Bonjour, Habr! Auparavant, je me plaignais de la vie dans l'infrastructure en tant que paradigme de code et je n'ai rien proposé pour résoudre cette situation. Aujourd'hui, je suis revenu pour vous dire quelles approches et pratiques aideront à sortir de l'abîme du désespoir et à remettre la situation sur la bonne voie.

Dans l'article précédent
«Infrastructure en tant que code: première connaissance», j'ai partagé mon impression de ce domaine, j'ai essayé de réfléchir sur la situation actuelle dans ce domaine et j'ai même suggéré que les pratiques standard connues de tous les développeurs peuvent aider. Il peut sembler qu'il y avait beaucoup de plaintes concernant la vie, mais il n'y avait aucune proposition pour sortir de cette situation.
Qui nous sommes, où nous sommes et quels problèmes nous avons
Nous faisons maintenant partie de l'équipe Sre Onboarding, qui se compose de six programmeurs et de trois ingénieurs d'infrastructure. Nous essayons tous d'écrire Infrastructure sous forme de code (IaC). Nous le faisons parce que, en principe, nous sommes capables d'écrire du code et dans l'histoire, nous sommes des développeurs du niveau «supérieur à la moyenne».
- Nous avons un ensemble d'avantages: une certaine formation, la connaissance des pratiques, la capacité d'écrire du code, le désir d'apprendre de nouvelles choses.
- Et il y a un fléchissement, c'est aussi un inconvénient: un manque de connaissances sur le matériel d'infrastructure.
La pile technologique que nous utilisons dans notre IaC.- Terraform pour créer des ressources.
- Packer pour assembler des images. Ce sont des images Windows CentOS 7.
- Jsonnet pour faire un build puissant dans drone.io, ainsi que pour générer packer json et nos modules terraform.
- Azure
- Possible pour la cuisson d'images.
- Python pour les services de support ainsi que les scripts de provisioning.
- Et tout cela dans VSCode avec des plugins partagés entre les membres de l'équipe.
La conclusion de mon
dernier article était la suivante: j'ai essayé d'inspirer l'optimisme (principalement en moi-même), je voulais dire que nous allons essayer les approches et les pratiques qui nous sont connues afin de faire face aux difficultés et aux difficultés qui existent dans ce domaine.
Nous sommes maintenant aux prises avec ces problèmes d'IaC:
- Imperfection des outils, outils de développement de code.
- Déploiement lent. L'infrastructure fait partie du monde réel et peut être lente.
- Manque d'approches et de pratiques.
- Nous sommes nouveaux et ne savons pas grand-chose.
Extreme Programming (XP) à la rescousse
Tous les développeurs connaissent la programmation extrême (XP) et les pratiques qui la sous-tendent. Beaucoup d'entre nous ont travaillé sur cette approche et elle a réussi. Alors pourquoi ne pas profiter des principes et pratiques qui y sont énoncés pour surmonter les difficultés des infrastructures? Nous avons décidé d'appliquer cette approche et de voir ce qui se passe.
Vérifier l'applicabilité de l'approche XP à votre domaineJe donne une description de l'environnement pour lequel XP est bien adapté, et comment il se rapporte à nous:
1. Configuration logicielle en constante évolution. Nous avons compris quel était le but ultime. Mais les détails peuvent varier. Nous décidons nous-mêmes où nous devons nous orienter, de sorte que les exigences changent périodiquement (principalement par nous-mêmes). Si vous prenez l'équipe SRE, qui fait elle-même l'automatisation et restreint elle-même les exigences et la portée du travail, alors cet élément va bien.
2. Risques causés par les projets à temps fixe utilisant les nouvelles technologies. Nous pouvons faire face à des risques lors de l'utilisation de choses inconnues. Et c'est à 100% notre cas. Tout notre projet est l'utilisation de technologies que nous ne connaissions pas complètement. En général, c'est un problème constant, car Dans le domaine des infrastructures, de nombreuses nouvelles technologies font constamment leur apparition.
3.4. Petite équipe de développement étendue colocalisée. La technologie que vous utilisez permet des tests unitaires et fonctionnels automatisés. Ces deux points ne nous conviennent pas tout à fait. Premièrement, nous ne sommes pas une équipe, et deuxièmement, nous sommes neuf, ce qui peut être considéré comme une grande équipe. Bien que, selon un certain nombre de définitions d'une «grande» équipe, beaucoup comptent plus de 14 personnes.
Examinons certaines pratiques de XP et comment elles affectent la vitesse et la qualité des commentaires.
Principe de la boucle de rétroaction XP
À mon avis, la rétroaction est la réponse à la question, est-ce que je fais bien, allons-nous là-bas? Dans XP, il y a un petit schéma divin à cet égard: une boucle de rétroaction temporelle. La chose intéressante est que plus nous sommes bas, plus vite nous pouvons obtenir un OS afin de répondre aux questions nécessaires.
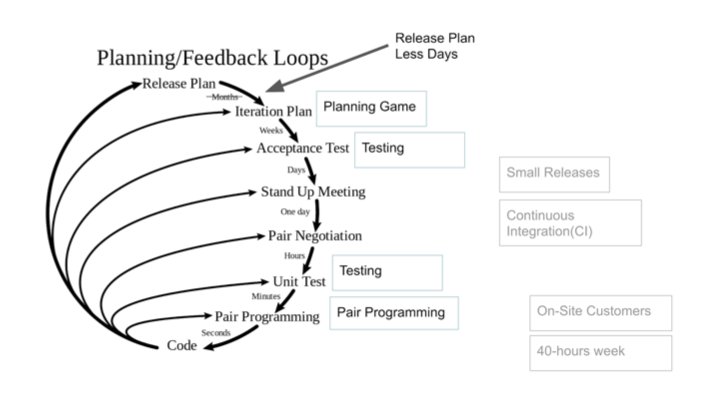
Il s'agit d'un sujet de discussion assez intéressant: dans notre industrie informatique, il est possible d'obtenir rapidement un système d'exploitation. Imaginez à quel point il est
douloureux de faire un projet pendant six mois et découvrez ensuite qu'une erreur a été commise au tout début. Cela se produit dans la conception et dans toute construction de systèmes complexes.
Dans notre cas, l'IaC nous aide à nous faire part de nos commentaires. Immédiatement, je fais un petit ajustement au schéma ci-dessus: nous n'avons pas de plan de sortie mensuel, mais cela arrive plusieurs fois par jour. Certaines pratiques sont liées à ce cycle de système d'exploitation, que nous examinerons plus en détail.
Important: la rétroaction peut être la solution à tous les problèmes mentionnés ci-dessus. Avec les pratiques XP, il peut tirer le désespoir de l'abîme.
Sortir de l'abîme du désespoir: trois pratiques
Les tests
Les tests sont mentionnés deux fois dans la boucle de rétroaction XP. Ce n'est pas seulement ça. Ils sont extrêmement importants pour toutes les techniques de programmation extrêmes.
On suppose que vous avez des tests unitaires et d'acceptation. Certains vous donnent un retour en quelques minutes, d'autres en quelques jours, car ils sont écrits plus longtemps et s'exécutent moins souvent.
Il existe une pyramide de tests classique, qui montre qu'il devrait y avoir plus de tests.
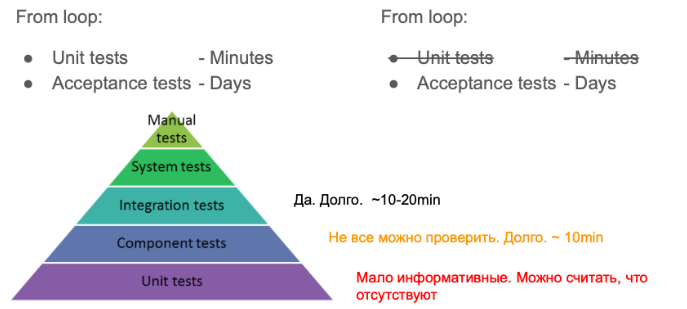
Comment ce schéma s'applique-t-il à nous dans un projet IaC? En fait ... rien.
