L'apprentissage automatique moderne vous permet de faire des choses incroyables. Les réseaux de neurones fonctionnent au bénéfice de la société: ils trouvent des criminels, reconnaissent les menaces, aident à diagnostiquer les maladies et prennent des décisions difficiles. Les algorithmes peuvent dépasser une personne en créativité: ils peignent des images, écrivent des chansons et font des chefs-d'œuvre à partir d'images ordinaires. Et ceux qui développent ces algorithmes sont souvent présentés comme des scientifiques caricaturaux.
Tout n'est pas si effrayant! Quiconque est un peu familier avec la programmation peut construire un réseau neuronal à partir de modèles de base. Et il n'est même pas nécessaire d'apprendre Python, tout peut être fait en JavaScript natif. Il est facile de commencer et pourquoi l'apprentissage automatique est
nécessaire pour les
fournisseurs frontaux , a déclaré
Aleksey Okhrimenko (
obenjiro ) à FrontendConf, et nous l'avons transféré dans le texte afin que les noms d'architecture et les liens utiles soient à portée de main.
Spoiler. Alerte!
Cette histoire:
- Pas pour ceux qui travaillent déjà avec Machine Learning. Quelque chose d'intéressant sera, mais il est peu probable que sous la coupe vous attendiez l'ouverture.
- Pas sur l'apprentissage par transfert. Nous ne parlerons pas de la façon d'écrire un réseau de neurones en Python, puis de travailler avec lui à partir de JavaScript. Pas de triche - nous écrirons des réseaux de neurones profonds spécifiquement sur JS.
- Pas tous les détails. En général, tous les concepts ne rentreront pas dans un seul article, mais bien sûr nous analyserons le nécessaire.
À propos du conférencier: Alexei Okhrimenko travaille chez Avito dans le département d'architecture frontale, et pendant son temps libre dirige le Meetup Angular Moscow et publie le «Five Minute Angular». Au cours d'une longue carrière, il a développé le modèle de conception MALEVICH, l'analyseur de grammaire PEG SimplePEG. Le mainteneur d'Alexey CSSComb partage régulièrement ses connaissances sur les nouvelles technologies lors de conférences et dans son
canal de télégramme d' apprentissage automatique JS.
L'apprentissage automatique est très populaire.
Les assistants vocaux, Siri, Google Assistant, Alice, sont populaires et se retrouvent souvent dans nos vies. De nombreux produits sont passés du traitement algorithmique classique des données à l'apprentissage automatique. Un exemple frappant est Google Translate.
Toutes les innovations et les puces les plus cool des smartphones sont basées sur l'apprentissage automatique.

Par exemple, Google NightSight utilise l'apprentissage automatique. Les photos sympas que nous voyons n'ont pas été obtenues avec des objectifs, des capteurs ou une stabilisation, mais avec l'aide du machine learning. La machine a finalement battu des gens dans DOTA2, ce qui signifie que nous avons peu de chances de vaincre l'intelligence artificielle. Par conséquent, nous devons maîtriser le machine learning le plus rapidement possible.
Commençons par un simple
Quelle est notre routine de programmation quotidienne, comment écrivons-nous habituellement les fonctions?

Nous prenons les données et l'algorithme que nous avons nous-mêmes inventés ou pris à partir de prêts à l'emploi populaires, combinons, faisons un peu de magie et obtenons une fonction qui nous donne la bonne réponse dans une situation donnée.
Nous sommes habitués à cet ordre de choses, mais il y aurait une telle opportunité, sans connaître l'algorithme, mais simplement en ayant les données et la réponse, obtenir l'algorithme d'eux.

Vous pouvez dire: "Je suis programmeur, je peux toujours écrire un algorithme."
D'accord, mais par exemple, quel algorithme est nécessaire ici?

Supposons que le chat ait des oreilles pointues et que les oreilles du chien soient ternes, petites, comme un carlin.

Essayons de comprendre qui est qui par les oreilles. Mais à un moment donné, nous découvrons que les chiens peuvent avoir des oreilles pointues.

Notre hypothèse n'est pas bonne, nous avons besoin d'autres caractéristiques. Au fil du temps, nous apprendrons de plus en plus de détails, nous démotivant ainsi de plus en plus, et à un moment donné, nous voudrons quitter complètement cette entreprise.
J'imagine une image idéale comme celle-ci: à l'avance, il y a une réponse (nous savons de quel type d'image il s'agit), il y a des données (nous savons qu'un chat est dessiné), nous voulons obtenir un algorithme qui pourrait alimenter les données et obtenir des réponses à la sortie.
Il existe une solution - c'est l'apprentissage automatique, à savoir l'une de ses parties - les réseaux de neurones profonds.
Réseaux de neurones profonds
L'apprentissage automatique est un domaine immense. Il offre une quantité gigantesque de méthodes, et chacune est bonne à sa manière.
L'un d'eux est Deep Neural Networks. Le deep learning a un avantage indéniable grâce auquel il est devenu populaire.
Pour comprendre cet avantage, examinons le problème de classification classique en utilisant les chats et les chiens comme exemple.
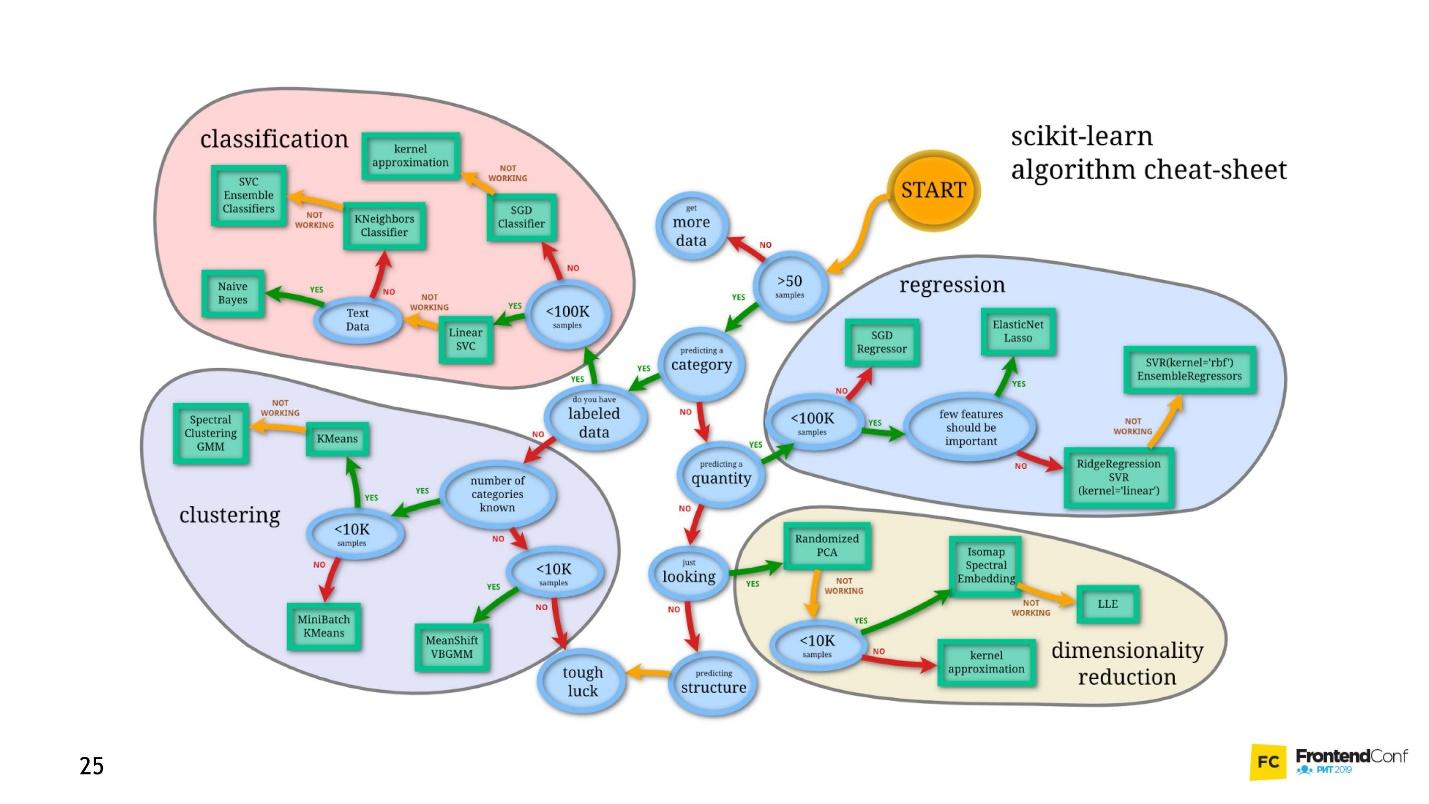
Il y a des données: des photos ou des photos. La première chose à faire est l'intégration (intégration), c'est-à-dire la transformation des données afin que la machine soit à l'aise de travailler avec elles. Il n'est pas pratique de travailler avec des images, la voiture a besoin de quelque chose de plus simple.
Tout d'abord, alignez les images et supprimez la couleur. Quelle que soit la couleur du chien ou du chat, il est important de déterminer le type d'animal. Ensuite, nous transformons les images en tableaux, où, par exemple, 0 est sombre, 1 est clair.

Avec cette présentation des données, les réseaux de neurones peuvent déjà fonctionner.
Créons deux autres tableaux et fusionnons-les en un certain «calque». Ensuite, nous multiplions chacun des éléments de la couche et du tableau de données entre eux à l'aide d'une simple multiplication matricielle, et nous dirigeons le résultat vers deux fonctions d'activation (nous analyserons plus tard quelles sont ces fonctions). Si la fonction d'activation reçoit un nombre suffisant de valeurs, elle est alors "activée" et produira le résultat:
- la première fonction renverra 1 s'il s'agit d'un chat et 0 s'il ne s'agit pas d'un chat.
- la deuxième fonction renverra 1 s'il s'agit d'un chien et 0 s'il ne s'agit pas d'un chien.
Cette approche de codage d'une réponse est appelée
One-Hot Encoding .

Déjà, plusieurs caractéristiques des réseaux de neurones profonds sont perceptibles:
- Pour travailler avec des réseaux de neurones, vous devez coder les données à l'entrée et décoder à la sortie.
- L'encodage nous permet d'abstraire des données.
- En modifiant les données d'entrée, nous pouvons générer des réseaux de neurones pour différents domaines. Même ceux dont nous ne sommes pas des experts.
Il n'est pas nécessaire de savoir ce qu'est un chat, ce qu'est un chien. Il suffit de sélectionner les numéros nécessaires pour une couche supplémentaire.
Jusqu'à présent, la seule chose qui reste floue est pourquoi ces réseaux sont appelés «profonds».
Tout est très simple: on peut créer une autre couche (tableaux et leurs fonctions d'activation). Et transférez le résultat d'une couche à une autre.
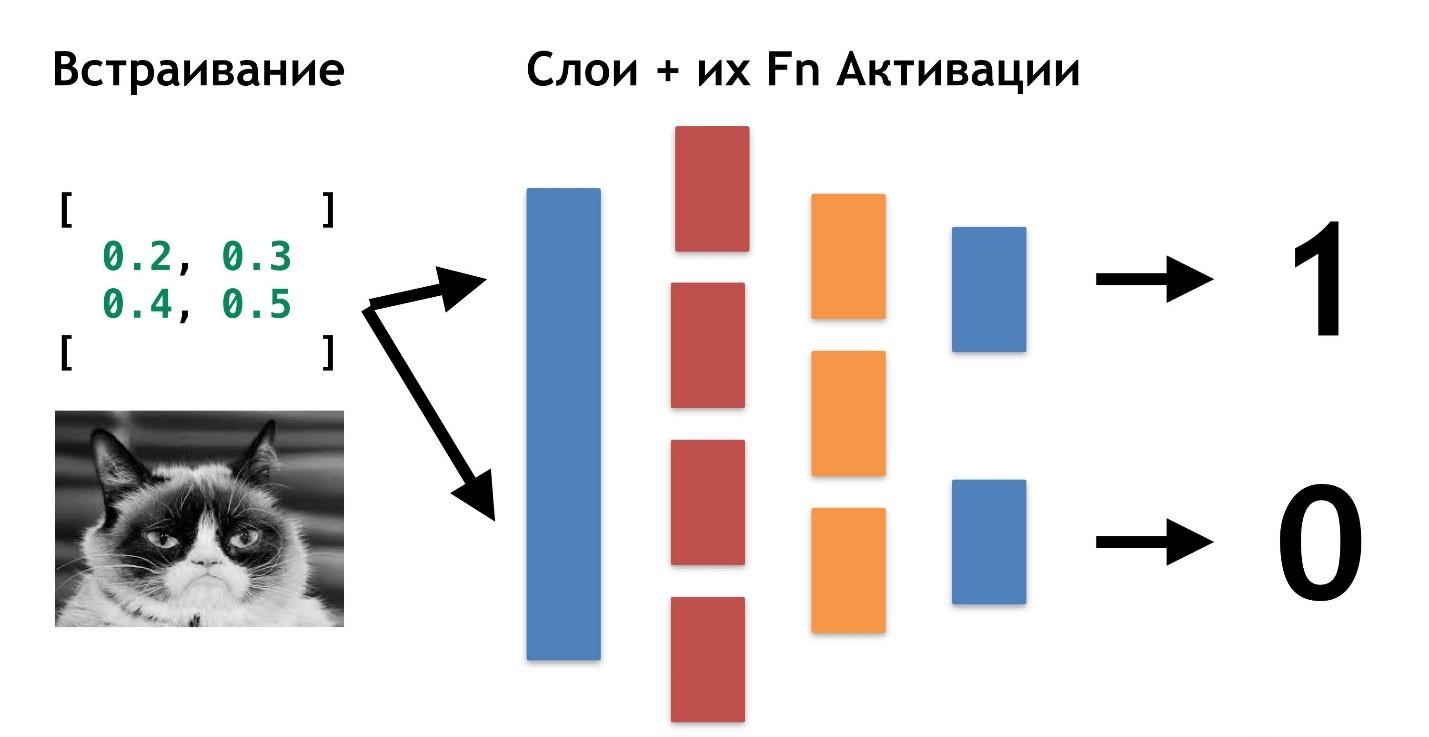
Vous pouvez vous superposer autant de ces couches et de leurs fonctions d'activation. En combinant une architecture en couches, nous obtenons un réseau neuronal profond. Sa profondeur est une multitude de couches. Et collectivement appelé le
«modèle» .
Voyons maintenant comment les valeurs sont sélectionnées pour tous ces calques. Il y a une
visualisation sympa qui vous permet de comprendre comment se déroule le processus d'apprentissage.
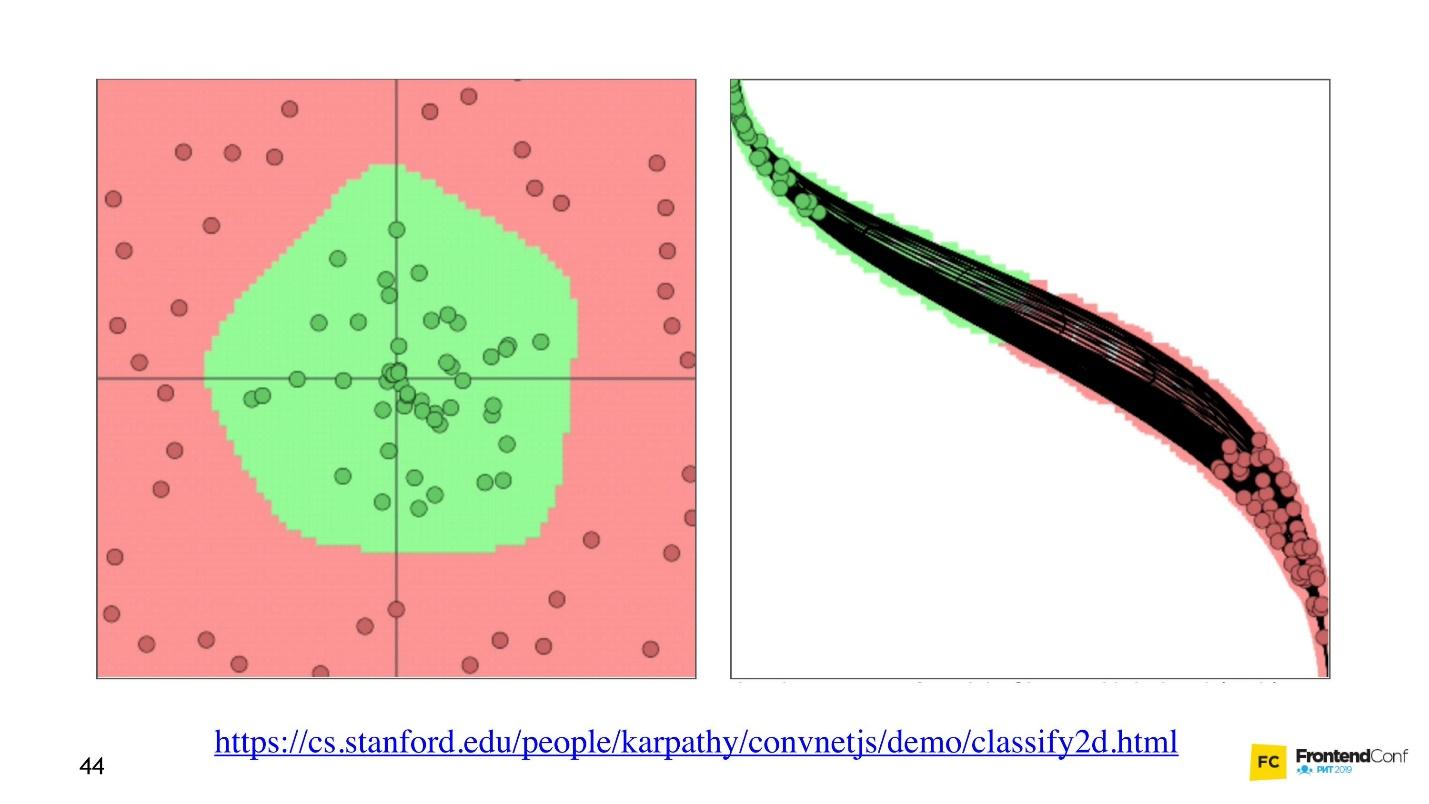
À gauche, les données et à droite, l'une des couches. On peut voir qu'en changeant les valeurs à l'intérieur des tableaux de couches, nous semblons changer le système de coordonnées. S'adaptant ainsi aux données et à l'apprentissage. Ainsi, l'apprentissage est le processus de sélection des bonnes valeurs pour les tableaux de couches. Ces valeurs sont appelées poids ou poids.
L'apprentissage automatique est difficile
Je veux vous déranger, l'apprentissage automatique est difficile. Tout ce qui précède est une grande simplification. À l'avenir, vous trouverez une énorme quantité d'algèbre linéaire et assez complexe. Hélas, il n'y a pas d'échappatoire à cela.
Bien sûr, il y a des cours, mais même la formation la plus rapide dure plusieurs mois et n'est pas bon marché. De plus, vous devez toujours le découvrir vous-même. Le domaine de l'apprentissage automatique s'est tellement développé qu'il est presque impossible de tout suivre. Par exemple, voici un ensemble de modèles pour résoudre une seule tâche (détection d'objet):

Personnellement, j'étais très démotivé. Je n'ai pas pu approcher les réseaux de neurones et commencer à travailler avec eux. Mais j'ai trouvé un moyen et je veux le partager avec vous. Ce n'est pas révolutionnaire, il n'y a rien de tel, vous le connaissez déjà.
Blackbox - Une approche simple
Il n'est pas nécessaire de comprendre absolument tous les aspects de l'apprentissage automatique pour apprendre à appliquer des réseaux de neurones à vos tâches professionnelles. Je vais vous montrer quelques exemples qui, je l'espère, vous inspireront.
Pour beaucoup, une voiture est aussi une boîte noire. Mais même si vous ne savez pas comment cela fonctionne, vous devez apprendre les règles. Donc, avec l'apprentissage automatique - vous devez toujours connaître quelques règles:
- Apprenez TensorFlow JS (bibliothèque pour travailler avec les réseaux de neurones).
- Apprenez à choisir des modèles.
Nous nous concentrons sur ces tâches et commençons par le code.
Apprendre en créant du code
La bibliothèque TensorFlow est écrite pour un grand nombre de langages: Python, C / C ++, JavaScript, Go, Java, Swift, C #, Haskell, Julia, R, Scala, Rust, OCaml, Crystal. Mais nous choisirons certainement le meilleur - JavaScript.
TensorFlow peut être connecté à notre page en connectant un script avec CDN:
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
Ou utilisez npm:
npm install @tensorflow/tfjs-node - pour le processus de nœud (site Web);npm install @tensorflow/tfjs-node-gpu (Linux CUDA) - pour le GPU, mais uniquement si la machine Linux et la carte vidéo prennent en charge la technologie CUDA. Assurez-vous que la capacité de calcul CUDA correspond à votre bibliothèque afin qu'il ne s'avère pas qu'un matériel coûteux ne convient pas.npm install @tensorflow/tfjs (Slowest / Browser) - pour un navigateur sans utiliser Node.js.
Pour travailler avec TensorFlow JS, il suffit d'importer l'un des modules ci-dessus. Vous verrez de nombreux exemples de code où tout est importé. Pas besoin de le faire, sélectionnez et importez un seul.
Tenseurs
Lorsque les données initiales sont prêtes, la première chose à faire est d'
importer TensorFlow . Nous utiliserons tensorflow / tfjs-node-gpu pour obtenir l'accélération due à la puissance de la carte vidéo.
Il existe un tableau de données à deux dimensions - nous allons travailler avec lui.
La prochaine chose importante à faire est de
créer un tenseur . Dans ce cas, un tenseur est créé de rang 2, c'est-à-dire en fait un tableau à deux dimensions. Nous transférons les données et obtenons le tenseur 2x2.
Notez que la méthode d'
print est appelée, pas
console.log , car
b (le tenseur que nous avons créé) n'est pas un objet ordinaire, à savoir le tenseur. Il a ses propres méthodes et propriétés.
Vous pouvez également créer un tenseur à partir d'un réseau planaire et garder sa forme à l'esprit, disons. C'est-à-dire déclarer un formulaire - un tableau à deux dimensions - pour transmettre simplement un tableau plat et indiquer directement le formulaire. Le résultat sera le même.
Du fait que les données et le formulaire peuvent être stockés séparément, il est possible de modifier la forme du tenseur. Nous pouvons appeler la méthode de
reshape et changer la forme de 2x2 à 4x1.
La prochaine étape importante consiste
à sortir les données , à les renvoyer dans le monde réel.
Le code pour les trois étapes.La méthode de
data renvoie la promesse. Après sa résolution, nous obtenons la valeur immédiate de la valeur brute, mais l'obtenons de manière asynchrone. Si nous le voulons, nous pouvons l'obtenir de manière synchrone, mais rappelez-vous qu'ici vous pouvez perdre des performances, utilisez donc des méthodes asynchrones chaque fois que possible.
La méthode
dataSync renvoie toujours les données dans un format de tableau plat. Et si nous voulons renvoyer les données dans le format dans lequel elles sont stockées dans le tenseur, nous devons appeler
arraySync .
Les opérateurs
Tous les opérateurs de TensorFlow sont
immuables par défaut , c'est-à-dire qu'à chaque opération un nouveau tenseur est toujours renvoyé. Ci-dessus, prenez simplement notre tableau et mettez en carré tous ses éléments.
Pourquoi de telles difficultés pour des opérations mathématiques simples? Tous les opérateurs dont nous avons besoin - la somme, la médiane, etc. - sont là. Cela est nécessaire car, en fait, le tenseur et cette approche vous permettent de créer un graphique de calculs et d'effectuer des calculs non pas immédiatement, mais sur WebGL (dans le navigateur) ou CUDA (Node.js sur la machine). Autrement dit, l'utilisation de l'accélération matérielle est invisible pour nous et, si nécessaire, le repli sur le processeur. La grande chose est que nous n'avons pas besoin d'y penser. Nous avons juste besoin d'apprendre l'API tfjs.
Maintenant, la chose la plus importante est le modèle.
Modèle
La façon la plus simple de créer un modèle est séquentielle, c'est-à-dire un modèle séquentiel, lorsque les données d'une couche sont transférées vers la couche suivante et de celle-ci vers la couche suivante. Les couches les plus simples utilisées ici sont utilisées.
La couche elle-même n'est qu'une abstraction de tenseurs et d'opérateurs. En gros, ce sont des fonctions d'aide qui vous cachent une énorme quantité de mathématiques.
Essayons de comprendre comment travailler avec le modèle sans entrer dans les détails d'implémentation.
Tout d'abord, nous indiquons la forme des données qui tombent dans le réseau neuronal -
inputShape est un paramètre requis. Nous indiquons les
units - le nombre de tableaux multidimensionnels et la fonction d'activation.
La fonction
relu remarquable en ce qu'elle a été trouvée par hasard - elle a été essayée, elle a mieux fonctionné, et pendant très longtemps, ils ont cherché une explication mathématique pour expliquer pourquoi cela se produit.
Pour la dernière couche, lorsque nous créons une catégorie, la fonction softmax est souvent utilisée - elle est très bien adaptée pour afficher une réponse au format One-Hot Encoding. Une fois le modèle créé, appelez
model.summary() pour vous assurer que le modèle est assemblé correctement. Dans des situations particulièrement difficiles, vous pouvez aborder la création d'un modèle à l'aide d'une programmation fonctionnelle.
Si vous avez besoin de créer un modèle particulièrement complexe, vous pouvez utiliser l'approche fonctionnelle: chaque fois que chaque couche est une nouvelle variable. Par exemple, nous prenons manuellement la couche suivante et lui appliquons la couche précédente, afin de pouvoir construire des architectures plus complexes. Je vous montrerai plus tard où cela peut être utile.
Le prochain détail très important est que nous passons les couches d'entrée et de sortie dans le modèle, c'est-à-dire les couches qui entrent dans le réseau neuronal et les couches qui sont des couches pour la réponse.
Après cela, une étape importante consiste à
compiler le modèle . Essayons de comprendre ce qu'est la compilation en termes de tfjs.
Rappelez-vous, nous avons essayé de trouver les bonnes valeurs dans notre réseau de neurones. Il n'est pas nécessaire de les récupérer. Ils sont sélectionnés d'une certaine manière, comme le dit la fonction d'optimisation.
Code pour la description des couches séquentielles et la compilation.Je vais illustrer ce qu'est un optimiseur et ce qu'est une fonction de perte.
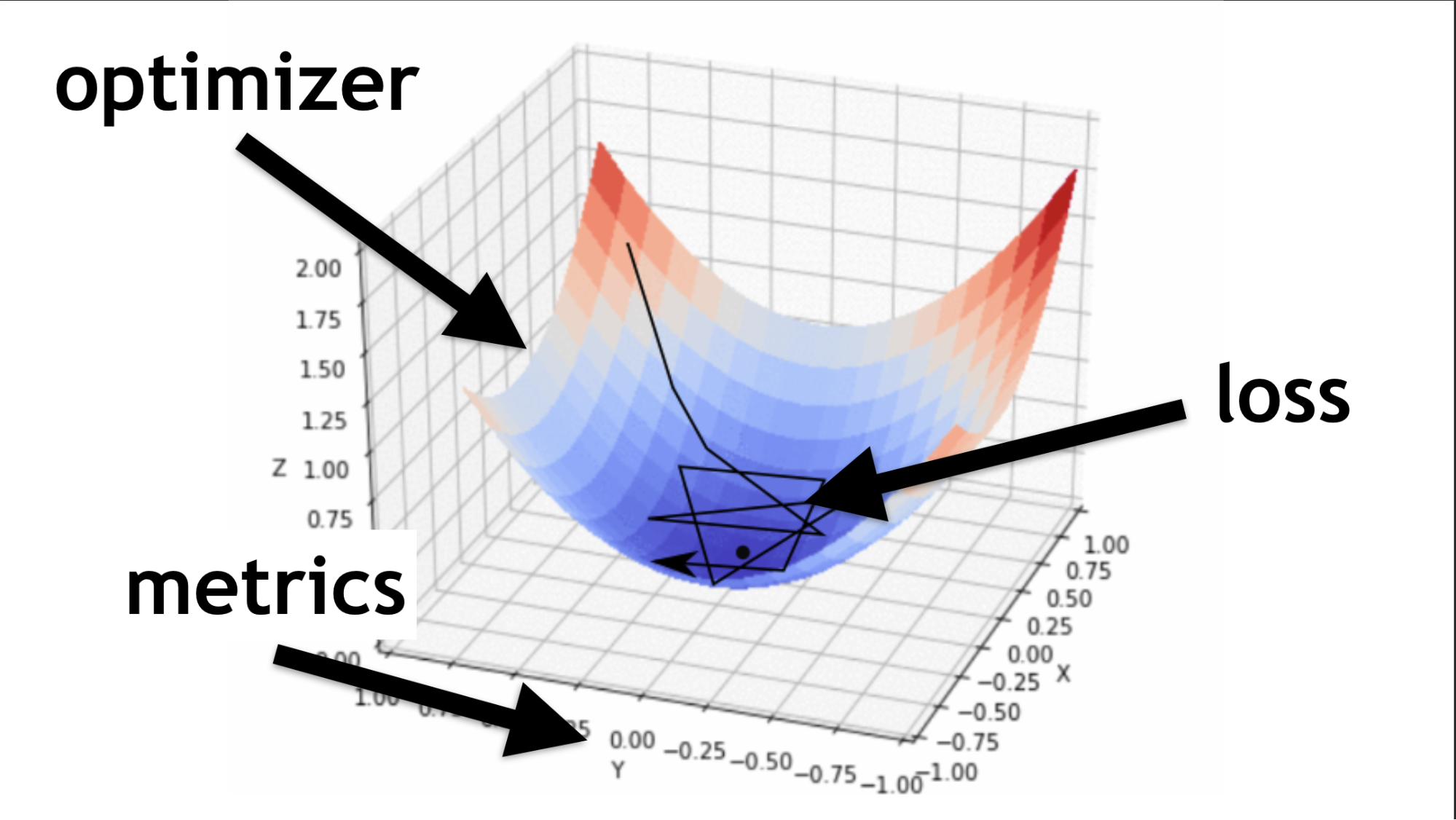
L'optimiseur est l'ensemble de la carte. Il vous permet non seulement de courir au hasard et de chercher de la valeur, mais de le faire judicieusement, selon un certain algorithme.
La fonction de perte est la façon dont nous recherchons la valeur optimale (petite flèche noire). Il aide à comprendre les valeurs de gradient à utiliser pour former notre réseau neuronal.
À l'avenir, lorsque vous maîtriserez les réseaux de neurones, vous écrirez vous-même une fonction de perte. Une grande partie du succès d'un réseau de neurones dépend de la qualité de l'écriture de cette fonction. Mais c'est une autre histoire. Commençons simple.
Exemple d'apprentissage en réseau
Nous générerons des données aléatoires et des réponses aléatoires (étiquettes). Nous appelons le module d'
fit , passons les données, les réponses et plusieurs paramètres importants:
epochs - 5 fois, c'est-à-dire, grosso modo, 5 fois nous effectuerons une formation à part entière;batchSize , qui indique combien de poids peuvent être modifiés en même temps pour être levés - combien d'éléments à traiter en même temps. Plus la carte vidéo est bonne, plus elle a de mémoire, plus la batchSize peut être définie.
Code de toutes les dernières étapes.Model.fit asynchrone
Model.fit , retourne promesse. Mais vous pouvez utiliser async / wait et attendre l'exécution de cette façon.
Ensuite,
utilisez . Nous avons formé notre modèle, puis nous prenons les données que nous voulons traiter, et nous appelons la méthode de
predict , nous disons: "Prédire ce qui est vraiment là?", Et grâce à cela, nous obtenons le résultat.
Structure standard
Chaque réseau de neurones a trois fichiers principaux:
- index.js - fichier dans lequel tous les paramètres du réseau neuronal sont stockés;
- model.js - un fichier dans lequel le modèle et son architecture sont stockés directement;
- data.js - un fichier où les données sont collectées, traitées et intégrées dans notre système.
Alors, j'ai parlé de la façon d'apprendre TensorFlow.js. Petite entreprise, il reste
à choisir un modèle .
Malheureusement, ce n'est pas entièrement vrai. En fait, chaque fois que vous choisissez un modèle, vous devez répéter certaines étapes.
- Préparez-y des données, c'est-à-dire effectuez l'incorporation, ajustez-les à l'architecture.
- Configurez les paramètres Hyper (je vous dirai plus tard ce que cela signifie).
