Je m'appelle Ivan Bondarenko. Je travaille sur des algorithmes d'apprentissage automatique pour l'analyse de texte et le langage parlé depuis 2005 environ. Maintenant, je travaille à Moscou PhysTech en tant que développeur scientifique de premier plan du laboratoire de solutions commerciales basé sur le centre de compétence NTI pour l'intelligence artificielle MIPT et dans la société Data Monsters, qui s'occupe du développement pratique de systèmes interactifs pour résoudre divers problèmes dans l'industrie. J'enseigne aussi un peu à notre université. Mon histoire sera consacrée à ce qu'est un bot de chat, à la façon dont les algorithmes d'apprentissage automatique et autres approches sont utilisés pour automatiser la communication homme-ordinateur et où il peut être mis en œuvre.
La version complète de mon discours à la "Nuit des histoires scientifiques" peut être vue dans la
vidéo , et je donnerai de brefs résumés dans le texte ci-dessous.

Capacités d'algorithme
Tout d'abord, les algorithmes d'interaction humaine sont utilisés avec succès dans les centres d'appels. Le travail d'un opérateur de centre d'appels est très difficile et coûteux. De plus, dans de nombreuses situations, il est presque impossible de résoudre complètement le problème de la communication homme-ordinateur. C’est une chose lorsque nous travaillons avec une banque, qui compte généralement plusieurs milliers de clients. Vous pouvez recruter le personnel du centre d'appels, qui servirait ces clients et leur parlerait. Mais lorsque nous résolvons des tâches plus ambitieuses (par exemple, nous produisons des smartphones ou d'autres appareils électroniques grand public), nos clients ne sont pas plusieurs milliers, mais plusieurs dizaines de millions dans le monde. Et nous voulons comprendre quels problèmes les gens ont avec nos produits. En règle générale, les utilisateurs partagent des informations entre eux dans les forums ou écrivent au service d'assistance du fabricant de smartphones. Les opérateurs en direct ne seront pas en mesure de faire face au travail sur une énorme base de clients, et ici les algorithmes viennent à la rescousse, qui peuvent fonctionner en mode multicanal, desservant un grand nombre de personnes.
Pour résoudre de tels problèmes, pour construire des algorithmes pour des systèmes de dialogue qui pourraient interagir avec une personne et extraire du sens, des informations importantes à partir de messages arbitraires, il y a tout un domaine dans le domaine de la linguistique informatique - l'analyse des textes en langage naturel. Un robot doit être capable de lire, comprendre, écouter, parler, etc. Cette zone - le traitement du langage naturel - se décompose en plusieurs parties.
Comprendre le texte (Natural Language Understanding, NLU).
Lorsqu'un bot communique avec une personne et qu'une personne écrit quelque chose dans le bot, vous devez comprendre ce qui est écrit, ce que l'utilisateur voulait, ce qu'il a mentionné dans son discours. Comprendre les intentions de l'utilisateur, la soi-disant intention - ce qu'une personne veut: réémettre une carte bancaire ou commander une pizza. Et l'attribution des entités nommées, c'est-à-dire des choses dont l'utilisateur parle spécifiquement: si c'est de la pizza, alors "Margarita" ou "Hawaiian", si la carte, alors quel système - MasterCard, World et ainsi de suite.

Et enfin, une compréhension de la tonalité du message - dans quel état émotionnel une personne est. L'algorithme doit être en mesure de détecter dans quelle clé le message est écrit, soit il s'agit d'un texte d'actualités, soit ce message provient d'une personne qui communique avec notre bot afin de répondre adéquatement à la clé.
 Génération du texte (Natural Language Generation)
Génération du texte (Natural Language Generation) - une réponse adéquate à une demande humaine dans la même langue humaine (naturel), et non une plaque complexe et pas des phrases formelles.
Reconnaissance vocale et synthèse vocale (Speech-to-Text et Text-to-Speech). Si un chatbot ne correspond pas seulement avec une personne, mais parle et écoute, vous devez lui apprendre à comprendre le langage parlé, convertir les vibrations sonores en texte, puis analyser ce texte avec un module de compréhension de texte et générer des vibrations sonores à partir du texte de réponse, à son tour que la personne, l'abonné entendra.
Types de chat bots
Les chatbots incluent plusieurs architectures clés.
