Le sujet des réseaux de neurones excite le cœur des développeurs, des scientifiques et des spécialistes du marketing non pas pour la première année, mais pour certains, même pas la première décennie. Mais nous savons tous que souvent dans le cadre de projets basés sur les neurones, il existe une simple grande date et un bulletin marketing, gonflés dans le contexte d'un en-tête de clickbait. Nous avons essayé d'éviter une telle histoire et développé un projet de neuropizza basé sur une étude de la compatibilité moléculaire des ingrédients, l'analyse de 300 mille recettes et la pure créativité. Sous la coupe, vous pouvez trouver les détails et trouver le lien open source sur GitHub.

Une voiture peut-elle proposer quelque chose de nouveau ou est-elle limitée par ce qu'elle sait? Jusqu'à présent, personne ne connaît la réponse à cette question. Mais maintenant, l'intelligence artificielle résout parfaitement les problèmes d'analyse de grandes données non standard.
Une fois chez Dodo Pizza, ils ont décidé de mener une expérience: systématiser et décrire structurellement ce qui est considéré comme chaotique et subjectif à travers le monde - le goût. L'intelligence artificielle a aidé à trouver les combinaisons d'ingrédients les plus folles qui, malgré leur nature inhabituelle, se sont avérées savoureuses pour la plupart des gens.
Mon collègue et moi avons agi en tant que spécialistes des réseaux de neurones du MIPT et de Skoltech dans ce projet inhabituel. Nous avons développé et formé un réseau de neurones qui peut résoudre le problème de génération de recettes de cuisine. Au cours des travaux, plus de 300 000 recettes ont été analysées, ainsi que les résultats de recherches scientifiques sur la compatibilité moléculaire des ingrédients. Sur cette base, l'IA a appris à trouver des liens non évidents entre les ingrédients et à comprendre comment ils se combinent entre eux et comment la présence de chacun d'eux affecte la compatibilité de tous les autres.
Comment nous sommes entrés dans le projet Dodo AI-pizza
Tout, comme d'habitude, s'est produit soudainement. Il y a eu une courte période de pause avant la pratique d'été, nous venons de terminer le cours d'apprentissage en profondeur, avons défendu le projet et avons essayé de nous adapter à un rythme plus détendu d'étude / vie. Mais ils ne pouvaient pas: ont accidentellement rencontré des référentiels dans une demande personnelle de BBDO sur la recherche de gars qui pourraient écrire un réseau de neurones pour générer de nouvelles recettes. Plus précisément: nouvelles recettes de pizza pour Dodo. Sans hésitation, nous avons décidé que nous voulions essayer.
Au début du projet, nous ne savions pas très bien s'il irait plus loin, s'il y aurait une mise en œuvre pratique, nous étions simplement intéressés par la tâche. Beaucoup de redbowl et d'Internet rapide nous ont aidés et nous ont fait avancer. Avec le recul, nous comprenons que certaines choses pourraient être faites différemment, mais c'est normal.
En tout cas, après quelques semaines le modèle de travail du réseau neuronal était prêt, l'étape de son lancement en production a commencé. Nous sommes très chanceux que le projet ne puisse pas être qualifié d’industriel ou technique au sens strict de ces mots. Le statut de l'expérience lui convient mieux.
En utilisant notre modèle, différentes variantes de recettes de pizza ont été générées, que nous avons passées entre les mains de chefs Dodo très cool pour effectuer des tests de produits. La dégustation de pizza au Dodo R&D Lab a été un tournant décisif en termes de reconnaissance de la valeur du travail que nous avons fait. C'était très excitant de voir le produit vendu. En effet, souvent tous les développements et solutions sont une chose plutôt éphémère, intangible, et ici le résultat pourrait non seulement être touché, mais aussi goûté.
Collection primaire de jeu de données et de piment
Tout modèle a besoin de données pour fonctionner. Par conséquent, pour former notre IA, nous avons collecté 300 000 recettes de toutes les sources disponibles. Il était important pour nous de collecter non seulement des recettes de pizza, mais de diversifier la sélection autant que possible, tout en essayant de ne pas aller au-delà du raisonnable (par exemple, ignorer les recettes de cocktails, en réalisant que leur sémantique n'affectera pas grandement la sémantique des recettes de pizza).
Après avoir collecté les données, nous avons obtenu plus de 100 000 ingrédients uniques. Le gros problème était de les amener sous une seule forme. Mais d'où venaient tant d'articles? Tout est simple, par exemple, les piments dans les recettes sont indiqués comme ceci: piment, piment, piments, piments. Il est évident pour vous qu'il s'agit du même poivre, mais le réseau neuronal perçoit différentes orthographes comme des entités distinctes. Nous l'avons corrigé. Après avoir nettoyé les données et les avoir amenées à une vue, il ne nous restait plus que 1 000 postes.
Analyse des goûts du monde
Après avoir reçu l'ensemble de données prêt pour le travail, nous avons effectué l'analyse initiale. Premièrement, nous avons examiné quelles cuisines du monde sont représentées dans notre ensemble de données dans un rapport quantitatif.
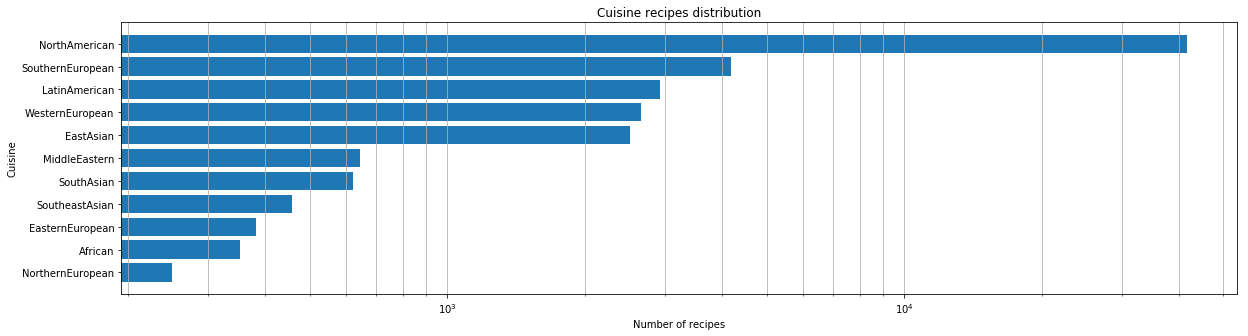
Pour chacune des cuisines, nous avons identifié les ingrédients les plus populaires.
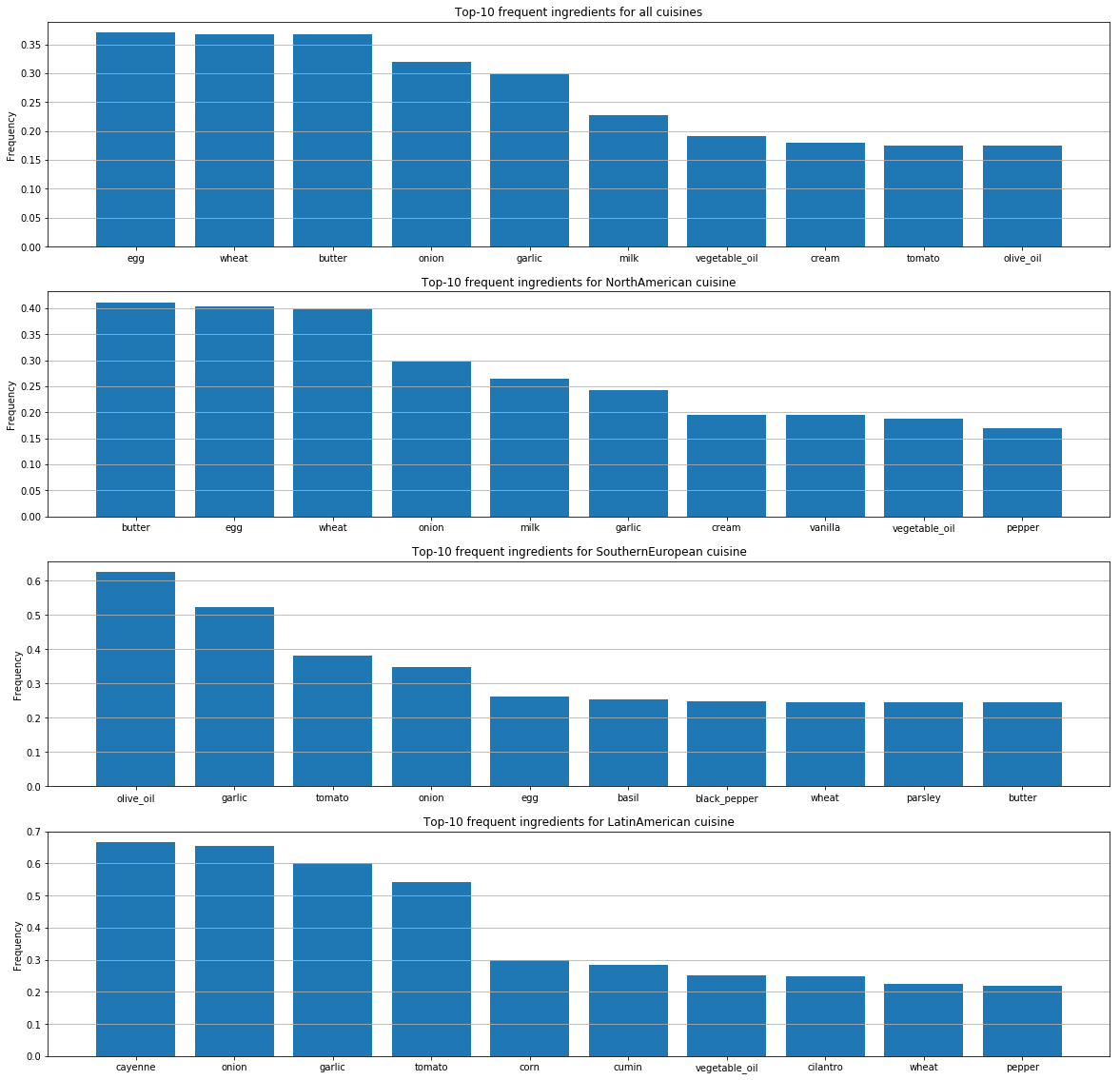
Sur ces graphiques, les différences dans les préférences gustatives des personnes par pays sont perceptibles. Il ressort également de ces préférences comment les gens de différents pays combinent les ingrédients les uns avec les autres.
Deux découvertes de pizza
Après cette analyse globale, nous avons décidé d'étudier plus en détail les recettes de pizza du monde entier pour trouver des modèles dans leur composition. Voici les conclusions que nous avons tirées:
- Les recettes de pizza sont d'un ordre de grandeur plus petites que les recettes de viande / poulet et les desserts.
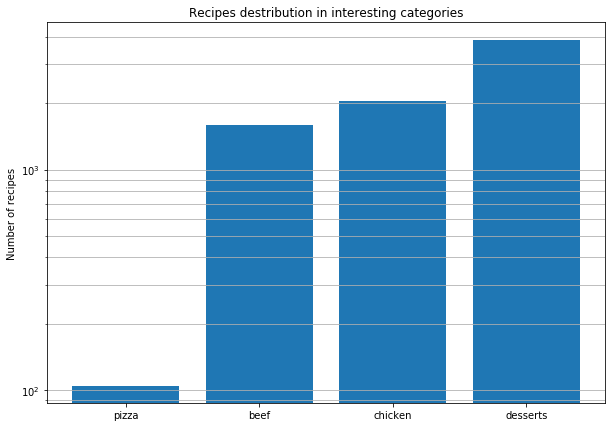
- De nombreux ingrédients trouvés dans les recettes de pizza sont limités. La variabilité même des produits est beaucoup plus faible que dans les autres plats.

Comment nous avons testé le modèle
Trouver de vraies combinaisons de saveurs n'est pas la même chose que révéler la compatibilité des molécules. Tous les fromages ont une composition moléculaire similaire, mais cela ne signifie pas que les combinaisons réussies se situent uniquement dans la zone des ingrédients les plus proches.
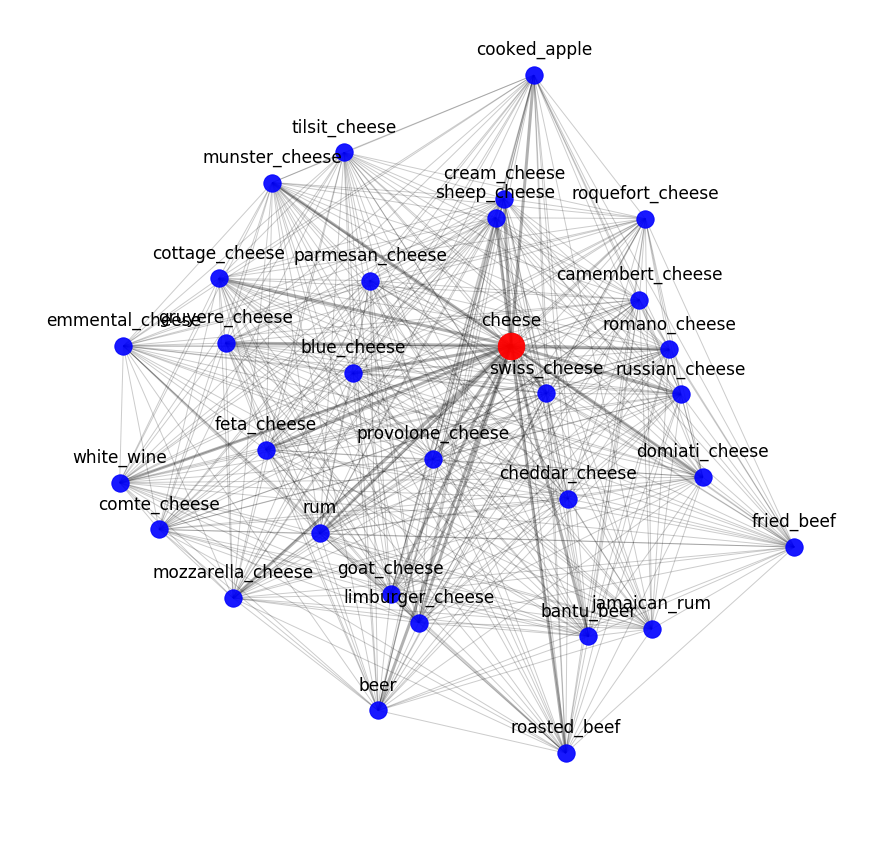
Cependant, nous devrions voir exactement la compatibilité des ingrédients similaires au niveau moléculaire lorsque nous traduisons tout en mathématiques. Parce que des objets similaires (les mêmes fromages) doivent rester similaires, peu importe comment nous les décrivons. Nous pouvons donc déterminer que décrit correctement ces objets.
Convertir la recette en mathématiques
Pour présenter la recette sous une forme compréhensible pour le réseau neuronal, nous avons utilisé le Skip-Gram Negative Sampling (SGNS) - l'algorithme word2vec, qui est basé sur l'occurrence de mots dans le contexte. Nous avons décidé de ne pas utiliser les modèles word2vec pré-formés, car notre recette est évidemment différente dans sa structure sémantique des textes simples. En utilisant de tels modèles, nous pourrions perdre des informations importantes.
Vous pouvez évaluer le résultat de word2vec en regardant les voisins sémantiques les plus proches. Par exemple, voici ce que notre modèle connaît du fromage:
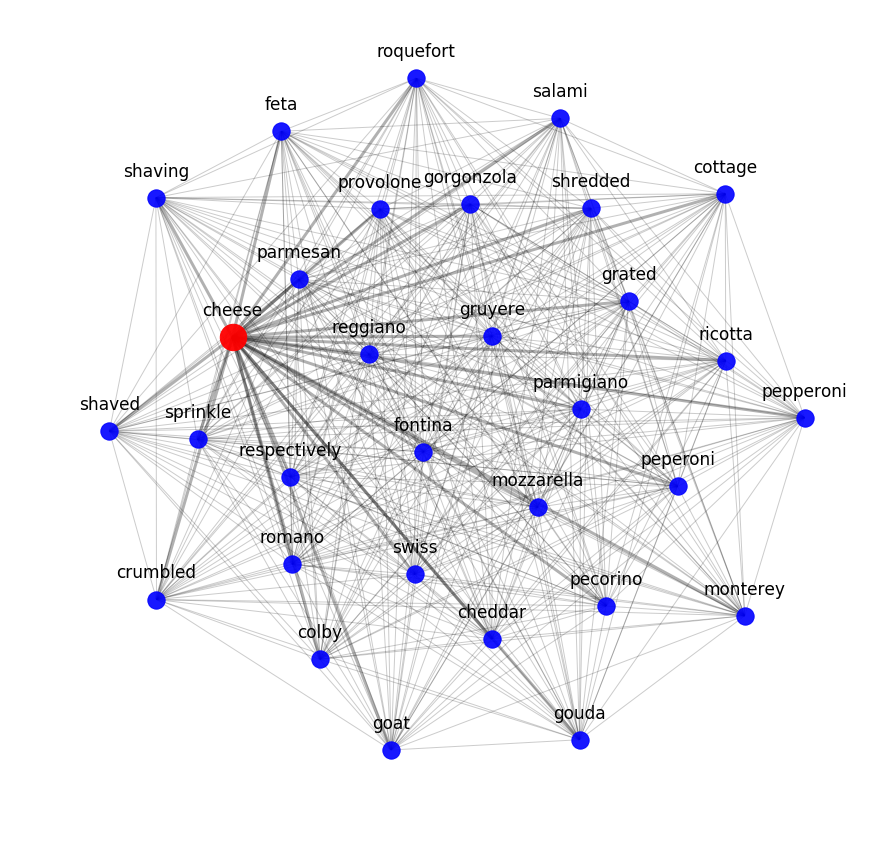
Pour tester comment les modèles sémantiques peuvent capturer les interactions de recette des ingrédients, nous avons appliqué un modèle de modélisation thématique pour toutes les recettes de l'échantillon. Autrement dit, ils ont essayé de diviser l'ensemble de données de recettes en grappes selon des modèles identifiés mathématiquement.

Sachant à l'avance qu'un certain échantillon de recettes appartient à différentes classes réelles obtenues à partir des données, nous avons construit la distribution d'appartenance de chaque classe réelle aux classes générées identifiées.

La plus évidente était la classe des desserts, qui formait le thème 0 et 1, générée par le modèle thématique. En plus des desserts, il n'y a presque pas d'autres classes dans ces matières, ce qui suggère que les desserts sont facilement séparés des autres classes de plats. Il y a aussi dans chaque matière une classe qui la décrit le mieux. Cela signifie que nos modèles ont bien géré la description mathématique de la signification non évidente du «goût».
Génération de recettes
Pour créer de nouvelles recettes, nous avons utilisé deux réseaux de neurones récurrents. Pour ce faire, nous avons suggéré que dans l'espace commun des recettes, il existe un sous-espace qui est responsable des recettes de pizza. Pour que le réseau neuronal apprenne à trouver de nouvelles recettes de pizza, nous avons dû trouver ce sous-espace.
Une telle tâche est similaire dans son sens à l'autocodage d'images lorsque nous présentons une image comme un vecteur de petite dimension. Dans ce cas, les vecteurs peuvent contenir une grande quantité d'informations spécifiques sur l'image.
Par exemple, pour la reconnaissance faciale sur la photo, ces vecteurs peuvent stocker des informations sur la couleur des cheveux humains dans une cellule séparée. Nous avons choisi cette approche précisément en raison des propriétés uniques du sous-espace caché.
Pour identifier le sous-espace pizza, nous avons exécuté des recettes à travers deux réseaux de neurones récurrents. Le premier a reçu une recette de pizza à l'entrée et a cherché sa représentation sous la forme d'un vecteur caché. Le second a reçu un vecteur caché du premier réseau neuronal et a dû proposer une recette basée sur lui. Les recettes à l'entrée du premier réseau neuronal et à la sortie du second auraient dû coïncider.
Ainsi, deux réseaux de neurones au format de décodage codeur ont appris à relayer correctement la recette à un vecteur caché (latent) et vice versa. Sur cette base, nous avons pu découvrir un sous-espace caché qui est responsable de toutes les nombreuses recettes de pizza.
Compatibilité moléculaire
Lorsque nous avons résolu le problème de la création d'une recette de pizza, nous avons dû ajouter le critère de compatibilité moléculaire au modèle. Pour cela, nous avons utilisé les résultats d'une
étude conjointe de scientifiques de Cambridge et de plusieurs universités américaines.
À la suite de l'étude, il a été constaté que les ingrédients avec le plus grand nombre de paires moléculaires totales sont mieux combinés. Par conséquent, lors de la création de la recette, le réseau neuronal a préféré des ingrédients ayant une structure moléculaire similaire.
Résultat et AI Pizza
En conséquence, notre réseau de neurones a appris à créer avec succès des recettes de pizza. En ajustant les coefficients, l'IA peut produire à la fois des recettes classiques (comme la Margarita ou le Pepperoni) et des recettes folles. Une telle recette folle a constitué la base de la première pizza moléculaire parfaite au monde avec dix ingrédients: sauce tomate, melon, poire, poulet, tomates cerises, thon, menthe, brocoli, fromage mozzarella, granola. Une édition limitée pourrait même être achetée dans l'une des pizzerias Dodo. Et voici quelques recettes plus intéressantes que vous pouvez essayer de cuisiner à la maison:
- épinards, fromage, tomate, olives noires, olive, ail, poivre, basilic, agrumes, melon, germes, babeurre, citron, bar, noix, rutabaga;
- oignon, tomate, olive, poivre noir, pain, pâte;
- poulet, oignon, olive noire, fromage, sauce, tomate, huile d'olive, fromage mozzarella;
- tomate, beurre, cream_cheese, poivre, olive_oil, fromage, black_pepper, mozzarella_cheese;
Tout ça serait de la poubelle si on ne donnait pas de lien vers le plus intéressant: