Comment tester des idées, l'architecture et les algorithmes sans écrire de code? Comment formuler et vérifier leurs propriétés? Que sont les vérificateurs de modèles et les chercheurs de modèles? Que faire lorsque les capacités des tests ne sont pas suffisantes?
Salut Je m'appelle Vasil Dyadov, maintenant je travaille comme programmeur dans Yandex.Mail, avant de travailler chez Intel, je développais le code RTL (niveau de transfert de registre) sur Verilog / VHDL pour ASIC / FPGA encore plus tôt. Je m'intéresse depuis longtemps au sujet de la fiabilité des logiciels et du matériel, des mathématiques, des outils et des méthodes utilisés pour développer des logiciels et de la logique avec des propriétés prédéfinies garanties.
Il s'agit du deuxième article d'une série (le premier article ici ), conçu pour attirer l'attention des développeurs et des gestionnaires sur l'approche d'ingénierie du développement logiciel. Récemment, il a été indûment ignoré, malgré des changements révolutionnaires dans son approche et ses outils de soutien.
Le premier article a semblé à certains lecteurs trop abstrait. Beaucoup aimeraient voir un exemple d'utilisation d'une approche d'ingénierie et de spécifications formelles dans des conditions proches de la réalité.
Dans cet article, nous examinerons un exemple d'application réelle de TLA + pour résoudre un problème pratique.
Je suis toujours ouvert pour discuter des questions liées au développement de logiciels, et je serai heureux de discuter avec les lecteurs (les coordonnées de communication sont dans mon profil).
Qu'est-ce que TLA +?
Pour commencer, je voudrais dire quelques mots sur TLA + et TLC.
TLA + (Logique temporelle des actions + données) est un formalisme basé sur une sorte de logique temporelle. Conçu par Leslie Lamport.
Dans le cadre de ce formalisme, on peut décrire l'espace des variantes de comportement du système et les propriétés de ces comportements.
Pour simplifier, nous pouvons supposer que le comportement du système est représenté par une séquence de ses états (comme des perles infinies, des boules sur une chaîne), et la formule TLA + définit une classe de chaînes qui décrivent toutes les variantes possibles du comportement du système (un grand nombre de perles).
TLA + est bien adapté pour décrire les machines à états finis non déterministes en interaction (par exemple, l'interaction des services dans un système), bien que son expressivité soit suffisante pour décrire beaucoup d'autres choses (qui peuvent être exprimées dans une logique de premier ordre).
Et TLC est un vérificateur de modèle à état explicite: un programme qui, selon une description de système TLA + et des formules de propriété données, parcourt les états du système et détermine si le système satisfait les propriétés spécifiées.
Typiquement, travailler avec TLA + / TLC est construit de cette façon: nous décrivons le système dans TLA +, formalisons des propriétés intéressantes dans TLA +, exécutons TLC pour vérification.
Puisqu'il n'est pas facile de décrire directement un système plus ou moins complexe dans TLA +, un langage de niveau supérieur a été inventé - PlusCal, qui se traduit par TLA +. PlusCal existe de deux manières: avec Pascal et la syntaxe de type C. Dans l'article que j'ai utilisé la syntaxe de type Pascal, il me semble qu'il vaut mieux la lire. PlusCal par rapport à TLA + est à peu près le même que C par rapport à l'assembleur.
Ici, nous n'entrerons pas profondément dans la théorie. La documentation sur l'immersion dans TLA + / PlusCal / TLC est fournie à la fin de l'article.
Ma tâche principale est de montrer l'application de TLA + / TLC dans un exemple concret simple et compréhensible.
Dans certains commentaires de l'article précédent, on m'a reproché de ne pas avoir peint les fondements théoriques des outils, mais le but de cette série d'articles était de montrer l'application pratique des outils pour l'approche d'ingénierie dans le développement de logiciels.
Je pense qu'une immersion profonde dans la théorie intéresse peu de monde, mais si vous êtes intéressé, vous pouvez toujours vous rendre au PM pour des liens et des explications, et pour autant que j'ai suffisamment de connaissances (après tout, je ne suis pas un mathématicien théorique, mais un ingénieur logiciel), je vais essayer de répondre .
Énoncé du problème
Je vais d'abord parler un peu de la tâche pour laquelle TLA + a été utilisé.
La tâche est liée au traitement du flux d'événements. À savoir, pour créer une file d'attente pour stocker des événements et envoyer des notifications sur ces événements.
L'entrepôt de données est organisé physiquement sur la base du SGBD PostgreSQL.
La principale chose que vous devez savoir:
- Il existe des sources d'événements. Pour nos besoins, nous pouvons nous limiter au fait que chaque événement est caractérisé par le temps dans lequel son traitement est planifié. Ces sources écrivent des événements dans la base de données. Habituellement, l'heure de l'écriture dans la base de données et l'heure du traitement prévu ne sont en aucun cas liées.
- Il existe des processus de coordination qui lisent les événements de la base de données et envoient des notifications d'événements à venir aux composants du système qui doivent répondre à ces notifications.
- Exigence fondamentale: nous ne devons pas perdre d'événements. La notification de l'événement dans les cas extrêmes peut être répétée, c'est-à-dire qu'il doit y avoir une garantie au moins une fois . Dans les systèmes distribués, il est extrêmement difficile de réaliser une garantie une seule fois (cela peut même être impossible, mais cela doit être prouvé) sans mécanismes de consensus, et ils (au moins tout ce que je sais) ont un effet très fort sur le système en termes de retard et de débit.
Maintenant quelques détails:
- Il existe de nombreux processus sources; ils peuvent générer des millions (dans le pire des cas) d'événements tombant dans un intervalle de temps étroit.
- Des événements peuvent être générés à la fois pour le futur et pour le temps passé (par exemple, si le processus source a ralenti et enregistré un événement pendant un moment qui s'est déjà écoulé).
- La priorité du traitement des événements est dans le temps, c'est-à-dire que nous devons d'abord traiter les premiers événements.
- Pour chaque événement, le processus source génère un nombre aléatoire worker_id , en raison duquel les événements sont répartis entre les coordinateurs.
- Il existe plusieurs processus de coordination (échelles en fonction des besoins en fonction de la charge du système).
- Chaque processus de coordinateur traite les événements pour son propre ensemble worker_id , c'est-à-dire qu'en raison de worker_id, nous évitons la concurrence entre les coordinateurs et le besoin de verrous.
