Bonjour à tous! Je m'appelle Lyudmila, je suis engagé dans les tests de charge, je veux partager comment nous avons effectué l'automatisation de l'analyse comparative du profil de régression des tests de charge du système à partir de la base de données sous le SGBD Oracle avec l'un de nos clients.
Le but de l'article n'est pas de découvrir une «nouvelle» approche pour comparer les performances des bases de données, mais de décrire notre expérience et de tenter d'automatiser la comparaison des résultats obtenus et
réduire le nombre d'appels vers DBA Oracle.
En effectuant des tests de charge de n'importe quelle base de données, nous sommes principalement intéressés par:
- Quelque chose s'est-il cassé après l'installation d'un nouvel assemblage?
- La dynamique de la base de données lors du test.
La comparaison des rapports AWR ne suffit pas à elle seule pour atteindre vos objectifs.
Le stockage centralisé des vidages AWR est également une bonne pratique. Les vidages AWR conservent toutes les vues historiques (dba_hist).
Cette pratique a déjà été appliquée par notre client.
Après la prochaine session de test de charge, nous comparons les résultats:
- décharge d'essai actuelle avec décharge industrielle;
- le vidage de test en cours avec le vidage de test précédent.
Pourquoi est-ce nécessaire?
Les objectifs sont différents:
- Parfois, le remplissage de la base elle-même dans un environnement de test diffère de celui opérationnel, ce qui signifie qu'il y aura des différences qui interfèrent avec l'analyse («interférence» pour répondre à la question principale, «avoir quelque chose de cassé?»). Je veux identifier ces différences;
- La comparaison du test actuel avec le travail de la base industrielle permet de comprendre à quel point les tests de résistance actuels sont corrects (quelque part, nous chargeons trop, mais nous avons oublié quelque chose du tout);
- La comparaison du test actuel avec le test précédent permet de comprendre si le comportement actuel du système est normal. Quelque chose a changé dans le comportement du système par rapport au test précédent.
Pour atteindre tous ces objectifs, nous résolvons souvent le problème de la comparaison de différentes décharges entre elles. Les dates sont généralement très serrées quand elles devaient être introduites hier! Le temps pour vérifier complètement chaque test de régression fait cruellement défaut. Et si vous exécutez le test de fiabilité pendant une journée, vous pouvez passer beaucoup de temps à analyser le résultat ...
Bien sûr, vous pouvez tout regarder en ligne dans Enterprise Manager (ou avec des demandes de vues gv $) pendant le test: ne pas fumer, manger et dormir ...

Peut-être avez-vous également votre propre outil personnalisé, fait pour vous? Vous pouvez partager dans les commentaires. Et nous partagerons ce que nous utilisons pour nos tâches.
Les rapports AWR contiennent de nombreuses informations utiles:

Il y a des informations utiles ici, par exemple: la quantité d'exécution de la requête, sql_id, le module et le texte abrégé. Bien que le texte soit là, il est tronqué et la version complète peut être extraite du paragraphe Liste complète du texte SQL.
Quant aux inconvénients: dans le rapport AWR, il n'est pas clair quand ces demandes ont eu lieu, à quel moment il y en avait plus, et à quel moins ... Après tout, analyser les résultats du test, comprendre ce qui s'est passé et à quel moment approximatif est important: uniformément pour l'ensemble test ou pic / surtension comme si sur un calendrier. Nous ne verrons également qu'un sommet limité ici. Cela peut être visualisé plus facilement en interrogeant les tableaux historiques.
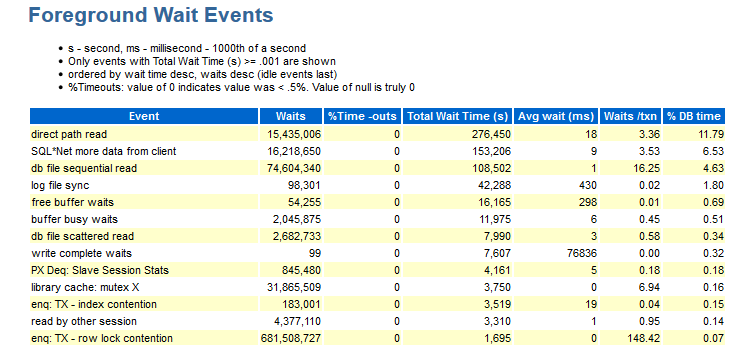
Ici, vous pouvez voir quels événements se sont déroulés pendant le test. Les données de cette section sont classées par heure DB.
Pour moi, dans cette section, les informations suivantes sont manquantes:
- Wait_class (oui, vous vous souvenez avec expérience à quel type d'attentes cet événement appartient).
- Distributions par modules (si je vois, par exemple, attendre enq: TX - conflit de verrouillage de ligne: des informations sont nécessaires, sous quel module cela s'est produit).
Il y a des jobs dans lesquels il y a des nombres qui ne portent pas de partie sémantique, c'est-à-dire que vous devez grouper les mêmes modules et obtenir une réponse pour le groupe, par exemple: module_A_1, module_A_2, module_A_3 et module_B_1, module_ B_2, module_ B_3. Autrement dit, il y avait deux modules sémantiques, mais ils ont tous des noms différents.
- L'objet auquel nous nous référons (CURRENT_OBJ # - si, par exemple, l'événement enq: TX - contention d'index se produit, il serait bien de savoir quel index est à blâmer).
- Sql_id - qui demande le texte de cette demande a tenté de s'exécuter.
- Informations sur la répartition des quantités par instantané (comme décrit ci-dessus ...).
Pour comparer les deux tests, vous pouvez utiliser la comparaison des rapports AWR:
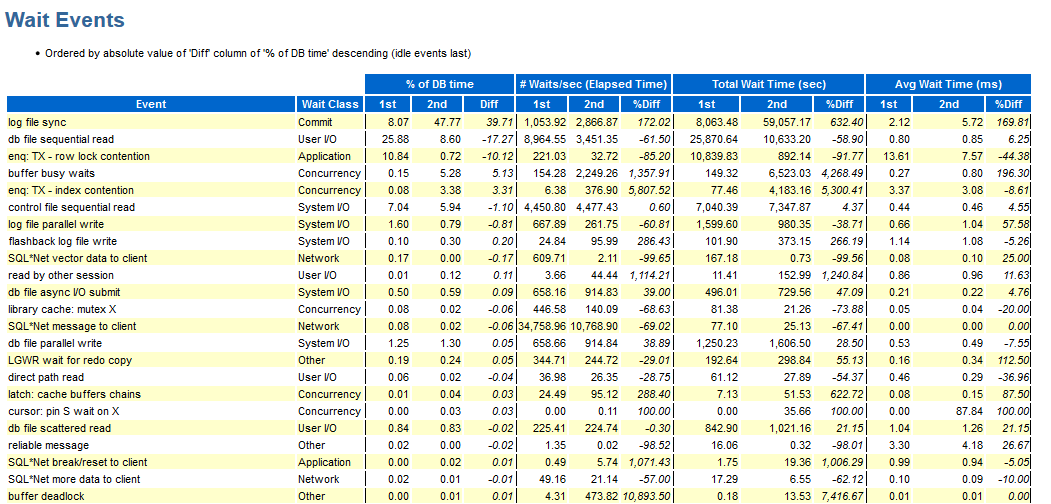
Hourra, nous avons ici wait_class affiché, sinon les inconvénients sont les mêmes que ceux décrits ci-dessus.
Parfois, il n'y a pas d'Enterprise Manager sur les projets et vous pouvez, par exemple, utiliser Enterprise Manager Express ou ASH Viewer. Dans Enterprise Manager, beaucoup utilisent Top Activity pour les données historiques, mais pour moi, beaucoup de choses sont plus faciles à regarder avec les requêtes elles-mêmes. Tout ce qui précède doit être comparé à d'autres tests / charge de travail. Nous avions déjà une comparaison personnalisée en termes d'exécution, mais nous n'avions pas de comparaison personnalisée, et nous avons vérifié manuellement les requêtes sur les tables historiques.