- Les tests unitaires, malgré le fait qu'ils devraient être nombreux, ne peuvent pas être très nombreux. Ou ils testent très indirectement quelque chose. En fait, nous pouvons dire que nous ne les écrivons pas du tout. Mais voici quelques applications pour de tels tests, que nous avons quand même réussi à faire:
- Test du code sur jsonnet. C'est, par exemple, notre assemblage de pipeline dans un drone, ce qui est assez compliqué. Le code jsonnet est bien couvert par les tests.
Nous utilisons ce cadre de test unitaire pour Jsonnet . - Teste les scripts exécutés au démarrage de la ressource. Des scripts en Python, et donc des tests pour eux, peuvent être écrits.
- La vérification de la configuration dans les tests est potentiellement possible, mais nous ne le faisons pas. Il est également possible de configurer la vérification des règles de configuration des ressources via tflint . Cependant, juste pour terraform, il existe des vérifications trop basiques, mais de nombreux scripts de test sont écrits pour AWS. Et nous sommes sur Azure, donc cela ne convient plus.
- Tests d'intégration de composants: cela dépend de la façon dont vous les classifiez et de l'endroit où vous les placez. Mais ils fonctionnent essentiellement.
Voici à quoi ressemblent les tests d'intégration.
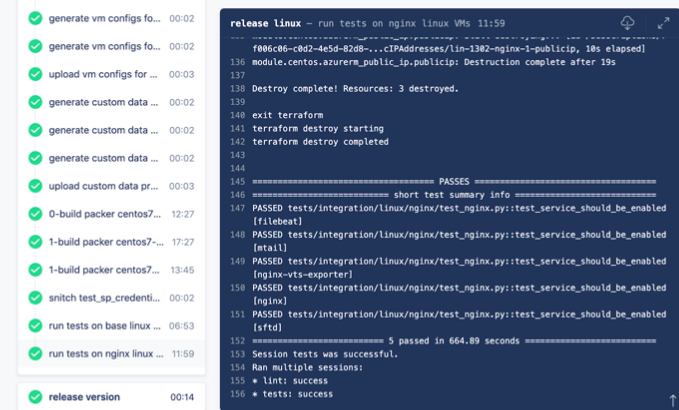
Ceci est un exemple lors de l'assemblage d'images dans Drone CI. Pour les atteindre, vous devez attendre 30 minutes que l'image Packer se rassemble, puis attendre encore 15 minutes pour qu'elles passent. Mais ils le sont!
Algorithme de validation d'image- Tout d'abord, Packer doit préparer l'image complètement.
- À côté du test, il y a une terraforme avec un état local, avec laquelle nous déployons cette image.
- Lors du déploiement, un petit module est utilisé à côté de lui afin qu'il soit plus facile de travailler avec l'image.
- Lorsque la machine virtuelle est déployée à partir de l'image, vous pouvez commencer la vérification. La plupart du temps, les contrôles sont effectués en voiture. Il vérifie le fonctionnement des scripts au démarrage, le fonctionnement des démons. Pour ce faire, via ssh ou winrm, nous allons sur la machine qui vient d'être levée et vérifions l'état de la configuration ou si les services ont augmenté.
- Une situation similaire avec des tests d'intégration et des modules pour terraform. Voici un bref tableau expliquant les caractéristiques de ces tests.
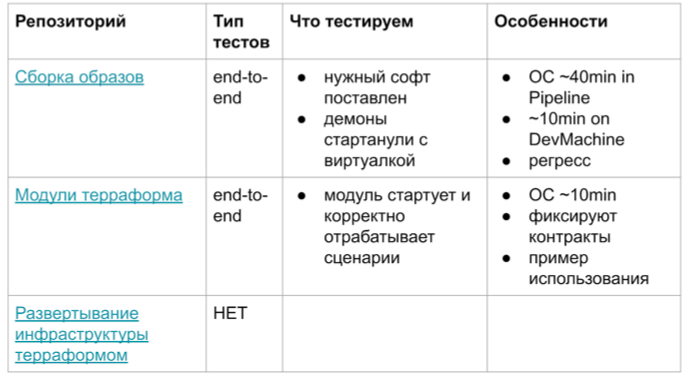
Retour d'information sur le pipeline dans un délai de 40 minutes. Tout prend très longtemps. Il peut être utilisé pour la régression, mais pour un nouveau développement, il est généralement irréaliste. Si vous vous y préparez vraiment, préparez des scripts en cours d'exécution, vous pouvez le réduire à 10 minutes. Mais ce n'est toujours pas des tests unitaires, qui sont 100 pièces en 5 secondes.
