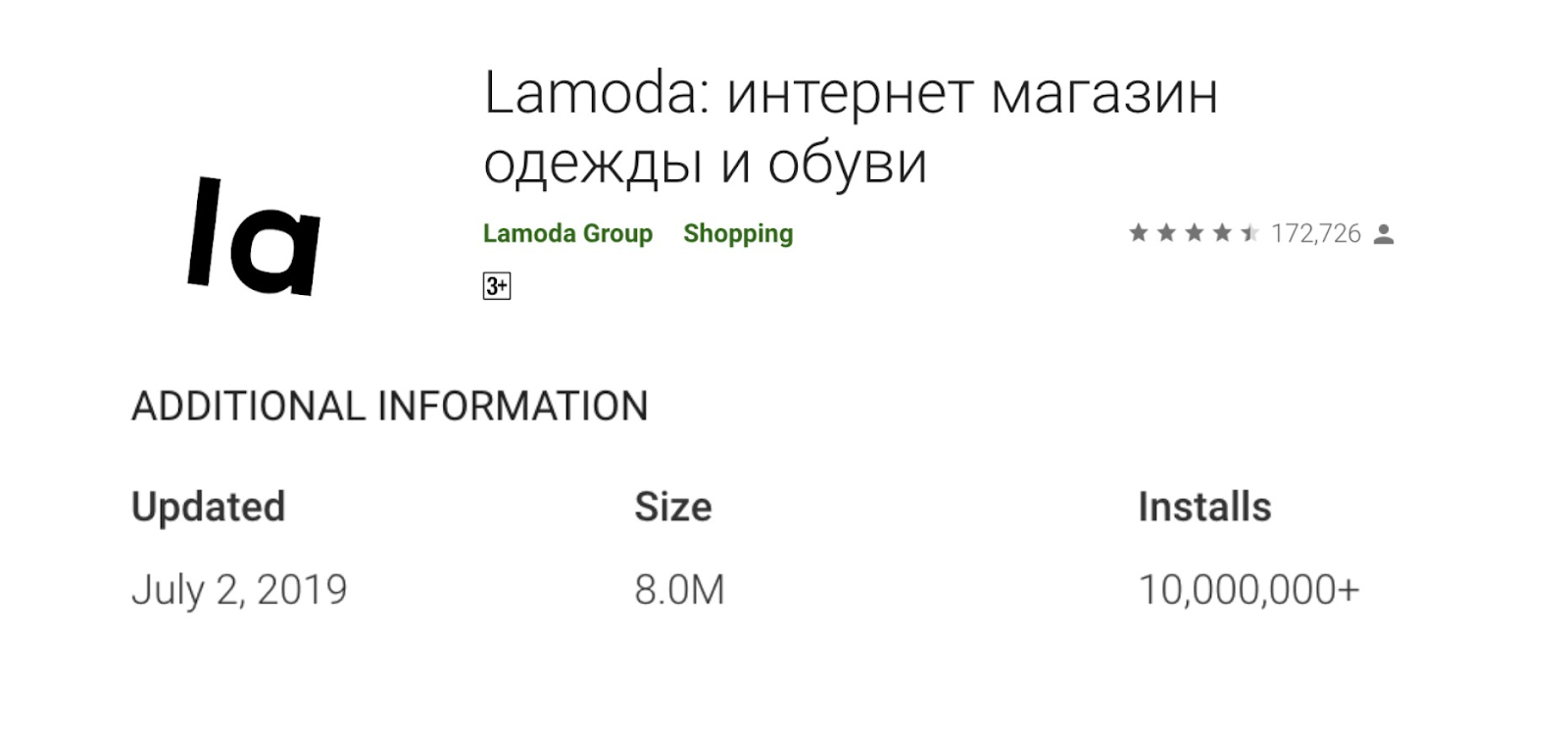 Indicateur début juillet 2019.
Indicateur début juillet 2019.
En plus du fait que nous tirons des conclusions sur la base des utilisateurs, nous avons également des clients internes qui sont également intéressés par l'analyse.
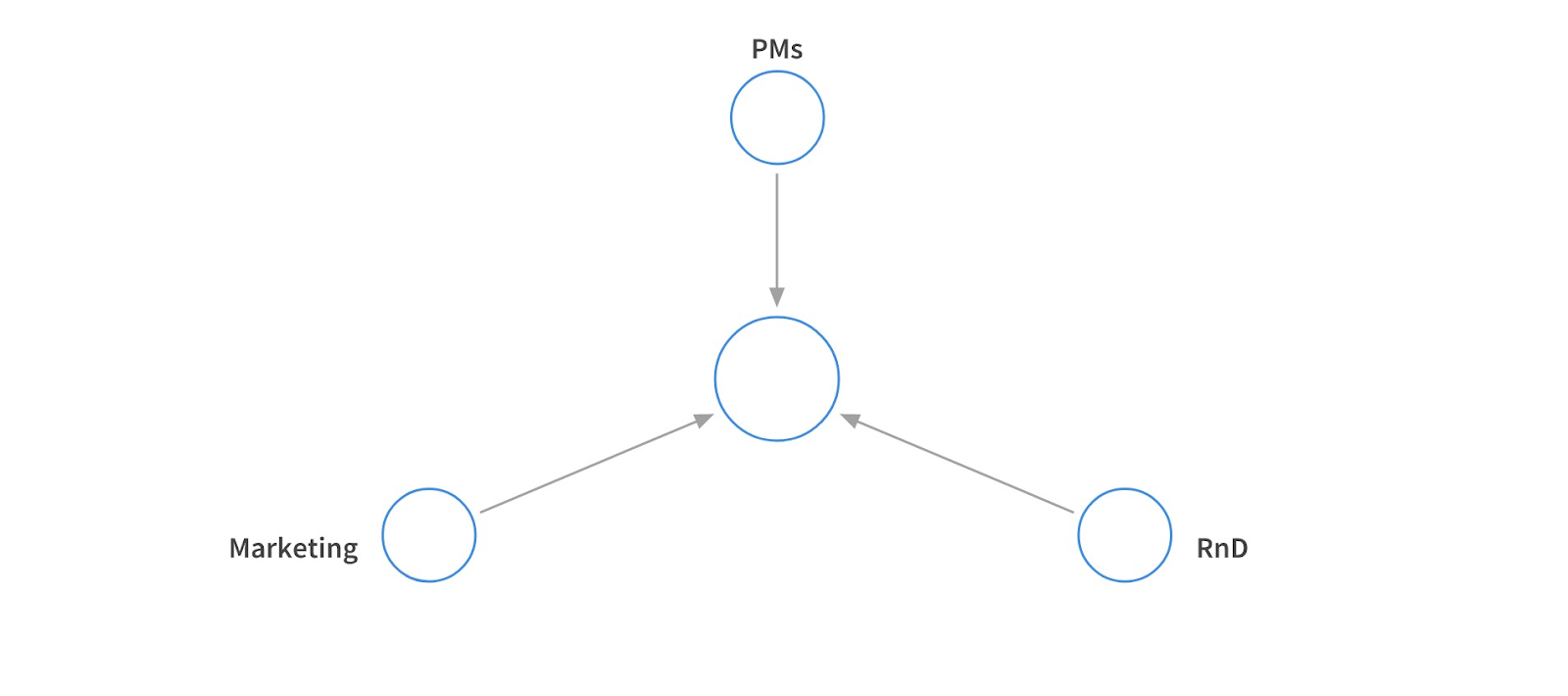
Tout d'abord, le marketing a besoin d'analyses pour ses propres besoins de recherche. La R&D contrôle nos requêtes de recherche au détriment de celle-ci, et les produits fonctionnent sur de nouvelles fonctionnalités.
Par exemple, nous avions une fonctionnalité qui nous permettait de collecter l'image entière dans son ensemble. Autrement dit, vous pouvez acheter non seulement la chemise que vous avez aimée sur le modèle, mais aussi un pantalon de la même image. Nous avons décidé que, pour commencer, nous l'écririons pour IOS, puis nous réfléchirions à la question de savoir si nous en avions besoin. Ils ont écrit, regardé et veillé à ce que les utilisateurs ne l'aiment pas.
Selon vous, que devrait-on faire avec les fonctionnalités dont les utilisateurs n'ont pas besoin?
Bon, jetez-les! Cela vaut particulièrement la peine lorsque la fonctionnalité est liée à des services externes, car ils ont tendance à recevoir des problèmes ou à être payés. C'est arrivé avec cette fonctionnalité. Nous n'avons implémenté ni Android ni Desktop, mais avons plutôt décidé de le faire évoluer. (peut-être qu'un jour elle ira au prod sous une forme plus parfaite).
Quelle est la difficulté?
Peu importe à quel point cela peut sembler drôle, lors de l'introduction de l'analyse, il peut être
difficile de travailler avec les analystes eux-mêmes . Le plus souvent, des conflits surviennent parce qu'ils demandent des données que vous ne possédez pas. Et cela se termine toujours par le fait que vous devez toujours faire glisser un tas de paramètres à travers 10 écrans pour leur envoyer un petit événement. Et cela arrive assez souvent.
Le deuxième défi consiste à
collecter des analyses . Nous avons ce processus effectué dans 7 systèmes.

Certains événements vont dans un seul système, d'autres en plusieurs à la fois ... De plus, il y a une telle fonctionnalité que les événements avec différents paramètres et dans différents formats peuvent aller vers différents systèmes. Bien sûr, nous ne voulons pas vraiment résoudre toutes ces dépendances.
LStat est notre propre SDK (statistiques Lamoda). Il s'agit d'un système massif, qui prend plus de 60% des événements divers. Ces événements qui vont plus loin dans Google, Adjust, ont souvent été initialement collectés uniquement dans LStat.
SDK
Notre SDK est le suivant.
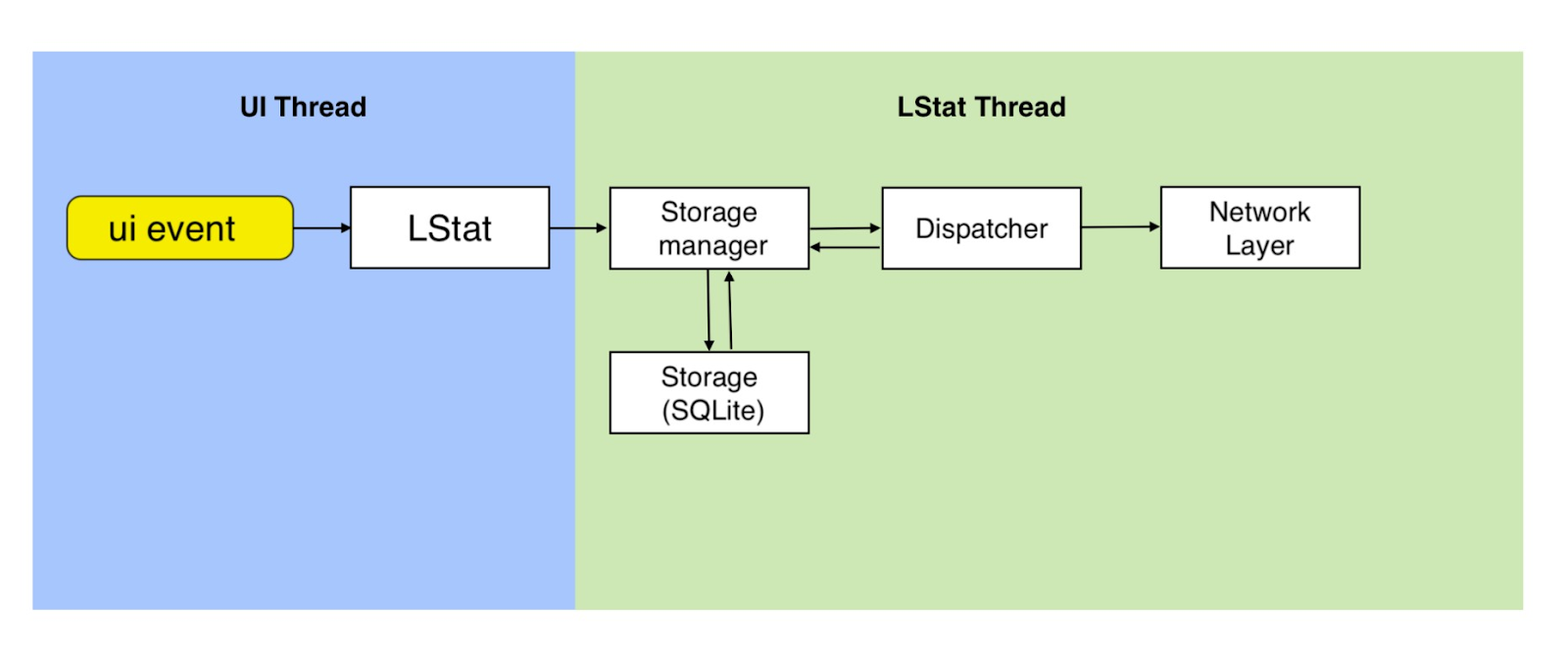