Comme on peut le voir dans la description, nous ne pouvons considérer qu'un seul processus de coordination et ne pas prendre en compte worker_id dans notre tâche.
Autrement dit, pour simplifier, nous supposons que:
- Il existe de nombreux processus source.
- Le processus de coordination en est un.
Je décrirai l'évolution de l'idée de résoudre ce problème par étapes, afin de mieux comprendre comment la pensée est passée d'une implémentation simple à une implémentation optimisée.
Décision frontale
Nous allons créer une plaque pour les événements où nous stockerons les événements sous la forme d'un simple horodatage (nous ne sommes pas intéressés par d'autres paramètres dans cette tâche). Construisons un index sur le champ d' horodatage .
Cela semble être une solution parfaitement normale.
Seulement, il y a un problème d'évolutivité: plus il y a d'événements, plus les opérations de base de données sont lentes.
Les événements peuvent venir pour le temps passé, donc le coordinateur devra constamment revoir la chronologie entière.
Le problème peut être résolu de manière approfondie en divisant la base de données en fragments par le temps, etc. Mais c'est un moyen gourmand en ressources.
En conséquence, le travail des coordinateurs ralentira, car vous devrez lire et combiner les données de plusieurs bases de données.
Il est difficile d'implémenter la mise en cache des événements dans le coordinateur afin de ne pas aller aux bases pour traiter chaque événement.
Plus de bases de données - plus de problèmes de tolérance aux pannes.
Et ainsi de suite.
Nous ne nous attarderons pas sur cette solution frontale en détail, car elle est triviale et sans intérêt.
Première optimisation
Voyons comment améliorer la solution frontale.
Pour optimiser l'accès à la base de données, vous pouvez compliquer un peu l'index, ajouter un identifiant augmentant de façon monotone aux événements qui seront générés lors de la validation d'une transaction dans la base de données. Autrement dit, l'événement est maintenant caractérisé par la paire {time, id} , où time est l'heure à laquelle l'événement est planifié, id est un compteur à augmentation monotone. Il y a une garantie de l'unicité de id pour chaque événement, mais il n'y a aucune garantie que les valeurs id vont sans trous (c'est-à-dire qu'il peut y avoir une telle séquence: 1 , 2 , 7 , 15 ).
Il semblerait que nous pouvons maintenant stocker l'identifiant du dernier événement lu dans le processus de coordination et, lors de la récupération, sélectionner des événements avec des identifiants supérieurs au dernier événement traité.
Mais ici, le problème apparaît immédiatement: les processus source peuvent enregistrer un événement avec un horodatage dans le futur. Ensuite, nous devrons constamment prendre en compte l'ensemble des événements avec de petits identifiants dans le processus de coordination, dont le temps de traitement n'est pas encore arrivé.
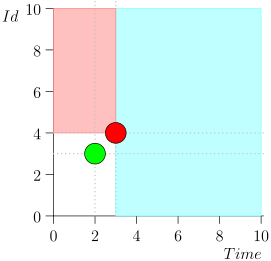
Vous pouvez remarquer que les événements relatifs à l'heure actuelle sont divisés en deux classes:
- Événements avec un horodatage dans le passé, mais avec un grand identifiant. Ils ont été écrits dans la base de données récemment, après que nous ayons traité cet intervalle de temps. Ce sont des événements hautement prioritaires, et ils doivent être traités en premier afin que la notification - qui est déjà en retard - ne soit même pas en retard.
- Événements enregistrés une fois avec des horodatages proches de l'instant présent. De tels événements auront une faible valeur d'identification.
Par conséquent, l'état actuel du processus de coordination est caractérisé par la paire {state.time, state.id}.
Il s'avère que les événements de haute priorité sont à gauche et au-dessus de ce point (région rose), et les événements normaux sont à droite (bleu clair):
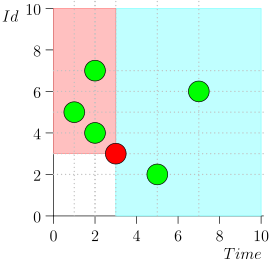
Organigramme
L'algorithme de travail du coordinateur est le suivant:
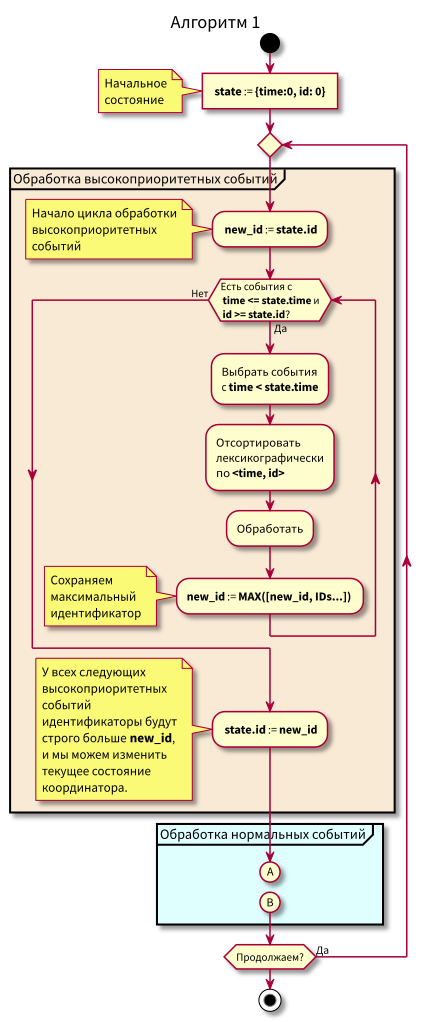
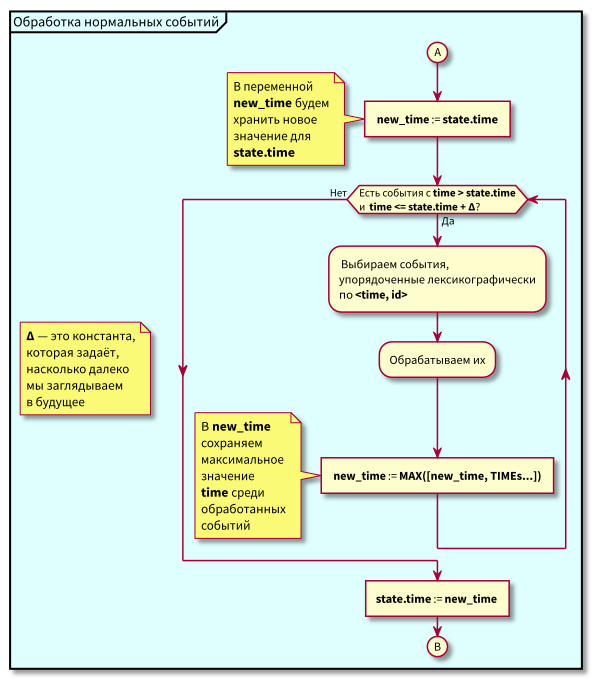
Lors de l'étude de l'algorithme, des questions peuvent se poser:
- Que se passe-t-il si le traitement des événements normaux commence et à ce moment-là de nouveaux événements du passé arrivent (dans la région rose), ne seront-ils pas perdus? Réponse: ils seront traités lors du prochain cycle de traitement des événements de haute priorité. Ils ne peuvent pas se perdre, car leur identifiant est garanti supérieur à state.id.
- Que se passe-t-il si après le traitement de tous les événements normaux - au moment du passage au traitement des événements de haute priorité - de nouveaux événements avec des horodatages de l'intervalle [state.time, state.time + Delta] arrivent, les perdons-nous? Réponse: ils tomberont dans la zone rose, car ils auront le temps <state.time and id > state.id: ils sont arrivés récemment et id augmente de façon monotone.
Exemple de fonctionnement d'algorithme
Regardons quelques étapes de l'algorithme:
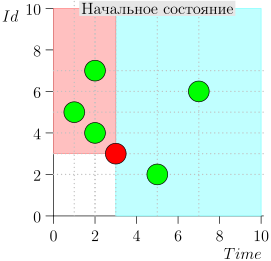
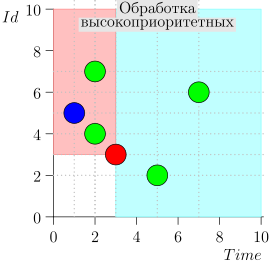
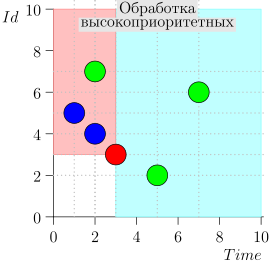
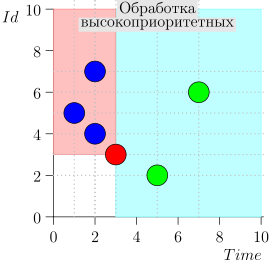
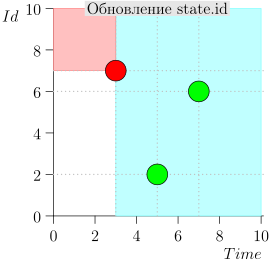
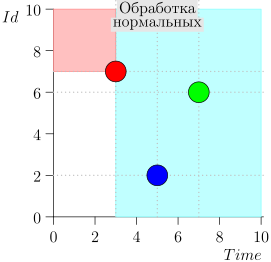
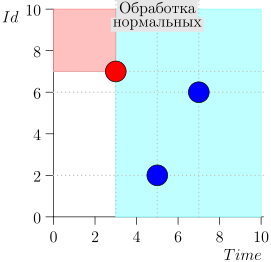
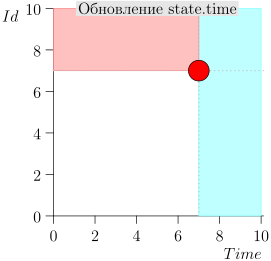
Modèle
Nous veillerons à ce que l'algorithme ne manque pas d'événements et toutes les notifications seront envoyées: nous composerons un modèle simple et le vérifierons.
Pour le modèle, nous utilisons TLA +, plus précisément PlusCal, qui se traduit par TLA +.
---------------- MODULE events ---------------- EXTENDS Naturals, FiniteSets, Sequences, TLC (* --algorithm Events \* \* (by Daniel Jackson) \* small-scope hypothesis, \* , ́ \* \* \* : \* Events - - , \* [time, id], \* \* \* \* Event_Id - \* id \* MAX_TIME - , \* \* TIME_DELTA - Delta, \* \* variables Events = {}, Event_Id = 0, MAX_TIME = 5, TIME_DELTA \in 1..3 define \* \* ZERO_EVT == [time |-> 0, id |-> 0] MAX(S) == CHOOSE x \in S: \A y \in S: y <= x MIN(S) == CHOOSE x \in S: \A y \in S: y >= x \* fold_left/fold_right RECURSIVE SetReduce(_, _, _) SetReduce(Op(_, _), S, value) == IF S = {} THEN value ELSE LET s == CHOOSE s \in S : TRUE IN SetReduce(Op, S \ {s}, Op(s, value)) (* ( ) *) ToSeq(S) == LET op(e, val) == Append(val, e) IN SetReduce(op, S, << >>) (* : *) ToSet(S) == {S[i] : i \in DOMAIN(S)} (* map *) MapSet(Op(_), S) == {Op(x) : x \in S} (* *) \* id GetIds(Evts) == MapSet(LAMBDA x: x.id, Evts) \* time GetTimes(Evts) == MapSet(LAMBDA x: x.time, Evts) (* SQL *) \* \* ORDER BY EventsOrderByTime(e1, e2) == e1.time < e2.time EventsOrderById(e1, e2) == e1.id < e2.id EventsOrder(e1, e2) == \* time, id \/ EventsOrderByTime(e1, e2) \/ /\ e1.time = e2.time /\ EventsOrderById(e1, e2) \* SELECT * FROM events \* WHERE time <= curr_time AND id >= max_id \* ORDER BY time, id SELECT_HIGH_PRIO(state) == LET \* \* time <= curr_time \* AND id >= maxt_id selected == {e \in Events : /\ e.time <= state.time /\ e.id >= state.id } IN selected \* SELECT * FROM events \* WHERE time > current_time AND time - Time <= delta_time \* ORDER BY time, id SELECT_NORMAL(state, delta_time) == LET selected == {e \in Events : /\ e.time <= state.time + delta_time /\ e.time > state.time } IN selected \* Safety predicate \* ALL_EVENTS_PROCESSED(state) == \A e \in Events: \/ e.time >= state.time \/ e.id >= state.id end define; \* - fair process inserter = "Sources" variable n, t; begin forever: while TRUE do \* get_time: \* \* , , \* with evt_time \in 0..MAX_TIME do t := evt_time; end with; \* ; \* : \* 1. . \* 2. , \* Event_Id - , \* commit: \* either - either Events := Events \cup {[time |-> t, id |-> Event_Id]} || Event_Id := Event_Id + 1; or Event_Id := Event_Id + 1; end either; end while; end process fair process coordinator = "Coordinator" variable state = ZERO_EVT, events = {}; begin forever: while TRUE do \* high_prio: events := SELECT_HIGH_PRIO(state); \* process_high_prio: \* , \* Events, \* state.id := MAX({state.id} \union GetIds(events)) || \* , \* Events := Events \ events || \* events , \* events := {}; \* - normal: events := SELECT_NORMAL(state, TIME_DELTA); process_normal: state.time := MAX({state.time} \union GetTimes(events)) || Events := Events \ events || events := {}; end while; end process end algorithm; *) \* BEGIN TRANSLATION \* TLA+, PlusCal \* END TRANSLATION ================================
Comme vous pouvez le voir, la description est relativement petite, malgré la section assez volumineuse des définitions (définir), qui pourrait être extraite dans un module séparé, puis réutilisée.
