Cet article est ma tentative d'exprimer mon point de vue sur les aspects suivants:
- Qu'est-ce qu'un facteur de vitesse d'apprentissage et quelle est sa valeur?
- Comment choisir ce coefficient lors de la formation des modèles?
- Pourquoi est-il nécessaire de modifier le coefficient de la vitesse d'apprentissage lors de la formation des modèles?
- Que faire d'un facteur de vitesse d'apprentissage lors de l'utilisation d'un modèle pré-formé?
La plupart de ce message est basé sur des documents préparés par
fast.ai : [1], [2], [5] and [3] - représentant une version concise de leur travail destiné à la compréhension la plus rapide de l'essence de la question. Pour vous familiariser avec les détails, il est recommandé de cliquer sur les liens ci-dessous.
Qu'est-ce qu'un facteur de vitesse d'apprentissage?
Le coefficient de vitesse d'apprentissage est un hyperparamètre qui détermine l'ordre dans lequel nous ajusterons nos échelles en tenant compte de la fonction de perte en descente de gradient. Plus la valeur est basse, plus nous nous déplaçons lentement le long de la pente. Bien que lorsque nous utilisons un faible coefficient de vitesse d'apprentissage, nous pouvons obtenir un effet positif dans le sens où nous ne manquons pas un seul minimum local, cela peut également signifier que nous devrons consacrer beaucoup de temps à la convergence, surtout si nous sommes dans la région du plateau.
La relation est illustrée par la formule suivante
 Descente en pente avec des facteurs de vitesse d'apprentissage petits (haut) et grands (bas). Source: Cours d'apprentissage automatique d'Andrew Ng sur Coursera
Descente en pente avec des facteurs de vitesse d'apprentissage petits (haut) et grands (bas). Source: Cours d'apprentissage automatique d'Andrew Ng sur Coursera
Le plus souvent, le facteur de vitesse d'apprentissage est fixé arbitrairement par l'utilisateur. Dans le meilleur des cas, pour une compréhension intuitive de la valeur la plus appropriée pour déterminer le coefficient de vitesse d'apprentissage, il peut s'appuyer sur des expériences précédentes (ou un autre type de matériel de formation).
Essentiellement, il est assez difficile de choisir la bonne valeur. Le diagramme ci-dessous illustre divers scénarios pouvant survenir lorsque l'utilisateur ajuste indépendamment le taux de vitesse d'apprentissage.
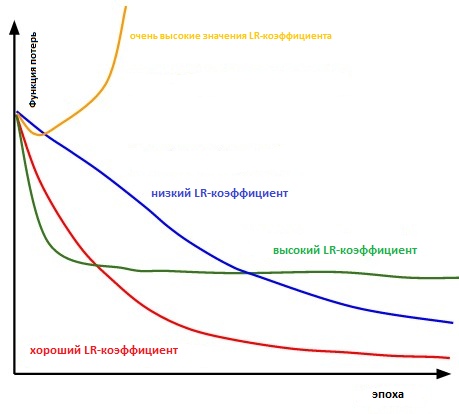 L'influence de divers facteurs de taux d'apprentissage sur la convergence. (Crédit Img: cs231n)
L'influence de divers facteurs de taux d'apprentissage sur la convergence. (Crédit Img: cs231n)
De plus, le facteur de vitesse d'apprentissage affecte la rapidité avec laquelle notre modèle atteint un minimum local (aka obtiendra la meilleure précision). Ainsi, le bon choix dès le début garantit moins de perte de temps pour la formation du modèle. Moins de temps de formation, moins d'argent est dépensé en puissance de calcul GPU dans le cloud.
Existe-t-il un moyen plus pratique de déterminer le taux de coefficient d'apprentissage?
Au paragraphe 3.3. «
Coefficients de taux d'apprentissage cycliques pour les réseaux de neurones » Leslie Smith a défendu le point suivant: l'efficacité de la vitesse d'apprentissage peut être estimée en entraînant le modèle avec une vitesse d'apprentissage initialement réglée faible, qui augmente ensuite (linéairement ou exponentiellement) à chaque itération.