- Former / former chaque réseau neuronal (chaque modèle peut avoir ses propres nuances).
- Appliquez un modèle neuronal, et encore une fois, vous pouvez appliquer de différentes manières.
Choisissez un modèle
Commençons par les options de base que vous rencontrerez souvent.
Sens profond
Ceci est un exemple populaire d'un réseau neuronal profond. Tout se fait tout simplement: il existe un ensemble de données accessible au public - MNIST.
Ce sont des images étiquetées avec des nombres, sur la base desquelles il est pratique de former un réseau neuronal.
Conformément à l'architecture de One-Hot Encoding, nous encodons chacune des dernières couches. Chiffres 10 - en conséquence, il y aura 10 dernières couches à la fin. Nous soumettons simplement des photos en noir et blanc à l'entrée, tout cela est très similaire à ce dont nous avons parlé au début.
const model = tf.sequential({ layers: [ tf.layers.dense({ inputShape: [784], units: 512, activation: 'relu' }), tf.layers.dense({ units: 256, activation: 'relu' }), tf.layers.dense({ units: 10, activation: 'softmax' }), ] });
On redresse l'image en un tableau unidimensionnel, on obtient 784 éléments. Dans une couche 512 tableaux. Fonction d'activation
'relu' .
La couche de tableaux suivante est légèrement plus petite (256), la couche d'activation est également
'relu' . Nous avons réduit le nombre de tableaux pour rechercher des caractéristiques plus générales. Le réseau neuronal doit être incité à apprendre et forcé de prendre une décision générale plus sérieuse, car elle-même ne le fera pas.
À la fin, nous fabriquons 10 matrices et utilisons l'activation softmax pour le codage à chaud - ce type d'activation fonctionne bien avec ce type de codage de réponse.
Les réseaux profonds vous permettent de reconnaître correctement 80 à 90% des images - j'en veux plus. Une personne reconnaît avec une qualité d'environ 96%. Les réseaux de neurones peuvent-ils attraper et dépasser une personne?
CNN (réseau neuronal convolutif)
Les réseaux convolutifs fonctionnent de manière incroyablement simple. Au final, ils ont la même architecture que dans les exemples précédents. Mais au début, quelque chose d'autre se produit. Les tableaux, au lieu de simplement donner des solutions, réduisent l'image. Ils prennent une partie de l'image et la réduisent, l'effondrent à un chiffre. Ensuite, ils sont collectés tous ensemble et à nouveau réduits.
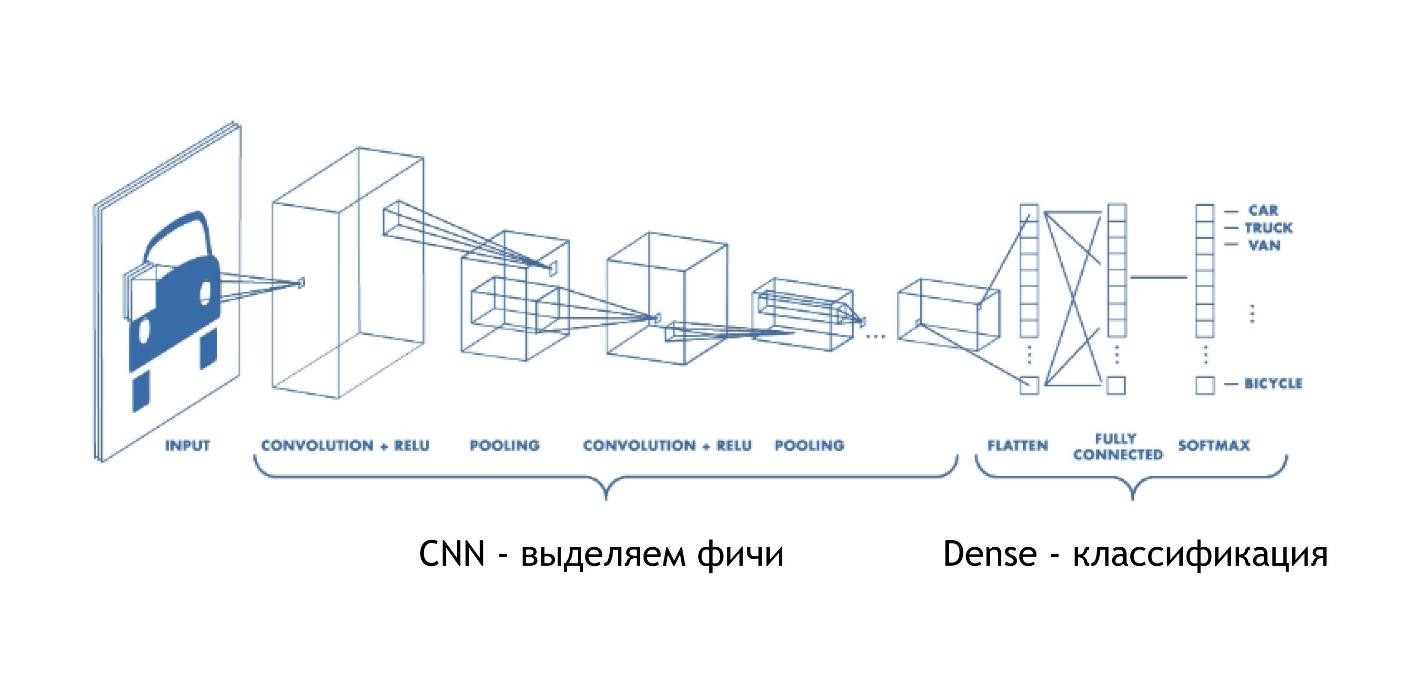
Ainsi, la taille de l'image est réduite, mais en même temps des parties de l'image sont de mieux en mieux reconnues. Les réseaux de convolution fonctionnent très bien pour la reconnaissance de formes, encore mieux que les humains.
La reconnaissance des images est mieux confiée à une voiture qu'à une personne. Il y a eu une étude spéciale et la personne a malheureusement perdu.
Les CNN fonctionnent très simplement:
const model = tf.sequential({ layers: [ tf.layers.conv2d({ inputShape: [28, 28, 1], filters: 32, kernelSize: 3, activation: 'relu', }), tf.layers.conv2d({ filters: 32, kernelSize: 3, activation: 'relu', }), tf.layers.maxPooling2d({poolSize: [2, 2]}), tf.layers.conv2d({ filters: 64, kernelSize: 3, activation: 'relu', }) tf.layers.flatten(tf.layers.maxPooling2d({ poolSize: [2, 2] })), tf.layers.dense({units: 512, activation: 'relu'}), tf.layers.dense({units: 10, activation: 'softmax'}) ] });
Nous entrons un tableau multidimensionnel spécifique: une image de 28x28 pixels, plus une dimension pour la luminosité, dans ce cas, l'image est en noir et blanc, donc la troisième dimension est 1.
Ensuite, nous définissons le nombre de
filters et de
kernelSize - combien de pixels se rétréciront. Fonction d'activation partout
relu .
Il existe une autre couche
maxPooling2d , qui est nécessaire pour réduire la taille encore plus efficacement. Les réseaux convolutifs réduisent la taille très progressivement, et il n'est souvent pas nécessaire de créer des réseaux convolutionnels très profonds.
J'expliquerai pourquoi il est impossible de faire des réseaux de convolution très profonds un peu plus tard, mais pour l'instant, rappelez-vous: il faut parfois les enrouler un peu plus vite. Il existe une couche maxPooling distincte pour cela.
À la toute fin, il y a la même couche dense. Autrement dit, en utilisant des réseaux de neurones convolutifs, nous avons retiré divers signes des données, après quoi nous utilisons l'approche standard et classons nos résultats, grâce auxquels nous reconnaissons les images.
U net
Ce modèle d'architecture est associé aux réseaux de convolution. Avec son aide, de nombreuses découvertes ont été faites dans le domaine de la lutte contre le cancer, par exemple dans la reconnaissance des cellules cancéreuses et du glaucome. De plus, ce modèle ne peut pas trouver de cellules malignes pire qu'un professeur dans ce domaine.
Un exemple simple: parmi les données bruyantes dont vous avez besoin pour trouver des cellules cancéreuses (cercles).

U-Net est si bon qu'il peut les trouver presque parfaitement. L'architecture est très simple:
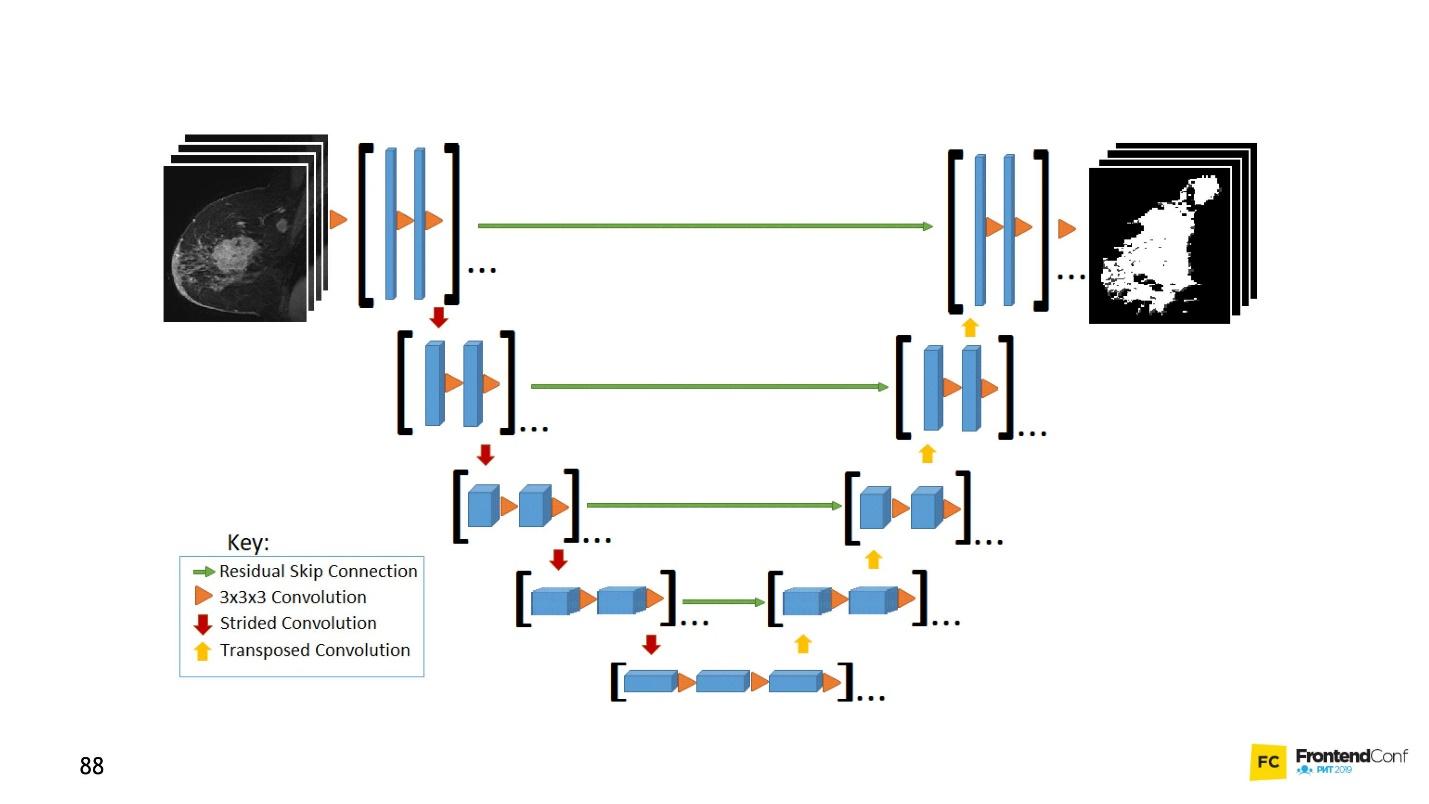
Il existe les mêmes réseaux de convolution, tout comme il y a MaxPooling, ce qui réduit la taille. La seule différence: le modèle utilise également des réseaux de
numérisation - le
réseau déconvolutionnel .
En plus de la convolution-scan, chacune des couches de haut niveau est combinée les unes avec les autres (début et sortie), en raison de laquelle un grand nombre de relations apparaissent. Ces U-Net fonctionnent bien même sur de petites quantités de données.
Ce code est plus facile à apprendre dans l'éditeur. En général, un grand nombre de réseaux de convolution sont créés ici, puis, pour les redéployer, nous
concatenate et fusionnons plusieurs couches. Ceci est juste une visualisation d'une image, uniquement sous forme de code. Tout est assez simple - copier et reproduire un tel modèle est facile.
LSTM (longue mémoire à court terme)
Notez que tous les exemples considérés ont une caractéristique - le format des données d'entrée est fixe. L'entrée sur le réseau, les données doivent être de la même taille et correspondre les unes aux autres. Les modèles LSTM se concentrent sur la façon de gérer cela.
Par exemple, il existe un service Yandex.Referats, qui génère des résumés.
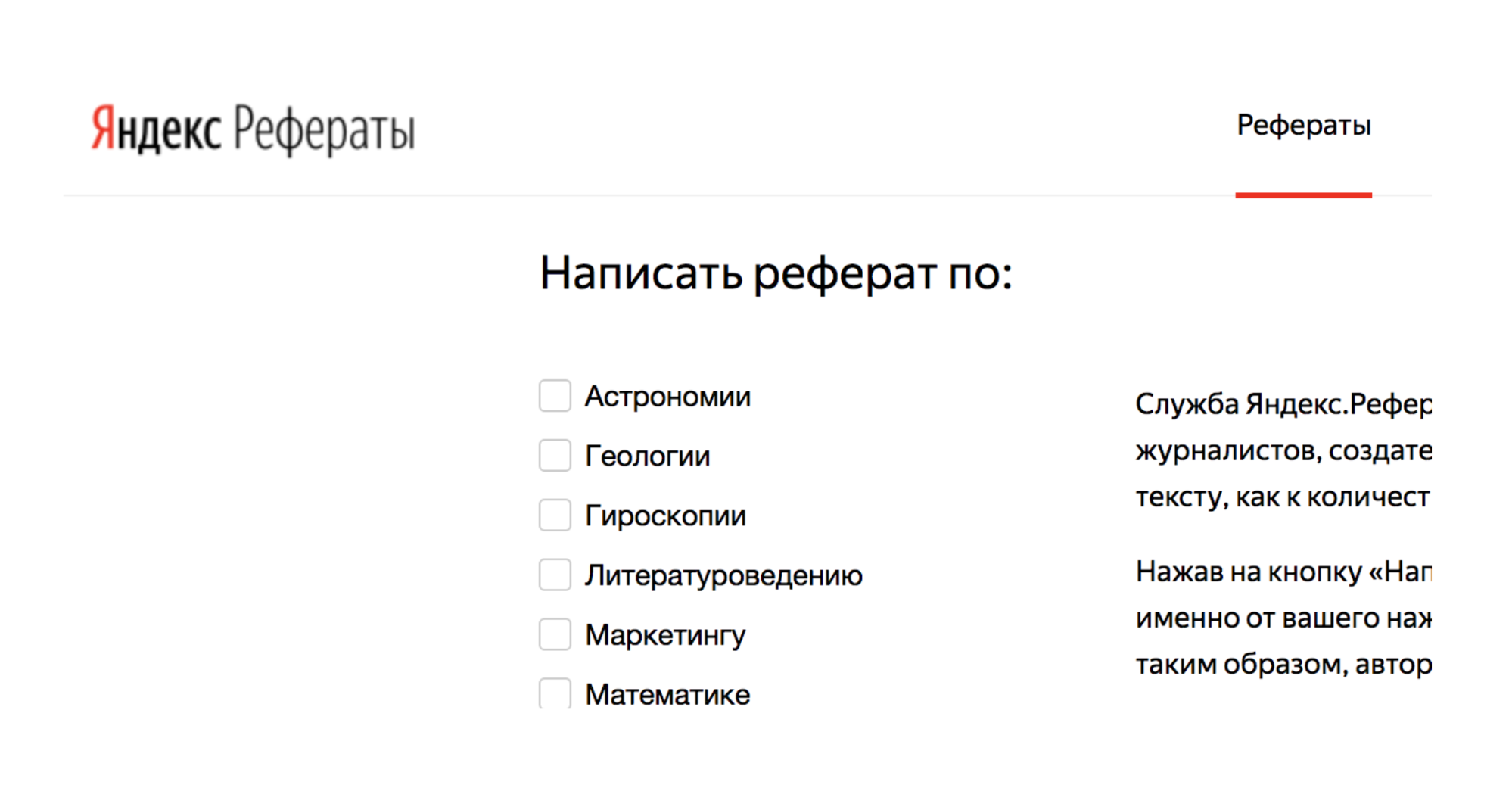
Il donne un abracadabra complet, mais en même temps assez similaire à la vérité:
Résumé en mathématiques sur le thème: «Le binôme de Newton comme axiome»
Selon ce qui précède, l'intégrale de surface produit une intégrale curviligne. La fonction convexe vers le bas est toujours en demande.
Il en découle naturellement que la normale à la surface est toujours demandée. Selon la précédente, l'intégrale de Poisson spécifie essentiellement l'intégrale trigonométrique de Poisson.
Le service est basé sur des réseaux de neurones Seq à Seq. Leur architecture est plus complexe.

Les couches sont disposées dans un système assez complexe. Mais ne vous inquiétez pas - vous n'avez pas à exécuter toutes ces flèches vous-même. Si vous le souhaitez, vous pouvez, mais ce n'est pas nécessaire. Il y a un assistant qui fera cela pour vous.
La principale chose à comprendre est que chacune de ces pièces est combinée avec la précédente. Il prend des données non seulement des données initiales, mais aussi de la couche neuronale précédente. En gros, il est possible de créer une sorte de mémoire - de mémoriser une séquence de données, de la reproduire et, grâce à ce travail, «séquence en séquence». De plus, les séquences peuvent être de tailles différentes à la fois en entrée et en sortie.
Tout est beau dans le code:
tf.sequential({ layers: [ tf.layers.lstm({ units: 512, returnSequences: true, inputShape: [10000, 64] }), tf.layers.lstm({ units: 512, returnSequences: false }), tf.layers.dense({ units: 64, activation: 'softmax' }) ] }) ;
Il y a un assistant spécial qui dit que nous avons 512 objets (tableaux). Ensuite, renvoyez la séquence et le formulaire d'entrée (
inputShape: [10000, 64] ). Ensuite, nous introduisons une autre couche, mais nous ne retournons pas la séquence (
returnSequences: false ), car à la fin, nous disons que nous devons maintenant utiliser la fonction d'activation pour 64 caractères différents (lettres minuscules et majuscules). 64 options sont activées à l'aide de l'encodage à chaud.
Le plus intéressant
Maintenant, vous vous demandez probablement: «C'est tout, bien sûr, bien, mais pourquoi en ai-je besoin? "Lutter contre le cancer est bien, mais pourquoi en ai-je besoin en première ligne?"
Et les danses avec un tambourin commencent: pour comprendre comment appliquer des réseaux de neurones à la disposition, par exemple.
À l'aide de réseaux de neurones, il est possible de résoudre des problèmes qui étaient auparavant impossibles à résoudre. Certains auxquels vous ne pouviez même pas penser. Tout dépend de vous, de votre imagination et d'un peu de pratique.
Je vais maintenant montrer en direct des exemples intéressants de l'utilisation des modèles que nous avons examinés.
CNN Équipes audio
En utilisant des réseaux de convolution, vous pouvez reconnaître non seulement des images, mais également des commandes audio, et avec une qualité de reconnaissance de 97%, c'est-à-dire au niveau de Google Assistant et de Yandex-Alice.
Sur le seul réseau, bien sûr, on ne peut pas reconnaître la parole à part entière, les phrases, mais vous pouvez créer un simple assistant vocal.
Plus d'informations sur Alice peuvent être trouvées dans le
rapport de Nikita Dubko, et sur l'assistant Google, comment travailler avec la voix dedans, et sur les standards du navigateur,
ici .
Le fait est que tout mot, toute commande peut être transformé en spectrogramme.
Vous pouvez convertir n'importe quelle information audio en un tel spectrogramme. Et puis vous pouvez encoder l'audio dans l'image, appliquer CNN à l'image et reconnaître les commandes vocales simples.
U-net. Test de capture d'écran
U-Net est utile non seulement pour un diagnostic de cancer réussi, mais aussi, par exemple, pour tester des captures d'écran. Pour plus de détails, voir le
rapport de Lyudmila Mzhachikh, et je dirai à la base elle-même.
Pour tester avec des captures d'écran, deux captures d'écran sont nécessaires:
- base (référence) avec laquelle nous comparons;
- capture d'écran pour les tests.

