Remarque perev. : Le principal ingénieur de Zalando, Henning Jacobs, a remarqué à plusieurs reprises des problèmes avec les utilisateurs de Kubernetes pour comprendre le but des sondes de vivacité (et de préparation) et leur application correcte. Par conséquent, il a rassemblé ses pensées dans cet article volumineux, qui au fil du temps fera partie de la documentation du K8.
Les bilans de santé, connus à Kubernetes sous le
nom de sondes de vivacité (c'est-à-dire littéralement «tests de viabilité» - environ. Trad.) , Peuvent être très dangereux. Je recommande de les éviter autant que possible: les seules exceptions sont les cas où elles sont vraiment nécessaires et que vous êtes pleinement conscient des spécificités et des conséquences de leur utilisation. Cette publication se concentrera sur les contrôles de vivacité et de préparation, et expliquera également dans quels cas
cela vaut la peine et ne vaut pas la peine de les utiliser.
Mon collègue Sandor a récemment partagé sur Twitter les erreurs les plus courantes qu'il rencontre, y compris celles liées à l'utilisation des sondes de préparation / vivacité:
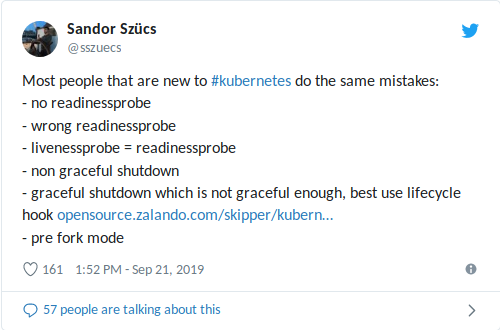
Une
livenessProbe mal configurée peut aggraver les situations avec une charge élevée (arrêt d'avalanche + lancement potentiellement long du conteneur / de l'application) et entraîner d'autres conséquences négatives telles qu'une baisse des dépendances
(voir également mon récent article sur la limitation du nombre de requêtes dans le bundle K3s + ACME) . Pire encore, lorsqu'une sonde de vivacité est combinée à un bilan de santé, qui agit comme une base de données externe: la
seule défaillance de la base de données redémarrera tous vos conteneurs !
Le message général
«N'utilisez pas de sondes de vivacité» dans ce cas aide un peu, par conséquent, nous examinerons à quoi servent les contrôles de préparation et de vivacité.
Remarque: La plupart du test ci-dessous a été initialement inclus dans la documentation interne pour les développeurs Zalando.Contrôles de préparation et de vivacité
Kubernetes fournit deux mécanismes importants appelés
sondes de vivacité et sondes de préparation . Ils effectuent périodiquement certaines actions - par exemple, envoyer une demande HTTP, ouvrir une connexion TCP ou exécuter une commande dans un conteneur - pour confirmer que l'application fonctionne correctement.
Kubernetes utilise des
sondes de préparation pour comprendre quand un conteneur est prêt à recevoir du trafic. Un pod est considéré prêt à partir si tous ses conteneurs sont prêts. Une application de ce mécanisme est de contrôler quels pods sont utilisés comme backends pour les services Kubernetes (et en particulier Ingress).
Les sondes de vivacité aident Kubernetes à comprendre quand il est temps de redémarrer le conteneur. Par exemple, une telle vérification vous permet d'intercepter un blocage lorsque l'application est «bloquée» en un seul endroit. Le redémarrage du conteneur dans cet état permet de déplacer l'application du sol, malgré les erreurs, mais cela peut également entraîner des échecs en cascade (voir ci-dessous).
Si vous essayez de déployer une mise à jour vers une application qui échoue aux vérifications de vivacité / préparation, le déploiement se bloquera car Kubernetes attendra l'état
Ready de tous les pods.
Exemple
Voici un exemple de sonde de préparation vérifiant le chemin
/health via HTTP avec les paramètres par défaut (
intervalle : 10 secondes,
délai d'expiration : 1 seconde,
seuil de réussite : 1,
seuil d'échec : 3):
# deployment'/ podTemplate: spec: containers: - name: my-container # ... readinessProbe: httpGet: path: /health port: 8080
Recommandations
- Pour les microservices avec un point de terminaison HTTP (REST, etc.), définissez toujours une sonde de disponibilité qui vérifie si l'application (pod) est prête à recevoir du trafic.
- Assurez-vous que la sonde de disponibilité couvre la disponibilité du port de serveur Web réel :
- En utilisant des ports pour les besoins administratifs appelés «admin» ou «gestion» (par exemple, 9090) pour
readinessProbe , assurez-vous que le point de terminaison ne retourne OK que si le port HTTP principal (comme 8080) est prêt à accepter le trafic *;
* Je connais au moins un cas à Zalando où cela ne s'est pas produit, c'est-à-dire que readinessProbe vérifié le port de «gestion», mais le serveur lui-même n'a pas démarré en raison de problèmes de chargement du cache. - suspendre la sonde de préparation sur un port séparé peut entraîner le fait que la congestion sur le port principal ne sera pas reflétée dans le contrôle d'intégrité (c'est-à-dire que le pool de threads sur le serveur est plein, mais le contrôle d'intégrité montre toujours que tout est OK).
- S'assurer que la sonde de préparation permet l'initialisation / migration de la base de données ;
- la manière la plus simple d'y parvenir est d'accéder au serveur HTTP uniquement une fois l'initialisation terminée (par exemple, migration de la base de données depuis Flyway , etc.); c'est-à-dire qu'au lieu de modifier l'état du contrôle de l'intégrité, ne démarrez simplement pas le serveur Web tant que la migration de la base de données * n'est pas terminée.
* Vous pouvez également exécuter des migrations de base de données à partir de conteneurs d'initialisation en dehors du pod. Je suis toujours un fan des applications autonomes, c'est-à-dire celles dans lesquelles le conteneur d'applications, sans coordination externe, sait comment amener la base de données à l'état souhaité.
- Utilisez
httpGet pour les vérifications de préparation via les points de terminaison typiques des vérifications de l'état (par exemple /health ). successThreshold: 1 paramètres de successThreshold: 1 ( interval: 10s , timeout: 1s , failureThreshold: 3 successThreshold: 1 , failureThreshold: 3 ):- les paramètres par défaut signifient que le pod ne sera pas prêt après environ 30 secondes (3 contrôles de santé ont échoué).
- Utilisez un port distinct pour «admin» ou «gestion» si la pile technologique (par exemple, Java / Spring) permet de séparer la gestion de l'intégrité et des métriques du trafic normal:
- mais n'oubliez pas le paragraphe 2.
- Si nécessaire, une sonde de disponibilité peut être utilisée pour réchauffer / charger le cache et renvoyer le code d'état 503 jusqu'à ce que le conteneur soit «réchauffé»:
- Je vous recommande également de vous familiariser avec la nouvelle vérification
startupProbe , qui est apparue dans la version 1.16 (nous avons écrit à ce sujet en russe ici - traduction approximative) .
Avertissements
- Ne vous fiez pas à des dépendances externes (telles que des stockages de données) lorsque vous effectuez des tests de préparation / vivacité - cela peut entraîner des échecs en cascade:
- à titre d'exemple, prenons un service REST avec état avec 10 pods en fonction d'une base de données Postgres: lorsque la vérification dépend d'une connexion fonctionnelle à la base de données, les 10 pods peuvent tomber en cas de retard dans le réseau / côté base de données - généralement, tout se termine pire qu'il ne pourrait;
- notez que Spring Data vérifie par défaut la connexion à la base de données *;
* Il s'agit du comportement par défaut de Spring Data Redis (du moins c'était comme lorsque j'ai vérifié la dernière fois), ce qui a conduit à un échec «catastrophique»: lorsque Redis était indisponible pendant une courte période, tous les pods «sont tombés». - «Externe» dans ce sens peut également signifier d'autres pods de la même application, c'est-à-dire, idéalement, la vérification ne devrait pas dépendre de l'état des autres pods du même cluster pour éviter les plantages en cascade:
- les résultats peuvent varier pour les applications à état distribué (par exemple, la mise en cache en mémoire dans les pods).
