Zabbix est un système de surveillance. Comme tout autre système, il fait face à trois problèmes principaux de tous les systèmes de surveillance: la collecte et le traitement des données, le stockage de l'historique et leur nettoyage.
Les étapes d'acquisition, de traitement et d'enregistrement des données prennent du temps. Pas grand-chose, mais pour un grand système, cela peut entraîner des retards importants. Le problème de stockage est un problème d'accès aux données. Ils sont utilisés pour les rapports, les vérifications et les déclencheurs. Les retards dans l'accès aux données affectent également les performances. Lorsque la base de données se développe, les données non pertinentes doivent être supprimées. L'enlèvement est une opération difficile qui consomme également une partie des ressources.

Les problèmes de retards lors de la collecte et du stockage dans Zabbix sont résolus par la mise en cache: plusieurs types de caches, la mise en cache dans la base de données. Pour résoudre le troisième problème, la mise en cache ne convient pas, par conséquent, Zabbix a utilisé TimescaleDB.
Andrey Gushchin , ingénieur du support technique chez
Zabbix SIA, en parlera. Andrey soutient Zabbix depuis plus de 6 ans et est directement confronté aux performances.
Comment fonctionne TimescaleDB, quelles performances peut-il offrir par rapport à PostgreSQL standard? Quel rôle joue Zabbix dans TimescaleDB? Comment exécuter à partir de zéro et comment migrer avec PostgreSQL et quelles performances sont les meilleures? À propos de tout cela sous la coupe.
Défis de performance
Chaque système de surveillance est confronté à des défis de performances spécifiques. J'en parlerai trois: collecte et traitement des données, stockage, nettoyage de l'historique.
Collecte et traitement rapides des données. Un bon système de surveillance devrait recevoir rapidement toutes les données et les traiter selon des expressions de déclenchement - selon ses propres critères. Après le traitement, le système doit également enregistrer rapidement ces données dans la base de données afin de les utiliser ultérieurement.
Garder une histoire. Un bon système de surveillance doit stocker l'historique dans la base de données et fournir un accès pratique aux métriques. Une histoire est nécessaire pour l'utiliser dans des rapports, des graphiques, des déclencheurs, des seuils et des éléments de données calculés pour les alertes.
Effacer l'histoire. Parfois, un jour vient où vous n'avez pas besoin de stocker des métriques. Pourquoi avez-vous besoin des données collectées il y a 5 ans, un mois ou deux: certains nœuds sont supprimés, certains hôtes ou mesures ne sont plus nécessaires, car ils sont obsolètes et ont cessé de collecter. Un bon système de surveillance doit stocker les données historiques et les supprimer de temps en temps afin que la base de données ne se développe pas.
La suppression des données obsolètes est un problème brûlant qui a un impact important sur les performances de la base de données.
Mise en cache Zabbix
Dans Zabbix, les premier et deuxième appels sont résolus à l'aide de la mise en cache. La RAM est utilisée pour la collecte et le traitement des données. Pour le stockage - des histoires dans des déclencheurs, des graphiques et des éléments de données calculés. Du côté de la base de données, il existe une certaine mise en cache pour les principaux échantillons, par exemple les graphiques.
La mise en cache sur le côté du serveur Zabbix lui-même est:
- ConfigurationCache;
- ValueCache;
- HistoryCache;
- TrendsCache.
Examinons-les plus en détail.
ConfigurationCache
Il s'agit du cache principal dans lequel nous stockons les métriques, les hôtes, les éléments de données, les déclencheurs - tout ce qui est nécessaire pour le prétraitement et la collecte de données.
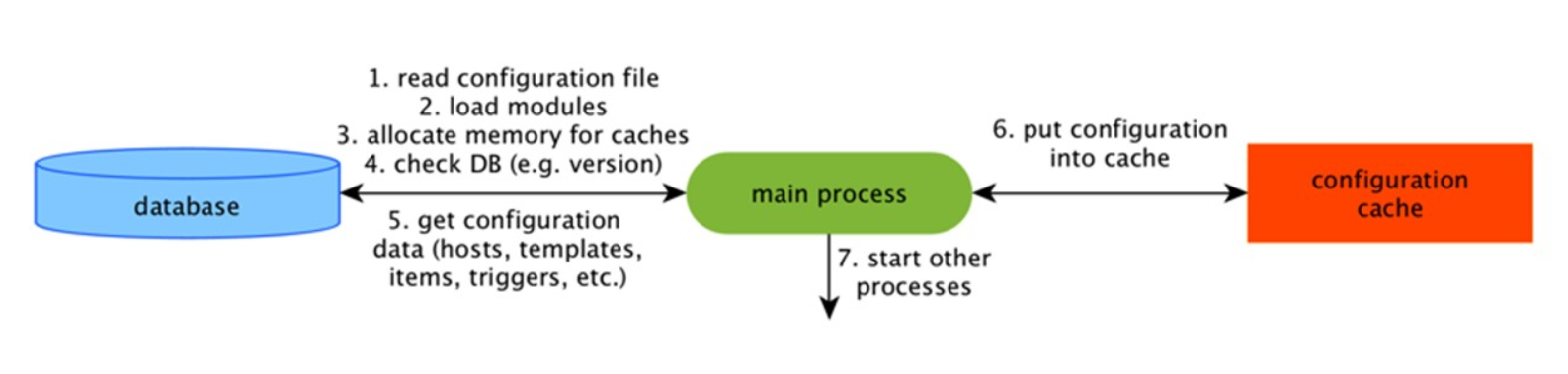
Tout cela est stocké dans ConfigurationCache afin de ne pas créer de requêtes inutiles dans la base de données. Après le démarrage du serveur, nous mettons à jour ce cache, créons et mettons à jour périodiquement les configurations.
Collecte de données
Le schéma est assez grand, mais l'essentiel est les
assembleurs . Ce sont les différents «assembleurs» - processus d'assemblage. Ils sont responsables de différents types d'assemblage: ils collectent les données via SNMP, IPMI et transfèrent le tout au pré-traitement.
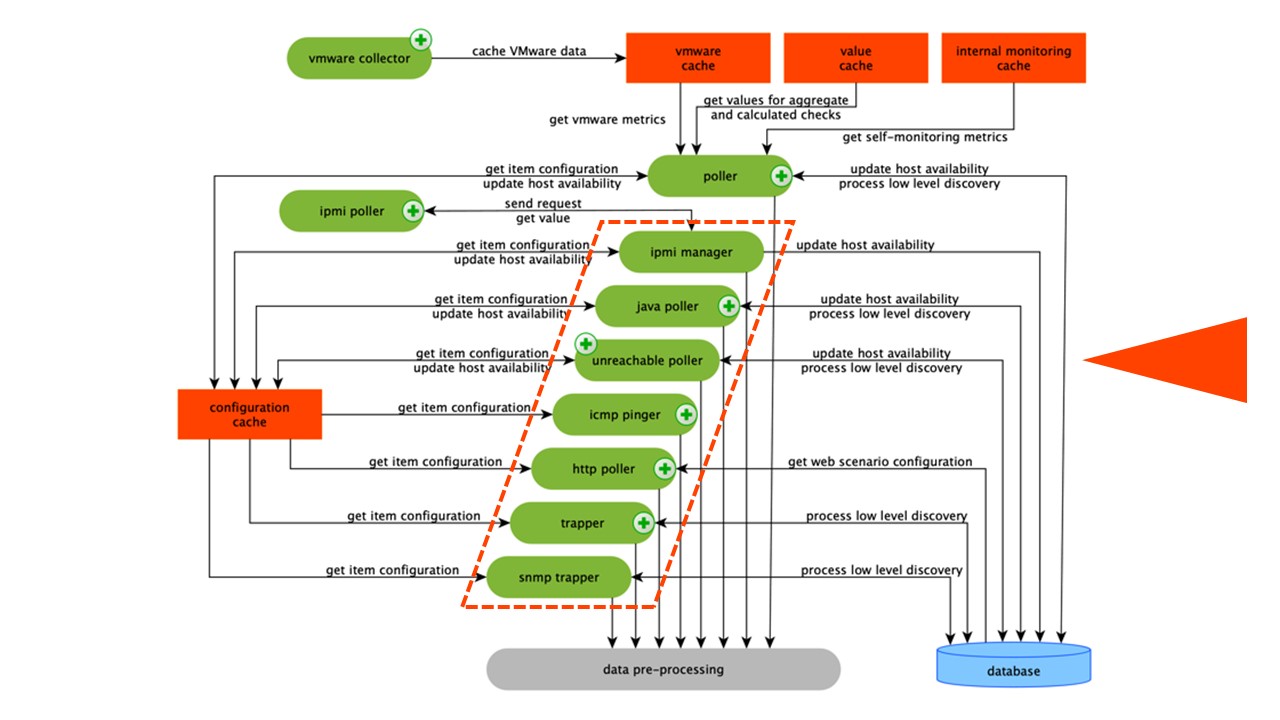 Les collecteurs sont entourés d'orange.
