Mikhail Konovalov, chef du département de soutien aux projets d'intégration, direction informatique de l'ICDBonjour Khabrovites!
But
Une approche systématique de la gestion des téléchargements. Nous voulons dire comment rationaliser et automatiser le remplissage du référentiel avec des informations, et en même temps ne pas se confondre dans les flux provenant de diverses sources.
Préambule
Tôt ou tard, un moment survient dans la base de données d'entreprise de toute entreprise lorsqu'elle atteint la taille où l'œil de l'architecte cesse de capter l'incertitude (chaos) du système, et se transforme en une masse incontrôlable de toutes sortes de téléchargements à partir de diverses sources.
Vous avez de la chance si votre système a été développé à partir de zéro (dès le premier tableau) et a été géré par un architecte, une équipe de développeurs et d'analystes. Et d'ailleurs, cet architecte a dirigé avec compétence le modèle d'entrepôt de données. Mais la vie est multiforme, dans la plupart des cas, la DWH se développe spontanément, au début il y avait 30 tables, puis nous en avons ajouté un peu plus au besoin, puis nous l'avons aimé et nous avons commencé à en ajouter pour chaque opportunité, et maintenant nous en avons plus de cinq mille, oui des couches, des mises en scène et des vitrines sont toujours apparues. Et tout ce «bonheur» est tombé sur nous à la suite d'un processus, mais très pratique, qui est une relation causale difficile:
- l'entreprise déclare: «Nous avons besoin de telles ou telles données. Besoin d'un nouveau rapport »
- l'analyste regarde
- développeur met en œuvre
- l'architecte coordonne et contribue au modèle de données
Mais, en règle générale, le dernier point de la réalité n'existe pas. Et cela n'apparaît qu'à un certain moment dans les grandes entreprises qui ont grandi jusqu'à leur DWH, où un architecte soigné gère avec compétence l'intégrité des informations dans la base de données. Ces référentiels sont un examen de la structure précédente, qui a été re-documentée, et souvent reconstruite, en gardant un œil sur la version précédente (non documentée).
Donc, un bref résumé:- il n'y a pas de DWH qui est né immédiatement et qui auparavant ne représentait pas une base de données régulière avec un ensemble de tables;
- tout ce qui existe maintenant, et qui est une structure clairement algorithmisée et documentée, a été obtenu à la suite d'une «expérience amère» des développements précédents.
Si vous êtes l'heureux propriétaire du DWH «correct», ou si vous faites partie de l'équipe de cet heureux propriétaire, cet article «en théorie» peut vous sembler intéressant. Et si vous avez juste à passer en revue ou (à vous interdire) de reconstruire, cet article peut grandement vous simplifier la vie.
Puisqu'il peut y avoir une quantité inimaginable de sources d'informations, il y a au moins le même nombre de flux de téléchargement et de surcharge d'objets différents, et souvent beaucoup plus, car chaque objet de base de données peut subir plus d'une transformation avant que ses données puissent être utilisées par l'utilisateur final pour construire rapports d'activité. Mais c’est pour lui, pour les affaires et non pour son propre plaisir que tout cet écosystème a été construit pour la «transfusion de vaisseau en vaisseau».
Oracle est utilisé comme base de données de notre stockage. Une fois, au stade de la création, le noyau central de notre base de données était constitué de quelques centaines de tables. Nous n'avons pas pensé à la mise en scène et aux vitrines. Mais, comme on dit, «tout coule, tout change», et maintenant nous avons grandi! L'entreprise impose de nouvelles exigences et l'intégration avec diverses bases de données MS SQL, SyBASE, Vertica, Access est déjà apparue. D'où l'information ne nous parvient pas, même exotiques tels que l'échange XML et JSON avec des systèmes tiers sont apparus, et le fichier XLS en tant que source d'information est complètement anachronique.
La vie nous a fait passer en revue et mettre à jour le modèle de données, le maintenir et le maintenir. Voici l'une des parties du noyau principal:
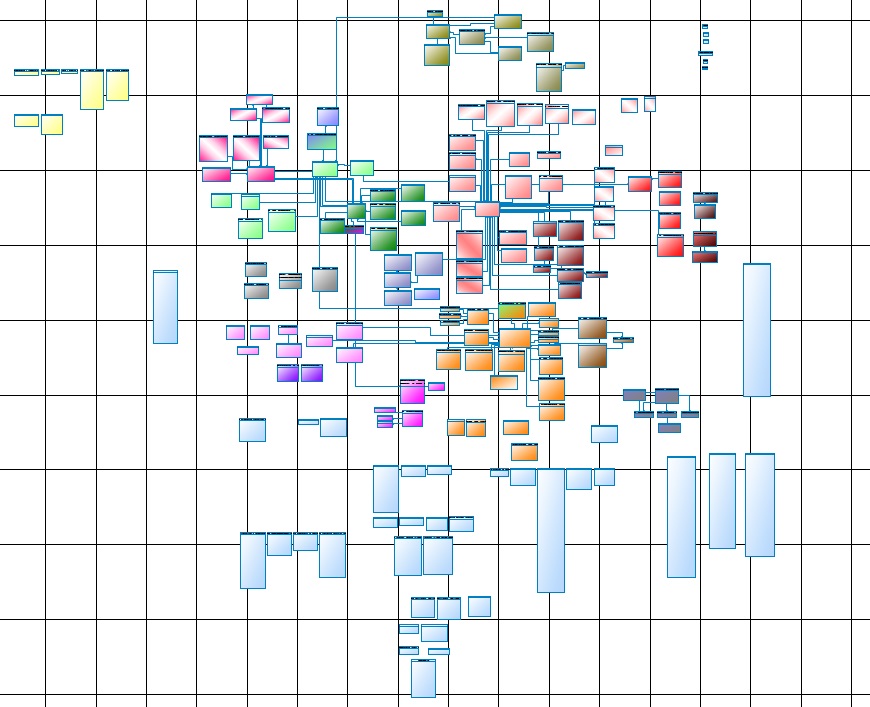 Fig. 1
Fig. 1Pour qui c'est, mais pour moi - il n'est lisible que sur un papier Whatman, et A0 sera un peu petit, meilleur que 4A0, à l'écran c'est impossible à l'oeil ou à l'imagination.
Rappelons maintenant que ce n'est que le noyau (Core Data Layer), ou plutôt sa partie principale, le noyau complet se compose de plusieurs sous-systèmes qui ne sont pas très inférieurs au principal.
La couche de données principale et la
couche Data Mart sont également ajoutées à cela. De plus - de plus, la couche primaire reçoit ses informations des sources de données, et ce, comme mentionné ci-dessus, diverses bases de données et fichiers. En revanche, à la couche des vitrines, différents systèmes de reporting sont joints par le consommateur.
Au début, quand il y avait peu de tables de base de données et d'algorithmes de chargement implémentés en PL / SQL, il n'y avait pas de difficultés particulières pour comprendre les mises à jour des données. Mais avec la montée en puissance de DWH, la décision stratégique a été d'acheter Informatica PowerCenter. Avec toute la commodité de cet outil, tant en termes de fiabilité de chargement que de visualisation de développement, cet outil présente plusieurs inconvénients. La figure ci-dessous montre un modèle pour la séquence de démarrage pour le chargement d'un DWH.
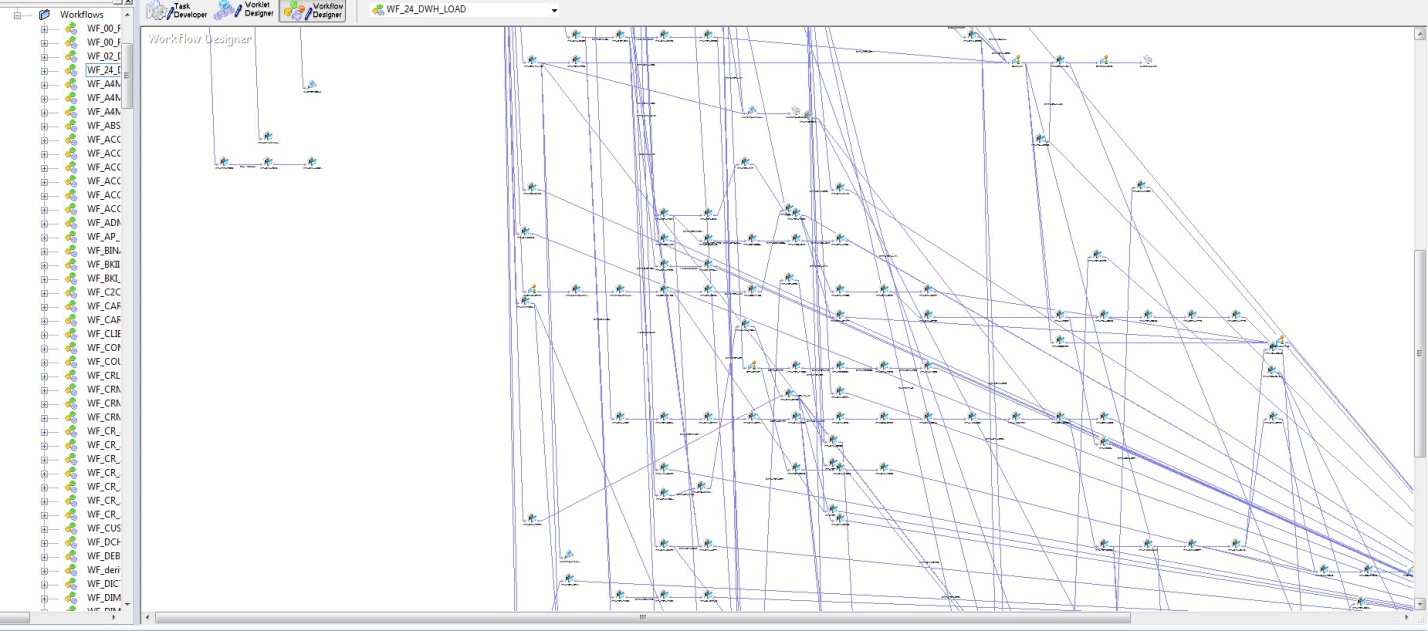 Fig. 2
Fig. 2L'inconvénient le plus important est la subjectivité, ou plutôt, seul l'architecte peut garantir que les articles ne sont pas chargés avant les factures. Malheureusement, avec la croissance de DWH, l'entropie des informations augmente également. Compte tenu du modèle de données physiques (Fig. 1) et de la logique de chargement de ces données (Fig. 2), la construction est toujours obtenue.
Que faire et comment le diriger, demandez-vous. Naturellement: avoir un brillant architecte capable de comprendre toutes les connexions de ces subtilités. Qui surveillera tous les flux, coordonnera les nouveaux flux et empêchera le chargement de la table de publication plus tôt que la table de compte. Bien sûr, tout cela est intégré dans les algorithmes et réglementé par les coupures des téléchargements, mais au départ, seul l'architecte peut comprendre et définir les téléchargements dans une séquence stricte, et avec une telle ramification, la probabilité d'erreurs est très élevée.
