
Salut les collègues! Comment mettre en évidence les principaux sujets de 20 000 nouvelles en 30 secondes? Vue d'ensemble de la modélisation thématique que nous faisons dans TASS, avec des contraintes et du code.
Pour commencer, les informations présentées dans cette note font partie d'un prototype en cours de développement au laboratoire numérique ITAR-TASS afin d'accompagner la «digitalisation» de l'entreprise. Les solutions s'améliorent constamment, je décrirai la section actuelle, elle ne sera évidemment pas la couronne de la création, mais plutôt un support pour de nouveaux développements.
Grande idée
En plus de l'agenda des nouvelles, sur lequel les rédactions de TASS travaillent quotidiennement, il est bon de comprendre quels sujets créent le plus de fond d'actualité dans les médias en ligne russes. À cette fin, nous collectons les dernières nouvelles des 300 sites les plus populaires toutes les quelques minutes, 24/7; vient alors le plus intéressant - le choix des méthodes de modélisation et des expériences.
À la fin de la session magique, mes collègues, éditeurs et gestionnaires commenceront à utiliser le rapport avec des sujets d'actualité. Je crois que pour les personnes en dehors du domaine du développement de logiciels et de la science des données, le traitement automatique, l'analyse et la visualisation des données textuelles semblent un peu magiques. En raison de l'aliénation d'une personne de la haute technologie, diverses imperfections dans son travail peuvent conduire à un manque de compréhension de ce qui est à l'intérieur et à la déception. Pour minimiser la réaction négative, j'essaie de rendre le produit plus simple et plus fiable. Et la compréhension de l'essence de la modélisation thématique peut être réduite au fait que les nouvelles liées à un sujet et différentes des nouvelles de tout autre sujet appartiennent à un seul sujet.
J'expérimente la modélisation thématique depuis environ un an maintenant. Malheureusement, la plupart des approches que j'ai essayées m'ont donné une qualité très douteuse de remplir des sujets d'actualité. Dans le même temps, j'ai effectué des actions selon la logique de sélection des paramètres dans les méthodes des bibliothèques de clustering populaires. Mais je n'ai pas de jeu de données étiqueté. Par conséquent, chaque fois que je regarde une sélection de textes qui tombent dans un sujet particulier. L'affaire est plutôt morne et non reconnaissante.
Une particularité particulière de cette tâche est que plusieurs spécialistes, en regardant les nouvelles incluses dans le sujet sélectionné, les trouveront à un degré ou à un autre inappropriés. Par exemple, les nouvelles avec la déclaration d'Erdogan sur le début de l'opération en Syrie et les nouvelles avec les premiers rapports après le début de l'opération en Syrie peuvent être comprises comme un ou plusieurs sujets. En conséquence, les médias, citant TASS ou une autre agence de presse, écriront une série de textes sur ceci et cela. Et le résultat de mon algorithme aura tendance à les combiner ou à les séparer en fonction de ... le cosinus de l'angle entre les vecteurs de fréquence des mots, le nombre de vecteurs acceptés a priori, ou le rayon dans la méthode de recherche des voisins les plus proches.
En général, toute cette grande idée est aussi fragile que belle.
Pourquoi l'analyse factorielle?
Un examen plus approfondi des méthodes de regroupement des textes montre que chacun d'eux est basé sur un certain nombre d'hypothèses. Si les hypothèses ne correspondent pas au problème étudié, alors le résultat peut fortement conduire au côté. Les hypothèses de l'analyse factorielle me semblent - et à beaucoup d'autres chercheurs - proches de la tâche de modélisation des sujets.
Créée au début du XXe siècle, cette approche était basée sur l'idée qu'en plus des variables caractérisant les observations de l'échantillon, il existe des facteurs cachés qui, parlant de manière informelle, sont en corrélation avec certaines variables observables. Par exemple, les réponses à la question «Croyez-vous en Dieu» et «Allez-vous à l'église» coïncideront plutôt que différeront. On peut supposer qu'il existe un «facteur de religiosité» qui se manifeste dans un ensemble de variables interdépendantes. Dans le même temps, il est également possible de mesurer à quel point les variables sont liées à leur facteur caché.