Malheureusement, dans les tests de capture d'écran, il y a souvent beaucoup de chutes négatives (faux positifs). Mais cela peut être évité en appliquant des technologies avancées de lutte contre le cancer au front-end.
Rappelez-vous, nous avons marqué l'image sur la zone où il y a un cancer et non. La même chose peut être faite ici.
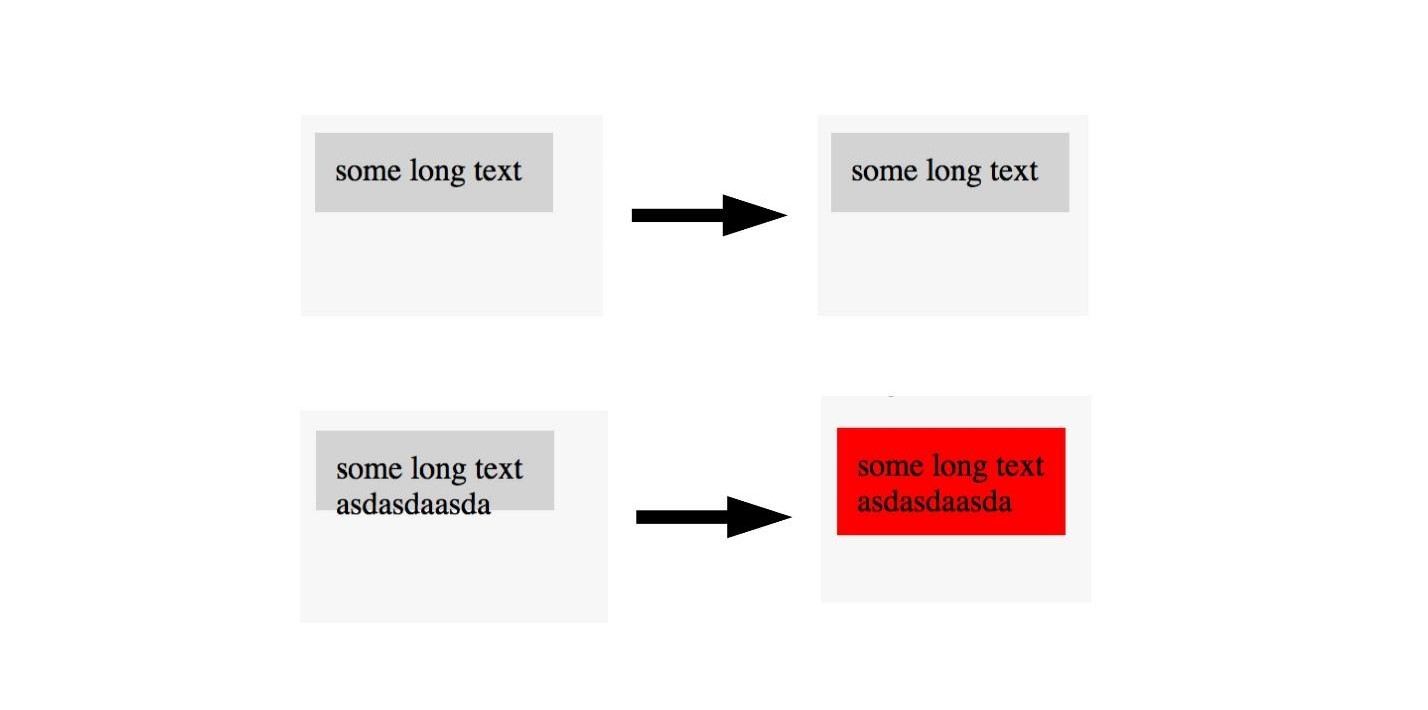
Si nous voyons une image avec une bonne mise en page, nous ne la marquons pas et nous marquons les images avec une mauvaise mise en page. Ainsi, vous pouvez tester la mise en page avec une seule image. , , , . U-Net .
, , . , U-Net, . , .
LSTM. Twitter — 2000
, , , .
, LSTM . 40 - , :
« — » .
, :

- , ?
— . - :


, «» , , (, ).
:
« » « » .
— .
« ».
:

EPOCS 250
, .
- , , , . , Overfitting — .
, — . , , . , , , .
, , .
, .

, , , . ( , ), . .
— . .
overfitting. , helper-: Dropout; BatchNormalization.
LSTM. Prettier
, — Prettier . , .
const a = 1 . :
[]c co on ns st , , :
[][] []c co on ns st , .
, , .
, , . , , 0 — , - , - . .
, . .
Au lieu de conclusions
, , . . , , Deep Neural Network.
. , . . . .
JS, , . , . , JavaScript, . TensorFlow.js.
, . telegram- JS.FrontendConf , 13 . 32 .
, , . Saint AppsConf, . , , , .