
Nous avions 4 comptes Amazon, 9 VPC et 30 environnements de développement, étapes et régressions les plus puissants - au total plus de 1000 instances EC2 de toutes les couleurs et nuances. Depuis que j'ai commencé à collecter des solutions cloud pour les entreprises, je dois aller jusqu'au bout de mon hobby et réfléchir à la façon d'automatiser tout cela.
Salut Je m'appelle Kirill Kazarin, je travaille comme ingénieur chez DINS. Nous développons des solutions de communication d'entreprise basées sur le cloud. Dans notre travail, nous utilisons activement Terraform, avec lequel nous gérons de manière flexible notre infrastructure. Je partagerai mon expérience avec cette solution.
L'article est long, alors faites le plein de thé au
pop-corn et c'est parti!
Et encore une nuance - l'article a été écrit sur la base de la version 0.11, dans la version 0.12 beaucoup a changé mais les principales pratiques et astuces sont toujours d'actualité. La question de la migration de 0,11 à 0,12 mérite un article séparé!
Qu'est-ce que Terraform
Terraform est un outil populaire d'Hashicorp qui est apparu en 2014.
Cet utilitaire vous permet de gérer votre infrastructure cloud dans l'
infrastructure en tant que paradigme de
code dans un langage déclaratif très convivial et facile à lire. Son application vous fournit un type unifié de ressources et d'application des pratiques de code pour la gestion de l'infrastructure, qui ont longtemps été développées par la communauté des développeurs. Terraform prend en charge toutes les plates-formes cloud modernes, vous permet de modifier l'infrastructure de manière sûre et prévisible.
Une fois lancé, Terraform lit le code et, à l'aide des plug-ins fournis par les fournisseurs de services cloud, amène votre infrastructure à l'état décrit en effectuant les appels d'API nécessaires.
Notre projet est entièrement sur Amazon, déployé sur la base des services AWS, et j'écris donc sur l'utilisation de Terraform dans cette veine. Séparément, je note qu'il peut être utilisé non seulement pour Amazon. Il vous permet de gérer tout ce qui a une API.
De plus, nous gérons les paramètres VPC, les stratégies IAM et les rôles. Nous gérons les tables de routage, les certificats, les ACL réseau. Nous gérons les paramètres de notre pare-feu d'application Web, S3-bucket, SQS-queues - tout ce que notre service peut utiliser dans Amazon. Je n'ai pas encore vu de fonctionnalités avec Amazon que Terraform ne pouvait pas décrire en termes d'infrastructure.
Il s’agit d’une infrastructure assez grande, avec vos mains, elle est facile à prendre en charge. Mais avec Terraform, c'est pratique et simple.
De quoi Terraform est fait
Les fournisseurs sont des plugins pour travailler avec l'API d'un service. Je les ai comptés
plus de 100 . Parmi eux se trouvent des fournisseurs pour Amazon, Google, DigitalOcean, VMware Vsphere, Docker. J'ai même trouvé un fournisseur sur cette liste officielle qui vous permet
de gérer les règles de Cisco ASA !
Entre autres choses, vous pouvez contrôler:
Et ce ne sont que des fournisseurs officiels, il y a encore plus de fournisseurs non officiels. Pendant les expériences, je suis tombé sur GitHub un tiers, non inclus dans le fournisseur de liste officiel, qui a
permis de travailler avec DNS de GoDaddy , ainsi qu'avec les
ressources Proxmox .
Dans un projet Terraform, vous pouvez utiliser différents fournisseurs et, par conséquent, les ressources de différents fournisseurs de services ou technologies. Par exemple, vous pouvez gérer votre infrastructure dans AWS, avec un DNS externe de GoDaddy. Et demain, votre entreprise a acheté une startup hébergée dans DO ou Azure. Et pendant que vous décidez de migrer ou non vers AWS, vous pouvez également le prendre en charge avec le même outil!
Ressources. Ce sont des entités cloud que vous pouvez créer à l'aide de Terraform. Leur liste, leur syntaxe et leurs propriétés dépendent du fournisseur utilisé, en fait - du cloud utilisé. Ou pas seulement des nuages.
Modules Ce sont les entités avec lesquelles Terraform vous permet de modéliser votre configuration. Ainsi, les modèles vous permettent de rendre votre code plus petit, vous permettent de le réutiliser. Eh bien, ils aident à travailler confortablement avec lui.
Pourquoi nous avons choisi Terraform
Pour nous, nous avons identifié 5 raisons principales. Peut-être de votre point de vue, tous ne sembleront pas significatifs:
- Terraform est un utilitaire de prise en charge de plusieurs Cloud
Cloud Agnostic (merci pour le précieux commentaire dans les commentaires) . Lorsque nous avons sélectionné cet outil, nous avons pensé: - Que se passera-t-il si la direction vient chez nous demain ou dans une semaine et dit: "Les gars, et nous avons pensé - ne nous contentons pas de déployer sur Amazon. Nous avons une sorte de projet, où nous devrons obtenir l'infrastructure dans Google Cloud. Ou dans Azure - eh bien, on ne sait jamais . " Nous avons décidé que nous aimerions avoir un outil qui ne sera pas lié de manière rigide à un service cloud. - Open source . Terraform est une solution open source . Le référentiel du projet a une note de plus de 16 mille étoiles, c'est une bonne confirmation de la réputation du projet.
Nous avons rencontré plus d'une ou deux fois le fait que dans certaines versions il y a des bugs ou un comportement pas tout à fait compréhensible. Avoir un référentiel ouvert vous permet de vous assurer qu'il s'agit bien d'un bug, et nous pouvons résoudre le problème en mettant simplement à jour le moteur ou la version du plugin. Ou qu'il s'agit d'un bug, mais "Les gars, attendez, littéralement deux jours plus tard, une nouvelle version sera publiée et nous le corrigerons." Ou: "Oui, c'est quelque chose d'incompréhensible, d'étrange, ils le trient, mais il y a du contournement." C'est très pratique. - Contrôle . Terraform en tant qu'utilitaire est entièrement sous votre contrôle. Il peut être installé sur un ordinateur portable, sur un serveur, il peut être facilement intégré dans votre pipeline, ce qui peut être fait sur la base de n'importe quel outil. Par exemple, nous l'utilisons dans GitLab CI.
- Vérification de l'état de l'infrastructure . Terraform peut vérifier et vérifie l'état de votre infrastructure.
Supposons que vous ayez commencé à utiliser Terraform dans votre équipe. Vous créez une description d'une ressource dans Amazon, par exemple, Security Group, appliquez-la - elle est créée pour vous, tout va bien. Et ici - bam! Votre collègue qui est rentré de vacances hier et ne sait pas encore que vous avez tout si bien arrangé ici, ou même un collègue d'un autre service entre et modifie les paramètres de ce groupe de sécurité par des poignées.
Et sans le rencontrer, sans parler ou sans avoir rencontré un certain problème, vous ne le saurez jamais dans une situation normale. Mais, si vous utilisez Terraform, même l'exécution d'un plan inactif sur cette ressource vous montrera qu'il y a des changements dans l'environnement de travail.
Lorsque Terraform examine votre code, il appelle simultanément l'API du fournisseur de cloud, reçoit l'état des objets de celui-ci et compare: «Et maintenant, il y a la même chose que je faisais avant, de quoi me souviens-je?» Puis il le compare avec le code, regarde ce qui doit être changé. Et, par exemple, si tout est le même dans son histoire, dans sa mémoire et dans votre code, mais qu'il y a des changements là-bas, il vous le montrera et vous proposera de le faire reculer. À mon avis, également une très bonne propriété. C'est donc une autre étape, personnellement pour nous, pour nous assurer d'avoir une infrastructure immuable. - Une autre caractéristique très importante est les modules que j'ai mentionnés et qui comptent. J'en parlerai un peu plus tard. Quand je comparerai avec les outils.
Et aussi une cerise sur le gâteau: Terraform a une
liste assez large de fonctions intégrées . Ces fonctions, malgré le langage déclaratif, nous permettent d'en implémenter certaines, pour ne pas dire programmatiques, mais logiques.
Par exemple, certains calculs automatiques, lignes fractionnées, transtypage en minuscules et majuscules, suppression de caractères de cette ligne. Nous l'utilisons assez activement. Ils facilitent la vie, surtout lorsque vous écrivez un module qui sera ensuite réutilisé dans différents environnements.
Terraform vs CloudFormation
Le réseau compare souvent Terraform à CloudFormation. Nous avons également posé cette question lors de son choix. Et voici le résultat de notre comparaison.
Comment démarrer avec Terraform
De manière générale, le démarrage est assez simple. Voici brièvement les premières étapes:
- Tout d'abord, créez un référentiel Git et commencez immédiatement à stocker toutes vos modifications, expériences et tout.
- Lisez le guide de démarrage . Il est petit, simple, assez détaillé et décrit bien comment démarrer avec cet utilitaire.
- Écrivez une démo, du code de travail. Vous pouvez même copier une sorte d'exemple pour jouer avec plus tard.
Notre pratique avec Terraform
Code source
Vous avez commencé votre premier projet et enregistrez tout dans un grand fichier main.tf.
Voici un exemple typique (j'ai honnêtement pris le premier que j'ai reçu de GitHub).
Rien de mal, mais la taille de la base de code a tendance à augmenter avec le temps. Les dépendances entre les ressources augmentent également. Après un certain temps, le fichier devient énorme, complexe, illisible, mal entretenu - et un changement imprudent au même endroit peut causer des problèmes.
La première chose que je recommande est de mettre en évidence le soi-disant référentiel de base, ou l'état de base de votre projet, votre environnement. Dès que vous commencez à créer une infrastructure à l'aide de Terraform ou à l'importer, vous constaterez immédiatement que vous avez des entités qui, une fois déployées, configurées, changent rarement. Par exemple, ce sont des paramètres VPC ou VPC lui-même. Ce sont des réseaux, des groupes de sécurité généraux et de base tels que l'accès SSH - vous pouvez compiler une liste assez longue.
Cela n'a aucun sens de le conserver dans le même référentiel que les services que vous modifiez fréquemment. Sélectionnez-les dans un référentiel séparé et ancrez-les via une fonction Terraform telle que l'état distant.
- Vous réduisez la base de code de cette partie du projet avec laquelle vous travaillez souvent directement.
- Au lieu d'un grand fichier tfstate qui contient une description de l'état de votre infrastructure, deux fichiers plus petits et à un moment donné, vous travaillez avec l'un d'eux.
Quel est le truc? Lorsque Terraform crée un plan, c'est-à-dire calcule, calcule ce qu'il doit changer, applique - il raconte complètement cet état, vérifie le code, vérifie le statut dans AWS. Plus votre état est grand, plus le plan prendra du temps.
Nous sommes arrivés à cette pratique quand il nous a fallu 20 minutes pour construire un plan pour l'ensemble de l'environnement en production. En raison du fait que nous avons retiré dans un noyau séparé tout ce que nous ne sommes pas soumis à des changements fréquents, nous avons réduit de moitié le temps de construire un plan. Nous avons une idée de la façon dont il peut être réduit davantage, se décomposant non seulement en cœur et en non-cœur, mais aussi en sous-systèmes, car nous les avons connectés et changeons généralement ensemble. Ainsi, nous disons, nous allons transformer 10 minutes en 3. Mais nous sommes toujours en train de mettre en œuvre une telle solution.
Moins de code - plus facile à lire
Le petit code est plus facile à comprendre et plus pratique à utiliser. Si vous avez une grande équipe et qu'elle a des gens avec différents niveaux d'expérience - sortez ce que vous changez rarement, mais globalement, dans un navet séparé, et fournissez-lui un accès plus étroit.
Disons que vous avez des juniors dans votre équipe et que vous ne leur donnez pas accès au référentiel global qui décrit les paramètres du VPC - de cette façon, vous vous assurez contre les erreurs. Si un ingénieur fait une erreur en écrivant l'instance et que quelque chose se crée mal - ce n'est pas effrayant. Et s'il fait une erreur dans les options installées sur toutes les machines, s'arrête ou fait quelque chose avec les paramètres des sous-réseaux, avec le routage - c'est beaucoup plus douloureux.
La sélection du référentiel central se déroule en plusieurs étapes.
Étape 1 . Créez un référentiel séparé. Stockez tout le code dedans, séparément - et décrivez les entités qui devraient être réutilisées dans un référentiel tiers à l'aide de cette sortie. Imaginons que nous créons une ressource de sous-réseau AWS dans laquelle nous décrivons où elle se trouve, quelle zone de disponibilité, espace d'adressage.
resource "aws_subnet" "lab_pub1a" { vpc_id = "${aws_vpc.lab.id}" cidr_block = "10.10.10.0/24" Availability_zone = "us-east-1a" ... } output "sn_lab_pub1a-id" { value = "${aws_subnet.lab_pub1a.id}" }
Et puis nous disons que nous envoyons l'id de cet objet à la sortie. Vous pouvez effectuer une sortie pour chaque paramètre dont vous avez besoin.
Quelle est l'astuce ici? Lorsque vous décrivez une valeur, Terraform l'enregistre séparément dans tfstate core. Et quand vous vous tournerez vers lui, il n'aura pas besoin de se synchroniser, de raconter - il pourra vous donner immédiatement cette affaire depuis cet état. De plus, dans le référentiel, qui n'est pas central, vous décrivez une telle connexion avec l'état distant: vous avez un état distant tel ou tel, il se trouve dans le seau S3 tel ou tel, telle ou telle clé et une région.
Étape 2 . Dans un projet non principal, nous créons un lien vers l'état du projet principal, afin de pouvoir faire référence aux paramètres exportés via la sortie.
data "terraform_remote_state" "lab_core" { backend = "s3" config { bucket = "lab-core-terraform-state" key = "terraform.tfstate" region = "us-east-1" } }
Étape 3 . Pour commencer! Lorsque j'ai besoin de déployer une nouvelle interface réseau pour une instance dans un sous-réseau spécifique, je dis: voici l'état distant des données, recherchez le nom de cet état dedans, trouvez ce paramètre dedans, qui, en fait, coïncide avec ce nom.
resource "aws_network_interface" "fwl01" { ... subnet_id = "${data.terraform_remote_state.lab_core.sn_lab_pub1a-id}" }
Et lorsque je construis un plan de changements dans mon référentiel non central, cette valeur pour Terraform deviendra une constante pour lui. Si vous voulez le changer, vous devez le faire dans le référentiel de ce noyau, bien sûr. Mais comme cela change rarement, cela ne vous dérange pas beaucoup.
Modules
Permettez-moi de vous rappeler qu'un module est une configuration autonome constituée d'une ou plusieurs ressources associées. Il est géré en groupe:
Un module est une chose extrêmement pratique car vous créez rarement une ressource comme ça, dans le vide, généralement elle est logiquement connectée à quelque chose.
module "AAA" { source = "..." count = "3" count_offset = "0" host_name_prefix = "XXX-YYY-AAA" ami_id = "${data.terraform_remote_state.lab_core.ami-base-ami_XXXX-id}" subnet_ids = ["${data.terraform_remote_state.lab_core.sn_lab_pub1a-id}", "${data.terraform_remote_state.lab_core.sn_lab_pub1b-id}"] instance_type = "t2.large" sgs_ids = [ "${data.terraform_remote_state.lab_core.sg_ssh_lab-id}", "${aws_security_group.XXX_lab.id}" ] boot_device = {volume_size = "50" volume_type = "gp2"} root_device = {device_name = "/dev/sdb" volume_size = "50" volume_type = "gp2" encrypted = "true"} tags = "${var.gas_tags}" }
Par exemple: lorsque nous déployons une nouvelle instance EC2, nous créons une interface réseau et une pièce jointe pour celle-ci, nous lui faisons souvent une adresse IP élastique, nous faisons un enregistrement route-53 et autre chose. Autrement dit, nous obtenons au moins 4 entités.
Chaque fois, les décrire en quatre morceaux de code n'est pas pratique. De plus, ils sont assez typiques. Cela demande - créez un modèle, puis faites simplement référence à ce modèle, en lui passant des paramètres: un nom, dans quelle grille pousser, quel groupe de sécurité y accrocher. C'est très pratique.
Terraform dispose d'une fonction de comptage, qui vous permet de réduire davantage votre état. Vous pouvez décrire un grand ensemble d'instances avec un seul morceau de code. Disons que je dois déployer 20 machines du même type. Je n'écrirai pas 20 morceaux de code même à partir d'un modèle, j'écrirai 1 morceau de code, j'indiquerai le nombre et le nombre - combien je dois faire.
Par exemple, certains modules font référence à un modèle. Je ne passe que des paramètres spécifiques: sous-réseau ID; AMI pour déployer avec; type d'instance; paramètres de groupe de sécurité; toute autre chose, et indiquez combien de ces choses me faire. Super, les a pris et les ont retournés!
Demain, les développeurs viennent me voir et me disent: «Écoutez, nous voulons expérimenter la charge, veuillez nous en donner deux autres.» Ce que je dois faire: je change un chiffre en 5. La quantité de code reste exactement la même.
Classiquement, les modules peuvent être divisés en deux types - ressources et infrastructures. Du point de vue du code, il n'y a pas de différence, mais plutôt les concepts de niveau supérieur que l'opérateur lui-même introduit.
Les modules de ressources fournissent une collection de ressources normalisées et paramétrées, liées de manière logique. L'exemple ci-dessus est un module de ressources typique. Comment travailler avec eux:
- Nous indiquons le chemin vers le module - la source de sa configuration, via la directive Source.
- Nous indiquons la version - oui, et le fonctionnement sur le principe des «dernières et meilleures» n'est pas la meilleure option ici. Vous n'incluez pas la dernière version de la bibliothèque à chaque fois dans votre projet? Mais plus à ce sujet plus tard.
- Nous lui transmettons des arguments.
Nous sommes attachés à la version du module, et nous prenons juste le dernier - l'infrastructure doit être versionnée (les ressources ne peuvent pas être versionnées, mais le code peut). Une ressource peut être créée supprimée ou recréée. C’est tout! Nous devons également savoir clairement quelle version nous avons créé chaque élément de l'infrastructure.
Les modules d'infrastructure sont assez simples. Ils sont constitués de ressources et incluent des normes d'entreprise (par exemple, des balises, des listes de valeurs standard, des valeurs par défaut acceptées, etc.).
En ce qui concerne notre projet et notre expérience, nous avons depuis longtemps et fermement basculé vers l'utilisation de modules de ressources pour tout ce qui est possible avec un processus de versioning et de révision très strict. Et maintenant, nous introduisons activement la pratique des modules d'infrastructure au niveau du laboratoire et de la mise en scène.
Recommandations pour l'utilisation des modules
- Si vous ne pouvez pas écrire, mais utilisez des clés en main, n'écrivez pas. Surtout si vous êtes nouveau dans ce domaine. Faites confiance aux modules prêts à l'emploi, ou au moins voyez comment ils vous l'ont fait. Cependant, si vous devez encore écrire le vôtre, n'utilisez pas l'appel aux fournisseurs en interne et soyez prudent avec les fournisseurs de services.
- Vérifiez que Terraform Registry ne contient pas de module de ressources prêt à l'emploi.
- Si vous écrivez votre module, cachez les détails sous le capot. L'utilisateur final n'a pas à se soucier de quoi et comment vous implémentez en interne.
- Faites les paramètres d'entrée et les valeurs de sortie de votre module. Et c'est mieux s'il s'agit de fichiers séparés. Tellement pratique.
- Si vous écrivez vos modules, stockez-les dans le référentiel et la version. Mieux vaut un référentiel séparé pour le module.
- N'utilisez pas de modules locaux - ils ne sont ni versionnés ni réutilisés.
- Évitez d'utiliser les descriptions des fournisseurs dans le module, car les informations d'identification de connexion peuvent être configurées et appliquées différemment pour différentes personnes. Quelqu'un utilise des variables d'environnement pour cela, et quelqu'un implique de stocker leurs clés et secrets dans des fichiers avec des chemins de prescription pour eux. Cela doit être indiqué à un niveau supérieur.
- Utilisez le provisionneur local avec précaution. Il est exécuté localement, sur la machine sur laquelle Terraform s'exécute, mais l'environnement d'exécution pour différents utilisateurs peut être différent. Jusqu'à ce que vous l'intégriez dans CI, vous pouvez rencontrer divers artefacts: par exemple, un exécutable local et un ansible en cours d'exécution. Et quelqu'un a une distribution différente, un autre shell, une version différente de ansible, ou même Windows.
Signes d'un bon module (voici un
peu plus en détail ):
- Les bons modules ont une documentation et des exemples. Si chacun est conçu comme un référentiel séparé, cela est plus facile à faire.
- Ils n'ont pas de paramètres codés en dur (par exemple, région AWS).
- Utilisez des valeurs par défaut raisonnables, conçues comme valeurs par défaut. Par exemple, le module pour l'instance EC2 par défaut ne créera pas de machine virtuelle de type m5d.24xlarge pour vous, il utilise pour cela l'un des types minimum t2 ou t3.
- Le code est «propre» - structuré, fourni avec des commentaires, pas inutilement confus, conçu dans le même style.
- Il est hautement souhaitable qu'il soit équipé de tests, bien que ce soit difficile. Malheureusement, nous n'y sommes pas encore parvenus.
Marquage
Les balises sont importantes.
Le balisage, c'est la facturation. AWS dispose d'outils qui vous permettent de voir combien d'argent vous dépensez sur votre infrastructure. Et notre direction voulait vraiment avoir un outil dans lequel ils pourraient le voir de façon déterministe. Par exemple, combien d'argent tel ou tel composant consomme, ou tel ou tel sous-système, telle ou telle équipe, tel ou tel environnement
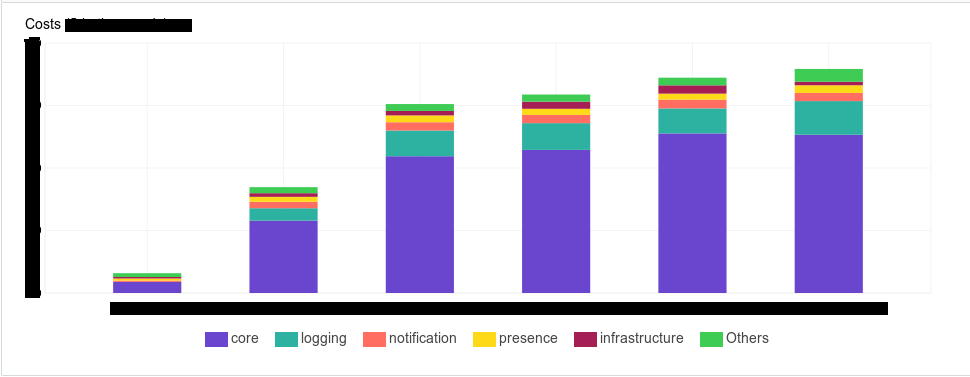
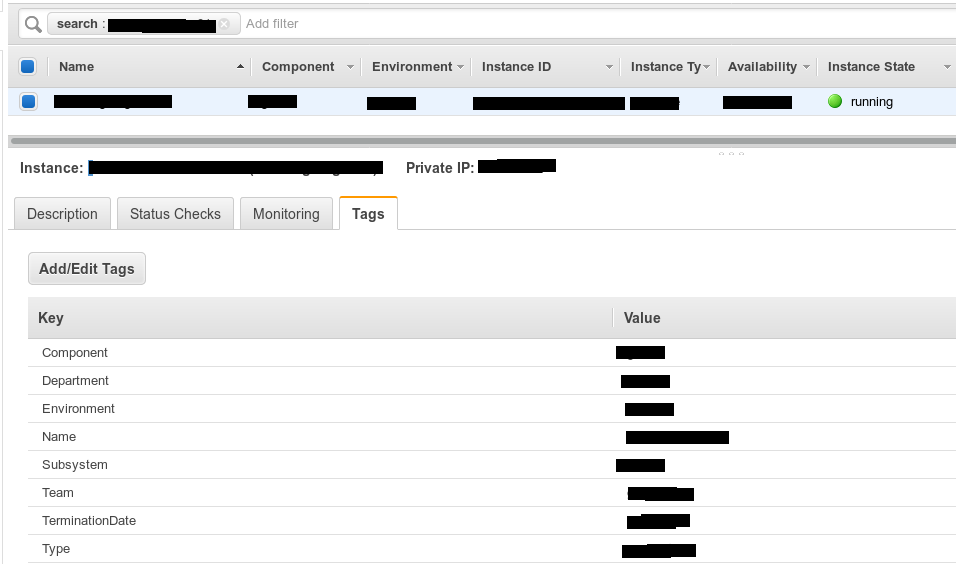
Le balisage est la documentation de votre système. Avec lui, vous simplifiez votre recherche. Même juste dans la console AWS, où ces balises sont parfaitement affichées sur votre écran, il devient plus facile pour vous de comprendre à quoi se réfère tel ou tel type d'instance. Si de nouveaux collègues viennent, il est plus facile pour vous d'expliquer cela en montrant: "Regardez, c'est ça - ici." Nous avons commencé à créer des balises comme suit - nous avons créé un tableau de balises pour chaque type de ressource.
Un exemple:
variable "XXX_tags" { description = "The set of XXX tags." type = "map" default = { "TerminationDate" = "03.23.2018", "Environment" = "env_name_here", "Department" = "dev", "Subsystem" = "subsystem_name", "Component" = "XXX", "Type" = "application", "Team" = "team_name" } }
Il se trouve que dans notre entreprise, plus d'une de nos équipes utilise AWS, et il existe une liste de balises requises.
- Équipe - quelle équipe utilise le nombre de ressources.
- Département - similaire à un département.
- Environnement - les ressources battent dans les "environnements", mais vous, par exemple, pouvez le remplacer par un projet ou quelque chose comme ça.
- Sous-système - le sous-système auquel appartient le composant. Les composants peuvent appartenir à un sous-système. Par exemple, nous voulons voir combien nous avons ce sous-système et ses entités ont commencé à consommer. Du coup, par exemple, pour le mois précédent, il a considérablement augmenté. Nous devons aller voir les développeurs et dire: «Les gars, c'est cher. Le budget est déjà proche les uns des autres, optimisons en quelque sorte la logique. »
- Type - type de composant: équilibreur, stockage, application ou base de données.
- Composant - le composant lui-même, son nom en notation interne.
- Date de résiliation - heure à laquelle elle doit être supprimée, au format date. Si son retrait n'est pas prévu, définissez-le sur «Permanent». Nous l'avons introduit parce que dans les environnements de développement, et même dans certains environnements de stade, nous avons une phase de test de stress qui monte pendant les sessions de stress, c'est-à-dire que nous ne gardons pas ces machines régulièrement. Nous indiquons la date à laquelle la ressource doit être détruite. De plus, vous pouvez sécuriser l'automatisation basée sur lambda, certains scripts externes qui fonctionnent via l'interface de ligne de commande AWS, qui détruiront automatiquement ces ressources.
Maintenant - comment marquer.
Nous avons décidé que nous ferions notre propre tag-map pour chaque composant, dans lequel nous listerions toutes les balises spécifiées: quand le terminer, à quoi il se réfère. Ils ont rapidement réalisé que c'était gênant. Parce que la base de code se développe, parce que nous avons plus de 30 composants, et 30 de ces morceaux de code ne sont pas pratiques. Si vous devez changer quelque chose, vous exécutez et changez.
Pour bien marquer, nous utilisons l'entité
Locals .
locals { common_tags = {"TerminationDate" = "XX.XX.XXXX", "Environment" = "env_name", "Department" = "dev", "Team" = "team_name"} subsystem_1_tags = "${merge(local.common_tags, map("Subsystem", "subsystem_1_name"))}" subsystem_2_tags = "${merge(local.common_tags, map("Subsystem", "subsystem_2_name"))}" }
Vous pouvez y répertorier un sous-ensemble, puis les utiliser les uns avec les autres.
Par exemple, nous avons supprimé certaines balises courantes dans une telle structure, puis des balises spécifiques par sous-systèmes. Nous disons: "Prenez ce bloc et ajoutez, par exemple, le sous-système 1. Et pour le sous-système 2, ajoutez le sous-système 2". Nous disons: "Tags, s'il vous plaît, prenez les généralités et ajoutez le type, l'application, le nom, le composant et qui c'est." Il s'avère un changement très bref, clair et centralisé, si tout à coup il est nécessaire.
module "ZZZ02" { count = 1 count_offset = 1 name = "XXX-YYY-ZZZ" ... tags = "${merge(local.core_tags, map("Type", "application", "Component", "XXX"))}" }
Contrôle de version
Vos modules de modèle, si vous les utilisez, doivent être stockés quelque part. Le moyen le plus simple que tout le monde démarre est le stockage local. Juste dans le même répertoire, juste un sous-répertoire dans lequel vous décrivez, par exemple, un modèle pour une sorte de service. Ce n'est pas un bon moyen. C'est pratique, il peut être rapidement réparé et testé rapidement, mais il est difficile de le réutiliser plus tard et difficile à contrôler
module "ZZZ02" { source = "./modules/srvroles/ZZZ" name = "XXX-YYY-ZZZ" }
Supposons que les développeurs viennent vers vous et vous disent: "Donc, nous avons besoin de telle ou telle entité dans telle ou telle configuration, dans notre infrastructure." Vous l'avez écrit, réalisé sous la forme d'un module local dans le référentiel de leur projet. Déployé - excellent. Ils ont testé, dit: «Ça va! En production. " Nous arrivons à la scène, aux tests de résistance, à la production. Chaque fois Ctrl-C, Ctrl-V; Ctrl-C, Ctrl-V. Pendant que nous arrivions à la vente, notre collègue l'a pris, a copié le code de l'environnement du laboratoire, l'a transféré à un autre endroit et l'a changé là. Et nous obtenons un état déjà incohérent. Avec la mise à l'échelle horizontale, lorsque vous avez autant d'environnements de laboratoire que nous, ce n'est qu'un adish.
Par conséquent, un bon moyen consiste à créer un référentiel Git distinct pour chacun de vos modules, puis à vous y référer. Nous changeons tout en un seul endroit - bon, pratique, contrôlé.
module "ZZZ" { source = "git::ssh://git@GIT_SERVER_FQDN/terraform/modules/general-vm/2-disks.git" host_name_prefix = "XXX-YYY-ZZZ"
Anticipant la question, comment votre code atteint-il la production. Pour cela, un projet distinct est créé qui réutilise les modules préparés et testés.
Très bien, nous avons une source de code qui change de manière centrale. J'ai pris, écrit, préparé et mis en place que demain matin je vais me déployer en production. Construit un plan, testé - super, allons-y. En ce moment, mon collègue, guidé exclusivement par de bonnes intentions, est allé et a optimisé quelque chose, ajouté à ce module. Et il se trouve que ces changements rompent la compatibilité descendante.
Par exemple, il a ajouté les paramètres nécessaires, qu'il doit transmettre, sinon le module ne s'assemblera pas. Ou il a changé le nom de ces paramètres. J'arrive le matin, j'ai un temps strictement limité pour les changements, je commence à construire un plan, et Terraform récupère les modules d'état de Git, commence à construire un plan et dit: «Oups, je ne peux pas. Pas assez pour vous, vous avez renommé. " Je suis surpris: "Mais je ne l'ai pas fait, comment y faire face?" Et s'il s'agit d'une ressource qui a été créée il y a longtemps, alors après de tels changements, vous devrez parcourir tous les environnements, en quelque sorte changer et conduire à un seul regard. C'est gênant.
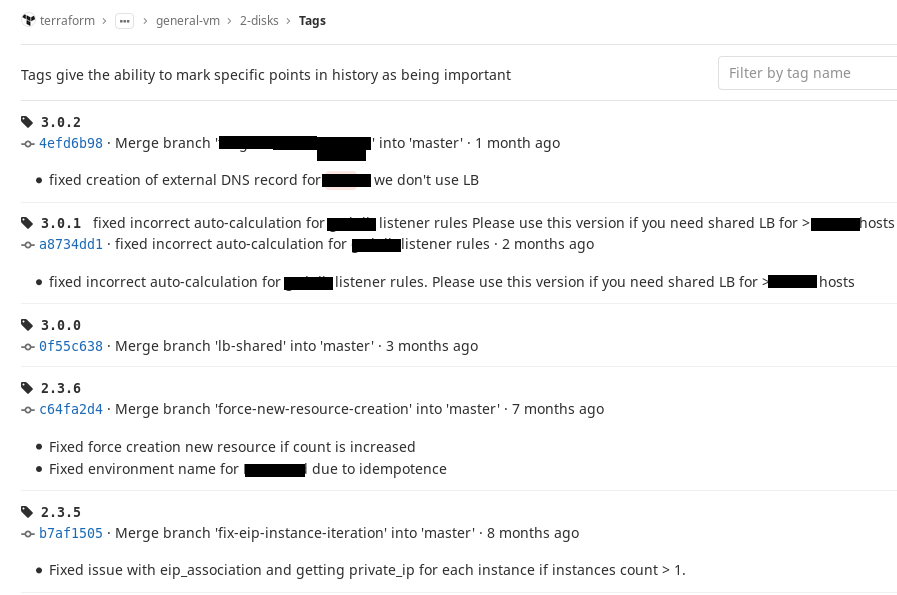
Cela peut être corrigé à l'aide des balises Git. Nous avons décidé par nous-mêmes d'utiliser la
notation SemVer et élaboré une règle simple: dès que la configuration de notre module atteint un certain état stable, c'est-à-dire que nous pouvons l'utiliser, nous mettons une balise sur ce commit. Si nous apportons des modifications et qu'elles ne cassent pas la compatibilité descendante, nous changeons le numéro mineur au niveau de la balise, si elles cassent, nous changeons le numéro majeur.
Donc, dans l'adresse source, attachez-vous à une balise spécifique et si au moins fournissez quelque chose que vous aviez auparavant, il sera toujours collecté. Laissez la version du module aller de l'avant, mais au bon moment, nous viendrons, et lorsque nous en aurons vraiment besoin, nous la changerons. Et ce qui fonctionnait avant ça, au moins ça ne cassera pas. C'est pratique. Voici à quoi cela ressemble dans notre GitLab.
Ramification
L'utilisation de la ramification est une autre pratique importante. Nous avons développé une règle pour nous-mêmes que vous ne devez apporter des modifications qu'au maître. Mais pour tout changement que vous souhaitez apporter et tester, veuillez créer une branche distincte, jouer avec, expérimenter, faire des plans et voir comment cela se passe. Et puis faites une demande de fusion et laissez un collègue regarder le code et l'aide.

Où conserver tfstate
Vous ne devez pas stocker votre état localement. Vous ne devez pas stocker votre état dans Git.
Nous nous sommes brûlés là-dessus lorsque quelqu'un, lors du déploiement des branches d'un non-maître, obtient son état tf, dans lequel l'état est enregistré - puis il l'allume via la fusion, quelqu'un ajoute le sien, il s'avère que les conflits de fusion. Ou cela se passe sans eux, mais un état incohérent, car "il l'a déjà, je ne l'ai pas encore", et puis tout réparer est une pratique désagréable. Par conséquent, nous avons décidé de le stocker dans un endroit sûr, versionné, mais ce serait en dehors de Git.
S3 s'inscrit parfaitement sous cela: il est disponible, il a HA, pour autant que je me souvienne
exactement de quatre neuf, peut-être cinq . Il donne des versions hors de la boîte, même si vous cassez votre tfstate, vous pouvez toujours revenir en arrière. Et il donne également une chose très importante en combinaison avec DynamoDB, qui, à mon avis, a appris ce Terraform depuis la version 0.8. Dans DynamoDB, vous disposez d'une plaque signalétique dans laquelle Terraform enregistre qu'il bloque l'état.
Autrement dit, supposons que je souhaite apporter des modifications. Je commence à construire un plan ou à commencer à l'appliquer, Terraform va à DynamoDB et dit qu'il indique dans cette plaque que cet état est bloqué; utilisateur, ordinateur, temps. En ce moment, mon collègue, qui travaille à distance ou peut-être à quelques tables de moi, mais concentré sur le travail et ne voit pas ce que je fais, a également décidé que quelque chose devait être changé. Il fait un plan, mais le lance un peu plus tard.
Terraform entre dans la dynamique, voit - Lock, s'interrompt, dit à l'utilisateur: "Désolé, tfstate est bloqué par quelque chose." Un collègue voit que je travaille maintenant, il peut venir vers moi et me dire: "Écoute, mon changeur est plus important, cède-moi, s'il te plaît." Je dis: "Bien", j'annule le plan, je supprime le bloc, même s'il est automatiquement supprimé si vous le faites correctement, sans interrompre Ctrl-C. Un collègue va et vient. Ainsi, nous nous assurons contre une situation où vous changez quelque chose.
Fusion-demande
Nous utilisons la ramification dans Git. Nous attribuons nos demandes de fusion à des collègues. De plus, dans Gitlab, nous utilisons presque tous les outils disponibles pour travailler ensemble, pour des demandes de fusion ou même juste quelques pools: discussion de votre code, sa révision, mise en cours ou problème, quelque chose comme ça. C'est très utile, ça aide dans le travail.
De plus, dans ce cas, la restauration est également plus facile, vous pouvez revenir à la validation précédente ou, si vous dites, par exemple, que vous appliqueriez non seulement les modifications de l'assistant, vous pouvez simplement basculer vers une branche stable. Par exemple, vous avez créé une branche de fonctionnalité et décidé que vous apporteriez d'abord des modifications à partir de la branche de fonctionnalité. Et puis les changements, après que tout a bien fonctionné, apportent au maître. Vous avez appliqué les changements dans votre branche, vous avez réalisé que quelque chose n'allait pas, vous êtes passé au maître - aucun changement, a déclaré appliquer - il est revenu.
Pipelines
Nous avons décidé que nous devions utiliser le processus CI pour appliquer nos modifications. Pour ce faire, sur la base de Gitlab CI, nous écrivons un pipeline qui automatise l'application des modifications. Jusqu'à présent, nous en avons deux types:
- Pipeline pour la branche principale (pipeline principal)
- Pipeline pour toutes les autres branches (pipeline de branche)
Que fait le pipeline de brunch? ( , ). . , merge-request, — , . . .
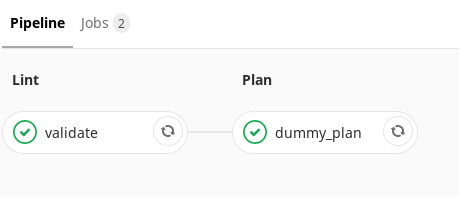
. , , . Terraform- , , . , merge-request . . . , , , .
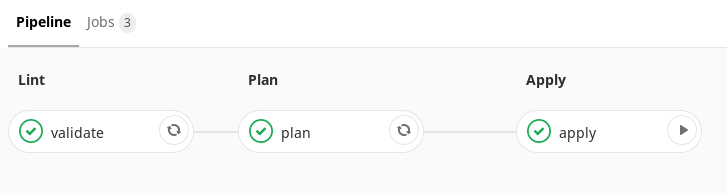
, . .
Terraform
. Terraform , , .
, «» — , .
, , count — , , , , availability-. , , , . . , AZ . , count .
, 4 AZ 5 , AZ — 4, , . : « ». ! , . Terraform .
. —
. . - - If Else. , — , .
. , , , , Terraform- , CI.
CI . , , , — merge, . .
, . . , , Terraform , , tfstate Terraform : «, , ». , , .
CI, , pipeline — , .
, . , . , target , . , : «Terraform apply target instance», -. - (, - ), .
, . . CI — , Terraform , . , - . , , , . .
Terraform —
:
- Terraform , . , , . , , , . , , , .
, — Tfstate, , . . « , » — .
, -, , - — . , . , — . - Terraform , . Terraform . Pourquoi? , . . , , AZ - -. , North Virginia, 6 . . , , : «, ». — . — , , Terraform .
- Terraform . , — 200 , 198 , 5. . , API . Hélas.
- , . , S3 bucket. , — , - . Terraform – , , : «, - ». . - , .
, Terraform — , . , .