Théorie
Je vais maintenant essayer d'énoncer les idées principales du dictionnaire de modèles de données, ainsi que les tâches qu'il résout.
Étant donné que les données stockées sont dans des tableaux et que les sources de données sont en partie des tableaux et en partie des vues, ces dernières sont elles-mêmes des tableaux. Ensuite, une idée simple suit - pour créer une structure de dépendance
TABLE - TABLE . La forme
3NF est parfaitement adaptée à cela.
Tout d'abord, en remplissant les données de l'entité DWH, nous l'appelons
(cible) , dans le cas le plus général, peut être représenté comme
sélectionné dans différentes tables. Que ce soit des tables Oracle, SyBase, MSSQL, des fichiers xls ou autre chose, ce n'est pas si important, tout ça, on appelle leurs sources
(source) . Autrement dit, nous avons une
source qui se jette dans la
cible .
Deuxièmement, chaque entité DWH a des références les unes aux autres.
Troisièmement, il existe une chronologie de démarrage des téléchargements de diverses entités DWH.
Cela reste le cas pour les petits, à mettre en œuvre - comment? Il semblerait que ce soit très simple, depuis la fondation de votre DWH, l'architecte, lorsque le prochain tableau de l'entité
(cible) apparaît, doit regarder et mettre dans le dictionnaire l'entité réceptrice et toutes les entités qui servent de sources. De plus, dans la deuxième table du dictionnaire, spécifiez les liens entre ces sources d'entités dans select, ainsi que toutes les tables subordonnées qui sont référencées par des références. Ensuite, vous pouvez intégrer le chargement de cette entité dans la chaîne de téléchargement du stockage. Seules deux tables - et la possibilité de prendre en compte la séquence de remplissage de l'entrepôt de données avec l'algorithme sont résolues.
Le modèle de données du dictionnaire résoudra les problèmes suivants:
- Afficher les dépendances. Vous pouvez voir de quelles données, d'où elles proviennent. C'est pratique pour les analystes qui sont toujours tourmentés par des questions: "où, ce qui se trouve et d'où vient tout". Présentez-le dans l'application sous forme d'arbre, de la source à la cible , et vice versa: de la cible à la source .