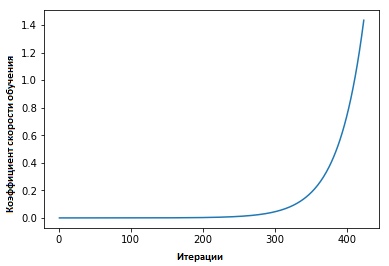 Le facteur de vitesse d'apprentissage augmente après chaque mini-package.
Le facteur de vitesse d'apprentissage augmente après chaque mini-package.
En fixant les valeurs des indicateurs à chaque itération, nous verrons qu'à mesure que la vitesse d'apprentissage augmente, un point sera (atteint) auquel la valeur de la fonction de perte cessera de diminuer et commencera à augmenter. Dans la pratique, notre vitesse d'apprentissage devrait idéalement se situer quelque part à gauche du point inférieur du graphique (comme indiqué dans le graphique ci-dessous). Dans ce cas (la valeur sera) de 0,001 à 0,01.
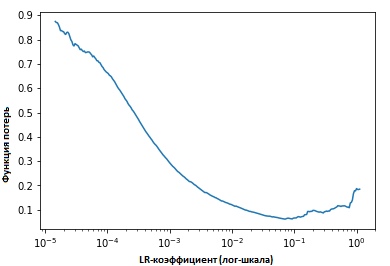
Ce qui précède semble utile. Comment commencer à l'utiliser?
À l'heure actuelle, il existe une fonction prête à l'
emploi dans le package
fast.ia développé par Jeremy Howard, c'est une sorte d'abstraction / add-on au-dessus de la bibliothèque pytorch (similaire à la façon dont cela est fait dans le cas de Keras et Tensorflow).
Il suffit de saisir la commande suivante pour commencer la recherche du coefficient optimal de vitesse d'apprentissage avant (de démarrer) l'entraînement du réseau neuronal.
learn.lr_find() learn.sched.plot_lr()
Améliorer le modèle
Nous avons donc parlé du coefficient de vitesse d'apprentissage, de sa valeur et de la manière d'atteindre sa valeur optimale avant de commencer à former le modèle lui-même.
Nous allons maintenant nous concentrer sur la façon dont le facteur de vitesse d'apprentissage peut être utilisé pour les modèles de réglage.
Sagesse conventionnelle
Habituellement, lorsque l'utilisateur définit son coefficient de vitesse d'apprentissage et commence à entraîner le modèle, il doit attendre que le coefficient de vitesse d'apprentissage commence à chuter et que le modèle atteigne la valeur optimale.
Cependant, à partir du moment où le gradient atteint un plateau, il devient plus difficile d'améliorer les valeurs de la fonction de perte lors de l'apprentissage du modèle. Dans [3], Dauphin exprime l'opinion que la difficulté de minimiser la fonction de perte provient du point de selle, et non du minimum local.
 Un point de selle à la surface des erreurs. Un point de selle est un point du domaine de définition d'une fonction qui est stationnaire pour une fonction donnée, mais qui n'est pas son extremum local
Un point de selle à la surface des erreurs. Un point de selle est un point du domaine de définition d'une fonction qui est stationnaire pour une fonction donnée, mais qui n'est pas son extremum local . (ImgCredit: safaribooksonline)
Alors, comment éviter cela?
Je propose d'envisager plusieurs options. L'un d'eux, général, en utilisant la citation de [1],
... au lieu d'utiliser une valeur fixe pour le coefficient de vitesse d'apprentissage et de la diminuer au fil du temps, si l'entraînement ne lisse plus notre perte, nous allons changer le coefficient de vitesse d'apprentissage à chaque itération selon une fonction cyclique f. Chaque boucle a - en termes de nombre d'itérations - une longueur fixe. Cette méthode permet au coefficient de vitesse d'apprentissage de varier entre des valeurs limites raisonnables. Cela aide vraiment, car, coincé dans les points de selle, en augmentant le coefficient de vitesse d'apprentissage, nous obtenons une intersection plus rapide du plateau des points de selle
Dans [2], Leslie propose la «méthode du triangle», dans laquelle le coefficient de vitesse d'apprentissage est révisé après chacune de plusieurs itérations.

