
Chaque jour, les utilisateurs de 2GIS nous aident à maintenir l'exactitude des données: ils informent sur les nouvelles sociétés, ajoutent des événements de trafic, téléchargent des photos et rédigent des avis. Auparavant, nous ne pouvions les remercier que par des mots ou organiser un cadeau. Mais au fil du temps, les mots sont oubliés et tout le monde ne reçoit pas de cadeaux. Par conséquent, nous avons décidé de nous assurer que tous ceux qui se soucient de 2GIS voient leur contribution au produit et notre gratitude pour cela.
Il y avait donc des récompenses - des médailles virtuelles que nous accumulons pour divers types de tâches: télécharger des photos sur des cartes de café, écrire des critiques sur les théâtres, spécifier les heures de travail des organisations, etc. Les utilisateurs voient les récompenses gagnées dans leur profil 2GIS personnel et sur l'onglet «Mon 2GIS» dans l'application mobile. Là, nous montrons combien il reste jusqu'à la prochaine réalisation.
Pour implémenter cette fonctionnalité, nous avons appris à traiter un flux d'événements avec un volume de 500 000 enregistrements par heure (par endroits jusqu'à 50 000 enregistrements par seconde) et à analyser les données de plusieurs services. Et aussi - ils ont ajouté un peu de métaprogrammation afin de simplifier la configuration lors du développement de nouvelles récompenses.
En collaboration avec
Rapter , nous vous dirons ce qui est sous le capot du processus d'attribution.
Concept
Afin de comprendre la complexité de la fonctionnalité, vous devez comprendre comment le problème technique a sonné. Ensuite, considérez l'idée de mise en œuvre et le schéma général des composants du système. C'est ce que nous allons faire dans cette section.
Conditions requises pour les résumés
Exigences - une chose plutôt ennuyeuse, donc nous ne peindrons pas toutes les nuances, nous nous concentrerons sur les choses les plus importantes:
- les récompenses ne sont accordées qu'aux utilisateurs autorisés;
- la mise à jour des progrès sur une récompense doit être aussi rapide que possible;
- récompense - le résultat d'un utilisateur effectuant un ensemble d'actions dans le produit: téléchargement d'une photo, rédaction d'un avis, recherche d'un itinéraire, etc. Il existe de nombreuses sources de données.
Idée architecturale
L'idée de mise en œuvre n'est pas très compliquée. Elle peut s'exprimer de manière thématique:
- l'attribution se compose de tâches dont les résultats sont combinés selon la formule spécifiée lors de la configuration de l'attribution;
- la tâche répond aux événements sur les actions des utilisateurs venant de l'extérieur, les filtre et enregistre le changement en cours sous forme de compteurs;
- Les «événements externes» sont générés par des systèmes maîtres (photo, rétroaction, services de raffinement, etc.) ou des services auxiliaires qui transforment ou filtrent des flux d'événements déjà existants;
- le traitement des événements se produit de manière asynchrone et peut être arrêté à tout moment si nécessaire;
- l'utilisateur voit l'état actuel de ses récompenses;
- tout le reste, ce sont les détails ...
Entités clés
Le diagramme ci-dessous montre les principales entités du domaine et leur relation:

Deux zones sont distinguées dans le schéma:
- Scheme - une zone pour décrire la structure des récompenses et les règles de leur accumulation;
- Données - Zone d'attribution pour des utilisateurs spécifiques et des données liées à leur statut actuel.
Les entités dans le diagramme:
- Atteindre - informations sur le prix qui peuvent être obtenues. Comprend des méta-informations et une description de la façon de combiner les résultats des tâches - une stratégie.
- Objectif - une tâche dont les conditions doivent être remplies pour progresser vers l'obtention d'un prix.
- UserAchieve - l'état actuel de la récompense pour un utilisateur particulier.
- UserObjective - l'état actuel du travail de récompense de l'utilisateur.
- Utilisateur - informations sur l'utilisateur, nécessaires pour les notifications et la compréhension de son état actuel (les récompenses à distance et interdites ne sont pas nécessaires).
- ProcessingLog - un journal des charges à payer pour les tâches. Contient des informations sur la manière dont une action spécifique a influencé la progression de la mission.
- Événement - les informations minimales nécessaires sur un événement qui ont influencé d'une manière ou d'une autre la progression des tâches de l'utilisateur.
Structure de service
Considérons maintenant les principaux composants du service et leurs dépendances:

- Bus d'événements - un bus d'événements qui peut être utilisé pour effectuer des tâches. Nous utilisons Apache Kafka.
- Les bases de données maître et esclave sont le principal entrepôt de données. Dans ce cas, un cluster PostgreSQL.
- ConsumingWorkers - gestionnaires d'événements de bus. La tâche principale consiste à lire les événements d'une source spécifique (photos, avis, etc.), à les appliquer aux tâches utilisateur et à enregistrer le résultat.
- AchievesWorker - raconte la progression des récompenses des utilisateurs en fonction de l'état des tâches.
- NotificationWorkers - un ensemble de gestionnaires pour planifier et envoyer des notifications sur la réception des récompenses, les annonces de nouvelles réalisations possibles, etc.
- API publique - une interface REST publique pour les applications Web et mobiles.
- API privée - Interface REST pour le panneau d'administration, qui aide à l'enquête sur les incidents et au support technique. Il est disponible pour les développeurs et les équipes de support.
Chacun des composants est isolé en termes de logique et de domaines de responsabilité, ce qui évite les intégrations inutiles et les blocages lors de la modification des données. Ci-dessous, nous ne considérons qu'une partie du schéma associé au traitement des événements et à leur conversion en récompenses.
Gestion des événements
Le contenu
Les récompenses sont principalement un service d'agrégation de données. Chaque système maître génère plusieurs types d'événements. En règle générale, chaque type d'événement est étroitement lié à l'état du contenu, à son modèle de statut. Ainsi, une photo peut être modérée, supprimée, bloquée, masquée ou active. Ce sont tous des événements différents qui sont gérés par un travailleur distinct spécialisé dans une source particulière. À l'heure actuelle, il existe une interaction avec les sources suivantes (systèmes maîtres):
- Photo - génère divers événements liés aux opérations effectuées par les utilisateurs sur des photographies.
- Avis - événements liés aux opérations sur les avis des utilisateurs.
- Datafeedback - événements liés aux opérations de raffinement. La clarification est un changement d'informations sur un objet sur une carte, que ce soit une entreprise ou un monument.
- Check - événements liés à l'application 2GIS Check.
- Les BSS sont des événements d'analyse qui génèrent des applications 2GIS. Par exemple, l'ouverture d'une certaine entreprise, des voyages sur le navigateur, etc.

Les événements générés par le système maître entrent dans le sujet Kafka dans l'ordre de changer leurs statuts, ce qui permet de faire avancer la récompense pour l'utilisateur non seulement en avant, mais aussi en arrière. Par exemple, si la photo était dans le statut «actif», puis qu'elle a acquis pour une raison quelconque le statut «bloquée», la progression de l'attribution devrait changer à la baisse. La progression des récompenses est une interprétation des objets internes appelés compteurs de contenu.
Les compteurs peuvent varier pour différentes données. Par exemple, pour les événements concernant la photo, ils sont les suivants: le nombre d'approbations, le nombre de modération, le nombre de blocages et pour les événements d'ouverture de cartes, vous devez considérer uniquement le nombre de cartes ouvertes par l'utilisateur. Sur la base des valeurs actuelles des compteurs de contenu, pour un utilisateur particulier, dans le cadre d'un prix spécifique, les réponses aux questions suivantes sont déterminées:
- Le prix a-t-il commencé?
- quel est le progrès
- La récompense est-elle entièrement terminée
Filtres et règles
Les compteurs d'emplois d'un prix particulier ne sont modifiés que si un événement est arrivé avec le type de contenu souhaité, ainsi qu'avec les données nécessaires pour recevoir le prix.
Afin de ne sauter que le contenu approprié pour le prix, nous organisons chaque événement à travers une série de filtres et de règles.
