
Il s'agit d'un mythe assez courant dans le domaine du matériel serveur. Dans la pratique, les solutions hyperconvergées (quand elles sont toutes réunies) ont besoin de beaucoup pour quoi. Historiquement, les premières architectures ont été développées par Amazon et Google pour leurs services. L'idée était alors de faire une batterie de calcul des mêmes nœuds, chacun ayant ses propres disques. Tout cela a été combiné par un logiciel de formation de système (hyperviseur) et était déjà divisé en machines virtuelles. La tâche principale est un minimum d'effort pour maintenir un nœud et un minimum de problèmes de mise à l'échelle: nous venons d'acheter encore mille ou deux des mêmes serveurs et de nous connecter à proximité. En pratique, ce sont des cas isolés, et bien plus souvent nous parlons d'un plus petit nombre de nœuds et d'une architecture légèrement différente.
Mais le plus reste le même: l'incroyable facilité de mise à l'échelle et de contrôle. Moins - différentes tâches consomment les ressources différemment, et quelque part il y aura beaucoup de disques locaux, quelque part il y aura peu de RAM, et ainsi de suite, c'est-à-dire qu'avec différents types de tâches, l'utilisation des ressources diminuera.
Il s'est avéré que vous payez 10 à 15% de plus pour la facilité d'installation. Cela a provoqué le mythe titre. Nous avons longtemps cherché où la technologie sera appliquée de manière optimale et l'avons trouvée. Le fait est que Tsiska n'avait pas ses propres systèmes de stockage, mais ils voulaient un marché de serveurs complet. Et ils ont fait Cisco Hyperflex, une solution de stockage local sur les nœuds.
Et cela s'est avéré soudain être une très bonne solution pour les centres de données de sauvegarde (Disaster Recovery). Pourquoi et comment - maintenant je vais le dire. Et je vais montrer des tests de cluster.
Où aller
L'hyper convergence est:
- Transférez des disques vers des nœuds de calcul.
- Intégration complète du sous-système de stockage avec le sous-système de virtualisation.
- Transfert / intégration avec le sous-système réseau.
Une telle combinaison vous permet de mettre en œuvre de nombreuses fonctionnalités des systèmes de stockage au niveau de la virtualisation et le tout à partir d'une seule fenêtre de contrôle.
Dans notre entreprise, les projets de conception de centres de données de sauvegarde sont très demandés, et c'est souvent la solution hyperconvergée qui est choisie en raison de la multitude d'options de réplication (jusqu'au cluster de métro) prêtes à l'emploi.
Dans le cas des datacenters de sauvegarde, il s'agit généralement d'une installation distante sur un site de l'autre côté de la ville ou dans une autre ville en général. Il vous permet de restaurer des systèmes critiques en cas de panne partielle ou totale du datacenter principal. Les données de vente y sont constamment répliquées, et cette réplication peut se faire au niveau de l'application ou au niveau du périphérique de bloc (SHD).
Alors maintenant, je vais parler de l'appareil et des tests du système, puis de quelques scénarios réels avec des données sur les économies.
Les tests
Notre copie se compose de quatre serveurs, chacun ayant 10 disques SSD par 960 Go. Il existe un disque dédié pour la mise en cache des opérations d'écriture et le stockage de la machine virtuelle de service. La solution elle-même est la quatrième version. Le premier est franchement brut (à en juger par les critiques), le second est humide, le troisième est déjà assez stable, et celui-ci peut être appelé une version après la fin des tests bêta pour le grand public. Lors du test des problèmes que je n'ai pas vus, tout fonctionne comme une horloge.
Changements dans la v4Correction d'un tas de bugs.
Initialement, la plate-forme ne pouvait fonctionner qu'avec l'hyperviseur VMware ESXi et supportait un petit nombre de nœuds. De plus, le processus de déploiement ne s'est pas toujours terminé avec succès, j'ai dû redémarrer certaines étapes, il y avait des problèmes de mise à jour à partir des anciennes versions, les données dans l'interface graphique n'étaient pas toujours affichées correctement (même si je ne suis toujours pas satisfait de l'affichage des graphiques de performances), parfois il y avait des problèmes à l'interface avec la virtualisation .
