 Vous pouvez télécharger le fichier avec le code et les données dans l'article d' origine sur mon blog
Vous pouvez télécharger le fichier avec le code et les données dans l'article d' origine sur mon blogIl y a un projet très intéressant - «
Rosetta Code» . Leur objectif est de «présenter la solution des mêmes problèmes dans le plus grand nombre possible de langages de programmation différents afin de démontrer leurs points communs et leurs différences et d'aider une personne qui a les connaissances nécessaires pour résoudre le problème avec une méthode à en apprendre une autre».
Cette ressource offre une occasion unique de comparer les codes de programme dans différentes langues, ce que nous ferons dans cet article. Il s'agit d'une révision complète et d'un raffinement de l'article de John MacLoon "
Code Length Measured in 14 Languages ".
Importer et analyser des données
Commençons par créer une modification de la fonction d'
importation qui stockera les données pour une utilisation future afin de ne pas les demander plus tard au serveur.
Clear[importOnce]; importOnce[args___]:=importOnce[args]=Import[args]; If[FileExistsQ[#], Get[#], Null]&@FileNameJoin[{NotebookDirectory[], "importOnce.mx"}]
Créez un analyseur pour importer des données.
Clear[createPageLinkDataset]; createPageLinkDataset[baseLink_]:=createPageLinkDataset[baseLink]=Cases[Cases[Import[baseLink, "XMLObject"], XMLElement["div", {"class"->"mw-content-ltr", "dir"->"ltr", "lang"->"en"}, data_]:>data, Infinity], XMLElement["li", {}, {XMLElement["a", {___, "href"->link_, ___}, {name_}]}]:><|"name"->name, "link"->"http://rosettacode.org"<>link|>, Infinity]; If[FileExistsQ[#], Get[#], Null]&@FileNameJoin[{NotebookDirectory[], "createPageLinkDataset.mx"}]
Nous importons la liste de tous les langages de programmation supportés par le projet (il y en a déjà plus de 750):
$Languages=createPageLinkDataset["http://rosettacode.org/wiki/Category:Programming_Languages"]; Dataset@$Languages

Nous allons créer des fonctions pour traduire le nom en lien et vice versa, cela nous sera utile plus tard:
langLinkToName[link_String]:=langLinkToName[link]=SelectFirst[$Languages, #[["link"]]==link&]["name"]; langNameToLink[name_String]:=langNameToLink[name]=SelectFirst[$Languages, #[["name"]]==name&]["link"];
Nous chargerons la liste des tâches résolues dans chacun des langages de programmation. L'analyse est conçue pour que tous les liens vers des pages ne soient pas des tâches. Nous les nettoierons plus tard.
$LangTasksAllPre=Map[<|"name"->#["name"], "link"->#["link"], "tasks"->createPageLinkDataset[#["link"]][[All, "link"]]|>&, $Languages]; Dataset@$LangTasksAllPre

Nous calculons une liste de toutes les tâches potentielles qui peuvent être résolues dans le projet (il y en a un peu plus de 2600):
$TasksPre=DeleteDuplicates[Flatten[$LangTasksAllPre[[;;, "tasks"]]]]; Length[$TasksPre]

Créons une fonction qui capture tous les fragments de code sur la page des tâches.
ClearAll[codeExtractor]; codeExtractor[link_String]:=Module[{code, positions, rawData}, code=importOnce[link, "XMLObject"]; positions=Map[{#[[1, 1;;-2]], Partition[#[[;;, -1]], 2, 1]}&, DeleteCases[ Gather[ Position[code, XMLElement["h2", _, title_]], And[Length[#1]==Length[#2], #1[[1;;-2]]==#2[[1;;-2]]]&], x_/; Length[x]==1]]; rawData=Framed/@Flatten[Map[ With[{pos=#[[1]]}, Map[Extract[code, pos][[#[[1]];;#[[2]]-1]]&, #[[2]]]]&, positions], 1]; Association@DeleteCases[Map[langLinkToName[("link"/.#)]->("code"/.#)&, Map[ KeyValueMap[If[#1==="link", #1->#2[[1]], #1->#2]&, Merge[SequenceSplit[Cases[#, Highlighted[x_, ___]:>x, Infinity], {"Output"}][[1]], Identity]]&, rawData/.{XMLElement["h2", _, title_]:>Cases[title, XMLElement["a", {___, "href"->linkInner_/; MemberQ[$Languages[[;;, "link"]], "http://rosettacode.org"<>linkInner], ___}, {___}]:>Highlighted[<|"link"->"http://rosettacode.org"<>linkInner|>], Infinity], XMLElement["div", {}, x_/; Not[FreeQ[x, "Output:"]]]:>Highlighted["Output"], XMLElement["pre", _, code_]:>Highlighted[<|"code"->Check[StringJoin@Flatten[code//.XMLElement["span", _, codeFragment_]:>codeFragment//.XMLElement["br", {"clear"->"none"}, {}]:>"\n"//.XMLElement["a", {___}, codeFragment_]:>codeFragment//.XMLElement["b", {}, {x_}]:>x//.XMLElement["big", {}, {x_}]:>x//.XMLElement["sup", {}, x_]:>Flatten[x]//.XMLElement["sub", {}, x_]:>Flatten[x]//.XMLElement[_, {___}, x_]:>Flatten[x]], Echo[StringJoin@Flatten[code//.XMLElement["span", _, codeFragment_]:>codeFragment//.XMLElement["br", {"clear"->"none"}, {}]:>"\n"//.XMLElement["a", {___}, codeFragment_]:>codeFragment//.XMLElement["b", {}, {x_}]:>x//.XMLElement["big", {}, {x_}]:>x//.XMLElement["sup", {}, x_]:>Flatten[x]//.XMLElement["sub", {}, x_]:>Flatten[x]//.XMLElement[_, {___}, x_]:>Flatten[x]]]]|>, Background->Red]} ]], _->"code"]];
Nous allons maintenant traiter toutes les pages:
ClearAll[taskCodes]; taskCodes[link_]:=taskCodes[link]=Check[codeExtractor[link], Echo[link]]; If[FileExistsQ[#], Get[#], taskCodes/@$TasksPre; DumpSave[#, taskCodes]]&@FileNameJoin[{NotebookDirectory[], "taskCodes.mx"}];
Un exemple de ce que la fonction produit:
Dataset[taskCodes[$TasksPre[[20]]]]
Sélectionnez les pages de tâches (celles contenant au moins un morceau de code):
$taskLangs=DeleteCases[{#, taskCodes[#]}&/@$TasksPre, {_, <||>}];
$langTasks=Map[<|"name"->#[["name"]], "link"->#[["link"]], "tasks"->With[{lang=#[["name"]]}, Select[$taskLangs, MemberQ[Keys[#[[2]]], lang]&][[;;, 1]]]|>&, $Languages]; Dataset[$langTasks]

Une liste de tâches et de fonctions qui traduisent le nom de la tâche en lien, et vice versa:
$Tasks=<|"name"->StringReplace[URLDecode[StringReplace[#, "http://rosettacode.org/wiki/"->""]], {"_"->" ", "/"->" -> "}], "link"->#|>&/@$taskLangs[[;;, 1]]; taskLinkToName[link_String]:=langLinkToName[link]=SelectFirst[$Tasks, #[["link"]]==link&]["name"]; taskNameToLink[name_String]:=langNameToLink[name]=SelectFirst[$Tasks, #[["name"]]==name&]["link"];
Statistiques simples
Pour un certain nombre de langues, il n'y a toujours pas de problème résolu:
WordCloud[1/StringLength[#]->#&/@Select[$langTasks, Length[#["tasks"]]==0&][[All, "name"]], ImageSize->{1200, 800}, MaxItems->All, WordOrientation->{

Liste des langues qui ont résolu des problèmes:
$LanguagesWithTasks=Select[$langTasks, Length[#["tasks"]]=!=0&][[All, "name"]]; Length[$LanguagesWithTasks]
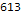
Répartition du nombre de problèmes résolus par langue:
Histogram[Length/@$langTasks[[;;, "tasks"]], 50, PlotRange->All, BarOrigin->Bottom, AspectRatio->1/2, ImageSize->700, Background->White, Frame->True, GridLines->Automatic, FrameLabel->Map[Style[#, 20]&, {" ", lg[" "]}], ScalingFunctions->"Log10", PlotLabel->Style[" ", 20]]
Répartition du nombre de langues par tâches résolues:
Histogram[Length/@$taskLangs[[;;, 2]], 50, PlotRange->All, AspectRatio->1/2, ImageSize->700, Background->White, Frame->True, GridLines->Automatic, FrameLabel->Map[Style[#, 20]&, {" ", " "}], PlotLabel->Style[" ", 20]]

Langues dans lesquelles les problèmes les plus résolus sont:
BarChart[#1[[;;, 2]], PlotRangePadding->0, BarSpacing -> 0.1, BarOrigin -> Left, AspectRatio -> 1, ImageSize -> 1000, ChartLabels -> #1[[;;, 1]], Frame -> True, GridLines -> {Range[0, 10^3, 50], None}, ColorFunction -> ColorData["Rainbow"], FrameLabel->{{None, None}, Style[#, FontFamily->"Open Sans Light", 16]&/@{" ", " "}}, FrameTicks->{Automatic, {All, All}}, Background->White] &@DeleteCases[SortBy[{#[["name"]], Length[#[["tasks"]]]}&/@$langTasks, Last], {_, x_/; x<200}]

Tâches résolues dans le plus grand nombre de langages de programmation:
BarChart[#1[[;;, 2]], PlotRangePadding->0, BarSpacing -> 0.2, BarOrigin -> Left, AspectRatio -> 1.6, ImageSize -> 1000, ChartLabels -> #1[[;;, 1]], Frame -> True, GridLines -> {Range[0, 10^3, 50], None}, ColorFunction -> ColorData["Rainbow"], FrameLabel->{{None, None}, Style[#, FontFamily->"Open Sans Light", 16]&/@{" ", " "}}, FrameTicks->{Automatic, {All, All}}, Background->White] &@DeleteCases[SortBy[{taskLinkToName[#[[1]]], Length[#[[2]]]}&/@$taskLangs, Last], {_, x_/; x<100}]

Tâches qui ont une solution pour un ensemble donné de langages de programmation
Une fonction qui affiche les tâches résolues dans un ou plusieurs langages de programmation à la fois:
commonTasks[lang_String]:=commonTasks[lang]=Sort[SelectFirst[$langTasks, #["name"]==lang&][["tasks"]]]; commonTasks["Mathematica"]:=commonTasks["Mathematica"]=Union[commonTasks["Wolfram Language"], Sort[SelectFirst[$langTasks, #["name"]=="Mathematica"&][["tasks"]]]]; commonTasks[lang_List]:=commonTasks[lang]=Sort[Intersection@@(commonTasks/@lang)];
Tâches communes aux 25 premières langues les plus utilisées (la taille de la police correspond au nombre relatif de langues dans lesquelles le problème est résolu):
WordCloud[With[{tasks=taskLinkToName/@commonTasks[SortBy[{#[["name"]], Length[#[["tasks"]]]}&/@$langTasks, Last][[-25;;-1]][[;;, 1]]]}, Transpose@{tasks, tasks/.Rule@@@SortBy[{taskLinkToName[#[[1]]], Length[#[[2]]]}&/@$taskLangs, Last]}], ImageSize->{1000, 1000}, MaxItems->All, WordOrientation->{

Fonction de mesure de la longueur du code
Ensuite, nous avons besoin d'une métrique pour estimer la longueur du code. On pense généralement que c'est le nombre de lignes de code:
SetAttributes[lineCount, Listable] lineCount[str_String]:=StringCount[StringReplace[StringReplace[str, {" "->"", "\t"->""}], "\n"..->"\n"], "\n"]+1;
Mais comme ce paramètre est considérablement affecté par le balisage du code (à la fin, par exemple, dans Wolfram Langiuage (
Mathematica ), vous pouvez écrire plusieurs commandes sur une seule ligne à la fois), nous utiliserons le nombre de caractères qui ne sont pas des espaces comme métrique.
SetAttributes[characterCount, Listable] characterCount[str_String]:=StringLength[StringReplace[str, WhitespaceCharacter->""]];
Une telle métrique ne joue pas entre les mains de
Mathematica avec ses longs noms de commande descriptifs (ce qui est sans aucun doute un gros plus en dehors de ce blog); par conséquent, nous implémentons également une métrique basée sur le comptage des jetons (objets «symboliques»), pour laquelle nous prendrons des mots individuels séparés par tout caractère qui n'est la lettre.
SetAttributes[tokens, Listable] tokens[str_String]:=DeleteCases[StringSplit[str, Complement[Characters@FromCharacterCode[Range[1, 127]], CharacterRange["a", "z"], CharacterRange["A", "Z"], CharacterRange["0", "9"], {"."}]], ""]; tokenCount[str_String]:=Length[tokens[str]];
Mesure de longueur de code
Nous obtenons un ensemble de données concernant chaque tâche:
$taskData=Map[<|"name"->#[[1]], "lineCount"->Map[lineCount, #[[2]]], "characterCount"->Map[characterCount, #[[2]]], "tokens"->Map[Flatten[tokens[#]]&, #[[2]]]|>&, $taskLangs]; Dataset[$taskData]

Une fonction qui recueille des statistiques pour chaque langue concernant toutes les tâches résolues dessus:
Clear[langData]; langData[name_]:=langData[name]=<|"name"->name, "lineCount"->If[name==="Mathematica", DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "lineCount"]], name]]]~Join~DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "lineCount"]], "Wolfram Language"]]], AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "lineCount"]], name]]], "characterCount"->If[name==="Mathematica", DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "characterCount"]], name]]]~Join~DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "characterCount"]], "Wolfram Language"]]], AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "characterCount"]], name]]], "tokens"->If[name==="Mathematica", DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "tokens"]], name]]]~Join~DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "tokens"]], "Wolfram Language"]]], AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "tokens"]], name]]]|>&@(With[{task=#}, SelectFirst[$taskData, #[["name"]]==task&]]&/@commonTasks[name]); Map[langData, $LanguagesWithTasks];
Une fonction qui compare les mesures de comparaison pour deux (ou plus) langages de programmation en fonction de toutes les tâches courantes:
ClearAll[compareLanguagesData, compareLanguages]; compareLanguagesData[langs_List/; Length[langs]>=2]:=compareLanguagesData[langs]=Module[{tasks, data}, tasks=commonTasks[langs]; data=langData/@langs; <|"lineCount"->Transpose[Lookup[#[["lineCount"]], tasks][[;;, 1]]&/@data], "characterCount"->Transpose[Lookup[#[["characterCount"]], tasks][[;;, 1]]&/@data], "tokensCount"->Transpose[Lookup[Map[Length, #[["tokens"]]], tasks]&/@data]|> ]; compareLanguages[langs_List/; Length[langs]>=2, function_]:=Module[{data}, data=compareLanguagesData[langs]; Map[Map[function, #]&, data] ];
Analyse et visualisation
Maintenant, nous pouvons obtenir beaucoup d'analyses.
Pour commencer, nous comparons les indicateurs absolus. La fonction ci-dessous construit un graphique dans lequel les points montrent les valeurs correspondantes pour deux langues. Si le point est en dessous de la ligne diagonale (l'échelle le long des axes est différente, souvent si la longueur du code varie fortement), cela signifie que la langue du bas "gagne", sinon la langue est "d'en haut".
compareGraphic[{lang1_, lang2_}]:= Grid[{#[[1;;2]], {#[[3]], SpanFromLeft}}&@KeyValueMap[Graphics[{Map[{If[#[[1]]<#[[2]], Orange, Darker@Green], Point[#]}&, #2], AbsoluteThickness[2], Gray, InfiniteLine[{{0, 0}, {1, 1}}]}, PlotRangePadding->0, GridLines->Automatic, AspectRatio->1, PlotRange->All, Frame->True, ImageSize->500, Background->White, FrameLabel->(Style[#/."Mathematica"->"Wolfram Language (Mathematica)", 16, FontFamily->"Open Sans Light"]&/@{lang1, lang2}), PlotLabel->(Style[(#1/.{"lineCount"->" ", "characterCount"->" ", "tokensCount"->" "}), 20, FontFamily->"Open Sans Light"])]&, compareLanguages[{lang1, lang2}, Identity]], Background->White]
Vous pouvez voir clairement que le code Wolfram Language est toujours presque plus court que le code C:
compareGraphic[{"Mathematica", "C"}]

Ou Pytnon:
compareGraphic[{"Mathematica", "Python"}]

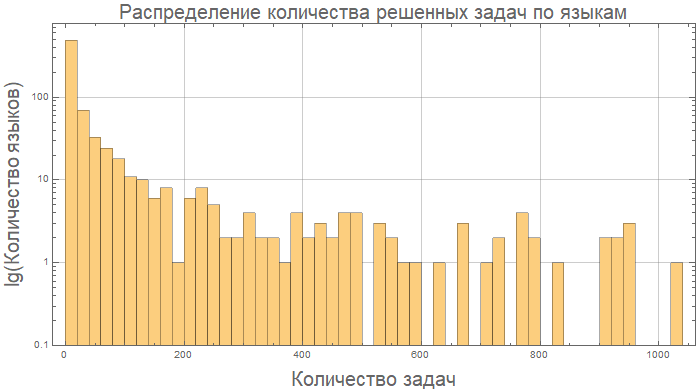
Et ici, par exemple, Kotlin et Java sont essentiellement "les mêmes" en termes de longueur de code:
compareGraphic[{"Kotlin", "Java"}]
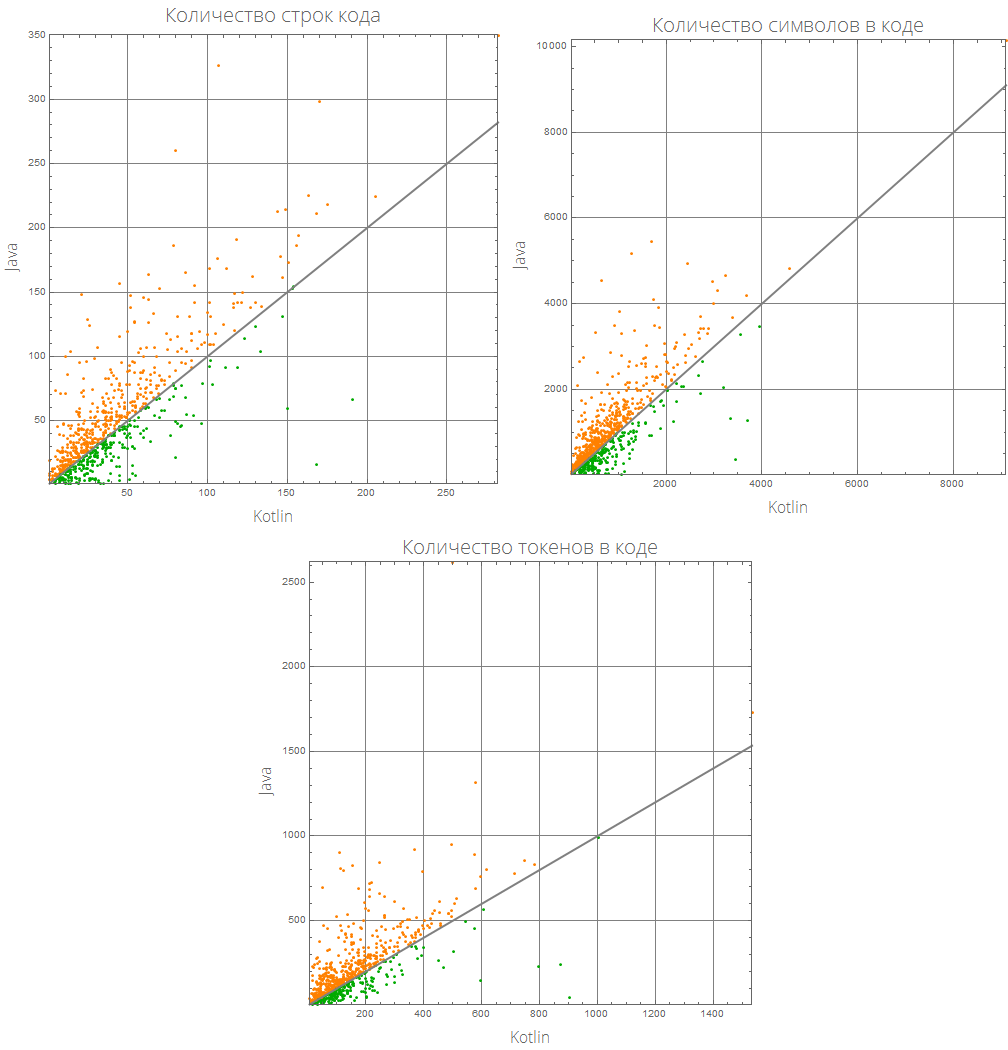
Cette représentation graphique peut être rendue plus informative:
comparePlot[{lang1_, lang2_}]:= Grid[{#[[1;;2]], {#[[3]], SpanFromLeft}}&@KeyValueMap[ListLinePlot[Sort@#2, GridLines->Automatic, AspectRatio->1, PlotRange->{Automatic, {0, 2}}, Frame->True, ImageSize->500, Background->White, FrameLabel->(Style[#/."Mathematica"->"Wolfram Language (Mathematica)", 16, FontFamily->"Open Sans Light"]&/@{lang1, lang2}), PlotLabel->(Style[(#1/.{"lineCount"->" ", "characterCount"->" ", "tokensCount"->" "}), 20, FontFamily->"Open Sans Light"]), ColorFunction->(If[#2>1, Orange, Darker@Green]&), ColorFunctionScaling->False, PlotStyle->AbsoluteThickness[3]]&, compareLanguages[{lang1, lang2}, Divide[#[[1]], #[[2]]]&]], Background->White]
comparePlot[{"Mathematica", "R"}]
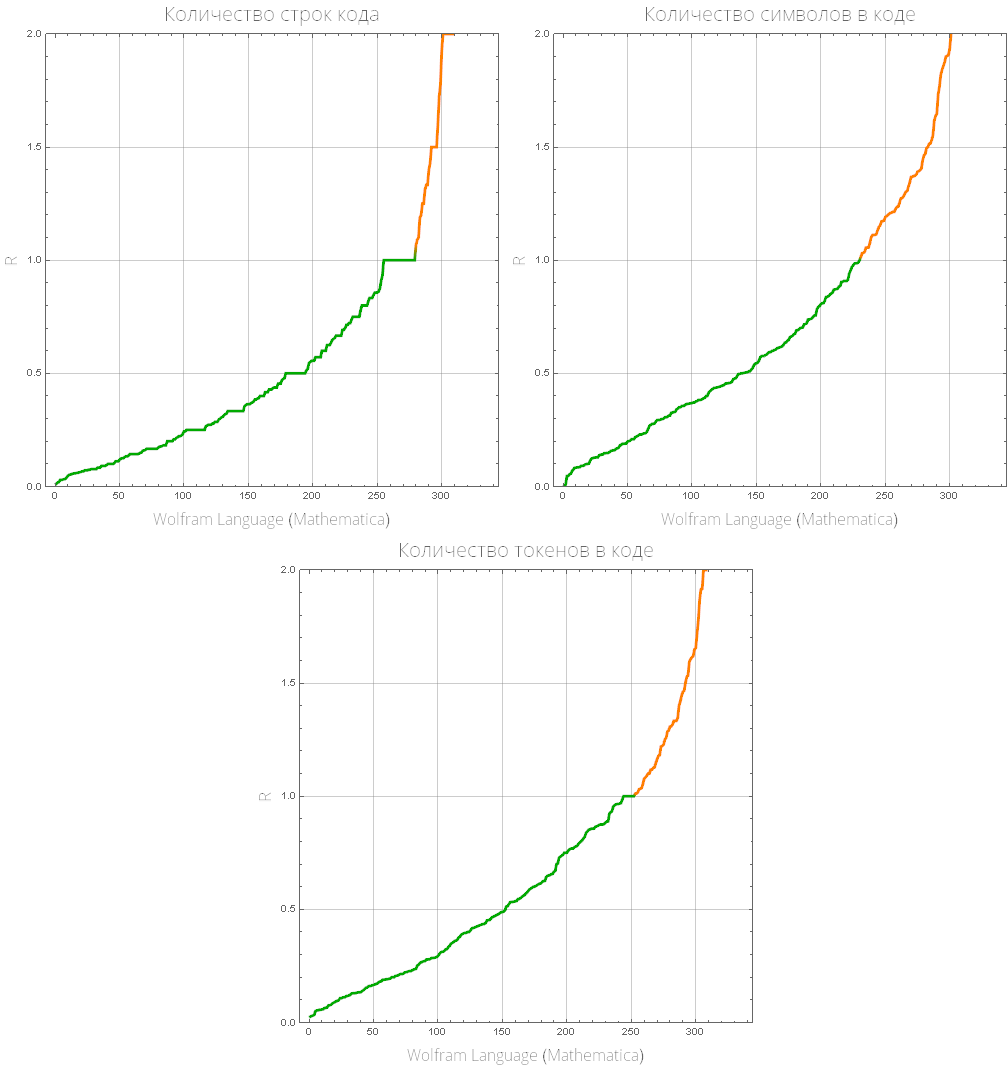
comparePlot[{"BASIC", "ALGOL 68"}]
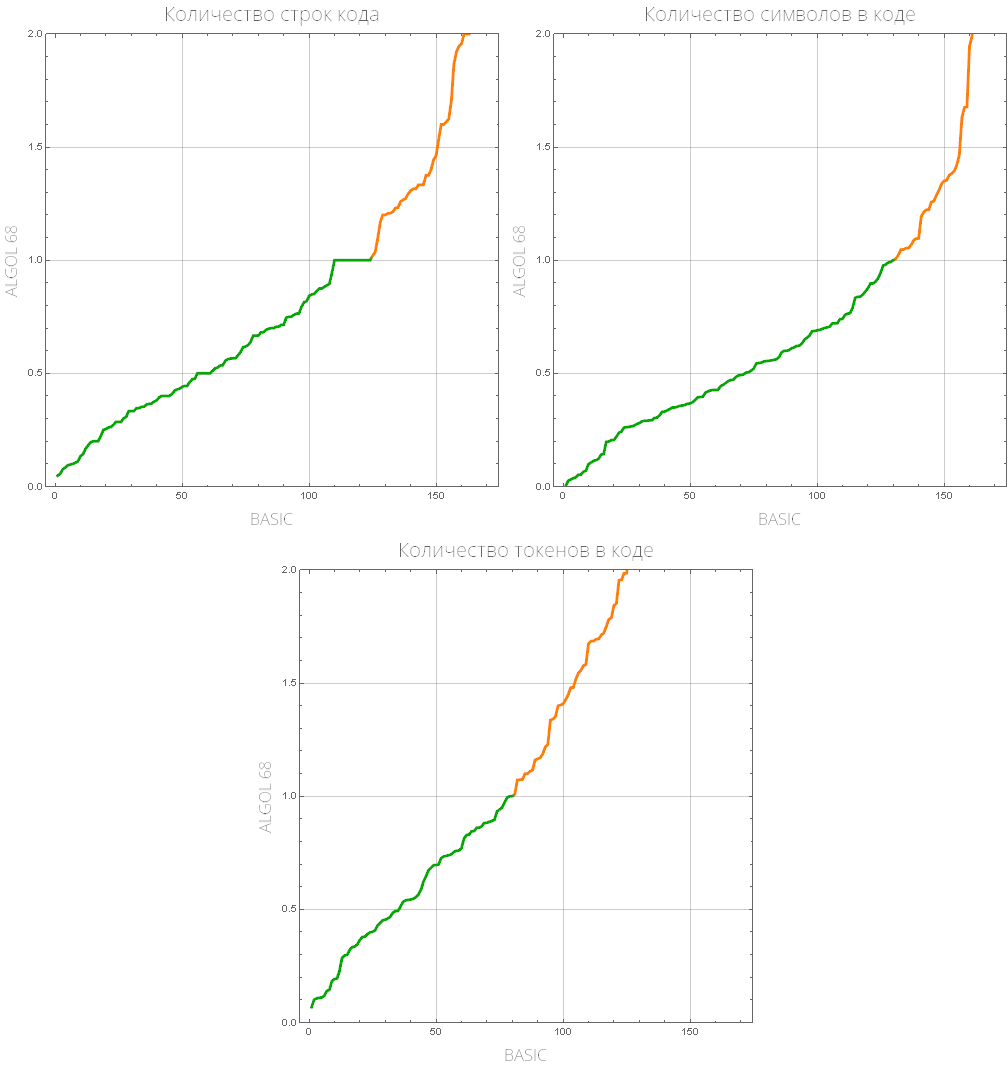
Nous définissons une fonction qui affichera une liste de langages de programmation «populaires» (ceux avec le plus grand nombre de tâches résolues):
Clear[$popularLanguages]; $popularLanguages[n_/; n>2]:=$popularLanguages[n]=Reverse[SortBy[{#[["name"]], Length[#[["tasks"]]]}&/@$langTasks, Last][[-n;;-1]]]
$popularLanguages[25]

Nous visualisons la liste des 350 premières langues (c'est ainsi que l'économiseur d'écran de ce post a été créé au début):
WordCloud[$popularLanguages[350], ColorNegate@Binarize@ImageCrop@Import@"D:\\YandexDisk\\WolframMathematicaRuFiles\\388-3885229_rosetta-stone-silhouette-stone-silhouette-png-transparent-png.png", ImageSize->1000, MaxItems->All, WordOrientation->{

Une fonction qui affiche l'analyse de la longueur du code dans différentes métriques pour les n premières langues populaires:
ClearAll[langMetricsGrid]; langMetricsGrid[n_Integer, type_, OptionsPattern[{"SortQ"->True, "measureFunction"->Mean}]]:=Module[{$nPL, $pl, tableData, scale, notSortedTableData, order, fullTableData, min, max, orderedMeans, meanFunction}, $nPL=n; meanFunction[{lang1_, lang2_}]:=Quiet[Map[Median[N[#]]&, compareLanguages[{lang1, lang2}, Divide[#[[1]], #[[2]]]&]/.ComplexInfinity->Nothing/.Indeterminate->Nothing]]; $pl=$popularLanguages[$nPL][[;;, 1]]; tableData=Quiet@Table[If[i==j, "", meanFunction[{$pl[[i]], $pl[[j]]}][[type]]], {i, 1, $nPL}, {j, 1, $nPL}]; order=If[OptionValue["SortQ"], Ordering[tableData, All, OptionValue["measureFunction"][#1/.""->Nothing]<OptionValue["measureFunction"][#2/.""->Nothing]&], Range[1, $nPL]]; orderedMeans=Round[If[OptionValue["SortQ"], Map[Mean, tableData/.""->Nothing][[order]], Map[Mean, tableData/.""->Nothing]], 1/1000]//N; {min, max}=MinMax[Cases[Flatten[tableData], _?NumericQ]]; scale=Function[Evaluate[Rescale[#, {min, max}, {0, 1}]]]; fullTableData=Transpose[{{""}~Join~$pl[[order]]}~Join~{{""}~Join~orderedMeans}~Join~Transpose[{Map[Rotate[#, 90Degree]&, $pl]}~Join~ReplaceAll[tableData, x_?NumericQ:>Item[Round[x, 1/100]//N, Background->Which[x<1, LightGreen, x==1, LightBlue, x>1, LightRed]]][[order]]/.""->Item["", Background->Gray]]]; Framed[Labeled[Style[Row[{" ", Style[type/.{"lineCount"->" ", "characterCount"->" ", "tokensCount"->" "}, Bold], "\n "}], 22, FontFamily->"Open Sans Light", TextAlignment->Center], Grid[fullTableData, Background->White, ItemStyle->Directive[FontSize -> 12, FontFamily->"Open Sans Light"], Dividers->White]], FrameStyle->None, Background->White]];
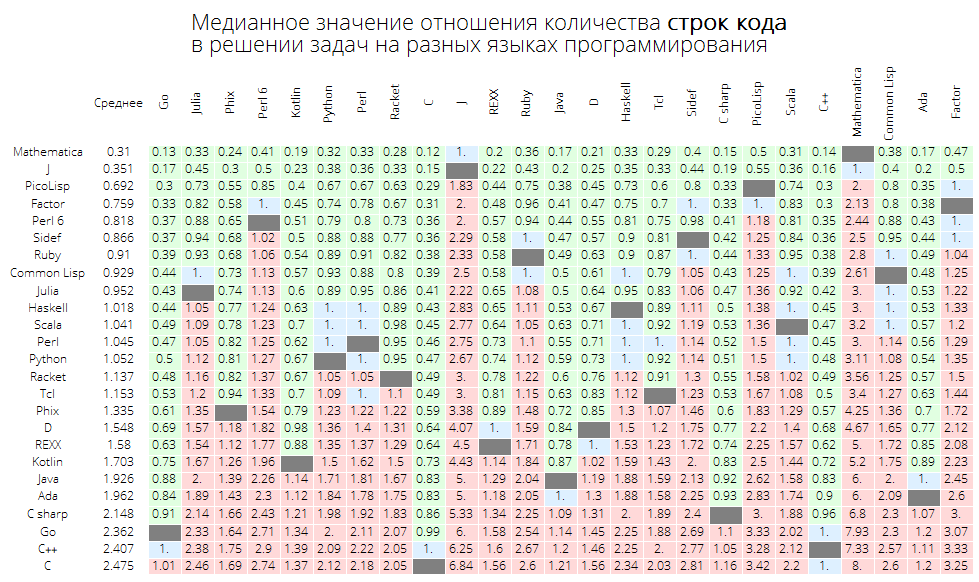
La valeur médiane du rapport du nombre de lignes de code dans la résolution de problèmes dans différents langages de programmation:
langMetricsGrid[25, "lineCount", "SortQ"->False]

Si vous triez le tableau par la colonne "Moyenne", ce sera plus évident - Wolfram Language (Mathematica) mène:
langMetricsGrid[25, "lineCount", "SortQ"->True]
La valeur médiane du rapport du nombre de caractères dans le code pour résoudre des problèmes dans différents langages de programmation:
langMetricsGrid[25, "characterCount", "SortQ"->True]

La valeur médiane du rapport du nombre de jetons dans le code pour résoudre des problèmes dans différents langages de programmation:
langMetricsGrid[25, "tokensCount", "SortQ"->True]

Les mêmes tables peuvent être construites, par exemple, pour les 50 premières langues les plus populaires:
langMetricsGrid[50, "lineCount", "SortQ"->True] langMetricsGrid[50, "characterCount", "SortQ"->True] langMetricsGrid[50, "tokensCount", "SortQ"->True]



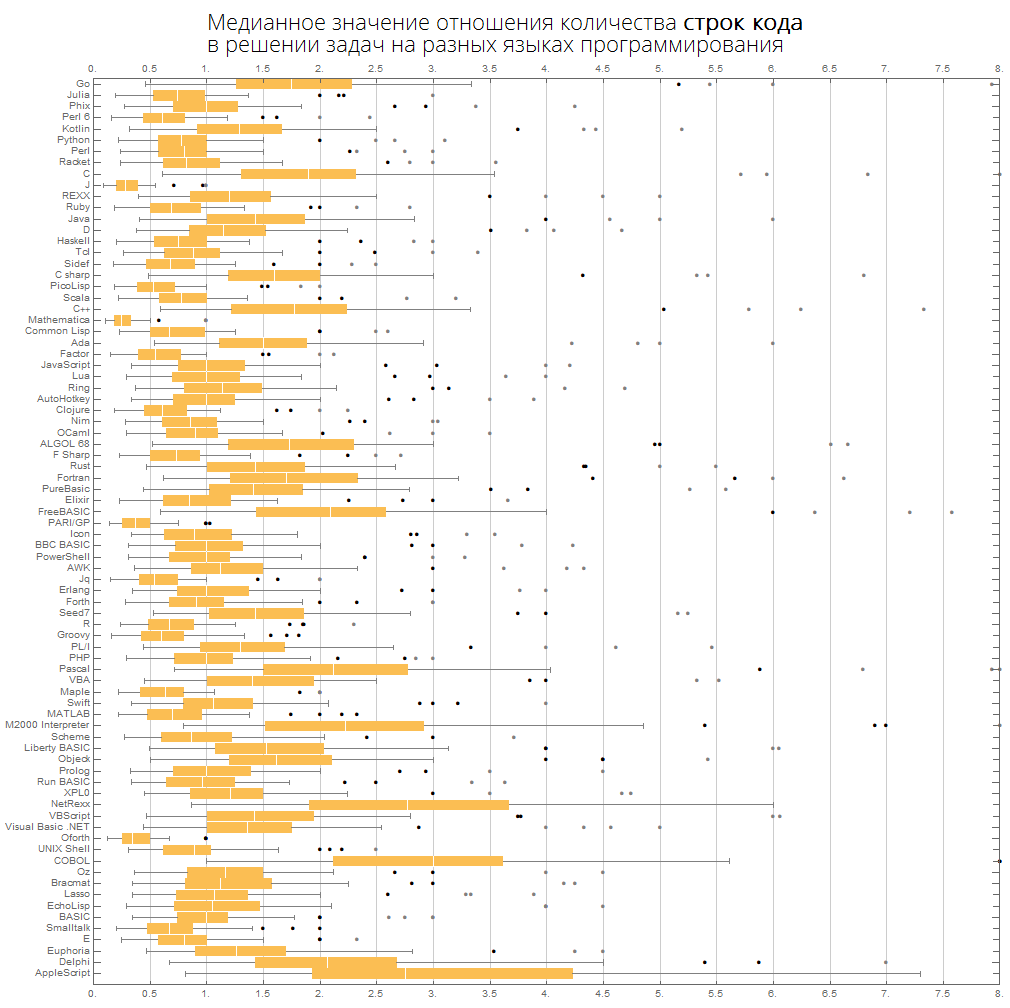
Nous pouvons imaginer les mêmes informations de manière plus compacte - sous la forme de boîtes avec une moustache (diagramme en boîte et moustaches):
ClearAll[langMetricsBoxWhiskerChart]; langMetricsBoxWhiskerChart[n_Integer, type_, OptionsPattern[{"SortQ"->True, "measureFunction"->Mean}]]:=Module[{$nPL, $pl, tableData, scale, notSortedTableData, order, fullTableData, min, max, orderedMeans, meanFunction}, $nPL=n; meanFunction[{lang1_, lang2_}]:=Quiet[Map[Median[N[#]]&, compareLanguages[{lang1, lang2}, Divide[#[[1]], #[[2]]]&]/.ComplexInfinity->Nothing/.Indeterminate->Nothing]]; $pl=Reverse@$popularLanguages[$nPL][[;;, 1]]; tableData=Quiet@Table[If[i==j, "", meanFunction[{$pl[[i]], $pl[[j]]}][[type]]], {i, 1, $nPL}, {j, 1, $nPL}]; order=If[OptionValue["SortQ"], Ordering[tableData, All, OptionValue["measureFunction"][#1/.""->Nothing]>OptionValue["measureFunction"][#2/.""->Nothing]&], Range[1, $nPL]]; Framed[Labeled[Style[Row[{" ", Style[type/.{"lineCount"->" ", "characterCount"->" ", "tokensCount"->" "}, Bold], "\n "}], 22, FontFamily->"Open Sans Light", TextAlignment->Center], BoxWhiskerChart[tableData[[order]], "Outliers", ChartLabels->$pl[[order]], BarOrigin->Left, ImageSize->1000, AspectRatio->1, GridLines->{Range[0, 20, 1/2], None}, FrameTicks->{Range[0, 20, 0.5], Automatic}, PlotRangePadding->0, PlotRange->{{0, 8}, Automatic}, Background->White] ], FrameStyle->None, Background->White]];
Les langues sont triées par popularité (le diagramme montre le rapport du nombre de lignes de code entre les langues):
langMetricsBoxWhiskerChart[80, "lineCount", "SortQ"->False]
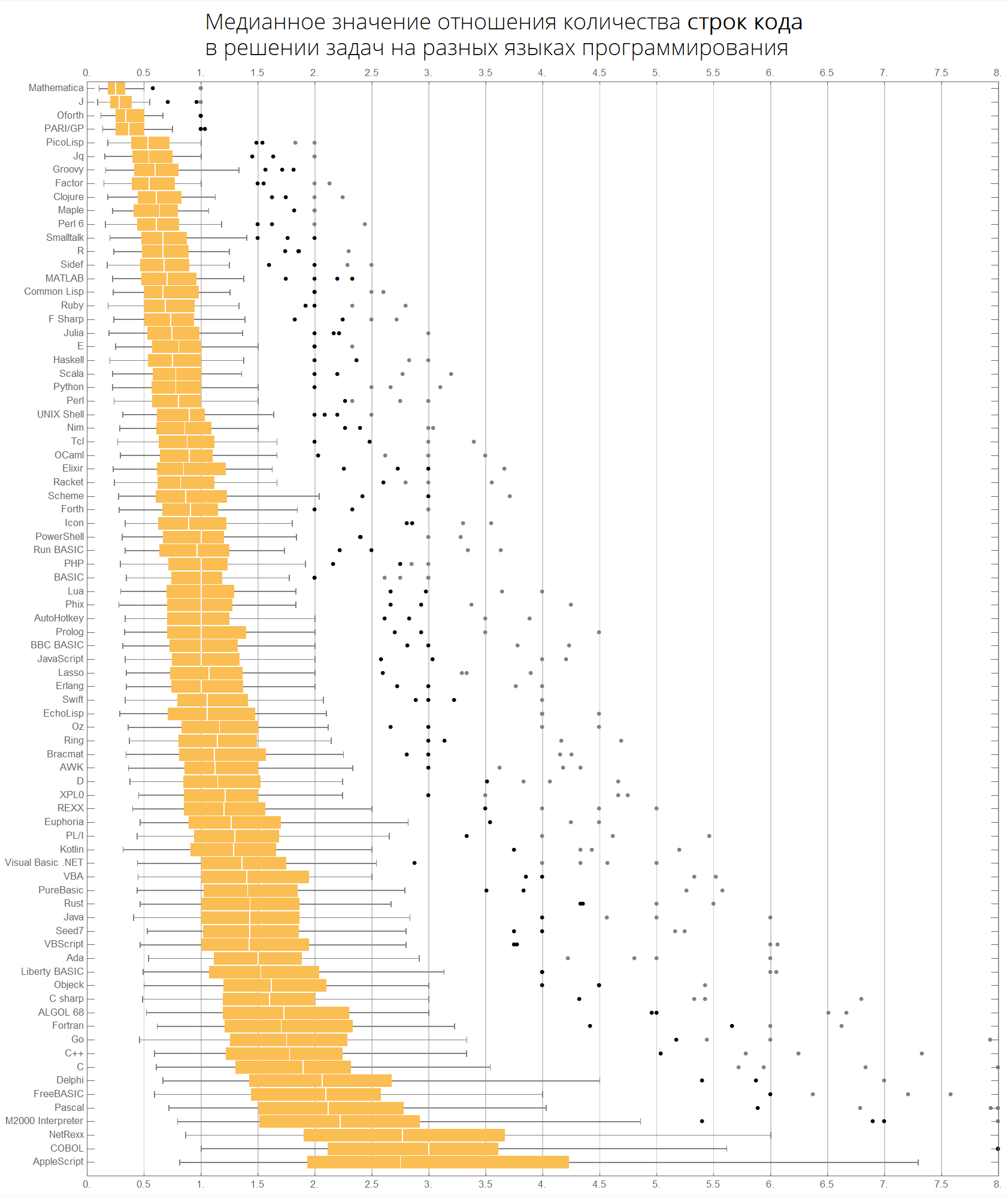
Par valeur médiane:
langMetricsBoxWhiskerChart[80, "lineCount", "SortQ"->True]
Enfin, des graphiques concernant le nombre de caractères et de jetons:
langMetricsBoxWhiskerChart[80, "characterCount", "SortQ"->True] langMetricsBoxWhiskerChart[80, "tokensCount", "SortQ"->True]
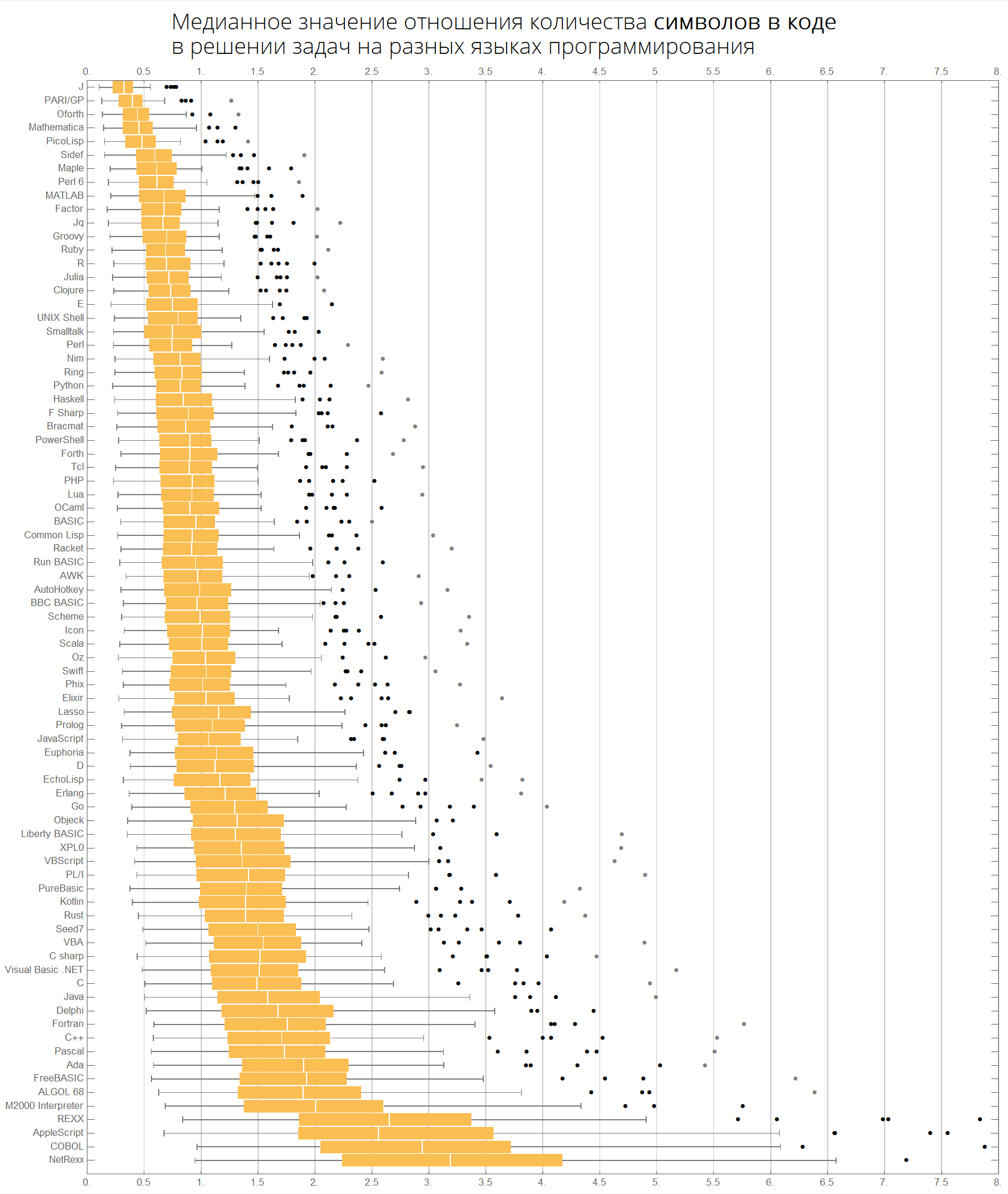
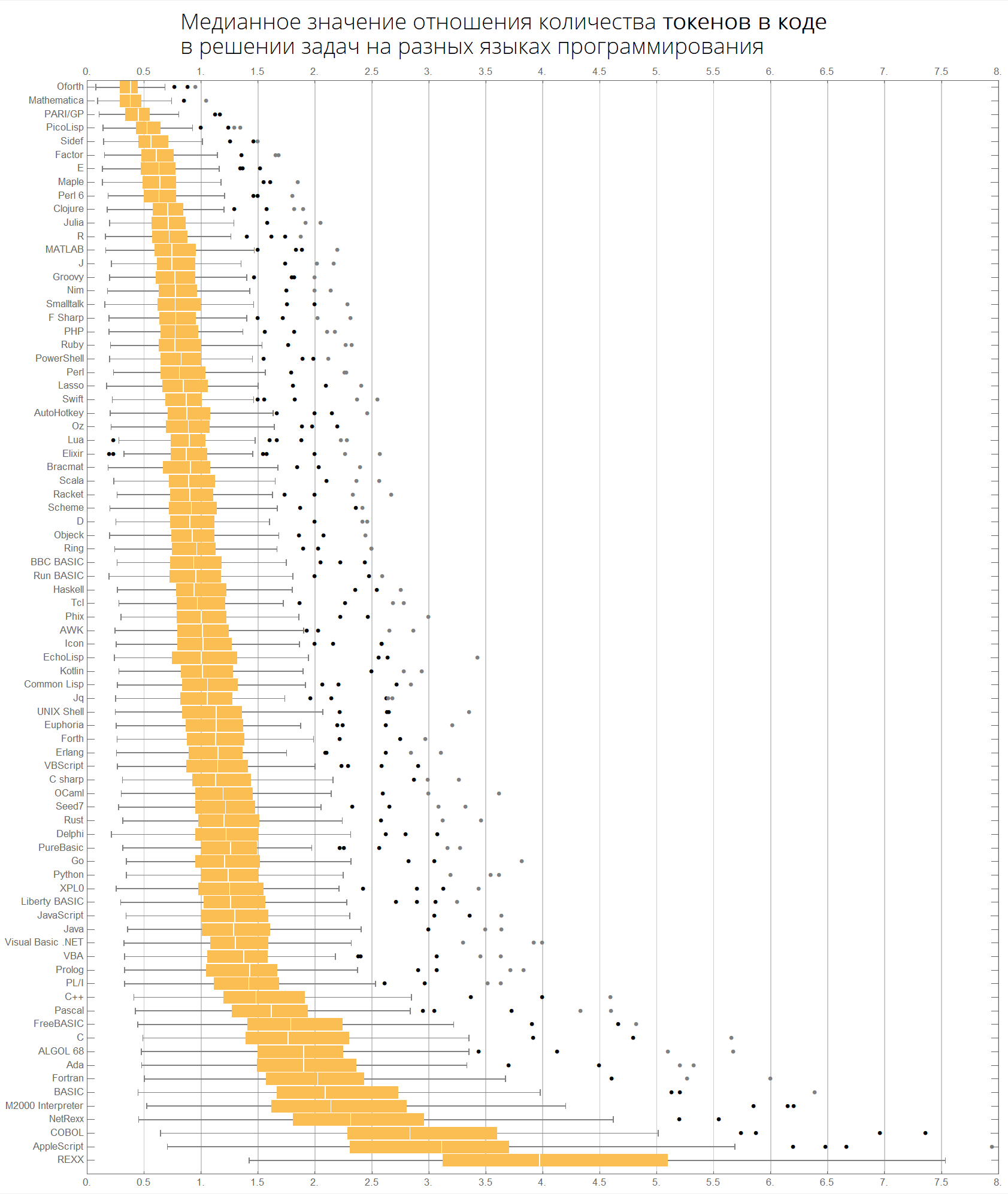
Voyons quels jetons sont populaires dans différentes langues:
languagePopularTokens[lang_, nMin_:50]:=Framed[Labeled[Style[Row[{" ", Style[lang, Bold]}], FontFamily->"Open Sans Light", 24], WordCloud[Cases[SortBy[Tally[Flatten[Values[langData[lang][["tokens"]]]]], -Last[#]&], {x_/; (StringLength[x]>1&&StringMatchQ[x, RegularExpression["[a-zA-Z0-9.]+"]]&&Not[StringMatchQ[x, RegularExpression["[0-9.]+"]]]), y_/; y>nMin}], ImageSize->{1000, 500}, MaxItems->200, WordOrientation->{
clouds=Grid[{Image[#, ImageSize->All]&@Rasterize[languagePopularTokens[#, 10]]}&/@{"Mathematica", "C", "Python", "Go", "JavaScript"}]

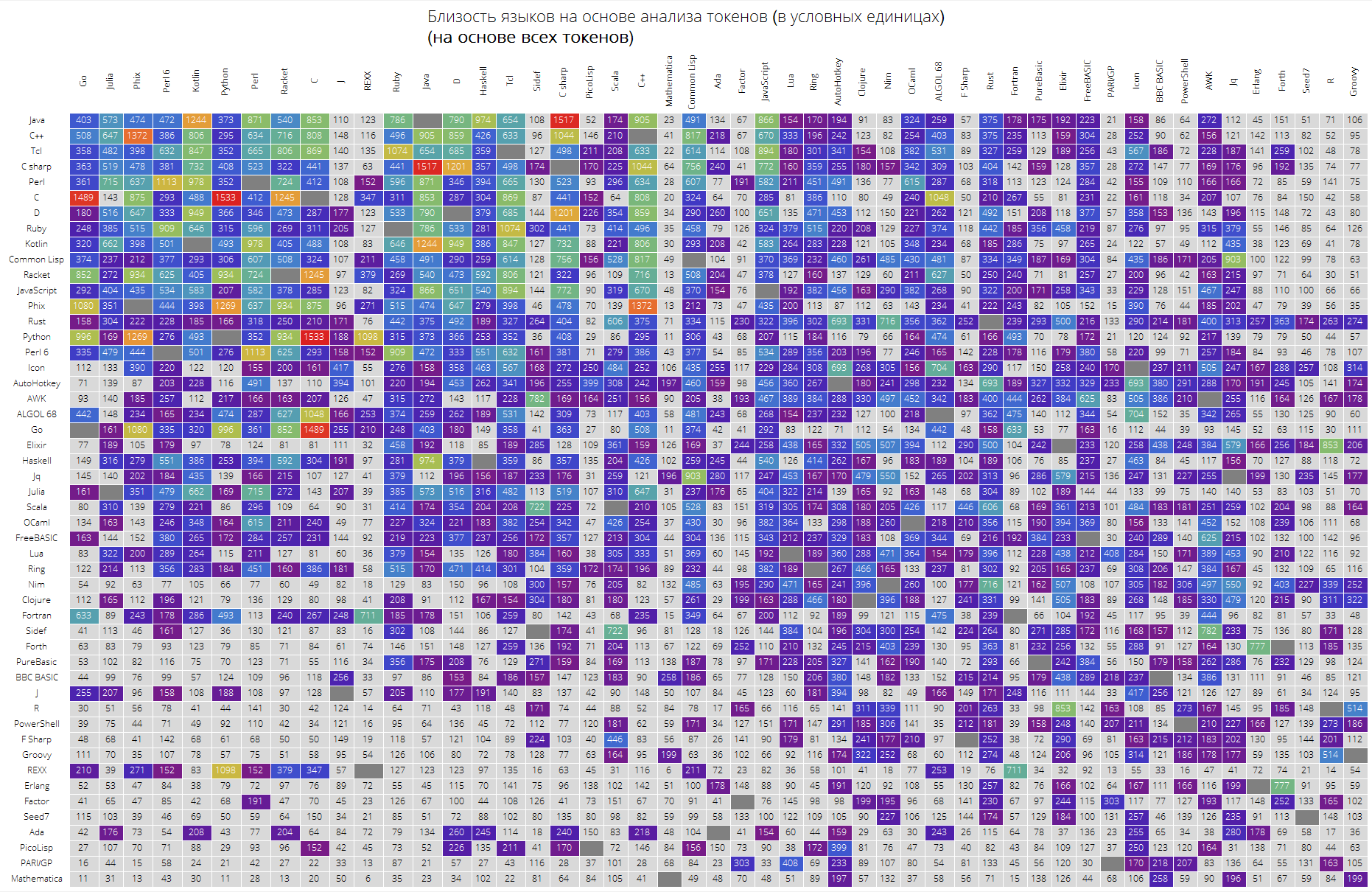
Et enfin, une comparaison des langues très intéressante basée sur la proximité de leurs tokens.
La fonction langSimilarity fonctionne comme suit: premièrement, des «jetons significatifs» sont sélectionnés (ceux qui sont considérés comme étant toutes des chaînes de caractères latins d'une longueur d'au moins 2 caractères pouvant contenir un point); puis les jetons sont recherchés pour une paire de langues lang1 et lang2; après cela, la mesure de leur «similitude» est considérée, comme le produit de la mesure Jacquard de deux ensembles de jetons par le montant responsable de la proximité des jetons entre eux (la somme des éléments de la forme
où
Est la somme des apparences symboliques dans toutes les solutions aux problèmes de langue lang1 et lang2, respectivement).
Clear[langSimilarity]; langSimilarity[{lang1_,lang2_},clearTokens_]:=langSimilarity@@(Sort[{lang1,lang2}]~Join~{clearTokens}); langSimilarity[lang1_,lang2_,clearTokens_:False]:=langSimilarity[lang1,lang2,clearTokens]=Module[{tokens,t1,t2,t1W,t2W,intersection}, tokens[lang_]:=Module[{values,tokensPre,allValues,replacements,n}, values=Values[langData[lang][["tokens"]]]; n=Length[values]; allValues=DeleteDuplicates[Flatten[values]]; tokensPre=If[clearTokens,Cases[allValues,x_/;(StringLength[x]>1&&StringMatchQ[x,RegularExpression["[a-zA-Z0-9._$]+"]]&&Not[StringMatchQ[x,RegularExpression["[0-9.,eE]+"]]])],allValues]; replacements=Dispatch@ Thread[Complement[allValues,tokensPre]->Nothing]; Cases[Tally@Flatten@(values/.replacements),{t_,x_/;x>=n/10}:>{t,x}]]; {t1,t2}=tokens/@{lang1,lang2}; {t1W,t2W}=Dispatch/@{Rule@@@t1,Rule@@@t2}; intersection=Intersection[t1[[;;,1]],t2[[;;,1]]]; Times@@{Total[(#[[1]]+#[[2]])/(1+Abs[#[[1]]-#[[2]]])&/@Transpose@N[{intersection/.t1W,intersection/.t2W}]],Length[intersection]/Length[Union[t1[[;;,1]],t2[[;;,1]]]]}]
ClearAll[langSimilarityGrid]; langSimilarityGrid[n_Integer, OptionsPattern[{"SortQ" -> True, "measureFunction" -> Mean, "clearTokens" -> True}]] := Module[{$nPL, $pl, tableData, notSortedTableData, order, fullTableData, min, max, orderedMeans, median, rescale}, $nPL = n; $pl = $popularLanguages[$nPL][[;; , 1]]; tableData = Quiet@Table[ If[i == j, "", langSimilarity[{$pl[[i]], $pl[[j]]}, OptionValue["clearTokens"]]], {i, 1, $nPL}, {j, 1, $nPL}]; {min, max} = MinMax[Flatten[tableData] /. "" -> Nothing]; median = 10^Median@Log10@Flatten[tableData /. "" -> Nothing]; rescale = Function[Evaluate[Rescale[#, {median, max}, {0, 1}]]]; order = If[OptionValue["SortQ"], Ordering[tableData, All, OptionValue["measureFunction"][#1 /. "" -> Nothing] > OptionValue["measureFunction"][#2 /. "" -> Nothing] &], Range[1, $nPL]]; fullTableData = Transpose[{{""}~Join~$pl[[order]]}~Join~ Transpose[{Map[Rotate[#, 90 Degree] &, $pl]}~Join~ ReplaceAll[tableData[[order]], x_?NumericQ :> Item[Style[Round[x, 1], If[x < median, Black, White]], Background -> If[x < median, LightGray, ColorData["Rainbow"][rescale[x]]]]] /. "" -> Item["", Background -> Gray]]]; Framed[ Labeled[Style[ Row[{" ( )", "\n", "(", Style[If[OptionValue["clearTokens"], " ", " "], Bold], ")"}], 22, FontFamily -> "Open Sans Light", TextAlignment -> Center], Grid[fullTableData, Background -> White, ItemStyle -> Directive[FontSize -> 12, FontFamily -> "Open Sans Light"], Dividers -> White]], FrameStyle -> None, Background -> White]];
UPD: après un commentaire précieux, assemblé a décidé de faire deux tableaux: avec des jetons effacés et avec tous les jetons, sans aucun type de nettoyage, afin d'influencer le moins possible le résultat. Le résultat est légèrement différent, comme vous pouvez le constater par vous-même, bien que certaines dépendances soient devenues plus claires.
Voici ce que nous obtenons (tableau non trié):
langSimilarityGrid[30, "SortQ" -> False, "clearTokens" -> True] langSimilarityGrid[30, "SortQ" -> False, "clearTokens" -> False]
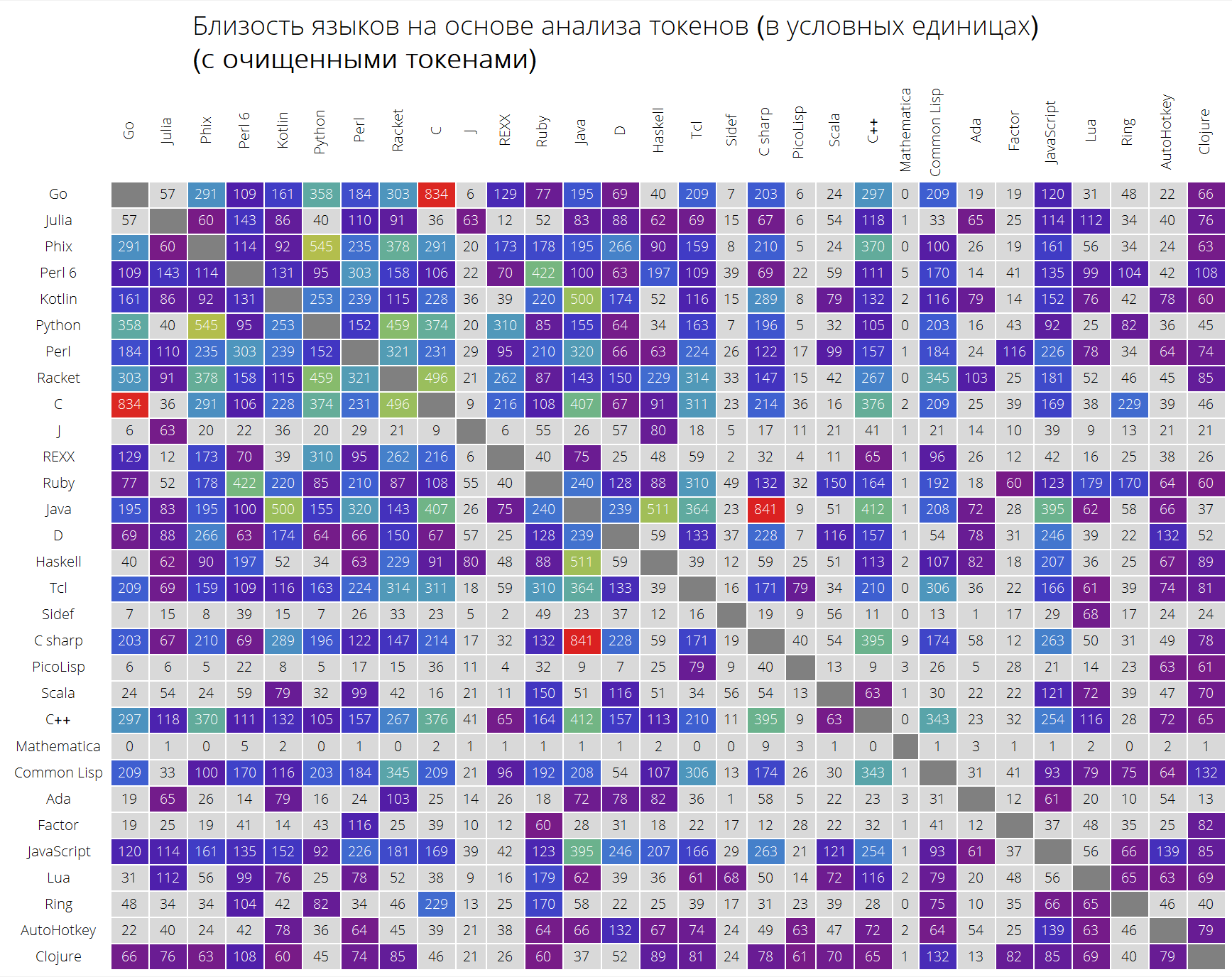

Tableau trié (en termes de similitude moyenne avec d'autres langages - plus la ligne est élevée, plus le nombre d'autres langages de programmation auxquels ce langage ressemble):
langSimilarityGrid[30, "SortQ"->True, "clearTokens" -> True] langSimilarityGrid[30, "SortQ"->True, "clearTokens" -> False]


Enfin, un grand tableau pour les 50 premières langues en popularité.
Il est prévu que les langages "clés" comme Java, C, C ++, C # soient en haut. Racket (anciennement PLTScheme) était là, dont l'un des objectifs est la création, le développement et l'implémentation de langages de programmation.
Fait intéressant, la langue Wolfram s'est avérée être essentiellement une langue différente.
Les liens entre les langages sont également visibles, disons que le lien entre Java et C #, Go et C, C et Java, Haskell et Java, Kotlin et Java, Python et Phix, Python et Racket et plus sont très visibles.
langSimilarityGrid[50, "SortQ"->True, "clearTokens" -> True] langSimilarityGrid[50, "SortQ"->True, "clearTokens" -> False]
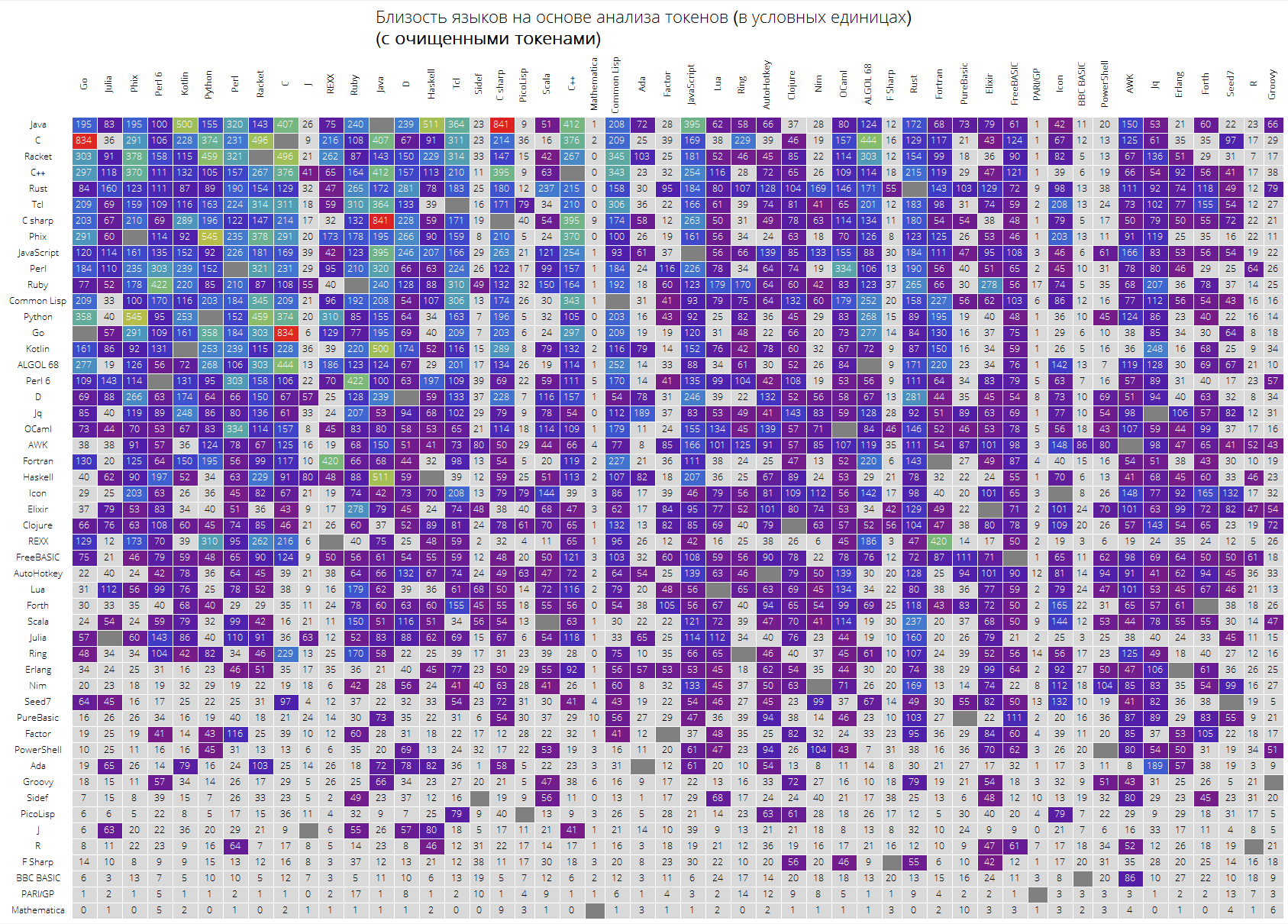
J'espère que cette étude sera intéressante pour vous et que vous pourrez découvrir quelque chose de nouveau. Pour moi, en tant que personne qui utilise constamment la langue Wolfram, il était agréable de savoir qu'elle se révèle être la langue la plus «compacte», d'une part, d'autre part, sa «dissimilarité» objective avec d'autres langues, évidemment, rend son entrée un peu plus difficile.
Vous voulez apprendre à programmer en Wolfram Language?
Regardez des webinaires hebdomadaires.
Inscription aux nouveaux cours . Cours en ligne prêt.