Un LStat propre sort, qui à l'intérieur se compose de deux parties: le stockage et l'expédition. Lorsque nous collectons un événement, nous ne l'envoyons pas immédiatement. Sinon, il y aurait trop d'événements et de demandes, ce qui n'est pas très pratique. Par conséquent, nous mettons tout dans notre petite base de données SQLite, où nous stockons tout. Ensuite, à certains intervalles, notre couche réseau extrait les données de la base de données et les envoie.
Après avoir reçu la confirmation du serveur que les événements sont arrivés, nous effaçons notre base de données. Ce processus se produit régulièrement. Grâce à cela, notre base ne grandit pas et nous garantissons la livraison de tous les événements. Si, pour une raison quelconque, l'événement n'est pas arrivé, il sera stocké dans notre base de données jusqu'à ce qu'une réponse soit reçue du serveur.
Collectionneurs
Comme je l'ai dit plus tôt, nous avons 7 collectionneurs. Ils se composent de ces méthodes: annotation personnalisée, EventHandler et AppStartEvent. Que pensez-vous de cet événement?

Bien sûr, c'est un démarrage à froid de l'application. Et l'essentiel ici est que nous avons une classe AppStartEvent qui hérite d'une interface Event. Et pourquoi en avons-nous besoin, je le dirai un peu plus tard.
Comment ça se passe? C'est là que le thrash, la brûlure et la réflexion commencent.

Nous passons d'abord par nos 7 collecteurs. Ensuite, nous retirons la classe Java et collectorName, dont nous avons besoin plus tard pour le stockage.
De plus, à partir de cette classe Java, nous retirons toutes nos méthodes qui sont dans ce code. Maintenant, nous devons vérifier et nous assurer que notre méthode est une méthode de suivi des événements qui sera responsable du stockage. Pour ce faire, nous avons plusieurs paramètres: le premier est que nous avons l'annotation @EventHandler, nous n'avons pas de liste de paramètres vide et un événement arrive à l'entrée.
Toutes les conditions sont remplies, nous pouvons donc supposer que cette fonction sera un événement avec nous. Je viens de l'envelopper dans un emballage et de l'envoyer à notre collection.
La réflexion n'est pas toujours mauvaise
Oui, beaucoup d'entre vous diront que la réflexion est mauvaise, lente, terrible.