Le chatbot qui répond aux questions les plus fréquemment posées (FAQ-chatbot) est l'option la plus simple. Nous pouvons toujours formuler un ensemble de questions modèles que les gens posent. Pour un site de livraison de plats cuisinés, ce sont généralement des questions: «combien coûtera la livraison», «livrez-vous dans le quartier Pervomaisky», etc. Vous pouvez les regrouper selon plusieurs classes, intentions, intentions des utilisateurs. Et pour chaque intention, sélectionnez des réponses typiques.
Bot de chat ciblé (bot orienté objectif). Ici, j'ai essayé de montrer l'architecture d'un tel chatbot, qui est implémentée dans le projet iPavlov. iPavlov est un projet de création d'intelligence artificielle conversationnelle. En particulier, un chatbot ciblé aide l'utilisateur à atteindre un certain objectif (par exemple, réserver une table dans un restaurant ou commander une pizza, ou apprendre quelque chose sur des problèmes à la banque). Il ne s'agit pas seulement de la réponse à la question (question-réponse - sans aucun contexte). Le chatbot ciblé possède un module pour comprendre le texte, la gestion du dialogue et un module pour générer des réponses.
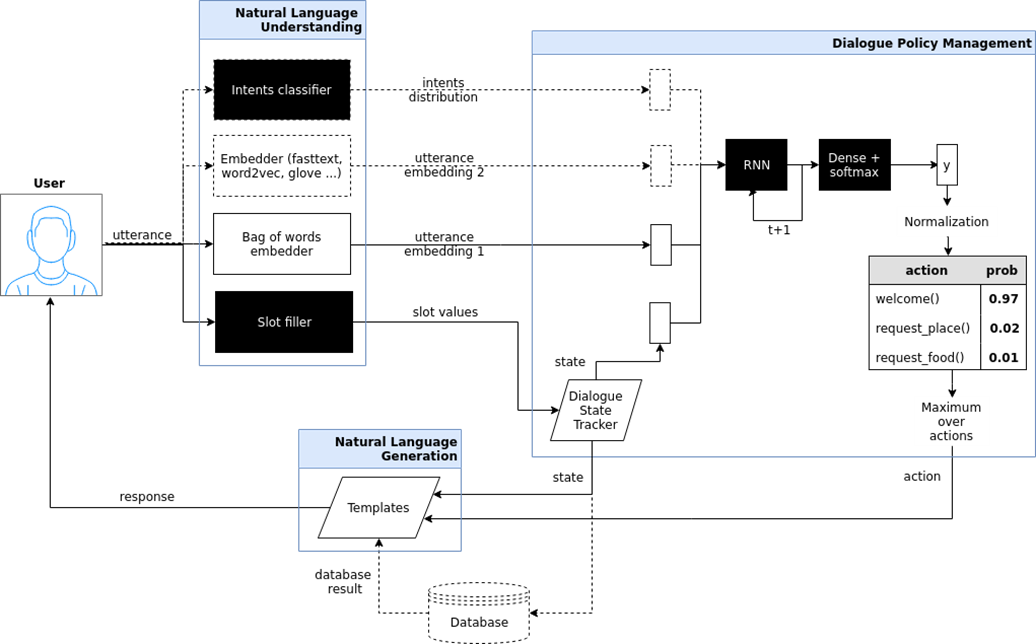 Les bots de chat du système de réponse aux questions, le système de réponse aux questions et seulement les «talkers» (chit chat bot).
Les bots de chat du système de réponse aux questions, le système de réponse aux questions et seulement les «talkers» (chit chat bot). Si les deux types de robots de chat précédents répondent aux questions les plus fréquemment posées ou conduisent l'utilisateur à travers la boîte de dialogue, en fin de compte, en aidant à réserver un restaurant, en déterminant ce que l'utilisateur veut, une cuisine chinoise ou italienne, etc., alors la question-réponse un système est un autre type de chat bot. Le but d'un tel chat n'est pas de se déplacer le long de la colonne du dialogue et non seulement de classer les intentions de l'utilisateur, mais de fournir une recherche d'informations - pour trouver le document le plus pertinent qui correspond à la question de la personne et l'endroit dans le document où la réponse est contenue. Par exemple, les employés d'un grand détaillant au lieu de mémoriser des instructions régissant le travail ou de chercher une réponse où mettre du sarrasin, posent une question à un tel chatbot sur la base d'un système de questions-réponses.