Dans les commentaires, j'ai essayé d'expliquer ce qui se passe dans le modèle. J'espère que ça
J'ai réussi et il n'est pas nécessaire de peindre le modèle plus en détail.
Je voudrais seulement clarifier un point concernant l'atomicité des transitions entre les états et les caractéristiques de modélisation.
La modélisation est réalisée en effectuant des étapes atomiques de processus. Dans une transition, une étape atomique d'un processus est effectuée au cours de laquelle cette étape peut être effectuée. Le choix de l'étape et du processus est non déterministe: lors de la modélisation, toutes les chaînes possibles d'étapes atomiques de tous les processus sont triées.
La question peut se poser: qu'en est-il de la modélisation du vrai parallélisme, lorsque nous réalisons simultanément plusieurs étapes atomiques dans des processus différents?
Cette question, Leslie Lamport a longtemps été répondu dans le livre Specifying Systems et d'autres travaux.
Je ne citerai pas complètement la réponse, en bref, l'essentiel est le suivant: s'il n'y a pas d'échelle de temps exacte où chaque événement est lié à un moment spécifique, il n'y a pas de différence dans la modélisation des événements parallèles comme des événements séquentiels non déterministes, car nous pouvons toujours supposer qu'un événement s'est produit plus tôt qu'un autre valeur infinitésimale.
Mais ce qui est vraiment important, c'est l'allocation compétente des étapes atomiques. S'il y en a trop, une explosion combinatoire de l'espace d'état se produira. Si vous prenez moins de mesures que nécessaire ou si vous les sélectionnez incorrectement, c'est-à-dire la probabilité de manquer un état / une transition non valide (c'est-à-dire que nous manquerons les erreurs sur le modèle).
Afin de décomposer correctement les processus en étapes atomiques, vous devez avoir une bonne idée du fonctionnement du système en termes de dépendance des processus vis-à-vis des données et des mécanismes de synchronisation.
En règle générale, la division des processus en étapes atomiques ne pose pas de gros problèmes. Et si c'est le cas, cela indique plutôt un manque de compréhension du problème, et non des problèmes de compilation du modèle et d'écriture de la spécification TLA +. C'est une autre caractéristique très utile des spécifications formelles: elles nécessitent une étude et une analyse approfondies.
un problème. En règle générale, si la tâche est significative et bien comprise, sa formalisation ne pose aucun problème.
Vérification du modèle
Pour la modélisation, j'utiliserai la boîte à outils TLA. Vous pouvez bien sûr tout exécuter à partir de la ligne de commande, mais l' EDI est encore plus pratique, en particulier pour commencer à apprendre la modélisation à l'aide de TLA +.
La création du projet est bien décrite dans les manuels, articles et livres, les liens vers lesquels j'ai cité à la fin de l'article, donc je ne vais pas me répéter. La seule chose sur laquelle j'attirerai votre attention est les paramètres de simulation.
TLC est un vérificateur de modèle avec vérification explicite de l'état. Il est clair que l'espace étatique doit être limité par des limites raisonnables. D'une part, elle doit être suffisamment grande pour pouvoir vérifier les propriétés qui nous intéressent, et d'autre part, suffisamment petite pour que la simulation soit réalisée dans un délai raisonnable en utilisant des ressources acceptables.
C'est un point assez délicat, ici vous devez comprendre les propriétés du système et du modèle. Mais cela vient rapidement avec l'expérience. Pour commencer, vous pouvez simplement définir les limites maximales possibles qui sont toujours acceptables en termes de temps de simulation et de ressources consommées.
Il existe également un mode de vérification non pas de la totalité de l'espace d'état, mais de chaînes sélectives jusqu'à une certaine profondeur. Il est également parfois possible et nécessaire de l'utiliser.
Nous revenons aux paramètres de simulation.
Tout d'abord, nous définissons les restrictions sur l'espace d'état du système. Les limites sont définies dans la section Paramètres de simulation Options avancées / Contrainte d'état .
Là, j'ai indiqué une expression TLA +: Cardinality(Events) <= 5 /\ Event_Id <= 5 ,
où Event_Id est la limite supérieure de la valeur de l'identificateur d'événement, Cardinality(Events) est la taille de l'ensemble des enregistrements d'événements (limité le modèle de base
données par cinq enregistrements dans une plaque).
Dans la simulation, la CCM ne regardera que les états dans lesquels cette formule est vraie.
Vous pouvez toujours autoriser des transitions d'état valides ( Options avancées / Contrainte d'action ),
mais nous n'en avons pas besoin.
Ensuite, nous indiquons la formule TLA + qui décrit notre système: Présentation du modèle / Formule temporelle = Spec , où Spec est le nom de la formule TLA + générée automatiquement par PlusCal (dans le code du modèle ci-dessus, ce n'est pas: pour économiser de l'espace, je n'ai pas cité le résultat de la traduction de PlusCal en TLA +) .
Le prochain paramètre à surveiller est le contrôle de l'impasse.
