
Bonjour, Habr! Nous continuons à publier des critiques d'articles scientifiques de membres de la communauté Open Data Science sur la chaîne #article_essense. Si vous souhaitez les recevoir avant tout le monde - rejoignez la communauté !
Articles pour aujourd'hui:
- Équations différentielles ordinaires neuronales (Université de Toronto, 2018)
- Apprentissage semi-non supervisé avec des modèles génératifs profonds: regroupement et classification à l'aide d'étiquettes ultra-clairsemées (Université d'Oxford, The Alan Turing Institute, Londres, 2019)
- Découvrir et atténuer les biais algorithmiques grâce à la structure latente apprise (Massachusetts Institute of Technology, Harvard University, 2019)
- Apprentissage par renforcement profond des préférences humaines (OpenAI, DeepMind, 2017)
- Explorer les réseaux de neurones câblés de manière aléatoire pour la reconnaissance d'images (Facebook AI Research, 2019)
- Photofeeler-D3: un réseau neuronal avec modélisation des électeurs pour la datation des photos (Photofeeler Inc., 2019)
- MixMatch: une approche holistique de l'apprentissage semi-supervisé (Google Reasearch, 2019)
- Diviser et conquérir l'espace d'intégration pour l'apprentissage métrique (Heidelberg University, 2019)
Liens vers les anciennes collections de la série: 1. Équations différentielles ordinaires neuronales
Auteurs: Ricky TQ Chen, Yulia Rubanova, Jesse Bettencourt, David Duvenaud (Université de Toronto, 2018)
→ Article original
L'auteur de la revue: George Ignatov (in slack a2dy2n7okhtp)
Prix NIPS du meilleur article

Les auteurs de l'article ont noté que les réseaux de type ResNet sont très similaires à la méthode d'Euler pour résoudre les équations différentielles. Si oui, alors pourquoi ne pas amener immédiatement l'idée au maximum: imaginez un réseau neuronal sous la forme d'une équation différentielle et obtenez
- Un réseau avec un nombre arbitraire de couches, qui peut être modifié à tout moment pendant la formation et l'inférence. Plus de couches -> plus de précision et des conversions plus fluides (et vice versa).
- Un nombre beaucoup plus petit de paramètres réduit donc les coûts de mémoire.
NODE par analogies:
- - voici à quoi ressemble la définition de la sortie de la couche n dans un réseau de type resnet, W - paramètres.
- - cela ressemblerait à un réseau de type NODE, à condition que n soit une quantité discrète.
- , - Méthode d'Euler.
- - ta-da! Réseau neuronal alimenté par ODE.
Nous le résolvons avec n'importe quel ODEsolver à boîte noire, jetons les gradients en utilisant la méthode de sensibilité adjointe (Pontryagin et al., 1962). En raison de sa différenciation complète, NODE peut être combiné avec des réseaux de neurones conventionnels. Les auteurs ont affiché le code sur pytorch.
L'article traite de 3 applications:
- Comparaison avec une architecture de type ResNet (sur MNIST). NODE ne fonctionne presque pas pire, tout en utilisant 3 fois moins de paramètres.
- Remplacement des flux normalisés via NODE - Flux normalisés continus (jeu de données synthétique). Le nouveau modèle réduit les coûts de calcul de O (n_hidden_units ^ 3) à linéaire.
- Modélisation d'événements temporaires avec observations irrégulières (jeu de données synthétique). Un ensemble de données de trajectoires en spirale a été généré à partir duquel des points échantillonnés au hasard ont été saupoudrés de: sel: bruit gaussien pour la plausibilité. Il a testé les RNN et NODE habituels, et le second s'est à nouveau révélé meilleur.
En petits caractères:
- La formation sur les mini-lots entraîne une sorte de surcharge de calcul, mais les auteurs affirment qu'en pratique, cela est presque invisible.
- Deux nouveaux hyperparamètres apparaissent: la profondeur du réseau et la tolérance aux erreurs lors de la résolution de l'ODE.
- Pour que la solution ODE reste unique, le réseau doit avoir des poids finis et utiliser des non-linéarités Lipshitz, telles que tanh ou relu.