Après chaque test de régression, il était nécessaire de comparer les résultats dans les tableaux historiques avec les requêtes à la base de données, de visualiser les rapports AWR, de localiser l'attente problématique (sur quel module il se produit, à quelle heure, sur quel objet il était accroché), de sorte qu'un résultat pourrait être généré pour la bonne équipe de développement.
La base de données du client a atteint 190 To, un grand nombre de demandes sont traitées dans le système: le nombre de modules parallèles est de 16237.
Et puis j'ai eu une idée de comment simplifier le processus de comparaison des décharges AWR. Avec cette idée, je suis allé voir
Fred . Ensemble, nous avons créé un portail pratique.
Au début, l'énoncé du problème de ma part ressemblait à ceci:

Puis, néanmoins, j'ai décidé de systématiser pour commencer quelles requêtes sur les tableaux historiques que j'utilise le plus souvent ... Fred a commencé à fixer cela au portail, puis cela a commencé ...
Tout d'abord, j'étais intéressé par une comparaison des événements, car une comparaison de la vitesse d'exécution des requêtes sous une certaine forme existait déjà. L'étape suivante, j'avais besoin d'informations détaillées sur chaque événement: par exemple, si l'événement est un conflit d'index, vous devez comprendre à quel index nous nous accrochons.
Ensuite, je me suis intéressé à l'heure à laquelle les moments de ces événements étaient les plus importants, car dans la mise en œuvre, de nombreuses tâches (emplois) étaient programmées et il était nécessaire de comprendre à quel moment tout se fissurait.
En général, voici ce que je voulais obtenir:
- comparaison quantitative des événements entre différents tests (sans squats supplémentaires);
- toutes les informations connexes dont j'ai besoin pour l'analyse: sql_id, texte de la requête, distribution pendant le test, qui objecte les sessions auxquelles il est fait référence, module;
- filtres pratiques pour voir ce qui a changé;
- GUI GUI, tout est si coloré qu'il est immédiatement visible (vous pouvez filtrer les parties intéressées du côté du développement)
- regroupement de modules: comme décrit précédemment, 16237 modules, mais, du point de vue des fonctions exercées, beaucoup moins.
Fred et moi avons créé un portail pratique pour notre utilisation pour comparer les vidages AWR des tests de charge, dont je parlerai plus en détail ci-dessous.
À propos du portail
Ainsi, les vidages AWR sont créés dans le système, qui sont versés dans la base de données et comparés sur le portail.
Nous avons utilisé la pile suivante:
- Oracle DB - pour stocker les vidages AWR
- Python 2+
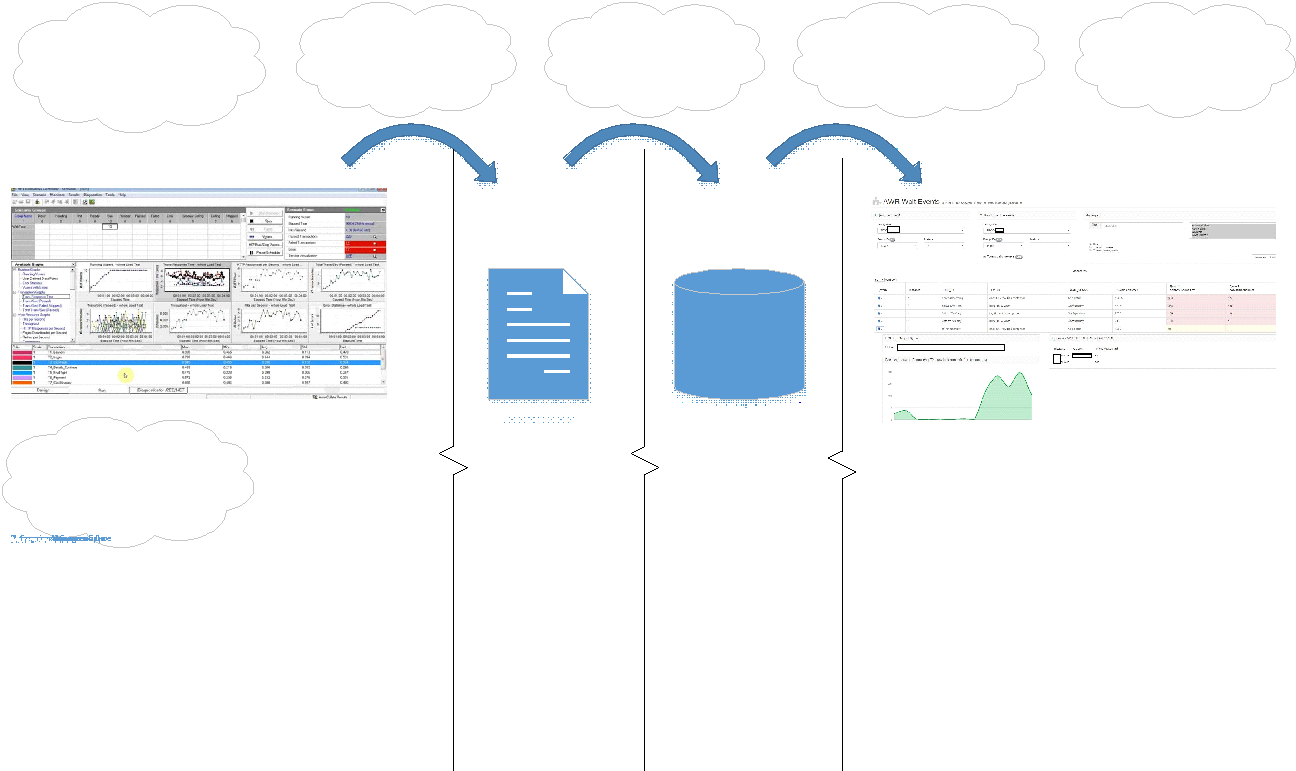
L'interface du portail ressemble à ceci:

Sur le portail, vous pouvez choisir les types de vidages comparés, test test ou test-prom.
Chaque vidage a son propre identifiant unique - DBID.
Vous pouvez également filtrer en fonction des paramètres suivants:
- Instance (instance) - nous avions une base de données de cluster;
- Demande (Sql_id);
- Type d'attente (Wait_Class);
- Événement
En haut à gauche, vous sélectionnez les vidages, et à droite, vous pouvez définir les filtres nécessaires pour sélectionner immédiatement le module souhaité - cela vous permet d'identifier les problèmes dans la fonctionnalité qui a été modifiée / améliorée afin qu'il n'y ait pas de problèmes de dégradation dans la version précédente.
Le tableau du milieu est le résultat de la comparaison des vidages. Les en-têtes de colonne indiquent immédiatement quelles données sont sorties. Les deux colonnes de droite montrent les différences entre les deux vidages:
- les événements surlignés en rouge sont plus que par rapport à un vidage comparatif pour l'instantané;
- jaune - nouveaux événements;
- vert - événements qui étaient déjà dans le vidage d'origine.
Il est immédiatement évident à quel point nous avons testé. Si l'événement s'est produit très souvent, alors très probablement:
- surchargé le système;
- ou les conditions d'exécution des tâches d'arrière-plan ont changé et l'événement a commencé à jouer plus souvent. Une fois de cette façon, une erreur a été trouvée dans le code: l'événement s'est produit en permanence, et non sur la branche de condition souhaitée.
Si nous avons un nouvel événement - jaune - alors cela indique une sorte de changement dans le système, et nous devons analyser ses conséquences. Ici, vous pouvez voir la distribution des événements par des instantanés et afficher des informations détaillées sur l'attente.
Une fois qu'il y avait un cas: un nouvel événement a été découvert, ce qui était assez rare et n'était pas inclus dans les événements les plus importants, mais à cause de cela, il y avait des ralentissements dans le fonctionnel, qui avait des SLA critiques. L'analyse des seules requêtes principales dans le rapport AWR n'a pas pu révéler cela.