Les collecteurs sont entourés d'orange.Zabbix a calculé les éléments de données d'agrégation nécessaires pour agréger les validations. Si nous les avons, nous les prenons directement à partir de ValueCache.
Historique de prétraitement
Tous les collecteurs utilisent ConfigurationCache pour recevoir des travaux. Ils les transmettent ensuite au prétraitement.

Le prétraitement utilise ConfigurationCache pour recevoir les étapes de prétraitement. Il traite ces données de différentes manières.
Après avoir traité les données à l'aide du prétraitement, nous les enregistrons dans HistoryCache pour les traiter. Cela met fin à la collecte de données et nous passons au processus principal dans Zabbix -
synchroniseur d'histoire , car il s'agit d'une architecture monolithique.
Remarque: le prétraitement est une opération assez difficile. Depuis la v 4.2, il a été soumis au proxy. Si vous avez un très grand Zabbix avec un grand nombre d'éléments de données et une fréquence de collecte, cela facilite grandement le travail.Cache ValueCache, historique et tendances
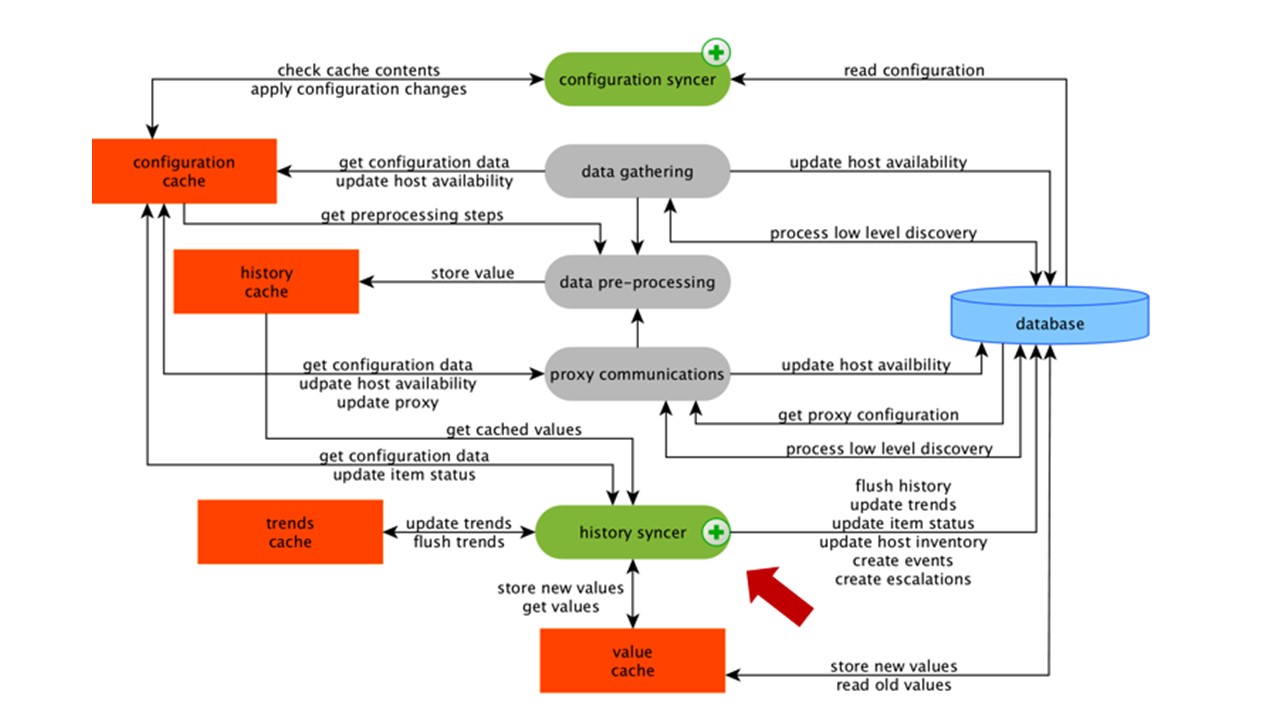
Le synchroniseur d'historique est le processus principal qui traite atomiquement chaque élément de données, c'est-à-dire chaque valeur.
Le synchroniseur d'historique prend des valeurs dans HistoryCache et vérifie dans la configuration les déclencheurs des calculs. S'ils le sont, il calcule.
Le synchroniseur d'historique crée un événement, une escalade pour créer des alertes, si la configuration l'exige, et des enregistrements. S'il existe des déclencheurs pour un traitement ultérieur, il se souvient de cette valeur dans ValueCache afin de ne pas accéder à la table d'historique. Donc ValueCache est rempli de données nécessaires au calcul des déclencheurs, des éléments calculés.
Le synchroniseur d'historique écrit toutes les données dans la base de données et elles sont écrites sur le disque. Le processus de traitement se termine ici.
Mise en cache DB
Côté DB, il existe différents caches lorsque vous souhaitez regarder des graphiques ou des rapports d'événements:
Innodb_buffer_pool du côté MySQL;shared_buffers du côté PostgreSQL;effective_cache_size du côté Oracle;shared_pool du côté DB2.
Il existe de nombreux autres caches, mais ce sont les principaux pour toutes les bases de données. Ils vous permettent de conserver en mémoire les données souvent nécessaires aux requêtes. Ils ont leurs propres technologies pour cela.
Les performances de la base de données sont essentielles
Le serveur Zabbix collecte constamment des données et les écrit. Lors du redémarrage, il lit également à partir de l'historique pour remplir ValueCache. Les scripts et les rapports utilisent l'
API Zabbix , qui est construite sur la base de l'interface Web. L'API Zabbix contacte la base de données et reçoit les données nécessaires pour les graphiques, les rapports, les listes d'événements et les problèmes récents.
Pour la visualisation -
Grafana . Parmi nos utilisateurs, c'est une solution populaire. Il peut envoyer directement des requêtes via l'API Zabbix et vers la base de données, et crée une certaine compétitivité pour la réception des données. Par conséquent, nous avons besoin d'un réglage plus fin et meilleur de la base de données pour correspondre à la sortie rapide des résultats et des tests.
Gouvernante
Le troisième défi de performance dans Zabbix est d'effacer l'histoire avec Housekeeper. Il observe tous les paramètres - les éléments de données indiquent combien conserver la dynamique des changements (tendances) en jours.
Nous calculons TrendsCache à la volée. Lorsque les données arrivent, nous les agrégons en une heure et les écrivons dans des tableaux pour la dynamique des changements de tendance.
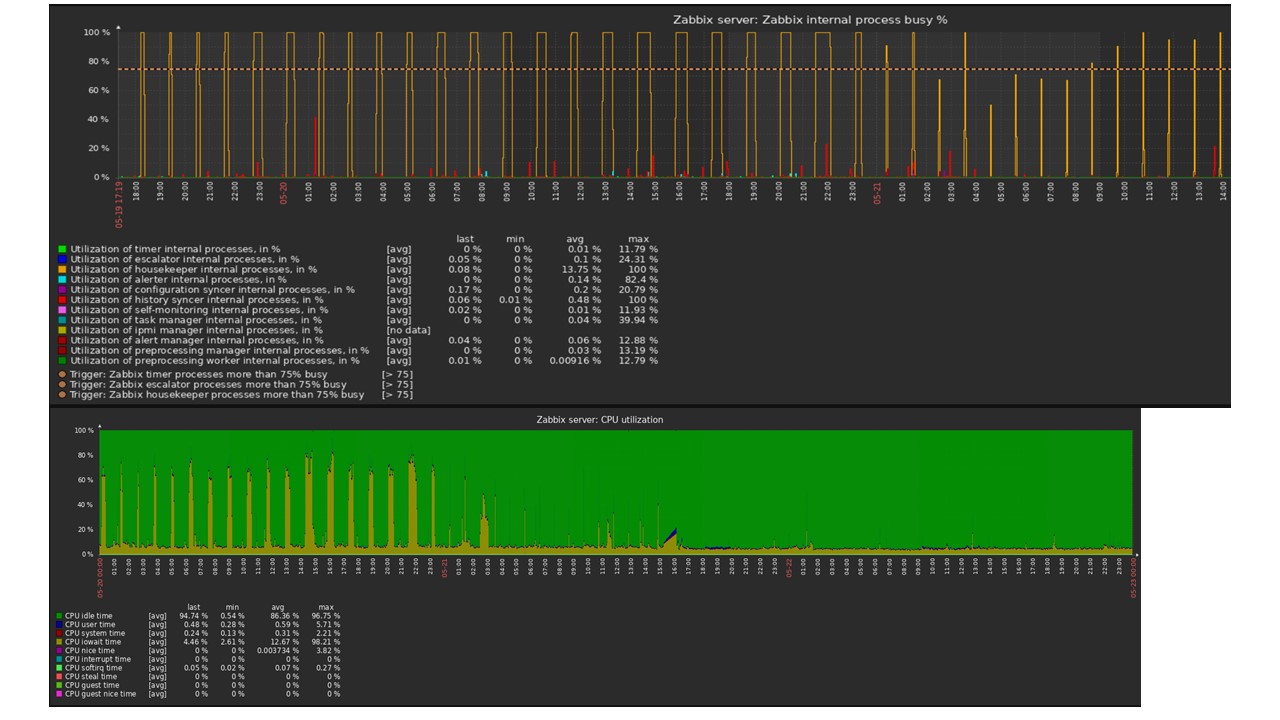
Housekeeper démarre et supprime les informations de la base de données avec les "sélections" habituelles. Ce n'est pas toujours efficace, ce qui peut être compris à partir des graphiques de performance des processus internes.
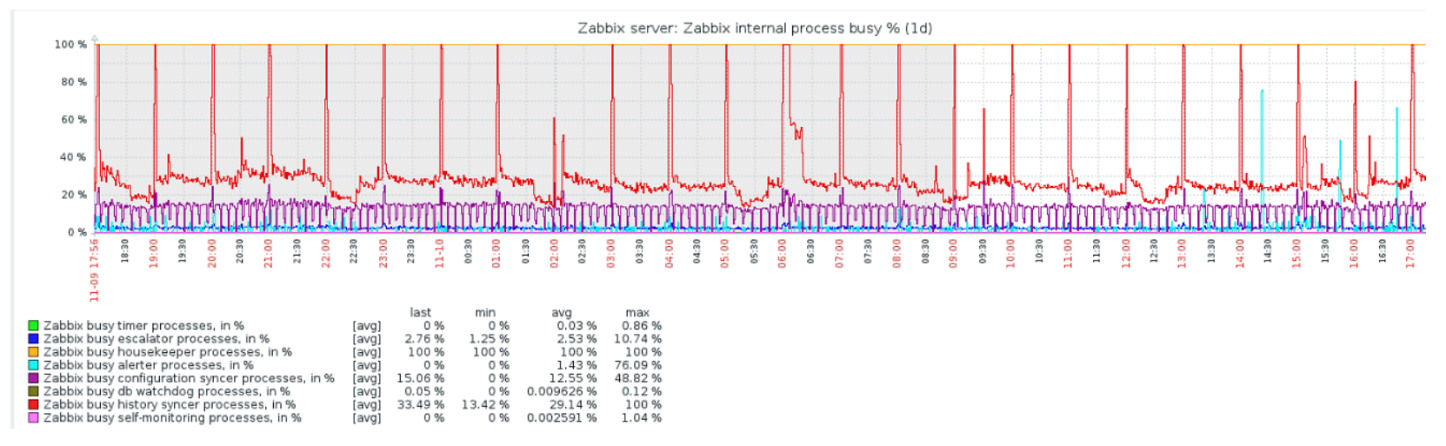
Un graphique rouge indique que le synchroniseur d'historique est constamment occupé. Le graphique orange ci-dessus est Housekeeper, qui fonctionne constamment. Il s'attend à ce que la base de données supprime toutes les lignes qu'il a spécifiées.
Quand désactiver Housekeeper? Par exemple, il existe un «ID d'article» et vous devez supprimer les 5 000 dernières lignes dans un certain temps. Bien sûr, cela se produit par index. Mais généralement, l'ensemble de données est très volumineux, et la base de données lit toujours à partir du disque et le place dans le cache. Il s'agit toujours d'une opération très coûteuse pour la base de données et, selon la taille de la base de données, peut entraîner des problèmes de performances.
La gouvernante vient de se déconnecter. Dans l'interface Web, il existe un paramètre dans "Administration générale" pour Housekeeper. Désactivez le nettoyage interne pour l'historique des tendances internes et il ne gère plus cela.
Gouvernante a été désactivée, les graphiques ont été nivelés - quel pourrait être le problème dans ce cas et qu'est-ce qui peut aider à résoudre le troisième défi de performance?
Partitionnement - partitionnement ou partitionnement
En règle générale, le partitionnement est configuré d'une manière différente sur chaque base de données relationnelle que j'ai répertoriée. Chacun a sa propre technologie, mais ils sont généralement similaires. La création d'une nouvelle partition entraîne souvent certains problèmes.
Les partitions sont généralement configurées en fonction de la «configuration» - la quantité de données créées en une journée. En règle générale, le partitionnement est exposé en une journée, c'est un minimum. Pour les tendances de la nouvelle partition - pendant 1 mois.
Les valeurs peuvent changer dans le cas d'une «configuration» très importante. Si la petite «configuration» va jusqu'à 5 000 nvps (nouvelles valeurs par seconde), la moyenne est de 5 000 à 25 000, alors la grande est supérieure à 25 000 nvps. Ce sont des installations grandes et très grandes qui nécessitent une configuration minutieuse de la base de données.
Sur de très grandes installations, une exécution d'une journée peut ne pas être optimale. J'ai vu sur des partitions MySQL de 40 Go ou plus par jour. Il s'agit d'une très grande quantité de données qui peut entraîner des problèmes et doit être réduite.
Qu'est-ce qui donne le partitionnement?
Tables de partitionnement . Il s'agit souvent de fichiers distincts sur le disque. Le plan de requête sélectionne de manière plus optimale une partition. Le partitionnement est généralement utilisé sur une plage - pour Zabbix, cela est également vrai. Nous utilisons là «timestamp» - le temps depuis le début de l'ère. Nous avons des nombres ordinaires. Vous définissez le début et la fin de la journée - c'est une partition.
Suppression rapide -
DELETE . Un seul fichier / sous-tableau est sélectionné, pas une sélection de lignes à supprimer.
Accélère visiblement la récupération des données SELECT - utilise une ou plusieurs partitions, pas la table entière. Si vous demandez des données il y a deux jours, elles sont sélectionnées plus rapidement dans la base de données car vous devez charger dans le cache et émettre un seul fichier, pas une grande table.
Souvent, de nombreuses bases de données accélèrent également les insertions
INSERT dans la table enfant.
Timescaledb
Pour la version 4.2, nous avons tourné notre attention vers TimescaleDB. Il s'agit d'une extension pour PostgreSQL avec une interface native. L'extension fonctionne efficacement avec les données de séries chronologiques, sans perdre les avantages des bases de données relationnelles. TimescaleDB partitionne également automatiquement.
TimescaleDB a le concept d'un
hypertable que vous créez. Il contient des
morceaux - des partitions. Les morceaux sont des fragments contrôlés automatiquement d'un hypertable qui n'affectent pas les autres fragments. Chaque morceau a sa propre plage horaire.
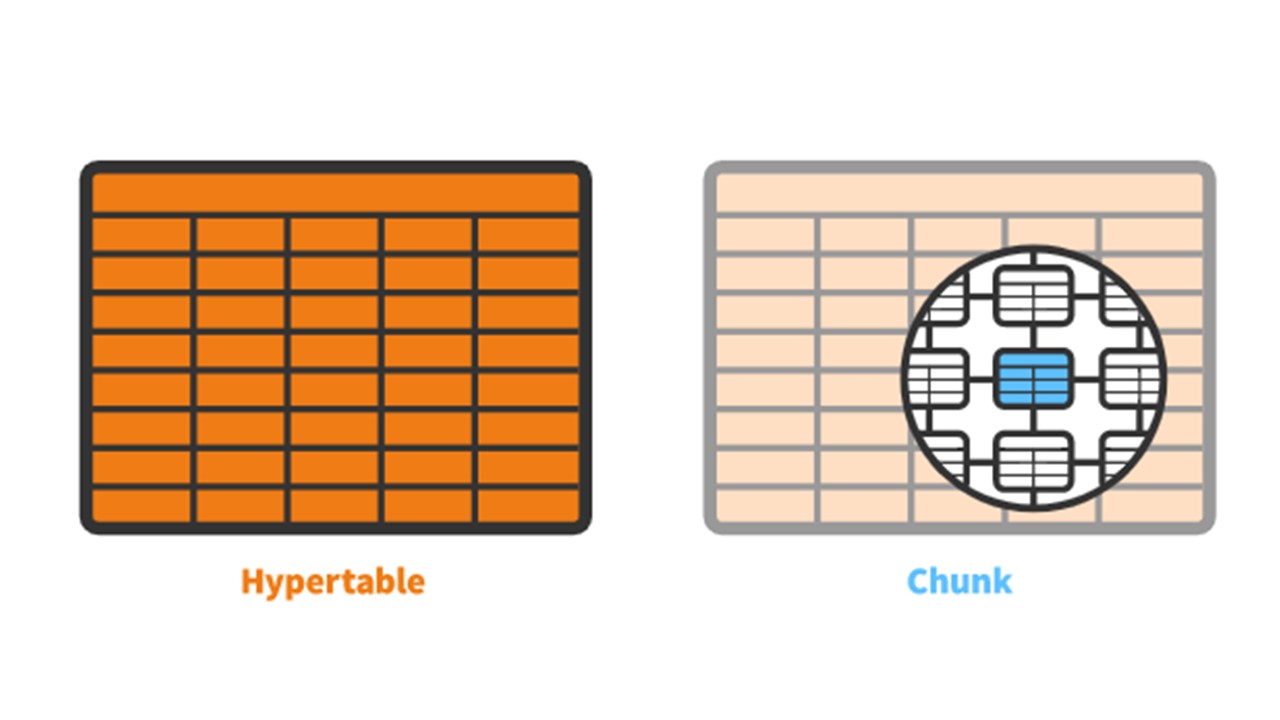
TimescaleDB vs PostgreSQL
TimescaleDB fonctionne vraiment efficacement. Les fabricants d'extensions affirment utiliser un algorithme de traitement des demandes plus correct, en particulier les <code> insertions </code>. Lorsque les dimensions de l'insertion de jeu de données augmentent, l'algorithme maintient des performances constantes.
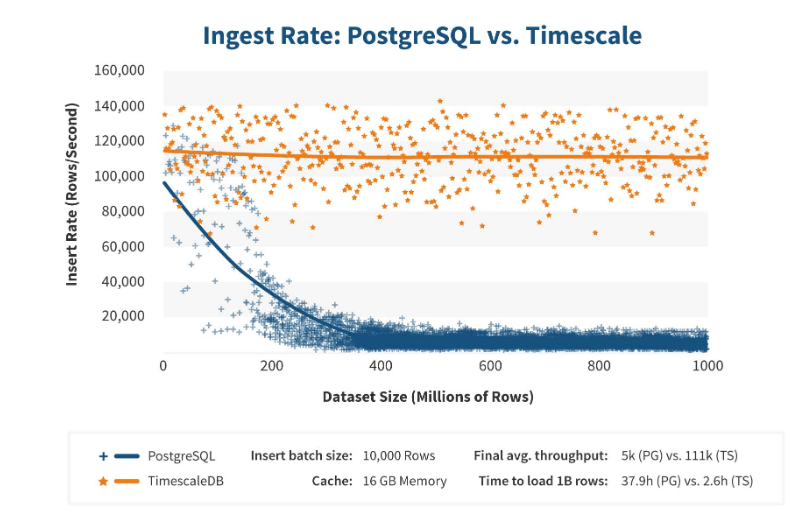
Après 200 millions de lignes, PostgreSQL commence généralement à s'affaisser fortement et perd des performances jusqu'à 0. TimescaleDB vous permet d'insérer efficacement des «insertions» pour n'importe quelle quantité de données.
L'installation
L'installation de TimescaleDB est assez facile pour tous les packages. La
documentation décrit tout en détail - cela dépend des packages officiels de PostgreSQL. TimescaleDB peut également être compilé et compilé manuellement.
Pour la base de données Zabbix, nous activons simplement l'extension:
echo "CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;" | sudo -u postgres psql zabbix
Vous activez l'
extension et la créez pour la base de données Zabbix. La dernière étape consiste à créer un hypertable.
Migration des tables d'historique vers TimescaleDB
Il existe une fonction spéciale
create_hypertable :
SELECT create_hypertable('history', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('history_unit', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('history_log', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('history_text', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('history_str', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('trends', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('trends_unit', 'clock', chunk_time_interval => 86400, migrate_data => true); UPDATE config SET db_extension='timescaledb', hk_history_global=1, hk_trends_global=1
La fonction a trois paramètres. Le premier est un
tableau de la base de
données pour lequel vous devez créer un hypertable. Le second est le
champ par lequel créer
chunk_time_interval - l'intervalle des morceaux de partitions que vous souhaitez utiliser. Dans mon cas, l'intervalle est d'un jour - 86 400.
Le troisième paramètre est
migrate_data . Si la valeur est
true , toutes les données actuelles sont transférées vers des blocs créés précédemment. J'ai moi-même utilisé
migrate_data . J'ai eu environ 1 To, ce qui a pris plus d'une heure. Même dans certains cas, lors des tests, j'ai supprimé les données historiques des types de caractères qui étaient facultatifs pour le stockage, afin de ne pas les transférer.
La dernière étape est
UPDATE : nous définissons
db_extension dans
db_extension pour que la base de données comprenne qu'il y a cette extension. Zabbix l'active et utilise correctement la syntaxe et les requêtes déjà dans la base de données - ces fonctionnalités qui sont nécessaires pour TimescaleDB.
Configuration du fer
J'ai utilisé deux serveurs. Le premier est une
machine VMware . Il est assez petit: 20 processeurs Intel® Xeon® E5-2630 v 4 à 2,20 GHz, 16 Go de RAM et un SSD de 200 Go.
J'ai installé PostgreSQL 10.8 dessus avec Debian 10.8-1.pgdg90 + 1 et le système de fichiers xfs. J'ai tout configuré de manière minimale pour utiliser cette base de données particulière, moins ce que Zabbix lui-même utilisera.
Sur la même machine se trouvait un serveur Zabbix, PostgreSQL et
des agents de chargement . J'avais 50 agents actifs qui utilisaient le
LoadableModule pour générer très rapidement divers résultats: nombres, chaînes. J'ai obstrué la base de données avec beaucoup de données.
Initialement, la configuration contenait
5 000 éléments de données par hôte. Presque chaque élément contenait un déclencheur, de sorte qu'il était similaire aux installations réelles. Dans certains cas, il y avait plus d'un déclencheur. Il y avait 3
000 à 7 000 déclencheurs par nœud de réseau.
L'intervalle de mise à jour des éléments de données est de
4 à 7 secondes . J'ai régulé la charge elle-même en utilisant non seulement 50 agents, mais également en ajoutant plus. De plus, à l'aide d'éléments de données, j'ai ajusté dynamiquement la charge et réduit l'intervalle de mise à jour à 4 s.
PostgreSQL 35 000 nvps
La première exécution sur ce matériel que j'ai eu sur PostgreSQL pur - 35 000 valeurs par seconde. Comme vous pouvez le voir, l'insertion de données prend des fractions de seconde - tout va bien et rapidement. La seule chose qu'un SSD de 200 Go se remplit rapidement.
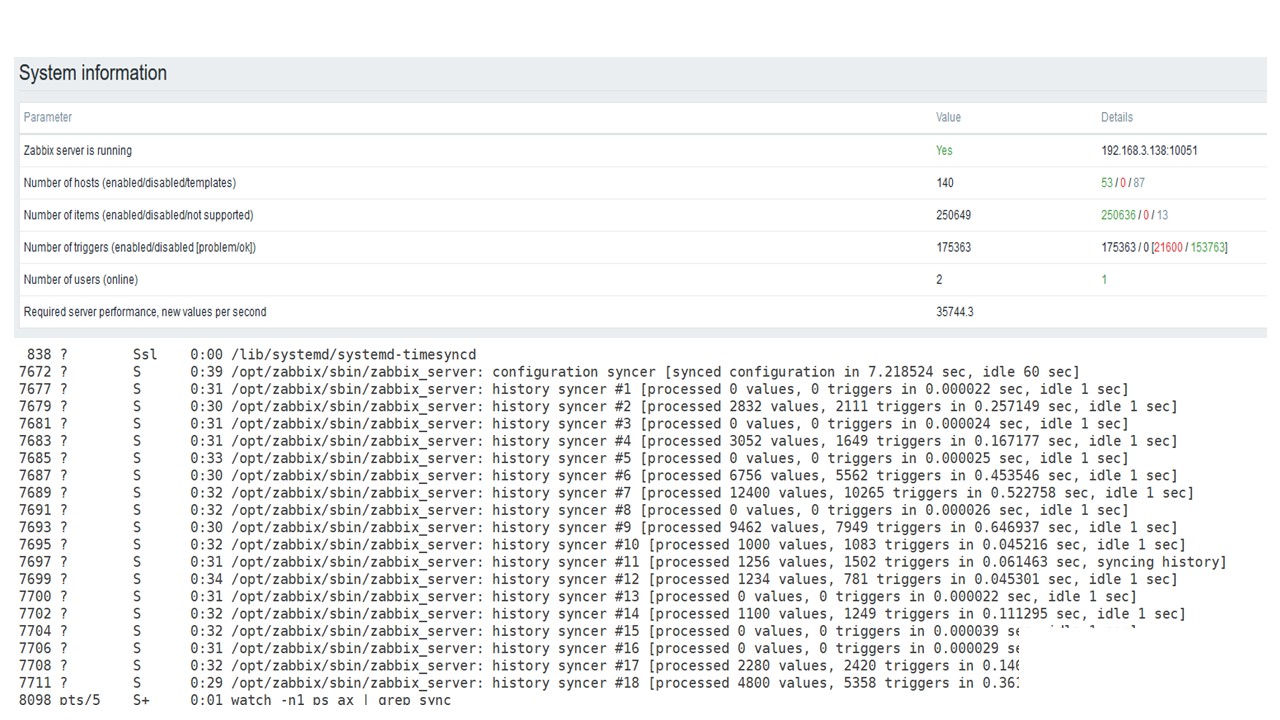
Il s'agit du tableau de bord standard des performances du serveur Zabbix.
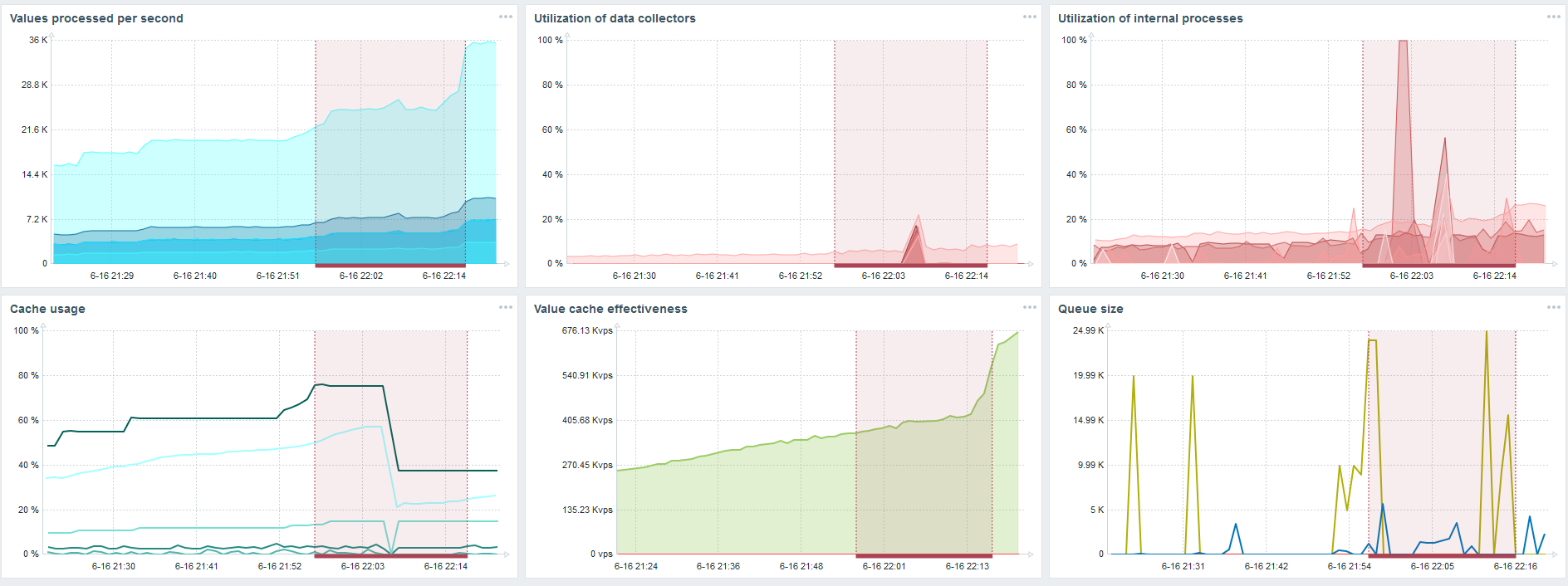
Le premier graphique bleu est le nombre de valeurs par seconde. Le deuxième graphique à droite est le chargement des processus d'assemblage. Le troisième est le chargement des processus d'assemblage internes: les synchroniseurs d'historique et Housekeeper, qui fonctionne depuis un certain temps ici.
Le quatrième graphique montre l'utilisation de HistoryCache. Il s'agit d'un tampon avant l'insertion dans la base de données. Le cinquième graphique vert montre l'utilisation de ValueCache, c'est-à-dire combien de hits ValueCache pour les déclencheurs sont plusieurs milliers de valeurs par seconde.
PostgreSQL 50 000 nvps
Ensuite, j'ai augmenté la charge à 50 000 valeurs par seconde sur le même matériel.
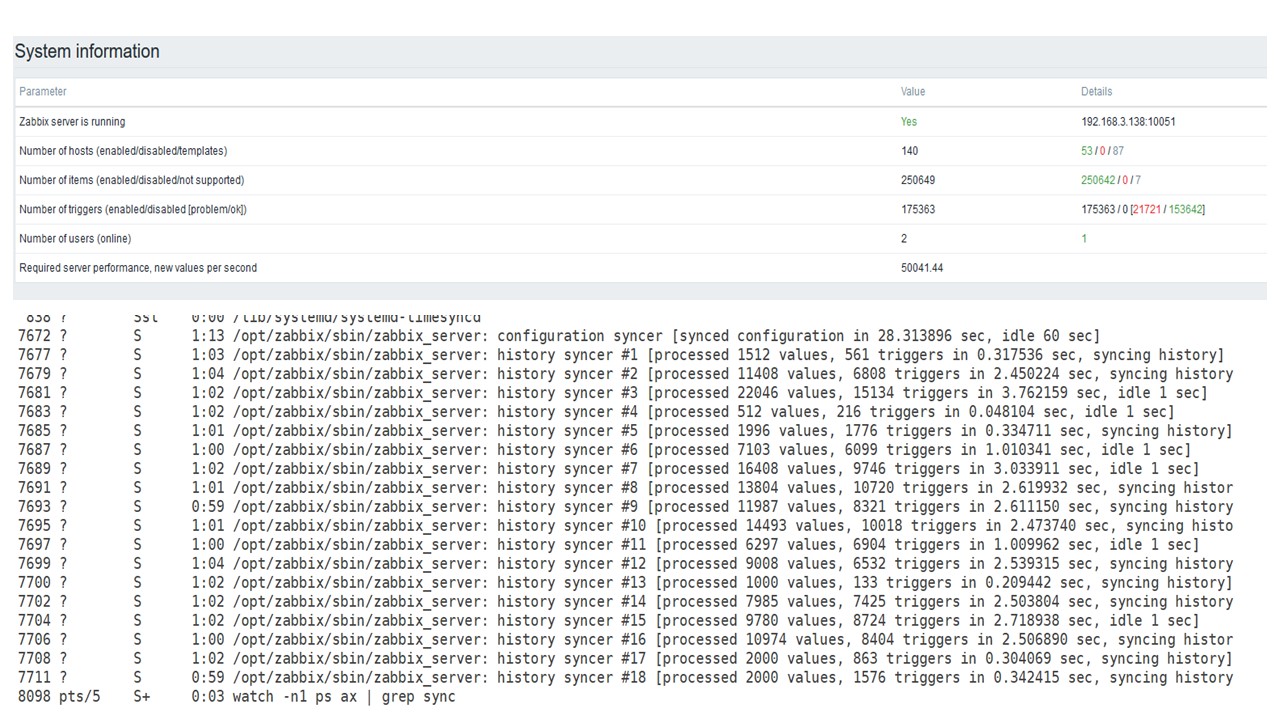
Lors du chargement à partir de Housekeeper, une insertion de 10 000 valeurs a été enregistrée pendant 2-3 s.
 La gouvernante commence déjà à se mettre en travers.
La gouvernante commence déjà à se mettre en travers.Le troisième graphique montre qu'en général, le chargement des trappeurs et des synchroniseurs d'historique est toujours à 60%. Dans le quatrième graphique, HistoryCache commence déjà à se remplir assez activement pendant le fonctionnement. Il est plein à 20% - il fait environ 0,5 Go.
PostgreSQL 80 000 nvps
J'ai ensuite augmenté la charge à 80 000 valeurs par seconde. Il s'agit d'environ 400 000 éléments de données et 280 000 déclencheurs.
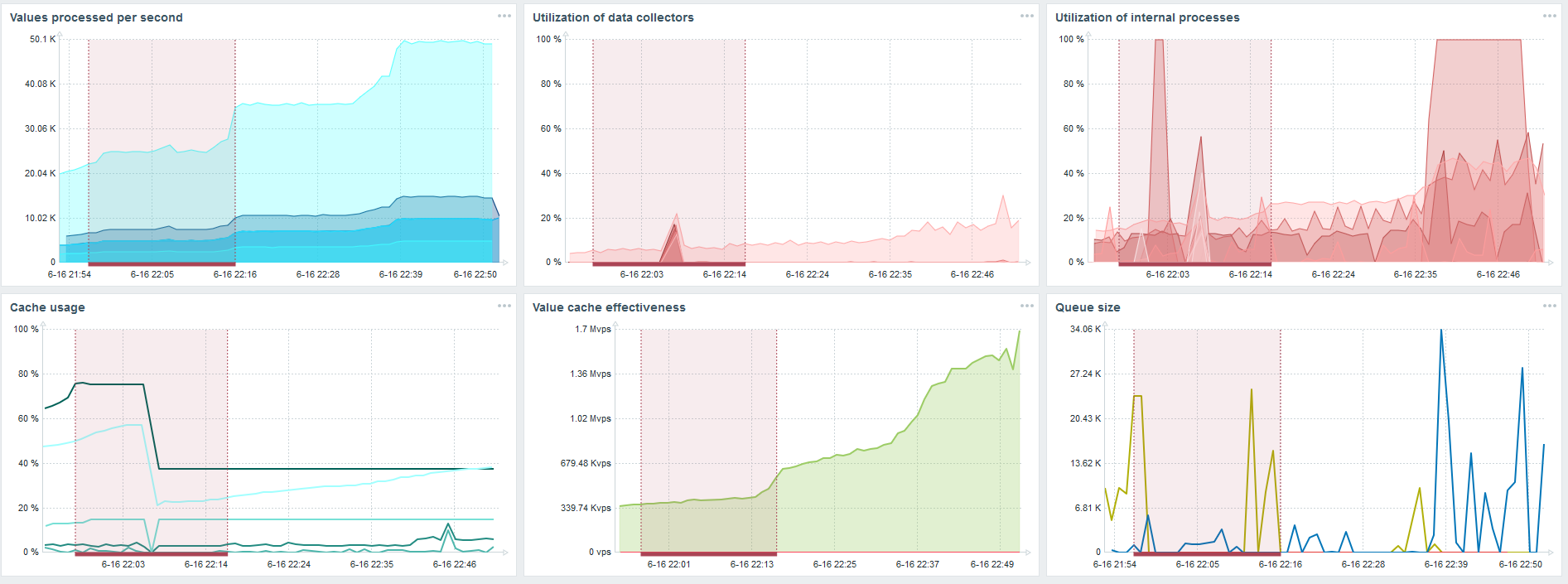
 L'insert pour charger trente synchroniseurs d'historique est déjà assez élevé.
L'insert pour charger trente synchroniseurs d'historique est déjà assez élevé.J'ai également augmenté divers paramètres: synchroniseurs d'historique, caches.
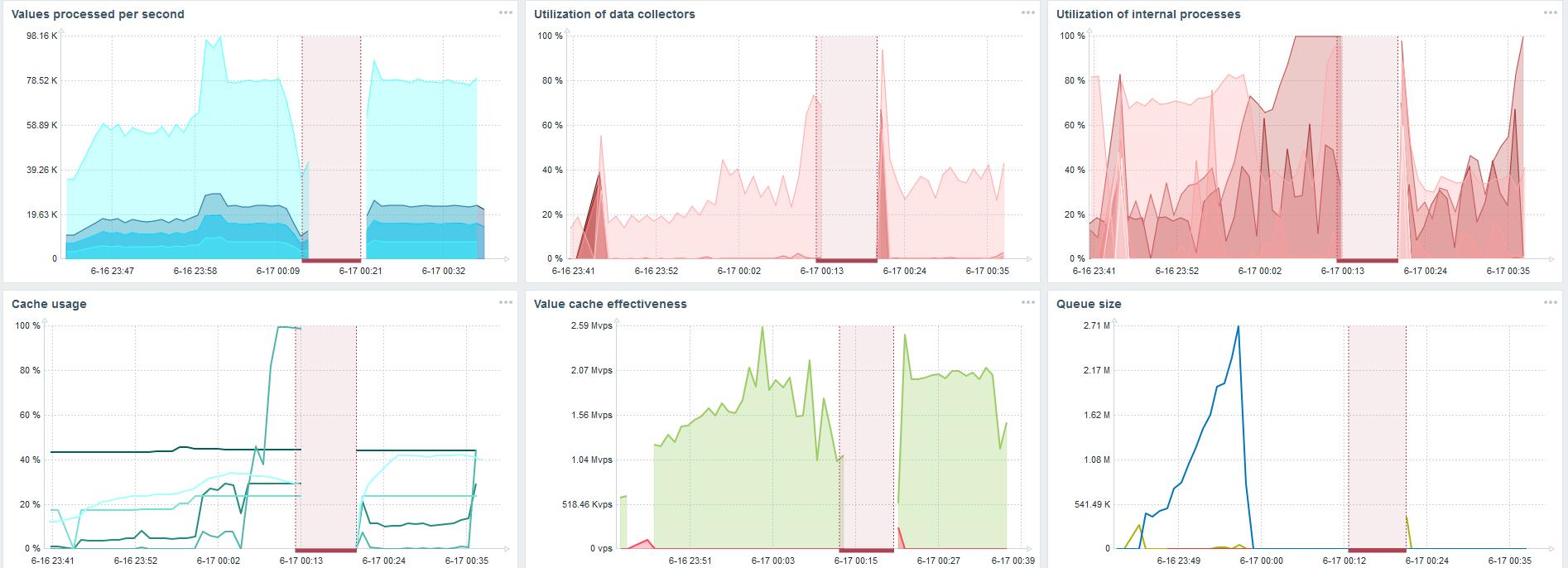
Sur mon matériel, la charge des synchroniseurs d'historique a augmenté au maximum. HistoryCache s'est rapidement rempli de données - les données de traitement accumulées dans le tampon.
Pendant tout ce temps, j'ai regardé comment le processeur, la RAM et d'autres paramètres système étaient utilisés, et j'ai constaté que l'utilisation du disque était maximisée.
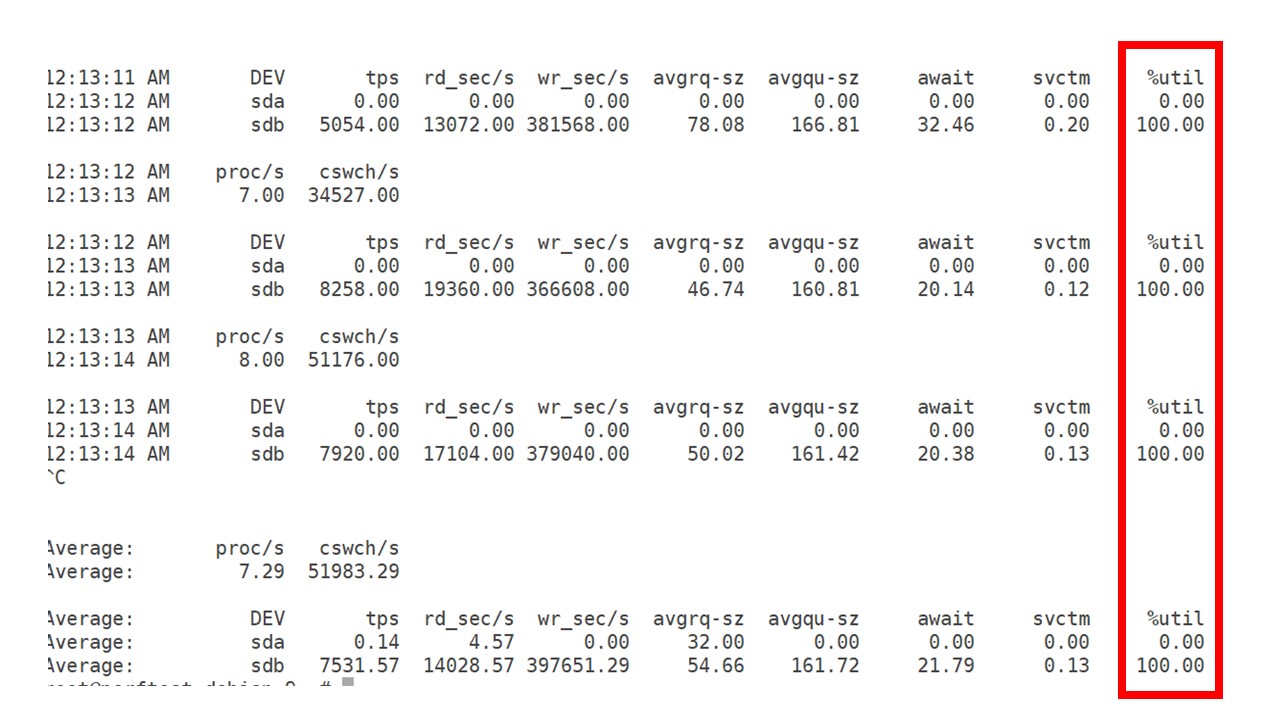
J'ai tiré le
meilleur parti du lecteur sur ce matériel et sur cette machine virtuelle. À cette intensité, PostgreSQL a commencé à vider les données assez activement, et le disque n'a plus eu le temps de travailler sur l'écriture et la lecture.
Deuxième serveur
J'ai pris un autre serveur qui avait déjà 48 processeurs et 128 Go de RAM. Réglez-le - définissez 60 synchroniseur d'historique et obtenez des performances acceptables.
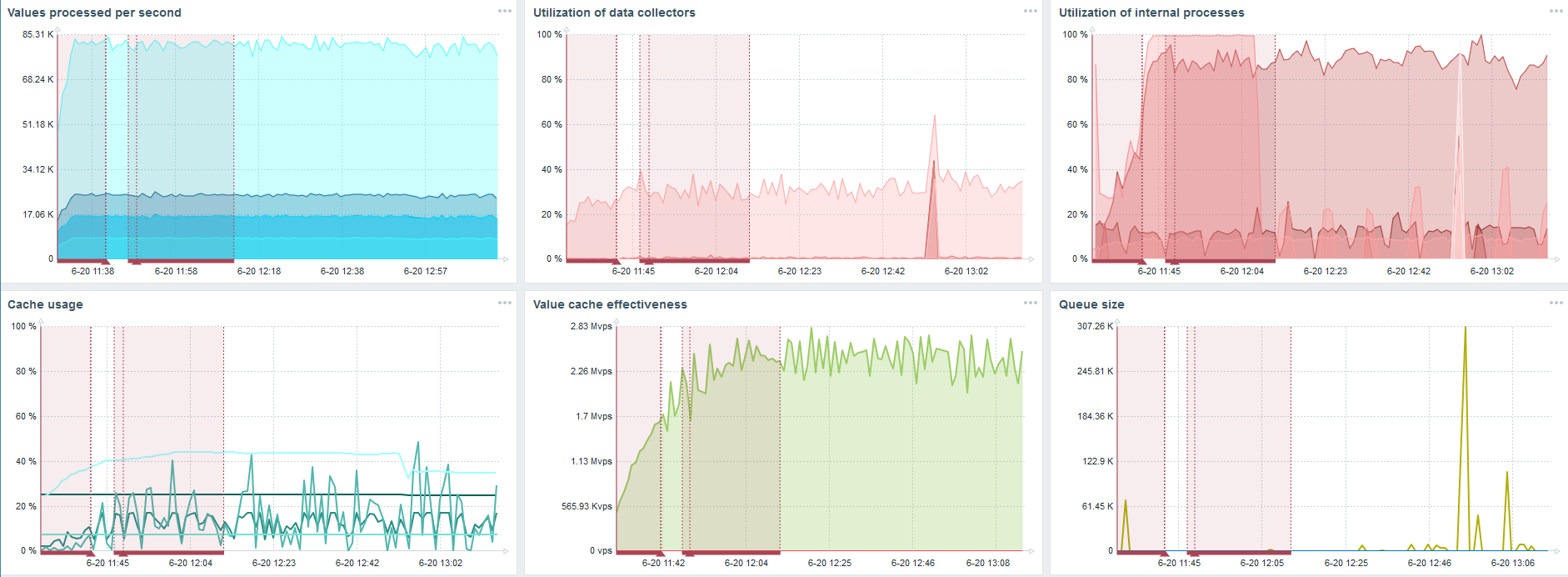
En fait, c'est déjà une limite de performance où quelque chose doit être fait.
TimescaleDB. 80 000 nvps
Ma tâche principale est de tester les capacités de TimescaleDB à partir de la charge Zabbix. 80 000 valeurs par seconde, c'est beaucoup, la fréquence de collecte des métriques (sauf pour Yandex, bien sûr) et une «configuration» assez importante.
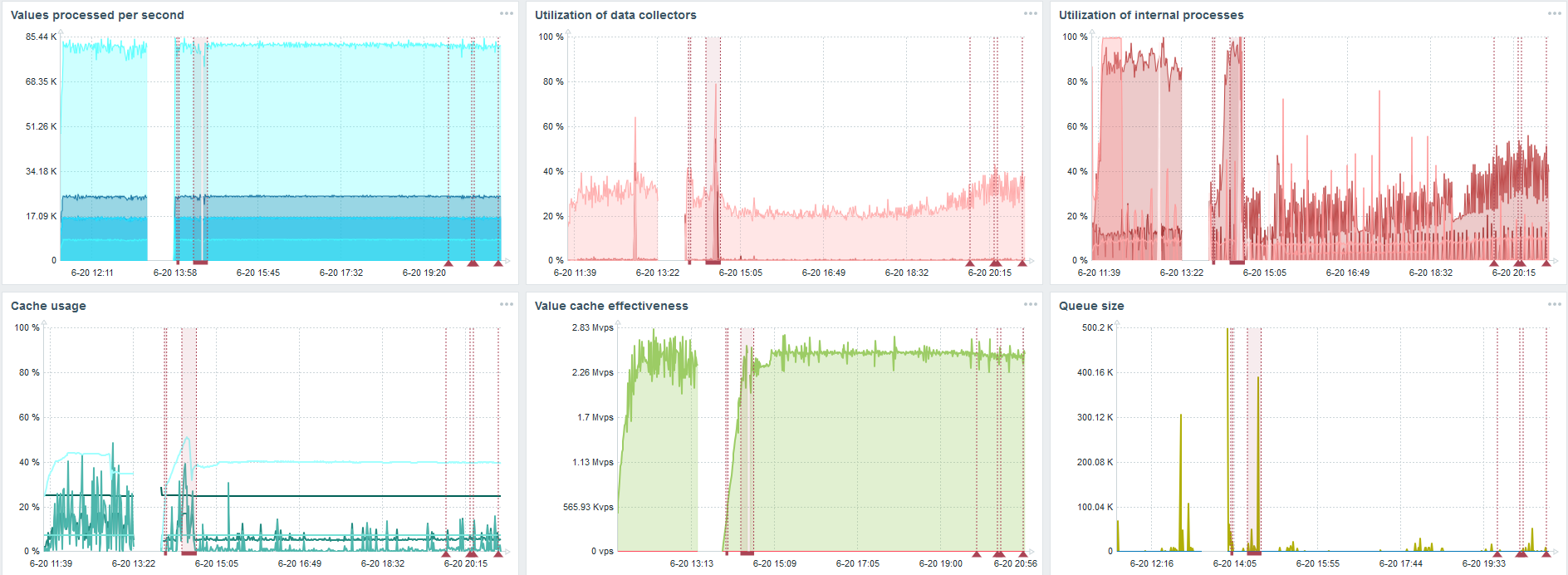
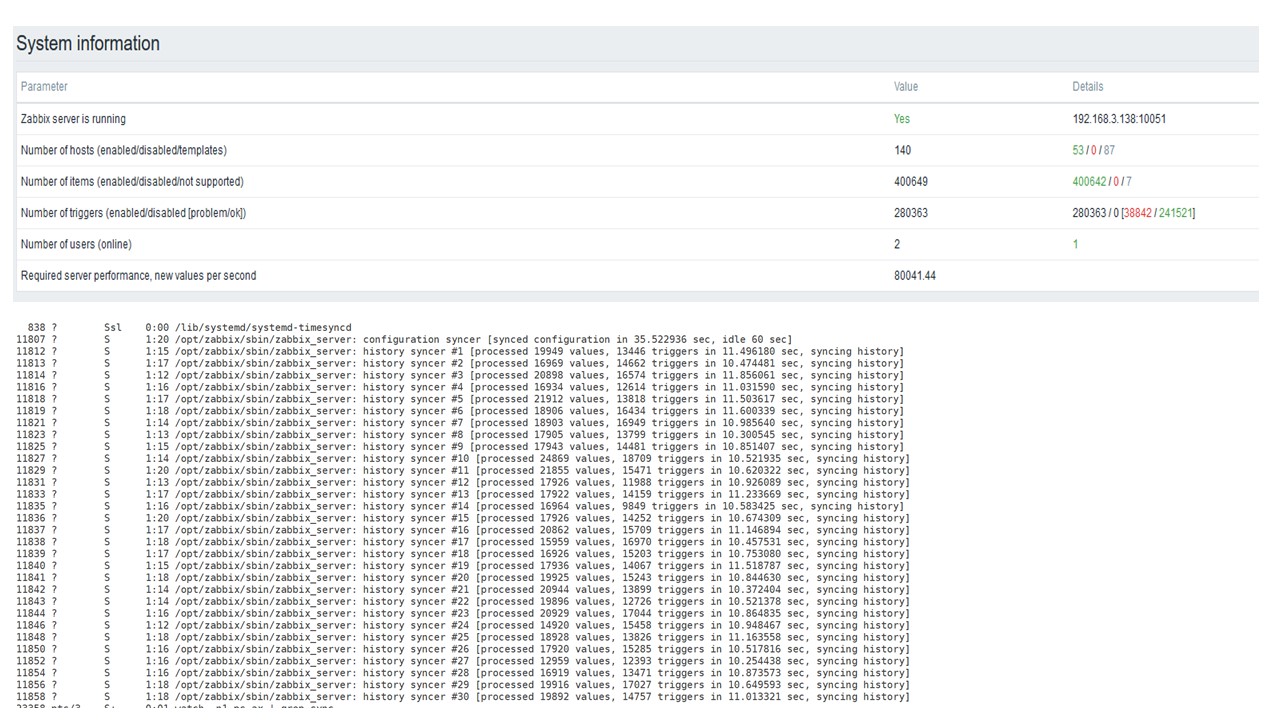
Il y a un échec sur chaque graphique - c'est juste une migration de données. Après des échecs sur le serveur Zabbix, le profil de démarrage du synchroniseur d'historique a beaucoup changé - il est tombé trois fois.
TimescaleDB vous permet d'insérer des données presque 3 fois plus rapidement et d'utiliser moins HistoryCache.
En conséquence, les données vous seront livrées en temps opportun.
TimescaleDB. 120 000 nvps
Ensuite, j'ai augmenté le nombre d'éléments de données à 500 000. La tâche principale était de vérifier les capacités de TimescaleDB - j'ai obtenu la valeur calculée de 125 000 valeurs par seconde.
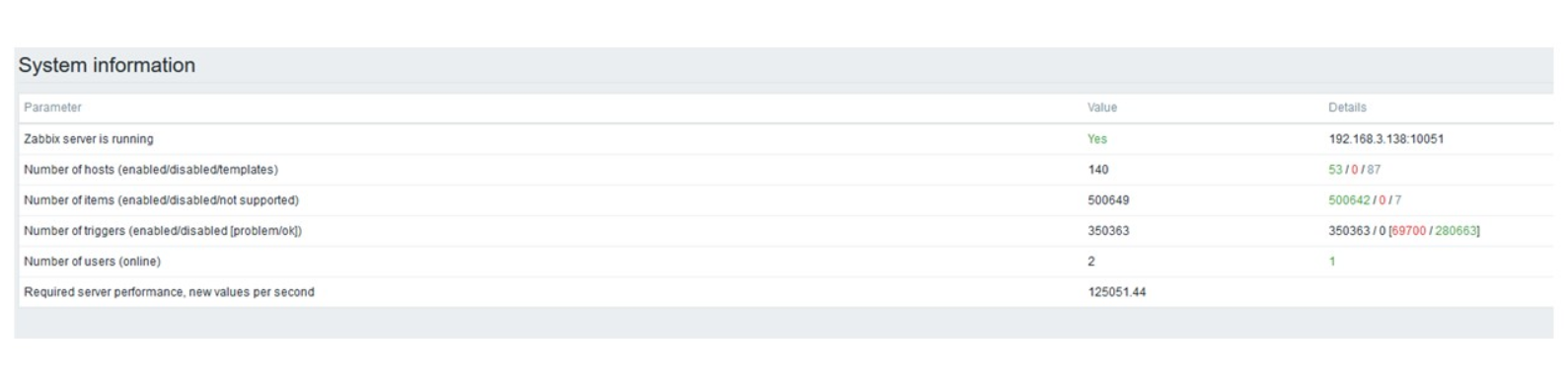
Il s'agit d'une «configuration» fonctionnelle qui peut fonctionner pendant longtemps. Mais comme mon disque ne faisait que 1,5 To, je l'ai rempli en quelques jours.
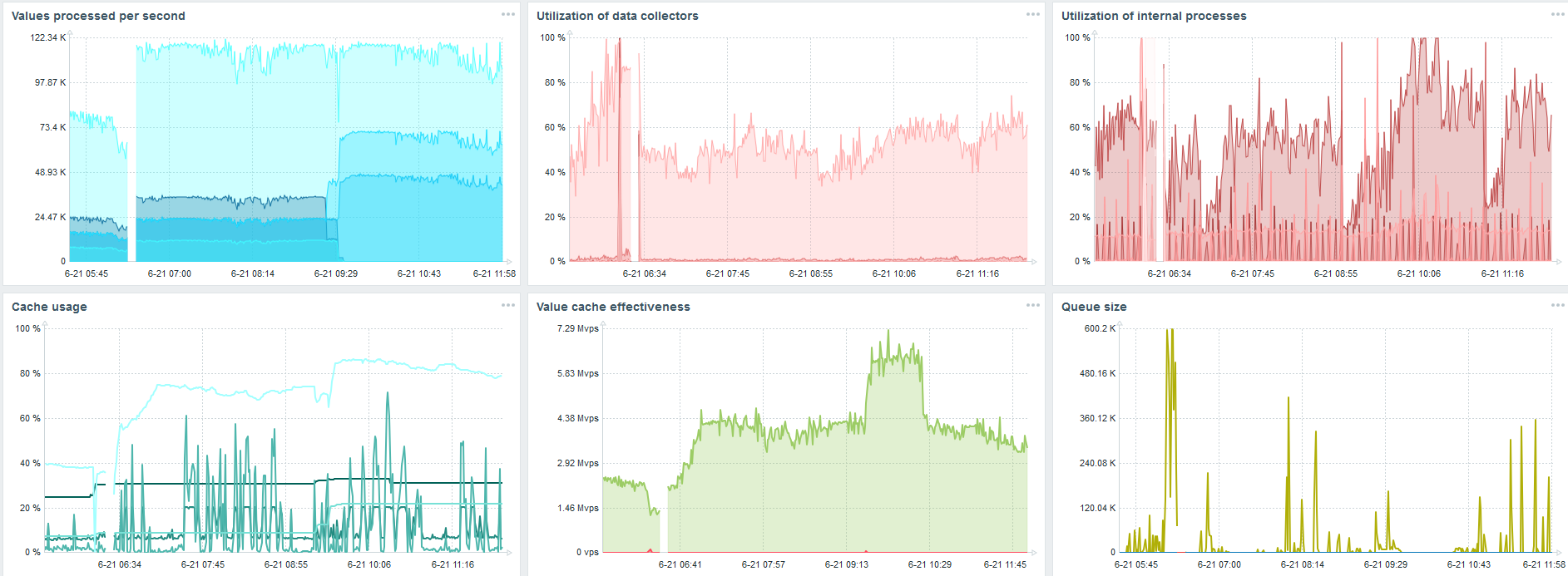
Plus important encore, en même temps, de nouvelles partitions TimescaleDB ont été créées.
Pour les performances, cela est complètement invisible. Lorsque des partitions sont créées dans MySQL, par exemple, tout est différent. Habituellement, cela se produit la nuit, car cela bloque l'insertion générale, en travaillant avec des tables et peut entraîner une dégradation du service. Dans le cas de TimescaleDB, ce n'est pas le cas.
Pour un exemple, je vais montrer un graphique de l'ensemble dans la communauté. TimescaleDB est inclus dans l'image, pour cette raison, la charge sur l'utilisation de io.weight sur le processeur a chuté. L'utilisation d'éléments de processus internes a également diminué. Et ceci est une machine virtuelle ordinaire sur des disques de crêpes ordinaires, pas un SSD.
Conclusions
TimescaleDB est une bonne solution pour les petites «configurations» qui dépendent des performances du disque. Il vous permettra de continuer à bien fonctionner jusqu'à ce que la base de données soit migrée pour repasser plus rapidement.
TimescaleDB est facile à configurer, améliore les performances, fonctionne bien avec Zabbix et
présente des avantages par rapport à PostgreSQL .
Si vous utilisez PostgreSQL et ne prévoyez pas de le changer, alors je recommande d'
utiliser PostgreSQL avec l'extension TimescaleDB en conjonction avec Zabbix . Cette solution fonctionne efficacement pour une «configuration» moyenne.
Nous disons «haute performance» - nous voulons dire HighLoad ++ . En attendant de se familiariser très brièvement avec les technologies et les pratiques qui permettent aux services de servir des millions d'utilisateurs. Nous avons déjà compilé une liste de rapports pour les 7 et 8 novembre, mais des mitaps peuvent toujours être proposés.
Abonnez-vous à notre newsletter et télégramme , dans lequel nous dévoilons les puces de la conférence à venir, et découvrez comment en tirer le meilleur parti.