
De nombreuses applications réseau se composent d'un serveur Web qui traite le trafic en temps réel et d'un gestionnaire supplémentaire qui s'exécute en arrière-plan de manière asynchrone. Il existe de nombreux conseils utiles pour vérifier l'état du trafic, et la communauté ne cesse de développer des outils comme Prometheus qui aident à l'évaluation. Mais les gestionnaires ne sont parfois pas moins - et même plus - importants. Ils ont également besoin d'attention et d'évaluation, mais il y a peu de conseils sur la façon de le faire tout en évitant les pièges courants.
Cet article est consacré aux pièges les plus courants dans le processus d'évaluation des gestionnaires asynchrones, à l'aide d'un exemple d'incident dans un environnement de production où, même avec des métriques, il était impossible de déterminer exactement ce que faisaient les gestionnaires. L'utilisation de métriques a tellement déplacé l'attention que les métriques elles-mêmes ont ouvertement menti, disent-ils, à vos gestionnaires en enfer.
Nous verrons comment utiliser les métriques de manière à fournir une estimation précise, et en conclusion, nous montrerons l'implémentation de référence de l'open source prometheus-client-tracer , que vous pouvez utiliser dans vos applications.
Incident
Les alertes sont arrivées à une vitesse mitrailleuse: le nombre d'erreurs HTTP a fortement augmenté, et les panneaux de contrôle ont confirmé que les files d'attente de demandes étaient en augmentation et que le temps de réponse était épuisé. Environ 2 minutes plus tard, les files d'attente ont été effacées et tout est revenu à la normale.
En y regardant de plus près, il s'est avéré que nos serveurs API se sont levés, attendant une réponse de la base de données, ce qui a provoqué le blocage et la soudaine interruption de toute l'activité. Et quand on considère que la charge la plus lourde tombe plus souvent au niveau des processeurs asynchrones, ils sont devenus les principaux suspects. La question logique était: que font-ils là-bas?!
La métrique Prometheus montre ce que le processus prend du temps, le voici:
# HELP job_worked_seconds_total Sum of the time spent processing each job class # TYPE job_worked_seconds_total counter job_worked_seconds_total{job}
En suivant le temps d'exécution total de chaque tâche et la fréquence à laquelle la métrique change, nous découvrirons combien de temps de travail a été consacré. Si pour une période de 15 secondes. le nombre a augmenté de 15, cela implique 1 gestionnaire occupé (une seconde pour chaque seconde passée), tandis qu'une augmentation de 30 signifie 2 gestionnaires, etc.
Un horaire de travail pendant l'incident montrera à quoi nous sommes confrontés. Les résultats sont décevants; l'heure de l'incident (16: 02-16: 04) est marquée par la ligne rouge alarmante:

Activité du gestionnaire pendant l'incident: un écart notable est visible.
En tant que personne qui a débogué après ce cauchemar, cela m'a fait mal de voir que la courbe d'activité était tout en bas juste pendant l'incident. C'est le moment de travailler avec les hooks Web, dans lesquels nous avons 20 gestionnaires dédiés. D'après les journaux, je sais qu'ils étaient tous en activité, et je m'attendais à ce que la courbe soit d'environ 20 secondes, et j'ai vu une ligne presque droite. De plus, voir ce grand pic bleu à 16h05? À en juger par le calendrier, 20 processeurs à un seul thread ont passé 45 secondes. pour chaque seconde d'activité, mais est-ce possible?!
Où et qu'est-ce qui a mal tourné?
Le calendrier de l'incident est mensonger: il masque l'activité de travail et montre en même temps des choses inutiles - selon l'endroit où mesurer. Pour savoir pourquoi cela se produit, vous devez prendre en compte la mise en œuvre du suivi des métriques et comment il interagit avec la collecte des métriques par Prometheus.
En commençant par la façon dont les gestionnaires collectent les métriques, vous pouvez esquisser un schéma d'implémentation de workflow approximatif (voir ci-dessous). Remarque: les gestionnaires ne mettent à jour les mesures qu'à la fin d'une tâche .
class Worker JobWorkedSecondsTotal = Prometheus::Client::Counter.new(...) def work job = acquire_job start = Time.monotonic_now job.run ensure # run after our main method block duration = Time.monotonic_now - start JobWorkedSecondsTotal.increment(by: duration, labels: { job: job.class }) end end
Prometheus (avec sa philosophie d'extraction de métriques) envoie une requête GET à chaque gestionnaire toutes les 15 secondes, enregistrant les valeurs des métriques au moment de la demande. Les gestionnaires mettent constamment à jour les mesures des tâches terminées et, au fil du temps, nous pouvons afficher graphiquement la dynamique des changements de valeurs.