Maintenant, toutes les plaies des enfants ont été corrigées, HyperFlex peut faire à la fois ESXi et Hyper-V, plus c'est possible:
- Création d'un cluster étiré.
- Création d'un cluster pour les bureaux sans utiliser Fabric Interconnect, de deux à quatre nœuds (nous n'achetons que des serveurs).
- Capacité à travailler avec un stockage externe.
- Prise en charge des conteneurs et Kubernetes.
- Création de zones d'accessibilité.
- Intégration avec VMware SRM, si la fonctionnalité intégrée ne convient pas.
L'architecture n'est pas très différente des décisions des principaux concurrents, ils n'ont pas commencé à créer un vélo. Tout fonctionne sur la plate-forme de virtualisation VMware ou Hyper-V. Matériel hébergé sur des serveurs propriétaires Cisco UCS. Il y a ceux qui détestent la plate-forme pour la complexité relative de la configuration initiale, de nombreux boutons, un système non trivial de modèles et de dépendances, mais il y a aussi ceux qui ont appris le Zen, ont été inspirés par l'idée et ne veulent plus travailler avec d'autres serveurs.
Nous considérerons la solution spécifiquement pour VMware, car la solution a été créée à l'origine pour elle et a plus de fonctionnalités, Hyper-V a été ajouté en cours de route pour rester en phase avec les concurrents et répondre aux attentes du marché.
Il y a un cluster de serveurs plein de disques. Il existe des disques pour le stockage des données (SSD ou HDD - à votre goût et vos besoins), il y a un disque SSD pour la mise en cache. Lorsque des données sont écrites dans le magasin de données, les données sont enregistrées sur la couche de mise en cache (disque SSD dédié et RAM de la VM de service). En parallèle, le bloc de données est envoyé aux nœuds du cluster (le nombre de nœuds dépend du facteur de réplication du cluster). Après confirmation de la réussite de l'enregistrement par tous les nœuds, la confirmation de l'enregistrement est envoyée à l'hyperviseur puis à la machine virtuelle. Les données enregistrées en arrière-plan sont dédupliquées, compressées et écrites sur des disques de stockage. Dans le même temps, un gros bloc est toujours écrit sur les disques de stockage et séquentiellement, ce qui réduit la charge sur les disques de stockage.
La déduplication et la compression sont toujours activées et ne peuvent pas être désactivées. Les données sont lues directement à partir des disques de stockage ou du cache RAM. Si une configuration hybride est utilisée, la lecture est également mise en cache sur le SSD.
Les données ne sont pas liées à l'emplacement actuel de la machine virtuelle et sont réparties uniformément entre les nœuds. Cette approche vous permet de charger également tous les lecteurs et interfaces réseau. L'inconvénient évident: nous ne pouvons pas minimiser le délai de lecture, car il n'y a aucune garantie de disponibilité des données localement. Mais je crois que c'est un sacrifice insignifiant par rapport aux avantages reçus. De plus, les retards du réseau ont atteint des valeurs telles qu'ils n'affectent pratiquement pas le résultat global.
Pour toute la logique du sous-système de disque, une machine virtuelle de service spéciale du contrôleur Cisco HyperFlex Data Platform est responsable, qui est créée sur chaque nœud de stockage. Dans notre configuration de VM de service, huit vCPU et 72 Go de RAM ont été alloués, ce qui n'est pas si petit. Permettez-moi de vous rappeler que l'hôte lui-même possède 28 cœurs physiques et 512 Go de RAM.
La machine virtuelle de service a directement accès aux disques physiques en transmettant le contrôleur SAS à la machine virtuelle. La communication avec l'hyperviseur se fait via un module IOVisor spécial, qui intercepte les opérations d'E / S et utilise un agent qui vous permet de transférer des commandes vers l'API de l'hyperviseur. L'agent est chargé de travailler avec les instantanés et les clones HyperFlex.