Pour les textes, l'énoncé du problème devient le suivant. Dans les nouvelles qui décrivent le même sujet, les mêmes mots se produiront. Par exemple, les mots «Syrie», «Erdogan», «Opération», «États-Unis», «Condamnation» se retrouveront plus souvent dans les nouvelles consacrées au déploiement de l'intervention militaire de la Turquie en Syrie et dans la réaction qui en découle aux États-Unis ( comme acteur géopolitique sur le même territoire).
Il reste à repérer tous les facteurs importants de l'agenda des nouvelles pendant une période. Ce seront des sujets d'actualité. Mais ce n'est pas tout ...
Un peu de maths
Pour les personnes expérimentées dans les techniques de modélisation de sujet, je peux faire une telle déclaration. La version de l'analyse factorielle que j'ai essayée est une version très simplifiée de la
méthodologie ARTM .
Mais j'ai décidé d'expérimenter des méthodes où il y a moins de degrés de liberté, pour que ce qui se passe à l'intérieur soit mieux compris.
(Big) ARTM est né de pLSA, une analyse sémantique latente probabiliste, qui, à son tour, était une alternative à LSA basée sur une décomposition matricielle singulière - SVD.
L'analyse des facteurs d'intelligence va plus loin que la SVD en ce qu'elle fournit une «structure simple» de la relation entre les variables et les facteurs, ce qui n'est peut-être pas simple pour la SVD, mais est limitée en ce qu'elle n'est pas conçue pour calculer avec précision les valeurs des facteurs (scores), puis il existe des vecteurs de valeurs de facteurs qui peuvent remplacer 2 variables observables ou plus.
Officiellement, la tâche de l'analyse des facteurs de renseignement est la suivante:
Où sont les variables observées
lié linéairement à des facteurs cachés
Besoin de trouver
C’est tout! Ces coefficients bêta sont appelés charges dans le monde de l'analyse factorielle. Considérez leur importance un peu plus tard.
Pour arriver au résultat de l'analyse, on peut se déplacer de différentes manières. L'un d'eux que j'ai utilisé est de trouver les principaux composants au sens classique, qui tournent ensuite pour mettre en évidence la «structure simple». Les principaux composants s'étendent de la décomposition singulière de la matrice, ou à travers la décomposition de la matrice de covariance variationnelle en vecteurs et valeurs propres. Le problème est également résolu en maximisant la fonction de vraisemblance. En général, l'analyse factorielle est un grand «zoo» de méthodes, au moins 10 qui donnent des résultats différents, et il est recommandé de choisir la méthode qui convient le mieux à la tâche.
La rotation de la matrice de charge peut également se faire de différentes manières, j'ai essayé varimax - rotation orthogonale.
Pourquoi tout est-il si compliqué?Le fait est que parmi les statisticiens et les candidats, la discussion ne s'arrête pas sur les différences et les similitudes de la méthode des composantes principales, de l'analyse factorielle et de leur combinaison. La méthodologie est reconstituée avec de nouvelles connaissances même après plus de 100 ans à partir du moment de la découverte. Un statisticien respecté m'a apporté l'image suivante pour faciliter la compréhension avec les mots: "C'est ça, triez-le."
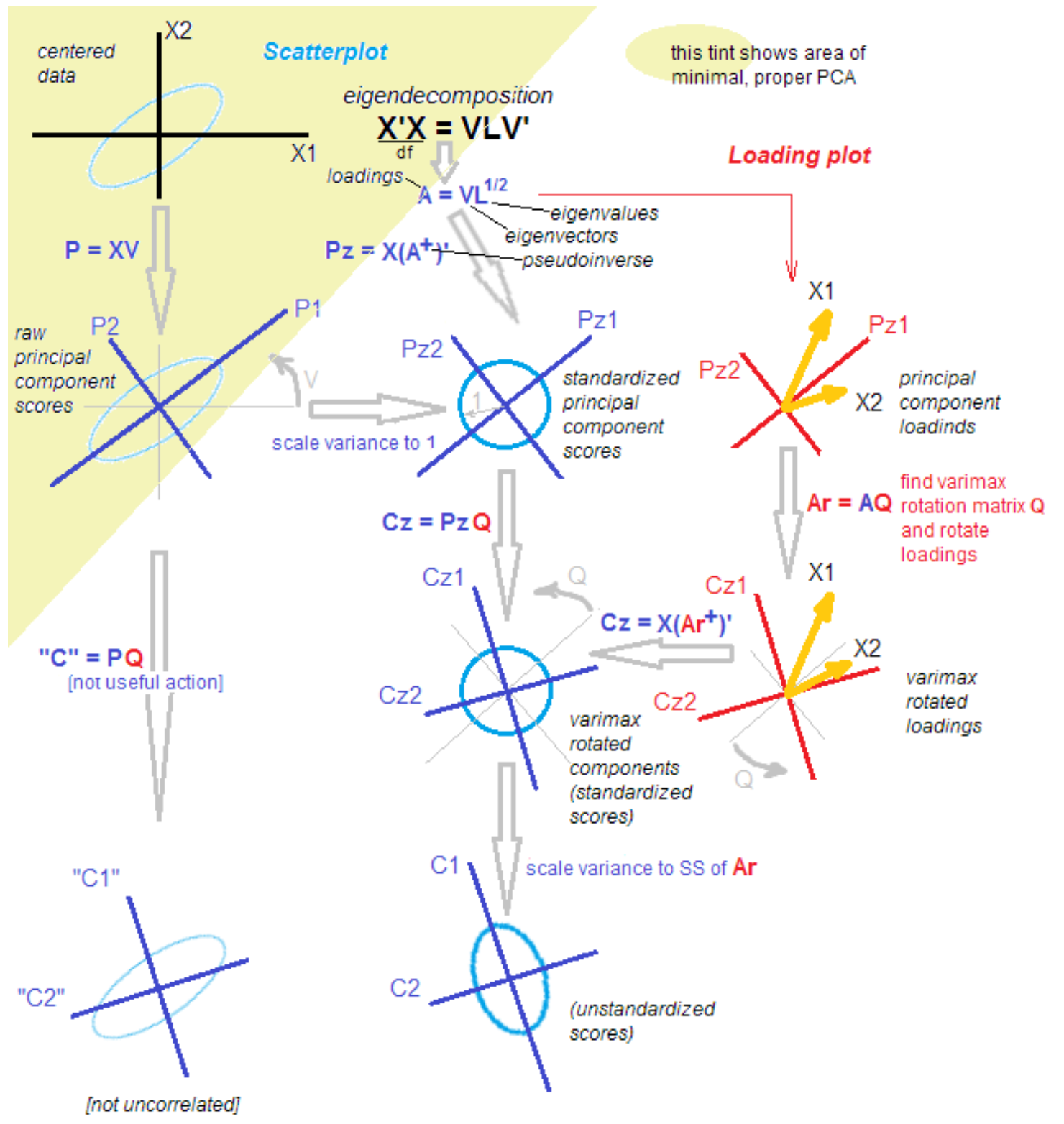 source
source .
Tout régler!
Je plaisante). Pour comprendre les étapes suivantes, il suffit qu'après avoir isolé les principaux composants, nous les faisons pivoter, en passant de l'explication de la variance au sein des variables à l'explication de la covariance des variables et des facteurs.
De plus, je fais tout cela en utilisant des fonctions atomiques, et pas seulement en appuyant sur un «gros bouton rouge». Cette approche nous permet de comprendre la transformation des données aux étapes intermédiaires.
Où est passée la LDA?
Mettre à jourJ'ai décidé d'ajouter mes réflexions sur les arrangements de Dirichlet latents. J'ai essayé cette méthode populaire, mais je n'ai pas pu obtenir un résultat net en peu de temps. Des exemples simples de la façon de l'utiliser et le «Divisons les nouvelles en politique, économie et culture» fonctionnent vraiment, mais ... Dans mon cas, je dois diviser, disons, la politique en 50 sujets de jour, où la Russie, Poutine et l'Iran seront , et des sujets aussi étroits que «la libération de Kokorin et de Mamaev». Tout cela, en fait, 1-2 nouvelles d'agence de presse, citées plusieurs dizaines de fois dans les médias.
De plus, l'hypothèse sur la nature des données, caractéristique de l'hypothèse que chaque texte est une distribution de probabilité par thème, me semble un peu artificielle dans le cadre de mon travail. Aucun éditeur n'est d'accord pour dire que la nouvelle du «rejet de l'affaire contre Golunov» est un mélange de thèmes. Pour nous, c'est 1 sujet. Peut-être qu'en choisissant des hyperparamètres, il est possible d'obtenir une telle fragmentation de la LDA, je laisserai cette question pour l'avenir.
Code
Je m'essaye à nouveau au langage R, donc cette petite expérience sera aryenne.
Nous travaillons avec 3 paires de valeurs aléatoires corrélées. Cet ensemble contient 3 facteurs cachés - juste pour plus de clarté.
set.seed(1) x1 = rnorm(1000) x2 = x1 + rnorm(1000, 0, 0.2) x3 = rnorm(1000) x4 = x3 + rnorm(1000, 0, 0.2) x5 = rnorm(1000) x6 = x5 + rnorm(1000, 0, 0.2) dt <- data.frame(cbind(x1,x2,x3,x4,x5,x6)) M <- as.matrix(dt) sing <- svd(M, nv = 3) loadings <- sing$v rot <- varimax(loadings, normalize = TRUE, eps = 1e-5) r <- rot$loadings loading_1 <- r[,1] loading_2 <- r[,2] loading_3 <- r[,3] plot(loading_1, type = 'l', ylim = c(-1,1), ylab = 'loadings', xlab = 'variables'); lines(loading_2, col = 'red'); lines(loading_3, col = 'blue'); axis(1, at = 1:6, labels = rep('', 6)); axis(1, at = 1:6, labels = paste0('x', 1:6))
Nous obtenons la matrice de charge suivante:
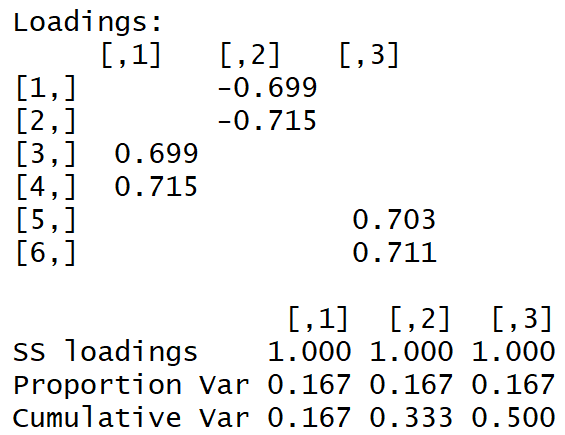
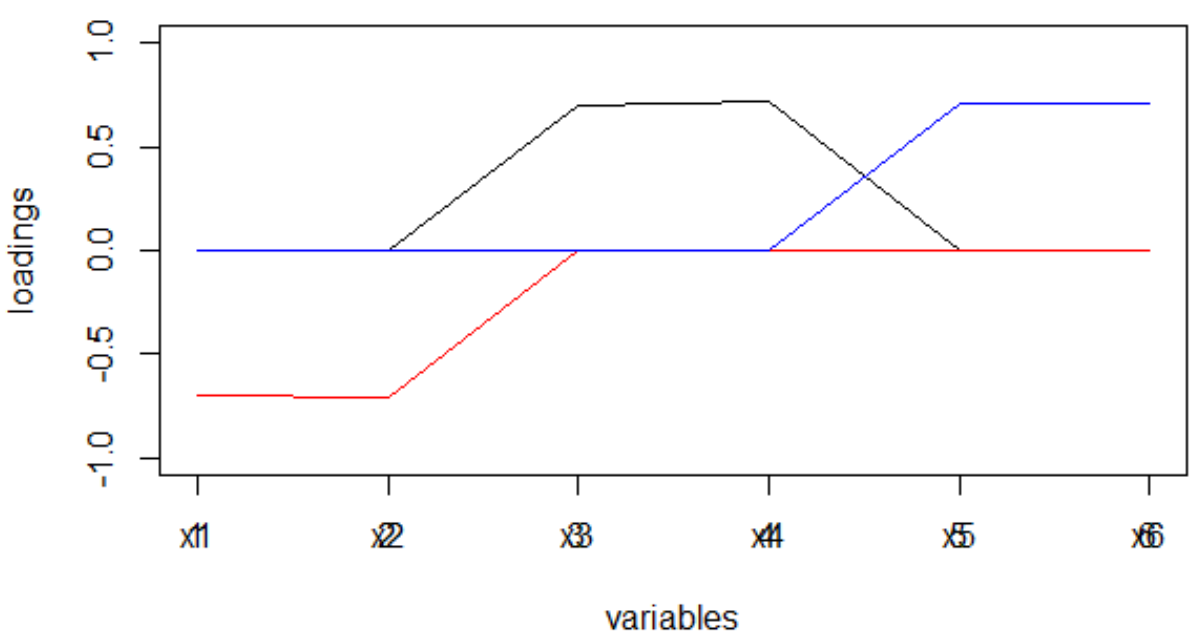
La "structure simple" est visible à l'œil nu.