Types d'apprentissage automatique
La reconnaissance des intentions, l'attribution des entités nommées, la recherche dans les documents et la recherche de lieux dans un document qui correspondent à la sémantique d'une question - tout cela sans apprentissage automatique, sans une sorte d'analyse statistique est impossible à mettre en œuvre. Par conséquent, la base des robots de discussion modernes est l'apprentissage automatique - les méthodes de tâche, les approximations de certains modèles cachés qui existent dans de grands ensembles de données et l'identification de ces modèles. Il est logique d'appliquer cette approche lorsqu'il existe des modèles, des tâches, mais il est impossible de trouver une formule simple, un formalisme pour décrire ce modèle.
Il existe plusieurs types d'apprentissage automatique: avec un enseignant (apprentissage supervisé), sans enseignant (apprentissage non supervisé), avec renforcement (apprentissage par renforcement). Nous sommes principalement intéressés par la tâche d'enseigner avec un enseignant - lorsqu'il y a des images d'entrée et des instructions (étiquettes) de l'enseignant et la classification de ces images. Ou entrez des signaux vocaux et leur classification. Et nous enseignons notre bot, notre algorithme pour reproduire le travail d'un enseignant.
D'accord, tout semble être cool. Et comment apprendre à un ordinateur à comprendre les textes? Le texte est un objet complexe, et comment les lettres se transforment-elles en chiffres et proposent-elles une description vectorielle du texte? Il y a l'option la plus simple - un «sac de mots». Nous demandons au dictionnaire de tout le système, par exemple, tous les mots qui sont dans la langue russe, et formulons de tels vecteurs très clairsemés avec des fréquences de mots. Cette option convient aux questions simples, mais pour les tâches plus complexes, elle ne convient pas.
En 2013, une sorte de révolution a eu lieu dans la modélisation des mots et des textes. Thomas Mikolov a proposé une approche spéciale pour la représentation vectorielle efficace des mots basée sur l'hypothèse de distribution. Si différents mots sont trouvés dans le même contexte, alors ils ont quelque chose en commun. Par exemple: «Les scientifiques ont mené une analyse des algorithmes» et «Les scientifiques ont mené une étude des algorithmes». Ainsi, «analyse» et «recherche» sont des synonymes et signifient à peu près la même chose. Par conséquent, vous pouvez apprendre à un réseau neuronal spécial à prédire un mot par contexte ou un contexte par mot.