Dans l'hyperviseur, les ressources disque sont montées comme une boule NFS ou SMB (selon le type d'hyperviseur, devinez lequel). Et sous le capot, il s'agit d'un système de fichiers distribué qui vous permet d'ajouter des fonctionnalités des systèmes de stockage à part entière pour adultes: allocation de volume léger, compression et déduplication, instantanés utilisant la technologie de redirection sur écriture, réplication synchrone / asynchrone.
Service VM donne accès à l'interface WEB de la gestion du sous-système HyperFlex. Il existe une intégration avec vCenter, et la plupart des tâches quotidiennes peuvent être effectuées à partir de celui-ci, mais les banques de données, par exemple, sont plus pratiques à couper à partir d'une webcam distincte si vous êtes déjà passé à une interface HTML5 rapide, ou utilisez un client Flash complet avec une intégration complète. Dans la webcam de service, vous pouvez voir les performances et l'état détaillé du système.
Il existe un autre type de nœud dans un cluster: les nœuds de calcul. Il peut s'agir de serveurs en rack ou en lame sans disques intégrés. Sur ces serveurs, vous pouvez exécuter des machines virtuelles dont les données sont stockées sur des serveurs avec des disques. Du point de vue de l'accès aux données, il n'y a pas de différence entre les types de nœuds, car l'architecture implique l'abstraction de l'emplacement physique des données. Le rapport maximal entre les nœuds de calcul et les nœuds de stockage est de 2: 1.
L'utilisation de nœuds de calcul augmente la flexibilité lors de la mise à l'échelle des ressources de cluster: nous n'avons pas besoin d'acheter des nœuds avec des disques si nous n'avons besoin que de CPU / RAM. De plus, nous pouvons ajouter un panier de lames et économiser de l'espace sur le serveur rack.
En conséquence, nous avons une plateforme hyperconvergée avec les fonctionnalités suivantes:
- Jusqu'à 64 nœuds dans un cluster (jusqu'à 32 nœuds de stockage).
- Le nombre minimum de nœuds dans un cluster est de trois (deux pour un cluster Edge).
- Mécanisme de redondance des données: mise en miroir avec les facteurs de réplication 2 et 3.
- Cluster Metro.
- Réplication de machine virtuelle asynchrone vers un autre cluster HyperFlex.
- Orchestration de la commutation des machines virtuelles vers un centre de données distant.
- Instantanés natifs utilisant la technologie de redirection sur écriture.
- Jusqu'à 1 PB d'espace utilisable avec facteur de réplication 3 et sans déduplication. Nous ne prenons pas en compte le facteur de réplication 2, car ce n'est pas une option pour une vente sérieuse.
Un autre énorme avantage est la facilité de gestion et de déploiement. Toutes les complexités de la configuration des serveurs UCS sont gérées par une machine virtuelle spécialisée préparée par les ingénieurs Cisco.
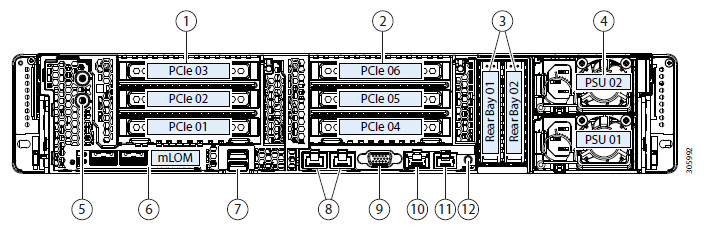
Configuration du banc d'essai:
- 2 x Cisco UCS Fabric Interconnect 6248UP en tant que cluster de gestion et composants réseau (48 ports fonctionnant en mode Ethernet 10G / FC 16G).
- Quatre serveurs Cisco UCS HXAF240 M4.
Caractéristiques du serveur:
Plus d'options de configurationEn plus du fer sélectionné, les options suivantes sont actuellement disponibles:
- HXAF240c M5.
- Un ou deux processeurs allant d'Intel Silver 4110 à Intel Platinum I8260Y. La deuxième génération est disponible.
- 24 emplacements mémoire, lattes de 16 Go RDIMM 2600 à 128 Go LRDIMM 2933.
- De 6 à 23 disques pour les données, un disque de mise en cache, un système et un disque de démarrage.