Un filtre est une certaine restriction imposée au contenu. Il ne souhaite que répondre à la question: «Un nouvel événement correspond-il ou non à cette condition?»
Une règle est un filtre spécial dont le but est de dire: "Si un événement correspond à la condition, alors comment les compteurs devraient-ils changer?" La règle comprend un algorithme pour changer les compteurs. Chaque prix contient une seule règle.
L'implémentation des filtres et des règles est dans le code du projet, et la description des filtres (règle) appartenant à un prix particulier est dans la base de données au format JSON. Nous n'avons pas pris une telle décision tout de suite. Initialement, les filtres et les règles ne pouvaient pas être définis à l'aide de la configuration via la base de données, l'attribution était entièrement décrite dans le code, seul son identifiant était stocké dans la table. Cette décision présente un certain nombre d'inconvénients importants:
- Le problème de la prise en charge de plusieurs environnements. Si vous souhaitez déployer un état de la liste des récompenses dans l'environnement de test et en envoyer un autre au combat, vous devez connaître le code d'environnement dans le code du projet ou disposer d'un fichier de configuration avec la liste des récompenses. En même temps, il n'est pas possible d'utiliser des bases de données différentes pour cette tâche, bien qu'elles existent déjà pour chaque environnement.
- Possibilité de configurer le filtrage uniquement par le développeur. Étant donné que tout est décrit dans le code, seule une personne connaissant le projet et le langage de programmation pourrait apporter des modifications, j'aimerais qu'il soit possible de le faire simplement via l'API privée ou la base de données.
- L'inconvénient de la visualisation. Il existe de nombreuses récompenses, parfois vous devez voir les filtres qu'ils utilisent. Chaque fois, faire cela en regardant le code est assez fastidieux.
Au début de l'application, nous comparons par le nom des filtres chargés à partir de la base de données et les mettons dans une récompense spécifique. Exemple de description de filtre:
[ { "name":"SourceFilter", "config":{ "sources":["reviews"] } }, { "name": "ReviewsLengthFilter", "config": { "allowed_length": 100 } } ]
Dans ce cas, nous ne prendrons que les avis (cela est indiqué par le premier objet de description du tableau de filtres), dont le texte contient plus de 100 caractères (le deuxième filtre de la liste).
Exemple de description de règle:
{"name": "ReviewUniqueByObjectRule","config":{}}
Cette règle vous permettra de modifier les compteurs uniquement si l'utilisateur a rédigé une évaluation pour l'objet, alors qu'une seule évaluation sera prise en compte pour un objet.
Bss
Arrêtons-nous séparément sur le travail avec le flux d'événements BSS. Il y a au moins trois raisons à cela:
- Les événements Analytics ne peuvent pas être annulés, ils ne contiennent aucun modèle d'état, ce qui est généralement logique, car la conduite via le navigateur ou la création d'un itinéraire ne peut pas être annulée. L'action était là ou non.
- Volumes. Permettez-moi de vous rappeler que l'audience totale de 2GIS est de plus de 50 millions d'utilisateurs par mois. Ensemble, ils effectuent plus de 1,5 milliard de requêtes de recherche, ainsi que de nombreuses autres actions: lancement de l'application, visualisation de la carte de l'objet, etc. Au plus fort, le nombre d'événements peut atteindre 50 000 par seconde. Nous devons transmettre toutes ces informations à travers des filtres afin de récompenser l'utilisateur.
- Les événements Analytics ont des fonctionnalités: plusieurs formats, une grande variété de types.
Tout cela a grandement influencé le traitement des données du sujet BSS, car si nous avons besoin de temps réel, nous avons besoin d'un temps de traitement très proche.
Pour réduire les différences décrites, un service distinct a été créé qui prépare ces événements. Le service peut fonctionner avec toute la variété de formats de messages provenant de l'analyse. L'essence de son travail est la suivante: l'ensemble du flux d'événements du BSS est lu, à partir duquel seuls ceux qui sont nécessaires pour les prix sont extraits. Un tel filtre de service réduit considérablement la charge (après filtrage, le débit est de ≈300 événements par seconde) des récompenses du processeur de flux BSS, et génère également des événements dans un format unique, nivelant l'inconvénient associé à l'historique du développement de l'analyse interne.