Lien vers un aperçu plus détaillé de habr.
2. Apprentissage semi-non supervisé avec des modèles génératifs profonds: regroupement et classification à l'aide d'étiquettes ultra-clairsemées
Auteurs de l'article: Matthew Willetts, Stephen Roberts et Christopher Holmes
(Université d'Oxford, The Alan Turing Institute, Londres, 2019)
→ Article original
Auteur de la revue: Alex Chiron (dans sliron shiron8bit)
Les auteurs considèrent un cas semi-non supervisé pour le problème de classification, lorsqu'une partie des classes présentes dans le balisage en raison d'un biais de sélection n'était pas du tout étiquetée, et pas beaucoup étaient étiquetées selon des classes de données connues. Cela crée des problèmes supplémentaires, car la plupart des modèles fonctionnent généralement en mode semi-supervisé / supervisé (classification) ou en mode non supervisé (clustering), et dans ce cas, nous devons considérer les deux options. De plus, l'utilisation d'algorithmes semi-supervisés peut conduire au fait que les données non allouées seront attribuées selon une métrique de proximité à des classes incorrectes. Un exemple hypothétique de telles données est un ensemble d'analyses de tumeurs. Nous avons pris une partie des données et marqué tous les types de tumeurs présentes sur cette partie, mais il s'est avéré que d'autres types de tumeurs étaient présents dans les données restantes, et la variabilité des espèces connues dans le balisage n'était pas entièrement reflétée.
Les auteurs se sont inspirés de modèles génératifs profonds (l'exemple le plus simple d'un tel modèle avec une seule couche de profondeur de variables cachées est un auto-encodeur variationnel, alias VAE): dans les travaux précédents, ces modèles ont réussi à gérer à la fois le cas semi-supervisé (M2, ADGM) et le clustering ( VaDE, GM-VAE).
Pourquoi ne pas résoudre 2 problèmes en même temps (apprentissage semi-supervisé sur des classes rarement balisées et non supervisé sur des classes non placées), garder en commun l'espace des variables latentes apprises et combiner les idées des modèles ci-dessus? C'est cette idée qui sous-tend les modèles GM-DGM / AGM-DGM proposés dans l'article.
Considérons le modèle M2 dans un cas semi-supervisé. Il est appelé ainsi, car sous M1, le créateur a impliqué un apprentissage séquentiel de VAE et un classificateur (svm) pour les représentations latentes résultantes de z, mais M2 est déjà obtenu à partir de VAE en ajoutant à la couche de variables cachées la variable y, qui est responsable de la classe parfois observée.
,
où ,
Ici q est un encodeur, p est un décodeur, partie - classificateur directement formé.
Pour le cas non supervisé / semi-non supervisé, M2 ne fonctionne pas - un effondrement postérieur se produit, la partie de classification q_phi (y | x) s'effondre à la distribution a priori p (y). L'auteur de GM-VAE dans son article a également montré l'inopérabilité de M2 dans la pratique et a noté que souvent lors de la mise en œuvre de M2, la première couche du décodeur h1 est très similaire à un mélange de gaussiens.
Sur la base de cette observation, GM-VAE utilise une couche explicite de variables cachées pour regrouper un mélange gaussien pour le regroupement, qui est également répété par les auteurs de cet article. Ainsi, le modèle GM-DGM, qui permet un fonctionnement réussi en mode semi-non supervisé, est une modification VAE utilisant un mélange de Gaussiens dans une couche cachée, en fonction d'une variable de classe y, avec la fonction ci-dessus de deux termes pour compter et maximiser ELBO.
Les auteurs de l'article ont mené une expérience sur une version semi-non supervisée de Fashion-MNIST: ils ont retiré les étiquettes des 5 premières classes, les 5 classes restantes ont laissé 5% des étiquettes, alors qu'elles ont reçu une précision totale de 77,2% contre 53% pour M2. La possibilité d'utiliser le modèle pour le clustering a également été montrée (ce qui n'est pas surprenant, car il s'agit presque de GM-VAE).