Et voici à quoi ressemblaient les charges juste après l'achèvement du MGK:
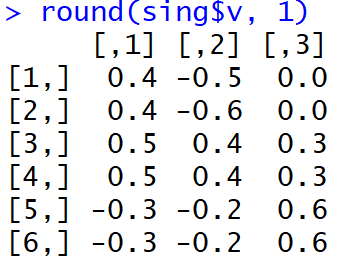
Il n'est pas très facile pour les gens de comprendre quels facteurs sont associés à quelles variables. De plus, de tels poids, pris modulo, et dans l'interprétation de la machine conduiront à une très étrange répartition des mots sur les sujets.
Mais, bo !, La part de la dispersion expliquée dans les trois premiers composants principaux (avant rotation) a atteint 99%.

Et les nouvelles?
Pour l'actualité, nos variables x1, x2 ... xm deviennent la fréquence (ou tf-idf) de l'occurrence du jeton dans le texte. Il y a beaucoup de mots! Par exemple, 50 000 mots uniques par semaine sont normaux. Le bi-gramme sera encore plus gros, naturellement. La complexité de la décomposition singulière est la moyenne:
Autrement dit, c'est énorme. La décomposition d'une matrice de 20 000 * 50 000 valeurs en un seul flux prend plusieurs heures ...
Pour pouvoir lire les sujets en temps réel et afficher Shiny sur un tableau de bord, je suis arrivé aux seuils douloureux suivants:
- 10% des mots les plus courants
- sélection aléatoire des textes selon la formule auto-réalisatrice:
où n est tous les textes.
En conséquence, je traite les données hebdomadaires en 30 secondes, un jour en 5 secondes. Pas mal! Mais, vous devez comprendre que les nouvelles ne sont saisies que par les plus bien nourris.
Ayant reçu des charges, qui, je le constate, sont des estimations de la covariance des variables observées avec les facteurs, je les libère du signe (via le module, pas par le degré), qui a tendance à changer selon la méthode de rotation utilisée.
Rappelez-vous comment la matrice de charge a différé après avoir effectué le MHC et après rotation avec varimax. La rareté des charges, ainsi que le fait que leur dispersion pour chaque facteur a été maximisée: il y en a de très grandes et de très petites, conduiront au fait que les mots seront répartis entre les facteurs assez proprement, ce qui, à son tour, conduira à et la distribution des facteurs sur le texte des nouvelles aura un pic prononcé.
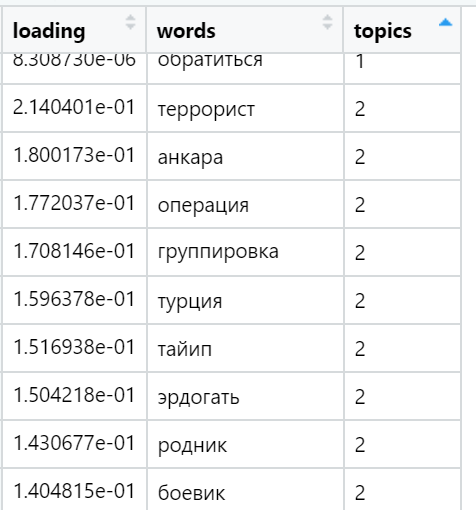
Exemples des mots les plus chargés dans divers sujets trouvés (sélectionnés au hasard):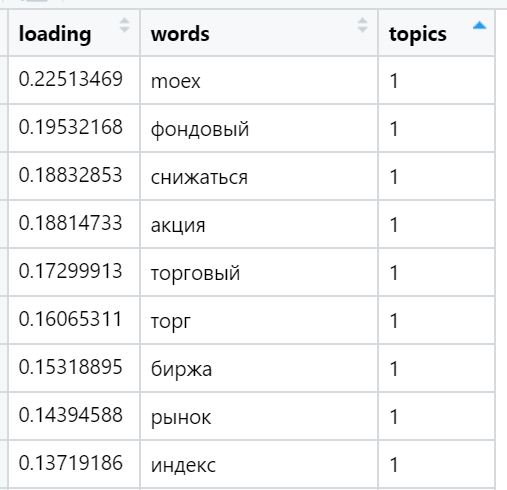

Et enfin, je considère la somme des charges dans les textes par rapport à chaque facteur. Les gains les plus forts: pour chaque texte, on sélectionne un facteur dont la somme des charges est maximisée - en tenant compte du nombre de mots inclus dans le document qui - comme nous l'avons fourni lors de la rotation - ont une répartition très inégale entre les facteurs de charge. Dans cette itération, tous les textes (n) sont déjà impliqués, c'est-à-dire l'échantillon complet.
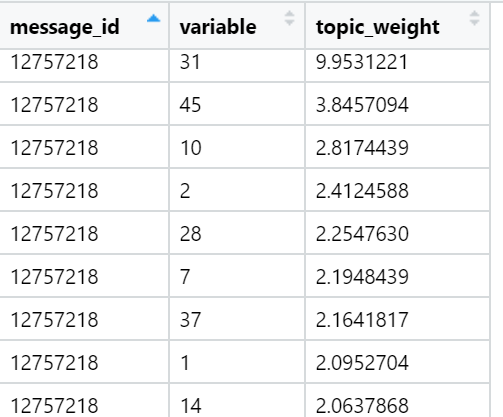
Exemples de sujets qui sont en tête en termes de somme de charges dans des textes d'actualités spécifiques (sélectionnés au hasard):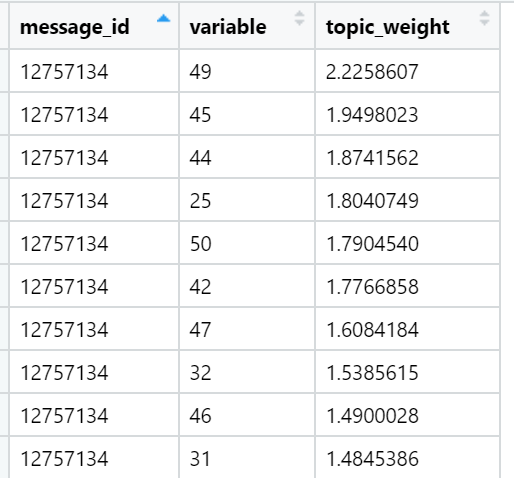
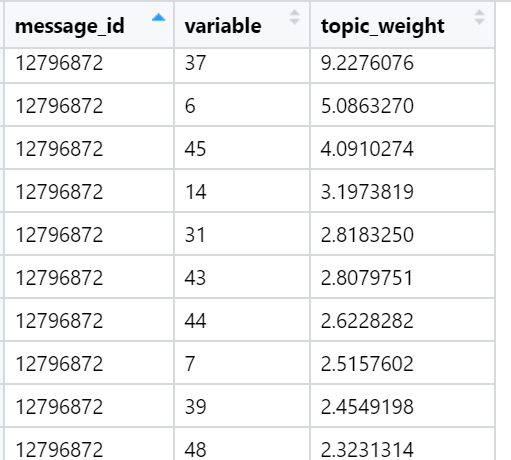 Le résultat pour aujourd'hui.
Le résultat pour aujourd'hui. Information complémentaire.
