pprof est le principal outil de profilage de Go. Le profileur est inclus dans la bibliothèque standard de Go et beaucoup a été écrit à ce sujet au fil des ans. Pour connecter pprof à une application existante, il vous suffit d'ajouter une ligne de code:
import _ “net/http/pprof”
Dans le serveur HTTP par défaut - net/http.DefaultServeMux - les gestionnaires qui envoient des résultats de profilage seront enregistrés le long du chemin /debug/pprof/ .
curl -o cpu-profile.pb.gz http://<server-addr>/debug/pprof/profile
(pour plus de détails, voir https://godoc.org/net/http/pprof )
Mais par expérience, ce n'est pas toujours aussi simple et dans la pratique en utilisant pprof au combat, il y a des pièges.
Pour commencer, nous ne voulons pas que les gestionnaires de profileurs se prolongent sur Internet. Le profilage est bon marché, en termes de frais généraux, mais pas gratuit, et le profil lui-même contient des informations sur la structure interne de l'application, ce qui n'est souvent pas conseillé d'ouvrir aux étrangers. Vous devez vous assurer que le chemin /debug n'est pas accessible aux utilisateurs non autorisés. L'accès peut être limité du côté du serveur proxy ou le serveur pprof peut être déplacé vers un port séparé, dont l'accès ne sera ouvert que via l'hôte privilégié.
Mais que se passe-t-il si l'application n'implique aucun accès HTTP - par exemple, s'agit-il d'un processeur de file d'attente hors ligne?
Selon l'état de l'infrastructure de l'entreprise, un serveur HTTP «soudain» à l'intérieur du processus de candidature peut soulever des questions de la part du service des opérations;) Le serveur limite en outre les possibilités de mise à l'échelle horizontale, car cela ne fonctionnera pas uniquement pour exécuter plusieurs instances de l'application sur le même hôte - les processus entreront en conflit, essayant d'ouvrir le même port TCP pour le serveur pprof.
Il est «simple» à résoudre en isolant chaque processus d'application dans le conteneur (ou en exécutant le serveur pprof sur un port unique ou socket UNIX). Vous ne surprendrez plus personne avec un service mis à l'échelle horizontalement dans des centaines d'instances, «réparties» sur plusieurs centres de données. Dans une infrastructure très dynamique, des conteneurs avec l'application peuvent périodiquement apparaître et disparaître. Et nous devons toujours contacter le profileur. Et cela signifie que quelle que soit la méthode de mise à l'échelle sélectionnée, des mécanismes de recherche pour une instance d'application spécifique et le port de serveur pprof correspondant sont nécessaires.
Selon les caractéristiques de l'entreprise, l'existence même de la possibilité d'accéder à quelque chose qui n'est pas lié à l'activité principale de production du service peut soulever des questions de la part du service de sécurité;) J'ai travaillé dans une entreprise où, pour des raisons objectives, l'accès à tout est de côté La production était exclusivement dans le département des opérations. La seule façon d'exécuter le profileur sur une application en cours d'exécution était d'ouvrir une tâche dans le traqueur de bogues d'opération, avec une description de la commande curl, dans quel contrôleur de domaine, sur quel serveur vous souhaitez exécuter, quel résultat attendre et quoi en faire.
Ou imaginez une situation: une matinée de travail. Vous avez ouvert Slack et avez découvert que le soir, dans l'un des processus du service de production, «quelque chose s'est mal passé», «quelque part, quelque chose de« arrêté »,« la mémoire a commencé à couler »,« les graphiques du processeur ont rampé »ou l'application a commencé à paniquer. Les équipes opérationnelles de service (ou OOM Killer) n'ont pas creusé profondément et ont simplement redémarré l'application ou annulé la dernière version de la veille.
Après coup, ce n'est pas facile de comprendre de telles situations. C'est formidable si le problème peut être reproduit dans un environnement de test (ou dans une partie isolée de la production à laquelle vous avez accès). Vous pouvez collecter les données nécessaires avec tous les outils à portée de main, puis déterminer de quel composant est le problème.
Mais s'il n'y a pas de moyen évident de reproduire le problème, ne nous reste-t-il que les journaux et les mesures d'hier? Dans de telles situations, il est toujours dommage que vous ne puissiez pas revenir en arrière au moment où le problème était visible en production et collecter rapidement tous les profils nécessaires, de sorte que plus tard, en mode silencieux, effectuez une analyse.
Mais si pprof est relativement bon marché, pourquoi ne pas collecter automatiquement les données de profilage, à certains intervalles, et les stocker dans un endroit séparé de la production, où vous pouvez donner accès à toutes les personnes intéressées?
En 2010, Google a publié le document Google Wide Wide Profiling: A Continuous Profiling Infrastructure for Data Centers , qui décrit une approche de profilage continu des systèmes de l'entreprise. Et après quelques années, la société a lancé un service de profilage continu - Stackdriver Profiler - accessible à tous.
Le principe de fonctionnement est simple: au lieu d'un serveur pprof, un agent stackdriver est connecté à l'application qui, en utilisant directement l'API runtime/pprof , collecte périodiquement différents types de profilage depuis l'application et envoie des profils vers le cloud. Tout ce dont le développeur a besoin, à l'aide du panneau de configuration Stackdriver, sélectionnez l'instance d'application souhaitée dans la liste AZ souhaitée et vous pouvez, après coup, analyser l'application à tout moment dans le passé.
D'autres fournisseurs SaaS offrent des fonctionnalités similaires. Mais les règles de sécurité de votre entreprise peuvent interdire l'exportation de données au-delà de sa propre infrastructure. Et les services qui vous permettent de déployer un système de profilage continu sur vos propres serveurs, je ne les ai pas vus.
Toutes les difficultés et les idées décrites ci-dessus sont loin d'être nouvelles et spécifiques non seulement pour Go. Avec eux, sous une forme ou une autre, les développeurs sont confrontés dans presque toutes les entreprises où j'ai travaillé.
À un moment donné, j'étais curieux d'essayer de construire un analogue du Stackdriver Profiler pour un Go-service arbitraire qui pourrait résoudre les problèmes décrits. En tant que projet de loisir, pendant mon temps libre, je travaille sur profefe ( https://github.com/profefe/profefe ) - un service ouvert de profilage continu. Le projet est encore au stade d'expériences et de discussions périodiques, mais il est déjà adapté aux tests.
Les tâches que j'ai définies pour le projet:
- Le service sera déployé sur l'infrastructure interne de l'entreprise.
- Le service sera utilisé comme un outil interne à l'entreprise. Vous pouvez faire confiance aux fournisseurs et aux consommateurs de données: au début, vous pouvez omettre l'autorisation des demandes d'écriture / lecture et ne pas essayer de vous protéger à l'avance d'une utilisation malveillante.
- Le service ne doit pas avoir d'attentes particulières de la part de l'infrastructure de l'entreprise: tout peut vivre dans le cloud ou dans ses propres DC; les applications profilées peuvent être exécutées à l'intérieur de conteneurs ("tout est contrôlé par les Kubernetes") ou peuvent fonctionner sur du métal nu.
- Le service doit être simple à utiliser (il semble que dans une certaine mesure, Prométhée en soit un bon exemple).
- Il doit être entendu que l'architecture sélectionnée peut ne pas satisfaire aux conditions dans lesquelles le service sera utilisé. Très probablement, vous aurez besoin de pouvoir étendre / remplacer les composants du système à l'échelle "sur place".
- Conformément à (4), nous devons essayer de minimiser les dépendances externes requises. Par exemple, un service doit en quelque sorte rechercher des instances d'applications profilées, mais, au moins dans les étapes initiales, je veux me passer d'une découverte de service explicite.
- Le service stockera et cataloguera les profils des applications Go. Nous nous attendons à ce qu'un fichier pprof occupe 100 Ko - 2 Mo (les profils de tas sont généralement beaucoup plus grands que les profils de processeur ). À partir d'une instance profilée, cela n'a aucun sens d'envoyer plus de N profils par minute (un agent Stackdriver envoie, en moyenne, 2 profils par minute). Il vaut la peine de calculer immédiatement qu’une seule application peut avoir plusieurs à plusieurs centaines d’instances.
- Grâce au service, les utilisateurs rechercheront différents types de profils (cpu, tas, mutex, etc.) de l'application ou une instance spécifique de l'application pendant une certaine période de temps.
- À partir du service, l'utilisateur demandera un profil pprof distinct des résultats de la recherche.
Désormais, profefe se compose de deux éléments:
profefe-collector est un collecteur de services avec une API RESTful simple.
La tâche du collecteur est d'obtenir le fichier pprof et certaines métadonnées et de les enregistrer dans le stockage permanent. L'API permet également aux clients de rechercher des profils par métadonnées dans une certaine fenêtre de temps ou de lire un profil spécifique (ou un groupe de profils du même type) à partir du magasin.
agent - une bibliothèque facultative qui doit être connectée à l'application au lieu du serveur pprof. Dans l'application, dans une goroutine distincte, l'agent démarre périodiquement le processus de profilage (à l'aide de runtime/pprof ) et envoie les profils pprof reçus, ainsi que les métadonnées au collecteur.
Les métadonnées sont un ensemble de valeurs-clés arbitraire qui décrit une application ou son instance individuelle. Par exemple: nom du service, version, centre de données et hôte sur lequel l'application s'exécute.

Diagramme d'interaction des composants Profefe
J'ai mentionné ci-dessus que l'agent est un composant facultatif. S'il n'est pas possible de le connecter à une application existante, mais que le serveur net/http/pprof est déjà connecté dans l'application, les profils peuvent être supprimés à l'aide de tout outil externe et envoyer des fichiers pprof au collecteur via l'API HTTP.
Par exemple, sur les hôtes, vous pouvez configurer une tâche cron qui collectera périodiquement les profils des instances en cours d'exécution et les enverra à profefe pour le stockage;)
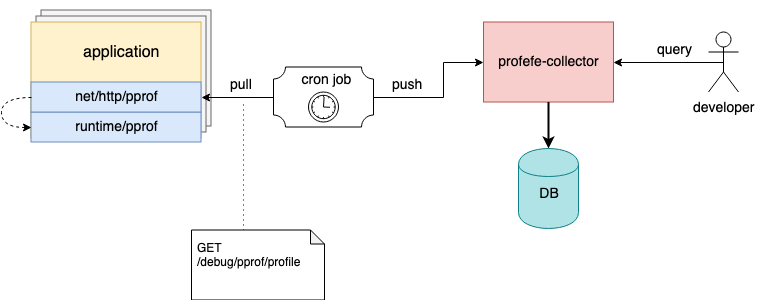
La tâche Cron collecte et envoie les profils d'application au collecteur profefe
Vous pouvez en savoir plus sur l'API profefe dans la documentation sur GitHub .
Plans
Jusqu'à présent, la seule façon d'interagir avec le collecteur profefe est l'API HTTP. L'une des tâches pour l'avenir consiste à assembler un service d'interface utilisateur distinct à travers lequel il sera possible d'afficher visuellement les données stockées: résultats de recherche, aperçu général des performances du cluster, etc.
La collecte et le stockage de données de profilage ne sont pas mauvais, mais «sans application, les données sont inutiles». L'équipe où je travaille dispose d'un ensemble d'outils expérimentaux pour collecter des statistiques de base pour plusieurs profils pprof du service. Cela aide beaucoup à analyser les conséquences de la mise à jour des dépendances clés de l'application ou les résultats d'un refactoring important ( malheureusement, les performances en production ne répondent pas toujours aux attentes basées sur le lancement de benchmarks isolés et le profilage dans un environnement de test ). Je souhaite ajouter des fonctionnalités similaires pour comparer et analyser les profils stockés dans l'API profefe.
Malgré le fait que l'objectif principal de profefe soit le profilage continu des services Go, le format de profil pprof n'est pas du tout lié à Go. Pour Java, JavaScript, Python, etc., il existe des bibliothèques qui vous permettent d'obtenir des données de profilage dans ce format. Peut-être que profefe peut devenir un service utile pour les applications écrites dans d'autres langues.
Entre autres choses, le référentiel a un certain nombre de questions ouvertes décrites dans le tracker de projet sur GitHub .
Conclusion
Au cours des dernières années, l'idée populaire a été ancrée parmi les développeurs que pour obtenir «l' observabilité » d'un service, trois composants sont nécessaires: les métriques, les journaux et le traçage (« trois piliers de l'observabilité »). Il me semble que la visibilité est la capacité de répondre efficacement aux questions sur la santé du système et de ses composants. Les métriques et le traçage permettent de comprendre le système dans son ensemble. Les journaux couvrent les parties délibérément décrites du système. Le profilage est un autre signal pour atteindre la visibilité, vous permettant de comprendre le système au niveau micro. Le profilage continu sur une période de temps permet également de comprendre comment les composants individuels et l'environnement ont influencé et affecté l'opérabilité et la productivité de l'ensemble du système.