- Rupture de boucles. Lors de l'incorporation de la prochaine charge dans un flux partagé déjà fonctionnel, sans avoir de dictionnaire de modèle de données, il est tout à fait possible de faire une erreur et d'attribuer une heure de début pour charger la prochaine cible devant l'une de ses sources. Cela crée une boucle. Un dictionnaire de modèles de données évitera facilement cela.
- Vous pouvez écrire un algorithme pour remplir le stockage en fonction du dictionnaire de modèles. Dans ce cas, il n'est pas nécessaire d'incorporer le prochain téléchargement n'importe où, il suffit de le refléter dans le dictionnaire et l'algorithme déterminera sa place. Reste à cliquer sur le bouton convoité «Make ALL» . Le chargeur de démarrage lancera des téléchargements de type avalanche de toutes les entités de stockage - du simple (indépendant) au complexe (dépendant).
Implémentation
En théorie, tout est toujours simple et beau; en pratique, les choses sont quelque peu différentes. Ce qui est écrit dans la section précédente est une situation idéale lorsque DWH s'est développé à partir de zéro, quand un architecte était inséparablement avec lui. Si vous n'êtes pas chanceux, vous avez passé tout cela en toute sécurité, il n'y a pas d'architecte, mais il y a un gigantesque ensemble de tables, puis de toute façon, il y a une issue.
Maintenant, en fait, je vais vous dire comment nous avons réussi à rattraper notre retard et à faire des révisions et des reconstructions assez bon marché. Notre DWH a commencé à évoluer avec une décision de leadership sur un besoin imminent (DWH). Comme outil, PL / SQL a été utilisé pour la première fois. Un peu plus tard, je suis passé à Informatica. Naturellement, la priorité était le moment de la création. Le modèle de données dans PowerAMC est apparu quelque temps plus tard, au moment où la confiance s'est clairement formée que personne ne pouvait clairement imaginer une image complète et claire de DWH. Nous avons vécu pendant un certain temps avec le modèle sur le mur, quand il est devenu clair que nous ne pouvions pas faire face à la gestion de tout ce système, nous avons commencé à chercher une solution que je vais essayer de décrire brièvement ici.
Le dictionnaire du modèle de données lui-même est aussi simple qu'un bâton. Mais le remplir est un problème. N mois de travail minutieux et, surtout, un examen attentif des trois parties ci-dessus:
- de quelles sources (source) chaque entité du référentiel (cible) est constituée;
- quelles sont les relations entre les objets de stockage (références);
- la chronologie du début des téléchargements et le remplissage du référentiel.
Heureusement, Oracle et Informatica nous ont aidés, et il s'est avéré que le référentiel Informatica se trouve dans la base de données Oracle. Prenant comme base qu'une session Informatica est l'atome de chargement d'une entité DWH, en creusant un peu dans le référentiel, nous avons trouvé toutes les sources et cibles. Autrement dit, dans le cadre d'une session, pour l'ensemble de sa cible (en règle générale, elle est une), toutes ses sources sont des sources. Ainsi, nous pouvons remplir la première condition du problème. Mais ne vous précipitez pas pour vous réjouir, la source peut être présentée sous la forme d'une sélection très intelligente, vous avez donc dû écrire un analyseur qui extrait toutes les tables spécifiées dans select - ce n'était pas du tout difficile. Mais ce n'est pas tout, ces tableaux eux-mêmes peuvent en fait être des représentations. En utilisant DBA_VIEWS (ou via DBA_DEPENDENCIES), ce problème a également été résolu. Nous avons tiré la deuxième condition de cette trilogie du modèle de données (Fig. 1) et de DBA_CONSTRAINTS. Nous avons également obtenu la troisième condition à partir du référentiel Informatica basé sur (Fig. 2).
Qu'est-il arrivé de tout cela?- Premièrement, nous avons démêlé toutes les boucles que nous avons réussi à enrouler dans l'évolution de notre DWH.
- Deuxièmement, nous avons un merveilleux arbre pour les analystes:

Fig. 3 - Troisièmement, notre super-chargeur, présenté sur la fig. 2 transformé en élégant (désolé, collègues, mais le flou de l'image est intentionnel, car il s'agit de données de travail):
Fig. 4
Vous pouvez avoir beaucoup plus de façons d'appliquer le dictionnaire de modèle de données.
Merci à tous!