- N'utilisez pas de sonde de vivacité pour les pods (les exceptions sont des cas où elles sont vraiment nécessaires et que vous êtes pleinement conscient des spécificités et des conséquences de leur utilisation):
- La sonde de vivacité peut aider à récupérer les conteneurs «bloqués», mais comme vous avez le contrôle total de votre application, des choses comme les processus et les blocages «bloqués» ne devraient idéalement pas se produire: la meilleure alternative est de supprimer intentionnellement l'application et de la renvoyer à précédent état d'équilibre;
- une sonde de vivacité échouée redémarrera le conteneur, ce qui aggravera potentiellement les conséquences des erreurs de chargement: le redémarrage du conteneur entraînera un temps d'arrêt (au moins pour le temps de lancement de l'application, disons pendant plus de 30 secondes), provoquant de nouvelles erreurs, augmentant la charge sur d'autres conteneurs et augmentant la probabilité de leur défaillance, etc.;
- les contrôles de vivacité combinés à une dépendance externe sont les pires combinaisons possibles, ce qui peut entraîner des échecs en cascade: un léger retard du côté base de données redémarrera tous vos conteneurs!
- Les paramètres des contrôles de vivacité et de préparation doivent être différents :
- vous pouvez utiliser une sonde de vivacité avec le même bilan de santé, mais un seuil plus élevé (
failureThreshold ), par exemple, attribuer le statut non prêt après 3 tentatives et supposer que la sonde de vivacité a échoué après 10 tentatives;
- N'utilisez pas de vérifications exécutées , car elles sont associées à des problèmes connus qui conduisent à l'apparition de processus zombies:
Résumé
- Utilisez des sondes de préparation pour déterminer quand un pod est prêt à recevoir du trafic.
- N'utilisez les sondes de vivacité que lorsqu'elles sont vraiment nécessaires.
- Une utilisation incorrecte des sondes de disponibilité / vivacité peut entraîner une disponibilité réduite et des échecs en cascade.

Documents supplémentaires sur le sujet
Mise à jour No1 du 2019-09-29
À propos des conteneurs d'initialisation pour la migration de la base de données : note de bas de page ajoutée.
EJ m'a rappelé la PDB: l'un des problèmes des contrôles de vivacité est le manque de coordination entre les pods. Kubernetes dispose de PDP (
Pod Disruption Budgets) pour limiter le nombre d'échecs simultanés qu'une application peut rencontrer, mais les vérifications ne prennent pas en compte les PDB. Idéalement, nous pouvons commander des K8: "Redémarrez un pod si sa vérification échoue, mais ne les redémarrez pas tous pour ne pas les aggraver."
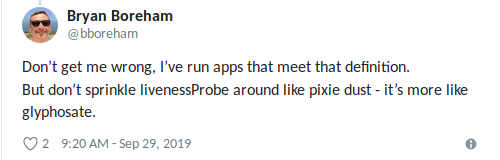
Bryan a parfaitement formulé : «Utilisez un son vivant lorsque vous savez avec certitude que la
meilleure chose que vous pouvez faire est de« tuer »l'application » (encore une fois, ne
vous laissez pas emporter).
Mise à jour n ° 2 du 2019-09-29
Concernant la lecture de la documentation avant utilisation : j'ai créé une
demande de fonctionnalité pour compléter la documentation sur les sondes de vivacité.
PS du traducteur
Lisez aussi dans notre blog: