
Présentation
Bonjour, cher Khabrovites!
Les deux dernières années de mon travail chez
Synesis ont été étroitement liées au processus de création et de développement de
Synet - une bibliothèque ouverte pour exécuter des réseaux de neurones convolutionnels pré-formés sur le CPU. Au cours de ce travail, j'ai dû rencontrer un certain nombre de points intéressants liés à l'optimisation des algorithmes de propagation directe du signal dans les réseaux de neurones. Il me semble qu'une description de ces points serait très intéressante pour les lecteurs d'Habrahabr. Ce que je veux dédier une série de mes articles. La durée du cycle dépendra de votre intérêt pour ce sujet et, bien sûr, de ma capacité à surmonter la paresse. Je veux commencer le cycle avec une description du cadre
vélo lui-même. Les questions des algorithmes qui le sous-tendent seront révélées dans les articles suivants:
- Couche de convolution: techniques d'optimisation de la multiplication matricielle
- Couche convolutionnelle: convolution rapide selon la méthode de Shmuel Vinograd
Réponses aux questions
Avant de commencer une description détaillée du cadre, je vais essayer de répondre immédiatement à un certain nombre de questions que les lecteurs auront probablement. L'expérience suggère qu'il vaut mieux le faire à l'avance, car beaucoup commencent immédiatement à écrire des commentaires en colère, n'ayant pas lu jusqu'à la fin.
La première question qui se pose généralement dans de tels cas:
qui gère les réseaux sur des processeurs conventionnels maintenant, quand existe-t-il des accélérateurs graphiques et des accélérateurs tenseurs (matriciels)?Je répondrai que oui - il n'est vraiment pas conseillé d'effectuer une formation sur les réseaux neuronaux sur le CPU, mais l'exécution de réseaux neuronaux prêts à l'emploi est une demande importante, surtout si le réseau est suffisamment petit. Les raisons peuvent être différentes, mais les principales:
- Les processeurs sont plus courants. Toutes les machines n'ont pas de GPU, en particulier les serveurs.
- Sur les petits réseaux de neurones, les gains de l'utilisation du GPU sont faibles et parfois totalement absents.
- Impliquer efficacement le GPU pour accélérer les réseaux de neurones nécessite généralement une structure d'application beaucoup plus complexe.
La prochaine question possible:
pourquoi utiliser une solution spécialisée pour lancer quand il y a Tensorflow , Caffe ou MXNet ?Vous pouvez répondre aux questions suivantes:
- Une variété de frameworks n'est pas toujours bonne - donc s'il y a plusieurs modèles formés dans différents frameworks dans un projet, vous devrez tous les intégrer dans une solution prête à l'emploi, ce qui est très gênant.
- Les frameworks classiques ont été conçus pour former des modèles de GPU - et ils sont certainement bons à cela! Mais pour exécuter des modèles entraînés sur le CPU, leur fonctionnalité est redondante et non optimale.
- La confirmation de la nécessité d'une solution spécialisée est la popularité d' OpenVINO - un framework d'Intel, qui remplit la même fonction.
Ici, immédiatement, une question logique se pose à propos de l'invention du vélo:
pourquoi utiliser votre métier alors qu'il existe une solution totalement professionnelle d'un leader mondial reconnu?Ma réponse est:
- Au début des travaux sur Synet, OpenVINO en était encore à ses balbutiements. Et en vérité, si à cette époque OpenVINO était dans son état actuel, alors avec une forte probabilité, je ne m'impliquerais pas dans mon propre projet.
- Vous pouvez adapter votre propre framework à vos besoins. Donc, dans mon cas, l'exigence principale était la performance maximale d'un seul thread.
- Vous pouvez prendre en charge les nouvelles fonctionnalités le plus rapidement possible si vous en avez soudainement besoin (par exemple, ajoutez une nouvelle couche et éliminez une erreur de performances).
- Facile à intégrer dans une solution clé en main.
- Le fonctionnement de la bibliothèque sur des plates-formes autres que x86 / x86_64 - par exemple, sur ARM.
Il est probable que les lecteurs auront d'autres questions ou objections - mais je ne peux toujours pas les prédire, et donc je répondrai dans les commentaires de l'article. En attendant, commençons par une description directe de Synet.
Synet Short Description
Synet est écrit en
C ++ et ne contient que des
fichiers d'en-tête . Des optimisations
spécifiques aux plates-formes de bas niveau sont implémentées dans
Simd , un autre projet open source dédié à l'accélération du traitement des images sur un CPU. Et c'est la seule dépendance externe de Synet (un tel schéma a été choisi afin de faciliter l'intégration de la bibliothèque dans des projets tiers). Pour lancer des réseaux de neurones, des modèles de leur propre format interne sont utilisés.
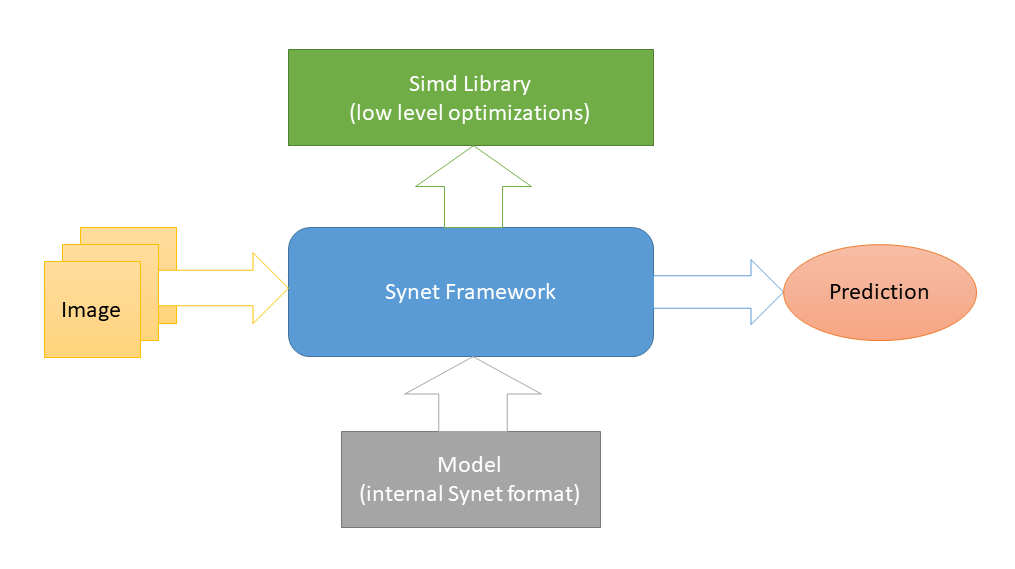
La conversion des modèles pré-formés au format interne s'effectue selon un schéma en deux étapes: 1) Tout d'abord, convertissez le modèle au format Inference Engine (bon
OpenVINO dispose de tous les
outils nécessaires pour cela). 2) Puis, à partir de cette représentation intermédiaire, convertissez directement au format Synet interne.

Le modèle Synet contient deux fichiers: 1) * .XML - un fichier avec une description de la structure du modèle. 2) * .BIN - un fichier avec des poids formés.

Exemple de Synet
Voici un exemple d'utilisation de Synet pour détecter des visages. Le modèle d'origine du moteur d'inférence est pris
ici .
#define SYNET_SIMD_LIBRARY_ENABLE #include "Synet/Network.h" #include "Synet/Converters/InferenceEngine.h" #include "Simd/SimdDrawing.hpp" typedef Synet::Network<float> Net; typedef Synet::View View; typedef Synet::Shape Shape; typedef Synet::Region<float> Region; typedef std::vector<Region> Regions; int main(int argc, char* argv[]) { Synet::ConvertInferenceEngineToSynet("ie_fd.xml", "ie_fd.bin", true, "synet.xml", "synet.bin"); Net net; net.Load("synet.xml", "synet.bin"); net.Reshape(256, 256, 1); Shape shape = net.NchwShape(); View original; original.Load("faces_0.ppm"); View resized(shape[3], shape[2], original.format); Simd::Resize(original, resized, ::SimdResizeMethodArea); net.SetInput(resized, 0.0f, 255.0f); net.Forward(); Regions faces = net.GetRegions(original.width, original.height, 0.5f, 0.5f); uint32_t white = 0xFFFFFFFF; for (size_t i = 0; i < faces.size(); ++i) { const Region & face = faces[i]; ptrdiff_t l = ptrdiff_t(face.x - face.w / 2); ptrdiff_t t = ptrdiff_t(face.y - face.h / 2); ptrdiff_t r = ptrdiff_t(face.x + face.w / 2); ptrdiff_t b = ptrdiff_t(face.y + face.h / 2); Simd::DrawRectangle(original, l, t, r, b, white); } original.Save("annotated_faces_0.ppm"); return 0; }
À la suite de l'exemple, une image avec des visages annotés devrait apparaître:

Prenons maintenant un exemple des étapes:
- Tout d'abord, le modèle est converti du format Inference Engine en Synet:
Synet::ConvertInferenceEngineToSynet("ie_fd.xml", "ie_fd.bin", true, "synet.xml", "synet.bin");
En réalité, cette étape est effectuée une fois, puis le modèle déjà converti est utilisé partout. - Téléchargez le modèle converti:
Net net; net.Load("synet.xml", "synet.bin");
- Une étape facultative pour redimensionner l'image d'entrée et le lot (naturellement, le modèle doit prendre en charge le redimensionnement de l'image d'entrée):
net.Reshape(256, 256, 1);
- Charger une image et la mettre dans la taille d'entrée du modèle:
View original; original.Load("faces_0.ppm"); View resized(net.NchwShape()[3], net.NchwShape()[2], original.format); Simd::Resize(original, resized, ::SimdResizeMethodArea);
- Chargement de l'image dans le modèle:
net.SetInput(resized, 0.0f, 255.0f);
- Démarrage de la propagation directe du signal dans le réseau:
net.Forward();
- Obtenir un ensemble de régions avec des visages trouvés:
Regions faces = net.GetRegions(original.width, original.height, 0.5f, 0.5f);
Comparaison des performances
Il ne serait probablement pas tout à fait correct de comparer Synet avec des frameworks classiques pour l'apprentissage automatique, par exemple, le moteur d'inférence les
contourne plusieurs fois sur un certain nombre de tests .
Par conséquent, ce qui suit est un exemple de comparaison des performances monothread du moteur d'inférence (un produit de fonctionnalités similaires) et de Synet sur un échantillon d'un
ensemble de modèles ouverts :
Comme le montre le tableau, dans ces tests sur une machine prenant en charge AVX2 (i7-6700), les performances de Synet correspondent généralement aux performances du moteur d'inférence (bien qu'elles varient considérablement d'un modèle à l'autre). Sur une machine prenant en charge l'AVX-512 (i9-7900X), les performances de Synet sont en moyenne 25% supérieures à celles du moteur d'inférence.
Toutes les mesures ont été effectuées par l'application de test, qui se trouve dans Synet. Ainsi, si vous le souhaitez, les lecteurs pourront reproduire les tests eux-mêmes:
git clone -b master --recurse-submodules -v https://github.com/ermig1979/Synet.git synet cd synet ./build.sh inference_engine ./test.sh
Avantages et inconvénients
Je vais commencer par les pros:
- Le projet est de petite taille, facilement mis en œuvre dans des projets tiers.
- Affiche des performances monothread élevées.
- Fonctionne sur les processeurs mobiles (prend en charge ARM-NEON).
Eh bien et par contre, où sans eux:
- Il n'y a pas de support pour GPU et autres accélérateurs spéciaux.
- Mauvaise parallélisation d'une tâche sur les processeurs multicœurs.
- Pas de support pour INT8 (quantification des poids).
Conclusion
Synet est actuellement utilisé dans le cadre du projet
Kipod , une plate-forme cloud pour l'analyse vidéo. Peut-être qu'il a d'autres utilisateurs, mais ce n'est pas sûr :). À l'avenir, au fur et à mesure du développement du projet, je voudrais y ajouter les éléments suivants:
- Prise en charge de nouveaux modèles, couches, algorithmes.
- Prise en charge des calculs d'entiers au format INT8 (poids quantifiés).
- Prise en charge de l'informatique GPU.
- Convertissez à partir du format ONNX.
Cette liste est loin d'être complète, et je voudrais la compléter en tenant compte de l'avis de la communauté - j'attends donc vos retours! Rendre l'outil utile non seulement pour notre entreprise, mais aussi pour un large éventail d'utilisateurs. De plus, l'auteur ne refuserait pas l'aide communautaire au processus de développement.
En décrivant Synet, que j'ai fait dans cet article, je n'ai pas intentionnellement fouillé dans les détails de son implémentation interne - il y a beaucoup d'algorithmes savoureux sous le capot, mais je voudrais divulguer les détails de leur implémentation dans les articles suivants de la série:
- Couche de convolution: techniques d'optimisation de la multiplication matricielle
- Couche convolutionnelle: convolution rapide selon la méthode de Shmuel Vinograd