Pour commencer, cela peut être lent ou rapide. Il existe des méthodes comme getFields, getConstructors qui fonctionnent très rapidement par rapport au reste de la réflexion. Et il y a, par exemple, Constructor newInstance, qui fonctionne très lentement. Par le mot «lent», je veux dire la différence entre les colonnes gauche et droite dans le tableau ci-dessus de plusieurs ordres de grandeur (environ une centuple de différence). Par conséquent, si vous comprenez ce que vous faites et savez à l'avance à quoi vous devez vous préparer, tout n'est pas si effrayant.
Nous tirons plus de 500 méthodes de 7 classes . Et nous ne le faisons qu'une fois par session. Le temps nécessaire pour terminer un passage est de 40 millisecondes. C'est moins de 3 images (au stade de l'écran de démarrage). Et c'était loin d'être un appareil haut de gamme, mais un simple NTC sur Android 6, qui existe depuis de nombreuses années.
Bien sûr, sur un appareil haut de gamme, tout fonctionnera plus rapidement. Et si nous parlons de vieux téléphones chinois, le temps passé sera de 100 millisecondes conditionnel. Les utilisateurs de ces téléphones sont déjà habitués au fait que tout fonctionne lentement pour eux, ils sont donc profondément indifférents à 40 millisecondes ou 100. Quelle est la différence? Ils ralentissent encore :)
Et maintenant la question principale: comment implémenter l'analytique pour ne pas casser l'architecture?
Architecte
Notre application utilise MVP.
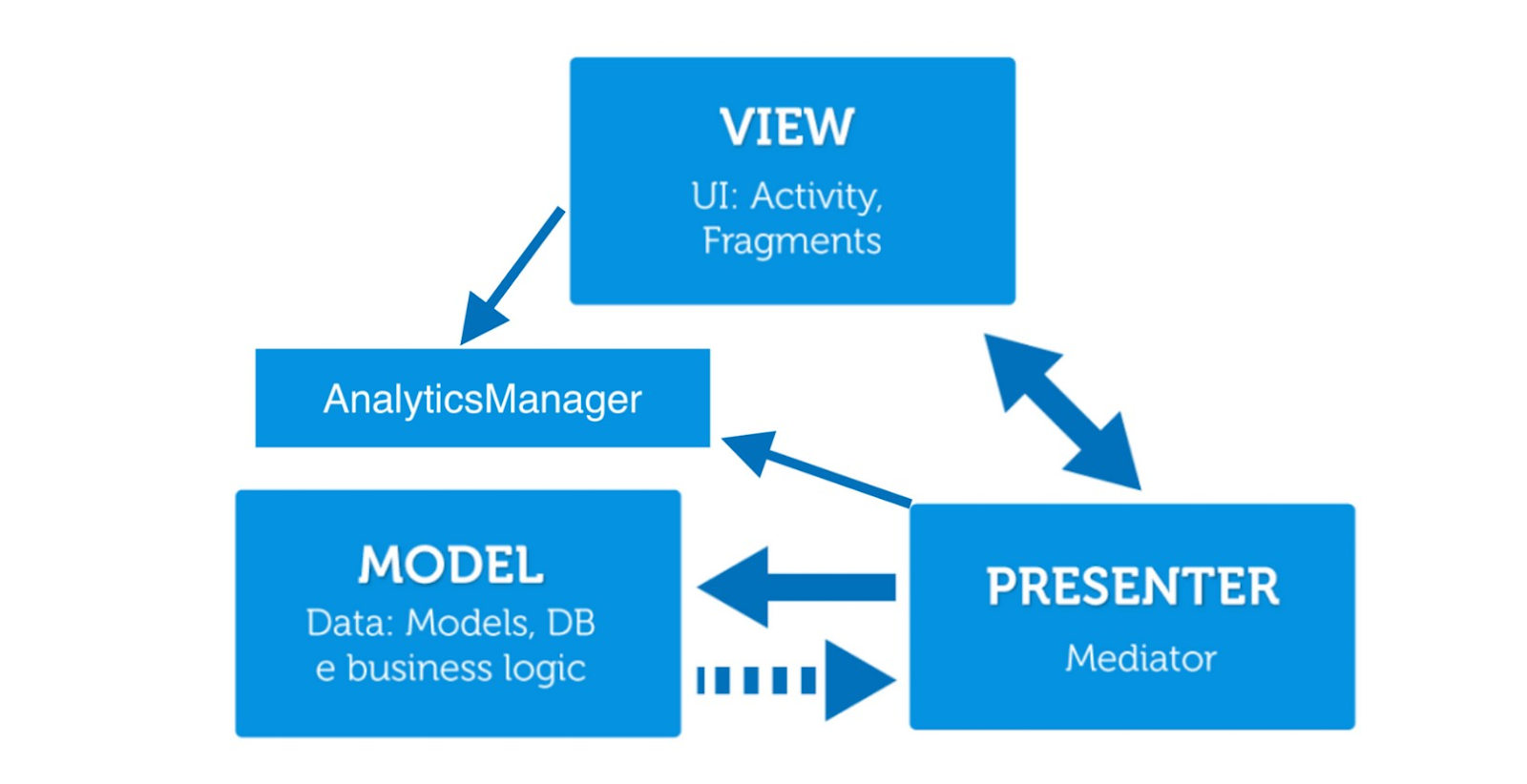
C'est notre genre d'essence divine, qui «vit» sur ApplicationScope et est injecté exactement là où nous en avons besoin. Par exemple, nous devons déposer surClick (). Afin de ne pas casser l'architecture, nous ne transmettrons pas l'événement de la couche View à Presenter, afin que plus tard, il aille quelque part. Au lieu de cela, nous faisons tout directement depuis la vue et passons la piste à AnalyticsManager.