Information complémentaire.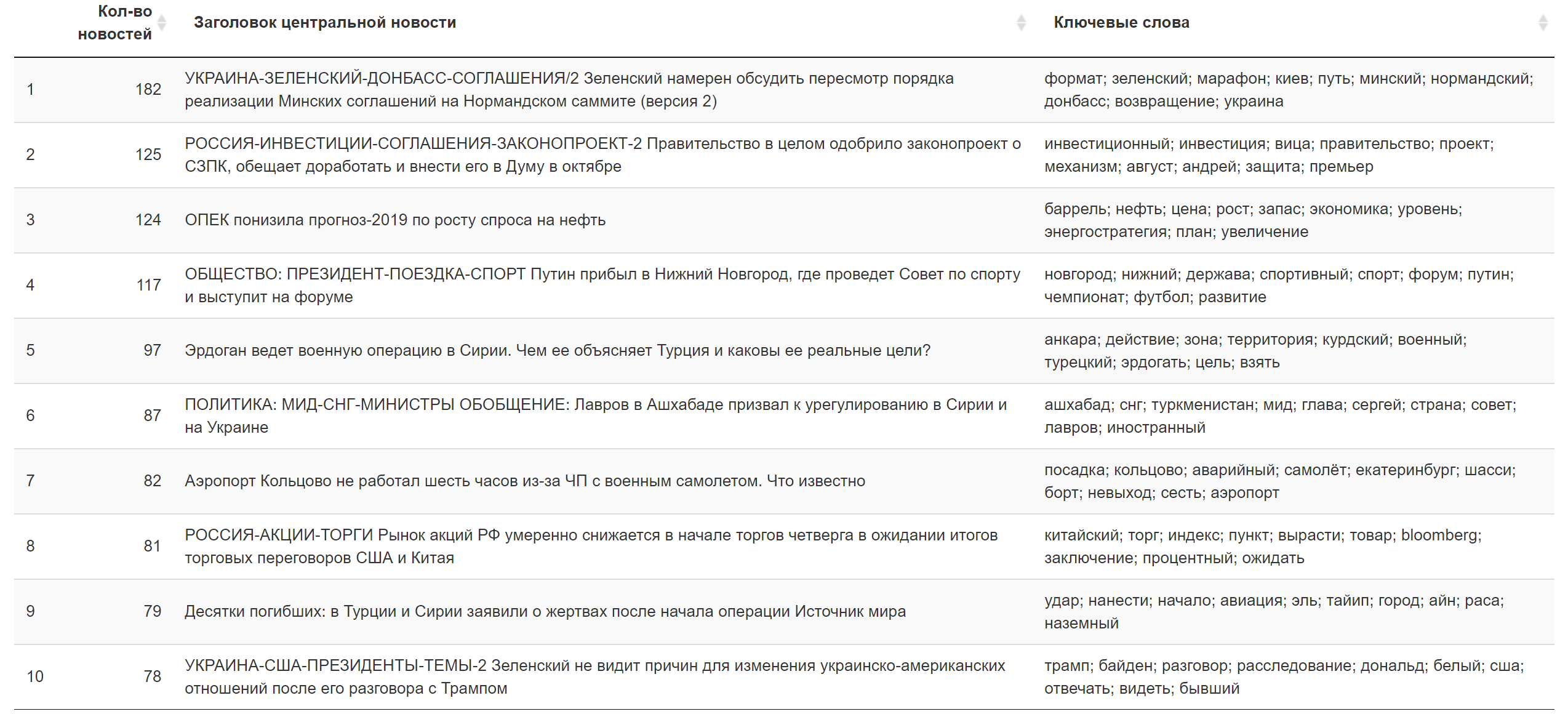
Que faire
Ici, la première chose que je ferai quand ... En général, lorsque l'inspiration viendra, j'essaierai de configurer le travail pour la formation horaire d'un réseau neuronal avec un cou étroit, ce qui me donnera juste une approximation non linéaire des facteurs - composants principaux déformés - sous la forme de neurones de couche cachés. En théorie, l'apprentissage peut se faire rapidement en utilisant la vitesse d'apprentissage accrue. Après cela, les poids de la couche cachée (en quelque sorte normalisés) joueront le rôle de charges de jetons. Ils peuvent déjà être rapidement chargés dans l'environnement de traitement final à une vitesse acceptable. Peut-être que cette astuce peut conduire au fait que la semaine sera traitée dans tous les textes en 10 secondes: le temps normal pour un cas aussi difficile.
Dans l'ensemble, c'est tout ce que je voulais couvrir. J'espère que cette brève excursion dans la méthode de modélisation du sujet vous permettra de mieux comprendre ce qui se fait sous le «gros bouton rouge», de réduire l'aliénation technologique et d'apporter de la satisfaction. Si vous le saviez déjà, je serai heureux d'entendre les avis d'un sens technique ou produit. Notre expérience évolue et change tout le temps!