Récompenses
Nous avons donc compris comment gérer les événements et calculer la progression des affectations. Il est maintenant temps de jeter un coup d'œil au processus d'attribution des récompenses aux utilisateurs.
La première question qui se pose est: pourquoi allouer la sortie à un travailleur séparé, ne peut-elle pas être recomptée lors du traitement de chaque événement? Réponse: possible, mais pas la peine.
Il y a plusieurs raisons pour attribuer l'extradition à un processus distinct:
- En transférant le recomptage à chaque ConsumingWorker, nous obtenons la condition de course pour l'opération de mise à jour de la progression par récompense, car chaque gestionnaire tentera de mettre à jour la progression en fonction de l'état connu des tâches, et d'autres changeront activement cet état.
- Chaque lot ConsumingWorker traite les événements de Kafka dans une transaction. En ajoutant un insert à la table des récompenses de l'utilisateur, nous appellerons des verrous supplémentaires au niveau de la base de données, ce qui empêchera les autres gestionnaires.
- Dans le processus de délivrance des récompenses, il existe une logique d'envoi de notifications qui ne fera que ralentir le traitement du flux d'événements, ce qui n'est pas souhaitable.
Les raisons de l'émergence d'un AchievesWorker distinct (gestionnaire pour la délivrance des récompenses) ont été triées. Vous devez maintenant traiter deux parties importantes du traitement:
- Il y a un ensemble de quêtes dans la récompense. Il existe un ensemble de compteurs pour ces tâches. Comment comprendre le montant de la récompense et comment l'exprimer en code?
Exemple: vous devez écrire 3 avis ou télécharger 3 photos. L'utilisateur a 1 avis et 2 photos. Quelle est la progression du prix? Réponse: 3, car l'utilisateur sera certain que vous en aurez besoin de 3 au total. - Nous avons un gestionnaire distinct pour l'émission des récompenses. Chaque fois, compter des dizaines de récompenses pour chaque utilisateur autorisé, c'est-à-dire plusieurs dizaines de millions, a peu de chances de réussir rapidement. Comment peut-il connaître la progression de quels utilisateurs particuliers et quelles tâches ont changé depuis le dernier traitement?
Nous considérerons chaque partie séparément.
Flux de progrès