3. Découvrir et atténuer les biais algorithmiques grâce à la structure latente apprise
Auteurs: Alexander Amini, Ava Soleimany, Wilko Schwarting, Sangeeta N.Bhatia, Daniela Rus (Massachusetts Institute of Technology, Harvard University, 2019)
→ Article original
Auteur de la revue: Alex Chiron (dans sliron shiron8bit)
Récemment, de plus en plus souvent dans les médias, vous pouvez trouver des nouvelles qui touchent au sujet du biais dans les données, en particulier concernant les algorithmes liés aux individus - avec la croissance de leur applicabilité, le risque d'un fort impact négatif sur les catégories et les groupes de personnes qui sont insuffisants (ou excessifs) présenté dans l'ensemble de données. L'un des derniers exemples est une étude qui a montré moins de précision dans la détection des piétons à la peau foncée (dans le contexte de la détection d'objets sur les jeux de données BDD100K et MSCOCO standard, lien ). Approches de base pour éliminer les biais:
- Équilibrage des classes par rééchantillonnage (nécessite une compréhension a priori de la structure de données cachée).
- Génération de données non biaisées (par exemple, l'utilisation du GAN pour générer des individus avec une grande variété de tons de peau ).
- Regroupement et rééchantillonnage ultérieur.
- Vous pouvez toujours attendre que le jeu de données IBM Diversity in Faces soit présenté aux académiciens.
Les auteurs de l'article proposent une modification de la VAE et de l'échantillonnage, en tenant compte de la distribution de la variable latente z, ce qui peut réduire l'influence du biais dans les données au stade de la formation.
Ainsi, les principales idées derrière DB-VAE sont:
- Considérons un problème de classification dans lequel nous avons un ensemble de données d'apprentissage {(x, y)}, x sont des entités à m dimensions, y sont des étiquettes à d dimensions et notre tâche consiste à approximer la cartographie X-> Y.
- Prenez VAE, mais en plus du vecteur z des variables cachées z de la dimension 2k, nous forcerons le codeur (je me souviens de 2 ici parce que nous avons affaire à des moyennes et des variances) à apprendre également un vecteur de dimension d, qui est responsable des étiquettes susmentionnées. Dans ce cas, le décodeur n'accepte que le vecteur z en entrée. Ainsi, nous obtenons un semblant d'apprentissage semi-supervisé, où une partie du modèle est apprise pour reconstruire l'entrée, et une partie pour résoudre un problème spécifique (classification).
- Nous contrôlons la formation du modèle due à la perte combinée, combinant la norme pour la perte VAE (reconstruction + divergence KL) et la perte pour une tâche auxiliaire (par exemple, l'entropie croisée pour le problème de classification binaire).
- Une attention particulière est accordée au fait que vous devez contrôler la formation sur les données que vous ne voulez pas débiaser (c'est-à-dire, ne pas les rétroporter à partir du décodeur).
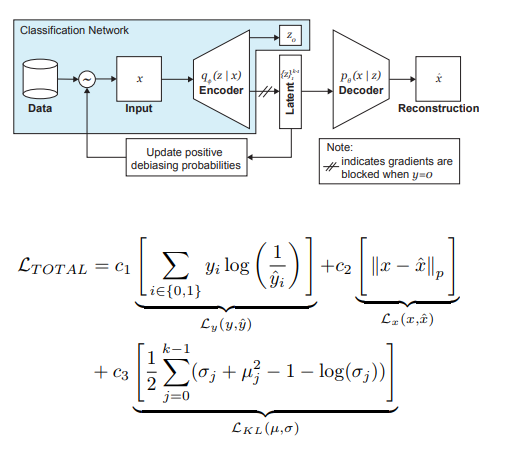
Le rôle le plus important dans l'élimination de la douleur des noirs est joué par l'échantillonnage adaptatif au stade de la formation. Nous voulons choisir des échantillons rares (du point de vue de certains facteurs cachés, non explicitement identifiés), nous nous tournons donc vers les histogrammes pour chaque dimension de l'espace des variables cachées z, dont le produit peut approximer la distribution Q (z | X) des données sur tout l'espace Z. Lors de la formation d'un nouveau lot, nous prendrons en compte la distribution `` inverse '' de Q (z | X) W (z (x) | X), qui détermine la probabilité de choisir un exemple dans le lot (alpha est un hyperparamètre qui détermine le degré de débiasing), en mettant à jour Q (z | X) à chaque époque. Comme vous pouvez le voir, le débiasing n'est pas présélectionné, mais plutôt basé sur les variables latentes apprises.
À titre expérimental, les auteurs ont résolu le problème de la classification binaire (trouver le visage sur la photo). Pour la formation, nous avons collecté un ensemble de données, qui comprenait 200 000 personnes avec CelebA et 200 000 non-personnes avec Imagenet, a redimensionné les images en 64 x 64. Comme mentionné précédemment, lors de la formation, la rétropropagation du décodeur pour les photos sans visages a été bloquée (y = 0). Après la formation, ils ont été validés sur le benchmark des parlements pilotes (PPB) (1270 photos de personnes des parlements d'Afrique du Sud, du Rwanda, du Sénégal, de la Suède, de la Finlande, de l'Islande): pour tous les alpha> 0, la précision de détection dans les catégories mâle foncé, femelle sombre, femelle claire a augmenté par rapport à option sans debiasing.
4. Apprentissage par renforcement profond des préférences humaines
Auteurs: Paul Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, Dario Amodei (OpenAI, DeepMind, 2017)
→ Article original
Auteur de la revue: Dmitry Nikulin (in dniku slack)
Cet article explique comment mettre en œuvre l'ancienne idée dans le contexte de l'apprentissage par renforcement profond (RL). Idée: demandons à une personne d'évaluer le comportement d'un agent, et sur cette base, nous apprendrons la fonction de récompense. Le problème est que le RL profond est très vorace et que le temps humain coûte cher. L'article fournit un ensemble de hacks qui vous permettent de réduire les heures humaines à des valeurs raisonnables.
La fonction de récompense est une fonction sur des paires (observation, action). Il est établi en faisant la moyenne de la prédiction d'un ensemble de réseaux de neurones. Les algorithmes RL utilisés (dans l'article A2C pour Atari et TRPO pour Mujoco) croient que cette moyenne est une vraie récompense, et sont formés sur elle. Ainsi, l'article se concentre sur la question de la formation de cet ensemble.
L'ensemble est formé aux évaluations humaines. Chaque notation est structurée comme suit. On montre à une personne deux vidéos d'un agent d'une à deux secondes. Il peut évaluer une telle paire de 4 façons: la gauche est meilleure / la droite est meilleure / trop similaire / incomparable. Si une personne a dit "incomparable", alors une telle évaluation est jetée. Sinon, le triple (σ¹, σ², μ) est mémorisé, où σⁱ est la trajectoire de l'agent dans la vidéo correspondante (c'est-à-dire la liste des paires (obs, act)), et μ est la paire (1, 0), (0, 1 ) ou (½, ½). De plus, on pense que la prédiction de la récompense pour la trajectoire est égale à la somme des prédictions pour chaque paire (obs, act). Enfin, nous optimisons simplement softmax_cross_entropy_with_logits.
On pense qu'une personne avec une probabilité de 10% sélectionne une réponse aléatoire, et cela est pris en compte lors de la construction d'un échantillon d'apprentissage. La section 2.2.3 de l'article donne quelques astuces supplémentaires et écrit toutes les formules.
Les paires de clips pour la démonstration à une personne sont sélectionnées comme suit: un grand nombre de clips sont échantillonnés, la dispersion de l'ensemble est prise en compte sur eux, et des paires aléatoires de clips à forte dispersion sont montrées aux personnes. Les auteurs disent que je voudrais choisir en fonction de la valeur de l'information, mais c'est un travail futur.
Les auteurs effectuent des tests sur Atari et Mujoco, avec des notations humaines réelles (sous-traitants) et synthétiques (les notations sont générées en fonction de la véritable fonction de récompense), et en même temps, elles sont comparées avec le RL habituel. Avec un nombre de notes approximativement égal, les tests synthétiques et réels fonctionnent de manière similaire. De plus, étonnamment, le RL régulier (qui voit la vraie fonction de récompense) ne fonctionne pas nécessairement mieux.
Enfin, en plus d'essayer de former l'agent pour obtenir beaucoup de récompenses au sens habituel, l'article donne également des exemples de deux autres tâches: la trémie de Mujoco effectue un backflip et la machine d'Atari Enduro ne dépasse pas les autres voitures, mais se déplace parallèlement à elles. Il s'est avéré résoudre les deux problèmes.
En conclusion: l' exemple décrit une tentative de reproduction de cet article. La tentative a été couronnée de succès, mais il a fallu 8 mois de travail en temps libre et 220 heures de temps pur, dont la moitié pour déboguer la version la plus simple.
5. Explorer les réseaux de neurones câblés de façon aléatoire pour la reconnaissance d'images
Auteurs: Saining Xie, Alexander Kirillov, Ross Girshick, Kaiming He (Facebook AI Research, 2019)
→ Article original
Auteur de la revue: Egor Panfilov (in slack tutk1ja)
Présentation:
Le travail pose la question de la génération d'architecture de réseaux de neurones. Actuellement, de nombreuses astuces architecturales sont connues (LSTM, Inception, ResNet, DenseNet), ce qui peut améliorer la qualité de nombreuses tâches, mais elles introduisent également une certaine forte architecture préalable dans le modèle. Au lieu des solutions mentionnées, Google va de l'avant avec sa recherche d'architecture neuronale (NAS), où la recherche d'architecture pour une tâche spécifique est effectuée à partir de modules prédéfinis via RL - NASNet, AmoebaNet.
Les auteurs soutiennent que les deux approches où la conception est déterminée par l'homme et le NAS introduisent trop strictes avant l'architecture. Pour tenter de le réduire, ils tentent d'utiliser l'approche générative paramétrique du réseau de neurones, où le câblage (connexion) des éléments est effectué de manière aléatoire. Il s'avère que des approches de câblage aléatoire ont été explorées depuis les années 1940 par des scientifiques tels que A. Turing, M. Minsky, F. Rosenblatt. Comme argument de plus, les auteurs rappellent que dans les études neuroscientifiques, il a été révélé que la structure des connexions neuronales dans les organismes d'une espèce est différente (jusqu'à un certain niveau de détail, bien sûr). Cela est vrai pour les vers et les bébés humains.En général, l'idée de la génération procédurale de réseaux de neurones semble intéressante et prometteuse, ce qui est le travail.