Pour chaque demande, vous pouvez obtenir des informations plus détaillées:
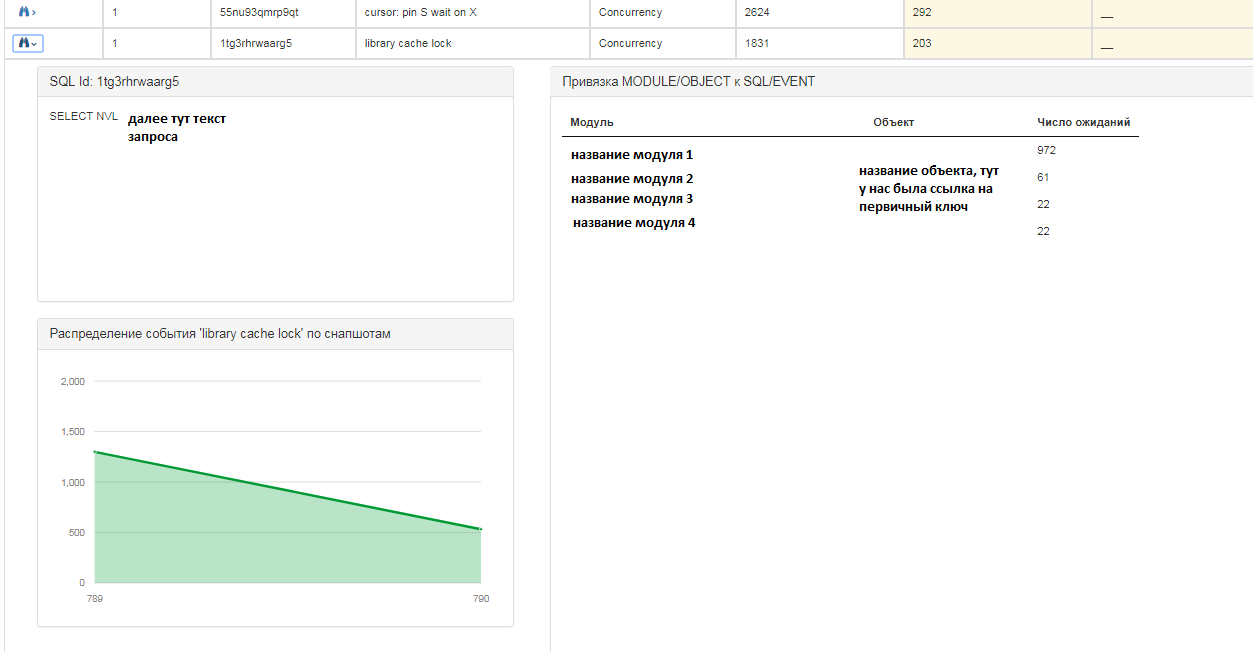
Pour chaque entrée, vous pouvez également voir les informations suivantes:
- requête texte sql;
- la distribution des événements sur un instantané dans un rapport quantitatif, c'est-à-dire à quel moment il y a eu plus / moins d'événements;
- sur quels modules et objets l'attente "suspendue".
Les vues système d'Oracle sont impliquées dans la comparaison des résultats:
DBA_HIST_ACTIVE_SESS_HISTORY, DBA_HIST_SEG_STAT, DBA_HIST_SNAPSHOT, DBA_HIST_SQLTEXT
+
V_DUMPS_LOADED - sa propre table de service (a déjà été implémentée par le client), elle contient des informations sur les vidages chargés.
Quelques requêtes:
Distribution des événements sur photos:
SELECT S.SNAP_ID, COUNT(*) RCOUNT FROM DBA_HIST_ACTIVE_SESS_HISTORY S, V_DUMPS_LOADED V. WHERE V.ID = :1 AND S.DBID = V.DBID AND S.INSTANCE_NUMBER = :2 AND S.SQL_ID = :3 AND S.EVENT_ID = :4 GROUP BY S.SNAP_ID ORDER BY S.SNAP_ID ASC
Regroupement par module (les modules qui sont un seul groupe logique y sont combinés), l'objet étant bloqué:
SELECT MODULE, OBJECT_NAME, COUNT(*) RCOUNT (SELECT CASE (WHEN INSTR(S.MODULE, ' 1')>0 THEN ' 1' WHEN INSTR(S.MODULE, ' 2')>0 THEN ' 2' … ELSE S.MODULE END) MODULE, O.OBJECT_NAME FROM DBA_HIST_ACTIVE_SESS_HISTORY S, V_DUMPS_LOADED V, DBA_HIST_SEG_STAT O WHERE V.ID = :1 AND S.DBID = V.DBID AND S.INSTANCE_NUMBER = :2 AND S.SQL_ID = :3 AND S.EVENT_ID = :4 AND S.CURRENT_OBJ
Qu'avez-vous obtenu à la fin?
Le portail nous a permis de gagner du temps en comparant les vidages AWR. La comparaison manuelle a pris 4 à 6 heures et nous passons maintenant 2 à 3 heures. Nous avons toujours à portée de main l'opportunité de comparer rapidement les résultats de différents tests à la fois entre eux et avec une décharge industrielle, ainsi que de définir les filtres dont nous avons besoin maintenant. Autrement dit, nous pouvons facilement comparer les données historiques entre nous, et pas seulement regarder le résultat actuel en ligne.
Auparavant, après chaque régression, il était nécessaire de comparer les résultats dans les tableaux historiques avec les requêtes à la base de données, de visualiser les rapports AWR, de localiser l'attente problématique (sur quel module il se produit, à quelle heure il s'est produit, sur quel objet il s'est accroché), de sorte qu'au final, cela pourrait conduire à un défaut sur la bonne équipe de développement. Et maintenant, sélectionnez simplement les vidages pour la comparaison, définissez les filtres - et les résultats de la comparaison sont immédiatement prêts. Vous pouvez également envoyer aux développeurs un lien vers le portail indiquant le DBID du vidage de test, et ils seront eux-mêmes filtrés par leur module.
Il n'a fallu que deux semaines pour créer le portail, car une partie de celui-ci était déjà prête: le chargement des vidages dans la base de données. Bien sûr, une telle solution de portail n'est pas nécessaire pour tout projet avec une base Oracle. Il est utile pour les produits divisés en de nombreux modules avec des noms différents. Pour les systèmes simples ou pour les systèmes dans lesquels ils n'ont pas attaché d'importance au remplissage du module, le portail sera redondant.
Étant donné que le portail analyse les images prises une fois au cours d'une certaine période, le portail ne dispense pas complètement de la surveillance en ligne de la base de données, car certains événements peuvent ne pas pouvoir pénétrer dans l'image.
Il s'agit d'un outil pratique pour analyser les données historiques à partir des résultats des tests, mais il peut être utile dans d'autres situations lorsque de nombreuses images sont créées et que de gros volumes de données doivent être vérifiés. Grâce à la combinaison de filtres et de graphiques, vous pouvez immédiatement voir des rafales d'événements qui, dans les rapports AWR normaux (à ne pas confondre avec les vidages), seront masqués dans les informations groupées. Il suffit de sélectionner des vidages pour la comparaison, de définir des filtres - et les résultats de la comparaison sont immédiatement prêts, ou vous pouvez envoyer un lien aux développeurs sur le portail indiquant le DBID du vidage de test, ils seront eux-mêmes filtrés par leur module.
Si vous décidez de développer un portail similaire pour votre projet, sélectionnez l'ensemble de filtres qui vous convient. Si vous filtrez selon des conditions différentes à chaque fois, il sera beaucoup plus facile de faire un filtre approprié pour cela.
La solution résultante peut encore être finalisée, par exemple:
- comparer la durée de la demande;
- comparer les plans de requête;
- comparer les demandes avec le même plan, mais avec un texte différent;
- déchargement dans les rapports de test (exécution en tant que document Word / Exel).
Ou, en général, dites au portail de se connecter à la base de données testée afin qu'il crée des images similaires en ligne en utilisant des vues en mémoire, et pas seulement des données historiques. Et enregistrez-les dans votre base de données.
Nous utilisons le portail depuis plus d'un an. Fred, merci beaucoup!
Publié par Lyudmila Matskus,
Jet Infosystems