
Ce message est un petit résumé de la recherche à grande échelle axée sur la reconnaissance des mots clés. La technique d'extraction sémantique a été initialement appliquée dans le domaine de la recherche sur les réseaux dépressifs sur les réseaux sociaux. Ici, je me concentre sur la PNL et les aspects mathématiques sans interprétation psychologique. Il est clair que l'analyse des fréquences d'un seul mot ne suffit pas. Le mélange aléatoire multiple de la collection n'affecte pas la fréquence relative mais détruit totalement l'information - effet sac de mots. Nous avons besoin d'une approche plus précise pour l'extraction des attracteurs sémantiques.
Selon la théorie du cadre relationnel (RFT), les liens bidirectionnels d'entités sont des éléments cognitifs de base. L'hypothèse du dictionnaire bigram a été testée. Nous avons exploré le haut mur d'aide russophone. 150 000 visites par jour. Les collectes de réponses / demandes ont été analysées: 25000 enregistrements en 2018.
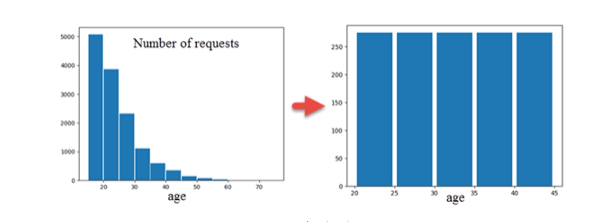
Le nettoyage de texte comprenait des normalisations d'âge / sexe / texte et de longueur de message. La standardisation sexuelle a été atteinte par la reconnaissance de [nom - sexe]. Le nettoyage morphologique et la tokenisation ont permis d'obtenir des noms sous forme standard. Le vocabulaire des bigrammes avec les fréquences correspondantes a été extrait. Les ensembles de Bigram sont classés par fréquence et normalisés à volume égal dans les deux groupes selon des critères de coupure. Chaque groupe, Request / Responce, est caractérisé par une matrice bigram unique. L'augmentation de l'information inverse à l'entropie de Shannon est montrée: 30% d'incrément. I (3) -I (2) = 6% pour les 3 grammes, [H (4) -H (3)] = 2% et moins de 1% pour N> 4.
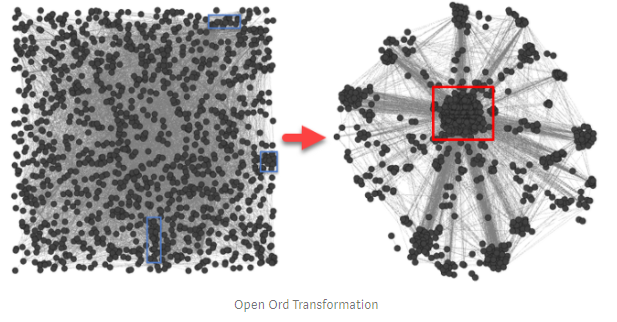
La matrice de Bigram a été utilisée comme générateur de graphe 3D non orienté pondéré. La conversion a été mise en œuvre par l'algorithme de mise en page à commande forcée d'Open Ord. Il transforme la matrice 2D en topologie arborescente. Le poids de chaque nœud correspond à la fréquence d'un seul mot (non représenté) tandis que la longueur de front est la fonction inverse de la fréquence du bigramme. J'ai considéré entre la centralité (BC) et les plus proches voisins modifiés. Les entités avec un BC très élevé peuvent être considérées comme des centres d'information, qui influencent la sémantique: la suppression de ces entités affecte principalement les informations . Les voisins les plus proches sont basés sur une analyse de fréquence de co-occurrence. J'ai considéré la commande de voisin modifiée. BC de la distance inverse à la cooccurrence (CD) voisine a été utilisée comme fonction de pondération: BC / CD.

Nous avons examiné les voisins les plus proches à proximité de la racine sélectionnée de la Colombie-Britannique: #Life. La valeur #Man (n ° 1) est presque fusionnée avec l'attracteur #Life. #Procréation (n ° 2), #Family (n ° 3) sont les entités les plus proches avec un grade BC / CD inférieur. Les valeurs de réponse sont représentées dans l'ordre suivant: #Man No. 1, #Job No. 2, #Procreation No. 3. Il convient de noter que le biais de sujet est évidemment présent dans le groupe de réponse. Cependant, la séparation des valeurs personnelles et de groupe (#Man vice #Life) est remarquable malgré le bruit du sujet. Le graphique était basé sur 10 000 bigrammes les plus fréquents: 44% des données. Cependant, les 5 premières entités classées par BC / CD ne changent pas après le redimensionnement à 50% et 88% du dictionnaire bigramme.
Les résultats considérés sont en corrélation avec les observations empiriques en psychologie. Par conséquent, ils confirment au préalable l'algorithme sélectionné de la plage BC / CD pour la reconnaissance des attracteurs sémantiques. C'est pratique si vous traitez avec des données de texte / parole bruyantes. Il peut être utilisé pour l'exploration de mots clés par rapport à l'entité sélectionnée ou en termes absolus. Vous pouvez en lire plus ici . L'instrument peut également avoir des applications dans l'évaluation des RH. Les auteurs mènent des recherches pertinentes dans le segment anglophone et recherchent une collaboration. La version complète de la recherche est en attente dans la revue à comité de lecture. Cependant, vous pouvez demander un brouillon sur demande personnelle . Je vous remercie.
Je voudrais remercier Dmitry Vodyanov pour la discussion fructueuse.