(coche dans Aperçu du modèle / Blocage ). Lorsque ce drapeau est activé, le TLC vérifie le modèle pour les états «suspendus», c'est-à-dire ceux dont il n'y a pas de transitions sortantes. S'il y a de tels états dans l'espace d'états, cela signifie une erreur claire dans le modèle. Ou dans TLC, qui, comme tout autre programme non trivial, n'est pas à l'abri des erreurs :) Dans ma pratique (pas si grande), je n'ai pas encore rencontré de blocages.
Et enfin, pour le bien de tous ces tests, la formule de sécurité dans Model Overview / Invariants = ALL_EVENTS_PROCESSED(state) .
TLC vérifiera la validité de la formule dans chaque état, et si elle devient fausse,
affichera un message d'erreur et montrera la séquence des états qui ont conduit à l'erreur.
Après avoir démarré TLC, après avoir travaillé pendant environ 8 minutes, il a signalé "Aucune erreur". Cela signifie que le modèle est testé et répond aux propriétés spécifiées.
TLC affiche également de nombreuses statistiques intéressantes. Par exemple, pour ce modèle, 7 677 824 états uniques ont été obtenus; au total, le TLC a examiné 27 109 029 états, le diamètre de l'espace d'états est de 47 (il s'agit de la longueur maximale de la chaîne d'états avant répétition,
longueur de cycle maximale à partir d'états non répétitifs dans le graphique d'état et de transition).
Si nous divisons 27 millions d'états en 8 minutes, nous obtenons environ 56 000 états par seconde, ce qui peut ne pas sembler très rapide. Mais gardez à l'esprit que j'ai exécuté la simulation sur un ordinateur portable qui fonctionnait en mode d'économie d'énergie (j'ai forcé la fréquence centrale à 800 MHz, parce que je conduisais à ce moment-là dans le train), et n'ai pas optimisé du tout le modèle pour la vitesse de simulation.
Il existe de nombreuses façons d'accélérer la simulation: du portage d'une partie du code du modèle TLA + à Java et à la connexion à TLC à la volée (il est utile d'accélérer toutes sortes de fonctions d'assistance) à l'exécution de TLC dans les nuages et sur les clusters (la prise en charge d'Amazon et Azure est intégrée directement dans TLC lui-même).
Deuxième optimisation
Dans l'algorithme précédent, tout va bien, à l'exception de quelques problèmes:
- Tant que nous n'avons pas traité tous les événements de la zone bleue dans l'intervalle
[state.time, state.time + Delta] , nous ne pouvons pas passer aux événements de haute priorité. Autrement dit, les événements tardifs seront encore plus tard. Et généralement, le retard est imprévisible. Pour cette raison, state.time peut être loin derrière l'heure actuelle, et c'est la cause du problème suivant. - Les événements arrivant dans la région des événements normaux peuvent être en retard ( id > state.id). Ils sont déjà hautement prioritaires et doivent être considérés comme des événements de la région rose, et nous les considérons toujours comme normaux et les traitons comme normaux.
- Il est difficile d'organiser la mise en cache des événements et le réapprovisionnement du cache (lecture à partir de la base de données).
Si les deux premiers points sont évidents, le troisième soulèvera probablement le plus de questions. Arrêtons-nous dessus plus en détail.
Supposons que nous voulons d'abord lire un nombre fixe d'événements en mémoire, puis les traiter.
Après le traitement, nous voulons marquer les événements dans la base de données avec des requêtes de bloc comme traités, car si vous ne travaillez pas avec des blocs, mais avec des événements uniques, il n'y aura pas de gros gain à partir de la mise en cache.
Supposons que nous ayons traité une partie des blocs et voulons compléter le cache. Ensuite, si des événements tardifs de haute priorité arrivent pendant le traitement, nous pouvons les traiter tôt.
Autrement dit, il est très souhaitable de pouvoir lire les événements en petits blocs afin de traiter les plus tard le plus rapidement possible, mais de mettre à jour l'attribut de traitement dans la base de données avec de gros blocs à la fois - pour plus d'efficacité.
Que faire dans ce cas?
Essayez de travailler avec la base de données en petits blocs avec une zone bleue et rose et déplacez le point d'état par petites étapes.
Ainsi, le cache a été introduit et lu à partir des éléments de données de la base de données, après chaque lecture, le point d'état a été décalé afin de ne pas relire les événements déjà lus.
Maintenant que l'algorithme est devenu un peu plus compliqué, nous avons commencé à lire en portions limitées.
Organigramme
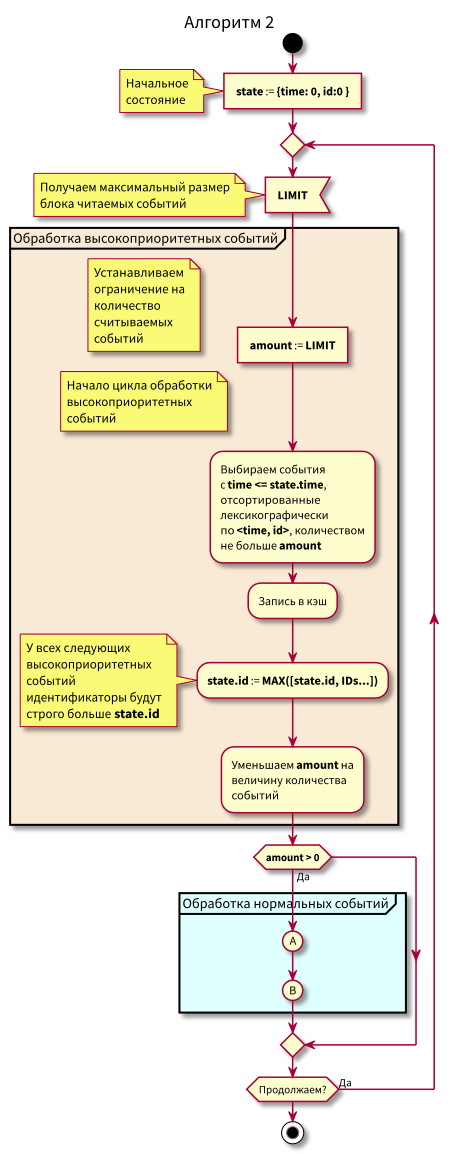
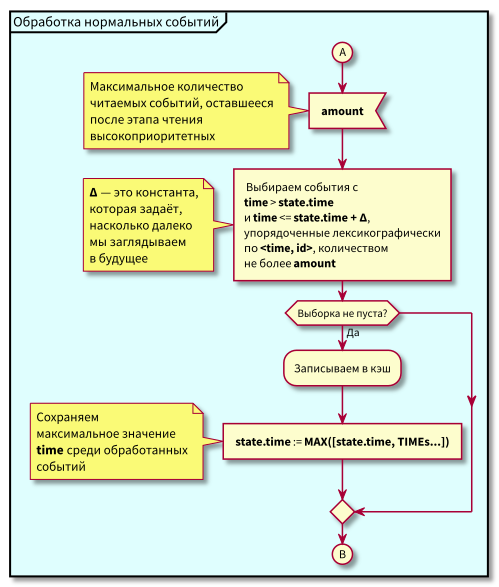
Dans cet algorithme, on peut voir qu'en raison de la restriction sur les blocs d'événements lisibles, le retard maximum dans la transition du traitement de faible priorité au traitement de haute priorité sera égal au temps de traitement maximal du bloc.
