Nginx est un serveur Web qui résout des dizaines de tâches commerciales, est configuré, mis à l'échelle de manière flexible et fonctionne sur presque tous les systèmes d'exploitation et plates-formes. Une liste des fonctionnalités, capacités et problèmes à résoudre hors de la boîte peut être décrite dans une petite brochure. Mais parfois, un certain nombre de tâches commerciales ne peuvent être résolues qu'en développant vos propres modules pour nginx. Ce sont des modules qui sont orientés métier et contiennent une logique métier, et pas seulement une solution système généralisée.

En général, tout dans nginx est constitué de modules qui ont été écrits par quelqu'un. Par conséquent, l'écriture de modules sous nginx est non seulement possible, mais également nécessaire. Quand il est nécessaire de le faire et pourquoi,
Vasily Soshnikov (
dedokOne ) racontera sur l'exemple de plusieurs cas.
Parlons des raisons qui encouragent l'écriture de modules en C, de l'architecture et du noyau de nginx, de l'anatomie des modules HTTP, des modules C, NJS, Lua et nginx.conf. Ceci est important à savoir non seulement pour ceux qui développent sous nginx, mais aussi pour ceux qui utilisent nginx-configs, Lua ou une autre langue à l'intérieur de nginx.
Remarque: l'article est basé sur un rapport de Vasily Soshnikov. Le rapport est constamment mis à jour et mis à jour. Les informations contenues dans le matériel sont assez techniques et afin d'en tirer le meilleur parti, les lecteurs doivent avoir une expérience de travail avec le code nginx à un niveau moyen et supérieur.En bref sur nginx
Tout ce que vous utilisez avec nginx sont des modules . Chaque directive dans la configuration nginx est un module distinct, qui a été soigneusement écrit par des collègues de la communauté nginx.
Les directives dans nginx.conf sont également des modules qui résolvent un problème spécifique. Par conséquent, dans les modules nginx sont tout. add_header, proxy_pass, toute directive - ce sont des modules ou des combinaisons de modules qui fonctionnent selon certaines règles.
Nginx est un framework qui a: E / S réseau et fichier, mémoire partagée, configuration et script. Il s'agit d'une énorme couche de bibliothèques de bas niveau, sur laquelle vous pouvez tout faire pour travailler avec les lecteurs réseau.
Nginx est rapide et stable, mais complexe . Vous devriez écrire un tel code pour ne pas perdre ces qualités de nginx. Les nginx instables en production sont des clients insatisfaits, et tout cela en découle.
Pourquoi créer vos propres modules
Convertissez le protocole HTTP en un autre protocole. C'est la raison principale qui motive souvent la création d'un module particulier.
Par exemple, le module memcached_pass convertit HTTP en un autre protocole et vous pouvez travailler avec d'autres systèmes externes. Le module proxy_pass vous permet également de convertir, bien que de HTTP (s) à HTTP (s). Un autre bon exemple est fastcgi_pass.
Ce sont toutes des directives du formulaire: "aller à tel ou tel backend, où pas HTTP (mais dans le cas de proxy_pass HTTP)."
Insertion de contenu dynamique: contournement AdBlock, insertion d'annonces. Par exemple, nous avons un backend et il est nécessaire de modifier le contenu qui en découle. Par exemple, AdBlock, qui analyse le code d'insertion d'annonce, et nous devons y faire face - pour le régler d'une manière ou d'une autre.
Une autre chose que vous devez souvent faire pour intégrer du contenu est le problème de la mise en cache HLS. Lorsque les paramètres sont mis en cache dans HLS, deux utilisateurs peuvent obtenir la même session ou les mêmes paramètres. De là, vous coupez ou ajoutez des paramètres lorsque vous avez besoin de suivre quelque chose.
Collecte de données Clickstream à partir de compteurs Internet / mobiles. Un cas populaire dans ma pratique. Le plus souvent, cela se fait sur nginx, mais pas sur access.log, mais un peu plus intelligent.
Conversion de toutes sortes de contenus. Par exemple, le module rtmp pour vous permet de travailler non seulement avec rtmp, mais aussi avec HLS. Ce module peut faire beaucoup avec du contenu vidéo.
Point d'autorisation générique: SEP ou Api Gateway. C'est le cas lorsque nginx fonctionne dans le cadre de l'infrastructure: autorise, collecte des métriques, envoie des données à la surveillance et à ClickStream. Nginx fonctionne ici comme un hub d'infrastructure - un point d'entrée unique pour les backends.