Enfin, comment s'entraîne-t-on? Afin de former le bot à comprendre les intentions, les véritables intentions, vous devez annoter manuellement un tas de textes à l'aide de programmes spéciaux. Pour apprendre au bot à comprendre les entités nommées - le nom de la personne, le nom de l'entreprise, l'emplacement - vous devez également placer des textes. En conséquence, d'une part, l'algorithme d'apprentissage avec l'enseignant est le plus efficace, il vous permet de créer un système de reconnaissance efficace, mais, d'autre part, un problème se pose: vous avez besoin de grands ensembles de données étiquetés, ce qui est coûteux et prend du temps. Dans le processus de balisage des ensembles de données, il peut y avoir des erreurs causées par le facteur humain.
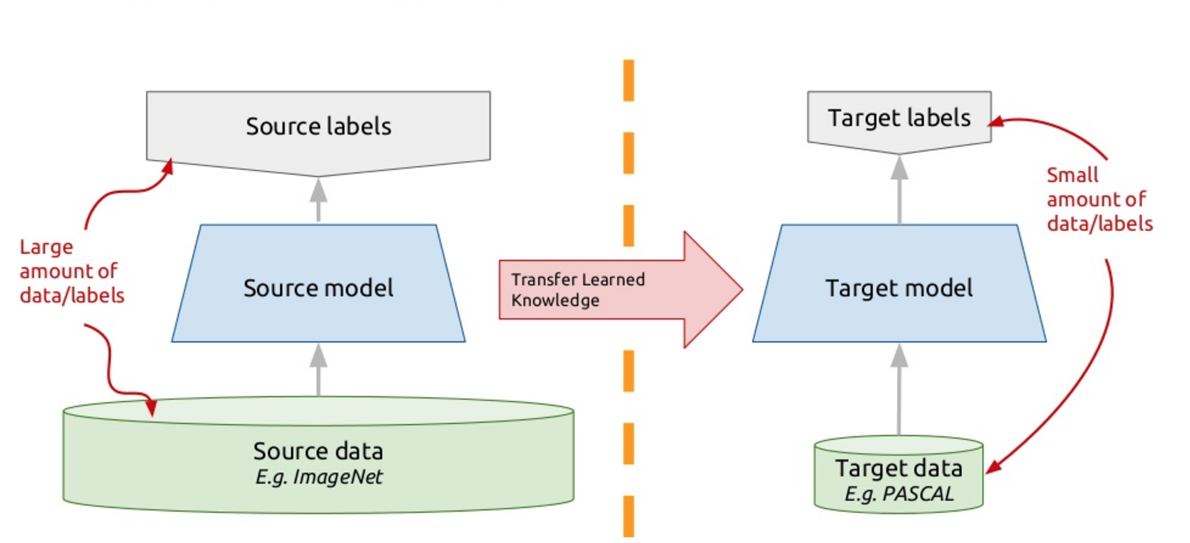
Pour résoudre ce problème, les chatbots modernes utilisent ce que l'on appelle l'apprentissage par transfert - apprentissage par transfert. Ceux qui connaissent de nombreuses langues étrangères ont probablement remarqué une telle nuance qu'il est plus facile d'apprendre une autre langue étrangère que la première. En fait, lorsque vous étudiez une nouvelle tâche, vous essayez d'utiliser votre expérience passée pour cela. Ainsi, l'apprentissage par transfert est basé sur ce principe: nous enseignons l'algorithme pour résoudre un problème, pour lequel nous avons un grand ensemble de données. Et puis cet algorithme entraîné (c'est-à-dire que nous prenons l'algorithme non pas à partir de zéro, mais formé pour résoudre un autre problème), nous nous entraînons à résoudre notre problème. Ainsi, nous obtenons une solution efficace en utilisant une petite variété de données.
Un tel modèle est ELMo (Embeddings from Language Models), comme ELMo de Sesame Street. Nous utilisons des réseaux de neurones récurrents, ils ont de la mémoire et peuvent traiter des séquences. Par exemple: «Le programmeur Vasya aime la bière. Tous les soirs après le travail, il se rend au Jonathan et manque un verre ou deux. " Alors, qui est-il? Est-ce ce soir, est-ce une bière, ou est-ce un programmeur Vasya? Un réseau neuronal qui traite les mots en tant qu'éléments d'une séquence, compte tenu du contexte, un réseau neuronal récurrent, peut comprendre les relations, résoudre ce problème et mettre en évidence certaines sémantiques.
Nous formons un réseau neuronal si profond pour modéliser des textes. Formellement, c'est la tâche d'apprendre avec un enseignant, mais l'enseignant est le texte non placé lui-même. Le mot suivant dans le texte est un enseignant par rapport à tous les précédents. Ainsi, nous pouvons utiliser des gigaoctets, des dizaines de gigaoctets de textes, former des modèles efficaces que la sémantique de ces textes met en valeur. Et puis, lorsque nous utilisons les Embeddings from Language Models (ELMo) en mode sortie, nous donnons le mot en fonction du contexte. Pas seulement un bâton, mais restons. Nous regardons ce que le réseau de neurones génère à ce moment-là, quels signaux. Nous catanalisons ces signaux et obtenons une représentation vectorielle du mot dans un texte spécifique, en tenant compte de sa signification sématique spécifique.