L'absence de tests unitaires lors de l'assemblage d'images ou de modules de la terraform encourage à déplacer le travail vers des services séparés qui peuvent simplement être extraits par REST, ou vers des scripts Python.
Par exemple, nous devions faire en sorte que lorsque la machine virtuelle
démarre , elle s'enregistre dans le service
ScaleFT , et lorsqu'elle est détruite, elle se supprime.
Étant donné que ScaleFT est un service, nous sommes obligés de travailler avec lui via l'API. Il a été écrit un wrapper que vous pouvez tirer et dire: "Entrez et supprimez ceci, cela." Il stocke tous les paramètres et accès nécessaires.
Nous pouvons déjà écrire des tests normaux pour cela, car il ne diffère en rien des logiciels ordinaires: certains apiha sont mouillés, vous tirez dessus et regardez ce qui se passe.
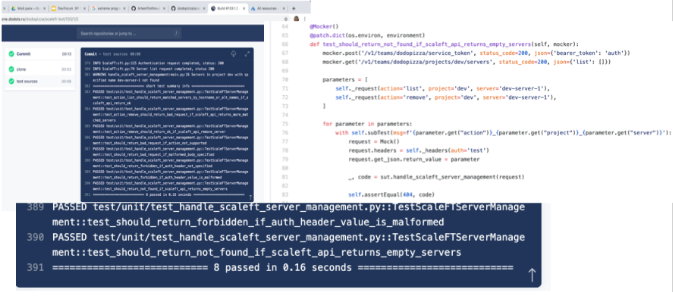
Résultats des tests: les tests unitaires, qui devraient donner le système d'exploitation en une minute, ne le donnent pas. Et des types de tests plus élevés dans la pyramide donnent un effet, mais seulement une partie des problèmes sont couverts.
Programmation par paire
Les tests sont bien sûr bons. Vous pouvez en écrire beaucoup, ils peuvent être de différents types. Ils travailleront à leurs niveaux et nous feront part de leurs commentaires. Mais le problème des tests unitaires médiocres, qui donnent le système d'exploitation le plus rapide, demeure. En même temps, il continue de vouloir un OS rapide, il est facile et agréable de travailler avec. Sans parler de la qualité de la solution. Heureusement, il existe des techniques pour donner une rétroaction encore plus rapide que les tests unitaires. Il s'agit de la programmation par paires.
Lors de l'écriture de code, je souhaite obtenir un retour sur sa qualité le plus rapidement possible. Oui, vous pouvez tout écrire dans la branche des fonctionnalités (afin de ne rien casser à personne), faire une demande d'extraction dans le github, l'assigner à quelqu'un dont l'opinion a du poids et attendre une réponse.
Mais vous pouvez attendre longtemps. Les gens sont tous occupés et la réponse, même si elle l'est, n'est peut-être pas de la plus haute qualité. Supposons que la réponse vienne tout de suite, le réviseur a instantanément compris toute l'idée, mais la réponse vient toujours tardivement, après coup. Mais je veux quelque chose plus tôt. Voici la programmation par paire et vise à cela - de sorte que immédiatement, au moment de l'écriture.
Voici les styles de programmation de paire et leur applicabilité dans le travail sur IaC:
1. Changement de minuterie classique, expérimenté + expérimenté. Deux rôles - conducteur et navigateur. Deux personnes. Ils travaillent sur un code et changent de rôle après une certaine période de temps prédéterminée.
Considérez la compatibilité de nos problèmes avec le style:
- Problème: imperfection des outils, outils de développement de code.