Et maintenant un peu sur l'envoi. Chez AnalyticsManager, une méthode ressort - c'est la méthode de suivi, qui accepte n'importe quelle classe d'événement comme entrée. Et puis la magie noire se produit.

Cette méthode est capable de résoudre tous nos problèmes.
Premièrement, cela aidera à
déposer dans plusieurs systèmes différents . Les gestionnaires sont tous nos événements qui seront collectés. Ensuite, nous recherchons ici la méthode souhaitée. Par conséquent, si nous avons un événement de piste écrit, par exemple, dans 4 collecteurs, il sera stocké en 4 exemplaires. Autrement dit, en 4 passes du cycle, nous le trouverons et l'enverrons aux 4 systèmes avec les paramètres correspondants.
Deuxièmement, cela
aide à résoudre le problème avec des événements ponctuels . Ce sont de tels événements qui doivent être promis strictement 1 fois pour tout le cycle de la demande. Mark e.once, la variable booléenne habituelle. Si nous disons qu'il s'agit d'un événement ponctuel, nous le supprimons simplement de la collection. Que se passe-t-il ensuite si nous essayons de le mettre en gage à nouveau? Évidemment, nous ne le trouverons tout simplement pas dans cette collection. Vous pouvez essayer de vous tirer une balle dans le pied autant que vous le souhaitez tout en continuant à écrire analyticsManager.track (AppStartEvent ()), cela continuera quand même une fois et il n'y en aura plus.
Quel est le profit?
1.
Nous ne cassons pas l'architecture de notre application , car AnalyticsManager se trouve et fonctionne en dehors de l'architecture. Cela nous permet de l'intégrer dans n'importe quelle partie de l'application.
2.
Vous permet de collecter tous les événements sur une seule ligne dans n'importe quel nombre de systèmes d'analyse. Pour ce faire, nous écrivons simplement: analyticsManager.track (Event ()). Parce qu'alors il décide lui-même où, en quelle quantité, avec quels paramètres, quand, etc.