Autrement dit, nous pouvons maintenant à la fois lire les événements dans le cache en petits blocs et contrôler le retard maximal dans la transition vers le traitement des événements de haute priorité en contrôlant la taille maximale des blocs pour la lecture.
Exemple de fonctionnement d'algorithme
Regardons l'algorithme en cours, par étapes. Pour plus de commodité, prenez LIMIT = 2 .
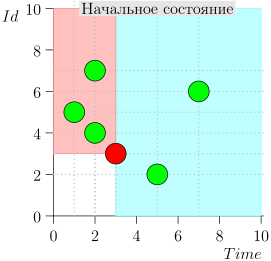
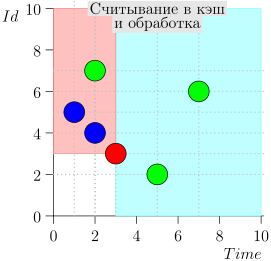
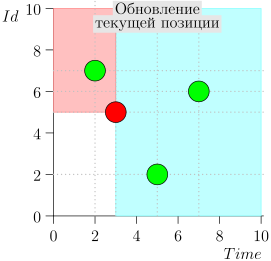
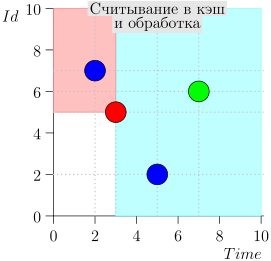
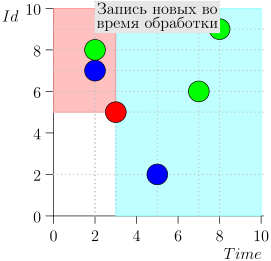
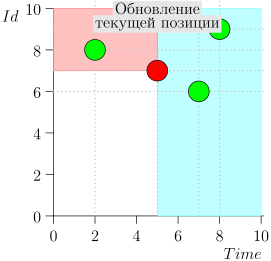
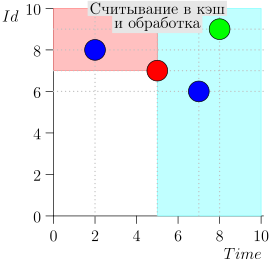
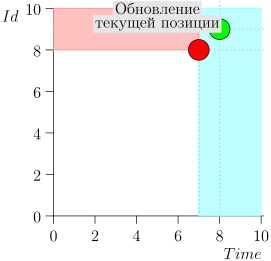
Il s'avère que le problème est résolu? Mais non. (Il est clair que si le problème a été complètement résolu à ce stade, alors
cet article n'aurait pas été :))
L'erreur?
Sous cette forme, l'algorithme a fonctionné assez longtemps. Les tests se sont tous bien déroulés. Aucun problème de production non plus.
Mais le développeur de l'algorithme et de son implémentation (mon collègue Peter Reznikov) est très expérimenté, et il a intuitivement senti que quelque chose n'allait pas ici. Par conséquent, un vérificateur a été fait à côté du code principal, qui vérifiait de temps en temps sur une minuterie pour voir s'il y avait des événements manqués, et
le cas échéant, je les ai traités.
Sous cette forme, le système a fonctionné avec succès. Certes, personne n'a conservé de statistiques sur le nombre d'événements sélectionnés par le vérificateur. Donc, malheureusement, nous ne savons pas combien d'échecs ont été associés à un traitement d'événement intempestif.
J'ai implémenté une file d'attente similaire d'objets limités dans le temps. En discutant de la mise en œuvre et de l'optimisation des algorithmes avec Peter Reznikov, nous avons parlé de cet algorithme pour travailler avec des événements. Ils doutaient que l'algorithme soit correct. Nous avons décidé de faire un petit modèle pour confirmer ou dissiper les doutes. En conséquence, nous avons trouvé une erreur.
Modèle
Avant de démonter la trace avec une erreur, je donnerai le code source du modèle sur lequel l'erreur a été détectée.
Les différences par rapport au modèle précédent sont très faibles, il n'y a qu'une limite sur la taille des blocs lus: l'opérateur Limit est ajouté et, en conséquence, les opérateurs de sélection d'événement sont modifiés.
Pour économiser de l'espace, j'ai laissé des commentaires uniquement sur les parties modifiées du modèle.