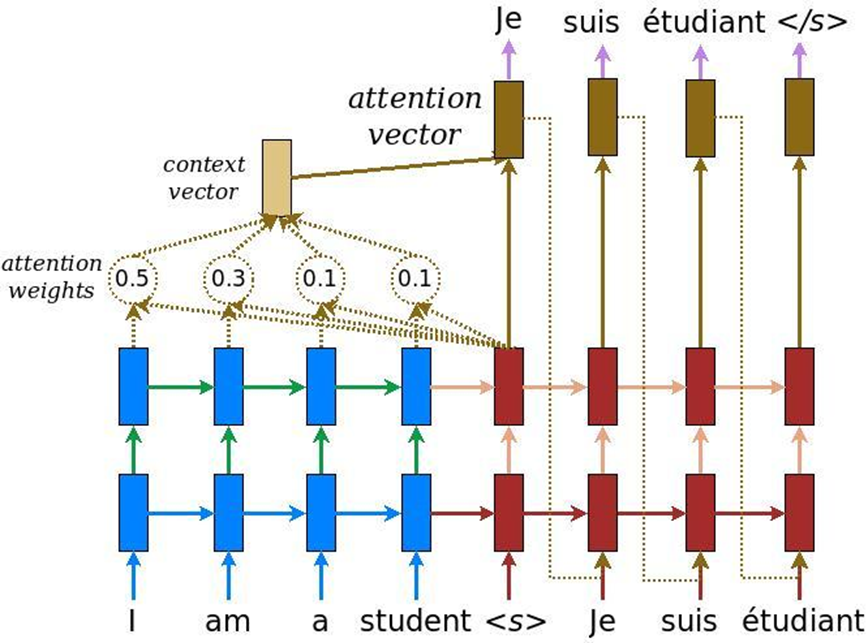
Dans l'analyse des textes, il y a une autre caractéristique: lorsque la tâche de traduction automatique est résolue, la même signification peut être transmise par un nombre de mots en anglais et un autre nombre de mots en russe. En conséquence, il n'y a pas de comparaison linéaire et nous avons besoin d'un mécanisme qui se concentrerait sur certains morceaux de texte afin de les traduire correctement dans une autre langue. Initialement, l'attention a été inventée pour la traduction automatique - la tâche de convertir un texte en un autre avec des systèmes neuronaux récurrents conventionnels. À cela, nous ajoutons une couche spéciale d'attention, qui à chaque instant évalue quel mot est important pour nous maintenant.
Mais alors, les gars de Google ont pensé, pourquoi ne pas utiliser le mécanisme d'attention sans réseaux de neurones récurrents - juste de l'attention. Et ils ont mis au point une architecture appelée transformateur (BERT (Bidirectional Encoder Representations from Transformers)).
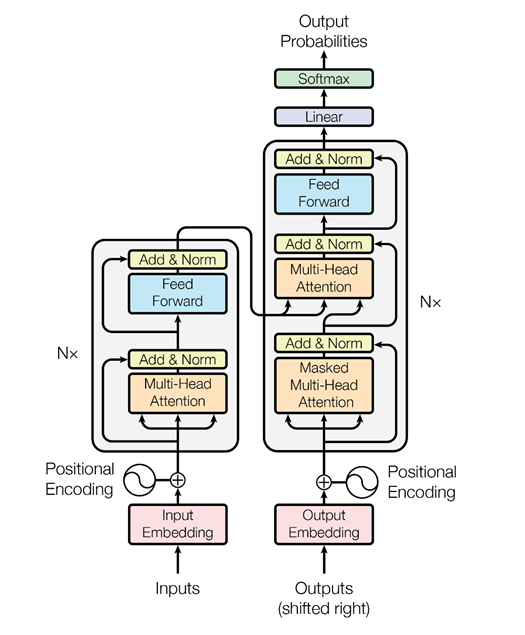
Sur la base d'une telle architecture, alors qu'il n'y a qu'une attention à plusieurs têtes, des algorithmes spéciaux ont été inventés qui peuvent également analyser la relation des mots dans les textes, la relation des textes les uns avec les autres - comme ELMo le fait, de façon plus astucieuse. Premièrement, c'est un réseau plus cool et plus complexe. Deuxièmement, nous résolvons deux problèmes simultanément, et non un, comme dans le cas de la modélisation ELMo-langage, la prévision. Nous essayons de restaurer les mots cachés dans le texte et de restaurer les liens entre les textes. Autrement dit, disons: «Le programmeur Vasya aime la bière. Chaque soir, il va au bar. » Deux textes sont interconnectés. «Le programmeur Vasya aime la bière. Les grues volent vers le sud à l'automne »- ce sont deux textes sans rapport. Encore une fois, ces informations peuvent être extraites de textes non alloués, formés BERT et obtenir des résultats très sympas.
Cela a été publié en novembre dernier dans l'article «L'attention est tout ce dont vous avez besoin», que je recommande fortement de lire. Pour le moment, c'est le résultat le plus cool dans le domaine de l'analyse de texte pour résoudre divers problèmes: pour la classification de texte (reconnaissance de la tonalité, intentions de l'utilisateur); pour les systèmes de questions et réponses; pour reconnaître les entités nommées, etc. Les systèmes de dialogue modernes utilisent BERT, des intégrations contextuelles pré-formées (ELMo ou BERT) afin de comprendre ce que veut l'utilisateur. Mais le module de gestion du dialogue est encore souvent conçu sur la base de règles, car un dialogue particulier peut être très dépendant du sujet ou même de la tâche.