Le problème de sous-évaluation et de réévaluation commence à apparaître chaque fois que le temps nécessaire pour terminer une tâche dépasse le temps d'attente pour une demande qui arrive toutes les 15 secondes. Par exemple, une tâche démarre 5 secondes avant la demande et se termine 1 seconde après. Entièrement et généralement, il dure 6 secondes, mais ce temps n'est visible que lors de l'estimation des coûts de temps effectués après la demande, alors que 5 de ces 6 secondes sont passées avant la demande.
Les indicateurs sont encore plus impies si les tâches prennent plus de temps que la période de rapport (15 secondes). Pendant l'exécution de la tâche pendant 1 minute, Prometheus aura le temps d'envoyer 4 demandes aux processeurs, mais la métrique ne sera mise à jour qu'après la quatrième.
Après avoir tracé une chronologie de l'activité de travail, nous verrons comment le moment où la métrique est mise à jour affecte ce que voit Prométhée. Dans le diagramme ci-dessous, nous divisons la chronologie de deux gestionnaires en plusieurs segments qui affichent des tâches de durées différentes. Les étiquettes rouges (15 secondes) et bleues (30 secondes) indiquent 2 échantillons de données Prometheus; Les tâches qui ont servi de source de données pour l'évaluation sont respectivement surlignées en couleur.
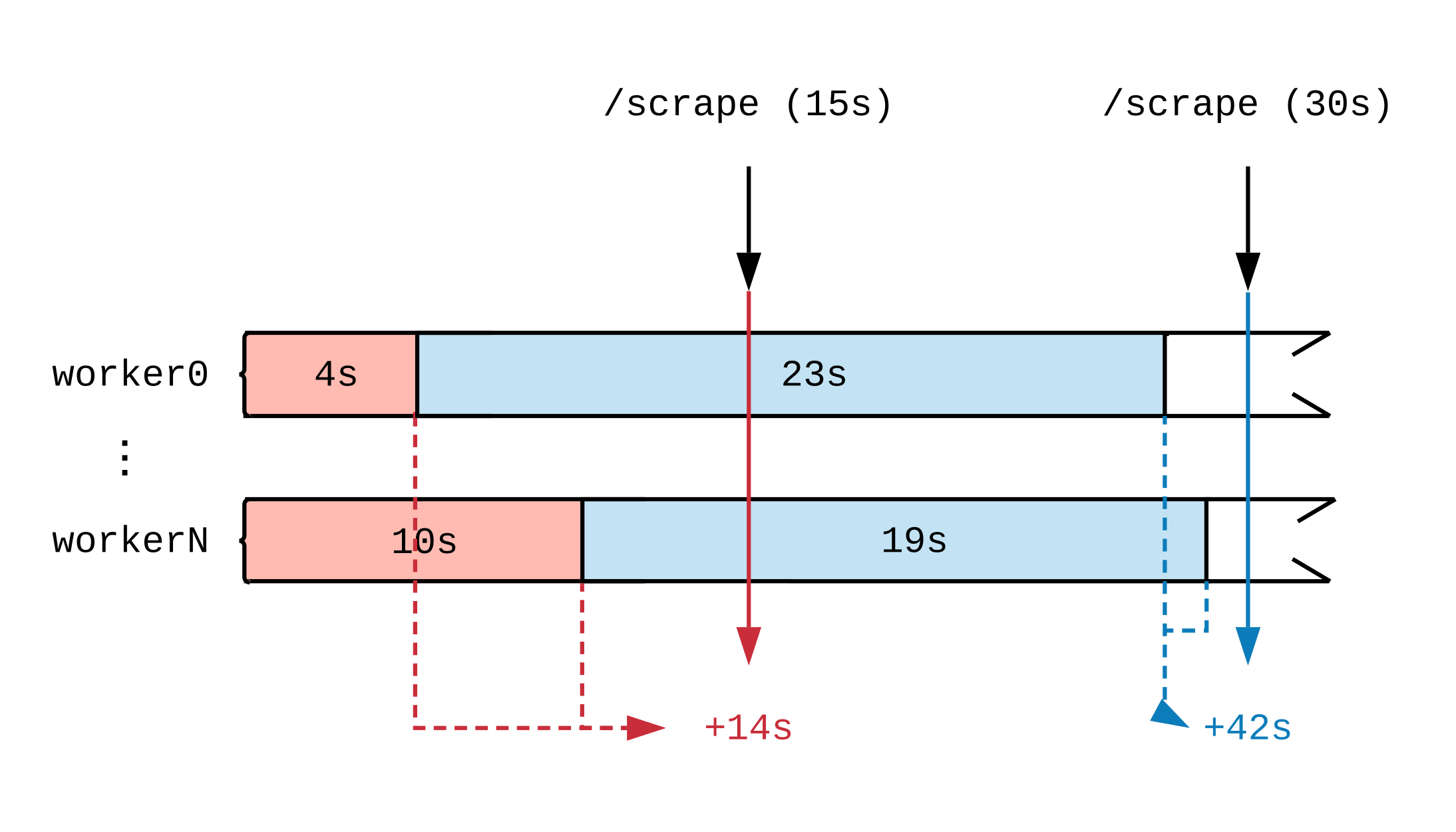
Indépendamment de ce que les gestionnaires font à pleine charge, ils effectueront 30 secondes de travail toutes les 15 secondes. Étant donné que Prometheus ne voit pas le travail jusqu'à ce qu'il soit terminé, à en juger par les métriques, 14 secondes de travail ont été achevées dans le premier intervalle de temps et 42 secondes dans le second. Si chaque gestionnaire entreprend une tâche volumineuse, alors même après quelques heures, jusqu'à la fin, nous ne verrons aucun rapport indiquant que le travail est en cours.
Pour démontrer cet effet, j'ai mené une expérience avec dix gestionnaires engagés dans des tâches dont la longueur est différente et semi-normale répartie entre 0,1 seconde et une valeur légèrement supérieure (voir tâches aléatoires ). Vous trouverez ci-dessous 3 graphiques décrivant l'activité professionnelle; la durée dans le temps est indiquée dans l'ordre croissant.
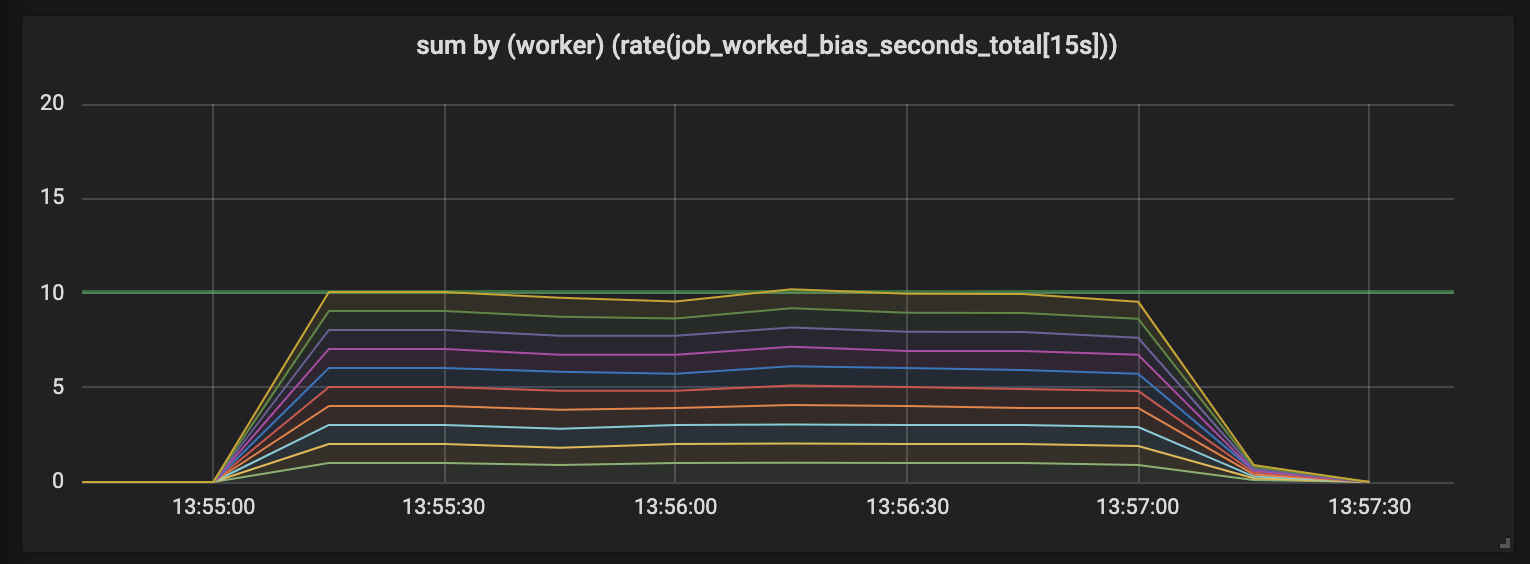
Tâches pouvant durer jusqu'à 1 seconde.
Le premier graphique montre que chaque gestionnaire accomplit environ 1 seconde de travail à chaque seconde - cela est visible sur des lignes plates et la quantité totale de travail est égale à nos capacités (10 gestionnaires donnent une seconde de travail par seconde de temps). En fait, cela, quelle que soit la durée de la tâche, nous nous attendons: tant pour les tâches courtes et longues, les processeurs à charge constante devraient céder.
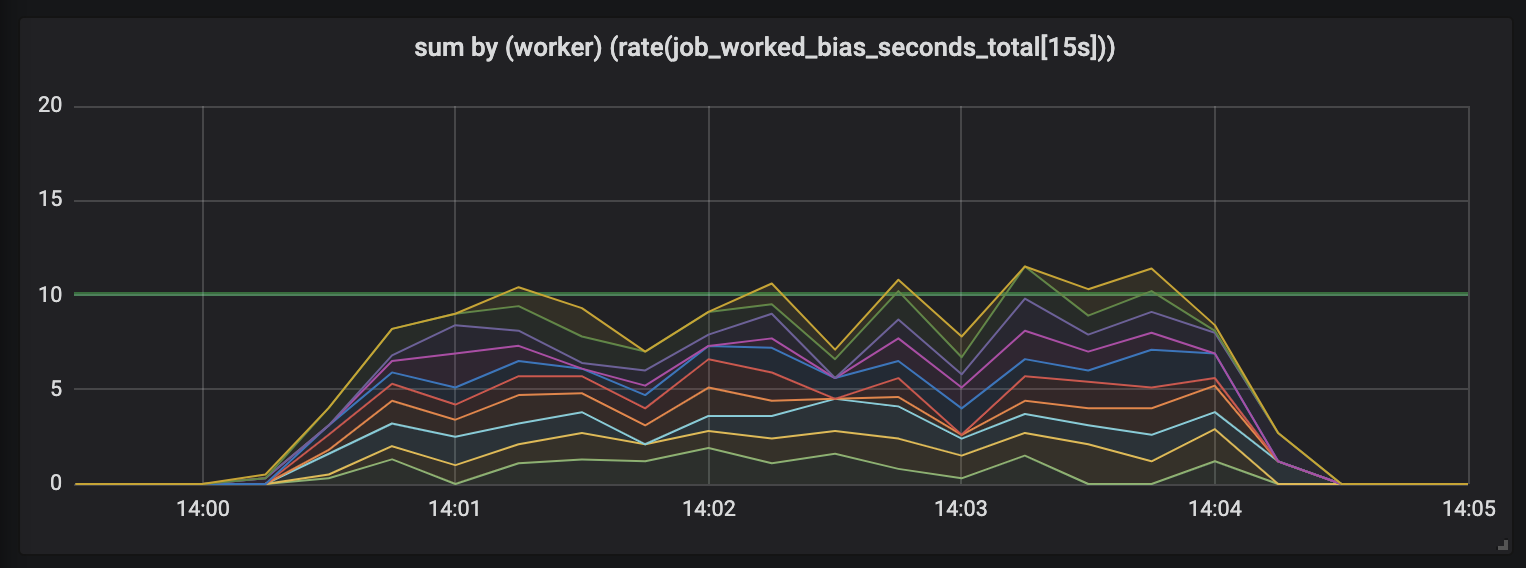
Tâches pouvant durer jusqu'à 15 secondes.
La durée des tâches augmente et un gâchis apparaît dans le calendrier: nous avons encore 10 processeurs, tous sont entièrement occupés, mais la quantité totale de travail saute - inférieure ou supérieure à la limite de capacité utile (10 secondes).
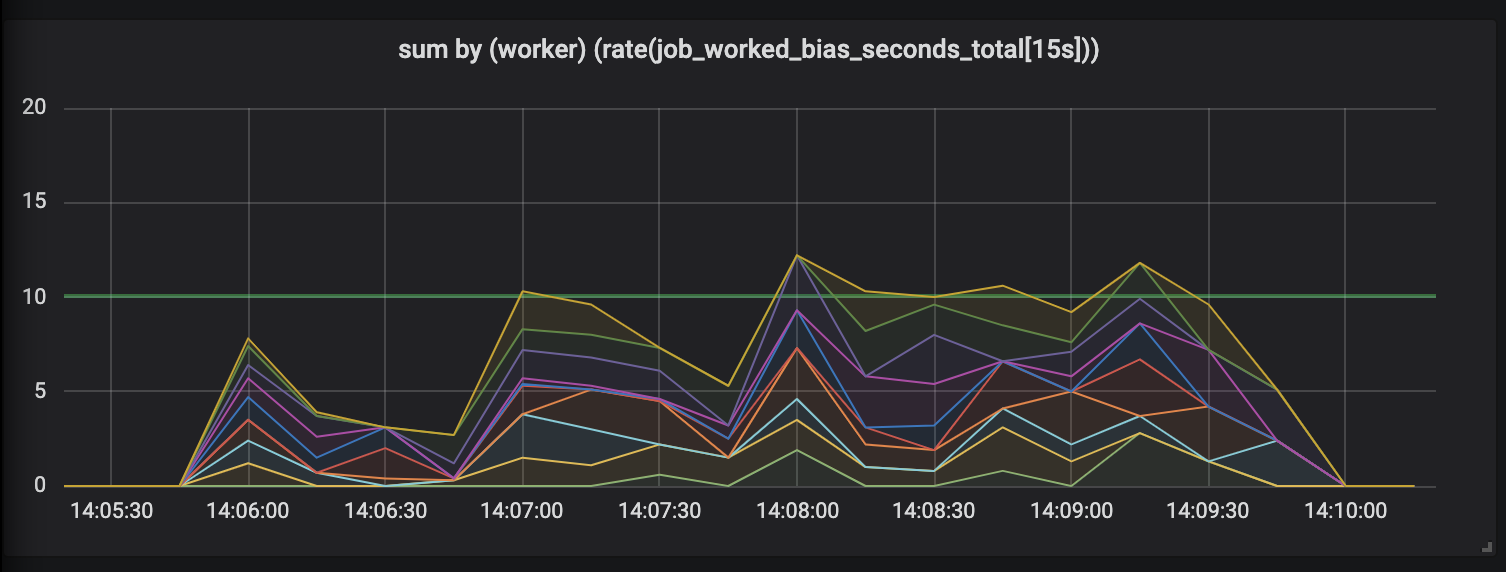
Tâches pouvant durer jusqu'à 30 secondes.
L'évaluation de travaux pouvant durer jusqu'à 30 secondes est tout simplement ridicule. Une mesure limitée dans le temps affiche une activité nulle pour les tâches les plus longues et, uniquement lorsque les tâches sont terminées, nous trace des pics d'activité.
Restaurer la confiance
Ce n'était pas suffisant pour nous, il y a donc un autre problème beaucoup plus insidieux avec ces tâches à long terme qui gâchent nos mesures. Chaque fois qu'une tâche à long terme se termine - par exemple, si Kubernetes jette un pod hors d'un pool, ou lorsqu'un nœud meurt, qu'advient-il des mesures? Cela vaut la peine de les mettre à jour immédiatement à la fin de la tâche, car ils montrent qu'ils n'ont pas du tout fait le travail.
Les mesures ne devraient pas mentir. L'ordinateur portable hurle incrédule, provoquant l'horreur existentielle, et les outils de surveillance qui déforment l'image du monde sont un piège et ne conviennent pas au travail.
Heureusement, le problème peut être résolu. La distorsion des données se produit car Prometheus prend des mesures indépendamment du moment où les processeurs mettent à jour les mesures. Si nous demandons aux gestionnaires de mettre à jour les métriques lorsque Prometheus envoie des demandes, nous verrons que Prometheus n'est plus excentrique et affiche l'activité actuelle.
Présentation ... Tracer
Une solution au problème des métriques déformées est le Tracer , un modèle abstrait qui évalue l'activité sur les tâches de longue durée en mettant à jour progressivement les métriques liées à Prometheus.
class Tracer def trace(metric, labels, &block) ... end def collect(traces = @traces) ... end end
Les traceurs fournissent une méthode de traçage qui prend les métriques Prometheus et la tâche à suivre. La commande trace exécutera le bloc donné (fonctions Ruby anonymes) et garantit que les demandes tracer.collect à tracer.collect pendant l'exécution mettront progressivement à jour les mesures associées, quel que soit le temps écoulé depuis la dernière demande de collect .
Nous devons connecter le tracer aux gestionnaires afin de suivre la durée de la tâche et le point de terminaison desservant les requêtes métriques Prometheus. Nous commençons par les gestionnaires, initialisons un nouveau traceur et lui demandons de suivre l’exécution d’ acquire_job.run .
class Worker def initialize @tracer = Tracer.new(self) end def work @tracer.trace(JobWorkedSecondsTotal, labels) { acquire_job.run } end # Tell the tracer to flush (incremental) trace progress to metrics def collect @tracer.collect end end
À ce stade, tracer ne mettra à jour les métriques qu'en secondes consacrées à la tâche terminée - comme nous l'avons fait lors de la mise en œuvre initiale des métriques. Nous devons demander à tracer de mettre à jour nos mesures avant d'exécuter une demande de Prometheus. Cela peut être fait en configurant le rack middleware.
# config.ru # https://rack.imtqy.com/ class WorkerCollector def initialize(@app, workers: @workers); end def call(env) workers.each(&:collect) @app.call(env) # call Prometheus::Exporter end end # Rack middleware DSL workers = start_workers # Array[Worker] # Run the collector before serving metrics use WorkerCollector, workers: workers use Prometheus::Middleware::Exporter
Rack est une interface pour les serveurs Web Ruby qui vous permet de combiner plusieurs gestionnaires de rack en un seul point de terminaison. La commande config.ru détermine que l'application Rack - chaque fois qu'elle reçoit la demande - envoie d'abord la commande collect aux gestionnaires, puis ne demande au client Prometheus de dessiner les résultats de la collecte.
Quant à notre graphique, nous mettons à jour les métriques chaque fois que la tâche se termine ou lorsque nous recevons une demande de métriques. Les tâches qui ont plusieurs requêtes envoient également des données sur tous les segments: comme le montrent les tâches dont la durée a été divisée en intervalles de 15 secondes.

Est-ce mieux?
L'utilisation de Tracer 24 heures sur 24 affecte la façon dont l'activité est enregistrée. Contrairement aux mesures initiales, qui montraient une «scie», lorsque le nombre de pics dépassait le nombre de processeurs en cours d'exécution et les périodes de silence ennuyeux, l'expérience avec dix processeurs fournit un graphique montrant clairement que chaque processeur est intégré dans le travail surveillé de manière égale.

Mesures basées sur la comparaison (à gauche) et contrôlées par un traceur (à droite), tirées d'une expérience de travail.
Par rapport au calendrier franchement inexact et chaotique des mesures initiales, les métriques collectées par le traceur sont lisses et cohérentes. Nous lions maintenant non seulement le travail à chaque demande de métrique avec précision, mais nous ne nous inquiétons pas non plus de la mort soudaine de l'un des gestionnaires: Prometheus enregistre les métriques jusqu'à la disparition du gestionnaire, évaluant tout son travail.
Peut-il être utilisé?
Oui! L'interface Tracer m'a été utile dans de nombreux projets, il s'agit donc d'un joyau Ruby distinct, prometheus-client-tracer . Si vous utilisez le client Prometheus dans vos applications Ruby, ajoutez simplement le prometheus-client-tracer à votre Gemfile:
require "prometheus/client" require "prometheus/client/tracer" JobWorkedSecondsTotal = Prometheus::Client::Counter.new(...) Prometheus::Client.trace(JobWorkedSecondsTotal) do sleep(long_time) end
Si cela vous est utile et si vous souhaitez que le client officiel de Prometheus Ruby apparaisse dans Tracer , laissez un avis dans client_ruby # 135 .
Et enfin, quelques réflexions
J'espère que cela aide les autres à collecter plus consciemment des mesures pour les tâches de longue durée et à résoudre l'un des problèmes courants. Ne vous y trompez pas, il est associé non seulement au traitement asynchrone: si vos requêtes HTTP sont ralenties, elles bénéficieront également de l'utilisation de tracer lors de l'évaluation du temps consacré au traitement.
Comme d'habitude, tous les commentaires et corrections sont les bienvenus: écrivez sur Twitter ou ouvrez PR . Si vous souhaitez contribuer à tracer gem, le code source se trouve sur prometheus-client-tracer-ruby .