A. A. A. A. A. A. A.
Avez-vous pensé à l'influence du métro le plus proche sur le prix de votre appartement? A.
A. A. Qu'en est-il de plusieurs jardins d'enfants autour de votre appartement? Êtes-vous prêt à plonger dans le monde des données géospatiales?
A. 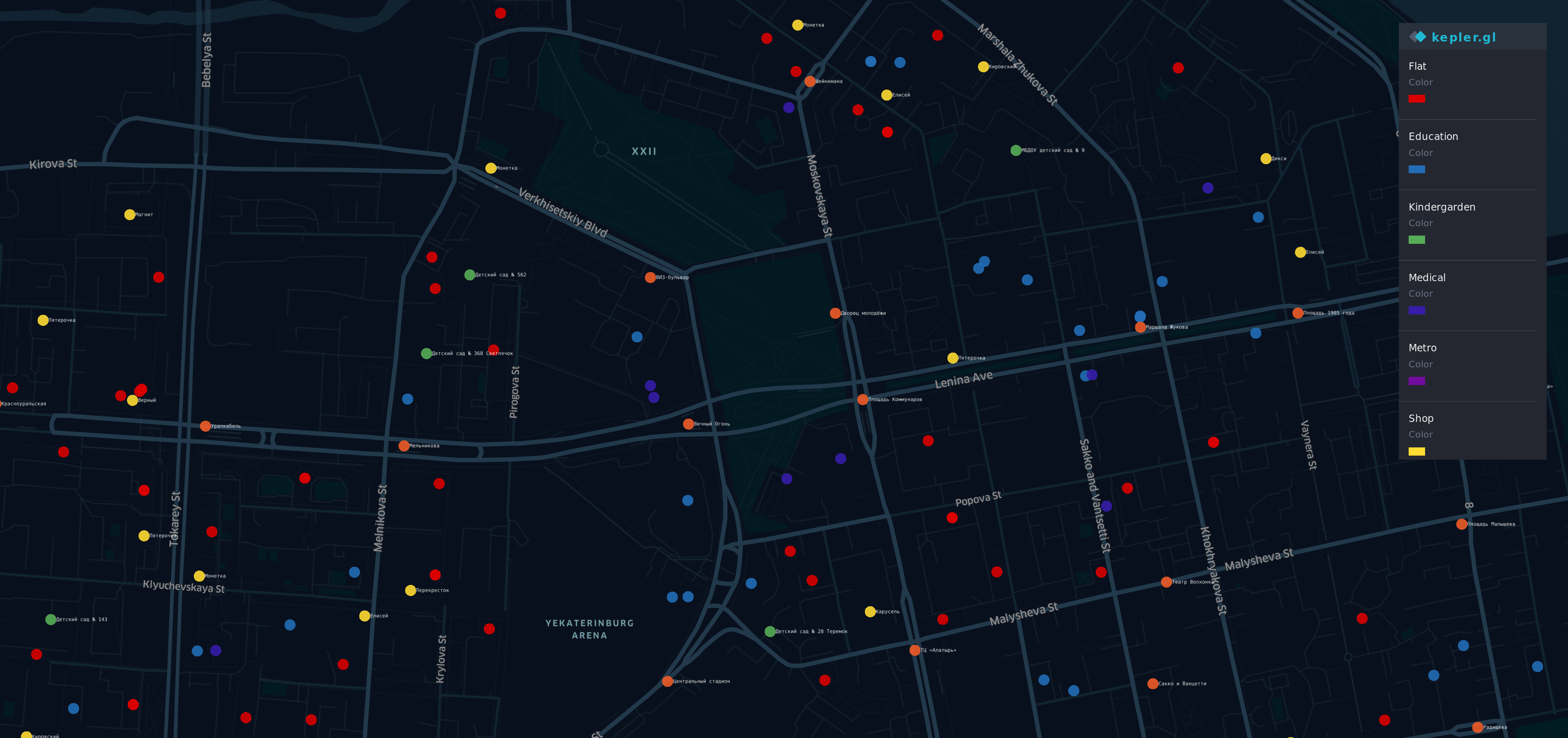 A.
A.
A. A.
A.
De quoi s'agit-il?
A.
Dans la partie précédente , nous avions quelques données et avons essayé de trouver une offre suffisamment bonne sur un marché immobilier à Iekaterinbourg.
Nous étions arrivés à un point où nous avions une précision de validation croisée proche de 73%. Cependant, chaque pièce a 2 faces. Et 73% de précision c'est 27% d'erreur. Comment pourrions-nous réduire cela? Quelle est la prochaine étape?
A.
Les données spatiales viennent en aide
Que diriez-vous d'obtenir plus de données de l'environnement? Nous pouvons utiliser le géo-contexte et certaines données spatiales.
A.
Les gens passent rarement toute leur vie à la maison. A. Parfois, ils vont aux magasins, prennent les enfants à la garderie. Leurs enfants grandissent et vont à l'école, à l'université, etc. A.
Ou ... parfois, ils ont besoin d'une aide médicale et recherchent un hôpital. Et une chose très importante est le transport public, le métro au moins. A. En d'autres termes, il y a beaucoup de choses à proximité, qui ont un impact sur les prix.
Permettez-moi de vous en montrer une liste:
- Arrêts des transports publics
- Boutiques
- Jardins d'enfants
- Hôpitaux / institutions médicales A. A. A. A. A. A. A. A. A.
- Établissements d'enseignement A. A. A. A. A. A. A. A. A.
- Métro
Visualisation des nouvelles données
Après avoir obtenu ces informations de A. Différentes sources A. A. , J'ai fait une visualisation.
A.
A.  A. A. A. A.
A. A. A. A.
Il y a quelques points sur la carte du quartier le plus prestigieux (et le plus cher) de Yek aterinburg. A. A. A. A. A.
A. A.
- A. A. A. A. R ed points - appartements
- O ran ge - arrêts
- Yellow - boutiques
- G reen - jardins d'enfants
- B lue - éducation
- I ndigo - médical
- V iolet - Metro
Oui, un arc-en-ciel est ici.
Présentation
Nous avons maintenant un ensemble de données qui est délimité par des géodonnées et contient de nouvelles informations
df.head(10)

df.describe()

Un bon vieux modèle
Essayez de la même manière qu'avant
y = df.cost X = df.drop(columns=['cost']) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,random_state=42)
Ensuite, nous entraînons à nouveau notre modèle, croisons les doigts et essayons à nouveau de prédire le prix de l'appartement.
from sklearn.linear_model import LinearRegression regressor = LinearRegression() model = regressor.fit(X_train, y_train) do_cross_validation(X_test, y_test, model)

Hmm ... il semble meilleur que le résultat précédent avec 73% de précision.
Qu'en est-il des essais d'interprétation? Notre modèle précédent avait une capacité suffisante pour expliquer le prix forfaitaire.
estimate_model(regressor)

Oups ... Notre nouveau modèle fonctionne bien avec les anciennes fonctionnalités, mais le comportement avec les nouvelles semble étrange.
Par exemple, le plus grand nombre d'établissements d'enseignement ou de médecine entraîne une baisse du prix de l'appartement. En conséquence, le nombre d'arrêts à proximité de l'appartement est une situation identique et il devrait gagner une contribution supplémentaire au prix forfaitaire.
Le nouveau modèle est plus précis, mais il ne correspond pas à la vie réelle.
Quelque chose est cassé
Voyons ce qui s'est passé.
Tout d'abord - je veux vous rappeler que la caractéristique clé de notre régression linéaire est ... euh ... la linéarité. Oui, le capitaine Obvious est ici.
Si vos données sont compatibles avec une idée "Le plus gros / le bail est X, le plus grand / le bail sera Y" - la régression linéaire sera un bon outil. Mais les géodonnées sont plus complexes que prévu.
Par exemple:
- Lorsque près de votre appartement est un arrêt de bus, c'est bien, mais si le nombre d'entre eux est d'environ 5, cela conduit à une rue bruyante et les gens voudraient éviter d'acheter un appartement à proximité.
- S'il y a une université, elle devrait avoir une bonne influence sur le prix,
en même temps, une foule d'étudiants près de chez vous n'est pas si heureuse si vous n'êtes pas une personne très sociable. - Le métro près de chez vous est bien, mais si vous vivez en une heure à pied
du métro le plus proche - cela ne devrait pas avoir de sens.
Comme vous le voyez, cela dépend de nombreux facteurs et points de vue. Et la nature de nos géodonnées n'est pas linéaire, nous ne pouvons en extrapoler l'impact.
Dans le même temps, pourquoi le modèle avec des coefficients bizarres fonctionne-t-il mieux que le précédent?
plot.figure(figsize=(10,10)) corr = df.corr()*100.0 sns.heatmap(corr[['cost']], cmap= sns.diverging_palette(220, 10), center=0, linewidths=1, cbar_kws={"shrink": .7}, annot=True, fmt=".2f")

Ça a l'air intéressant. Nous avons vu l'image similaire dans la partie précédente.
Il existe une corrélation négative entre la distance au métro le plus proche et le prix. Et ce facteur a un impact sur la précision plus que certains anciens.
Pendant ce temps , notre modèle fonctionne mal et ne voit pas les dépendances entre les données agrégées et la variable cible. La simplicité de la régression linéaire a ses propres limites. A.
Le roi est mort, vive le roi!
Et si une régression linéaire ne convient pas à notre cas, quoi de mieux? Si seulement notre modèle pouvait être "plus intelligent" ...
Heureusement, nous avons une approche qui devrait mieux à cause de cela plus ... flexible et a un mécanisme intégré "faire si ça fait autre chose faire ça".
L'arbre de décision apparaît sur la scène.
from sklearn.tree import DecisionTreeRegressor A decision tree can have a different depth, usually, it works well when depth is 3 and bigger. And the parameter of max depth has the biggest influence on the result. Let's do some code for checking depth from 3 to 32 data = [] for x in range(3,32): regressor = DecisionTreeRegressor(max_depth=x,random_state=42) model = regressor.fit(X_train, y_train) accuracy = do_cross_validation(X, y, model) data.append({'max_depth':x,'accuracy':accuracy}) data = pd.DataFrame(data) ax = sns.lineplot(x="max_depth", y="accuracy", data=data) max_result = data.loc[data['accuracy'].idxmax()] ax.set_title(f'Max accuracy-{max_result.accuracy}\nDepth {max_result.max_depth} ')

Eh bien ... pour une situation où le m A. Ax_depth d'un arbre est égal à 8 la précision est supérieure à 77.
Et ce serait une bonne réussite si nous ne réfléchissions pas aux limites de cette approche. Voyons comment cela fonctionnera avec A. A. M ax_depht = 2 A. A. A.
from IPython.core.display import Image, SVG from sklearn.tree import export_graphviz from graphviz import Source 2_level_regressor = DecisionTreeRegressor(max_depth=2, random_state=42) model = 2_level_regressor.fit(X_train, y_train) graph = Source(export_graphviz(model, out_file=None , feature_names=X.columns , filled = True)) SVG(graph.pipe(format='svg'))

Sur cette photo, nous pouvons voir qu'il n'y a que 4 variantes de prédiction. Lorsque vous utilisez DecisionTreeRegressor , cela fonctionne différemment de la régression linéaire . Tout simplement différemment. Il n'utilise pas une contribution de facteurs (coefficients), au lieu de cela que DecisionTreeRegressor utilise la "vraisemblance". Et le prix d'un appartement sera le même que celui le plus similaire prévu.
Nous pouvons le montrer en prédisant notre prix avec cet arbre.
y = two_level_regressor.predict(X_test) errors = pd.DataFrame(data=y,columns=['errors']) f, ax = plot.subplots(figsize=(12, 12)) sns.countplot(x="errors", data=errors)

Et chaque prédiction correspondra à l'une de ces valeurs. Et lorsque nous utilisons max_depth = 8, nous ne pouvons nous attendre à plus de 256 options différentes pour plus de 2000 appartements. C'est peut-être bon pour les problèmes de classification, mais ce n'est pas assez flexible pour notre cas.
Sagesse de la foule
Si vous essayez de prédire le score lors de la finale de la Coupe du monde - il y a de fortes chances que vous vous trompiez. Dans le même temps, si vous demandez l'avis de tous les juges du championnat, vous aurez de meilleures chances de deviner. Si vous demandez à des experts indépendants, des formateurs, des juges, puis faites de la magie avec les réponses - vos chances augmenteront considérablement. On dirait une élection d'un président.
Un ensemble de plusieurs arbres «primitifs» peut donner plus que chacun d'eux. Et rando mForestRegressor est un outil que nous utiliserons
Tout d'abord, considérons les paramètres de base - max_depth , max_features et un certain nombre d'arbres dans le modèle.
A.
Nombre d'arbres
Conformément à "Combien d'arbres dans une forêt aléatoire?" le meilleur choix sera de 128 arbres . Une augmentation supplémentaire du nombre d'arbres n'entraîne pas une amélioration significative de la précision, mais augmente le temps de formation.
Nombre maximal de fonctionnalités
En ce moment, notre modèle a 12 fonctionnalités. La moitié d'entre eux sont des anciens qui sont liés à des fonctionnalités de flat, d'autres liés au géo-contexte. J'ai donc décidé de donner une chance à chacun d'eux. Soit 6 fonctionnalités pour un arbre.
Profondeur maximale d'un arbre
Pour ce paramètre, nous pouvons analyser une courbe d'apprentissage.
from sklearn.ensemble import RandomForestRegressor data = [] for x in range(1,32): regressor = RandomForestRegressor(random_state=42, max_depth=x, n_estimators=128,max_features=6)model = regressor.fit(X_train, y_train)accuracy = do_cross_validation(X, y, model) data.append({'max_depth':x,'accuracy':accuracy}) data = pd.DataFrame(data) f, ax = plot.subplots(figsize=(10, 10)) sns.lineplot(x="max_depth", y="accuracy", data=data) max_result = data.loc[data['accuracy'].idxmax()] ax.set_title(f'Max accuracy-{max_result.accuracy}\nDepth {max_result.max_depth} ')

Whoa ... plus de 86% de précision sur max_depth = 16 contre 77% sur un arbre de conception. Cela a l'air incroyable, n'est-ce pas?
Conclusion
Eh bien ... maintenant, nous avons un meilleur résultat en prévision que les précédents, 86% est près de la ligne d'arrivée. La dernière étape pour vérifier - examinons l'importance des fonctionnalités. Les géodonnées ont-elles profité à notre modèle?
feat_importances = model.feature_importances_ feat_importances = pd.Series(feat_importances, index=X.columns) feat_importances.nlargest(5).plot(kind='barh')

Certaines anciennes fonctionnalités ont encore affecté le résultat. En même temps, la distance par rapport au métro et aux jardins d'enfants les plus proches a également été affectée. Et cela semble logique.
Sans aucun doute, les géodonnées nous ont aidés à améliorer notre modèle.
Merci d'avoir lu!
PS
Notre voyage n'est pas encore terminé. Une précision de 86% est un résultat formidable pour des données réelles. En attendant, voici un petit écart entre 14% et 10% d'erreur moyenne, ce que nous attendons. Dans le prochain chapitre de notre histoire, nous allons essayer de surmonter cette barrière ou au moins de diminuer cette erreur. A. A. A. A. A. A. A. A.
Il y a le cahier IPython