3.
Résout le problème des «événements ponctuels» . Maintenant, nous n'avons plus besoin de faire différents types de contrôles. Une fois envoyé, retiré, et nous ne le rencontrerons plus.
4.
Résout le problème de la collecte du même élément dans différents systèmes . Étant donné que nous avons tout écrit dans différents collectionneurs, cela est allé à différents collectionneurs. Ainsi, vous n'avez pas à recourir à des gestes inutiles. À mon avis, c'est merveilleux.
Test ...
Nous testons manuellement. Pourquoi ne pas automatiser, demandez-vous? Et puis une chose triste se révèle.
Tout d'abord, malheureusement, vous ne couvrirez pas normalement cela avec un test unitaire. Parce que la plupart des problèmes liés aux événements dans l'analyse ne se posent pas en raison du fait que certains des paramètres que vous n'avez pas rassemblés. D'après mon expérience personnelle, 90% des problèmes surviennent parce que vous n'avez pas envoyé l'événement où il était censé aller. De tels cas ne peuvent être détectés qu'avec des tests d'interface utilisateur, que nous n'avons pas encore écrits pour tout cela.
Et deuxièmement, pour l'instant, nous nous reposons un peu sur le fait que les analystes décrivent les événements dans un format assez strict (en confluence), mais ce format n'est pas un format de spécification strict, comme Swagger. En conséquence, il y a de légères différences, il y a des doublons (bien que dans ce cas, un simple lien vers une autre page soit souvent créé). Jusqu'à présent, cela nous limite dans les possibilités d'automatisation des tests d'analyse. Mais nous y travaillons.
Conclusions
Que peut-on faire de plus avec cette décision?
1.
Écrivez des autotests pour l'analyse . Cela nécessitera beaucoup de travail préparatoire. Mais on ne peut pas dire que cela soit impossible.
2. Les méthodes de suivi plus-moins sont assez similaires. Dans chacun, nous générons des paramètres «universels» dont tout le monde a besoin. Et rassemblez simplement la carte des valeurs. En général, on pourrait
écrire un plug-in ou un utilitaire . Peu importe. L'essentiel est qu'elle génère un événement de piste pour les classes respectives.
Mais ici, un petit problème peut survenir si les événements commencent à disparaître un peu différemment (par exemple, pour différents systèmes d'analyse). Pour cette raison, tout ne peut pas être résolu de manière adéquate. Et d'ailleurs, je ne veux pas produire de génération de code inutile dans un projet, il y en a tellement dans de nombreux projets sur Android (bonjour Dagger, Moksi et d'autres qui travaillent sur codegen).
3.
Intégration de l'application avec les spécifications des analystes . C'est probablement un rêve trop transcendantal, mais quand même ... Nous aimerions vraiment que nos analystes écrivent dans un format strict, et nous pourrions analyser leurs œuvres d'art et les intégrer. Alors la paix et l'harmonie viendraient. Tout le monde serait content :)
Alors qu'est-ce que je veux dire avec tout ça?
Premièrement, l'analyse est toujours nécessaire. Parce qu'il vous permet d'économiser de l'argent, des ressources et des efforts. Cela vous évite d'écrire du code inutile ou de supprimer du code qui ne semble pas vieux, mais qui n'est toujours pas nécessaire ici. Moins d'héritage est toujours bon.
Deuxièmement, la réflexion n'est pas toujours mauvaise. Oui, c'est lent. Mais parfois, nous perdons très peu de performances, mais nous obtenons beaucoup, par exemple, dans le domaine du développement et de la gestion des erreurs.
Et troisièmement, nous plaçons l'analyse au stade de la planification des fonctionnalités. Pour cette raison, nous pouvons négocier avec les analystes beaucoup plus tôt, pour parvenir à un compromis. Et cela nous donne également la possibilité d'estimer à l'avance le temps nécessaire pour écrire des analyses.