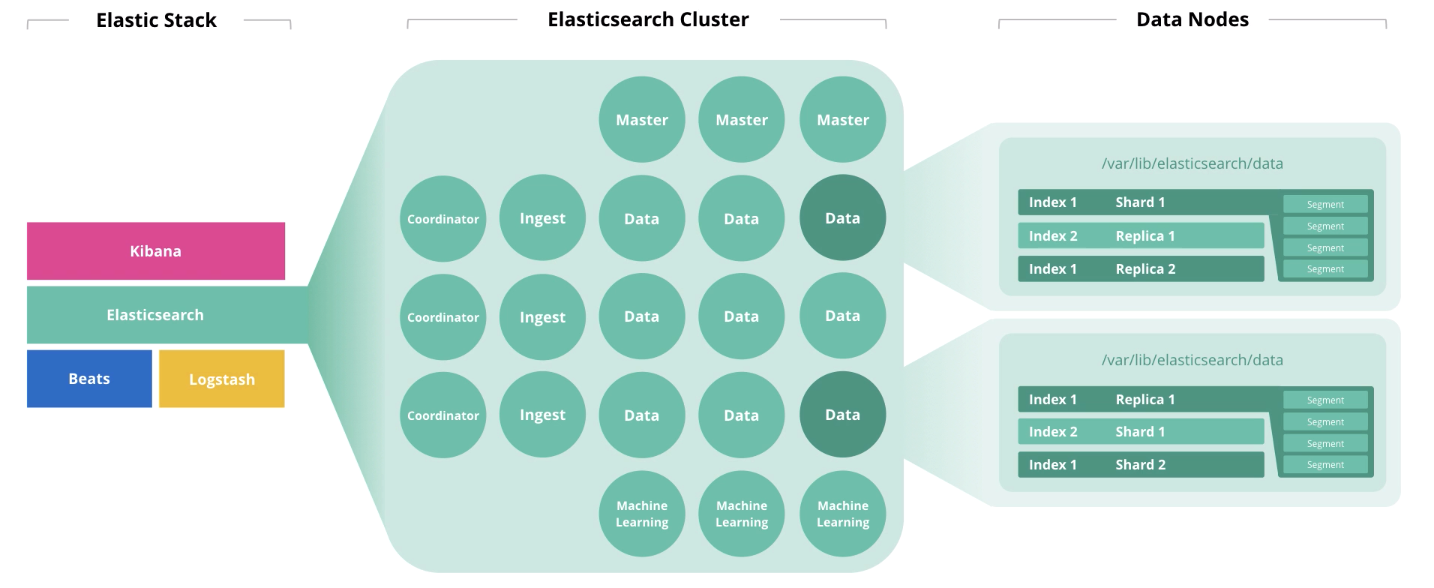
- Quelle est la taille d'un cluster dont j'ai besoin?
- Eh bien, ça dépend ... (gloussement de colère)
Elasticsearch est le cœur de la pile élastique, dans laquelle se déroule toute la magie des documents: émission, réception, traitement et stockage. Les performances dépendent du nombre correct de nœuds et de l'architecture de la solution. Et le prix, d'ailleurs, aussi, si votre abonnement est Gold ou Platinum.
Les principales caractéristiques du matériel sont le disque (stockage), la mémoire (mémoire), les processeurs (calcul) et le réseau (réseau). Chacun de ces composants est responsable de l'action qu'Elasticsearch effectue sur les documents, qui sont respectivement le stockage, la lecture, le calcul et la réception / transmission. Parlons des principes généraux du dimensionnement et révélons le «ça dépend». Et à la fin de l'article, vous trouverez des liens vers des webinaires et des articles connexes. C'est parti!
Cet article est basé sur
le dimensionnement et la planification de la capacité du webinaire de David Moore . Nous avons complété son raisonnement par des liens et des commentaires pour le rendre un peu plus clair. À la fin de l'article, une piste bonus est des liens vers des matériaux élastiques pour ceux qui veulent mieux se plonger dans le sujet. Si vous avez une bonne expérience avec Elasticsearch, veuillez partager dans les commentaires comment concevoir un cluster. Nous et tous nos collègues aimerions connaître votre opinion.
Architecture et opérations d'Elasticsearch
Au début de l'article, nous avons parlé de 4 composants qui forment le matériel: disque, mémoire, processeurs et réseau. Le rôle d'un nœud affecte l'élimination de chacun de ces composants. Un nœud peut jouer plusieurs rôles à la fois, mais avec la croissance du cluster, ces rôles doivent être répartis sur différents nœuds.
Les nœuds maîtres surveillent la santé du cluster dans son ensemble. Dans le travail du nœud maître, un quorum doit être observé, c'est-à-dire leur nombre devrait être impair (peut-être 1, mais mieux 3).
Les nœuds de données exécutent des fonctions de stockage. Pour augmenter les performances du cluster, les nœuds doivent être divisés en
«chaud», «chaud» et «froid» (figé) . Les premiers sont pour l'accès en ligne, le second pour le stockage et le troisième pour l'archivage. En conséquence, pour "chaud", il est raisonnable d'utiliser des disques SSD locaux, et pour les disques durs "chauds" et "froids", il convient localement ou en SAN.
Pour déterminer la capacité de stockage des nœuds pour le stockage, Elastic recommande d'utiliser la logique suivante: «chaud» → 1:30 (30 Go d'espace disque par gigaoctet de mémoire), «chaud» → 1: 100, «froid» → 1: 500). Sous le
tas JVM, pas plus de 50% de la mémoire totale et pas plus de 30 Go pour éviter le raid du ramasse-miettes. La mémoire restante sera utilisée comme cache du système d'exploitation.
Les indicateurs de performances des instances Elastisearch tels que les
pools de threads et les files d'attente de threads sont plus affectés par l'
utilisation du cœur du processeur. Les premiers sont formés sur la base des actions que le nœud effectue: rechercher, analyser, écrire et autres. Les seconds sont la file d'attente des requêtes correspondantes de différents types. Le nombre de processeurs Elasticsearch disponibles à utiliser est déterminé automatiquement, mais vous pouvez spécifier cette valeur manuellement dans les paramètres (cela peut être utile lorsque deux instances Elasticsearch ou plus s'exécutent sur le même hôte). Le nombre maximal de pools de threads et de files d'attente de threads de chaque type peut être défini dans les paramètres. La métrique des pools de threads est la métrique de performances principale pour Elasticsearch.
Les nœuds d'ingestion prennent les données des collecteurs (Logstash, Beats, etc.), effectuent des conversions sur eux et écrivent dans l'index cible.
Les nœuds d'apprentissage automatique sont destinés à l'analyse des données. Comme nous l'avons écrit dans un
article sur l'apprentissage automatique dans Elastic Stack , le mécanisme est écrit en C ++ et fonctionne en dehors de la JVM, qui exécute Elasticsearch lui-même, il est donc raisonnable d'effectuer de telles analyses sur un nœud distinct.
Les nœuds coordinateurs acceptent une demande de recherche et l'acheminent. La présence de ce type de nœud accélère le traitement des requêtes de recherche.
Si nous considérons la charge sur les nœuds en termes de capacités d'infrastructure, la distribution sera quelque chose comme ceci:
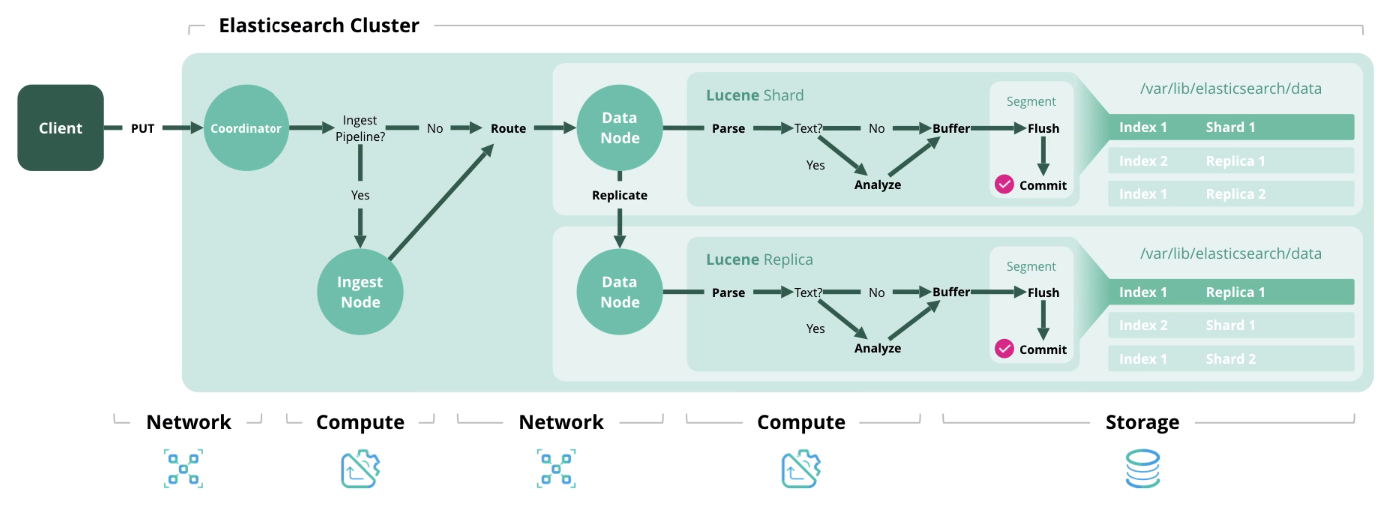
Ensuite, nous présentons 4 principaux types d'opérations dans Elasticsearch, chacune nécessitant un certain type de ressource.
Index - traitement et enregistrement d'un document dans l'index. Le diagramme ci-dessous montre les ressources utilisées à chaque étape.
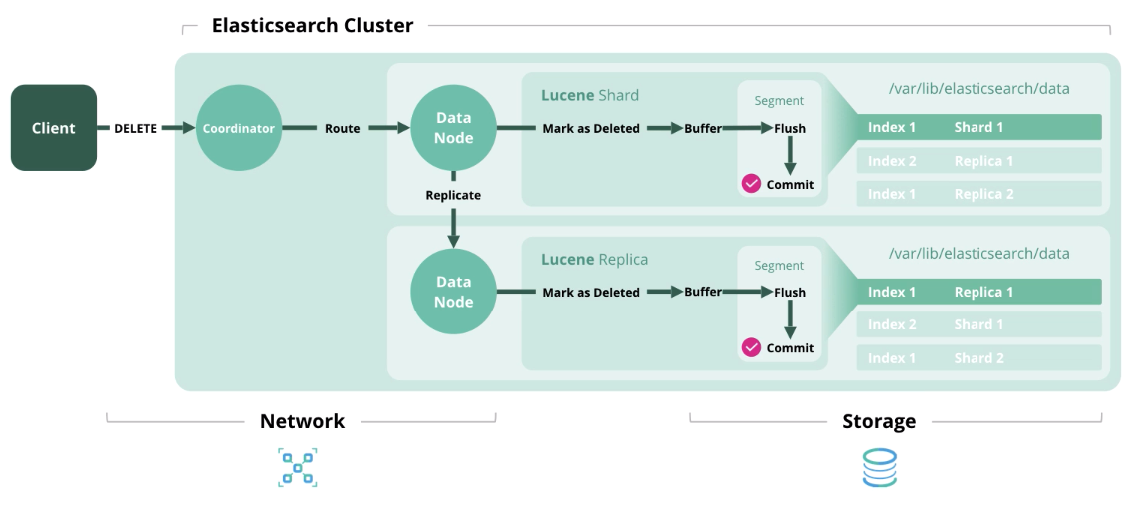
 Supprimer
Supprimer - supprimer un document de l'index.
 Mise à jour
Mise à jour - Fonctionne comme Index et Supprimer, car les documents dans Elasticsearch sont immuables.
Recherche - obtenir un ou plusieurs documents ou leur agrégation à partir d'un ou plusieurs index.
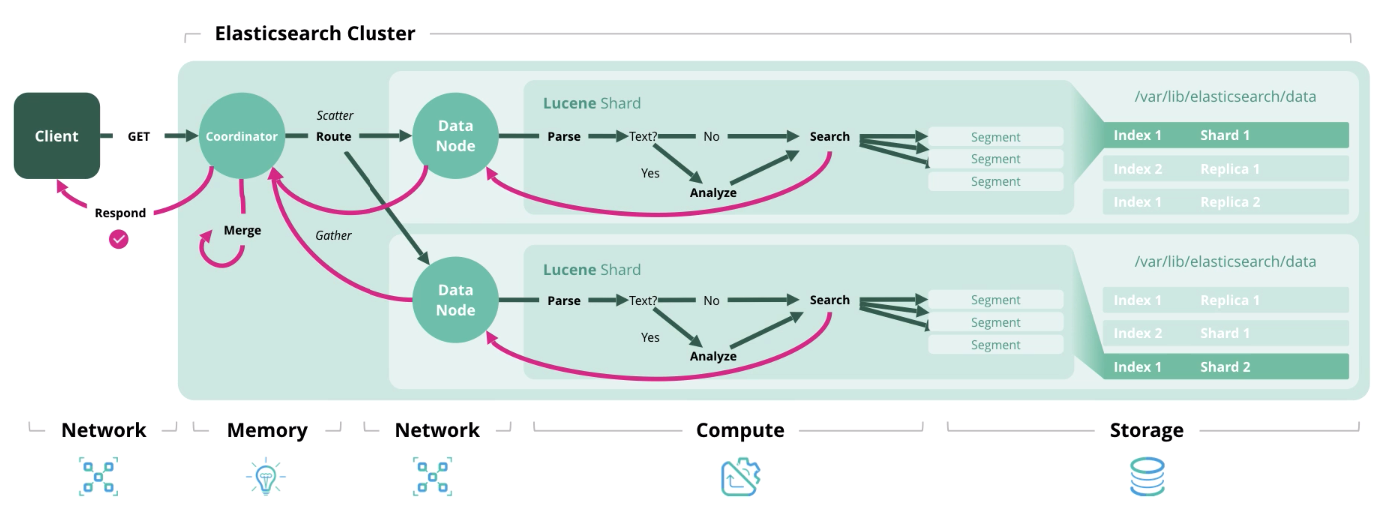
Nous avons compris l'architecture et les types de charges, passons maintenant à la formation d'un modèle de dimensionnement.
Dimensionnement d'Elasticsearch et questions avant sa formation
Elastic recommande d'utiliser deux stratégies de dimensionnement: orientée stockage et débit. Dans le premier cas, les ressources disque et la mémoire sont d'une importance primordiale, et dans le second cas, la mémoire, la puissance du processeur et le réseau.
Dimensionnement de l'architecture Elasticsearch en fonction de la taille du stockage
Avant les calculs, nous obtenons les données initiales. Besoin:
- La quantité de données brutes par jour;
- La période de stockage des données en jours;
- Facteur de transformation des données (facteur json + facteur d'indexation + facteur de compression);
- Nombre de réplications de fragments;
- La quantité de nœuds de données de mémoire;
- Le rapport mémoire / données (1:30, 1: 100, etc.).
Malheureusement, le facteur de transformation des données n'est calculé qu'empiriquement et dépend de diverses choses: le format des données brutes, le nombre de champs dans les documents, etc. Pour le savoir, vous devez charger une partie des données de test dans l'index. Sur le sujet de ces tests, il y a une
vidéo intéressante de la conférence et une
discussion dans la communauté Elastic . En général, vous pouvez le laisser égal à 1.
Par défaut,
Elasticsearch compresse les données en utilisant l'algorithme LZ4, mais il y a aussi DEFLATE, qui appuie 15% de plus. En général, une compression de 20 à 30% peut être obtenue, mais elle est également calculée empiriquement. Lors du passage à l'algorithme DEFLATE, la charge sur la puissance de calcul augmente.
Il y a encore des recommandations supplémentaires:
- Déposez 15% pour avoir une réserve d'espace disque;
- Engagez 5% pour les besoins supplémentaires;
- Fixez 1 équivalent d'un nœud de données pour assurer une migration rapide.
Passons maintenant aux formules. Il n'y a rien de compliqué ici, et nous pensons qu'il sera intéressant pour vous de vérifier la conformité de votre cluster avec ces recommandations.
Quantité totale de données (Go) = données brutes par jour * nombre de jours de stockage * facteur de transformation des données * (nombre de répliques - 1)
Stockage total des données (Go) = Total des données (Go) * (1 + 0,15 stock + 0,05 besoins supplémentaires)
Nombre total de nœuds = OK (Stockage total de données (Go) / Volume de mémoire par nœud / rapport mémoire / données + 1 équivalent de nœud de données)
Dimensionnement de l'architecture Elasticsearch pour déterminer le nombre de fragments et de nœuds de données en fonction de la taille du stockage
Avant les calculs, nous obtenons les données initiales. Besoin:
- Le nombre de modèles d'index que vous allez créer;
- Le nombre de fragments de base et de répliques;
- Après combien de jours la rotation d'index sera effectuée, le cas échéant;
- Le nombre de jours pour stocker les indices;
- La quantité de mémoire pour chaque nœud.
Il y a encore des recommandations supplémentaires:
- Ne dépassez pas 20 fragments par segment JVM de 1 Go sur chaque nœud;
- Ne dépassez pas 40 Go d'espace disque de partition.
Les formules sont les suivantes:
Nombre de fragments = Nombre de modèles d'index * Nombre de fragments principaux * (Nombre de fragments répliqués + 1) * Nombre de jours de stockage
Nombre de nœuds de données = OK (nombre de fragments / (20 * mémoire pour chaque nœud))
Dimensionnement de la bande passante Elasticsearch
Le cas le plus courant lorsqu'une bande passante élevée est nécessaire est fréquent et dans les requêtes de recherche en grand nombre.
Données initiales nécessaires pour le calcul:
- Recherches de pointe par seconde;
- Temps de réponse admissible moyen en millisecondes;
- Nombre de cœurs et de threads par cœur de processeur sur les nœuds de données.
Valeur maximale des threads = OK (nombre maximal de requêtes de recherche par seconde * nombre moyen de temps pour répondre à une requête de recherche en millisecondes / 1000 millisecondes)
Pool de threads de volume = OKRUP ((nombre de cœurs physiques par nœud * nombre de threads par cœur * 3/2) +1)
Nombre de nœuds de données = OK (valeur maximale du thread / volume du pool de threads)
Peut-être que toutes les données initiales ne seront pas entre vos mains lors de la conception de l'architecture, mais après avoir regardé le
webinaire ou lu cet article, une compréhension apparaîtra qui affecte en principe la quantité de ressources matérielles.
Veuillez noter qu'il n'est pas nécessaire d'adhérer à l'architecture donnée (par exemple, créer des nœuds coord coord et des nœuds de gestionnaire). Il suffit de savoir qu'une telle architecture de référence existe et qu'elle peut donner une amélioration des performances que vous ne pourriez pas obtenir par d'autres moyens.
Dans l'un des articles suivants, nous publierons une liste complète des questions auxquelles il faut répondre pour déterminer la taille du cluster.
Pour nous contacter, vous pouvez utiliser des messages personnels sur Habré ou le
formulaire de feedback sur le site .
Matériel supplémentaireWebinaire "Dimensionnement d'Elasticsearch et planification des capacités"Webinaire sur la planification des capacités d'ElasticsearchDiscours à ElasticON sur le thème «Dimensionnement quantitatif des clusters»Webinaire sur l'utilitaire Rally pour déterminer les indicateurs de performance du clusterArticle sur les tailles d'ElasticsearchWebinaire sur la pile élastique