Enrichissement des demandes pour leur traçage ultérieur. Les systèmes modernes sont très complexes, avec plusieurs types de backends qui forment différentes équipes. En règle générale, ils sont difficiles à débuter, parfois il est même difficile de comprendre d'où vient la demande et où elle va. Pour simplifier le débogage, certaines grandes entreprises utilisent une technique délicate - elles ajoutent certaines données aux demandes. L'utilisateur ne les verra pas, mais à partir de ces données, il est facile de tracer le chemin de demande à l'intérieur du système. C'est ce qu'on appelle une
trace .
Proxy S3. Cette année, je vois souvent des gens travailler avec leurs objets via s3. Mais il n'est pas nécessaire de le faire sur les modules C, l'infrastructure est également suffisante dans nginx. Pour résoudre certains de ces problèmes, vous pouvez utiliser Lua, quelque chose est en train d'être résolu sur NJS. Mais parfois il faut écrire des modules en C.
Quand est-il temps de créer des modules
Il y a deux critères pour comprendre que le moment est venu.
Généralisation des fonctionnalités. Lorsque vous comprenez que quelqu'un d'autre a besoin de votre produit, vous devez le faire passer en Open Source, créer des fonctionnalités généralisées, le publier et le laisser être utilisé.
Résolution des problèmes commerciaux. Lorsqu'une entreprise définit de telles exigences qui ne peuvent être satisfaites qu'en écrivant son propre module pour nginx. Par exemple, l'insertion / modification dynamique de contenu, la collecte ClickStream peut être effectuée sur Lua, mais très probablement, cela ne fonctionnera pas normalement.
Architecture Nginx
J'écris du code nginx depuis longtemps. Neuf de mes modules tournent en production, l'un d'eux est en Open Source, et en production pour beaucoup. Par conséquent, j'ai de l'expérience et de la compréhension.
Nginx est une poupée gigogne dans laquelle tout est construit autour du noyau.
Je comprends donc nginx.
Les noyaux sont des enveloppes sur epoll.
Epoll est une méthode qui vous permet de travailler de manière asynchrone avec n'importe quel fichier descripteur, pas seulement avec des sockets, car un descripteur n'est pas seulement une socket.
Au-dessus du cœur se trouvent les amonts, HTTP et les scripts. Par script, je veux dire nginx.conf, pas NJS. En plus des amonts, du HTTP et des scripts, des modules HTTP sont déjà construits, dont nous parlerons.
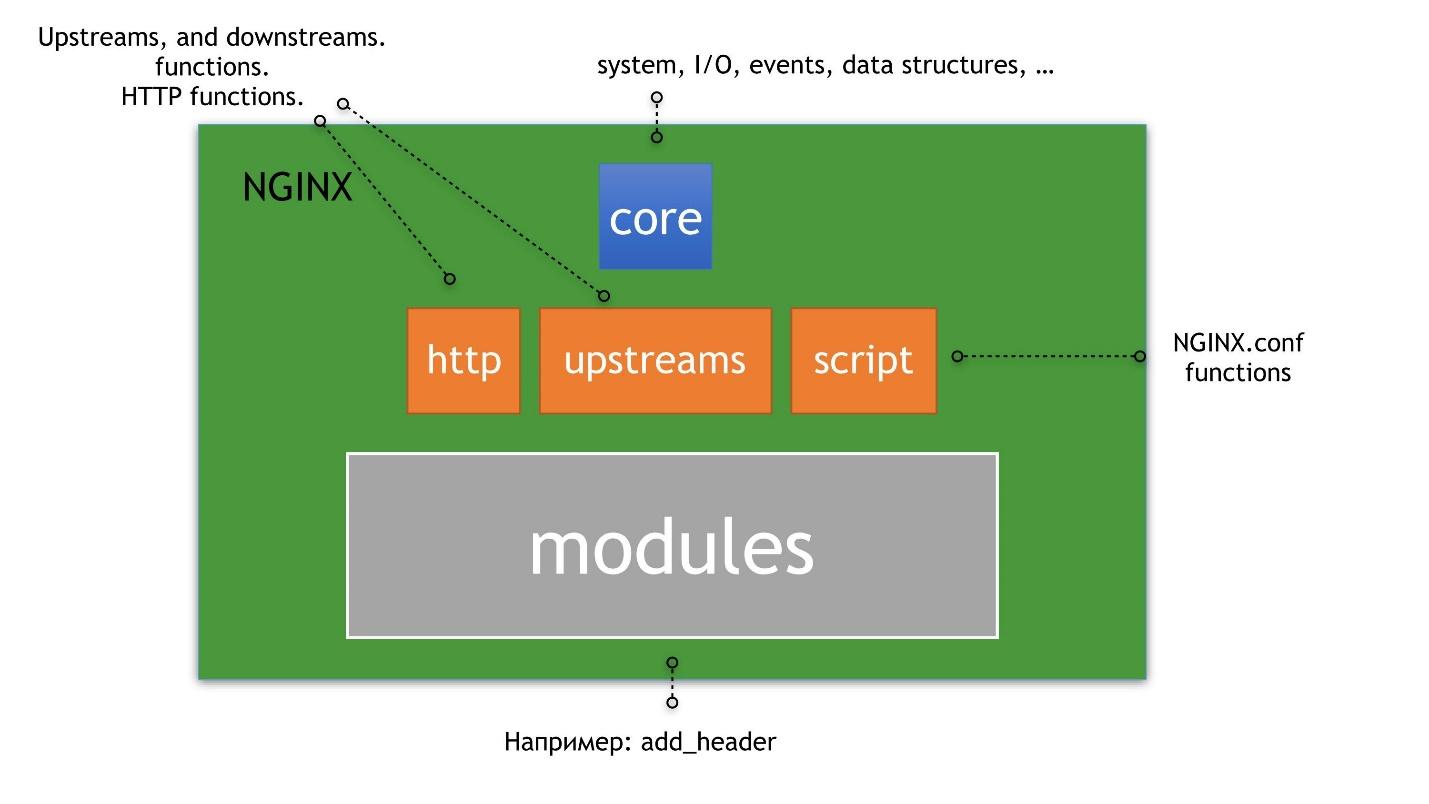
Un exemple classique d'amont et de HTTP sont les serveurs amont - directives à l'intérieur de la configuration. Un exemple de modules pour HTTP est add_header. Un exemple de script est le fichier de configuration lui-même. Le fichier contient les modules qui composent nginx; il est interprété d'une manière ou d'une autre et vous permet de faire quelque chose en tant qu'administrateur ou en tant qu'utilisateur.
Nous ne considérerons pas le noyau et nous attarderons très brièvement sur les amonts, car il s'agit d'un univers séparé à l'intérieur de nginx. L'histoire à leur sujet mérite plusieurs articles.
Anatomie des modules HTTP
Même si vous n'écrivez pas de code C dans nginx, mais que vous l'utilisez, n'oubliez pas la règle principale.
Dans nginx, tout obéit au modèle de chaîne de responsabilité - COR.
Je ne sais pas comment traduire cela en russe, mais je vais décrire la logique. Votre demande passe par une galaxie de modules de chaîne configurés, à partir de l'emplacement. Chacun de ces modules renvoie un résultat. Si le résultat est mauvais, la chaîne est interrompue.

Lorsque vous développez des modules ou utilisez une sorte de directive dans NJS et Lua, n'oubliez pas que votre code peut planter l'exécution de cette chaîne.
L'analogie la plus proche de la
chaîne de responsabilité est une ligne de code Bash:
grep -RI pool nginx | awk -F":" '{print $1}' | sort -u | wc -l
Dans le code, tout est assez simple: si AWK est tombé au milieu de la ligne, puis
sort et les commandes suivantes échoueront. Le module nginx fonctionne de manière similaire, mais la vérité est dans nginx et vous pouvez contourner cela - redémarrez le code. Mais vous devez être prêt à planter et à exécuter, tout comme vos modules que vous utilisez dans la configuration, mais pas le fait qu'il en soit ainsi.
Types de modules HTTP
HTTP et nginx sont un tas de PHASES différentes.
- Gestion des phases - gestionnaires PHASE .
- Filtres - Filtres corps / en-têtes . Ce filtrage est soit des en-têtes, soit des corps de demande.
- Les procurations . Les modules proxy typiques sont proxy_pass, fastcgi_pass, memcached_pass.
- Modules pour un équilibrage de charge spécifique - Equilibreurs de charge . C'est le type de modules le plus sans torsion, ils ne sont pas beaucoup développés. Un exemple est le module Ketama CHash, qui vous permet de faire un hachage cohérent à l'intérieur de nginx pour distribuer les requêtes aux backends.
Je vais parler de chacun de ces types et de leur objectif.
Gestionnaires de phases
Imaginez que nous ayons plusieurs phases, à partir de la phase d'accès. Il y a plusieurs modules dans chaque phase. Par exemple, la phase ACCESS est divisée en une connexion, une demande à nginx, une vérification de l'autorisation de l'utilisateur. Chaque module est une cellule de la chaîne. Il peut y avoir un nombre infini de tels modules en phase.
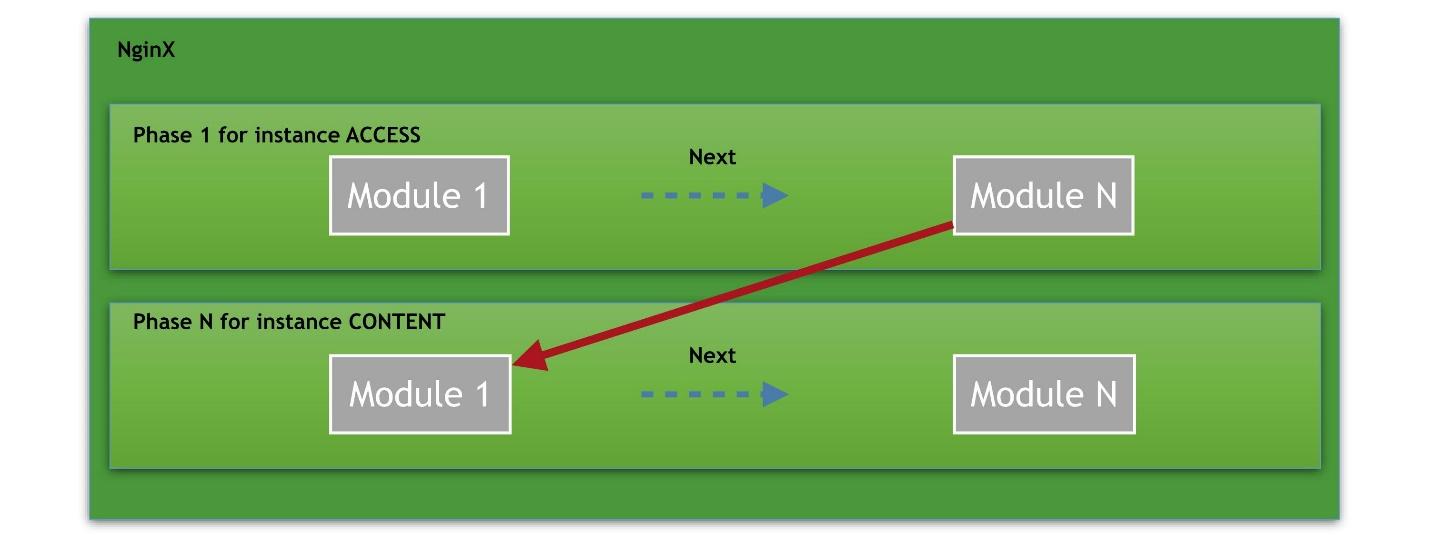
Le dernier et dernier gestionnaire est la phase CONTENT dans laquelle le contenu est livré à la demande.
Le chemin est toujours le suivant: demande - une chaîne de gestionnaires - contenu de sortie.
Phases disponibles pour les développeurs de modules à partir des
sources NGINX :
typedef enum { NGX_HTTP_POST_READ_PHASE = 0, NGX_HTTP_SERVER_REWRITE_PHASE, NGX_HTTP_FIND_CONFIG_PHASE, NGX_HTTP_REWRITE_PHASE, NGX_HTTP_POST_REWRITE_PHASE, NGX_HTTP_PREACCESS_PHASE, NGX_HTTP_ACESS_PHASE, NGX_HTTP_POST_ACESS_PHASE, NGX_HTTP_PRECONTENT_PHASE, NGX_HTTP_CONTENT_PHASE, NGX_HTTP_LOG_PHASE, } ngx_http_phases;
Les phases peuvent être écrasées, ajoutez votre propre gestionnaire. Tous ne sont pas nécessaires dans la vie réelle, si vous n'êtes pas le développeur de Nginx Core. Par conséquent, je ne parlerai pas de chaque phase, mais seulement des principales que j'ai utilisées.
Le principal est
ACCESS_PHASE. Il est particulièrement utile d'ajouter votre autorisation à nginx - pour vérifier l'exécution de la demande en termes d'accès.
Les prochaines phases importantes que j'exploite souvent sont les phases de pré-contenu et de contenu.
PRECONTENT_PHASE vous permet de collecter des métriques sur le contenu qui est sur le point d'être envoyé en réponse au client.
CONTENT_PHASE vous permet de générer votre propre contenu unique basé sur quelque chose.
La dernière phase que j'utilise souvent est la phase d'enregistrement
LOG_PHASE. Par ailleurs, la directive ACCESS_LOG y fonctionne. La phase de journalisation a les restrictions les plus folles qui me rendent fou: vous ne pouvez pas utiliser de sous-demande et généralement vous ne pouvez utiliser aucune demande. Vous avez déjà laissé le contenu à l'utilisateur, et les gestionnaires, les posthandlers et toute sous-demande ne seront pas exécutés.
Je vais vous expliquer pourquoi c'est ennuyeux. Disons quand vous voulez croiser nginx et Kafka dans la phase de journalisation. Dans cette phase, tout est déjà terminé: il y a une taille calculée du contenu, du statut, de toutes les données, mais vous ne pouvez pas le faire sur demande. Ils n'y travaillent pas. Vous devez écrire sur des sockets nus dans la phase de journalisation pour envoyer des données à Kafka.
Filtres corps / en-têtes
Il existe deux types de filtres: les filtres de corps et les filtres d'en-têtes.
Un exemple de
filtre Body est le module de filtre gzip. Pourquoi des filtres corporels sont-ils nécessaires? Imaginez que vous ayez un certain proxy_pass et que vous souhaitiez transformer le contenu ou l'analyser d'une manière ou d'une autre. Dans ce cas, vous devez utiliser le filtre Corps.
Cela fonctionne comme ceci: de nombreux morceaux viennent à vous, vous faites quelque chose avec eux, regardez le contenu, agrégez, etc. Mais le filtre a également des limites importantes. Par exemple, si vous décidez de changer le corps - pour insérer ou couper le corps de la réponse, n'oubliez pas que les attributs HTTP, par exemple, un flux de contenu, seront remplacés. Cela peut conduire à des effets étranges si vous ne prévoyez pas de restrictions et si vous réfléchissez correctement dans votre code.
Un exemple de
filtre d'en-tête est l'add_header que tout le monde a utilisé. L'algorithme fonctionne comme dans le filtre Body. Une réponse est préparée pour le client et le filtre add_header vous permet d'y faire quelque chose: ajouter un en-tête, supprimer un en-tête, remplacer un en-tête, envoyer une sous-demande.
Soit dit en passant, dans le filtre Corps et dans le filtre En-tête, des sous-demandes sont disponibles, vous pouvez même envoyer des identifications internes à un emplacement supplémentaire.
Proxy
Il s'agit du type de modules le plus complexe et le plus controversé qui vous permet de mandater des requêtes vers des systèmes externes, par exemple, de
convertir HTTP en un autre protocole . Exemples: proxy_pass, redis_pass, tnt_pass.
Le proxy est une interface que les développeurs du noyau nginx ont proposée pour faciliter l'écriture des modules proxy. Si cela se fait de manière classique, alors pour un tel proxy, les gestionnaires PHASES, les filtres, les équilibreurs seront exécutés. Cependant, si le protocole auquel vous souhaitez convertir HTTP est en quelque sorte différent des classiques, alors de gros problèmes commencent. L'API proxy fournie par nginx n'est tout simplement pas adaptée - vous devez inventer ce module proxy à partir de zéro.
Un bon exemple d'un tel module est postgres_pass. Il permet à nginx de communiquer avec PostgreSQL. Le module n'utilise pas du tout l'interface qui a été développée dans nginx - il a son propre chemin.
N'oubliez pas le proxy, mais de préférence n'écrivez pas. Pour écrire un proxy, vous devrez apprendre tous les nginx par cœur - c'est très long et difficile.
Équilibreurs de charge
La tâche des équilibreurs de charge est très simple - travailler en mode round-robin. Imaginez que vous avez une section en amont, certains serveurs, vous spécifiez des poids et des méthodes d'équilibrage. Il s'agit d'un équilibreur de charge typique.
Ce mode n'est pas toujours adapté. Par conséquent, le module Ketama CHash a été développé, où il est conditionnellement possible d'arriver à une demande de hachage cohérente à un serveur. Parfois, c'est pratique. Nginx Lua propose balancer_by_lua. Sur Lua, vous pouvez écrire n'importe quel équilibreur en général.
Modules C
Vient ensuite mon opinion absolument subjective sur le développement des modules C. Pour commencer - mes règles subjectives.
Le module démarre avec les directives nginx.conf. Même si vous créez un module C qui ne sera exploité que par votre entreprise, pensez toujours aux directives. Commencez à concevoir le module avec eux, car c'est avec cela que l'administrateur système communiquera. C'est important - coordonnez toutes les nuances avec lui ou avec la personne qui fera fonctionner votre module C. NGINX est un produit bien connu, ses directives obéissent à certaines lois que les administrateurs système connaissent. Par conséquent, pensez-y toujours.
Utilisez le style de code nginx. Imaginez que votre module sera pris en charge par une autre personne. S'il connaît déjà nginx et son style de code, il lui sera beaucoup plus facile de lire et de comprendre votre code.
Récemment, un bon ami d'Allemagne m'a demandé de l'aider à gérer un bug dans son code nginx. Je ne sais pas pour quel style de code il l'a écrit, mais je ne pouvais même pas lire le code normalement.
Utilisez le pool de mémoire correct. Gardez toujours cela à l'esprit, même si vous avez beaucoup d'expérience avec nginx. Une erreur typique d'un développeur de module C novice pour nginx est d'obtenir le mauvais pool.
Petit rappel: nginx utilise généralement l'idéologie des allocateurs faibles. Vous pouvez y utiliser malloc, mais ce n'est pas recommandé. Il a ses propres dalles, son propre allocateur de mémoire, vous devez l'utiliser. Par conséquent, chaque objet a un lien vers son pool, et ce pool doit être utilisé. Une erreur de novice typique consiste à utiliser une connexion de pool dans le filtre d'en-tête, pas une demande de pool. Cela signifie que si nous avons une connexion permanente, le pool se gonflera jusqu'à ce qu'il n'y ait plus de mémoire ou d'autres effets secondaires. C'est donc important.
De plus, de telles erreurs sont extrêmement difficiles à débuter. Valgrind ("syshniks" comprendra) ne fonctionne pas avec l'allocation de dalles - cela affichera une image étrange.
N'utilisez pas les E / S bloquantes. Une erreur typique de ceux qui souhaitent appliquer quelque chose d'extérieur plus rapidement est d'utiliser le blocage des E / S et des sockets de blocage. Vous ne pouvez jamais faire cela dans nginx - il contient de nombreux processus, mais chaque processus utilise un thread.
Vous pouvez faire du multi-threading, mais, en règle générale, cela ne fait qu'empirer les choses. Si vous utilisez le blocage des E / S dans une telle architecture, alors tout le monde attendra cette pièce de blocage.
Je vais déchiffrer ce que j'ai dit ci-dessus.
Le module démarre avec les directives nginx.conf
Décidez dans quels tableaux votre directive doit vivre: Principal, Serveur, HTTP, emplacement, emplacement si.
Essayez d'éviter l'emplacement si - en règle générale, cela conduit à une utilisation très étrange de la configuration nginx.
Toutes les directives de nginx vivent dans différents contextes et dans différentes étendues. La directive add_header peut fonctionner au niveau HTTP, au niveau emplacement, au niveau emplacement si niveau. Ceci est généralement décrit dans la documentation.
Comprenez à quels niveaux votre directive peut fonctionner, où la directive est exécutée: gestionnaire PHASE, filtre corps / en-tête.
Ceci est important car dans nginx la configuration est gelée. Par convention, lorsque vous écrivez add_header quelque part au-dessus, cette valeur est lissée dans le bas add_header, que vous avez déjà à l'emplacement. En conséquence, vous ajouterez deux en-têtes. Cela s'applique à toute directive.
Si vous spécifiez quelque chose comme port d'hôte, alors vice versa - pool de sockets. Cela devrait être indiqué une fois.
En général, j'interdirais toute fusion - vous n'en avez tout simplement pas besoin. Par conséquent, vous devez toujours déterminer clairement dans quels tableaux nginx de la configuration réside votre directive ou votre ensemble de directives.
Bon exemple:
location /my_location/ { add_header “My-Header” “my value”; }
Ici, add_header est simplement ajouté à l'emplacement. Le même add_header pourrait être quelque part au-dessus, et tout serait simplement contorsionné. Il s'agit d'un comportement documenté et compréhensible.
Réfléchissez à ce qui pourrait entraver la mise en œuvre de la directive.
Imaginez que vous développez un filtre Body. Comme je l'ai dit ci-dessus, nginx place simplement votre module dans une chaîne commune, et vous n'avez aucune garantie que le module gzip ne soit pas entré dans la chaîne devant votre filtre Body au moment de la compilation. Dans ce cas, si quelqu'un active le module gzip, les données seront envoyées à votre module pour le gzip. Cela menace que vous ne puissiez tout simplement rien faire avec le contenu. Vous pouvez le recompresser, par exemple, mais c'est une moquerie du point de vue du CPU.
Les mêmes règles s'appliquent à tous les gestionnaires de phase - il n'y a aucune garantie qui sera appelé avant et qui sera après. Par conséquent, respectez celui qui sera appelé après, et rappelez-vous que certains gzip ou autre chose peuvent vous arriver de façon inattendue.
Style de code Nginx
Lorsque vous avez créé le produit, n'oubliez pas que quelqu'un le soutiendra. N'oubliez pas le style de code nginx.
Avant d'écrire votre module nginx, familiarisez-vous avec la source: l'
une et la
seconde .
Si à l'avenir vous vous lancez dans le développement de modules nginx, alors vous serez bien au courant des sources nginx. Vous les adorerez car il
n'y a pas de documentation . Vous apprendrez bien la structure du répertoire nginx, apprendrez à utiliser Grep, éventuellement Sed, lorsque vous aurez besoin de transférer quelques morceaux de nginx vers vos modules.
Pool de mémoire
Les piscines doivent être utilisées correctement.
Par exemple, "r-> connexion-> pool! = R-> pool". En aucun cas, vous ne pouvez utiliser la configuration du pool de mémoire lors du traitement des demandes, elle gonflera jusqu'au redémarrage de nginx.
Comprenez la durée de vie de l'objet. Supposons que la relecture de la demande ait exactement cette durée de vie du pipeline. Dans cette piscine, vous pouvez placer beaucoup de choses et faire de la place. La connexion peut vivre théoriquement indéfiniment - il vaut mieux y placer quelque chose de vraiment important.
Essayez de ne pas utiliser d'allocateurs externes, par exemple, malloc / free . Cela a un mauvais effet sur la fragmentation de la mémoire. Si vous travaillez avec de gros volumes de données et utilisez beaucoup de malloc, ce nginx ralentit assez bien.
Pour les fans de Valgrind, il existe un hack qui vous permet de déboguer les pools de nginx à l'aide de Valgrind. Ceci est important si vous avez beaucoup de code C sur nginx, car même un développeur expérimenté dans l'utilisation de la mémoire peut faire une erreur.
Blocage des E / S
Ici, tout est simple - n'utilisez pas les E / S bloquantes.
Sinon, au moins il y aura des problèmes avec les connexions persistantes, mais au maximum, tout fonctionnera très longtemps.
Je connais le cas où une personne a utilisé Quora à l'intérieur de nginx en mode blocage (ne demandez pas pourquoi). Cela a conduit au fait que les connexions de maintien en vie ont abandonné leur activité et ont expiré tout le temps. Il vaut mieux ne pas le faire - tout fonctionnera longtemps, de manière inefficace et vous devrez immédiatement tordre un million de délais, car nginx démarrera le délai sur de nombreuses choses.
Mais il existe une alternative aux modules C - NJS et Lua.
Lorsque vous n'avez pas besoin de développer des modules C
Cette année, j'ai eu ma première expérience de travail sur NJS, j'ai eu une impression subjective à ce sujet et j'ai même réalisé ce qui manquait là-bas, pour que tout se passe bien. Je voudrais également parler de mon expérience de travail sur Lua sous nginx et, en outre, partager les problèmes qui sont présents dans Lua.
Lua / LuaJit Essentials
Nginx n'utilise pas Lua, mais LuaJit. Mais ce n'est pas Lua, car Lua a déjà avancé deux versions, et LuaJit est coincé quelque part dans le passé.
L'auteur ne développe pratiquement pas LuaJit - il vit souvent dans des fourchettes. La fourche la plus récente est
LuaJit2 . Cela ajoute des situations étranges dans le même OpenResty.
Garbage Collector a besoin d'attention . LuaJit ne peut pas surmonter ce problème - il suffit de trouver des solutions de contournement. Avec une charge énorme, lorsque de nombreux Garbage Collector persistants seront visibles sur le client avec des échecs sur le graphique et 500 erreurs. Il existe de nombreuses façons de traiter le Garbage Collector à Lua, je ne me concentrerai pas sur eux ici. Il y a beaucoup d'informations à ce sujet sur Internet.
L'implémentation de chaînes entraîne des problèmes de performances . C'est juste le mal de LuaJit, et à Lua il a été réparé. L'implémentation de chaînes dans LuaJit défie simplement toute logique. Les lignes ralentissent de la manière la plus folle, ce qui est associé à l'implémentation interne.
Incapacité à utiliser de nombreuses bibliothèques prêtes à l'emploi . Lua bloque initialement, donc la plupart des bibliothèques sur Lua et LuaJit utilisent des E / S de blocage. En raison du fait que nginx ne bloque pas, il est impossible d'utiliser des bibliothèques prêtes à l'emploi à l'intérieur de nginx qui utilisent des E / S de blocage. Cela ralentira nginx.
Les raisons d'utiliser LuaJit sont identiques aux raisons d'utiliser des modules:
- prototypage de modules complexes;
- Calculs HMAC, SHA pour les autorisations;
- équilibreurs ;
- petites applications: gestionnaires d'en-tête, règles de redirection;
- calcul des variables pour nginx.conf.
Où est-il préférable de ne pas utiliser LuaJit?
La règle principale: ne traitez pas un énorme corps sur Lua - cela ne fonctionne pas.
Les gestionnaires de contenu sur Lua ne fonctionnent pas non plus . Essayez de minimiser la logique à quelques
if . Un simple équilibreur fonctionnera, mais une barre latérale sur Lua fonctionnera très mal.
La mémoire partagée ou Garbage Collector viendra. N'utilisez pas la mémoire partagée avec Lua - Garbage Collector va rapidement et avec garantie sortir tout le cerveau en production.
N'utilisez pas de coroutines contenant beaucoup de composés persistants. Les coroutines génèrent encore plus de déchets à l'intérieur du récupérateur de déchets LuaJit, ce qui est mauvais.
Si vous utilisez déjà LuaJit, n'oubliez pas:
- sur la surveillance de la mémoire;
- sur le suivi et l'optimisation du travail de Garbage Collector;
- sur le fonctionnement de Garbage Collector, si vous avez écrit une application compliquée pour LuaJit, car vous devez ajouter quelque chose de nouveau.
Njs
Quand j'étais à NGINX Conf, ils m'ont convaincu que ce serait cool de ne pas écrire de code en C. Je pensais que je devais essayer, et c'est ce que j'ai obtenu.
Autorisation Cela fonctionne, le code est simple, il n'affecte pas la vitesse - tout est super. Mon petit
prototype avec
lequel j'ai commencé est 10 lignes de code. Mais ces 10 lignes font une autorisation avec s3.
Variables de calcul pour nginx.conf. De nombreuses variables peuvent être calculées à l'aide de NJS. À l'intérieur de Nginx, c'est cool. Il y a une telle fonctionnalité dans Lua, mais il y a un Garbage Collector, donc ce n'est pas si cool.
Cependant, tout n'est pas si bon. Pour faire des choses vraiment cool sur NJS, il lui manque quelques petites choses.
Mémoire partagée . J'ai patché la mémoire partagée, c'est ma propre fourchette, alors maintenant ça suffit.
Filtres prenant en charge plusieurs phases . Dans NJS, il n'y a que la phase de contenu et les variables, et le filtre d'en-tête fait très défaut. Vous devez écrire des béquilles pour ajouter beaucoup d'en-têtes. Il n'y a pas assez de filtre de corps pour une logique complexe ou pour travailler avec du contenu.
Informations sur la façon de le surveiller et de le profiler . Je sais maintenant comment, mais j'ai dû étudier la source. Il n'y a pas suffisamment d'informations ou d'outils sur le profilage approprié. Si c'est le cas, il est caché où il est introuvable. Au même moment, il n'y a pas assez d'informations sur
où je peux utiliser NJS et où je ne peux pas?
Modules C. J'avais envie d'étendre NJS.
Postface
Pourquoi créer vos propres modules? Pour résoudre des problèmes généraux et commerciaux.
Quand dois-je implémenter des modules en C? S'il n'y a pas d'autres options. Par exemple, une lourde charge, l'insertion de contenu ou des économies de base sur le matériel. Ensuite, cela doit être fait garanti en C. Dans la plupart des cas, Lua ou NJS convient. Mais vous devez toujours penser à l'avenir.
Et sur Lua? Lorsque vous ne pouvez pas écrire en C. Par exemple, vous n'avez pas besoin de convertir le corps de la demande avec un énorme RPS. Votre nombre de clients augmente, à un moment donné, vous cesserez de faire face - pensez-y.
NJS? Quand LuaJit en a marre de son Garbage Collector et de ses cordes. Par exemple, l'autorisation a généré de nombreux objets Garbage sur Lua, mais ce n'était pas critique. Cependant, cela s'est reflété dans la surveillance et ennuyeux. Maintenant, il a cessé d'apparaître dans ma surveillance, et tout est devenu bon.
À HighLoad ++ 2019, Vasily Soshnikov poursuivra le sujet des modules nginx et parlera davantage de NJS, sans oublier la comparaison avec LuaJit et C.
Consultez la liste complète des rapports sur le site Web et rendez-vous les 7 et 8 novembre à la plus grande conférence pour les développeurs de systèmes hautement chargés. Suivez nos nouvelles idées dans la newsletter et le canal télégramme .