Méthode:
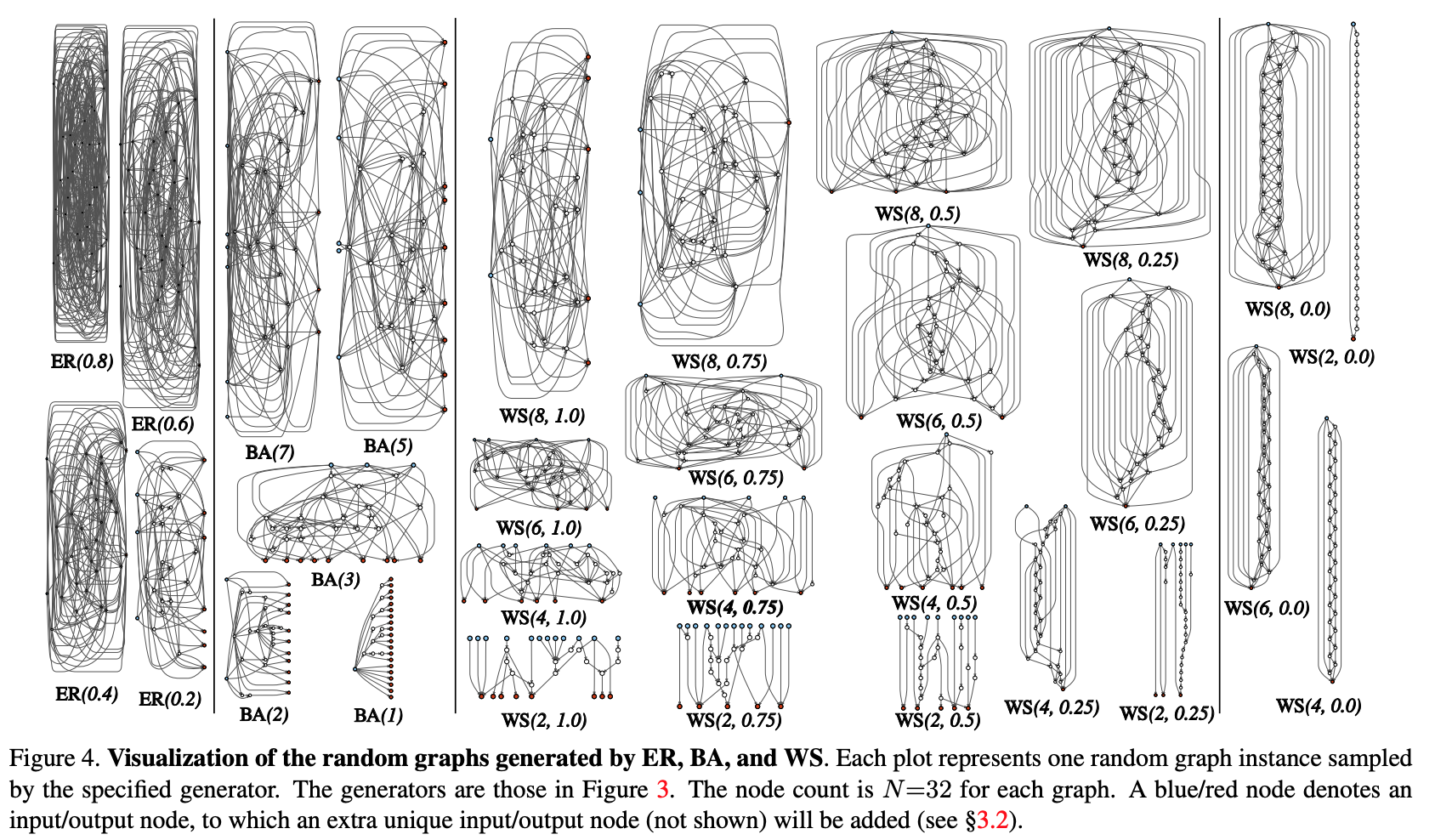
Essayons de modulariser le processus de génération procédurale de l'architecture de réseau neuronal à travers une approche graphique. Les étapes initiales sont les suivantes:
- Un graphe stochastique est généré à partir d'une famille paramétrée. Des méthodes classiques sont utilisées: Erdos-Renyi (ER), Barabasi-Albert (BA) et Watts-Strogatz (WS).
- Le graphique est converti en réseau neuronal:
- tous les bords du graphique sont supposés être des porteurs dirigés de tenseurs de données;
- pour chaque sommet du graphe, le type d'opération qu'il effectue est déterminé: (I) agrégation par sommation avec les poids entraînés, (II) transformation - ReLU + convolution + BN, (III) distribution - transfert du tenseur le long de chaque bord de sortie;
- selon les résultats du paragraphe précédent, il peut y avoir plusieurs sommets d'entrée et de sortie, mais je veux avoir 1 point d'entrée dans le graphique et 1 point de sortie. Ces nœuds sont créés séparément. L'entrée se propage simplement une copie du tenseur à tous les sommets d'entrée du graphique, la sortie considère la moyenne non pondérée de tous les sommets de sortie. En conséquence des étapes 1 et 2, en fait, aucun réseau complet n'est créé, mais un seul des modules (comme conv_1, ... dans les populaires codeurs convolutifs). Afin d'obtenir complètement le réseau neuronal:
- Plusieurs modules sont créés et connectés en série. Pour réduire le nombre de paramètres réseau, les transformations à tous les sommets d'entrée des modules sont effectuées avec une foulée de 2x2. Le nombre de canaux dans la transition vers le module suivant augmente de 2 fois. Pour effectuer des expériences sur une tâche spécifique:
- A la sortie du réseau, une tête est ajoutée pour le classement.
Résultats:
Des tests de la méthode ont été effectués sur le problème de classification sur ImageNet. La qualité du réseau neuronal généré s'est avérée être à égalité avec les architectures SotA, perdant un peu par rapport au récent DeepBrain AmoebaNet de Google: (avec un nombre comparable de paramètres).
Nous avons vérifié ce qui se passerait si nous supprimions un sommet / bord aléatoire du graphique résultant. Métrique - réduction de la qualité en fonction du nombre adjacent d'arêtes de sortie / sommets d'entrée, respectivement. En général, la qualité baisse, mais pas critique.
Les auteurs ont également vérifié si l'apprentissage par transfert fonctionne avec cette architecture. Dans la tâche de détection COCO, le backbone Faster R-CNN avec FPN a été remplacé par un réseau généré et pré-formé. Les résultats ont montré que la qualité du modèle n'est pas pire que celle de ResNeXt-50 / -101. Mais même le fait que l'apprentissage par transfert démarre est assez amusant.
6. Photofeeler-D3: un réseau neuronal avec modélisation des électeurs pour la datation des photos
Auteurs de l'article: Agastya Kalra et Ben Peterson (Photofeeler Inc., 2019)
→ Article original
Auteur de la revue: Alex Chiron (dans sliron shiron8bit)
Les auteurs suggèrent Photofeeler-D3: une architecture de réseau pour évaluer les photos de sites de rencontres dans 3 directions / traits - à quel point une personne semble intelligente, digne de confiance et attrayante (négligez l'effet de halo!). La tâche découle d'une enquête réalisée par The Guardian, selon laquelle 90% des personnes décident d'une date future uniquement sur la base de l'évaluation des photos d'un satellite potentiel
Ainsi, le réseau se compose des blocs suivants:
- ( ) — (GAP ), 10 ( ) — temporary output.
- ( , voter model) - (voter), , temporary output , , 10 v_ij (( 10 [0;1]). v_ij [0.05, 0.15, 0.25...0.95].
- , 200 , .
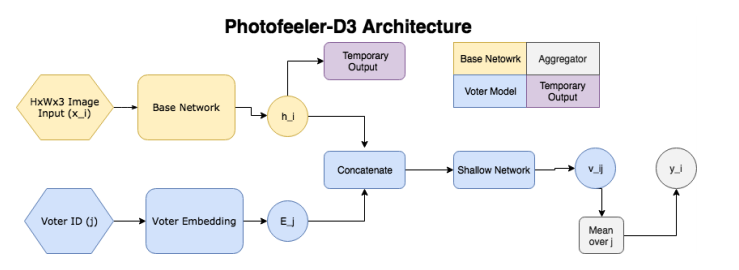
, , , , . Facial Beauty Prediction (FBP) SCUT-FBP Hot-Or-Not, , Photofeeler, . : +100k , 1.2 , (200 ) 200 (50 ). , 600px. 10000 8000 . , 0 3, [0,1] ( , ).
:
- (backbone , , etc) (20000 train, 3000 val, 2311 test), xception 600x600.
- , (temporary output) KL- ( , , 10 [0,1]).
- voter model one-hot .
- voter' , 2 .
- trait' 2 , .:
- ~80% , London Faces , prettyscale.com hotness.ai (81 53 52).
- FBP (SCUT-FBP Hot-Or-Not) , SOTA.
- , , 10
7. MixMatch: A Holistic Approach to Semi-Supervised Learning
: D. Berthelot, N. Carlini, IJ Goodfellow, N. Papernot, A. Oliver and Colin Raffel (Google Reasearch, 2019)
→
: ( JanRocketMan)
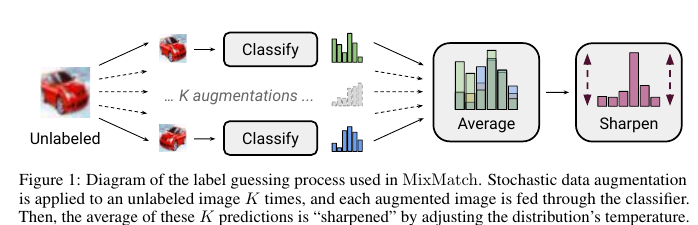
MeanTeacher Mixup- SOT- Semi-Supervised Learning (SSL) . , SSL consistency regularization. , ( ) "" , . Mean Teacher ( — c EMA ), — Mixup ( ). , . :
- unsupervised , .
"" p. - "" , one-hot. : . T , , , ( ), .
- , . , SVHN, STL CIFAR10.
CIFAR10 90% accuracy 250 . — VAT, 60%. SVHN - 96% 250- , VAT Mean Teacher 90.
STL10 90% 1 , - CCGAN, 80. , :
- , ( );
- GridSearch- ;
c. SSL SVHN .
8. Divide and Conquer the Embedding Space for Metric Learning
: Artsiom Sanakoyeu, Vadim Tschernezki, Uta Buchler and Bjorn Ommer (Heidelberg University, 2019)
→
: ( Alexander Denisenko)
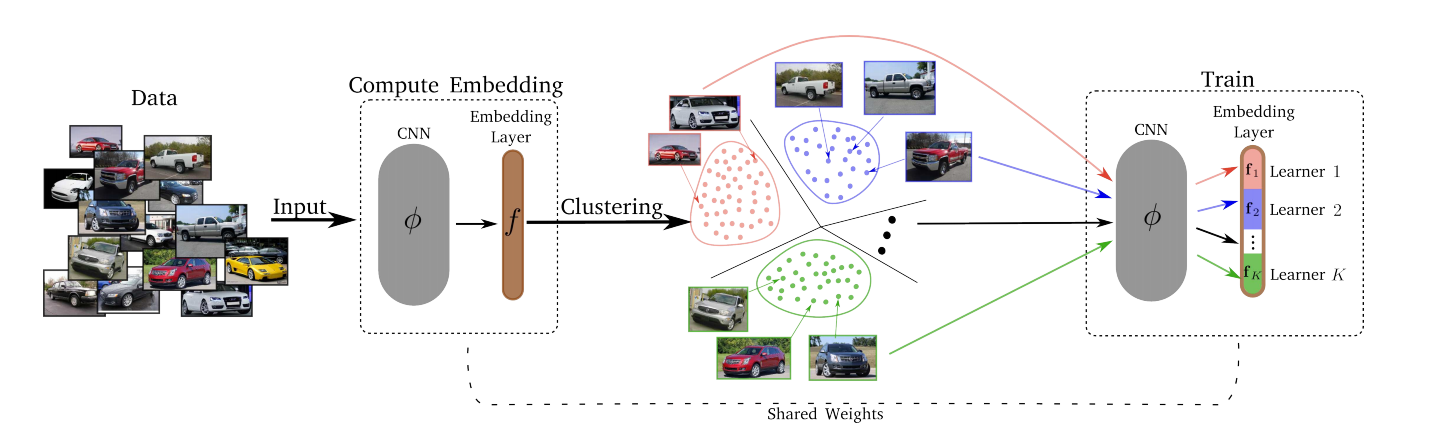
— , . , , – , , , ..
, :
- Divide.
- k-means. . . Embedding layer K . – . d/K (d – ). - Conquérir.
Après l'étape Divide, chacun des K clusters est mappé sur l'un des K Lerners. Les Lerners s'entraînent à leur tour, c'est-à-dire qu'à tout moment, nous sélectionnons un cluster sur lequel la formation a lieu, un mini-lot en est échantillonné et le Lerner correspondant minimise sa perte en mettant à jour ses paramètres. L'espace des plongements est mis à jour au fil du temps, de sorte que toutes les époques T, le clustering (Divide) soit refait. - Merjim - nous concaténons tous les Lerners (tranches de la couche d'intégration). Ensuite, nous formons la couche d'intégration sur l'ensemble de données pour faire des amis Lerners.
Résultats expérimentaux: tout le monde a gagné sur plusieurs jeux de données.
La perte peut être n'importe quoi - perte de triplet, perte de marge, proxy-NCA, etc.
Le nombre optimal de K Lerners s'est avéré être 8 (la dimension de tout l'espace d'intégration était de 128, de sorte que chaque Lerner a résolu sa sous-tâche dans un espace à 16 dimensions).
Un changement de T de 1 à 10 n'a eu aucune incidence significative sur rien, donc T = 2 a été utilisé.