Impact négatif: pour se développer plus longtemps, on ralentit, le rythme / rythme de travail s'égare.
Comment se battre: nous utilisons un autre réglage, un IDE commun et nous apprenons toujours des raccourcis. - Problème: déploiement lent.
Impact négatif: augmente le temps de création d'un code de travail. Nous manquons en attendant, les mains sont tirées pour faire autre chose pendant que vous attendez.
Comment se battre: n'a pas vaincu. - Problème: manque d'approches et de pratiques.
Effet négatif: on ne sait pas comment faire le bien, mais à quel point. Prolonge la rétroaction.
Comment lutter: l'échange d'opinions et de pratiques de jumelage résout presque le problème.
Le principal problème avec l'application de ce style à l'IaC à un rythme inégal. Dans le développement logiciel traditionnel, vous avez un mouvement très uniforme. Vous pouvez passer cinq minutes et écrire N. Passer 10 minutes et écrire 2N, 15 minutes - 3N. Ici, vous pouvez passer cinq minutes et écrire N, puis passer encore 30 minutes et écrire un dixième de N. Ici, vous ne savez rien, vous avez un bâillon, un abruti. L'essai prend du temps et distrait de la programmation elle-même.
Conclusion: dans sa forme pure ne nous convient pas.
2. Ping-pong. Cette approche suppose qu'un participant rédige un test et que l'autre effectue une implémentation pour lui. Étant donné que tout est compliqué avec les tests unitaires et que vous devez écrire un long test d'intégration, toute la facilité du ping-pong disparaît.
Je peux dire que nous avons essayé de séparer les responsabilités pour la conception d'un script de test et l'implémentation du code correspondant. Un participant est venu avec un script, dans cette partie du travail dont il était responsable, il avait le dernier mot. Et l'autre était responsable de la mise en œuvre. Cela a bien fonctionné. La qualité du scénario avec cette approche augmente.
Conclusion: hélas, le rythme de travail ne permet pas l'utilisation du ping-pong, comme la pratique de la programmation en binôme en IaC.
3. Style fort. Pratique difficile . L'idée est qu'un participant devienne un navigateur d'annuaire, et le second joue le rôle d'un pilote d'exécution. Dans ce cas, le droit de prendre des décisions exclusivement avec le navigateur. Le pilote imprime uniquement et en un mot peut affecter ce qui se passe. Les rôles ne changent pas longtemps.
Bien adapté à la formation, mais nécessite de solides compétences générales. Sur ce, nous avons vacillé. La technique était difficile. Et le point ici n'est même pas l'infrastructure.
Conclusion: potentiellement il peut être appliqué, nous n'abandonnons pas les tentatives
4. Mobbing, essaimage et tous les styles connus mais non répertoriés ici ne
sont pas pris en compte, car n'a pas essayé de dire à ce sujet dans le cadre de notre travail ne fonctionnera pas.
Résultats généraux sur l'utilisation de la programmation par paires:
- Nous avons un rythme de travail inégal, ce qui renverse.
- Nous avons rencontré des compétences générales insuffisamment bonnes. Et le sujet ne contribue pas à surmonter ces lacunes.
- De longs tests, des problèmes avec les outils rendent le développement des paires visqueux.
5. Malgré cela, il y a eu des succès. Nous avons trouvé notre propre méthode de convergence - divergence. Je vais décrire brièvement comment cela fonctionne.
Nous avons des partenaires réguliers depuis plusieurs jours (moins d'une semaine). Nous faisons une tâche ensemble. Pendant un moment, nous nous asseyons ensemble: l'un écrit, le second s'assoit et regarde l'équipe de soutien. Ensuite, nous sommes en désaccord pendant un certain temps, tout le monde fait des choses indépendantes, puis nous convergeons à nouveau, nous synchronisons très rapidement, faisons quelque chose ensemble et divergent encore.