Lecteurs de capacité- HX-SD960G61X-EV 960 Go 2,5 pouces SSD Enterprise Value 6G SATA (1X endurance) SAS 960 Go.
- HX-SD38T61X-EV 3,8 To 2,5 pouces Enterprise Value 6G SATA SSD (1X endurance) SAS 3.8 TB.
- Mise en cache des pilotes
- HX-NVMEXPB-I375 Disque Intel Optane 2,5 pouces 375 Go 2,5 pouces, performances et endurance extrêmes.
- HX-NVMEHW-H1600 * 1,6 To 2,5 pouces Ent. Perf NVMe SSD (3X endurance) NVMe 1,6 To.
- HX-SD400G12TX-EP 400 Go 2,5 pouces Ent. Perf SSD SAS 12G (endurance 10X) SAS 400 Go.
- HX-SD800GBENK9 ** 800 Go 2,5 pouces Ent. Perf SSD SAS SED 12G (endurance 10X) SAS 800 Go.
- HX-SD16T123X-EP 1,6 To 2,5 pouces SSD Enterprise Performance 12G SAS (3X endurance).
Lecteurs système / journaux- SSD HX-SD240GM1X-EV 240 Go 2,5 pouces Enterprise Value 6G SATA (Nécessite une mise à niveau).
Pilotes de démarrage- HX-M2-240 Go 240 Go SATA M.2 SSD SATA 240 Go.
Connexion à un réseau sur des ports Ethernet 40G, 25G ou 10G.
Comme FI peut être HX-FI-6332 (40G), HX-FI-6332-16UP (40G), HX-FI-6454 (40G / 100G).
Se tester
Pour tester le sous-système de disque, j'ai utilisé HCIBench 2.2.1. Il s'agit d'un utilitaire gratuit qui vous permet d'automatiser la création de charge à partir de plusieurs machines virtuelles. La charge elle-même est générée par fio ordinaire.
Notre cluster se compose de quatre nœuds, facteur de réplication 3, tous les lecteurs Flash.
Pour les tests, j'ai créé quatre banques de données et huit machines virtuelles. Pour les tests d'écriture, il est supposé que le disque de mise en cache n'est pas plein.
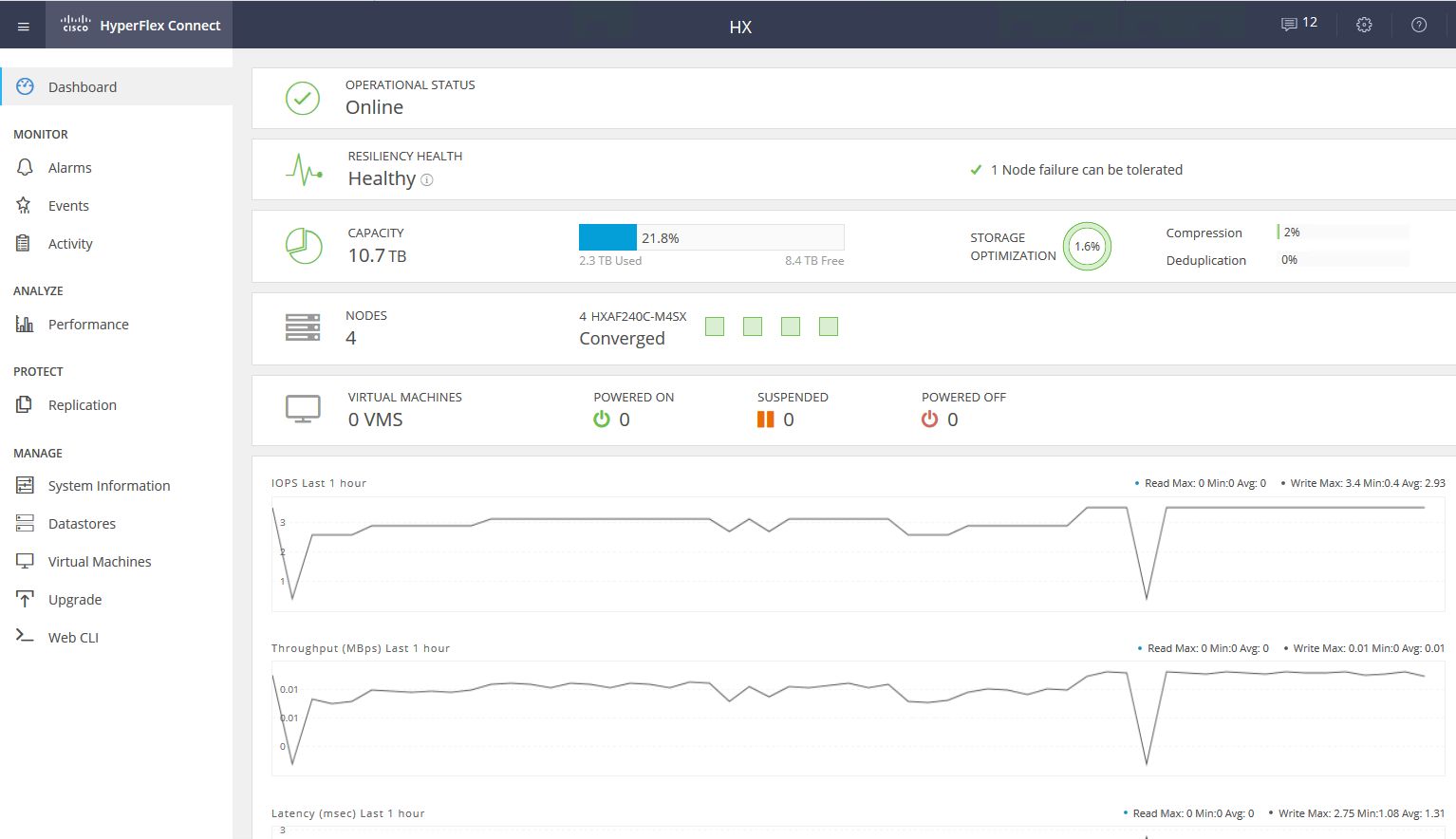
Les résultats des tests sont les suivants:
Des valeurs en gras sont indiquées, après quoi il n'y a pas d'augmentation de la productivité, parfois même une dégradation est visible. En raison du fait que nous nous reposons sur les performances du réseau / contrôleurs / lecteurs.- Lecture séquentielle 4432 Mo / s.
- Écriture séquentielle 804 Mo / s.
- Si un contrôleur tombe en panne (échec de la machine virtuelle ou de l'hôte), le rabattement des performances est doublé.
- Si le lecteur de stockage tombe en panne, le rabattement est de 1/3. Le disque de reconstruction nécessite 5% des ressources de chaque contrôleur.
Sur un petit bloc, nous rencontrons les performances du contrôleur (machine virtuelle), son CPU est chargé à 100%, tout en augmentant le bloc que nous exécutons sur la bande passante du port. 10 Gbps ne suffisent pas pour libérer le potentiel du système AllFlash. Malheureusement, les paramètres du support de démonstration fourni ne permettent pas de vérifier le travail à 40 Gb / s.
Dans mon impression des tests et de l'étude de l'architecture, en raison de l'algorithme qui place les données entre tous les hôtes, nous obtenons des performances prévisibles évolutives, mais c'est aussi une limitation lors de la lecture, car il serait possible de presser davantage sur les disques locaux et plus, ici pour économiser un réseau plus productif, par exemple, des IF à 40 Gbit / s sont disponibles.
En outre, un disque pour la mise en cache et la déduplication peut être une limitation; en fait, dans ce stand, nous pouvons écrire sur quatre disques SSD. Ce serait formidable de pouvoir augmenter le nombre de disques mis en cache et voir la différence.
Utilisation réelle
Deux approches peuvent être utilisées pour organiser un centre de données de sauvegarde (nous n'envisageons pas de placer la sauvegarde sur un site distant):
- Passif actif Toutes les applications sont hébergées dans le centre de données principal. La réplication est synchrone ou asynchrone. En cas de chute du centre de données principal, nous devons activer celui de sauvegarde. Cela peut être fait manuellement / applications de scripts / orchestration. Ici, nous obtenons un RPO proportionnel à la fréquence de réplication, et le RTO dépend de la réaction et des compétences de l'administrateur et de la qualité du développement / débogage du plan de commutation.
- Actif Actif Dans ce cas, seule la réplication synchrone est présente, la disponibilité des centres de données est déterminée par un quorum / arbitre, placé strictement sur la troisième plateforme. RPO = 0 et RTO peut atteindre 0 (si l'application le permet) ou égal au temps de basculement sur un nœud dans un cluster de virtualisation. Au niveau de la virtualisation, un cluster étendu (Metro) est créé qui nécessite un stockage actif-actif.
Habituellement, nous voyons avec les clients une architecture déjà mise en œuvre avec un stockage classique dans le centre de données principal, nous en concevons donc une autre pour la réplication. Comme je l'ai mentionné, Cisco HyperFlex offre une réplication asynchrone et la création d'un cluster de virtualisation étendu. Dans le même temps, nous n'avons pas besoin d'un système de stockage de milieu de gamme ou supérieur dédié avec les fonctions coûteuses de réplication et d'accès aux données Active-Active sur deux systèmes de stockage.
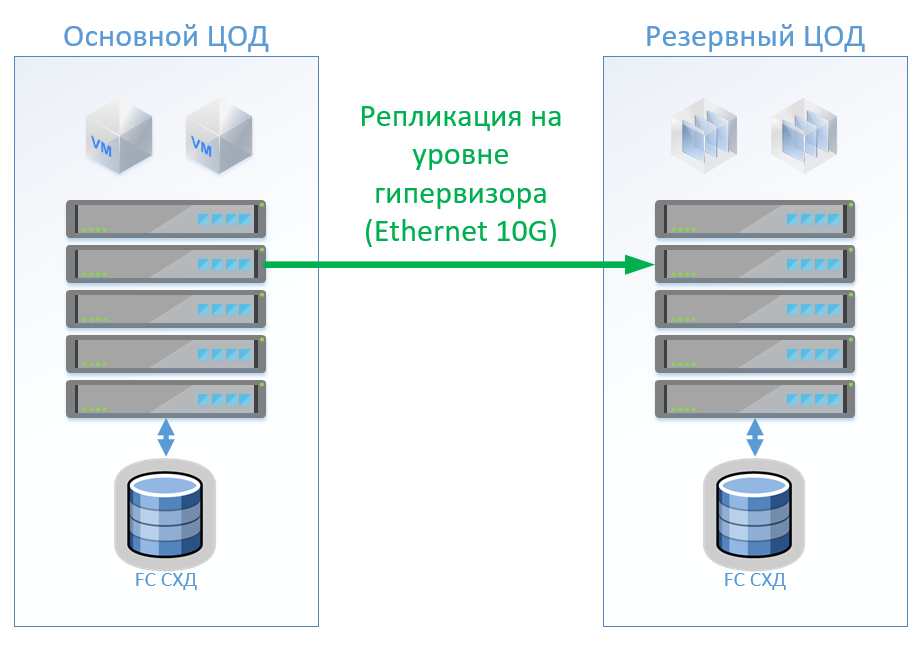
Scénario 1: Nous avons des centres de données principaux et de sauvegarde, une plate-forme de virtualisation sur VMware vSphere. Tous les systèmes productifs sont situés principalement dans le centre de données et la réplication des machines virtuelles est effectuée au niveau de l'hyperviseur, ce qui permettra de ne pas garder les machines virtuelles sous tension dans le centre de données de sauvegarde. Nous répliquons les bases de données et les applications spéciales avec des outils intégrés et gardons les VM sous tension. Si le centre de données principal tombe en panne, nous démarrons le système dans le centre de données de sauvegarde. Nous pensons que nous avons environ 100 machines virtuelles. Tant que le centre de données principal fonctionne, des environnements de test et d'autres systèmes peuvent être lancés dans le centre de données de sauvegarde, qui peut être désactivé si le centre de données principal est commuté. Il est également possible que nous utilisions la réplication bidirectionnelle. Du point de vue des équipements, rien ne changera.
Dans le cas d'une architecture classique, nous mettrons un système de stockage hybride dans chaque centre de données avec accès via FibreChannel, déchirement, déduplication et compression (mais pas en ligne), 8 serveurs par site, 2 commutateurs FibreChannel et Ethernet 10G. Pour la réplication et le contrôle de commutation dans une architecture classique, nous pouvons utiliser des outils VMware (Réplication + SRM) ou des outils tiers qui seront légèrement moins chers et parfois plus pratiques.
La figure montre un diagramme.
Si vous utilisez Cisco HyperFlex, vous obtenez l'architecture suivante:
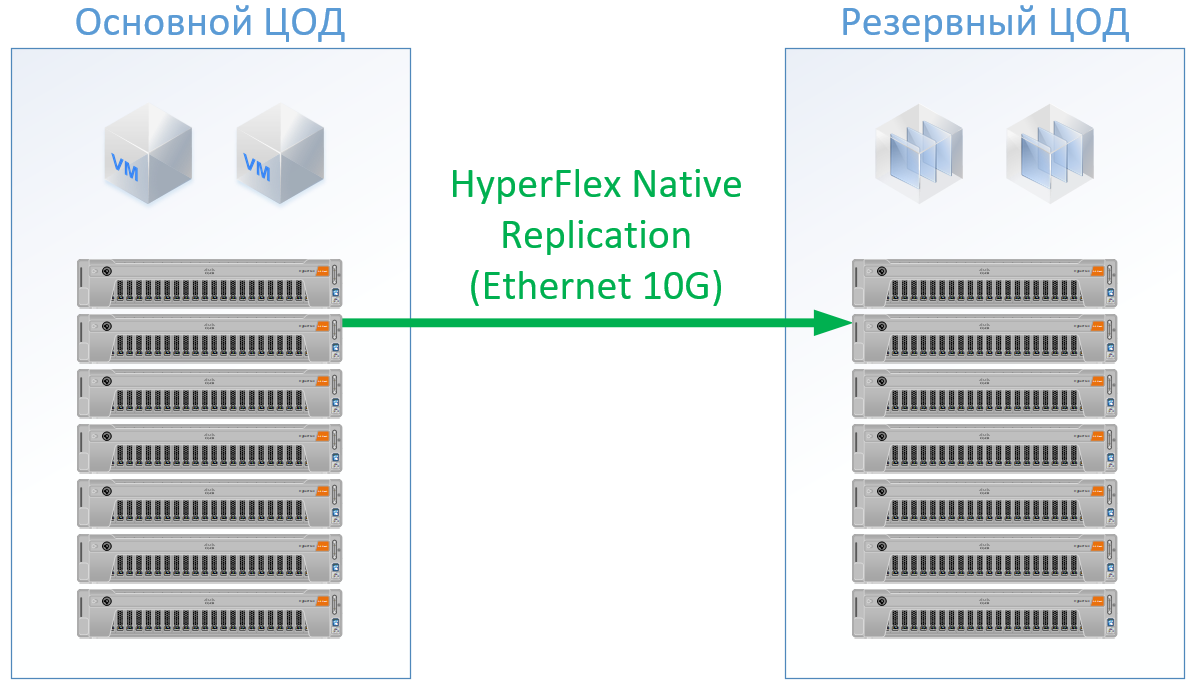
Pour HyperFlex, j'ai utilisé des serveurs avec de grandes ressources CPU / RAM, comme une partie des ressources ira à la machine virtuelle du contrôleur HyperFlex, j'ai même rechargé un peu la configuration HyperFlex sur le processeur et la mémoire afin de ne pas jouer avec Cisco et garantir des ressources pour le reste des machines virtuelles. Mais nous pouvons refuser des commutateurs FibreChannel, et nous n'avons pas besoin de ports Ethernet pour chaque serveur, le trafic local est commuté à l'intérieur de FI.
Le résultat est la configuration suivante pour chaque centre de données:
Pour Hyperflex, je n'ai pas promis de licences de logiciel de réplication, car cela est disponible dès le départ avec nous.