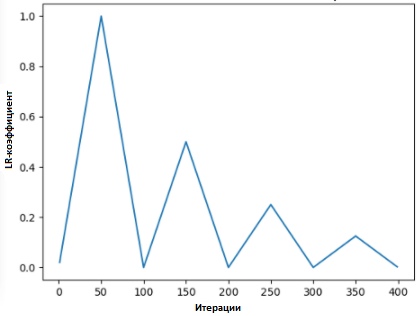 «La méthode des triangles» et «la méthode des triangles-2» sont des méthodes de test cyclique des coefficients de taux d'apprentissage, proposées par Leslie N. Smith. Dans le graphique supérieur, le minimum et le maximum Ir sont maintenus égaux.
«La méthode des triangles» et «la méthode des triangles-2» sont des méthodes de test cyclique des coefficients de taux d'apprentissage, proposées par Leslie N. Smith. Dans le graphique supérieur, le minimum et le maximum Ir sont maintenus égaux.Une autre méthode, non moins populaire et appelée «descente de gradient stochastique avec réinitialisation à chaud», a été proposée par Lonchilov & Hutter [6]. Cette méthode, qui repose sur l'utilisation de la fonction cosinus comme fonction cyclique, redémarre le coefficient de la vitesse d'apprentissage au point maximum de chaque cycle. L'apparition du bit «Hot» est due au fait que lorsque le coefficient de taux d'apprentissage est redémarré, il part non pas du niveau zéro, mais des paramètres auxquels le modèle a atteint l'étape précédente.
Étant donné que cette méthode a des variations, le graphique ci-dessous montre l'une des méthodes de son application, où chaque cycle est lié au même intervalle de temps.
 SGDR - graphique, coefficient du taux d'apprentissage vs. itérations
SGDR - graphique, coefficient du taux d'apprentissage vs. itérations
Ainsi, nous obtenons un moyen de raccourcir la durée de la formation en sautant simplement de temps en temps sur les «pics» (comme indiqué ci-dessous).
 Comparaison des coefficients de taux d'apprentissage fixes et cycliques
Comparaison des coefficients de taux d'apprentissage fixes et cycliques (crédit img:
arxiv.org/abs/1704.00109En plus de gagner du temps, cette méthode, selon les études, améliore la précision de la classification sans réglage et pour moins d'itérations.
Transfert de taux d'apprentissage dans Transfert d'apprentissage
Au cours de
fast.ai, l' accent est mis sur la gestion d'un modèle pré-formé pour résoudre les problèmes d'intelligence artificielle. Par exemple, lors de la résolution de problèmes de classification d'images, les étudiants sont formés à l'utilisation de modèles pré-formés tels que VGG et Resnet50 et à les lier à l'échantillon de données d'image à prévoir.
Afin de résumer la façon dont le modèle est construit dans le programme
fast.ai (à ne pas confondre avec
le package fast. Ai - le package du programme),
voici les étapes que nous prendrons dans une situation ordinaire:
- Activer l'augmentation des données et le précalcul = True
- Utilisez Ir_find () pour trouver le coefficient de taux d'apprentissage le plus élevé, où la perte continue de s'améliorer clairement.
- Entraînez la dernière couche d'activations pré-calculées pour l'ère 1-2.
- Entraînez la dernière couche avec un gain de données (c'est-à-dire, calculer = faux) pendant 1-2 époques avec le cycle _len 1.
- Décongeler toutes les couches.
- Placez les couches précédentes à un facteur de vitesse d'apprentissage qui est 3x-10x en dessous de la couche supérieure suivante
- Réutiliser Ir_find ()
- Former un réseau complet avec le cycle _mult = 2 = 2 jusqu'à ce qu'il commence à se recycler.
