Chaque jour, un nombre croissant d'appareils crée plus de données. Ils doivent être gérés en différents points et non dans plusieurs centres de données cloud centralisés. En d'autres termes, le processus de gestion dépasse les frontières des centres de données traditionnels et se déplace vers l'endroit où les données sont créées - à la périphérie du réseau, plus près des utilisateurs finaux. Ici, les données sont générées par divers capteurs, caméras, gadgets et appareils Internet des objets (IoT). Lorsque les résultats de leur travail sont collectés et traités directement aux limites du réseau, ils peuvent être analysés et utilisés beaucoup plus rapidement.

Selon les
experts de Gartner , d'ici 2020, plus de 50% de toutes les données générées par les entreprises seront traitées en dehors des centres de données traditionnels ou de l'environnement cloud (ce chiffre n'est aujourd'hui que de 10%). Dans cette architecture, 5,6 milliards d'appareils Internet des objets (IoT) fonctionneront. Dans le même temps, les volumes de données produites par les appareils sont calculés en téraoctets et doivent souvent être interprétés et analysés en temps réel.
Pour aider les partenaires et les clients à explorer cette tendance, Seagate s'est associé à un consortium d'entreprises spécialisées dans l'informatique périphérique et a publié le rapport
Data at the Edge . Il a également utilisé les résultats d'une
étude menée par IDC. Le rapport avait pour objectif d'illustrer certains des problèmes de données qui concernent les entreprises aujourd'hui et de montrer comment les entreprises gèrent mieux leurs ressources informatiques.
Informatique périphérique
«Les acteurs du marché du stockage ont franchi plusieurs étapes dans le développement de leur entreprise. Il y a quelques décennies, les installations de stockage pour les systèmes de serveurs étaient considérées comme prometteuses, puis les centres de données locaux étaient à l'honneur. Cela s'est reflété dans les gammes de produits des fournisseurs: ils ont commencé à produire des disques pour ce segment. Commence alors le développement du stockage cloud, du cloud computing. La prochaine étape est l’informatique périphérique », explique Alexander Malinin, directeur du bureau de représentation de Seagate en Russie et dans la CEI. - Puisqu'il y a beaucoup de données, et qu'elles sont générées non seulement par des personnes, mais aussi par des machines, envoyer tout cela au centre de données n'est pas toujours optimal. Il est logique de faire partie des calculs en dehors des centres de données et de transférer les résultats traités vers le centre de données. En fait, il s'agit de la création d'un autre circuit de calculs, où les données sont accumulées, stockées pendant un certain temps, traitées et transférées au centre de données principal pour un stockage ultérieur et un accès à ces données.
Alors que des milliards d'appareils continuent de se connecter au réseau, collectant et générant des zettaoctets de données, les environnements cloud centralisés d'aujourd'hui nécessitent la prise en charge d'une nouvelle architecture informatique périphérique. Et en plaçant les ressources informatiques, réseau et de stockage à proximité de ces appareils, vous pouvez analyser les données directement sur place.
Du fait que les données subissent un traitement primaire au même endroit où elles sont créées, une partie des décisions de gestion (par exemple, pour ajuster le mode de fonctionnement des équipements industriels) peut être prise localement, avec un minimum de retard.
La périphérie peut être située n'importe où: des magasins d'usine aux fermes, sur les toits des maisons et sur les tours de téléphonie cellulaire, dans tous les véhicules terrestres, maritimes et aériens. Étant la frontière extérieure d'un réseau, il est souvent situé à des centaines de kilomètres du centre de données d'entreprise ou cloud le plus proche et très proche de la source de données.
Selon une étude IDC, d'ici 2020, 45% de toutes les données générées par les appareils IoT seront stockées et traitées dans ou à proximité des segments frontaliers du réseau. Il existe de nombreux cas où il est préférable de déplacer le processus informatique vers la périphérie. Ainsi, dans les «smart cities», le traitement et l'analyse des données au plus près de leur source réduisent les délais et permettent à différents services de répondre plus rapidement à la situation.
Dans les systèmes de transport intelligents, l'informatique périphérique vous permet de traiter les informations localement, en n'envoyant que les données les plus importantes vers le cloud. Cette technologie est déjà utilisée dans les systèmes de transport intelligents. De plus, cette approche améliore la sécurité et l'efficacité du transport. Les voitures autonomes doivent répondre instantanément aux données reçues, car même le moindre retard peut être dangereux.
La diffusion de l'informatique périphérique nécessitera une nouvelle infrastructure de stockage et de gestion des données. Par exemple, une usine intelligente créera environ 5 pétaoctets de vidéo par jour, une ville intelligente avec une population de 1 million de personnes - 200 pétaoctets de données par jour et une voiture autonome - 4 téraoctets.
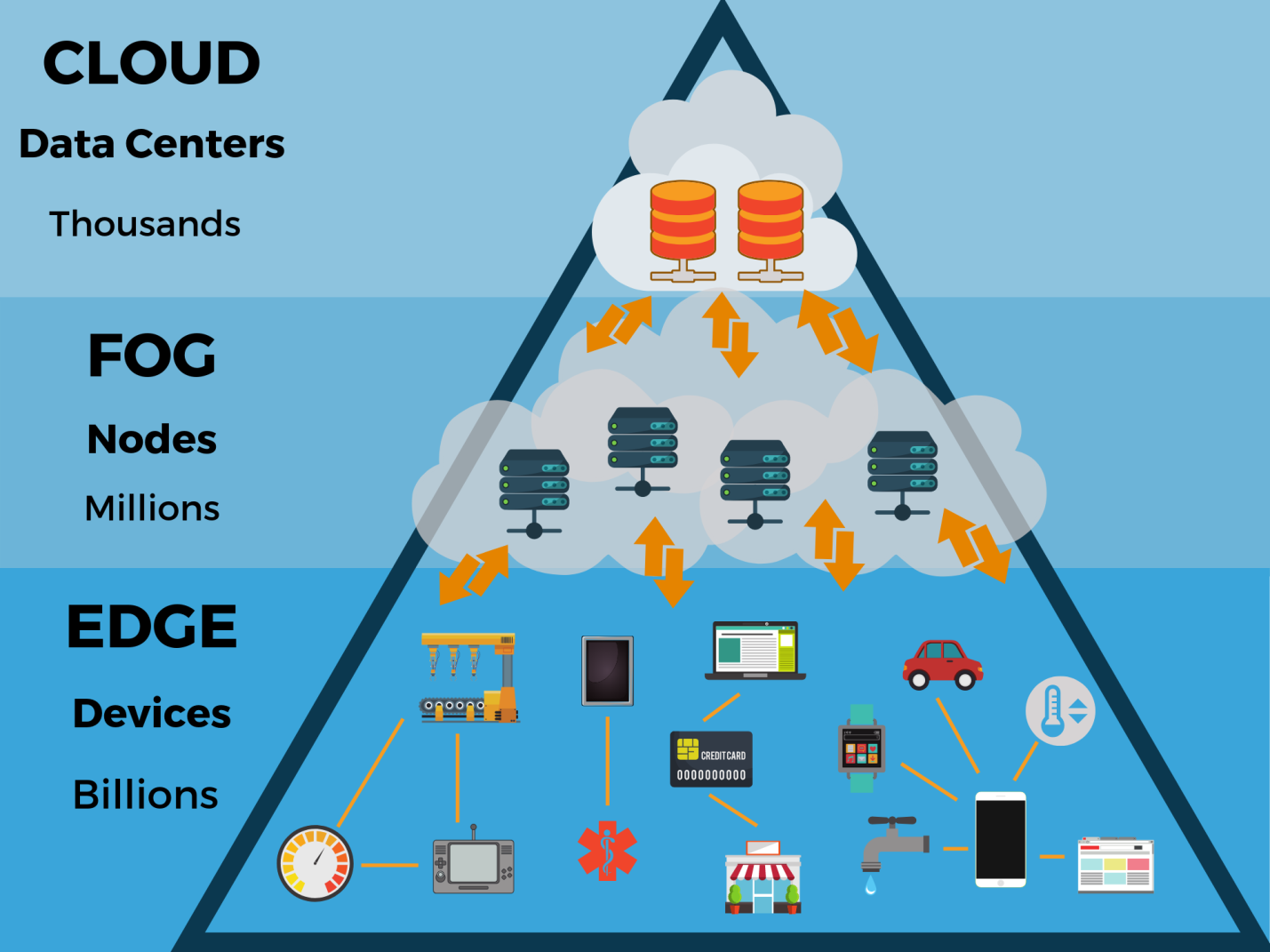
Que signifieront ces données à la frontière? Comment une telle évolution affectera-t-elle la structure et le fonctionnement des datacenters existants et des datacenters cloud? Le cloud computing, qui prévaut aujourd'hui, pourrait-il supplanter l'informatique périphérique car il est plus flexible et évolutif en termes d'applications?
Nuages et périphériques
Les auteurs du rapport «
Data at the Edge » soulignent que même si l'informatique périphérique permet une utilisation plus efficace des données, l'infrastructure traditionnelle ne perdra pas son importance. Comme d'énormes quantités de données seront créées en dehors des centres traditionnels de leur traitement, le cloud s'étendra à la périphérie. Autrement dit, il ne s'agit pas du scénario «cloud contre la périphérie», mais plutôt du «cloud avec la périphérie».
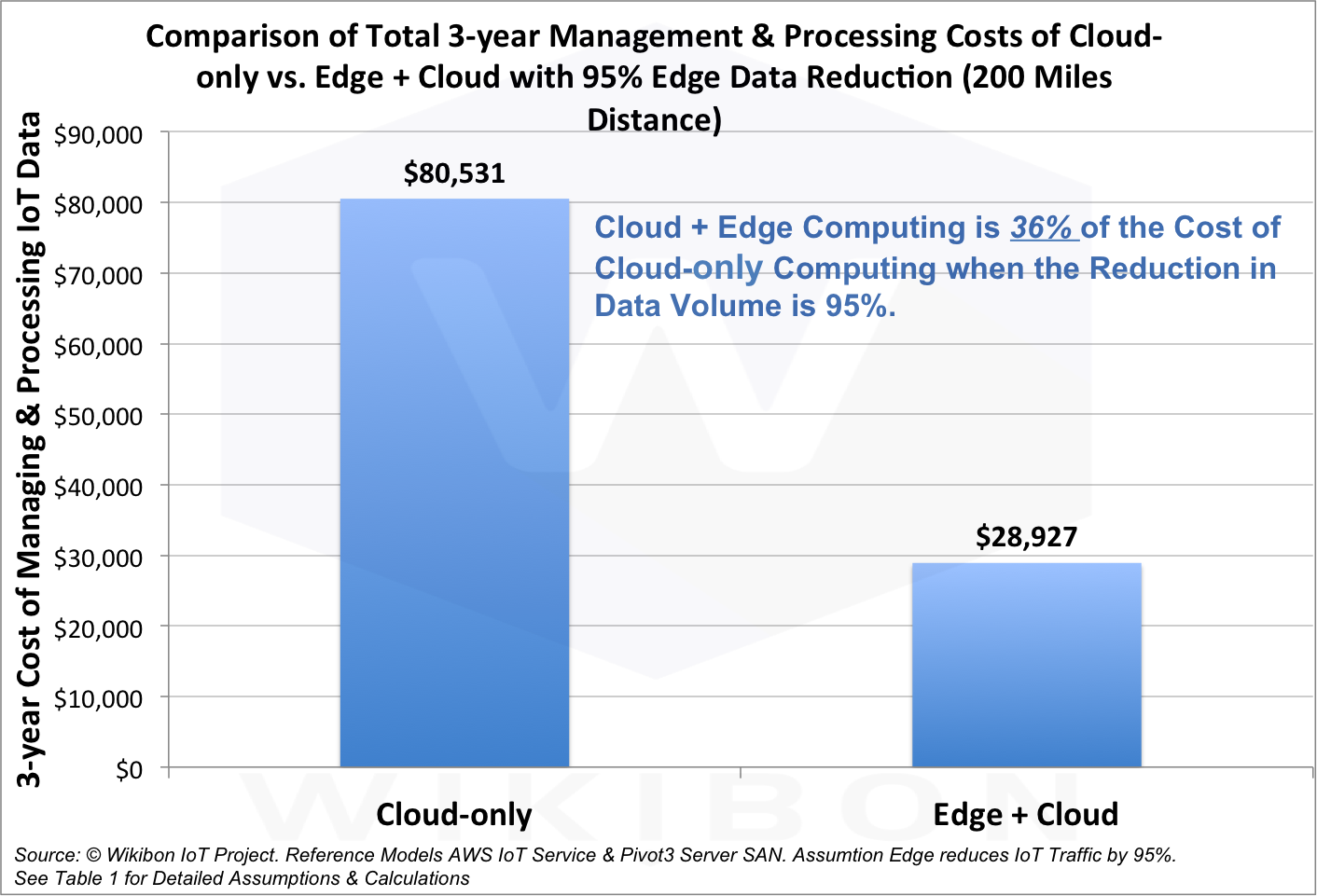
Selon les analystes, la combinaison du cloud et de l'informatique périphérique ne coûtera que 36% du coût d'une version purement cloud, et la quantité de données transmises sera réduite de 95%.
Ainsi, l'avenir réside dans le travail conjoint de la périphérie et du cloud. Cela aidera les entreprises à prendre instantanément des décisions plus éclairées, à accroître leur productivité, leur efficacité au travail et à mieux répondre aux besoins des clients.
Entreprise basée sur les données
Aujourd'hui, presque toute entreprise ou organisation est associée au traitement et au stockage des données. Les innovations dans la gestion de l'information ont ouvert la voie à des façons plus efficaces de l'utiliser. Cela s'applique également aux données périphériques.
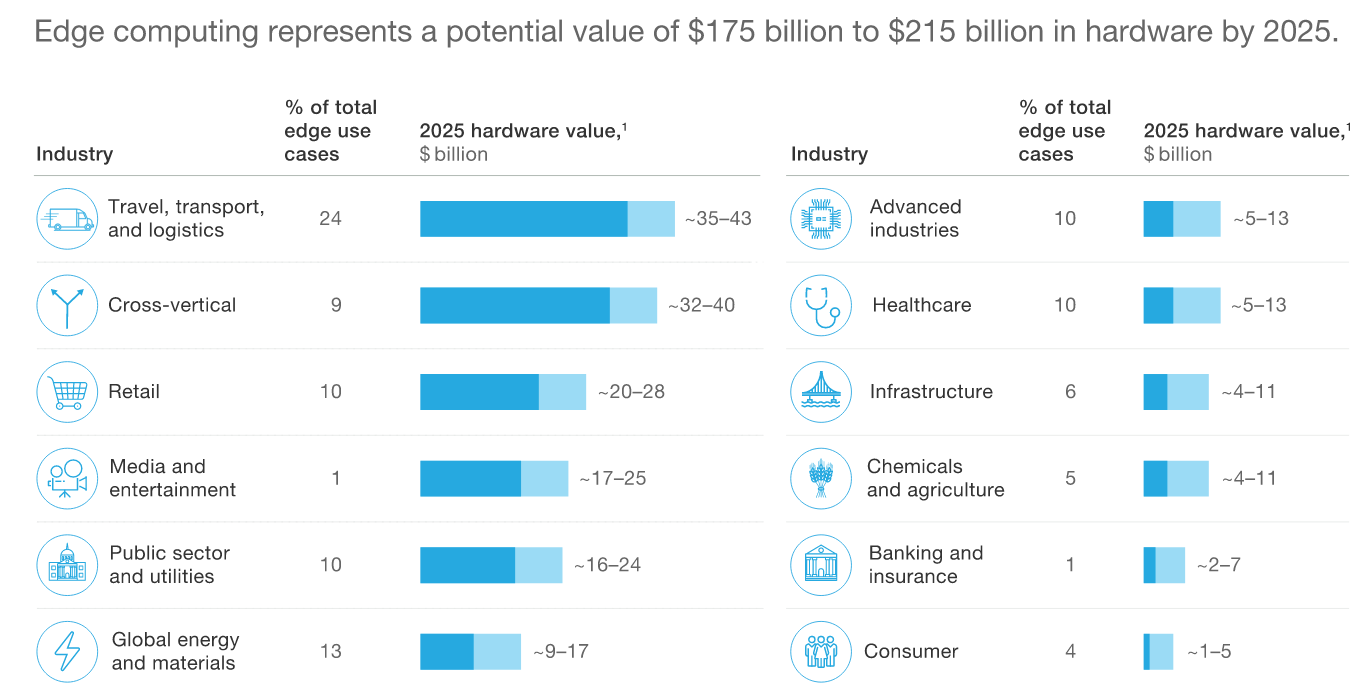
Selon
McKinsey , le marché mondial des équipements informatiques périphériques atteindra 175 à 215 milliards de dollars d'ici 2025.
Périphériques et vie
Qu'est-ce que cela signifie pour les grandes entreprises, les villes, les petites entreprises et les particuliers, quels en sont les avantages? Comment les données à la périphérie nous aideront-elles à mieux travailler, à nous détendre, à vivre, à voyager? Quelles opportunités pour l'analyse des données se présentent à la périphérie du réseau? Telles sont les questions auxquelles le rapport Seagate répond.
Data at the Edge fournit plusieurs exemples de la façon dont l'informatique périphérique transforme les affaires mondiales aujourd'hui et profite aux gens. Par exemple, au Chili, un système d'irrigation à intelligence artificielle, équipé de capteurs, réduit la consommation d'eau de 70%.
Mais ce qui se passe dans les propres usines de Seagate. La société produit chaque année des millions d'unités et des milliards de capteurs. Cela nécessite l'introduction de processus hautement automatisés et le système doit prendre de 20 à 30 décisions par seconde. À cette vitesse, il n'y a pas de temps pour attendre que les données collectées sur la ligne de production soient envoyées au centre pour traitement, puis une solution viendra de là.

Nous ne pouvons pas arrêter la chaîne de production: nous devons maintenir le rythme de production, tout en garantissant sa haute qualité. Ainsi, les décisions doivent être prises au même endroit où les données sont générées. Pour ce faire, Seagate a créé sa propre technologie pour détecter les anomalies et analyser les images sur le site de l'usine. Cela réduit la latence de centaines à moins de 10 millisecondes.
L'informatique périphérique en Russie
«Dans quelle mesure l'informatique périphérique est-elle utilisée en Russie? Premièrement, l'introduction de toute nouvelle technologie prend du temps. Deuxièmement, le terme "informatique périphérique" lui-même n'est pas encore utilisé. Autrement dit, même si l'entreprise utilise cette approche, elle l'appelle différemment », explique Alexander Malinin. - Parallèlement, l'informatique périphérique est souvent utilisée, par exemple, en géodésie, dans l'industrie pétrolière et gazière. Les données d'enquête sont collectées et traitées dans un petit centre de données local, puis envoyées à un référentiel centralisé. L'informatique périphérique est également utilisée dans l'industrie du pétrole et du gaz, où une grande quantité de données est collectée et toutes n'ont pas besoin d'être stockées. »
«Avec le développement des télécommunications, avec une augmentation de la vitesse de transfert des données, le nombre de centres de données périphériques ne fera qu'augmenter», poursuit Alexander Malinin. - Oui, et le terme «informatique périphérique» lui-même sera plus répandu. L'industrie du stockage de données a quelque chose à offrir. Il existe différentes technologies de stockage qui répondent à différentes tâches, il existe des algorithmes mathématiques pour l'analyse des données. Le principal problème réside maintenant dans les technologies des télécommunications, dans l'obtention de données. Par exemple, l'Internet des objets offre une utilisation répandue des connexions sans fil. Cela nécessitera le déploiement de réseaux sans fil, tels que la 5G. Des processus similaires ont eu lieu avec l'introduction de la technologie des mégadonnées. Ils ont déjà commencé à l'utiliser, mais ils l'ont appelé différemment: c'est une question de terminologie. "
Facteurs de croissance
Qu'est-ce qui stimule la demande d'une nouvelle architecture informatique? Sur la base de recherches et d'enquêtes auprès des responsables informatiques de Seagate,
quatre facteurs clés ont été identifiés qui déterminent la demande en informatique périphérique. Il s'agit de la latence du réseau (latence); bande passante insuffisante des canaux de communication pour la livraison de grandes quantités de données au centre de données; efficacité et coût de la solution; souveraineté et conformité des données.
1. Latence
Le facteur numéro un est la latence. En raison des limites physiques de l'infrastructure informatique et de télécommunications, le déplacement des données de leur emplacement de création vers le site central prend trop de temps. Ainsi, la latence devient un facteur clé: l'envoi de données vers et depuis le site central peut prendre à la fois 100 et 200 millisecondes.
2. Débit
Le facteur numéro deux est le problème de bande passante. Les volumes de données totaux ne sont plus exaoctets, mais zettaoctets. Et ils continuent de croître, ne serait-ce qu'en raison de l'apparition de nouveaux capteurs - non seulement la température, la météo, les vibrations ou d'autres capteurs qui collectent relativement peu de données, mais aussi des caméras, des radars, des lidars et d'autres appareils qui génèrent beaucoup d'informations. À l'avenir, il y aura encore plus de tels capteurs. L'infrastructure 5G peut prendre en charge des millions d'appareils au kilomètre carré, mais où puis-je trouver la bande passante pour envoyer toutes les données à un centre de données cloud centralisé?
3. Efficacité
Troisièmement, l'efficacité. Même si vous pouvez envoyer toutes les données à un centre de données centralisé, les coûts et la complexité de l'architecture de traitement d'une telle quantité d'informations seront si importants que le système sera mal géré. Avec un système qui traite intensivement les données à la périphérie, plus près de la source, les choses vont beaucoup mieux.
4. Exigences réglementaires et normes d'entreprise
Enfin, le quatrième facteur est l'exigence que les données soient traitées conformément aux normes et standards acceptés par les clients. Lorsque vous traitez avec la sécurité de l'information, vous ne pouvez souvent pas envoyer de données d'une certaine région ou d'un certain pays à l'étranger pour un traitement centralisé. Cela s'applique, par exemple, aux informations personnelles.
«L'informatique périphérique nécessitera des approches spéciales pour réguler le stockage des données afin d'assurer la sécurité, y compris la sécurité de l'accès physique aux données», souligne Alexander Malinin. "Mais nous verrons certainement une augmentation de l'informatique périphérique au cours des deux à trois prochaines années, car le nombre de demandes des organisations pour de petits centres de données augmente, ce qui servirait à la fois les industries individuelles et les grandes entreprises nationales." Autrement dit, le nombre de demandes d'organisation du stockage de données local augmente. »
Nouvelle architecture
Qu'est-ce que cela signifie pour les architectes informatiques, que devraient-ils faire différemment? Pour commencer, la conception de l'infrastructure traditionnelle d'un centre de données ou d'un centre de données cloud est très différente du développement d'une architecture périphérique. Les centres de données traditionnels comprennent des systèmes de réfrigération et de climatisation, des alimentations sans coupure redondantes et des systèmes de sécurité physique. Ils sont servis par toute une équipe de spécialistes.
Le centre de données périphérique (ou plutôt, le nœud) de traitement des données peut être situé sur une tour de télécommunication ou dans une petite salle. Il est souvent exposé à l'environnement extérieur, de sorte que son contrôle climatique est une tâche difficile.
En matière de sécurité physique, l'architecture devra intégrer une protection spéciale des données en cas de catastrophe naturelle ou d'actes malveillants. De plus, faute de personnel pouvant venir tout réparer rapidement, les systèmes périphériques doivent être particulièrement fiables. Si quelque chose se produit, le centre de données périphérique devrait se récupérer et continuer à fonctionner.
En d'autres termes, si nous avons l'intention de traiter des données à la périphérie, nous devons perfectionner les fonctionnalités du centre de données: refroidissement, sécurité, etc. Les architectes système travaillent déjà sur la recherche de solutions. L'objectif est de simplifier les centres de données périphériques et de fournir une télémétrie suffisante.
De plus, certaines des données qui seront traitées à la périphérie n'y resteront pas. Ils iront au centre pour une analyse plus approfondie ou un stockage plus long. Un architecte informatique doit réfléchir à ce processus en définissant une stratégie de gestion des données.
Les entreprises devront s'appuyer sur leur architecture de cloud computing, apprendre à traiter et, surtout, stocker en toute sécurité plus de données en périphérie.
Le
rapport sur
les données périphériques de Seagate et Vapor IO indique que chaque organisation a une valeur qu'elle ne soupçonne même pas. Ce sont ses propres données. La façon dont nous créons des données et travaillons avec la périphérie du réseau lui confère une importance particulière. Pour continuer à croître, les entreprises doivent en profiter.
«Les problèmes de mise en œuvre de l'informatique périphérique se résument désormais principalement aux télécommunications, à la vitesse d'accès aux données. Plus l'introduction des technologies de télécommunication de prochaine génération en Russie commencera rapidement, plus l'informatique périphérique se développera rapidement », explique Alexander Malinin. - Parallèlement, l'informatique périphérique se développera parallèlement aux datacenters existants et les complétera. Aucune restructuration radicale n'est requise. »
Gartner prévoit que d'ici 2021, 40% des entreprises dans le monde développeront des stratégies informatiques périphériques à grande échelle. Par conséquent, les vendeurs sont maintenant pressés d'occuper un créneau prometteur. Au cours des cinq prochaines années, le marché sera activement formé, de nouvelles plates-formes et des solutions clés en main apparaîtront qui se concentreront sur diverses tâches et industries. Les entreprises engagées dans le développement de l'informatique périphérique pourront devenir des leaders dans de nouveaux domaines d'activité.