Poursuite de la traduction d'un petit livre:
"Comprendre les courtiers de messages",
auteur: Jakub Korab, éditeur: O'Reilly Media, Inc., date de publication: juin 2017, ISBN: 9781492049296.
Traduction terminéePartie précédente:
Comprendre les courtiers de messages. Apprentissage de la mécanique de la messagerie via ActiveMQ et Kafka. Chapitre 1. IntroductionCHAPITRE 2
Activemq
ActiveMQ est mieux décrit comme un système de messagerie classique. Il a été écrit en 2004 pour répondre au besoin d'un courtier de messages open source. À cette époque, si vous vouliez utiliser la messagerie dans vos applications, le seul choix était des produits commerciaux coûteux.
ActiveMQ a été développé comme une implémentation de la spécification JMS (Java Message Service). Cette décision a été prise pour répondre aux exigences de mise en œuvre de la messagerie compatible JMS dans le projet Apache Geronimo, un serveur d'applications J2EE open source.
Un système de messagerie (ou middleware orienté message, comme on l'appelle parfois) qui implémente la spécification JMS comprend les composants suivants:
CourtierUn middleware central distribuant des messages.
ClientLe logiciel qui envoie des messages via un courtier. Il se compose à son tour des artefacts suivants:
- Code à l'aide de l'API JMS.
- L'API JMS est un ensemble d'interfaces pour interagir avec un courtier conformément aux garanties énoncées dans la spécification JMS.
- La bibliothèque cliente du système qui fournit l'implémentation de l'API et interagit avec le courtier.
Le client et le courtier communiquent entre eux via le protocole de couche application, également appelé
protocole d'interaction (figure 2-1) . La spécification JMS a laissé les détails de ce protocole à des implémentations spécifiques.
 Figure 2-1. Examen JMS
Figure 2-1. Examen JMSJMS utilise le terme
fournisseur pour décrire l'implémentation par le fournisseur du système de messagerie sous-jacent à l'API JMS, qui inclut le courtier, ainsi que ses bibliothèques clientes.
Le choix en faveur de la mise en œuvre de JMS a eu des conséquences profondes sur les décisions de mise en œuvre prises par les auteurs d'ActiveMQ. La spécification elle-même fournit des indications claires sur les responsabilités du client du système de messagerie et du courtier avec qui il communique, en privilégiant l'obligation du courtier de distribuer et de livrer des messages. La responsabilité principale du client est d'interagir avec le destinataire (file d'attente ou sujet) des messages envoyés par lui. La spécification elle-même vise à rendre l'interaction de l'API avec le courtier relativement simple.
Ce domaine, comme nous le verrons plus loin, a eu un impact significatif sur les performances d'ActiveMQ. Outre la complexité du courtier, le package de compatibilité pour la spécification fournie par Sun Microsystems avait de nombreuses nuances, avec leur propre impact sur les performances. Ces nuances auraient dû toutes être prises en compte pour que ActiveMQ soit considéré comme compatible JMS.
La communication
Bien que l'API et le comportement attendu soient bien définis dans la spécification JMS, le protocole de communication client-courtier réel a été délibérément exclu de la spécification afin que les courtiers existants puissent être rendus conformes à JMS. Ainsi, ActiveMQ était libre de définir son propre protocole d'interaction, OpenWire. OpenWire est utilisé par l'implémentation de la bibliothèque cliente ActiveMQ JMS, ainsi que ses homologues en .Net et C ++: NMS et CMS, qui sont des sous-projets ActiveMQ hébergés par Apache Software Foundation.
Au fil du temps, la prise en charge d'autres protocoles d'interaction a été ajoutée à ActiveMQ, ce qui a augmenté la capacité d'interagir avec d'autres langages et environnements:
AMQP 1.0Le protocole Advanced Message Queuing (ISO / IEC 19464: 2014) ne doit pas être confondu avec son prédécesseur 0.X, qui est implémenté dans d'autres systèmes de messagerie, en particulier RabbitMQ, qui utilise 0.9.1. AMQP 1.0 est un protocole binaire à usage général pour l'échange de messages entre deux nœuds. Il n'a aucun concept de clients ou de courtiers et comprend des fonctions telles que le contrôle de flux, les transactions et diverses QoS (pas plus d'une fois, au moins une fois et exactement une fois).
STOMPSimple / Streaming Text Oriented Messaging Protocol, un protocole facile à implémenter qui a des dizaines d'implémentations client dans différentes langues.
XmppMessagerie extensible et protocole de présence. (Protocole de messagerie et de présence extensible). Anciennement appelé Jabber, ce protocole basé sur XML a été initialement développé pour les systèmes de chat, mais a été étendu au-delà de ses cas d'utilisation d'origine pour inclure la messagerie de publication-abonnement.
MQTTLe protocole léger de publication-abonnement (ISO / IEC 20922: 2016) utilisé pour les applications Machine-to-Machine (M2M) et Internet of Things (IoT).
ActiveMQ prend également en charge l'imposition des protocoles ci-dessus sur WebSockets, qui permet l'échange de données en duplex intégral entre les applications d'un navigateur Web et les destinations du courtier.
Compte tenu de cela, maintenant, lorsque nous parlons d'ActiveMQ, nous ne faisons plus référence exclusivement à la pile d'interaction basée sur les bibliothèques JMS / NMS / CMS et le protocole OpenWire. La combinaison et la sélection des langues, des plates-formes et des bibliothèques externes les mieux adaptées à cette application deviennent de plus en plus populaires. Par exemple, il est possible qu'une application JavaScript s'exécute dans un navigateur à l'aide de la bibliothèque
Eclipse Paho MQTT pour envoyer des messages à ActiveMQ via des sockets Web, et ces messages sont lus par un processus serveur C ++ qui utilise AMQP via la bibliothèque
Apache Qpid Proton . De ce point de vue, le paysage de la messagerie se diversifie.
En regardant vers l'avenir, AMQP, en particulier, aura beaucoup plus d'opportunités qu'aujourd'hui, car les composants qui ne sont ni clients ni courtiers deviennent une partie plus familière du paysage de la messagerie. Par exemple,
Apache Qpid Dispatch Router agit comme un routeur de messages, auquel les clients se connectent directement, permettant à différentes destinations de traiter différentes adresses, tout en offrant la possibilité d'un partage (séparation).
Lorsque vous travaillez avec des bibliothèques tierces et des composants externes, veuillez noter qu'ils ont une qualité variable et peuvent ne pas être compatibles avec les fonctions fournies dans ActiveMQ. À titre d'exemple très simple - il est impossible d'envoyer des messages à la file d'attente via MQTT (sans configurer le routage dans le courtier). Ainsi, vous devrez passer un certain temps à travailler avec des options pour déterminer la pile du système de messagerie qui convient le mieux aux exigences de votre application.
Le compromis entre performance et fiabilité
Avant de nous plonger dans les détails du fonctionnement de la messagerie point à point dans ActiveMQ, nous devons parler un peu de ce à quoi tous les systèmes à traitement intensif des données sont confrontés: un compromis entre performances et fiabilité.
Tout système qui accepte des données, qu'il s'agisse d'un courtier de messages ou d'une base de données, doit être informé de la façon de traiter ces données en cas de défaillance. L'échec peut prendre de nombreuses formes, mais pour simplifier, nous allons le réduire à une situation où le système perd son alimentation et s'arrête immédiatement. Dans cette situation, nous devons spéculer sur ce qui arrivera aux données qui étaient dans le système. Si les données (dans ce cas, les messages) étaient en mémoire ou dans la partie volatile du fer, par exemple, dans le cache, alors ces données seront perdues. Cependant, si les données ont été envoyées vers un stockage non volatile, par exemple sur le disque, elles seront à nouveau disponibles lorsque le système reprendra le travail.
De ce point de vue, il est logique que si nous ne voulons pas perdre de messages en cas de défaillance d'un courtier, nous devons les écrire dans le stockage permanent. Malheureusement, le coût de cette solution particulière est assez élevé.
Notez que la différence entre l'écriture d'un mégaoctet de données sur le disque est 100 à 1000 fois plus lente que l'écriture dans la mémoire. Par conséquent, le développeur de l'application doit décider si la fiabilité du message vaut la perte de performances. De telles décisions doivent être prises en fonction d'un scénario d'utilisation.
Le compromis entre performances et fiabilité est basé sur une gamme d'options. Plus la fiabilité est élevée, plus les performances sont faibles. Si vous décidez de rendre le système moins fiable, par exemple en ne stockant des messages qu'en mémoire, votre productivité augmentera considérablement. Par défaut, JMS est configuré pour avoir ActiveMQ prêt à l'emploi pour la fiabilité. Il existe de nombreux mécanismes qui vous permettent de configurer le courtier et d'interagir avec lui à une position dans ce spectre qui convient le mieux à des scénarios spécifiques d'utilisation du système de messagerie.
Ce compromis s'applique au niveau des courtiers individuels. Cependant, une fois la mise en place d'un courtier individuel terminée, il est possible de faire évoluer le système de messagerie au-delà de ce point en examinant attentivement les flux de messages et en partageant le trafic entre plusieurs courtiers. Ceci peut être réalisé en fournissant des destinataires spécifiques avec leurs propres courtiers ou en divisant le flux de messages global soit au niveau de l'application, soit en utilisant un composant intermédiaire. Plus loin, nous verrons plus en détail comment prendre en compte les topologies des courtiers.
Sauvegarde des messages
ActiveMQ est livré avec un certain nombre de stratégies de rétention de messages enfichables. Ils se présentent sous la forme d'adaptateurs de persistance (persistance), qui peuvent être considérés comme des moteurs de stockage de messages. Il s'agit notamment de solutions sur disque telles que KahaDB et LevelDB, ainsi que la possibilité d'utiliser la base de données via JDBC. Étant donné que les premiers sont les plus couramment utilisés, nous concentrerons notre discussion sur eux.
Lorsqu'un courtier reçoit des messages persistants, ils sont d'abord écrits sur le disque dans un journal. Un journal est une structure de données sur disque dans laquelle vous ne pouvez ajouter que des données et composé de plusieurs fichiers. Les messages entrants sont sérialisés par le courtier dans une représentation indépendante de protocole de l'objet, puis marshalés sous forme binaire, qui est ensuite écrit à la fin du journal. Le journal contient un journal de tous les messages entrants, ainsi que des informations sur les messages dont la lecture a été confirmée par le client.
Les adaptateurs de disque de persistance prennent en charge les fichiers d'index qui suivent l'emplacement des messages transférés suivants dans le journal. Lorsque tous les messages du fichier journal sont lus, ils sont supprimés ou archivés par le flux de travail en arrière-plan ActiveMQ. Si ce journal est endommagé lors de l'échec du courtier, ActiveMQ le reconstruira en fonction des informations contenues dans les fichiers journaux.
Les messages de toutes les files d'attente sont écrits dans les mêmes fichiers journaux, ce qui signifie que si un message n'est pas lu, le fichier entier (généralement la valeur par défaut est de 32 Mo ou 100 Mo, selon l'adaptateur de persistance) ne peut pas être effacé. Cela peut entraîner des problèmes d'espace disque faible au fil du temps.
Les courtiers de messages classiques ne sont pas conçus pour un stockage à long terme - lisez vos messages!
Les journaux sont un mécanisme extrêmement efficace pour le stockage et la récupération ultérieure des messages, car l'accès au disque est séquentiel pour les deux opérations. Sur les disques durs conventionnels, cela minimise le nombre de recherches de disque par cylindres, car les têtes sur le disque continuent simplement à lire ou à écrire des secteurs sur le substrat rotatif du disque. De même, sur les SSD, l'accès séquentiel est beaucoup plus rapide que l'accès aléatoire, car le premier utilise mieux les pages de mémoire du lecteur.
Facteurs de performance du disque
Il existe un certain nombre de facteurs qui déterminent la vitesse à laquelle un disque peut fonctionner. Pour comprendre cela, considérez la méthode d'écriture sur un disque à travers un modèle mental simplifié d'un tuyau (
figure 2-2 ).
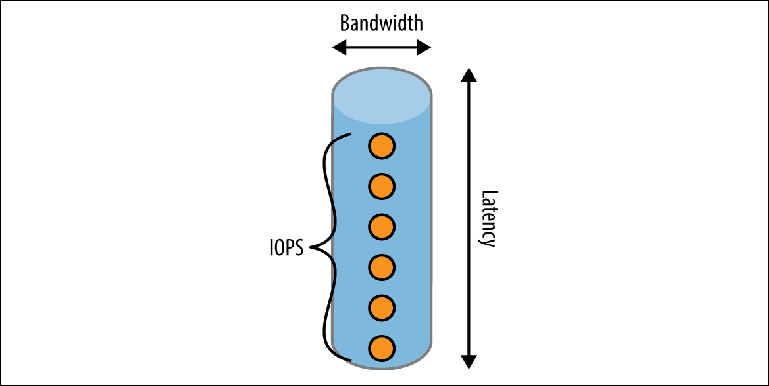 Figure 2-2. Modèle de tube de performance de disque
Figure 2-2. Modèle de tube de performance de disqueUn tuyau a trois dimensions:
La longueurCorrespond à la
latence attendue pour terminer une opération. Pour la plupart des disques locaux, il est assez bon, mais il peut devenir un facteur limitant majeur dans les environnements cloud où le disque local est réellement en ligne. Par exemple, au moment de la rédaction (avril 2017), Amazon garantit que l'écriture sur son stockage EBS se fera "en moins de 2 ms". Si nous enregistrons séquentiellement, cela donne un débit maximum de 500 enregistrements par seconde.
LargeurDétermine la
capacité de charge ou la bande passante d'une seule opération. Les caches de système de fichiers utilisent cette propriété en combinant de nombreux petits enregistrements dans un ensemble plus petit d'opérations d'écriture plus importantes effectuées sur le disque.
Bande passante au fil du tempsL'idée est présentée sous la forme d'une série d'événements qui peuvent être dans le tuyau en même temps, exprimés par une métrique appelée
IOPS (nombre d'opérations d'E / S par seconde) . IOPS est couramment utilisé par les fabricants de stockage et les fournisseurs de cloud pour mesurer les performances. Le disque dur aura différentes valeurs IOPS dans différents contextes: si la charge de travail se compose principalement de lecture, d'écriture ou d'une combinaison d'entre elles, et si ces opérations sont séquentielles, arbitraires ou mixtes. Les mesures IOPS les plus intéressantes du point de vue du courtier sont des opérations de lecture et d'écriture séquentielles, car elles correspondent à la lecture et à l'écriture des journaux d'un journal.
Le débit maximal d'un courtier de messages est déterminé par la
réalisation de la première de ces restrictions, et la configuration du courtier dépend en grande partie de la façon dont vous interagissez avec les disques. Cela n'est pas seulement un facteur de la configuration, par exemple, du courtier, mais dépend également de la façon dont les producteurs interagissent avec le courtier. Comme pour tout ce qui concerne les performances, il est nécessaire de tester le courtier sur une charge de travail représentative (c'est-à-dire aussi proche que possible des vrais messages) et sur la configuration de stockage réelle qui sera utilisée dans PROM. Ceci est fait afin de comprendre comment le système se comportera dans la réalité.
API JMS
Avant d'entrer dans les détails de la façon dont ActiveMQ communique avec les clients, nous devons d'abord apprendre l'API JMS. L'API définit un ensemble d'interfaces de programmation utilisées par le code client:
ConnectionFactoryIl s'agit de l'interface de niveau supérieur utilisée pour établir des connexions avec le courtier. Dans une application de messagerie typique, il n'y a qu'une seule instance de cette interface. Dans ActiveMQ, il s'agit d'un ActiveMQConnectionFactory. Au niveau supérieur, cette conception indique l'emplacement du courtier de messages, ainsi que des détails de bas niveau sur la façon d'interagir avec lui. Comme son nom l'indique, ConnectionFactory est le mécanisme par lequel les objets Connection sont créés.
ConnexionIl s'agit d'un objet à longue durée de vie qui ressemble à peu près à une connexion TCP - après sa création, il existe généralement tout au long du cycle de vie de l'application jusqu'à sa fermeture. La connexion est thread-safe et peut fonctionner avec plusieurs threads simultanément. Les objets de connexion vous permettent de créer des objets Session.
SéanceIl s'agit d'un descripteur de flux lors de l'interaction avec un courtier. Les objets de session ne sont pas thread-safe, ce qui signifie qu'ils ne sont pas accessibles par plusieurs threads en même temps. La session est le principal descripteur transactionnel avec lequel le programmeur peut valider et annuler les messages de restauration s'il est en mode transactionnel. À l'aide de cet objet, vous créez des objets Message, MessageConsumer et MessageProducer, ainsi que des pointeurs (descripteurs) vers des objets Rubrique et File d'attente.
MessageProducerCette interface vous permet d'envoyer un message au destinataire.
MessageconsumerCette interface permet au développeur de recevoir des messages. Il existe deux mécanismes de récupération des messages:
- Enregistrez MessageListener. Il s'agit de l'interface du gestionnaire de messages que vous avez implémentée, qui traitera séquentiellement tous les messages émis par le courtier à l'aide d'un seul flux.
- Interrogation des messages à l'aide de la méthode receive ().
MessageIl s'agit probablement de la structure la plus importante car elle transfère vos données. Les messages dans JMS se composent de deux aspects:
- Métadonnées du message. Le message contient des en-têtes et des propriétés. Cela et cela peuvent être considérés comme des éléments d'une carte. Les en-têtes sont des éléments bien connus définis par la spécification JMS et disponibles directement via l'API, tels que JMSDestination et JMSTimestamp. Les propriétés sont des éléments arbitraires de message définis pour simplifier le traitement ou le routage des messages sans avoir à lire la charge utile du message lui-même. Vous pouvez, par exemple, définir l'en-tête sur AccountID ou OrderType.
- Corps du message. Depuis Session, plusieurs types de messages différents peuvent être créés en fonction du type de contenu qui sera envoyé dans le corps, les plus courants étant TextMessage pour les chaînes et BytesMessage pour les données binaires.
Comment fonctionnent les files d'attente: une histoire à deux cerveaux
Un modèle de travail ActiveMQ utile, quoique inexact, est un modèle de deux moitiés du cerveau. Une partie est chargée de recevoir les messages du producteur, et l'autre envoie ces messages aux consommateurs. Les relations sont en fait plus complexes à des fins d'optimisation des performances, mais le modèle est suffisant pour une compréhension de base.
Envoi de messages à la file d'attente
Examinons l'interaction qui se produit lors de l'envoi d'un message.
La figure 2-3 nous montre un modèle simplifié du processus par lequel les messages sont reçus par le courtier. Il ne correspond pas entièrement au comportement dans chaque cas, mais il est tout à fait approprié pour obtenir une compréhension de base.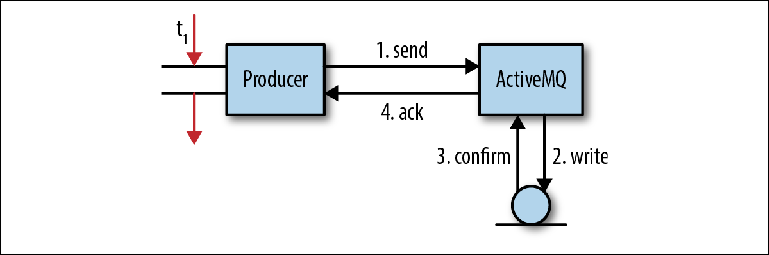 Figure 2-3. Envoi de messages à JMSDans une application cliente, un thread reçoit un pointeur vers un MessageProducer. Il crée un message avec une charge utile de message estimée et appelle MessageProducer.send ("commandes", message), avec la file d'attente comme destination finale du message. Étant donné que le programmeur ne souhaite pas perdre le message en cas de panne du courtier, l'en-tête du message JMSDeliveryMode a été défini sur PERSISTENT (comportement par défaut).À ce stade (1), le flux d'envoi appelle la bibliothèque cliente et rassemble le message au format OpenWire. Ensuite, le message est envoyé au courtier.Dans le courtier, le flux de réception supprime le message de la ligne et le démasque à l'objet interne. Ensuite, l'objet de message est transmis à l'adaptateur de persistance, qui rassemble le message à l'aide du format de tampons de protocole Google et l'écrit dans le stockage (2).Après avoir enregistré le message dans le stockage, l'adaptateur de persistance devrait recevoir la confirmation que le message a bien été enregistré (3). C'est généralement la partie la plus lente de toute l'interaction; plus sur cela plus tard.Dès que le courtier s'assure que le message a bien été enregistré, il envoie une réponse de confirmation (4) au client. Après cela, le thread client qui a initialement appelé l'opération send () peut continuer son travail.Cette confirmation en attente de messages persistants est la base de la garantie fournie par l'API JMS - si vous souhaitez que le message soit enregistré, il est probablement également important pour vous si le message a été reçu par le courtier en premier lieu. Il existe un certain nombre de raisons pour lesquelles cela peut ne pas être possible, par exemple, une limite de mémoire ou de disque a été atteinte. Au lieu d'échouer, le courtier suspend l'opération d'envoi, forçant le producteur à attendre jusqu'à ce que suffisamment de ressources système apparaissent pour traiter le message (un processus appelé Producer Flow Control), ou il enverra une confirmation négative au producteur, lançant une exception. Le comportement exact est personnalisable pour chaque courtier.Dans cette opération simple, un nombre important d'interactions d'E / S ont lieu: deux opérations réseau entre le producteur et le courtier, une opération de sauvegarde et une étape de confirmation. L'opération de sauvegarde peut être une simple écriture sur le disque ou une autre transition réseau vers le serveur de stockage.Cela soulève une question importante concernant les courtiers de messages: leur travail est associé à un flux extrêmement intensif d'opérations d'E / S et ils sont très sensibles à l'infrastructure utilisée, en particulier aux disques.Examinons de plus près l'étape de confirmation (3) dans l'interaction ci-dessus. Si l'adaptateur de persistance est basé sur un fichier, le stockage du message implique l'écriture dans le système de fichiers. Si oui, alors pourquoi dois-je confirmer que l'opération d'écriture est terminée? Le fait de terminer un enregistrement signifie-t-il vraiment qu'un enregistrement a eu lieu?
Figure 2-3. Envoi de messages à JMSDans une application cliente, un thread reçoit un pointeur vers un MessageProducer. Il crée un message avec une charge utile de message estimée et appelle MessageProducer.send ("commandes", message), avec la file d'attente comme destination finale du message. Étant donné que le programmeur ne souhaite pas perdre le message en cas de panne du courtier, l'en-tête du message JMSDeliveryMode a été défini sur PERSISTENT (comportement par défaut).À ce stade (1), le flux d'envoi appelle la bibliothèque cliente et rassemble le message au format OpenWire. Ensuite, le message est envoyé au courtier.Dans le courtier, le flux de réception supprime le message de la ligne et le démasque à l'objet interne. Ensuite, l'objet de message est transmis à l'adaptateur de persistance, qui rassemble le message à l'aide du format de tampons de protocole Google et l'écrit dans le stockage (2).Après avoir enregistré le message dans le stockage, l'adaptateur de persistance devrait recevoir la confirmation que le message a bien été enregistré (3). C'est généralement la partie la plus lente de toute l'interaction; plus sur cela plus tard.Dès que le courtier s'assure que le message a bien été enregistré, il envoie une réponse de confirmation (4) au client. Après cela, le thread client qui a initialement appelé l'opération send () peut continuer son travail.Cette confirmation en attente de messages persistants est la base de la garantie fournie par l'API JMS - si vous souhaitez que le message soit enregistré, il est probablement également important pour vous si le message a été reçu par le courtier en premier lieu. Il existe un certain nombre de raisons pour lesquelles cela peut ne pas être possible, par exemple, une limite de mémoire ou de disque a été atteinte. Au lieu d'échouer, le courtier suspend l'opération d'envoi, forçant le producteur à attendre jusqu'à ce que suffisamment de ressources système apparaissent pour traiter le message (un processus appelé Producer Flow Control), ou il enverra une confirmation négative au producteur, lançant une exception. Le comportement exact est personnalisable pour chaque courtier.Dans cette opération simple, un nombre important d'interactions d'E / S ont lieu: deux opérations réseau entre le producteur et le courtier, une opération de sauvegarde et une étape de confirmation. L'opération de sauvegarde peut être une simple écriture sur le disque ou une autre transition réseau vers le serveur de stockage.Cela soulève une question importante concernant les courtiers de messages: leur travail est associé à un flux extrêmement intensif d'opérations d'E / S et ils sont très sensibles à l'infrastructure utilisée, en particulier aux disques.Examinons de plus près l'étape de confirmation (3) dans l'interaction ci-dessus. Si l'adaptateur de persistance est basé sur un fichier, le stockage du message implique l'écriture dans le système de fichiers. Si oui, alors pourquoi dois-je confirmer que l'opération d'écriture est terminée? Le fait de terminer un enregistrement signifie-t-il vraiment qu'un enregistrement a eu lieu?Pas vraiment.
Comme cela se produit habituellement, plus vous étudiez quelque chose en profondeur, plus il s'avère complexe. Dans ce cas particulier, la mise en cache est le coupable .Caches, caches partout
Lorsqu'un processus du système d'exploitation, tel qu'un courtier, écrit des données sur le disque, il interagit avec le système de fichiers. Un système de fichiers est un processus qui résume les détails de l'interaction avec le support de stockage utilisé, fournissant une API pour les opérations de fichiers telles que OPEN, CLOSE, READ et WRITE. L'une de ces fonctions consiste à minimiser le nombre d'opérations d'écriture en mettant en mémoire tampon les données écrites par le système d'exploitation dans des blocs qui peuvent être enregistrés sur le disque en une seule approche. Les opérations d'écriture du système de fichiers qui semblent interagir avec les disques sont en fait écrites dans ce cache tampon .Soit dit en passant, c'est pourquoi votre ordinateur se plaint lorsque vous éjectez un lecteur USB en toute sécurité - les fichiers que vous avez copiés peuvent ne pas avoir été réellement écrits!Dès que les données dépassent le cache de tampon, elles passent au niveau suivant de mise en cache, cette fois au niveau matériel - le cache du contrôleur de disque . Ils sont particulièrement importants pour les systèmes RAID et remplissent la même fonction que la mise en cache au niveau du système d'exploitation: minimiser le nombre d'interactions requises pour les disques eux-mêmes. Ces caches se répartissent en deux catégories: lesécritures à écritureimmédiate sont transférées sur le disque dès leur réception.RéécritureL'enregistrement est effectué sur les disques uniquement lorsque le tampon est plein atteint une certaine valeur de seuil.Les données stockées dans ces caches peuvent être facilement perdues lors d'une panne de courant, car la mémoire qu'ils utilisent est généralement volatile (volatile) . Les cartes plus chères ont des batteries redondantes (BBU) qui prennent en charge l'alimentation du cache jusqu'à ce que tout le système puisse restaurer l'alimentation, après quoi les données seront écrites sur le disque.Le dernier niveau de cache se trouve sur les disques eux-mêmes. Caches de disquesitués sur des disques durs (à la fois sur des disques durs standard et sur des disques SSD) et peuvent être à écriture directe ou à réécriture. La plupart des lecteurs commerciaux utilisent des caches de réécriture et sont volatils, ce qui signifie encore une fois que les données peuvent être perdues en cas de panne de courant.De retour au courtier de messages, vous devez terminer l'étape de confirmation pour vous assurer que les données ont bien atteint le disque. Malheureusement, l'interaction avec ces tampons matériels dépend du système de fichiers, donc tout ce qu'un processus comme ActiveMQ peut faire est d'envoyer un signal au système de fichiers indiquant qu'il veut synchroniser tous les tampons système avec le périphérique utilisé. Pour ce faire, le courtier appelle la méthode java.io.FileDescriptor.sync (), qui, à son tour, démarre l'opération POSIX fsync ().Ce comportement de synchronisation est une exigence du JMS pour garantir que tous les messages marqués comme persistants sont réellement enregistrés sur le disque et donc exécutés après la réception de chaque message ou ensemble de messages associés dans une transaction. Par conséquent, la vitesse à laquelle un disque peut exécuter sync () est critique pour les performances du courtier.Conflits internes
L'utilisation d'un journal pour toutes les files d'attente ajoute une complexité supplémentaire. À tout moment, plusieurs producteurs peuvent envoyer des messages simultanément. Le courtier dispose de plusieurs flux qui reçoivent ces messages des sockets entrantes. Chaque thread doit enregistrer son message dans le journal. Étant donné que plusieurs threads ne peuvent pas écrire dans le même fichier en même temps, car les enregistrements entreront en conflit les uns avec les autres, puis les enregistrements doivent être mis en file d'attente à l'aide du mécanisme d'exclusion mutuelle. Nous appelons ce conflit de thread .Chaque message doit être entièrement enregistré et synchronisé avant de traiter le message suivant. Cette restriction affecte simultanément toutes les files d'attente du courtier. Ainsi, la vitesse à laquelle un message peut être reçu est le temps qu'il faut pour écrire sur le disque, plus le temps d'attente pour que d'autres flux terminent l'enregistrement.ActiveMQ comprend un tampon d'écriture, dans lequel les flux de réception écrivent leurs messages, en attendant la fin de l'enregistrement précédent. Ensuite, le tampon est écrit en une seule action lorsque le message devient disponible. À la fin, les threads sont notifiés. Ainsi, le courtier maximise l'utilisation de la bande passante de stockage.Pour minimiser l'impact des conflits de threads, les ensembles de files d'attente peuvent se voir attribuer leurs propres journaux à l'aide de l'adaptateur mKahaDB. Cette approche réduit la latence d'écriture, car à tout moment, les threads écrivent très probablement dans des journaux différents et n'ont pas besoin de se faire concurrence pour un accès exclusif à un fichier journal.Les transactions
L'avantage d'utiliser un seul journal pour toutes les files d'attente est que, du point de vue des auteurs du courtier, il est beaucoup plus facile d'implémenter des transactions.Regardons un exemple où plusieurs messages sont envoyés par un producteur à plusieurs files d'attente. L'utilisation d'une transaction signifie que l'ensemble des messages à envoyer doit être considéré comme une seule opération atomique. Dans cette interaction, la bibliothèque cliente ActiveMQ est en mesure d'effectuer des optimisations qui augmenteront considérablement la vitesse d'envoi.Dans l'opération illustrée à la figure 2-4, le producteur envoie trois messages, tous dans des files d'attente différentes. Au lieu de l'interaction habituelle avec le courtier, lorsque chaque message est confirmé, le client envoie les trois messages de manière asynchrone, c'est-à-dire sans attendre de réponse. Ces messages sont stockés dans la mémoire du courtier. Dès que l'opération est terminée, le producteur informe ses sessions de la nécessité de valider, ce qui oblige le courtier à effectuer un grand enregistrement avec une seule opération de synchronisation.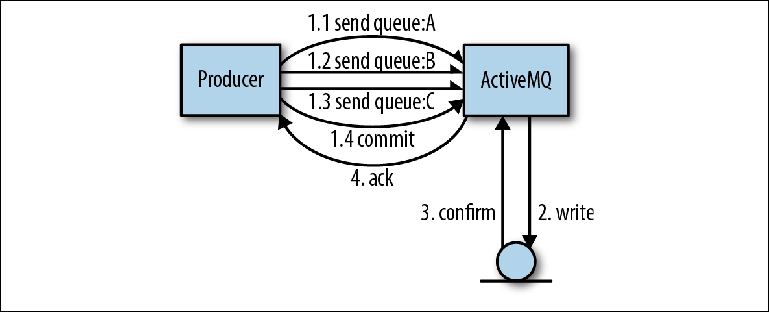 Figure 2-4. Envoi de messages dans les transactionsDans ce type d'opération, ActiveMQ utilise deux optimisations pour augmenter la vitesse:
Figure 2-4. Envoi de messages dans les transactionsDans ce type d'opération, ActiveMQ utilise deux optimisations pour augmenter la vitesse:- La suppression du temps d'attente avant la prochaine expédition par le producteur devient possible
- Combiner de nombreuses opérations de petits disques en une seule - cela vous permet d'utiliser toute la bande passante du bus de disque
Si nous comparons cela avec la situation où chaque file d'attente est stockée dans son propre journal, alors le courtier devrait fournir quelque chose comme la coordination des transactions entre tous les enregistrements.Soustraire des messages de la file d'attente
Le processus de lecture des messages commence lorsque le consommateur exprime sa volonté de les accepter soit en configurant un MessageListener pour traiter les messages à leur arrivée, soit en appelant la méthode MessageConsumer.receive () ( figure 2-5 ).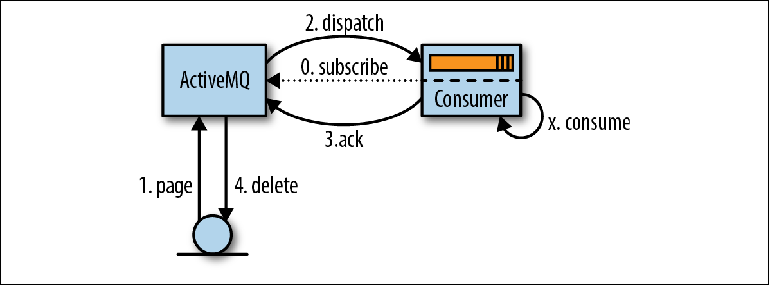 Figure 2-5. Lecture de messages via JMSLorsque ActiveMQ prend connaissance d'un consommateur, il (ActiveMQ) lit (pages) les messages page par page du stockage vers la mémoire de distribution (1). Ces messages sont ensuite redirigés (envoyés) vers le comptable (2), souvent en plusieurs parties pour réduire la quantité d'interaction réseau. Le courtier garde une trace des messages qui ont été redirigés et vers quel consommateur.Les messages reçus par le consommateur ne sont pas traités immédiatement par l'application, mais sont placés dans une zone mémoire appeléetampon de prélecture (tampon de prélecture) . Le but de ce tampon est de rationaliser le flux de messages afin que le courtier puisse émettre des messages au superviseur lorsqu'ils deviennent disponibles pour l'envoi, tandis que le consommateur peut les recevoir de manière ordonnée, une à la fois.À un certain moment après être entré dans le tampon de prélecture, les messages sont lus par la logique d'application (X) et la confirmation de la relecture est envoyée au courtier (3). Le délai entre le traitement des messages et la confirmation est configuré à l'aide d'un paramètre de session JMS appelé mode d'accusé de réception , dont nous parlerons un peu plus tard.Dès que le courtier accepte la confirmation de remise du message, celle-ci est supprimée de la mémoire et de la mémoire de messages (4). Le terme «suppression» est quelque peu trompeur, car en réalité, un enregistrement de confirmation est écrit dans le journal et l'indice dans l'indice augmente. La suppression effective du fichier journal contenant le message sera effectuée par le garbage collector dans le thread d'arrière-plan en fonction de ces informations.Le comportement décrit ci-dessus est une simplification pour faciliter la compréhension. En fait, ActiveMQ ne se contente pas de lire les données page par page à partir du disque, mais utilise à la place le mécanisme de curseur entre les parties de réception et de redirection du courtier pour minimiser l'interaction avec le référentiel du courtier dans la mesure du possible. La pagination, comme décrit ci-dessus, est l'un des modes utilisés dans ce mécanisme. Les curseurs peuvent être vus comme un cache au niveau de l'application qui doit être synchronisé avec le référentiel du courtier. Le protocole de cohérence utilisé est une partie importante de ce qui rend le mécanisme de répartition ActiveMQ beaucoup plus complexe que le mécanisme Kafka décrit dans le chapitre suivant.
Figure 2-5. Lecture de messages via JMSLorsque ActiveMQ prend connaissance d'un consommateur, il (ActiveMQ) lit (pages) les messages page par page du stockage vers la mémoire de distribution (1). Ces messages sont ensuite redirigés (envoyés) vers le comptable (2), souvent en plusieurs parties pour réduire la quantité d'interaction réseau. Le courtier garde une trace des messages qui ont été redirigés et vers quel consommateur.Les messages reçus par le consommateur ne sont pas traités immédiatement par l'application, mais sont placés dans une zone mémoire appeléetampon de prélecture (tampon de prélecture) . Le but de ce tampon est de rationaliser le flux de messages afin que le courtier puisse émettre des messages au superviseur lorsqu'ils deviennent disponibles pour l'envoi, tandis que le consommateur peut les recevoir de manière ordonnée, une à la fois.À un certain moment après être entré dans le tampon de prélecture, les messages sont lus par la logique d'application (X) et la confirmation de la relecture est envoyée au courtier (3). Le délai entre le traitement des messages et la confirmation est configuré à l'aide d'un paramètre de session JMS appelé mode d'accusé de réception , dont nous parlerons un peu plus tard.Dès que le courtier accepte la confirmation de remise du message, celle-ci est supprimée de la mémoire et de la mémoire de messages (4). Le terme «suppression» est quelque peu trompeur, car en réalité, un enregistrement de confirmation est écrit dans le journal et l'indice dans l'indice augmente. La suppression effective du fichier journal contenant le message sera effectuée par le garbage collector dans le thread d'arrière-plan en fonction de ces informations.Le comportement décrit ci-dessus est une simplification pour faciliter la compréhension. En fait, ActiveMQ ne se contente pas de lire les données page par page à partir du disque, mais utilise à la place le mécanisme de curseur entre les parties de réception et de redirection du courtier pour minimiser l'interaction avec le référentiel du courtier dans la mesure du possible. La pagination, comme décrit ci-dessus, est l'un des modes utilisés dans ce mécanisme. Les curseurs peuvent être vus comme un cache au niveau de l'application qui doit être synchronisé avec le référentiel du courtier. Le protocole de cohérence utilisé est une partie importante de ce qui rend le mécanisme de répartition ActiveMQ beaucoup plus complexe que le mécanisme Kafka décrit dans le chapitre suivant.Modes de confirmation et de transaction
Différents modes de confirmation, qui déterminent l'ordre entre la relecture et la confirmation, ont un impact significatif sur la logique à implémenter dans le client. Ils sont les suivants:AUTO_ACKNOWLEDGEC'est le mode le plus utilisé, peut-être parce qu'il a le mot AUTO. Ce mode force la bibliothèque cliente à accuser réception du message en même temps que le message est lu par l'appel receive (). Cela signifie que si la logique métier initiée par le message lève une exception, le message est perdu car il a déjà été supprimé sur le courtier. Si le message est lu par l'auditeur, le message ne sera confirmé qu'après que l'auditeur a terminé avec succès le travail.CLIENT_ACKNOWLEDGEUne confirmation sera envoyée uniquement lorsque le code consommateur appelle explicitement la méthode Message.acknowledge ().DUPS_OK_ACKNOWLEDGEIci, les confirmations seront mises en mémoire tampon par le consommateur avant de les envoyer simultanément afin de réduire la quantité de trafic réseau. Cependant, si le système client s'arrête, les confirmations seront perdues et les messages seront renvoyés et traités une deuxième fois. Par conséquent, le code doit prendre en compte la probabilité de messages en double.Les modes de confirmation sont complétés par des outils de lecture transactionnelle. Lors de la création d'une session, elle peut être marquée comme transactionnelle. Cela signifie que le programmeur doit appeler explicitement Session.commit () ou Session.rollback (). Du côté des consommateurs, les transactions élargissent la gamme d'interactions que le code peut effectuer comme une seule opération atomique. Par exemple, vous pouvez lire et traiter plusieurs messages dans leur ensemble, ou soustraire un message d'une file d'attente, puis l'envoyer à une autre à l'aide du même objet Session.Envoi et plusieurs consommateurs
Jusqu'à présent, nous avons discuté du comportement de lecture des messages avec un seul consommateur. Voyons maintenant comment ce modèle est applicable à plusieurs consommateurs.Lorsque plusieurs consommateurs s'abonnent à la file d'attente, le comportement par défaut du courtier consiste à envoyer des messages à tour de rôle aux consommateurs qui ont une place dans les tampons de prélecture. Les messages seront envoyés dans l'ordre dans lequel ils sont arrivés dans la file d'attente - c'est la seule garantie FIFO fournie (premier entré, premier sorti; premier entré, premier sorti).Lorsque le consommateur s'arrête subitement, tous les messages qui lui sont envoyés, mais pas encore confirmés, seront renvoyés à un autre client disponible.Cela soulève une question importante: même lorsque des transactions avec les consommateurs sont utilisées, rien ne garantit que le message ne sera pas traité plusieurs fois.Tenez compte de la logique de traitement suivante à l'intérieur du consommateur:- Le message est soustrait de la file d'attente. La transaction commence.
- Un service Web est appelé avec le contenu du message.
- La transaction est validée. Une confirmation est envoyée au courtier.
Si le client termine entre les étapes 2 et 3, la relecture du message a déjà affecté un autre système en appelant le service Web. Les appels de service Web sont des requêtes HTTP et, en tant que tels, ne sont pas transactionnels.
Ce comportement est vrai pour tous les systèmes de mise en file d'attente - même s'ils sont transactionnels, ils ne peuvent garantir qu'il n'y aura pas d'effets secondaires lors du traitement des messages. Après avoir examiné en détail le traitement des messages, nous pouvons affirmer avec confiance que:
La livraison de messages n'existe pas une seule fois .Les files d'attente offrent une garantie de livraison
au moins une fois, et les parties sensibles du code doivent toujours envisager la possibilité de recevoir des messages répétés. Nous verrons plus loin comment un client de messagerie peut utiliser la lecture idempotente pour suivre les messages qui ont déjà été consultés et éviter les doublons.
Tri des messages
Pour un ensemble de messages arrivant dans l'ordre de [A, B, C, D], et pour deux consommateurs C1 et C2, la distribution normale des messages sera la suivante:
C1: [A, C]
C2: [B, D]Étant donné que le courtier ne contrôle pas le fonctionnement des processus de lecture et que l'ordre de traitement est parallèle, il n'est pas déterministe. Si C1 est plus lent que C2, alors l'ensemble initial de messages peut être traité comme [B, D, A, C].
Ce comportement peut surprendre les débutants qui s'attendent à ce que les messages soient traités dans l'ordre et, sur cette base, développent leur propre application de messagerie. L'exigence selon laquelle les messages envoyés par le même expéditeur doivent être traités dans l'ordre les uns par rapport aux autres, également appelée
ordre causal , est assez courante.
Prenons l'exemple d'utilisation suivant tiré des paris en ligne:
- Le compte utilisateur est configuré.
- L'argent est crédité sur le compte.
- Un pari est effectué qui retire de l'argent du compte.
Il est logique ici que les messages soient traités dans l'ordre dans lequel ils ont été envoyés, de sorte que l'état général du compte soit pris en compte. Des choses étranges peuvent se produire si le système essaie de retirer de l'argent d'un compte qui n'a pas de fonds. Il existe bien sûr des moyens de contourner ce problème.
Le modèle
client exclusif comprend l'envoi de tous les messages de la file d'attente à un client. En utilisant cette approche, lorsque vous connectez plusieurs instances d'applications ou de threads à la file d'attente, ils sont signés à l'aide d'un paramètre de destinataire spécial:
my.queue?consumer.exclusive=true . Lorsque vous connectez un consommateur monopole, il reçoit tous les messages. Lorsque le deuxième consommateur est connecté, il ne recevra aucun message tant que le premier ne se déconnecte pas. Ce deuxième consommateur est en fait une réserve chaude, tandis que le premier consommateur recevra désormais des messages exactement dans l'ordre dans lequel ils ont été enregistrés dans le journal - dans un ordre causal.
L'inconvénient de cette approche est que, bien que le traitement des messages soit cohérent, il s'agit d'un goulot d'étranglement car tous les messages doivent être traités par un seul ordinateur.
Pour mieux comprendre ce cas d'utilisation, vous devez reconsidérer le problème. Tous les messages doivent-ils être traités dans l'ordre? Dans le cas du traitement des offres décrites ci-dessus, il est nécessaire de traiter uniquement les messages liés à un compte de manière séquentielle. ActiveMQ fournit un mécanisme pour faire face à cette situation appelé
groupes de messages JMS .
Les groupes de messages sont une sorte de mécanisme de partitionnement qui permet aux producteurs de distribuer des messages en groupes qui seront traités séquentiellement selon une clé métier. Cette clé métier est définie dans une propriété de message appelée
JMSXGroupID .
La clé naturelle en cas de traitement des offres sera l'identifiant du compte.
Pour illustrer le fonctionnement de l'envoi, considérez un ensemble de messages arrivant dans l'ordre suivant:
[(A, Group1), (B, Group1), (C, Group2), (D, Group3), (E, Group2)]
Lorsqu'un message est traité par le mécanisme de répartition dans ActiveMQ et qu'il voit un
JMSXGroupID qui n'existait pas auparavant, cette clé est affectée au consommateur sur une base cyclique. Désormais, tous les messages avec cette clé seront envoyés à ce comptable.
Ici, les groupes seront répartis entre deux consommateurs: C1 et C2, comme suit:
C1: [Group1, Group3] C2: [Group2]
Les messages seront redirigés et traités comme suit:
C2: [B, D] C2: [(C, Group2), (E, Group2)]
Si le consommateur tombe en panne, tous les groupes qui lui sont attribués seront redistribués parmi le reste des consommateurs et tous les messages non confirmés seront redirigés à nouveau. Par conséquent, bien que nous puissions garantir que tous les messages associés seront traités dans l'ordre, nous ne pouvons pas prétendre qu'ils seront traités par le même consommateur.
Haute disponibilité
ActiveMQ offre une haute disponibilité avec un maître-esclave basé sur le stockage partagé. Dans ce schéma, deux ou plusieurs courtiers (bien que généralement deux) sont configurés sur des serveurs distincts et leurs messages sont stockés dans un magasin de messages situé dans un emplacement externe. Un magasin de messages ne peut pas être utilisé simultanément par plusieurs instances d'un courtier, donc sa fonction secondaire (magasin) est d'agir comme un mécanisme de blocage pour déterminer quel courtier obtiendra un accès exclusif (
figure 2-6 ).
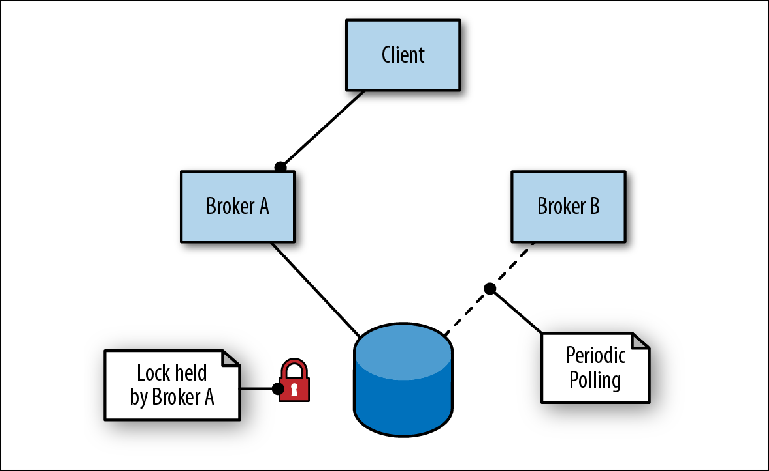 Figure 2-6. Le courtier A est le principal; le courtier B est en veille en tant qu'esclave
Figure 2-6. Le courtier A est le principal; le courtier B est en veille en tant qu'esclavePour se connecter au référentiel, le premier courtier (Broker A) assume le rôle de leader et ouvre ses ports pour le trafic des messages. Lorsque le deuxième courtier (Broker B) se connecte au référentiel, il essaie d'obtenir un verrou et, comme il ne réussit pas, s'arrête pendant une courte période avant d'essayer d'obtenir à nouveau un verrou. C'est ce qu'on appelle le confinement entraîné.
Dans le même temps, le client alterne les adresses des deux courtiers pour tenter de se connecter au port entrant, appelé connecteur de transport. Dès que le courtier principal est disponible, le client se connecte à son port et peut envoyer et lire des messages.
Lorsque le courtier A, agissant en tant que leader, échoue en raison d'une défaillance du processus (
figure 2-7 ), les événements suivants se produisent:
- Le client se déconnecte et essaie immédiatement de se reconnecter, en alternant les adresses de deux courtiers.
- Le verrou du message est libéré. Le timing dépend de l'implémentation du stockage.
- Le courtier B, qui était en mode esclave, essayant périodiquement d'obtenir un verrou, réussit enfin et assume le rôle de maître, ouvrant ses ports.
- Le client se connecte au Broker B et poursuit son travail.
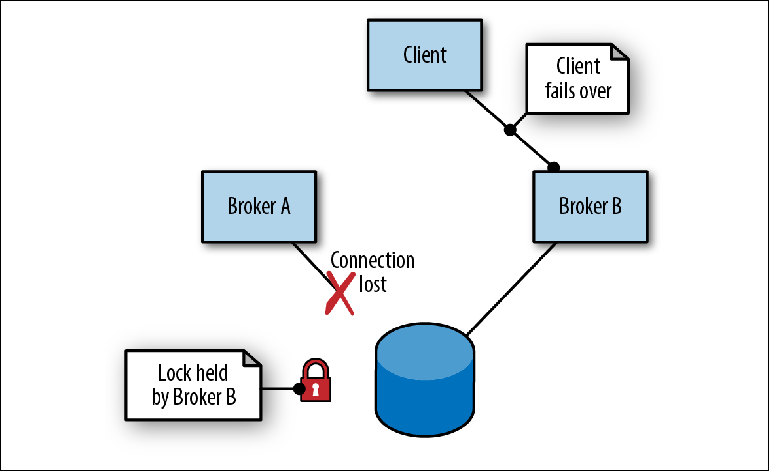 Figure 2-7. Le courtier A se termine en perdant la connexion au référentiel. Le courtier B prend les devants
Figure 2-7. Le courtier A se termine en perdant la connexion au référentiel. Le courtier B prend les devantsLa logique d'alternance entre plusieurs adresses de courtier n'est pas garantie d'être intégrée dans la bibliothèque cliente, comme c'est le cas dans les implémentations JMS / NMS / CMS. Si la bibliothèque ne fournit que la reconnexion à une seule adresse, vous devrez peut-être placer quelques courtiers derrière un équilibreur de charge, qui devrait également être hautement disponible.
Le principal inconvénient de cette approche est que pour simplifier le travail d'un courtier logique, plusieurs serveurs physiques sont nécessaires. Dans ce cas, l'un des deux serveurs du courtier est inactif, attendant la déconnexion de son partenaire avant de pouvoir commencer à fonctionner.
Cette approche présente également la complexité supplémentaire que le stockage du courtier utilisé, qu'il s'agisse d'un système de fichiers réseau partagé ou d'une base de données, doit également être hautement accessible. Cela entraîne des coûts supplémentaires pour l'équipement et l'administration des paramètres du courtier. Dans ce scénario, il est tentant de réutiliser des référentiels à haute disponibilité existants utilisés par d'autres parties de l'infrastructure, comme une base de données, mais c'est une erreur.
Il est important de se rappeler que le disque est le principal limiteur des performances globales du courtier. Si le disque lui-même est utilisé simultanément par un processus autre que le courtier de messages, l'interaction de ce processus avec le disque ralentit probablement l'enregistrement du courtier et, par conséquent, la vitesse à laquelle les messages peuvent transiter par le système. De tels ralentissements sont difficiles à diagnostiquer et la seule solution consiste à séparer les deux processus en différents volumes de stockage.
Pour assurer le fonctionnement stable du courtier, un stockage dédié et exclusif est nécessaire.
Mise à l'échelle verticale et horizontale
À un moment donné de la vie du projet, vous pouvez rencontrer une limitation des performances sur le courtier de messages. Ces limitations concernent généralement les ressources, en particulier les interactions ActiveMQ avec le stockage utilisé. Ces problèmes surviennent généralement en raison de conflits de volume de messages ou de bande passante entre les destinataires, par exemple, lorsqu'une file d'attente déborde du courtier pendant les périodes de pointe.
Il existe plusieurs façons d'obtenir plus de performances de l'infrastructure du courtier:
- N'utilisez pas la persistance si ce n'est pas nécessaire. Certains scénarios d'utilisation autorisent la perte de messages lors de plantages, en particulier lorsqu'un système envoie un autre état d'instantané complet à l'autre via la file d'attente, périodiquement ou à la demande.
- Exécutez le courtier sur des disques plus rapides. En conditions réelles, des différences significatives dans la bande passante d'enregistrement ont été notées entre le disque dur standard et les alternatives basées sur la mémoire.
- Tirez le meilleur parti des tailles de disque. Comme le montre le modèle d'interaction de pipeline de disques décrit ci-dessus, un débit plus élevé peut être atteint en utilisant des transactions pour envoyer des groupes de messages, combinant ainsi plusieurs opérations d'écriture en une plus grande.
- Utilisez le partitionnement du trafic. Vous pouvez obtenir un débit plus élevé en fractionnant les destinations de l'une des manières suivantes:
- Plusieurs disques dans un courtier, par exemple, en utilisant l'adaptateur de persistance mKahaDB pour plusieurs répertoires, chacun étant monté sur un disque distinct.
- Plusieurs courtiers, et le partitionnement du trafic est effectué manuellement par l'application cliente. ActiveMQ ne fournit aucune fonction native à cet effet.
L'une des causes les plus courantes des problèmes de performances des courtiers est simplement une tentative d'en faire trop avec une seule instance. En règle générale, cela se produit dans des situations où le courtier est naïvement divisé entre plusieurs applications sans prendre en compte la charge existante sur le courtier ou comprendre les volumes. Au fil du temps, un courtier est de plus en plus chargé jusqu'à ce qu'il cesse de se comporter correctement.
Le problème se pose souvent pendant la phase de conception du système, lorsque l'architecte du système peut proposer un tel schéma comme dans la
figure 2-8 .
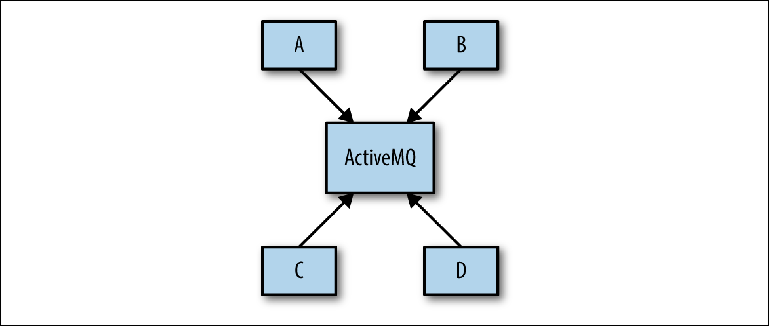 Figure 2-8. Vue conceptuelle de l'infrastructure de messagerie
Figure 2-8. Vue conceptuelle de l'infrastructure de messagerieL'objectif est que plusieurs applications communiquent entre elles de manière asynchrone via ActiveMQ. L'objectif n'est plus spécifié, puis le schéma détermine la base de la configuration réelle du courtier. Cette approche est appelée Universal Data Pipeline.
Il ne prend pas en compte l'étape fondamentale d'analyse entre la conception conceptuelle mentionnée ci-dessus et la mise en œuvre physique. Avant de procéder à la construction d'une configuration spécifique, il est nécessaire d'effectuer une analyse, qui sera ensuite utilisée pour justifier le projet physique. La première étape de ce processus consiste à déterminer quels systèmes interagissent les uns avec les autres - un diagramme assez simple avec des rectangles et des flèches (
figure 2-9 ).
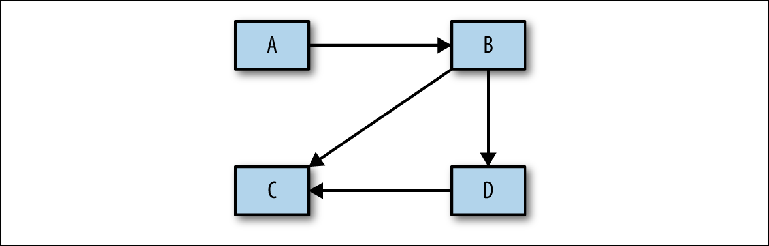 Figure 2-9. Esquissez les flux de messages entre les systèmes
Figure 2-9. Esquissez les flux de messages entre les systèmesAprès son approbation, vous pouvez accéder aux détails pour répondre aux questions suivantes:
- Combien de files d'attente et de sujets seront utilisés?
- Quels volumes de messages sont attendus pour chacun d'eux?
- Quelle est la taille des messages de chaque destinataire? Les messages volumineux peuvent provoquer des problèmes dans le processus de pagination, entraînant le dépassement des limites de mémoire et le blocage du courtier.
- Les flux de messages seront-ils uniformes tout au long de la journée ou y aura-t-il des pointes dues aux travaux par lots? Des lots volumineux dans une file d'attente moins utilisée peuvent interférer avec les écritures de disque en temps opportun pour les destinations hautes performances.
- Les systèmes sont-ils dans le même centre de données ou dans différents? La communication à distance implique une sorte de courtier réseau.
L'idée est de définir des scénarios de messagerie distincts qui peuvent être combinés ou divisés par des courtiers individuels (
Figure 2-10 ).
Après une telle panne, les scénarios d'utilisation peuvent être simulés en combinant les uns avec les autres à l'aide du module de performance ActiveMQ pour identifier les problèmes.
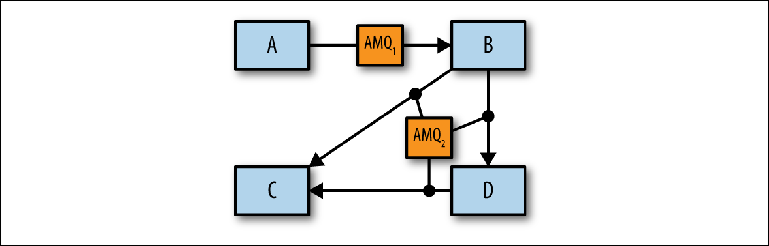 Figure 2-10. Identification des courtiers individuels
Figure 2-10. Identification des courtiers individuelsAprès avoir déterminé le nombre approprié de courtiers logiques, vous pouvez déterminer comment les implémenter au niveau physique à l'aide de configurations et de réseaux de courtiers hautement accessibles.
Résumé
Dans ce chapitre, nous avons examiné le mécanisme par lequel ActiveMQ reçoit et distribue les messages. Nous avons discuté des fonctionnalités prises en charge par cette architecture, y compris l'équilibrage de charge permanent des messages et des transactions associés. Dans le même temps, nous avons introduit un ensemble de concepts communs à tous les systèmes de messagerie, y compris les protocoles de communication et les magazines. Nous avons également examiné en détail les difficultés liées à l'écriture sur disque et comment les courtiers peuvent utiliser des techniques telles que l'écriture de paquets pour améliorer les performances. Enfin, nous avons examiné comment ActiveMQ peut être rendu hautement disponible et comment le faire évoluer au-delà des capacités d'un courtier individuel.
Dans le chapitre suivant, nous verrons Apache Kafka et comment son architecture redéfinit la relation entre les clients et les courtiers pour fournir un pipeline de messages incroyablement robuste avec une bande passante qui est beaucoup plus grande qu'un courtier de messages classique. Nous discuterons de la fonctionnalité qu'il utilise pour atteindre cet objectif et examinerons brièvement l'architecture des applications qui fournissent cette fonctionnalité.
Partie suivante:
Comprendre les courtiers de messages. Apprentissage de la mécanique de la messagerie via ActiveMQ et Kafka. Chapitre 3. KafkaTraduction terminée: tele.gg/middle_java