Vous remarquerez peut-être que les étapes deux, cinq et sept (ci-dessus) sont liées au taux de facteur d'apprentissage. Dans une partie antérieure de notre article, nous avons souligné le point des deuxièmes étapes mentionnées - où nous avons abordé la façon d'obtenir le meilleur coefficient de vitesse d'apprentissage avant de commencer à entraîner le modèle.
Dans le paragraphe suivant, nous avons expliqué comment vous pouvez réduire le temps de formation à l'aide de SGDR et, en redémarrant périodiquement le facteur de vitesse d'apprentissage, améliorer la précision afin d'éviter les zones où le gradient est proche de zéro.
Dans la dernière section, nous aborderons le concept d'apprentissage différencié et expliquerons comment il est utilisé pour déterminer le coefficient de vitesse d'apprentissage lorsqu'un modèle formé est associé à un modèle pré-formé ...
Qu'est-ce que l'apprentissage différentiel
Il s'agit d'une méthode dans laquelle divers facteurs de vitesse d'entraînement sont définis sur le réseau pendant l'entraînement. Il offre une alternative à la façon dont les utilisateurs ajustent généralement les facteurs de vitesse d'apprentissage - à savoir, en utilisant le même facteur de vitesse d'apprentissage via le réseau pendant la formation.
 La raison pour laquelle j'aime Twitter est une réponse directe de la personne elle-même.
La raison pour laquelle j'aime Twitter est une réponse directe de la personne elle-même.
(Au moment de la rédaction de cet article, Jeremy a publié un article avec Sebastian Ruder, qui a plongé encore plus profondément dans ce sujet. Donc, je crois, le coefficient différentiel de la vitesse d'apprentissage a maintenant un autre nom - réglage exact discriminatoire :)
Pour illustrer le concept plus clairement, nous pouvons nous référer au diagramme ci-dessous, dans lequel le modèle pré-formé est «divisé» en 3 groupes, où chacun est ajusté avec une valeur croissante du coefficient de vitesse d'apprentissage.
 Exemple CNN avec coefficient de taux d'apprentissage différencié
Exemple CNN avec coefficient de taux d'apprentissage différencié . Crédit d'image de [3]
Cette méthode de configuration est basée sur la compréhension suivante: les premières couches contiennent généralement de très petits détails des données, telles que les lignes et les angles - à partir desquels nous n'essaierons pas de changer beaucoup et d'essayer d'enregistrer les informations qu'elles contiennent. En général, il n'est pas vraiment nécessaire de changer leur poids en un grand nombre.
Au contraire, pour les couches suivantes - telles que celles de l'image peintes en vert, où nous obtenons des signes détaillés des données, comme le blanc des yeux, ou de la bouche, ou du nez - la nécessité de les sauvegarder disparaît.
Comment cela se compare-t-il avec d'autres méthodes de réglage fin?
Dans [9], il a été prouvé qu'un réglage fin de l'ensemble du modèle serait trop coûteux, car les utilisateurs peuvent obtenir plus de 100 couches. Le plus souvent, les gens ont recours à l'optimisation du modèle une couche à la fois.
Cependant, c'est la raison d'un certain nombre d'exigences, les soi-disant interférant concurrence, et nécessite plusieurs entrées à travers un ensemble de données, ce qui conduit à la sur-formation de petits ensembles.
Nous avons également montré que les méthodes présentées dans [9] sont capables à la fois d'améliorer la précision et de réduire le nombre d'erreurs dans diverses tâches liées à la classification NRL.
 Résultats tirés de la source [9]
Résultats tirés de la source [9]Références:
[1] Améliorer notre façon de travailler avec le taux d'apprentissage.
[2] La technique du taux d'apprentissage cyclique.
[3] Transférer l'apprentissage en utilisant des taux d'apprentissage différentiels.
[4] Leslie N. Smith. Taux d'apprentissage cycliques pour la formation des réseaux de neurones.
[5] Estimation d'un taux d'apprentissage optimal pour un réseau neuronal profond
[6] Descente de gradient stochastique avec redémarrage à chaud
[7] Optimisation des points forts du Deep Learning en 2017
[8] Leçon 1 Notebook, fast.ai Part 1 V2
[9] Modèles de langue affinés pour la classification des textes