Je propose de me familiariser avec le décodage du rapport de Denis Yakovlev "Automatisation des infrastructures. Pourquoi faisons-nous cela?"
Le rapport 2016 lui-même. Le rapport a été spécialement décrypté pour ceux qui créent des machines virtuelles avec leurs mains.
Rapportez comment nous, chez 2GIS, travaillons de manière automatisée avec l'infrastructure.
«Il faut courir aussi vite pour rester en place, mais pour aller quelque part, il faut courir au moins deux fois plus vite» (Alice au pays des merveilles).
Que signifie cette phrase pour nous? Dans un environnement hautement concurrentiel, les entreprises doivent s'efforcer de livrer leurs produits aux utilisateurs le plus rapidement possible. La réduction du délai de mise sur le marché est une tâche à plusieurs niveaux. Pour le résoudre, vous devez modifier à la fois les processus et les outils de développement. L'infrastructure est une base importante pour l'ensemble du processus de développement. Plus l'infrastructure est grande, plus elle présente de problèmes, de cas d'utilisation, etc. Si toutes les opérations avec celui-ci ne sont pas automatisées, le nombre de problèmes augmente. L'un d'eux est le temps qu'un développeur passe sur les problèmes d'infrastructure au lieu d'écrire la logique métier.
Parlons de:
- Quels problèmes d'infrastructure ont rencontré les équipes;
- Comment les processus de développement et de test en ont souffert;
- Comment nous avons implémenté OpenStack;
- Quels sont nos scénarios d'utilisation d'OpenStack;
- Comment l'automatisation a reçu une impulsion supplémentaire dans le développement et de nouveaux produits internes ont commencé à apparaître;
- Les aspects qui nous restent ne sont pas automatisés.
À propos de moi. Société 2GIS. Je travaille dans l'entreprise depuis deux ans.

Équipe des infrastructures et des opérations. Nous supportons principalement l'infrastructure interne du département Web. Récemment, d'autres équipes de produits internes nous ont rejoint. Nous sommes également responsables du fonctionnement des produits Web de l'entreprise en production. Et nous recherchons et développons également de nouveaux outils pour nous faciliter la vie et améliorer la vie de nos développeurs bien-aimés. Nous ne sommes que 9.

Nous comprenons d'abord l'infrastructure. Pourquoi parlons-nous d'elle? Qu'est ce que c'est Quand commençons-nous à parler d'elle?

Dès les premiers moments de travail sur le produit et certains projets, nous avons une question - où allons-nous déployer? où vérifier les résultats? où tester et ainsi de suite.

Immédiatement, la première réponse est locale. Localement parce que c'est très simple. Développé sur son ordinateur portable, lancé, vérifié - tout va bien. Vous êtes assis en pensant - pourquoi vérifier en plus de votre ordinateur portable? Tout fonctionne pour moi.

Et si nous avons un système d'exploitation sur l'ordinateur portable, et un autre tourne en production? Ou notre produit doit-il prendre en charge plusieurs systèmes d'exploitation?

L'affaire n'est pas couverte. Autrement dit, différents systèmes d'exploitation.

Si nous en avons l'occasion et que nous prenons une décision ferme - nous avons Linux partout. Par exemple, certains Ubuntu. Le reste vient du malin. Il nous semble que nous avons résolu tous nos problèmes.

Mais il ne suffit pas de faire correspondre le système d'exploitation. Nous avons besoin de packages d'une certaine version.

nous pensons comment résoudre ce problème. Et rappelez-vous - nous avons l'isolement. Des trucs très élevés. Dieu merci, il y a tellement de produits sur le marché. Nous prenons virtualbox. Créez une machine virtuelle. Nous roulons notre produit. Nous faisons des instantanés. Nous avons l'environnement.

Nous nous développons. Notre produit devient plus difficile. Ce n'est plus seulement une application de base de données php. L'application est devenue un système distribué. Nous avons d'autres produits à venir.

L'entreprise se développe. Et nous avons de nouveaux cas d'utilisation. Tous ces produits veulent s'intégrer, pouvoir travailler ensemble. Nous avons des fonctionnalités qui passent par plusieurs produits. On nous demande constamment de montrer ce que vous avez développé. Voyons cela quelque part. Nous n'avons plus de ressources pour les tests manuels. Nous rappelons qu'il existe une intégration continue, des autotests. Pour ce faire, vous avez besoin d'un logiciel supplémentaire. L'environnement local américain, même avec tout l'isolement, ne suffit plus. C'est là que l'infrastructure entre en jeu. Nous avons besoin d'un endroit où nous pouvons déployer nos produits et montrer à quelqu'un les résultats. Nous devons en quelque sorte gérer tout cela et cela devrait être pratique.

Allons voir notre société 2GIS.

Ceci est un guide et des cartes. Vous pouvez consulter le plan de la ville, rechercher des organisations.

Nous avons: produits web, mobile, application bureautique. Il y a environ trente-cinq équipes différentes de tailles différentes.

Quels problèmes avons-nous rencontrés avec l'infrastructure? Fin 2013, nous avons utilisé proxmox. Il s'agit d'un système de gestion de virtualisation. En l'utilisant, vous pouvez créer des machines virtuelles KVM ou des conteneurs OpenVZ. Mais tout cela se fait à la main via des interfaces. Pour un fonctionnement complet, vous devez toujours accéder à la machine virtuelle et configurer le réseau, DNS.

Par conséquent, pendant un certain temps, le flux de notre développement a été le suivant. En tant que développeur, je recherche des administrateurs de tickets. Les administrateurs, lorsqu'ils ont le temps, créent une machine virtuelle. Ils donnent une adresse IP, un login, un mot de passe. Mais si j'ai besoin de redéployer cette machine virtuelle, je reviens aux administrateurs qui me regardent déjà avec méfiance. Ils disent - un gars autant que possible?

Il n'y avait pas de séparation des projets. Il y avait un ensemble de machines virtuelles sur plusieurs serveurs, où les administrateurs ont tout créé avec leurs mains. Il y avait une forte probabilité d'erreur humaine. Vous pouvez confondre l'adresse IP ou supprimer la mauvaise machine virtuelle. Un très, très grand nombre de ces cas. Et la responsabilité de la machine virtuelle est incompréhensible. Les développeurs ne sont pas responsables, les administrateurs ne prennent pas non plus de bain de vapeur. Il n'est pas clair que quelqu'un d'autre ait besoin d'une machine virtuelle ou que tout le monde l'ait oublié depuis longtemps et ne le sache pas.

De plus, il y a une API faible. Les plugins sont payants ou perl.

Mais en plus des problèmes, nous avions autre chose d'utile. Nous avions notre propre fer à repasser, sur lequel tout cela tournait. Nos administrateurs système sont de bons amis, ils savent comment cuisiner ce fer, en prendre soin et l'acheter correctement. Et ils avaient une certaine expérience de la virtualisation.

Nous avons commencé à penser: quelle solution nous conviendrait? À quoi devrait ressembler notre infrastructure pour ne pas interférer avec le processus de développement, mais plutôt aider?
Nous avons obtenu la liste d'exigences suivante à la suite de l'étude:
Utilisation efficace du fer. Nous ne voulons pas de machines virtuelles orphelines. Nous ne voulons pas simplement réchauffer l'air dans le centre de données.
Nous voulons avoir des ressources d'équipe afin que l'équipe prenne la responsabilité des ressources qu'elle utilise. Et elle était attentive à eux.
Nous voulons que la solution soit modulaire, choisissez uniquement les services dont nous avons besoin. Et en cas de besoin, avec de nouveaux développements, être en mesure de se développer.
La solution doit être facilement finalisée. Si de nouvelles exigences apparaissent, nous pourrions affiner la solution à nos besoins spécifiques.
Nous avons besoin non seulement d'une interface utilisateur, nous avons besoin d'une API pour écrire nos liaisons et gérer l'infrastructure.
Nous voulons isoler les équipes, et surtout l'équipe de test de charge. Je voulais qu'elle ne dérange pas du tout le reste.

Quelles étaient nos options?
Nous avons examiné le cloud public: AWS et plus encore. L'option est intéressante dans la mesure où elle prend en charge presque tous les problèmes liés aux infrastructures. Il était possible de prendre et de payer beaucoup d'argent à ces sociétés célèbres, mais nous étions contraints par la situation dégoûtante du dollar (ou des sanctions). Je ne voulais pas vraiment avoir de verrou de fournisseur. La troisième option, dans laquelle nous avons examiné ce que nous avons sur le marché open source? Quelles solutions sont proposées? Nous avons notre propre matériel, il reste à choisir quelque chose parmi ces nombreuses applications open source.

Donc, à la fin, nos recherches et expériences nous ont conduit à un logiciel appelé OpenStack. Softinke bien sûr, cela semble trop grossier.

OpenStack est un logiciel à part entière, en fait, c'est un ensemble de services pour la construction d'un cloud public ou privé. OpenStack est une solution open source. Tous les services sont écrits en python. Chaque service est responsable de sa tâche, possède sa propre API.
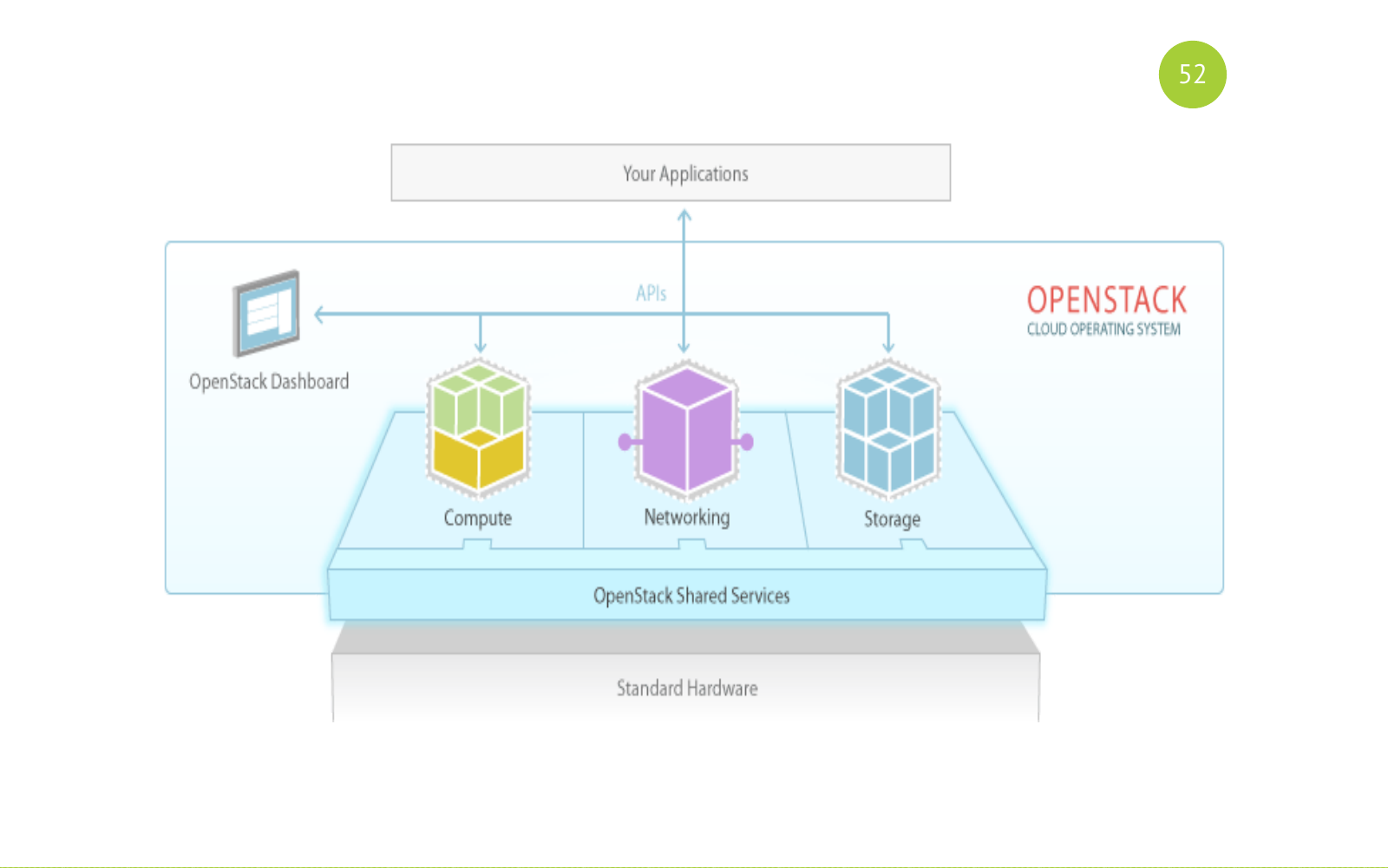
Et ça ressemble à ça. Rappelez-vous cette image. Ensuite, nous reviendrons vers elle. Il existe des services (généraux) partagés. Il existe des services à cet effet: calcul, mise en réseau, stockage. Et notre application ou utilisateur travaille avec ces services.

Solution open source. La sortie a lieu six mois. La version comprend des composants de base. Chaque version comprend de nouveaux composants qui apparaissent initialement dans cet incubateur. Ils y passent du temps, corrigent des bugs, se stabilisent et ainsi de suite. Et à un moment donné, la communauté décide que ce composant devrait être inclus dans les composants de base de la prochaine version. Il existe également de nombreux mailings, réunions, conférences. La plus grande conférence est l'OpenStack Summit. Tenue chaque année. Et lors du dernier OpenStack Summit, il y avait environ quatre ou cinq mille participants. Un si grand événement. Beaucoup de rapports.

Beaucoup de gens contribuent à cette décision. Ici, je n'ai donné qu'une liste de ces hauts. Cette liste est suffisante pour comprendre la gravité du projet et les entreprises et les ressources qu'elles y investissent.

Comment nous avons résolu nos problèmes d'infrastructure.
- L'un des composants d'OpenStack est le planificateur, qui sélectionne l'hôte sur lequel la machine virtuelle sera créée.
- L'équipe dispose désormais de ses propres ressources. C'est la quantité de CPU, de mémoire et plus encore. Nous nous sommes débarrassés de ce scénario pour créer un virtuel sur tiket (application).
- OpenStack est un ensemble de services qui l'est. Nous n'avons pris que le kit de base qui répondait à nos besoins.
- Étant donné qu'OpenStack est open-source, il est possible de le modifier.
- Chaque service possède une API. Il existe des versions python. Autrement dit, il est assez simple d'interagir avec chaque service et d'écrire vos propres liaisons.
- Isolement. Nous pouvons isoler des équipes pour nous sur des projets, sur des zones d'agrégation, sur des réseaux, etc.

Les développeurs de l'équipe ont reçu l'infrastructure en tant que service. À quoi ça ressemble.

Il existe deux concepts de pile et de modèle. Stack est un ensemble de ressources cloud: machines virtuelles, réseau, enregistrements DNS et plus encore. Un modèle est une description de cette pile. Dans le cas d'OpenStack, il s'agit d'un fichier YAML normal. Voici une partie du dossier. Il indique qu'il existe une entité telle qu'un serveur avec un serveur OS Nova de type interne. Pour son fonctionnement normal, vous avez besoin d'une adresse IP et d'un enregistrement DNS. Ici, les paramètres de nom sont acceptés en entrée, la saveur est une description des ressources dont ce serveur a besoin. Système d'exploitation d'image. nom_clé - quelle clé publique mettre lors du déploiement du serveur. Nous avons tous ces modèles dans le référentiel de chacun d'eux dans git. Tout le monde y a accès. Tout le monde peut envoyer une demande de pull.

Et la création de Stack est la suivante. Heat est le composant OpenStack responsable de l'orchestration. Nous disons cela dans ce contexte. Il s'agit d'un excellent utilitaire que nous avons installé pour nous-mêmes. Nous disons chère chaleur, créez-nous une pile avec ce nom, voici une description des ressources dont nous avons besoin pour créer cette pile. Et voici l'entrée requise par notre modèle, qui décrit notre pile. Nous le chargeons en chaleur. Il y fait du bruit pendant un moment, crée en nous toutes les ressources nécessaires. Et aussi nous dans ce modèle ici, nous pouvons spécifier la sortie. Lorsque la chaleur a créé Stack, elle peut produire des informations: adresse IP, accès et le reste que nous demandons. De plus, nous pouvons déjà appliquer ces informations pour une automatisation supplémentaire.