Planification et communication
Le dernier bloc de pratiques permettant de résoudre les problèmes de système d'exploitation est l'organisation du travail avec les tâches elles-mêmes. Cela comprend également l'échange d'expériences, qui est en dehors du travail en binôme. Considérez trois pratiques:
1. Tâches dans l'arbre des objectifs. Nous avons organisé la gestion générale du projet à travers un arbre qui va sans cesse vers le futur. Techniquement, le plomb se fait chez Miro. Il y a une tâche - c'est un objectif intermédiaire. Soit des objectifs plus petits, soit des groupes de tâches en découlent. D'eux découlent les tâches elles-mêmes. Toutes les tâches sont créées et exécutées sur ce tableau.
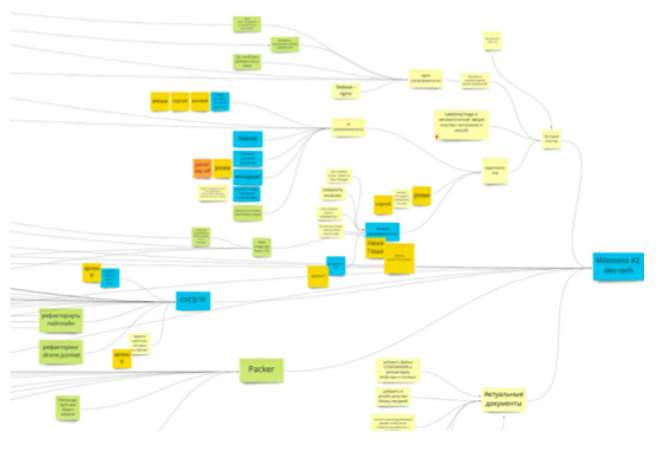
Ce schéma fournit également des commentaires qui se produisent une fois par jour lorsque nous nous synchronisons lors des rallyes. La présence devant tout le monde d'un plan commun, bien que structuré et totalement ouvert, permet à chacun de se tenir au courant de ce qui se passe et des progrès que nous avons réalisés.
Avantages de la vision visuelle des tâches:
- Causalité. Chaque tâche mène à un objectif global. Les tâches sont regroupées en objectifs plus petits. Le domaine de l'infrastructure lui-même est assez technique. Il n'est pas toujours clair immédiatement quel impact spécifique sur l'entreprise est exercé, par exemple, en écrivant un classement sur la migration vers un autre nginx. La présence d'une carte cible à proximité rend cela plus clair.
La causalité est une propriété importante des tâches. Cela répond directement à la question: "Est-ce que je le fais?" - Parallélisme. Nous sommes neuf, et il est impossible d'attaquer tout le monde avec une seule tâche simplement physiquement. Les tâches d'un domaine peuvent également ne pas toujours suffire. Nous sommes obligés de travailler en parallèle entre de petits groupes de travail. En même temps, les groupes assument leur tâche pendant un certain temps, ils peuvent être renforcés par quelqu'un d'autre. Les gens tombent parfois de ce groupe de travail. Quelqu'un part en vacances, quelqu'un fait un rapport pour la conférence de conférence DevOps, quelqu'un écrit un article sur Habr. Il est très important de savoir quels buts et objectifs peuvent être réalisés en parallèle.
2. Présentateurs changeants des rassemblements du matin. Au stand-up, nous avons eu un tel problème - les gens font de nombreuses tâches en parallèle. Parfois, les tâches sont mal couplées et on ne sait pas qui fait quoi. Et l'avis d'un autre membre de l'équipe est très important. Il s'agit d'informations supplémentaires qui peuvent changer le cours de la résolution d'un problème. Bien sûr, généralement quelqu'un est jumelé avec vous, mais la consultation et les conseils ne sont toujours pas superflus.
Pour améliorer cette situation, nous avons appliqué la technique de «Changer le stand-up leader». Maintenant, ils tournent sur une liste spécifique, et cela a son effet. En ce qui vous concerne, vous êtes obligé de plonger et de comprendre ce qui se passe pour bien mener une mêlée de mêlée.
 3. Démo interne.
3. Démo interne. L'aide à la résolution des problèmes de la programmation par paires, la visualisation sur l'arbre des tâches et l'aide aux rallyes de mêlée le matin sont bonnes, mais pas parfaites. Dans un couple, vous n'êtes limité que par vos connaissances. L'arborescence des tâches vous aide à comprendre globalement qui fait quoi. Et l'hôte et les collègues de la réunion du matin ne plongeront pas profondément dans vos problèmes. Ils peuvent certainement manquer quelque chose.
La solution a été trouvée en démontrant le travail effectué les uns aux autres et leur discussion ultérieure. Nous nous réunissons une fois par semaine pendant une heure et montrons les détails des solutions aux tâches que nous avons faites au cours de la semaine dernière.
Dans le processus de démonstration, il est nécessaire de révéler les détails de la tâche et assurez-vous de démontrer son travail.
Le rapport peut être conservé sur la liste de contrôle.1. Entrez dans le contexte. D'où vient la tâche, pourquoi était-elle nécessaire?
2. Comment le problème a-t-il été résolu auparavant? Par exemple, des clics de souris massifs étaient nécessaires, ou il était généralement impossible de faire quoi que ce soit.
3. Comment nous l'améliorons. Par exemple: "Regardez, maintenant il y a un scriptosik, voici un readme."
4. Montrez comment cela fonctionne. Il est conseillé d'implémenter directement n'importe quel script utilisateur. Je veux X, fais Y, vois Y (ou Z). Par exemple, déployez NGINX, URL de fumée, j'obtiens 200 OK. Si l'action est longue, préparez-vous à l'avance pour la montrer plus tard. Il est conseillé de ne pas se séparer surtout s'il est fragile une heure avant la démo.
5. Expliquez dans quelle mesure le problème a été résolu, quelles difficultés sont restées, ce qui n'a pas été achevé, quelles améliorations sont possibles à l'avenir. Par exemple, maintenant cli, il y aura alors une automatisation complète dans CI.
Il est conseillé à chaque intervenant de rester dans les 5 à 10 minutes. Si votre performance est évidemment importante et prend plus de temps, coordonnez-la à l'avance dans le canal de reprise.
Après la partie à temps plein, il y a une discussion dans le fil. C'est là que le feedback nécessaire sur nos tâches apparaît.

En conséquence, une enquête est menée pour identifier l'utilité de ce qui se passe. Il s'agit déjà d'un retour sur l'essence du discours et l'importance de la tâche.

Longues conclusions et prochaines étapes
Il peut sembler que le ton de l'article est quelque peu pessimiste. Ce n'est pas le cas. Deux niveaux de rétroaction à la base, à savoir les tests et la programmation par paires, fonctionnent. Pas aussi parfait que dans le développement traditionnel, mais cela a un effet positif.
Les tests, dans leur forme actuelle, ne fournissent qu'une couverture partielle du code. De nombreuses fonctions de configuration ne sont pas testées. Leur influence sur le travail direct lors de l'écriture de code est faible. Cependant, il y a un effet des tests d'intégration, et ce sont eux qui permettent de faire des refactorings sans crainte. C'est une grande réussite. De plus, avec le transfert de l'attention au développement dans les langages de haut niveau (nous avons python, allez), le problème disparaît. Mais il y a beaucoup de contrôles sur la «colle» et il n'y a pas besoin d'une intégration suffisamment générale.
Le travail en binôme dépend davantage de personnes spécifiques. Il y a un facteur de tâche et nos compétences générales. Ça se passe très bien avec quelqu'un, pire avec quelqu'un. Il y a certainement un avantage à cela. Il est clair que même avec un respect insuffisant des règles du travail en binôme, le fait de l'exécution conjointe de tâches affecte positivement la qualité du résultat. Personnellement, c’est plus facile et plus agréable pour moi de travailler ensemble.
Des façons plus élevées d'influencer l'OS - planifier et travailler avec des tâches donnent précisément les effets: un échange de connaissances de haute qualité et une amélioration de la qualité du développement.
Conclusions courtes en une ligne
- Les pratiques XP fonctionnent dans l'IaC, mais avec moins d'efficacité.
- Renforcez ce qui fonctionne.
- Concevez vos propres mécanismes et pratiques compensatoires.