Salut, Habr.
Cet article sera dans un format un peu "vendredi", aujourd'hui nous traiterons de la PNL. Pas le PNL sur lequel les livres sont vendus dans les passages souterrains, mais celui que
Natural Language Processing traite les langues naturelles. Comme exemple d'un tel traitement, la génération de texte utilisant un réseau neuronal sera utilisée. Nous pouvons créer des textes dans n'importe quelle langue, du russe ou de l'anglais, au C ++. Les résultats sont très intéressants, vous pouvez probablement le deviner sur la photo.

Pour ceux qui sont intéressés par ce qui se passe, les résultats et le code source sont sous la coupe.
Préparation des données
Pour le traitement, nous utiliserons une classe spéciale de réseaux de neurones - les réseaux de neurones dits récurrents (RNN). Ce réseau diffère de l'habituel en ce qu'en plus des cellules habituelles, il possède des cellules mémoire. Cela nous permet d'analyser des données d'une structure plus complexe, et en fait, plus proche de la mémoire humaine, car nous ne partons pas non plus de toutes les pensées «à partir de zéro». Pour écrire du code, nous utiliserons les
réseaux LSTM (Long Short-Term Memory), car ils sont déjà pris en charge par Keras.
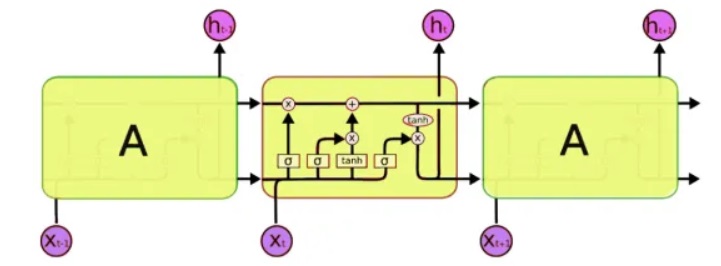
Le problème suivant qui doit être résolu est, en fait, de travailler avec du texte. Et ici, il y a deux approches - pour soumettre des symboles ou les mots entiers à l'entrée. Le principe de la première approche est simple: le texte est divisé en blocs courts, où les «entrées» sont un morceau de texte et la «sortie» est le caractère suivant. Par exemple, pour la dernière phrase, «les entrées sont un morceau de texte»:
input: output: ""
input: : output: ""
input: : output:""
input: : output: ""
input: : output: "".
Et ainsi de suite. Ainsi, le réseau neuronal reçoit des fragments de texte en entrée et en sortie les caractères qu'il doit former.
La deuxième approche est fondamentalement la même, seuls des mots entiers sont utilisés à la place des mots. Tout d'abord, un dictionnaire de mots est compilé et des nombres sont saisis à la place des mots à l'entrée du réseau.
Ceci, bien sûr, est une description plutôt simplifiée. Keras a
déjà des exemples de génération de texte, mais d'une part, ils ne sont pas décrits en détail, et d'autre part, tous les didacticiels en anglais utilisent des textes plutôt abstraits comme Shakespeare, qui sont difficiles à comprendre pour le natif. Eh bien, nous testons un réseau de neurones sur notre grand et puissant réseau, qui, bien sûr, sera plus clair et compréhensible.
Formation réseau
En tant que texte d'entrée, j'ai utilisé ... les commentaires de Habr, la taille du fichier source est de 1 Mo (il y a en fait plus de commentaires, bien sûr, mais je n'ai dû utiliser qu'une partie, sinon le réseau de neurones aurait été formé pendant une semaine et les lecteurs n'auraient pas vu ce texte vendredi). Permettez-moi de vous rappeler que seules les lettres sont alimentées à l'entrée d'un réseau neuronal, le réseau ne «sait» rien du langage ou de sa structure. Allons-y, commençons la formation du réseau.
5 minutes de formation:Jusqu'à présent, rien n'est clair, mais vous pouvez déjà voir des combinaisons de lettres reconnaissables:
. . . «
15 minutes de formation:Le résultat est déjà nettement meilleur:
« » — « » » —Pour une raison quelconque, tous les textes se sont révélés être sans points et sans majuscules, peut-être que le traitement utf-8 n'a pas été fait correctement. Mais dans l'ensemble, c'est impressionnant. En analysant et en se souvenant uniquement des codes de symboles, le programme a effectivement appris «indépendamment» des mots russes et peut générer un texte d'aspect assez crédible.
Non moins intéressant est le fait que le programme mémorise assez bien le style de texte. Dans l'exemple suivant, le texte d'une loi a été utilisé comme outil pédagogique. Temps de formation réseau 5 minutes.
"" , , , , , , , ,
Et ici, les annotations médicales pour les médicaments ont été utilisées comme un ensemble d'entrée. Temps de formation réseau 5 minutes.
, ,
Ici, nous voyons des phrases presque entières. Cela est dû au fait que le texte original est court et que le réseau neuronal a en fait "mémorisé" certaines phrases dans leur ensemble. Cet effet est appelé «recyclage» et doit être évité. Idéalement, vous devez tester un réseau de neurones sur de grands ensembles de données, mais la formation dans ce cas peut prendre de nombreuses heures, et malheureusement je n'ai pas de supercalculateur supplémentaire.
Un exemple amusant d'utilisation d'un tel réseau est la génération de noms. Après avoir téléchargé une liste de noms masculins et féminins dans le fichier, j'ai obtenu de nouvelles options assez intéressantes qui conviendraient tout à fait à un roman de science-fiction: Rlar, Laaa, Aria, Arera, Aelia, Ninran, Air. Quelque chose en eux sent le style d'Efremov et de la nébuleuse d'Andromède ...
C ++
Ce qui est intéressant, c'est que dans l'ensemble, un réseau de neurones, c'est comme se souvenir. L'étape suivante consistait à vérifier comment le programme gère le code source. Comme test, j'ai pris différentes sources C ++ et les ai combinées en un seul fichier texte.
Honnêtement, le résultat a surpris encore plus que dans le cas de la langue russe.
5 minutes de formationMerde, c'est presque du vrai C ++.
if ( snd_pcm_state_channels = 0 ) { errortext_ = "rtapialsa::probedeviceopen: esror stream_.buffer stream!"; errortext_ = errorstream_.str(); goto unlock; } if ( stream_.mode == input && stream_.mode == output || false; if ( stream_.state == stream_stopped ) { for ( unsigned int i=0; i<stream_.nuserbuffer[i] ) { for (j=0; j<info.channels; } } }
30 minutes de formation void maxirecorder::stopstream() { for (int i = 0; i < ainchannels; i++ ) { int input=(stream, null; conternallock( pthread_cond_wate);
Comme vous pouvez le voir, le programme a "appris" à écrire des fonctions entières. En même temps, il séparait complètement «humainement» les fonctions par un commentaire avec des astérisques, mettait des commentaires dans le code, et tout ça. Je voudrais apprendre un nouveau langage de programmation avec une telle vitesse ... Bien sûr, il y a des erreurs dans le code, et bien sûr, il ne se compilera pas. Et au fait, je n'ai pas formaté le code, le programme a également appris à mettre des parenthèses et des retraits "moi-même".
Bien sûr, ces programmes n'ont pas l'essentiel - le
sens , et ont donc l'air surréaliste, comme s'ils étaient écrits dans un rêve, ou qu'ils n'étaient pas écrits par une personne en parfaite santé. Néanmoins, les résultats sont impressionnants. Et peut-être qu'une étude plus approfondie de la génération de différents textes aidera à mieux comprendre certaines des maladies mentales de vrais patients. Par ailleurs, comme suggéré dans les commentaires, une telle maladie mentale dans laquelle une personne parle dans un texte grammaticalement lié mais complètement dénué de sens (
schizophasie ) existe.
Conclusion
Les réseaux de neurones récréatifs sont considérés comme très prometteurs, et c'est en effet un grand pas en avant par rapport aux réseaux «ordinaires» comme MLP, qui n'ont pas de mémoire. En effet, les capacités des réseaux de neurones à stocker et traiter des structures assez complexes sont impressionnantes. C'est après ces tests que j'ai pensé pour la première fois qu'Ilon Mask avait probablement raison quand j'ai écrit que l'IA à l'avenir pourrait être "le plus grand risque pour l'humanité" - même si un simple réseau de neurones peut facilement se souvenir et se reproduire modèles assez complexes, que peut faire un réseau de milliards de composants? Mais d'un autre côté, n'oubliez pas que notre réseau de neurones ne peut pas
penser , il ne se souvient essentiellement que mécaniquement de séquences de caractères, ne comprenant pas leur signification. C'est un point important - même si vous entraînez un réseau neuronal sur un supercalculateur et un énorme ensemble de données, au mieux il apprendra à générer des phrases grammaticalement correctes à 100%, mais complètement dénuées de sens.
Mais il ne sera pas supprimé en philosophie, l'article s'adresse toujours plus aux praticiens. Pour ceux qui veulent expérimenter par eux-mêmes, le
code source de Python 3.7 est sous le spoiler. Ce code est une compilation de divers projets github, et n'est pas un échantillon du meilleur code, mais il semble accomplir sa tâche.
L'utilisation du programme ne nécessite pas de compétences en programmation, il suffit de savoir installer Python. Exemples de démarrage à partir de la ligne de commande:
- Création et formation de modèles et génération de texte:
python. \ keras_textgen.py --text = text_habr.txt --epochs = 10 --out_len = 4000
- Génération de texte uniquement sans formation de modèle:
python. \ keras_textgen.py --text = text_habr.txt --epochs = 10 --out_len = 4000 --generate
Je pense que cela s'est avéré être un générateur de texte de travail très
génial ,
qui est utile pour écrire des articles sur Habr . Il est particulièrement intéressant de tester des textes volumineux et un grand nombre d'itérations de formation.Si quelqu'un a accès à des ordinateurs rapides, il serait intéressant de voir les résultats.
Si quelqu'un veut étudier le sujet plus en détail, une bonne description de l'utilisation de RNN avec des exemples détaillés peut être trouvée à
http://karpathy.imtqy.com/2015/05/21/rnn-effectiveness/ .
PS: Et enfin, quelques versets;) Il est intéressant de noter que ce n'est pas moi qui ai fait la mise en forme du texte ou même l'ajout d'étoiles, "c'est moi-même". La prochaine étape est intéressante pour vérifier la possibilité de dessiner des images et de composer de la musique. Je pense que les réseaux de neurones sont assez prometteurs ici.
xxx
pour certains, être pris dans des biscuits - tout porte bonheur dans une cour à pain.
et sous la soirée de tamaki
sous une bougie, prenez une montagne.
xxx
bientôt fils mons à petachas en tram
la lumière invisible sent la joie
c'est pourquoi je frappe ensemble grandit
vous ne serez pas malade d'une inconnue.
coeur à cueillir dans l'ogora décalé,
ce n'est pas si vieux que les céréales mangent,
Je garde le pont vers le ballon pour voler.
de la même manière Darina à Doba,
J'entends dans mon cœur de neige sur ma main.
notre chant blanc combien doux dumina
J'ai détourné le volot de la bête de minerai.
xxx
vétérinaire crucifier fretters avec un sort
et renversé sous l'oubli.
et vous mettez, comme avec les branches de cuba
brille en elle.
o plaisir à zakoto
avec le vol de lait.
oh tu es une rose, lumière
lumière des nuages à portée de main:
et roulé à l'aube
comment allez-vous, mon cavalier!
il sert le soir, pas jusqu'aux os,
la nuit à Tanya la lumière bleue
comme une sorte de tristesse.Et les derniers versets dans l'apprentissage par mot. Ici, la rime a disparu, mais une signification est apparue (?).
et toi, de la flamme
les étoiles.
parlé à des individus éloignés.
vous inquiète rus ,, vous ,, demain.
"Pluie de colombe,
et la maison des meurtriers,
pour la princesse
son visage.
xxx
oh berger, agite les chambres
sur un bosquet au printemps.
Je traverse le coeur de la maison jusqu'à l'étang,
et les souris guilleret
Cloches de Nijni Novgorod.
mais n'ayez crainte, le vent du matin,
avec un chemin, avec un club de fer,
et pensé avec l'huître
hébergé sur un étang
en rakit appauvri.