Pour que vous ne pensiez pas qu'OpenStack est simple et bon marché, je vais vous dire pour quel matériel OpenStack fonctionne. Le panneau de contrôle tourne sur 3 infra-nœuds. Ce sont des serveurs de fer avec de telles ressources. Il s'agit de la configuration recommandée pour le basculement.

Nous avons également deux nœuds de réseau KVM qui desservent notre réseau.

Les ressources de l'équipe tournent sur 8 nœuds de calcul. Ils sont divisés en 3 zones d'agrégation. Un nœud de calcul est alloué par zone pour les tests de charge. Là, les serveurs sont créés uniquement à partir de l'équipe de test de charge. Afin de ne pas interférer avec le reste. Nous avons une zone d'agrégation pour notre projet d'automatisation des tests GUI internes. Il a certaines exigences. Il est situé dans une zone d'agrégation distincte. Tous les autres environnements de développement, serveurs, environnements de test tournent dans la troisième grande zone d'agrégation. Cela nous prend 6 nœuds de calcul.

Nous faisons tourner environ 350 machines virtuelles pour toutes les équipes.

Qu'avons-nous compris alors que nous avions déjà parcouru un certain chemin. Pour déployer et prendre en charge ce logiciel, vous avez besoin d'une équipe. Équipe en fonction de vos ressources.

Les équipes doivent avoir certaines compétences.
Tout d'abord, c'est naturellement Ansible. OpenStack deploy est écrit en Ansible. Il existe un projet OpenStack-Ansible . Si vous souhaitez ajouter OpenStack-Ansible à vos besoins, les personnes qui le feront doivent posséder Ansible.
Expérience de virtualisation. Vous devez être capable de cuisiner la virtualisation, vous devez régler. Comprenez comment cela fonctionne.
Le même réseau.
Il en va de même pour les services backend qu'OpenStack utilise pour son travail. Cette base de données est MySQL Galera et RabbitMQ en tant que file d'attente.
Comprendre le fonctionnement du DNS. Comment le configurer.
OpenStack est écrit en python. Vous devez pouvoir lire le code. Idéalement, vous devez pouvoir patcher. Recherchez les correctifs de la communauté. Être capable de débuter le code. Tout cela est très utile. Si une équipe a une telle approche, sait utiliser une approche comme Infrastructure comme code, comme ansible, par exemple, toutes les modifications sont stockées dans le code, alors elles n'auront pas de problèmes lors de la configuration des mains.
Intégration continue. La suite de services OpenStack comprend un service tel que tempest . Dans ce document, tous les tests sont écrits sur tous les composants. Si nous changeons la configuration, exécutons un diplôme séparé dans l'installation All-In-One et exécutons Tempest - nous cherchons à voir si quelque chose est tombé avec nous. CI est configuré et l'équipe doit comprendre cela et doit être en mesure de configurer tout cela.
Parce que tout semble simple et attrayant étant donné.

Mais lorsque vous commencez à vous y plonger davantage, vous comprenez qu'en fait, tout ressemble à ceci. Cela peut être une surprise pour quelqu'un.

L'introduction d'OpenStack n'est pas seulement une solution technique. De plus, il faut pouvoir vendre, être en mesure d'expliquer aux équipes le nouveau paradigme de leur fonctionnement actuel, quels bénéfices cela apporte. Comment travailler avec lui pour obtenir un profit. Nous avons écrit beaucoup de documentation. La documentation est de la forme quickstart (démarrage rapide), premières étapes (premières étapes). C'est-à-dire ce qui doit être fait pour vous faciliter la vie rapidement et ne pas y consacrer beaucoup de temps.
Nous avons mené TechTalk, nous avons parlé, fait des sujets, montré, parlé, maintenant voyez maintenant que vous pouvez obtenir votre produit comme suit. littéralement ici, nous écrivons un modèle, nous le lançons. Tout est assez simple. Maintenant, vous n'avez plus besoin d'aller voir les administrateurs pour leur demander quelque chose.
Dans des cas particulièrement difficiles lorsque le projet est complexe, il a beaucoup de cas, nous sommes venus en équipes, avons travaillé directement avec les équipes. Autrement dit, ils ont en quelque sorte essayé de les aider dans l'automatisation des processus. Mettre en place toutes les équipes. Blessé quelques bugs. Ils ont compris que nous n'avions pas configuré quelque chose de mal là-bas. En général, un travail serré avec les équipes.

Nous avons reçu un déploiement rapide de produits. Auparavant, pour recevoir des produits, il fallait effectuer de nombreuses actions manuelles, interagir avec de nombreuses personnes. Nous obtenons maintenant la création d'Environnement (environnement, serveur) par bouton. Et si le déploiement est écrit et fonctionne pour le projet, nous obtenons le déploiement par le bouton ou le nouvel environnement (environnement, serveurs) avec le produit installé.
L'absence d'une infrastructure normale a été un obstacle pour certaines équipes en termes de mise en œuvre du processus CI au sein de l'équipe. Nous avons résolu les problèmes d'infrastructure, les équipes formées sur le serveur CI, configuré le pipeline, les machines virtuelles sont créées dans le pipeline. En général, ils ont donné une impulsion au développement de ces processus.
Ils ont également aidé certains produits internes qui utilisent l'infrastructure pour automatiser les tests. VM Master est un produit qui teste notre ligne. Il doit élever beaucoup de machines virtuelles afin d'accéder au site à partir de différents navigateurs, suivre certaines étapes pour comprendre que le fonctionnement en ligne dans tous les navigateurs connus. Autrement dit, ils l'ont beaucoup aidé.
Un bon bonus est qu'ils ont déchargé les administrateurs (eux-mêmes). Parce qu'à un moment donné, l'activité de création d'une machine virtuelle a commencé à prendre du temps. Et tout le monde a commencé à devenir nerveux. Maintenant, nous faisons des choses intéressantes, des produits complexes. Nous nous sommes débarrassés de la tâche de routine.

Des questions?
Question: Combien de temps a-t-il fallu pour déployer OpenStack?
Réponse: La question est compliquée parce que nous avions un processus qui peut accueillir une série comique. Il a un seuil d'entrée élevé. Nous avons compris toute notre infrastructure, recherché une solution - cela a pris trois mois. Puis, en un mois, nous avons déployé la première installation quelque part. Nous y avons ajouté quelques projets. Ils y vivaient. Puis le facteur humain s'est produit - ils ont tiré sur la tête de cette installation. Nous avons réalisé que le manque de tolérance aux pannes est mauvais. Ensuite, nous avons attendu le fer.
Question: Utilisez-vous un support payant?
Réponse: non, nous ne l'utilisons pas.
Question: Quelle version d'OpenStack utilisez-vous?
Réponse: Les versions d'OpenStack sont appelées mots. Tout d'abord, Juno, puis nous sommes passés à Liberty.
Question: Les machines virtuelles sont-elles créées dans le pipeline Intégration continue?
Réponse: Construire dans Jenkins peut provoquer de la chaleur et créer une machine virtuelle.
Question: Avez-vous rencontré des problèmes avec le partage des ressources? En gros, 2 machines virtuelles sont sur le même serveur physique. L'un d'eux commence à charger un disque, par exemple une base de données. Si vous êtes confronté, comment avez-vous décidé?
Réponse: Nous n'avons pas rencontré de problèmes avec le partage des ressources. Les produits des autres n'interfèrent pas beaucoup. Nous avons présenté les scripts. Si vous devez exécuter un scénario lourd, exécuter des tests de charge, vous devez vous adresser à l'équipe de test de charge et celle-ci exécute le test de charge.
: - ?
: OpenStack . . . .
: . . OpenStack ?
: . OpenStack . .
: OpenStack?
: . proxmox. OpenStack.
: DevOps?
: DevOps , . , , .
PS 2019 OpenStack heat Terraform .