Pour l'architecture classique, j'ai pris un vendeur qui s'est imposé comme un fabricant de qualité et peu coûteux. Pour les deux options, j'ai utilisé un standard pour un skid de solution spécifique, à la sortie, j'ai obtenu des prix réels.
La solution sur Cisco HyperFlex était 13% moins chère.
Scénario 2: création de deux centres de données actifs. Dans ce scénario, nous concevons un cluster étendu sur VMware.
L'architecture classique se compose de serveurs de virtualisation, d'un SAN (protocole FC) et de deux systèmes de stockage qui peuvent lire et écrire sur celui qui les sépare. Sur chaque SHD, nous fixons une capacité utile pour la serrure.
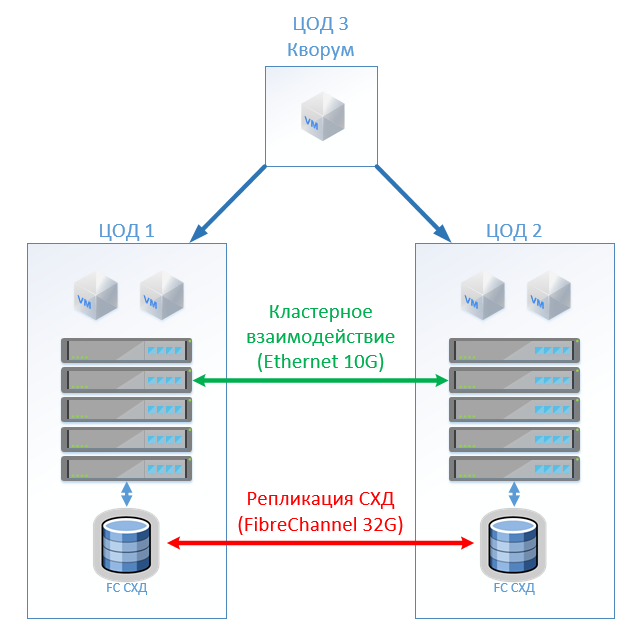
Chez HyperFlex, nous créons simplement un Stretch Cluster avec le même nombre de nœuds sur les deux sites. Dans ce cas, le facteur de réplication 2 + 2 est utilisé.
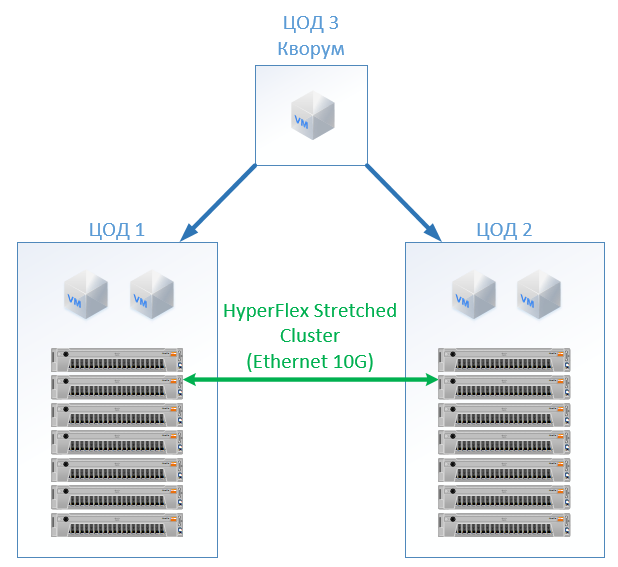
La configuration suivante s'est avérée:
Dans tous les calculs, je n'ai pas pris en compte l'infrastructure réseau, les coûts du datacenter, etc.: ils seront les mêmes pour l'architecture classique et pour la solution HyperFlex.
Au prix coûtant, HyperFlex s'est avéré 5% plus cher. Il convient de noter ici que pour les ressources CPU / RAM, j'ai eu un biais pour Cisco, car dans la configuration, il remplissait les canaux des contrôleurs de mémoire de manière égale. , , , « », . , Cisco UCS .
SAN , - , (, , — ), ( ), .
, — Cisco. Cisco UCS, , HyperFlex , . , . : « , ?» « - , . !» — , : « » .
Les références