---------------- MODULE events ---------------- EXTENDS Naturals, FiniteSets, Sequences, TLC (* --algorithm Events \* LIMIT, \* \* \* variables Events = {}, Event_Id = 0, MAX_TIME = 5, LIMIT \in 1..3, TIME_DELTA \in 1..2 define ZERO_EVT == [time |-> 0, id |-> 0] MAX(S) == CHOOSE x \in S: \A y \in S: y <= x MIN(S) == CHOOSE x \in S: \A y \in S: y >= x RECURSIVE SetReduce(_, _, _) SetReduce(Op(_, _), S, value) == IF S = {} THEN value ELSE LET s == CHOOSE s \in S : TRUE IN SetReduce(Op, S \ {s}, Op(s, value)) ToSeq(S) == LET op(e, val) == Append(val, e) IN SetReduce(op, S, << >>) ToSet(S) == {S[i] : i \in DOMAIN(S)} MapSet(Op(_), S) == {Op(x) : x \in S} GetIds(Evts) == MapSet(LAMBDA x: x.id, Evts) GetTimes(Evts) == MapSet(LAMBDA x: x.time, Evts) EventsOrderByTime(e1, e2) == e1.time < e2.time EventsOrderById(e1, e2) == e1.id < e2.id EventsOrder(e1, e2) == \/ EventsOrderByTime(e1, e2) \/ /\ e1.time = e2.time /\ EventsOrderById(e1, e2) Limit(S, limit) == LET amount == MIN({limit, Len(S)}) result == IF amount > 0 THEN SubSeq(S, 1, amount) ELSE << >> IN result \* SELECT * FROM events \* WHERE time <= curr_time AND id > max_id \* ORDER BY id \* LIMIT limit SELECT_HIGH_PRIO(state, limit) == LET selected == {e \in Events : /\ e.time <= state.time /\ e.id >= state.id } \* Id sorted == SortSeq(ToSeq(selected), EventsOrderById) \* limited == Limit(sorted, limit) IN ToSet(limited) \* SELECT * FROM events \* WHERE time > current_time \* AND time - Time <= delta_time \* ORDER BY time, id \* LIMIT limit SELECT_NORMAL(state, delta_time, limit) == LET selected == {e \in Events: /\ e.time <= state.time + delta_time /\ e.time > state.time } \* sorted == SortSeq(ToSeq(selected), EventsOrder) \* limited == Limit(sorted, limit) IN ToSet(limited) ALL_EVENTS_PROCESSED(state) == \A e \in Events: \/ e.time >= state.time \/ e.id >= state.id end define; fair process inserter = "Sources" variable t; begin forever: while TRUE do get_time: with evt_time \in 0..MAX_TIME do t := evt_time; end with; commit: either Events := Events \union {[time |-> t, id |-> Event_Id]} || Event_Id := Event_Id + 1; or Event_Id := Event_Id + 1; end either; end while; end process fair process event_processor = "Event_processor" variable state = ZERO_EVT, events = {}; begin forever: while TRUE do select: events := LET evts_high_prio == SELECT_HIGH_PRIO(state, LIMIT) new_limit == LIMIT - Cardinality(evts_high_prio) evts_normal == SELECT_NORMAL(state, TIME_DELTA, new_limit) IN evts_high_prio \union evts_normal; proc_evts: Events := Events \ events || state := [ time |-> MAX({state.time} \union GetTimes(events)), id |-> MAX({state.id} \union GetIds(events))] || events := {}; end while; end process end algorithm; *) \* BEGIN TRANSLATION \* TLA+, PlusCal \* END TRANSLATION ===================================================
Un lecteur attentif peut remarquer qu'en plus d'introduire Limit, les étiquettes dans event_processor ont également été modifiées. Le but est un peu mieux de simuler du code réel que deux sélections exécutent en une seule transaction, c'est-à-dire que la sélection d'événements peut être considérée comme effectuée de manière atomique.
Eh bien, si nous trouvons une erreur dans un modèle avec des opérations atomiques plus grandes, cela garantit pratiquement que la même erreur se produit dans le même modèle, mais avec des étapes atomiques plus petites (une déclaration plutôt forte, mais je pense que c'est intuitif; bien que il doit être bon sinon prouvé, puis vérifié sur une large sélection de modèles).
Vérification du modèle
Nous commençons la simulation avec les mêmes paramètres que dans le premier mode de réalisation.
Et nous obtenons une violation de la propriété ALL_EVENTS_PROCESSED à la 19e étape de la simulation lors de la recherche en largeur.
Pour des données initiales données (il s'agit d'un très petit espace d'état), l'erreur à la 19e étape indique que l'erreur est très rare et difficile à détecter, car avant cela, toutes les chaînes d'état d'une longueur inférieure à 19 ont été examinées.
Par conséquent, cette erreur est difficile à détecter dans les tests. Uniquement si vous savez où chercher et si vous sélectionnez spécifiquement des tests et des huttes temporaires.
Je n'apporterai pas tout l'itinéraire pour gagner de l'espace et du temps. Voici un segment de plusieurs états avec une erreur:
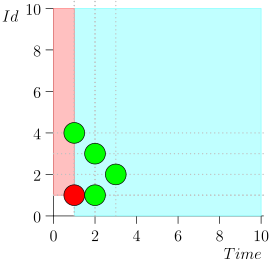

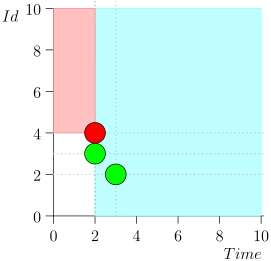
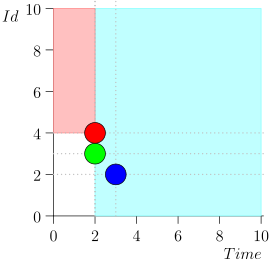
Analyse et correction
Que s'est-il passé?
Comme vous pouvez le voir, l'erreur s'est manifestée par le fait que nous avons manqué l'événement {2, 3} en raison du fait que la limite s'est terminée à l'événement {2, 1}, et après cela, nous avons changé l'état du coordinateur. Cela ne peut se produire que si à un moment donné il y a plusieurs événements.
C'est pourquoi l'erreur était insaisissable dans les tests. Pour sa manifestation, il faut que des choses assez rares coïncident:
- Plusieurs événements ont touché le même moment.
- La limite de sélection des événements s'est terminée avant le moment de la lecture de tous ces événements.
L'erreur peut être relativement facilement corrigée si l'état du coordinateur est un peu développé: ajoutez l'heure et l'identifiant du dernier événement lu dans la zone d'événements normale avec l'id maximum si l'heure de cet événement correspond à la valeur state.time suivante.
S'il n'y a pas un tel événement, nous définissons l'état supplémentaire (extra_state) sur un état non valide (UNDEF_EVT) et ne le prenons pas en compte lors du travail.
Ces événements de la région normale qui n'ont pas été traités à l'étape précédente du coordinateur, nous considérerons déjà une priorité élevée et corrigerons en conséquence la sélection du prédicat de haute priorité et de sécurité.
Il serait possible d'introduire une autre zone intermédiaire entre haute priorité et normale, et de changer l'algorithme. Tout d'abord, il traitera les plus prioritaires, puis les intermédiaires, puis passera aux normaux avec le changement d'état suivant.
Mais de tels changements conduiraient à un plus grand volume de refactoring avec des avantages non évidents (l'algorithme sera un peu plus clair; d'autres avantages ne sont pas visibles tout de suite).
Par conséquent, nous avons décidé d'ajuster légèrement l'état actuel et la sélection des événements de la base de données.
Modèle ajusté
Voici le modèle corrigé.
------------------- MODULE events ------------------- EXTENDS Naturals, FiniteSets, Sequences, TLC \* CONSTANTS MAX_TIME, LIMIT, TIME_DELTA (* --algorithm Events variables Events = {}, Limit \in LIMIT, Delta \in TIME_DELTA, Event_Id = 0 define \* \* , extra_state UNDEF_EVT == [time |-> MAX_TIME + 1, id |-> 0] ZERO_EVT == [time |-> 0, id |-> 0] MAX(S) == CHOOSE x \in S: \A y \in S: y <= x MIN(S) == CHOOSE x \in S: \A y \in S: y >= x RECURSIVE SetReduce(_, _, _) SetReduce(Op(_, _), S, value) == IF S = {} THEN value ELSE LET s == CHOOSE s \in S : TRUE IN SetReduce(Op, S \ {s}, Op(s, value)) ToSeq(S) == LET op(e, val) == Append(val, e) IN SetReduce(op, S, << >>) ToSet(S) == {S[i] : i \in DOMAIN(S)} MapSet(Op(_), S) == {Op(x) : x \in S} GetIds(Evts) == MapSet(LAMBDA x: x.id, Evts) GetTimes(Evts) == MapSet(LAMBDA x: x.time, Evts) EventsOrderByTime(e1, e2) == e1.time < e2.time EventsOrderById(e1, e2) == e1.id < e2.id EventsOrder(e1, e2) == \/ EventsOrderByTime(e1, e2) \/ /\ e1.time = e2.time /\ EventsOrderById(e1, e2) TakeN(S, limit) == LET amount == MIN({limit, Len(S)}) result == IF amount > 0 THEN SubSeq(S, 1, amount) ELSE << >> IN result (* SELECT * FROM events WHERE time <= curr_time AND id > max_id ORDER BY id Limit limit *) SELECT_HIGH_PRIO(state, limit, extra_state) == LET \* \* time <= curr_time \* AND id > maxt_id selected == {e \in Events : \/ /\ e.time <= state.time /\ e.id >= state.id \/ /\ e.time = extra_state.time /\ e.id > extra_state.id} sorted == \* SortSeq(ToSeq(selected), EventsOrderById) limited == TakeN(sorted, limit) IN ToSet(limited) SELECT_NORMAL(state, delta_time, limit) == LET selected == {e \in Events : /\ e.time <= state.time + delta_time /\ e.time > state.time } sorted == SortSeq(ToSeq(selected), EventsOrder) limited == TakeN(sorted, limit) IN ToSet(limited) \* extra_state UpdateExtraState(events, state, extra_state) == LET exact == {evt \in events : evt.time = state.time} IN IF exact # {} THEN CHOOSE evt \in exact : \A e \in exact: e.id <= evt.id ELSE UNDEF_EVT \* extra_state ALL_EVENTS_PROCESSED(state, extra_state) == \A e \in Events: \/ e.time >= state.time \/ e.id > state.id \/ /\ e.time = extra_state.time /\ e.id > extra_state.id end define; fair process inserter = "Sources" variable t; begin forever: while TRUE do get_time: with evt_time \in 0..MAX_TIME do t := evt_time; end with; commit: either Events := Events \union {[time |-> t, id |-> Event_Id]} || Event_Id := Event_Id + 1; or Event_Id := Event_Id + 1; end either; end while; end process fair process event_processor = "Event_processor" variable events = {}, state = ZERO_EVT, extra_state = UNDEF_EVT; begin forever: while TRUE do select: events := LET evts_high_prio == SELECT_HIGH_PRIO(state, Limit, extra_state) new_limit == Limit - Cardinality(evts_high_prio) evts_normal == SELECT_NORMAL(state, Delta, new_limit) IN evts_high_prio \union evts_normal; proc_evts: Events := Events \ events || state := [ time |-> MAX({state.time} \union GetTimes(events)), id |-> MAX({state.id} \union GetIds(events)) ]; extra_state := UpdateExtraState(events, state, extra_state) || events := {}; end while; end process end algorithm; *) \* BEGIN TRANSLATION \* TLA+, PlusCal \* END TRANSLATION ===================================================
Comme vous pouvez le voir, les changements sont très faibles:
- Ajout de données supplémentaires à l'état extra_state.
- Modification de la sélection des événements hautement prioritaires.
- UpdateExtraState extra_state.
- safety - .
Modélisation
, . , (, , , ).
, , TLA+/TLC . :)
Conclusion
, , ( , , , ).
, , TLA+/TLC, . , .
TLA+/TLC , , ( , ) .
, , , TLA+/TLC .
Bibliographie
Livres
, , , . .
Michael Jackson Problem Frames: Analysing & Structuring Software Development Problems
( !), . , . , .
Hillel Wayne Practical TLA+: Planning Driven Development
TLA+/PlusCal . , . . : .
MODEL CHECKING.
. , , . , .
Leslie Lamport Specifying Systems: The TLA+ Language and Tools for Hardware and Software Engineers
TLA+. , . : , . , TLA+ , .
Formal Development of a Network-Centric RTOS
TLA+ ( RTOS ) TLC.
, . , TLA+ , , RTOS — Virtuoso. , .
, (, , , , ).
w Amazon Web Services Uses Formal Methods
TLA+ AWS. : http://lamport.azurewebsites.net/tla/amazon-excerpt.html
Internet
Blogs
Hillel Wayne ( "Practical TLA+")
. , . , - .
Ron Pressler
. . , TLA+. TLA+, computer science .
Leslie Lamport
TLA+ computer science . TLA+ .
. . , . . , . . .
, , .
TLA+,
, TLA+. , TLA+.
Hillel Wayne
Hillel Wayne . .
Ron Pressler
, Hillel Wayne, . , . Ron Pressler . ́ , , .
Modélisation
TLA toolbox + TLAPS : TLA+
. Alloy Analyzer .