 Équipement de laboratoire de simulation hybride. La photo montre le panneau de commande du SDS 9300 qui, avec plusieurs ordinateurs analogiques, a élaboré des simulations du module de commande et du module lunaire.
Équipement de laboratoire de simulation hybride. La photo montre le panneau de commande du SDS 9300 qui, avec plusieurs ordinateurs analogiques, a élaboré des simulations du module de commande et du module lunaire.Des années avant Apollo 11, lorsque le système de contrôle était en cours de développement, ils pensaient que le logiciel embarqué pouvait être fait en dernier: «Hal le fera», ont-ils déclaré. En fait, des dizaines de personnes et des centaines de personnel de soutien le faisaient, mais Hal Laning a d'abord dû trouver comment organiser de nombreuses fonctions logicielles afin qu'elles puissent être exécutées presque simultanément en temps réel sur l'ordinateur de bord de l'engin spatial, qui a une taille et une vitesse limitées .
L'architecture de Hal a évité les pièges d'un système d'exploitation dans lequel les calculs devraient être clairement divisés entre les périodes. De tels systèmes sont assez difficiles à mettre en œuvre, car les tâches peuvent changer arbitrairement. Lorsque des tâches sont ajoutées ou modifiées au cours du processus de développement, un changement dans la planification des tâches peut être nécessaire. Le pire est que le système d'exploitation existant de l'ordinateur de bord est très fragile, en ce sens qu'il échoue complètement si la tâche prend plus de temps que prévu.
Au lieu de cela, Leining a développé un système dans lequel les fonctions du programme sont distribuées sous forme de «tâches», qui peuvent être de n'importe quelle taille qui sera nécessaire pour exécuter ces fonctions. Chaque tâche se voit attribuer une priorité. Le système d'exploitation exécute toujours la tâche avec la priorité la plus élevée. Si une tâche de faible priorité est exécutée et qu'une tâche de haute priorité est affectée à ce moment, la tâche de faible priorité sera suspendue jusqu'à ce que la tâche de haute priorité soit terminée. Un tel système nous donne l'illusion que les tâches sont exécutées simultanément, bien qu'en réalité, bien sûr, les tâches soient exécutées à tour de rôle. Un tel système n'est pas déterministe, mais ses fonctions sont compréhensibles et peuvent être vérifiées, et il augmente la fiabilité, la sécurité, la flexibilité d'utilisation et, en particulier, la facilité de développement.
Executive (
le système d'exploitation en temps réel AGC et LGC. Approx. Transl. ) Organisé l'exécution des tâches de telle sorte que chaque tâche conserve son état sous la forme d'un ensemble de registres, et l'état est maintenu pendant que la tâche est exécutée avec une haute priorité. LGC contient un tableau de huit ensembles de 12 registres chacun, 15 bits par registre. Un ensemble de registres de cette taille est suffisant pour effectuer de nombreuses tâches, mais les tâches qui utilisent l'interpréteur (un
langage d'interprétation intégré pour les tâches qui fonctionnent avec des nombres à double précision. Approx. Transl. ) Pour effectuer des calculs vectoriels et matriciels nécessitent plus d'espace. Pour de telles tâches, un tableau séparé de 43 registres est alloué. LGC contient cinq de ces matrices (Vector Accumulator, VAC).
Avec un tel ensemble limité de tableaux pour maintenir le contexte des tâches, le lancement des tâches pour exécution doit être fait très soigneusement. Les fonctions exécutées séquentiellement les unes après les autres ont été combinées en une seule tâche. La grande tâche de SERVICER a été active pendant toute la phase d'atterrissage et les autres phases du vol avec le moteur allumé, et elle comprenait la navigation à l'aide d'accéléromètres, d'équations de mouvement, de commande des gaz du moteur, des données sur la position du navire, d'autres données sur l'affichage, et chaque la fonction a utilisé la sortie des précédentes.
Le nombre de tableaux de registres et de VAC disponibles limite le nombre de tâches pouvant être mises en file d'attente pour exécution de huit, dont jusqu'à cinq peuvent utiliser des tableaux VAC. Pendant le fonctionnement normal, le nombre de tâches en cours d'exécution reste constant, bien que les tâches lancées pour une seule exécution, ou de manière asynchrone, puissent provoquer des fluctuations de la charge du système.
Cependant, si le nombre de tâches démarrées est plus que terminé, le nombre de tableaux de registres et de VAC utilisés augmente. Si cette situation persiste pendant une période suffisamment longue, leur nombre s'épuise et la demande de lancement de la tâche suivante ne peut pas être satisfaite.
Nous reviendrons un an plus tôt, avant le lancement d'Apollo 11, lorsque nous, les ingénieurs logiciels, pensions que nous avions déjà suffisamment de choses, et ils nous ont demandé d'écrire un logiciel pour atterrir sur la Lune de telle sorte qu'il puisse littéralement être désactivé et réactivé. sans interrompre le processus d'atterrissage et autres manœuvres vitales! Cela s'appelait «redémarrer la protection». Outre les interférences d'alimentation, d'autres facteurs peuvent entraîner le redémarrage du système. Le redémarrage se produit si le matériel pense que le programme s'est écrasé dans une boucle infinie, ou si une erreur de parité s'est produite lors de la lecture de la ROM, ou pour plusieurs autres raisons.
La protection contre le redémarrage a été mise en œuvre en enregistrant des «points de cheminement» à des points appropriés dans le programme, disposés de telle sorte que le retour au dernier «point de cheminement» ne provoque pas d'erreur, comme le montre l'exemple suivant:
NEW_X = X + 1
X = NEW_XDe toute évidence, sans enregistrer le waypoint, l'exécution de ce code une deuxième fois entraînera une nouvelle incrémentation de X.
Après le redémarrage, un tel programme reprend son travail. Chaque tâche commence par le dernier waypoint enregistré. si plusieurs copies de la même tâche étaient dans la file d'attente, seule la dernière reprend. Certaines tâches n'ont pas de statut vital et ne sont pas protégées contre le redémarrage. Ils disparaissent simplement.
La protection de redémarrage a très bien fonctionné. Sur le panneau de commande de notre simulateur hybride à Cambridge, un bouton a provoqué le redémarrage d'AGC. Lors des tests de logiciels, nous avons parfois appuyé sur ce bouton à des moments aléatoires, espérant presque que l'échec nous conduirait à un autre bogue. Invariablement, chaque fois que la protection contre le redémarrage était déclenchée et le travail se poursuivait sans s'arrêter.
(Le simulateur hybride contenait un ordinateur numérique SDS 9300 et un ordinateur analogique Beckmann, un véritable ordinateur AGC et des modèles de cockpit réalistes pour les modules de commande et de lune.)
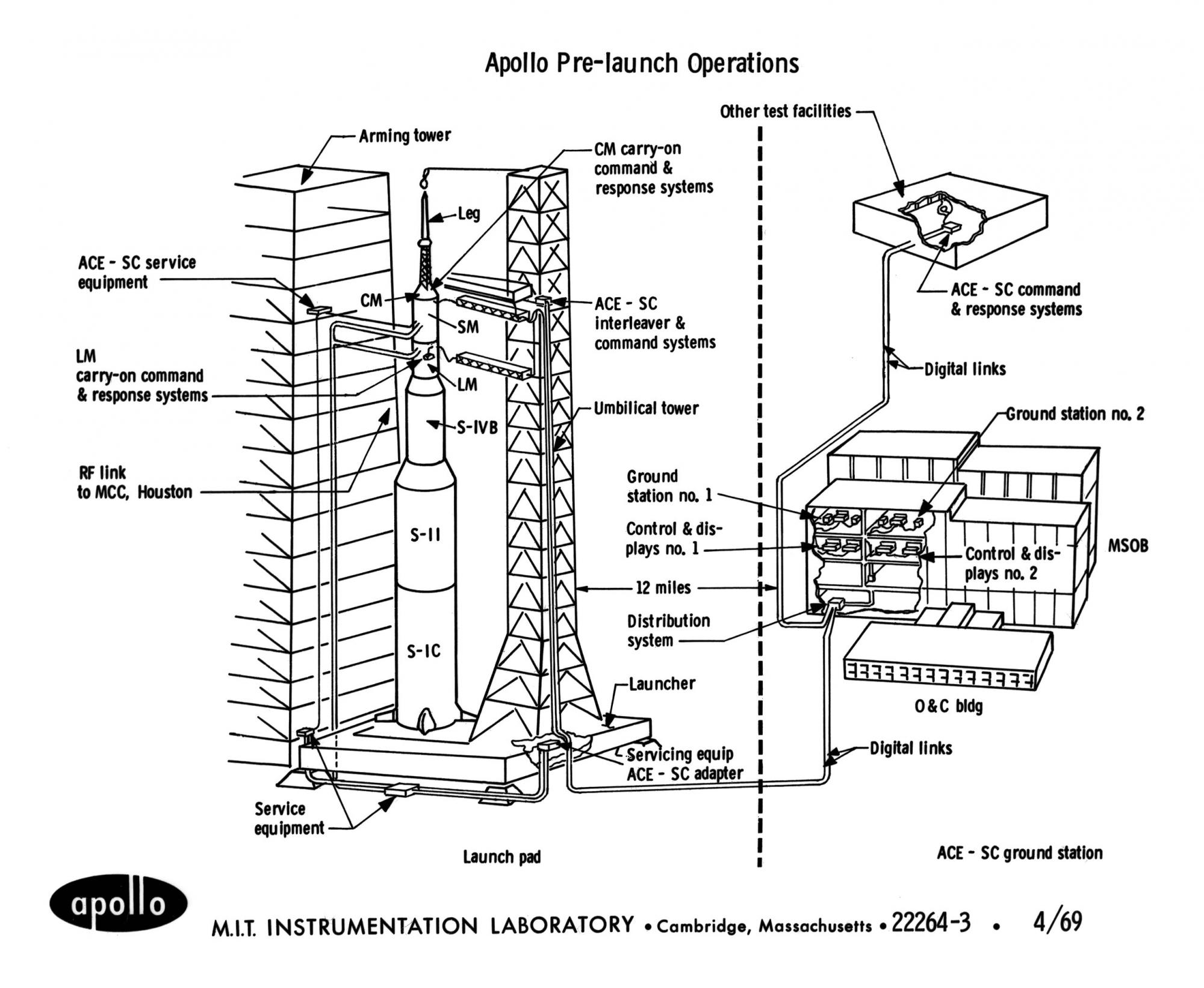 Avant la préparation d'Apollo.
Avant la préparation d'Apollo.Non seulement le fer pouvait provoquer un redémarrage, mais il pouvait être appelé par programme si le programme atteignait un point où l'ordinateur ne savait pas comment continuer à exécuter le programme. Cela s'est produit lors du transfert du contrôle sous la balise BAILOUT dans le module Alarms and Aborts. L'appel était accompagné d'un code d'erreur.
Ces actions ont été effectuées par le système exécutif en cas d'épuisement des ressources. Si la tâche ne peut pas être définie en raison du fait qu'il n'y a pas de tableaux libres pour enregistrer les registres, Executive a appelé BAILOUT avec le code d'erreur 1202. S'il n'y avait pas de VAC libre, alors BAILOUT avec le code 1201 a été appelé.
Toutes les fonctions exécutées par LGC n'étaient pas exécutées en tant que «tâches». En plus d'eux, il y avait des interruptions matérielles qui pouvaient survenir à tout moment (si elles n'étaient pas explicitement interdites) qui remplissaient des fonctions de haute priorité, des interruptions étaient assignées à certains appareils, y compris le pilote automatique numérique, la «liaison montante» et la «liaison descendante» (dispositif d'
émission et de réception) données sur le canal radio avec la Terre (traduction approximative ) et le clavier.
D'autres interruptions pourraient être utilisées pour exécuter des morceaux de code qui doivent être exécutés à un moment précis. Ces fonctions étaient appelées tâches, et elles étaient programmées dans un sous-programme appelé WAITLIST. Les «tâches» étaient censées avoir un délai d'exécution très court.
Alors que les «tâches» devaient être exécutées avec une certaine priorité, les «tâches» devaient être lancées à un certain moment. Les tâches et les tâches étaient souvent partagées. La tâche pourrait être lancée pour lire les lectures du capteur, qui devraient être lues à un moment strictement défini, et la tâche, à son tour, a lancé une tâche avec une certaine priorité pour le traitement de ces lectures.
Lorsque Hal Lane a conçu Executive et Waitlist au milieu des années 1960, il a tout fait à partir de zéro, sans s'appuyer sur des exemples. Et ses principes sont vrais aujourd'hui. La répartition des fonctions par un nombre limité de processus asynchrones, sous le contrôle d'un environnement exécutif avec un multitâche préemptif basé sur des intervalles de temps et des priorités, tout cela sous-tend toujours les systèmes informatiques modernes en temps réel pour les applications spatiales.
 Assemblage de gyroscopes.
Assemblage de gyroscopes.* * *
Pour comprendre la cause profonde des alarmes sur Apollo 11 pendant la descente, il est nécessaire de considérer la procédure d'approche du module de commande, qui suit après la montée du module lunaire de la surface lunaire à l'orbite lunaire. Tout comme nous utilisons un radar d'atterrissage pour mesurer l'altitude et la vitesse par rapport à la surface lunaire lors de l'atterrissage sur la lune, l'approche du module de commande en orbite lunaire nécessite de mesurer la distance, la vitesse et la direction par rapport au deuxième navire utilisant le radar d'approche.
Le radar de proximité a plusieurs modes de fonctionnement qui sont définis par le commutateur de mode. Ces modes sont les suivants: SLEW, AUTO et LGC. En modes SLEW et AUTO, le radar fonctionne sous contrôle de commande, quel que soit le LGC. Ce mode de fonctionnement pourrait être utilisé lors du décollage et de l'approche en cas de panne du système de navigation principal. En mode SLEW, l'antenne radar est guidée manuellement, le reste du temps, elle est immobile. Lorsque l'antenne est dirigée vers la cible, vous pouvez basculer le mode sur AUTO (suivi automatique) et elle suivra la cible. Le radar de proximité mesure la distance et la vitesse, et les angles de rotation des arbres sur lesquels l'antenne tourne sont affichés sur les écrans du cockpit et sur les indicateurs sous forme d'échelles verticales. De plus, les données de distance et de vitesse sont entrées dans le système de guidage abandonné (AGS), un ordinateur avec seulement 6144 mots de mémoire qui a dupliqué le système PGNS principal lors de l'atterrissage sur la lune et du décollage de la lune.
(Les noms des trois modes de fonctionnement du radar de rapprochement étaient une source d'embarras pour certains commentateurs. À la demande de l'équipage, les désignations ont été modifiées après la mission LM-1 et avant l'atterrissage sur la lune. Le mode qu'Apollo 11 a appelé LGC était anciennement appelé AUTO. Le mode qui il s'appelait AUTO sur Apollo 11, précédemment appelé MANUAL. Le nom du mode SLEW est resté inchangé. Bien que cela n'ait aucunement contribué au problème sur Apollo 11, la documentation LUMINAIRE interne dans la section relative au canal discret 33, à l'époque encore appelée re Référence LGC avec le radar de proximité activé par RR AUTO-POWER ON.)
Si le système PGNS fonctionnait (tel qu'il était en réalité), le LGC contrôlait le radar, auquel cas le commutateur de mode du radar de proximité était réglé sur LGC. L'électronique de l'interface radar a permis au logiciel d'obtenir des données sur la distance et la vitesse mesurées par le radar, ainsi que les angles de l'arbre de rotation de l'antenne, à partir desquels la direction de la cible peut être trouvée. Le programme LGC a utilisé ces informations pour rapprocher le LGC du module de commande.
Il s'est avéré que le radar d'approche peut également fonctionner pendant la descente, et cela a été fait pendant la descente d'Apollo 11. Les instructions de l'équipage exigeaient que le radar soit allumé immédiatement avant le début de la phase P63 et qu'il reste en mode SLEW ou AUTO pendant toute la manœuvre d'atterrissage.
De nombreuses explications ont été données sur les raisons pour lesquelles le radar a été réglé de cette manière pour atterrir sur la lune. Par exemple, certaines personnes à Houston peuvent avoir envisagé un système de surveillance d'atterrissage de fantaisie en comparant les données radar avec un graphique des lectures attendues. Cependant, il y a une explication plus simple: le radar a été allumé avant l'atterrissage uniquement pour rester au chaud en cas d'accident lors d'une interruption, et était en mode AUTO (si le module lunaire était dans une position qui vous permet de suivre le module de commande) ou SLEW (à d'autres moments), juste pour éviter tout mouvement inutile de l'antenne.
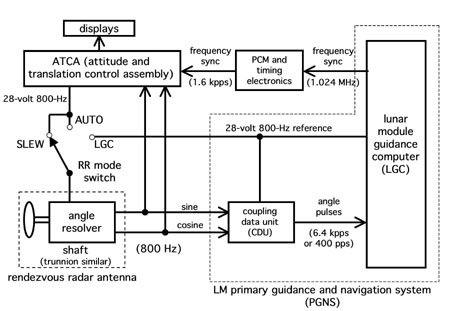
Figure 7.
Interfaces radar PGNS, ATCA et de proximitéCe problème était souvent attribué (y compris par l'auteur plus tôt) simplement comme une erreur dans la liste de contrôle. Il s'agit d'un libellé inexact, tout comme il est inexact d'appeler un arrêt prématuré du moniteur
Le moteur delta-V du module lunaire est une "erreur informatique", alors qu'en fait l'erreur était dans la documentation. En fait, la position du commutateur radar de proximité Apollo 11 n'aurait pas dû poser de problème. Mais à partir d'ici, vous pouvez retracer un autre cas d'erreurs dans la documentation.
Des années auparavant, la documentation était écrite sur le document de contrôle d'interface (ICD), qui définit l'interface électrique entre le PGNS et l'électronique ATCA (assiette et translation control assembly), qui a été fourni par Grumman Aerospace, la société qui a construit le module d'atterrissage. ICD a déterminé que les circuits d'alimentation 28V avec une fréquence de 800 Hz dans deux systèmes devraient être alignés en fréquence, mais il n'est pas écrit qu'ils devraient être synchronisés en phase. En fait, les deux systèmes étaient alignés en fréquence avec le signal de «synchronisation de fréquence» envoyé par LGC. Ils avaient une relation de phase constante. Cependant, la phase entre les deux tensions était une variable complètement aléatoire, selon le moment où le LGC, toujours alimenté après ACTA, commençait à envoyer un signal de synchronisation. Ces interfaces sont représentées sur la fig. 7.
Un problème avec la phase 800 Hz a été détecté lors du test du module d'atterrissage LM-3 et est documenté, mais n'a jamais été corrigé. En conséquence, lorsque le commutateur de mode radar était en position AUTO ou SLEW, le mécanisme rotatif du radar était excité par un signal de 800 Hz provenant de l'ATCA, qui avec une probabilité élevée ne coïncide pas en phase avec le signal de 800 Hz, qui est utilisé comme référence dans les CDU qui convertissent les signaux à partir de un mécanisme pour transformer en données pour l'ordinateur et décrémenter (ou décrémenter) les compteurs de l'ordinateur qui indiquent au programme comment l'antenne tourne.
Sur Apollo 11, cependant, les CDU fonctionnaient différemment. Puisqu'ils ont pris la tension générée séparément comme signal de référence, les signaux du capteur d'angle d'antenne reçus par le CDU ont montré un angle inconnu. L'erreur était plus grande si la différence de phase était proche de 90 ou 270 degrés, et Apollo 11, évidemment, a touché l'un de ces points intéressants. En réponse, le CDU a commencé à incrémenter ou décrémenter les compteurs LGC à une vitesse presque constante, environ 6400 impulsions par seconde pour chacun des coins. Cela se produisait chaque fois que le commutateur était en mode SLEW ou AUTO, que le radar de proximité soit activé ou non.
Les compteurs CDU dans LGC ont été incrémentés ou décrémentés par des signaux externes qui ont été traités dans l'ordinateur. Cela prenait du temps, dans ce cas un cycle de mémoire de 11,7 µs chacun. Si les compteurs augmentaient à la vitesse maximale, cela prenait environ 15% du temps total (ce temps de fuite est appelé TLOSS). Nous fournissons actuellement une estimation prudente du temps passé de 13%, ce qui est cohérent avec le comportement observé.
Après le vol d'Apollo 11, les ingénieurs de Grumman ont effectué des tests afin de reproduire le comportement informatique observé en vol. Ils ont confirmé que même dans le pire des cas, les CDU ne pouvaient pas envoyer d'impulsions à la vitesse maximale. Ils sont arrivés à la conclusion que la charge informatique maximale avec ces compteurs (TLOSS) pouvait être de 13,36%. Au cours de la simulation, des erreurs similaires à celles survenues en vol ont été reproduites. Ainsi, la valeur TLOSS citée est la meilleure estimation documentée de la charge informatique d'Apollo 11. [Clint Tillman, «Simulation de l'interface RR-CDU lorsque le RR est en mode SLEW ou AUTO (pas LGC) dans le laboratoire FMES / FCI», 9 août , 1969]
Je suis redevable à George Silver, expert en systèmes de guidage de module lunaire, pour son explication patiente de l'interface radar d'approche du module lunaire. Il a joué un rôle central dans la mission Apollo 11. Au moment du lancement, il était à Cap Canaveral, puis a volé à Boston, à Cambridge, pour prendre le devoir de surveiller le décollage de la Lune. Il a regardé la lune atterrir à la maison à la télévision le 20 juillet. Il a entendu le son des alarmes, a deviné que quelque chose prenait du temps à l'ordinateur et a rappelé un cas qu'il avait vu lors des tests des systèmes LM-3, lorsque le radar de proximité avait provoqué une activité effrénée des compteurs. Après une analyse plus approfondie de l'équipe de surveillance de la mission à Cambridge, Silver a finalement contacté les représentants du MIT à Houston le matin du 21 juillet, moins d'une heure avant le décollage de la lune.
 Fragment de contrôle manuel
Fragment de contrôle manuel* * *
L'atterrissage sur la lune a été la phase de vol la plus intense. Le système de contrôle d'atterrissage devait atteindre un objectif avec certaines coordonnées, ayant une certaine vitesse, accélération, degré de saccades (degré de changement / accélération). Klumpp a appelé le taux de variation du «jerk» («jerk») «snap» (snap), et les deux dérivés suivants ont été appelés «crackle» et «pop» (pop). Dans la phase de visibilité (
c'est-à-dire lorsque la surface de la lune était visible dans hublot du navire. environ. ) le programme a permis à l'équipage de changer de site d'atterrissage. L'accélérateur a été contrôlé en continu. La navigation comprenait des mesures à l'aide du radar d'atterrissage. La figure 8. montre un profil de charge typique entre le choix de la phase P63 et le contact avec la surface de la lune.

Fig. 8:
Charge lors de l'atterrissage (données du simulateur)Même dans ces conditions, nous avons essayé de rendre nos programmes assez rapides pour avoir suffisamment de temps en cas de gros TLOSS. La principale limitation était la période de deux secondes, qui était intégrée au programme «G moyen» utilisé pendant la phase de vol.
C'est la période pendant laquelle la tâche READACCS a lu les lectures des accéléromètres et a lancé la tâche SERVICER, qui a utilisé ces valeurs comme données initiales pour une nouvelle itération des calculs de trajectoire, étranglant le moteur, déterminant la position du navire et l'affichant à l'écran. Lors de l'atterrissage, le degré de charge informatique a simplement montré combien de temps a été consacré aux tâches et aux interruptions au cours de chaque période de deux secondes.Pendant la phase de freinage, jusqu'à ce que le radar d'atterrissage voie la surface, le temps de réserve était d'au moins 15%. Après la mise en service du radar, des calculs supplémentaires commencent, associés au transfert des coordonnées du système de référence radar vers le système de coordonnées pour la navigation, ce qui réduit la marge de 13%. Lorsque l'affichage démarre (verbe 16, substantif 68), la marge diminue à 10% ou moins. Baz Aldrin était perspicace quand il a dit après le signal 1202, "il semble qu'il soit apparu lorsque nous sommes entrés en 1668" [16].Lorsque la marge est de 10% et 13% est supprimée, LGC n'a pas suffisamment de temps processeur pour effectuer toutes les fonctions requises. En raison de la flexibilité de la conception exécutive et contrairement à ce qui se passerait avec une architecture rigide, il n'y a pas eu de catastrophe.Tableau 1. Tâches actives lors de l'atterrissage sur la lune. Le tableau 1 répertorie les tâches actives lors de l'atterrissage d'Apollo 11. SERVICER a la priorité la plus faible et s'exécute le plus longtemps. Les tâches hautement prioritaires peuvent arrêter le SERVICER, mais elles ont un délai d'exécution relativement court.Étant donné que SERVICER avait une faible priorité en raison de sa grande taille, il est tombé en panne par manque de temps de calcul. Avec une marge de temps négative, SERVICER n'a pas réussi à donner une réponse lorsque READACCS, qui a démarré selon un calendrier, a redémarré et a redémarré SERVICER. Étant donné que la copie précédente de SERVICER n'a pas terminé le calcul, elle n'a pas libéré le registre et les tableaux VAC, et READACCS a appelé FINDVAC pour que l'Exécutif alloue le nouveau registre et le tableau VAC et démarre SERVICER. Ce SERVICER n'a pas non plus terminé le travail à temps. Après un court cycle de telles opérations, le registre et les matrices VAC sont terminées. Lorsque la demande suivante est arrivée à l'Exécutif, BAILOUT a été appelé avec le code 1201 ou 1202.
Le tableau 1 répertorie les tâches actives lors de l'atterrissage d'Apollo 11. SERVICER a la priorité la plus faible et s'exécute le plus longtemps. Les tâches hautement prioritaires peuvent arrêter le SERVICER, mais elles ont un délai d'exécution relativement court.Étant donné que SERVICER avait une faible priorité en raison de sa grande taille, il est tombé en panne par manque de temps de calcul. Avec une marge de temps négative, SERVICER n'a pas réussi à donner une réponse lorsque READACCS, qui a démarré selon un calendrier, a redémarré et a redémarré SERVICER. Étant donné que la copie précédente de SERVICER n'a pas terminé le calcul, elle n'a pas libéré le registre et les tableaux VAC, et READACCS a appelé FINDVAC pour que l'Exécutif alloue le nouveau registre et le tableau VAC et démarre SERVICER. Ce SERVICER n'a pas non plus terminé le travail à temps. Après un court cycle de telles opérations, le registre et les matrices VAC sont terminées. Lorsque la demande suivante est arrivée à l'Exécutif, BAILOUT a été appelé avec le code 1201 ou 1202.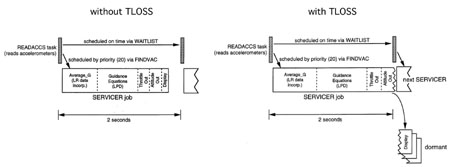 Fig. 9: Fonctionnement du SERVICER sans et avec TLOSS
Fig. 9: Fonctionnement du SERVICER sans et avec TLOSSFig.
La figure 9 montre comment SERVICER se comporte avec un TLOSS puissant, et sur la fig. La figure 10 montre une comparaison des registres et des ensembles VAC pendant le fonctionnement normal et avec un TLOSS puissant, pendant lequel le redémarrage se produit.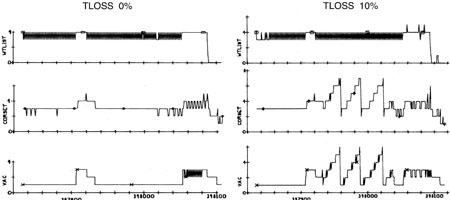
Fig.
10. L'effet produit par TLOSS sur les ressources de l'exécutif et de la liste d'attente lors de l'atterrissage sur la lune (les données du simulateur commencent par la phase P63 avant de recevoir les données de vitesse du radar et se terminent par l'atterrissage [17].)Un effet intéressant de cette séquence d'événements pendant la phase P63 , c'est que le problème s'est éliminé. Un redémarrage du logiciel n'a restauré que la copie la plus récente de la tâche SERVICER et supprimé toutes les copies incomplètes de SERVICER. De plus, il a réalisé toutes les fonctions qui n'ont pas de protection contre le redémarrage car elles ne sont pas critiques, y compris le moniteur DELTAH (verbe 16, substantif 68). Cela a fait passer l'affichage de «nom 68» à «nom 63» après deux alarmes en P63.Le système de protection contre le redémarrage a été initialement développé en raison d'éventuelles défaillances matérielles et a permis de réduire la charge de calcul avec un TLOSS volumineux. Le système en temps réel que nous avons développé s'est révélé tolérant aux pannes dans certaines conditions.Pendant la phase P64, la situation était différente. En plus des équations de mouvement habituelles, un traitement supplémentaire a été ajouté, notamment la possibilité de réaffecter le site d'atterrissage. Des fonctionnalités logicielles supplémentaires laissent une marge de temps inférieure à 10%. Des alarmes ont continué de se produire. Trois alarmes de 1201 et 1202 se sont produites en 40 secondes. À chaque fois, le logiciel a redémarré, effaçant la file d'attente des tâches, mais n'a pas pu réduire la charge.Temps de mission 102: 43: 08, anticipant la prochaine alarme, Armstrong a fait passer le pilote automatique du mode AUTO au mode ATT HOLD, affaiblissant la charge de calcul, puis est entré en mode semi-manuel P66, dans lequel la charge de l'ordinateur était faible. Après 2 minutes et 20 secondes de manœuvre en phase P66, le module lunaire s'est assis.