Pour mieux comprendre comment vous pouvez décrire comment transformer l'avancement des tâches en progrès par récompense, nous divisons les récompenses en catégories et examinons les transformations.
"Terminez une tâche par X unités." Exemple: Conduisez 10 km sur le navigateur.
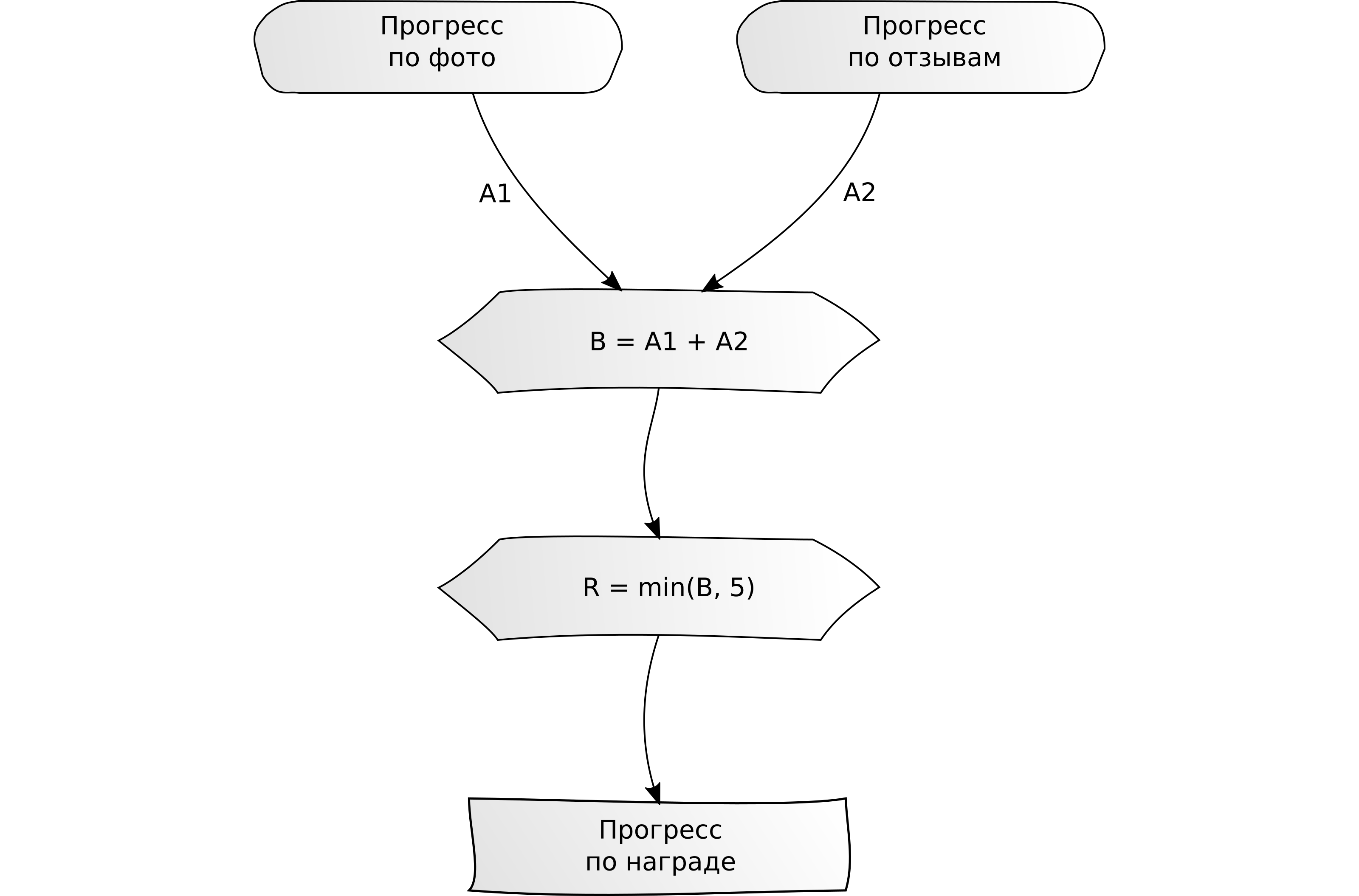
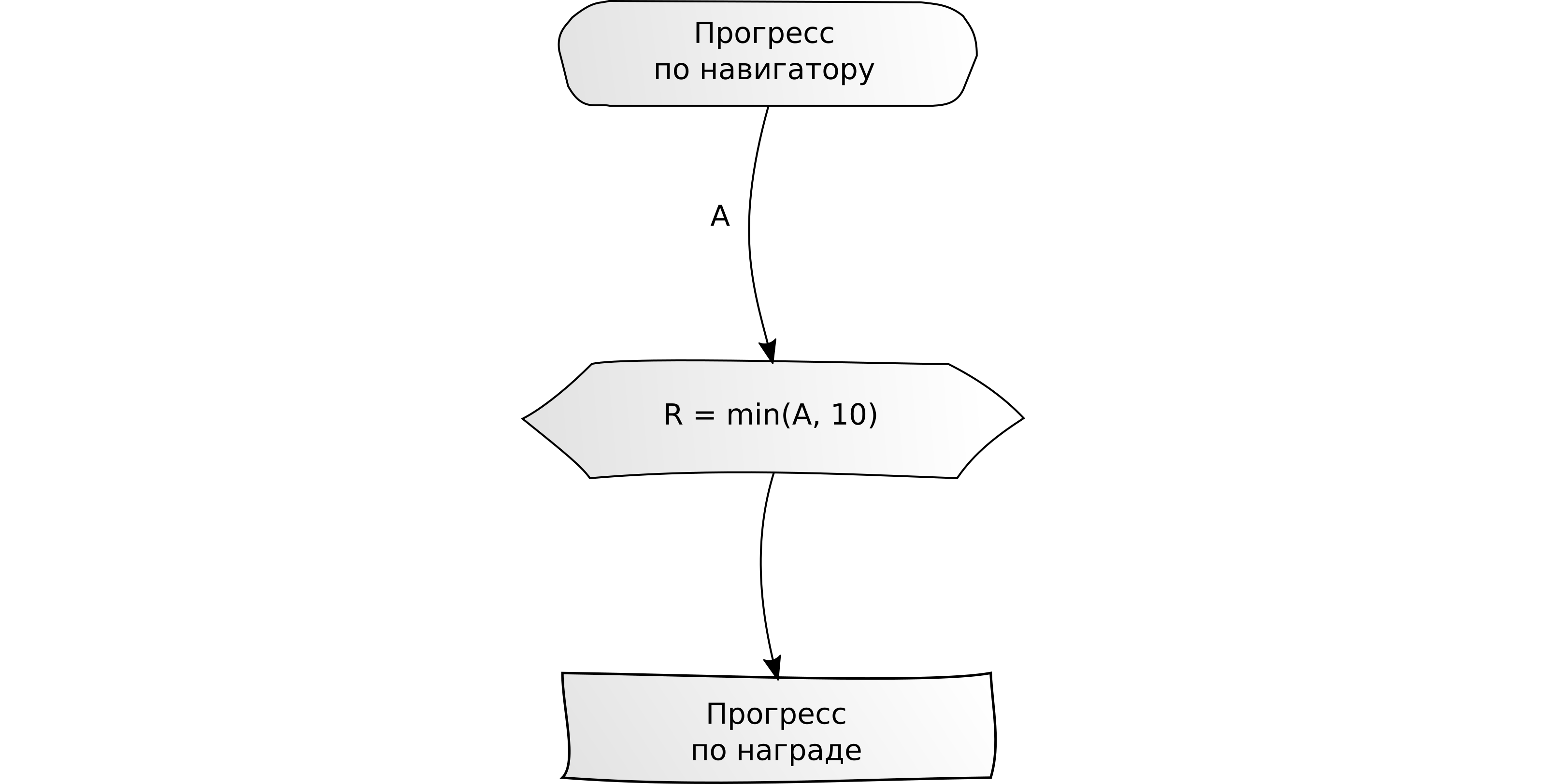 "Remplissez plusieurs tâches pour X unités chacune."
"Remplissez plusieurs tâches pour X unités chacune." Exemple: téléchargez 5 photos et écrivez 5 avis sur des cartes - seulement 10 unités de contenu.
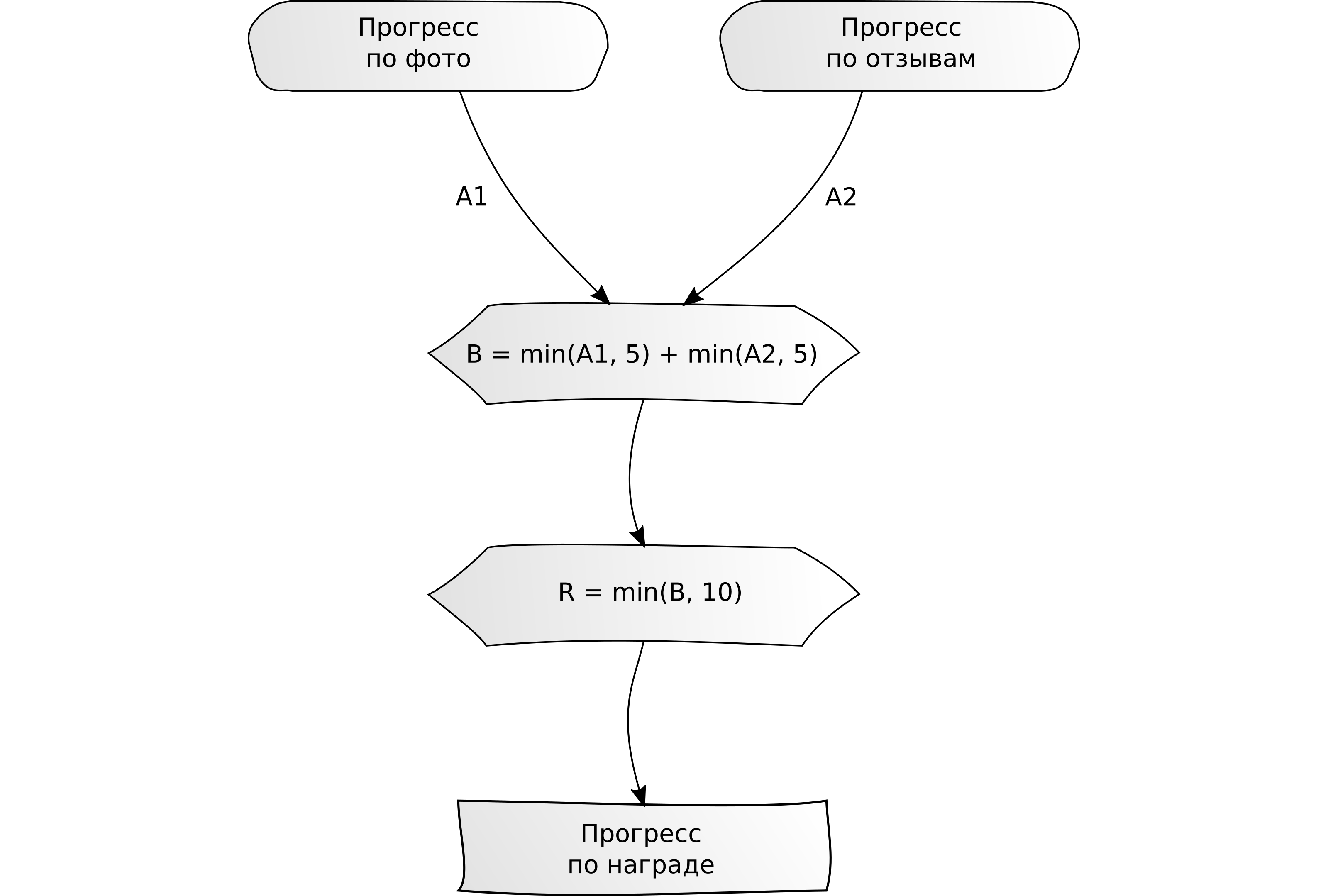 "Complétez plusieurs tâches pour X unités au total."
"Complétez plusieurs tâches pour X unités au total." Exemple: rédigez 5 avis ou téléchargez 5 photos.
 "Effectuez plusieurs tâches regroupées par type."
"Effectuez plusieurs tâches regroupées par type." Exemple: téléchargez 5 unités de contenu (photos ou avis) et parcourez 10 km sur le navigateur.

Théoriquement, il pourrait y avoir des combinaisons imbriquées plus complexes. Cependant, dans des conditions réelles, il n'est pas possible d'expliquer à l'utilisateur en deux ou trois phrases la combinaison logique complexe qui doit être effectuée pour recevoir la récompense. Par conséquent, dans la plupart des cas, ces options sont suffisantes.
Nous avons appelé la méthode de conversion une stratégie et avons essayé de la rendre plus ou moins universelle en élaborant une description formelle sous la forme d'un objet JSON. Vous pourriez, bien sûr, penser à écrire sous la forme d'une formule, mais il vous faudrait alors utiliser des similitudes pour évaluer ou décrire la grammaire et la mettre en œuvre, et c'est clairement une sur-application. Le stockage de la stratégie pour chaque récompense dans le code source n'est pas très pratique, car la description de la récompense (partie dans la base de données et partie dans le code) sera rompue, et elle ne permettra pas non plus de collecter des récompenses à partir de composants prêts à l'emploi sans développement.
La stratégie est présentée sous la forme d'un arbre, où chaque nœud:
- Fait référence à la progression actuelle de l'affectation ou est un groupe d'autres nœuds.
- Peut avoir une restriction supérieure - en fait une indication de la nécessité d'utiliser min ().
- Peut avoir un coefficient de normalisation. Nécessaire pour les conversions simples en multipliant le résultat par un nombre. Nous sommes utiles pour convertir des mètres en kilomètres.
Pour décrire les exemples ci-dessus, une opération suffit - somme. La somme est idéale pour montrer clairement la progression de l'utilisateur avec un seul numéro, mais d'autres opérations peuvent être utilisées si vous le souhaitez.
Voici un exemple de description de stratégie pour la dernière catégorie:
{ "goal": 15, "operation": "sum", "strategy": [ { "goal": 5, "operation": "sum", "strategy": [ { "objective_id": "photo" }, { "objective_id": "reviews" } ] }, { "goal": 10, "operation": "sum", "strategy": [ { "objective_id": "navi", "normalization_factor": 0.001 } ] } ] }
Mises à jour requises
Il existe plusieurs gestionnaires qui analysent sans relâche les événements des utilisateurs et appliquent des modifications à la progression des tâches. Une recherche régulière de tous les utilisateurs avec chaque récompense mènera à une analyse de plusieurs dizaines de millions de récompenses - pas très encourageant, à condition que les mises à jour réelles soient mesurées en milliers. Comment apprendre seulement sur des milliers et ne pas gaspiller des millions de CPU?
L'idée de recalculer les progrès uniquement sur les récompenses qui ont réellement changé est venue assez rapidement. Il est basé sur l'utilisation de montres vectorielles.
Avant la description, je rappellerai les entités:
- UserObjective - données sur la progression de l'utilisateur en définissant le prix.
- UserAchieve - récompense les données de progression de l'utilisateur.
L'implémentation ressemble à ceci:
- Nous obtenons le champ de version pour UserObjective et UserAchieve et Sequence dans PostgreSQL.
- Chaque mise à jour de l'entité UserObjective change de version. La valeur est tirée de la séquence (nous l'avons commune à tous les enregistrements).
- La valeur de version pour UserAchieve sera déterminée comme le maximum des versions de UserObjective associé.
- À chaque cycle de traitement, AchievesWorker recherche un tel UserObjective pour lequel il n'y a pas UserAchieve ou UserAchieve.version <UserObjective.version. Le problème est résolu par une seule requête dans la base de données.
Il convient de noter immédiatement que la solution a des limites sur le nombre d'entrées dans les tableaux des récompenses et des tâches, ainsi que sur la fréquence des changements en cours sur les tâches, mais avec quelques dizaines de millions de récompenses et le nombre de mises à jour moins de mille par minute, il est tout à fait possible de vivre avec une telle solution. D'une manière ou d'une autre, nous expliquerons séparément comment nous avons optimisé l'émission pour le concours «
2GIS Agents ».
Conclusions
Malgré le fait que l'article se soit avéré assez volumineux, beaucoup de nuances sont restées dans les coulisses, car il ne serait pas possible d'en parler brièvement.
Quelles conclusions avons-nous tirées grâce aux prix:
- Le principe de «diviser pour régner» dans ce cas a joué entre nos mains. L'allocation de gestionnaires d'événements à chaque source nous aide à évoluer si nécessaire. Leur travail est isolé selon les données et ne se recoupe que dans de petites zones. La mise en évidence de la logique de récompense vous permet de réduire les frais généraux des gestionnaires d'événements.
- Si vous avez besoin de digérer beaucoup de données et que le traitement est assez coûteux, vous devriez immédiatement réfléchir à la façon de filtrer ce qui n'est certainement pas nécessaire. L'expérience du filtrage d'un flux BSS en est un exemple.
- Encore une fois, nous étions convaincus que l'intégration de services via un bus d'événements commun est très pratique et vous permet d'éviter une charge inutile sur d'autres services. Si le service Rewards recevait des données des services Photo, Avis, etc. via des requêtes http, plusieurs services devraient être préparés pour un chargement supplémentaire.
- Un peu de métaprogrammation peut aider à maintenir arbitrairement l'intégrité de la configuration des données et des environnements séparés. Le stockage des filtres, des règles et des stratégies dans la base de données a simplifié le processus de développement et de publication de nouvelles récompenses.