Nous présentons une feuille de triche exhaustive où nous disons en termes simples ce que «fait» l'intelligence artificielle et comment tout cela fonctionne.
Quelle est la différence entre l'intelligence artificielle, l'apprentissage automatique et la science des données?
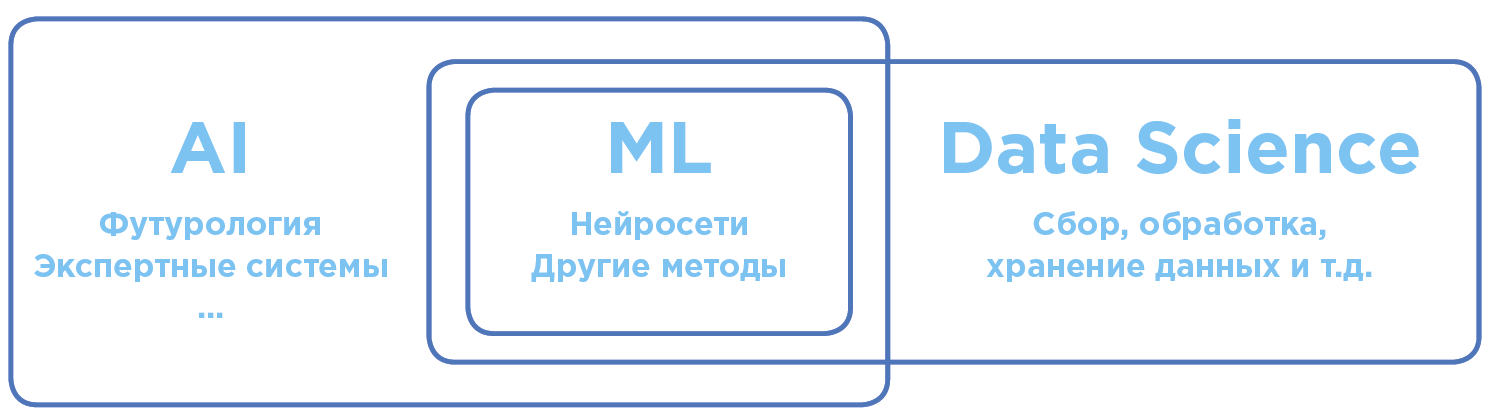 Différenciation des concepts dans le domaine de l'intelligence artificielle et de l'analyse des données.
Différenciation des concepts dans le domaine de l'intelligence artificielle et de l'analyse des données.Intelligence artificielle - AI (Intelligence artificielle)
Au sens universel global, l'IA est le terme le plus large possible. Il comprend à la fois des théories scientifiques et des pratiques technologiques spécifiques pour créer des programmes proches de l'intelligence humaine.
Apprentissage automatique - ML (Apprentissage automatique)
Section AI, appliquée activement dans la pratique. Aujourd'hui, lorsqu'il s'agit d'utiliser l'IA dans les affaires ou la fabrication, nous entendons le plus souvent le Machine Learning.
Les algorithmes ML, en règle générale, fonctionnent sur le principe d'un modèle mathématique d'apprentissage qui effectue une analyse sur la base d'une grande quantité de données, tandis que des conclusions sont tirées sans suivre des règles définies de manière rigide.
Le type de tâche le plus courant dans l'apprentissage automatique est l'apprentissage avec un enseignant. Pour résoudre ce type de problèmes, la formation est utilisée sur un ensemble de données dont la réponse est connue à l'avance (voir ci-dessous).
Science des données - DS (Data Science)
La science et la pratique de l'analyse de grands volumes de données à l'aide de toutes sortes de méthodes mathématiques, y compris l'apprentissage automatique, ainsi que la résolution de tâches connexes liées à la collecte, au stockage et au traitement de tableaux de données.
Les Data Scientists sont des experts en données, en particulier, qui analysent à l'aide de l'apprentissage automatique.

Comment fonctionne l'apprentissage automatique?
Considérons le travail de ML sur l'exemple de la tâche de notation bancaire. La Banque dispose de données sur les clients existants. Il sait si quelqu'un a des paiements de prêt en retard. La tâche consiste à déterminer si un nouveau client potentiel effectuera les paiements à temps. Pour chaque client, la banque a une combinaison de certains traits / caractéristiques: sexe, âge, revenu mensuel, profession, lieu de résidence, éducation, etc. Parmi les caractéristiques peuvent être des paramètres mal structurés, tels que les données des réseaux sociaux ou l'historique des achats. De plus, les données peuvent être enrichies d'informations provenant de sources externes: taux de change, données des bureaux de crédit, etc.
Une machine considère tout client comme une combinaison de fonctionnalités:
. Où par exemple
- âge
- les revenus, et
- le nombre de photos d'achats coûteux par mois (en pratique, dans le cadre d'une tâche similaire, Data Scientist travaille avec plus d'une centaine de fonctionnalités). Chaque client a une variable de plus -
avec deux résultats possibles: 1 (il y a des retards de paiement) ou 0 (pas de retards de paiement).
Totalité de toutes les données
et
- il existe un ensemble de données. À l'aide de ces données, Data Scientist crée un modèle
, sélection et modification de l'algorithme d'apprentissage automatique.
Dans ce cas, le modèle d'analyse ressemble à ceci:
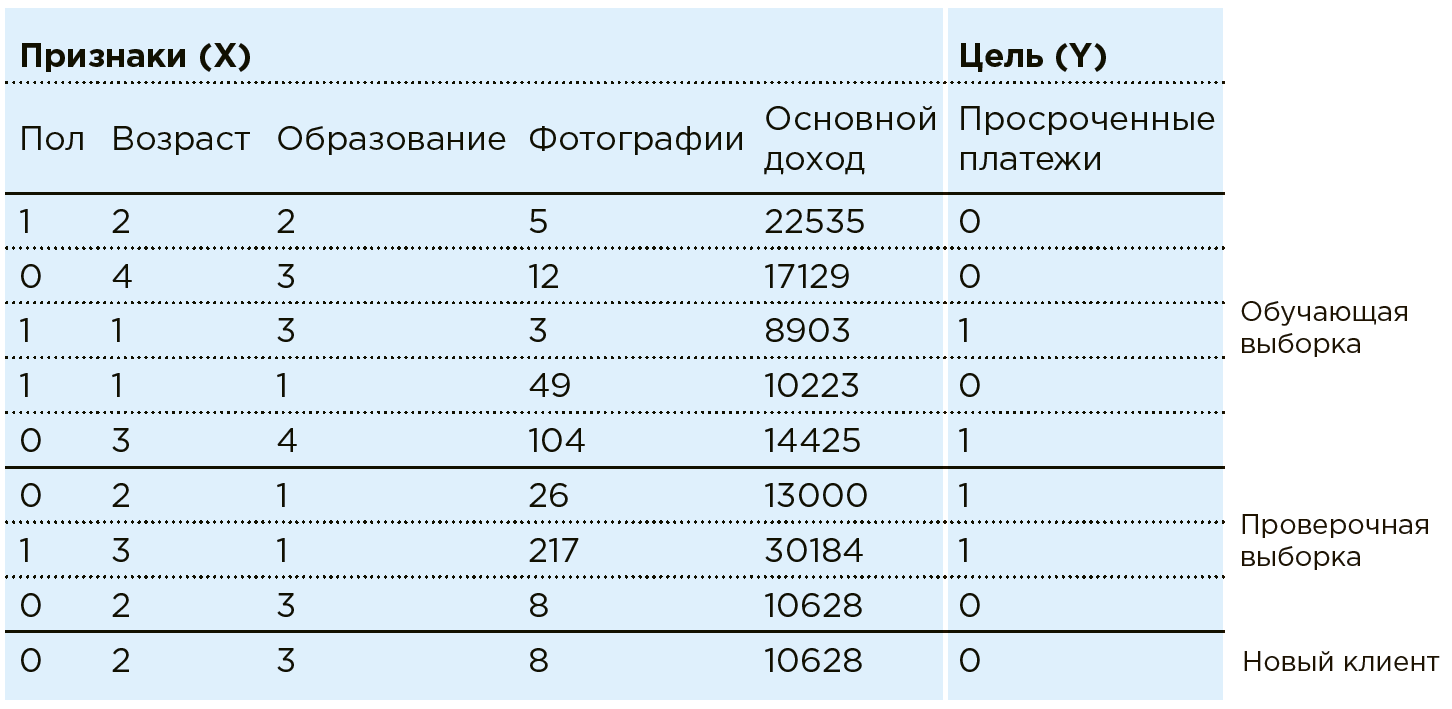
Les algorithmes d'apprentissage automatique impliquent une approximation progressive des réponses du modèle
aux vraies réponses (qui sont connues à l'avance dans l'ensemble de données de formation). Il s'agit d'une formation avec un enseignant dans un échantillon particulier.
En pratique, le plus souvent, la machine n'apprend que sur une partie de la matrice (80%), en utilisant le reste (20%) pour vérifier l'exactitude de l'algorithme sélectionné. Par exemple, un système peut être formé sur une matrice dont les données d'une paire de régions sont exclues, sur lesquelles la précision du modèle est vérifiée après.
Maintenant, quand un nouveau client vient à la banque, selon lequel
la banque n'est pas encore connue, le système dira la fiabilité du payeur sur la base des données connues
.
Cependant, l'enseignement avec un enseignant n'est pas la seule classe de problèmes que le ML peut résoudre.
Une autre gamme de tâches est le clustering, qui est capable de séparer les objets en fonction de leurs attributs, par exemple, d'identifier différentes catégories de clients pour qu'ils puissent faire des offres individuelles.
De plus, à l'aide d'algorithmes ML, des tâches telles que la modélisation de la communication d'un spécialiste du support ou la création d'œuvres d'art indiscernables des créations humaines (par exemple, les réseaux de neurones peignent des images) sont résolues.
Une nouvelle classe de tâches populaire est la formation de renforcement, qui se déroule dans un environnement limité qui évalue les actions des agents (par exemple, en utilisant cet algorithme, AlphaGo a été créé pour vaincre la personne en Go).

Réseau de neurones
Une des méthodes du Machine Learning. Un algorithme inspiré de la structure du cerveau humain, qui est basé sur les neurones et les connexions entre eux. Dans le processus d'apprentissage, les connexions entre les neurones sont ajustées de manière à minimiser les erreurs de l'ensemble du réseau.
Une caractéristique des réseaux de neurones est la présence d'architectures adaptées à presque tous les formats de données: réseaux de neurones convolutifs pour analyser les images, réseaux de neurones récurrents pour analyser les textes et les séquences, auto-encodeurs pour la compression des données, réseaux de neurones génératifs pour créer de nouveaux objets, etc.
Dans le même temps, presque tous les réseaux de neurones ont une limitation importante - pour leur formation, une grande quantité de données est nécessaire (des ordres de grandeur supérieurs au nombre de connexions entre les neurones dans ce réseau). Étant donné que récemment, les volumes de données prêtes à être analysées ont augmenté de manière significative, la portée augmente également. À l'aide des réseaux de neurones d'aujourd'hui, par exemple, les tâches de reconnaissance d'image sont résolues, telles que la détermination de l'âge et du sexe d'une personne à partir d'une vidéo, ou le port d'un casque sur le travailleur.
Interprétation du résultat
La section Data Science, qui permet de comprendre les raisons du choix de l'une ou l'autre solution par le modèle ML.
Il existe deux principaux domaines de recherche:
- Etudier le modèle comme une boîte noire. En analysant les exemples qui y sont chargés, l'algorithme compare les caractéristiques de ces exemples et les conclusions de l'algorithme, en tirant des conclusions sur la priorité de chacun d'entre eux. Dans le cas des réseaux de neurones, une boîte noire est généralement utilisée.
- Étudier les propriétés du modèle lui-même. L'étude des caractéristiques que le modèle utilise pour déterminer le degré de leur importance. Le plus souvent appliqué à des algorithmes basés sur la méthode de l'arbre de décision.
Par exemple, lors de la prévision de défauts de production, des signes d'objets
- ce sont les données sur les réglages des machines, la composition chimique des matières premières, les indicateurs des capteurs, la vidéo du convoyeur, etc. Et les réponses
- ce sont les réponses à la question de savoir s'il y aura mariage ou non.
Naturellement, la production s'intéresse non seulement à la prévision du mariage lui-même, mais aussi à l'interprétation du résultat, c'est-à-dire les raisons du mariage pour leur élimination ultérieure. Cela peut être une longue absence d'entretien de la machine, la qualité des matières premières ou simplement des lectures anormales de certains capteurs auxquelles le technologue doit prêter attention.
Par conséquent, dans le cadre du projet de prévision du mariage en production, un modèle de ML devrait non seulement être créé, mais un travail devrait également être fait pour l'interpréter, c'est-à-dire pour identifier les facteurs qui affectent le mariage.

Quand l'apprentissage automatique est-il efficace?
Lorsqu'il existe un grand nombre de données statistiques, mais qu'il est impossible ou très laborieux de trouver des dépendances à l'aide de méthodes mathématiques classiques ou expertes. Donc, s'il y a plus d'un millier de paramètres à l'entrée (parmi lesquels sont à la fois numériques et texte, ainsi que vidéo, audio et images), il est impossible de trouver la dépendance du résultat sur eux sans machine.
Par exemple, en plus des substances elles-mêmes entrant dans l'interaction, une réaction chimique est influencée par de nombreux paramètres: température, humidité, matériau du récipient dans lequel elle se produit, etc. Il est difficile pour un chimiste de prendre en compte tous ces signes afin de calculer avec précision le temps de réaction. Très probablement, il prendra en compte plusieurs paramètres clés et sera basé sur son expérience. Parallèlement, sur la base des données des réactions précédentes, le machine learning pourra prendre en compte tous les signes et donner une prévision plus précise.
Comment les Big Data et l'apprentissage automatique sont-ils liés?
Afin de construire des modèles d'apprentissage automatique, dans différents cas, des données numériques, textuelles, photo, vidéo, audio et autres sont nécessaires. Afin de stocker et d'analyser ces informations, il existe tout un domaine technologique: le Big Data. Pour un stockage et une analyse optimaux des données, ils créent «Data Lake» - un stockage distribué spécial pour de grands volumes d'informations mal structurées basé sur les technologies Big Data.
Double numérique comme passeport électronique
Un double numérique est une copie virtuelle d'un objet matériel réel, d'un processus ou d'une organisation, qui vous permet de simuler le comportement de l'objet / processus étudié. Par exemple, vous pouvez voir de façon préliminaire les résultats des changements dans la composition chimique en usine après des changements dans les paramètres des lignes de production, des changements dans les ventes après une campagne publicitaire avec certaines caractéristiques, etc. Dans ce cas, les prévisions sont faites par un double numérique basé sur les données accumulées, et les scénarios et les situations futures sont modélisés y compris les méthodes d'apprentissage automatique.
De quoi a-t-on besoin pour un apprentissage automatique de qualité?
Data Scientiest! Ce sont eux qui créent l'algorithme de prévision: ils étudient les données disponibles, avancent des hypothèses, construisent des modèles à partir du Data Set. Ils devraient avoir trois principaux groupes de compétences: connaissances informatiques, connaissances mathématiques et statistiques et expérience substantielle dans un domaine particulier.
L'apprentissage automatique repose sur trois piliers
Récupération de donnéesPeut être utilisé les données des systèmes associés: calendrier de travail, plan de vente. Les données peuvent également être enrichies par des sources externes: taux de change, météo, calendrier des vacances, etc. Il est nécessaire de développer une méthodologie pour travailler avec chaque type de données et de réfléchir à un pipeline pour les convertir en un modèle de machine learning (un ensemble de nombres).
CaractérisationElle est réalisée en collaboration avec des experts du domaine requis. Cela permet de calculer des données bien adaptées à des fins de prévision: statistiques et changements du nombre de ventes au cours du dernier mois pour la prévision du marché.
Modèle d'apprentissage automatiqueLa méthode de résolution de ce problème commercial est choisie par le data scientist de manière indépendante sur la base de son expérience et des capacités de différents modèles. Pour chaque tâche spécifique, vous devez choisir un algorithme distinct. La vitesse et la précision du résultat du traitement des données source dépendent directement de la méthode sélectionnée.
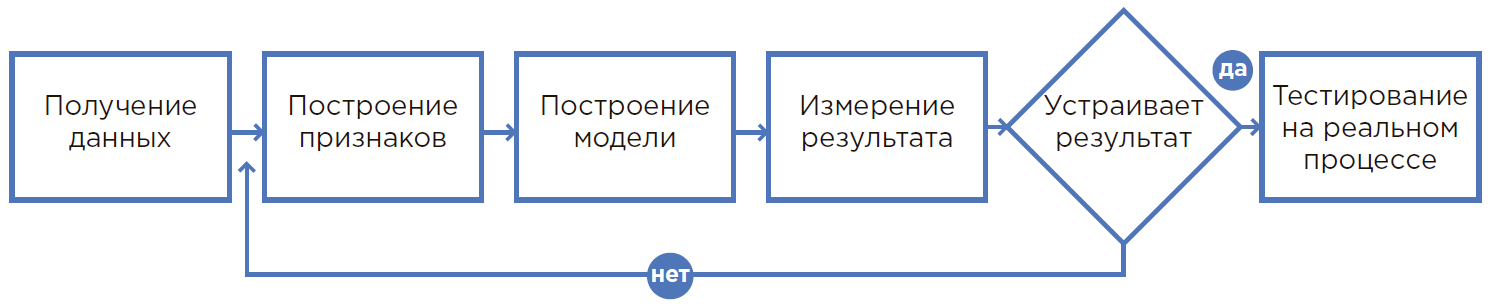 Processus de création d'un modèle ML.
Processus de création d'un modèle ML.De l'hypothèse au résultat
1. Tout commence par une hypothèse
Une hypothèse naît lors de l'analyse du processus de problème, de l'expérience des employés ou d'un regard neuf sur la production. En règle générale, une hypothèse affecte un processus dans lequel une personne est physiquement incapable de prendre en compte de nombreux facteurs et utilise des arrondis, des hypothèses ou fait simplement comme il l'a toujours fait.
Dans ce processus, l'utilisation de l'apprentissage automatique vous permet d'utiliser beaucoup plus d'informations lors de la prise de décisions, il est donc possible d'obtenir des résultats nettement meilleurs. De plus, l'automatisation des processus utilisant le ML et la réduction de la dépendance à l'égard d'une personne spécifique minimisent considérablement le facteur humain (maladie, faible concentration, etc.).
2. Évaluation de l'hypothèse
Sur la base de l'hypothèse formulée, les données nécessaires au développement d'un modèle d'apprentissage automatique sont sélectionnées. Une recherche est effectuée pour les données pertinentes et une évaluation de leur aptitude à intégrer le modèle dans les processus actuels est déterminée qui seront ses utilisateurs et en raison de laquelle l'effet est obtenu. Si nécessaire, des modifications organisationnelles et autres sont apportées.
3. Le calcul de l'effet économique et du retour sur investissement (ROI)
L'évaluation de l'effet économique de la solution mise en œuvre est réalisée par des spécialistes en collaboration avec les services concernés: efficacité, finances, etc. À ce stade, vous devez comprendre quelle est exactement la métrique (nombre de clients correctement identifiés / augmentation de la production / économie de consommables, etc.) et articuler clairement l'objectif mesuré.
4. La formulation mathématique du problème
Après avoir compris le résultat commercial, il est nécessaire de le déplacer vers le plan mathématique - pour définir des mesures et des restrictions de mesure qui ne peuvent pas être violées. Données étapes données
Un scientifique travaille en collaboration avec un client commercial.
5. Collecte et analyse des données
Il est nécessaire de collecter des données en un seul endroit, de les analyser, en tenant compte de diverses statistiques, de comprendre la structure et les relations cachées de ces données pour former des signes.
6. Création d'un prototype
Il s'agit en fait d'un test d'hypothèse. C'est l'occasion de construire un modèle à partir des données actuelles et de vérifier dans un premier temps les résultats de son travail. Généralement, un prototype est réalisé sur des données existantes sans développer d'intégrations et travailler avec un flux en temps réel.
Le prototypage est un moyen rapide et peu coûteux de vérifier si un problème est résolu. Ceci est très utile lorsqu'il est impossible de comprendre à l'avance s'il sera possible d'obtenir l'effet économique souhaité. De plus, le processus de création d'un prototype permet de mieux évaluer la portée et les détails du projet de mise en œuvre de la solution, de préparer une justification économique à une telle mise en œuvre.
DevOps et DataOps
Pendant le fonctionnement, un nouveau type de données peut apparaître (par exemple, un autre capteur apparaîtra sur la machine ou un nouveau type de marchandises apparaîtra dans l'entrepôt), puis le modèle doit être formé. DevOps et DataOps sont des méthodologies qui aident à mettre en place une collaboration et des processus de bout en bout entre les équipes de Data Science, les ingénieurs de préparation des données, le développement informatique et les services d'exploitation, et aident à intégrer ces ajouts dans le processus actuel rapidement, sans erreurs et sans résoudre chaque fois unique problèmes.
7. Créer une solution
À ce moment, lorsque les résultats du travail de prototype démontrent la réalisation confiante d'indicateurs, une solution complète est créée où le modèle d'apprentissage automatique n'est qu'une composante des processus étudiés. Ensuite, l'intégration, l'installation des équipements nécessaires, la formation du personnel, l'évolution des processus décisionnels, etc.
8. Opération pilote et industrielle
Pendant l'opération d'essai, le système fonctionne en mode conseil, tandis que le spécialiste répète toujours les actions habituelles, donnant à chaque fois un retour sur les améliorations nécessaires au système et augmentant la précision des prévisions.
La dernière partie est l'exploitation industrielle, lorsque les processus établis passent à une maintenance entièrement automatique.
Vous pouvez télécharger la feuille de triche à partir du
lien .
Demain, lors du forum sur les systèmes d'intelligence artificielle
RAIF 2019 à 09h30 - 10h45, il y aura une table ronde: "L'IA pour les gens: nous comprenons en termes simples."
Dans cette section, dans un format de débat, les conférenciers expliqueront des technologies complexes avec des mots simples sur des exemples de vie. Et discutez également sur les sujets suivants:
- Quelle est la différence entre l'intelligence artificielle, l'apprentissage automatique et la science des données?
- Comment fonctionne l'apprentissage automatique?
- Comment fonctionnent les réseaux de neurones?
- De quoi a-t-on besoin pour un apprentissage automatique de qualité?
- Qu'est-ce que le balisage, l'étiquetage des données?
- Qu'est-ce qu'un double numérique et comment travailler avec des copies virtuelles d'objets matériels réels?
- Quelle est l'essence de l'hypothèse? Comment passer de la manière dont il est posé à l'évaluation et à l'interprétation du résultat?
La discussion est suivie par:
Nikolay Marine, directeur de la technologie, IBM en Russie et dans la CEI
Alexey Natekin, fondateur, Open Data Science x Data Souls
Alexey Hakhunov, CTO, Dbrain
Evgeny Kolesnikov, directeur, Centre d'apprentissage machine, Jet Infosystems
Pavel Doronin, PDG, AI Today
La discussion sera disponible sur
la chaîne YouTube Jet Infosystems fin octobre.