Cette courte histoire sera consacrée à la façon de ne pas tomber dans le piège du contrôle imaginaire sur le processus d'estimation des tâches pour le prochain sprint. Je dois dire tout de suite que les données présentées ci-dessous ne sont qu'indicatives et que les commentaires sur la non-utilisation des nombres de Fibonacci aux fins d'estimation ici seront superflus.
Notre équipe était composée d'un analyste, testeur, designer et 2 développeurs, cependant, pour plus de clarté, nous ne laissons que les développeurs.
Nous commençons un nouveau sprint et procédons en douceur à l'évaluation des User stories. Rien de nouveau. Allez-y ...

La planification est terminée et les résultats sont visibles ci-dessus. Ils ont pris 3 User stories évaluées à 16, 20 et 37 points d'histoire, respectivement. Total - 73.
De plus, comme toute équipe de développement qui se respecte et adore tous les plaisirs de travailler sur Scrum, nous ajoutons ces notes à Jira. Dans le même temps, nous n'introduisons que des estimations générales (ou moyennes - pire encore!) Pour chaque histoire.
Deux semaines de travail sans retirer vos mains du clavier et sans vous lever de la chaise de bureau tant appréciée depuis des années, vous pouvez contempler la nouvelle fonctionnalité.
Mais quel est le problème? Le sprint est terminé et nous voyons que l'avant a tout fait comme prévu et n'aurait pas le temps de faire une seule frappe, et l'arrière est allé au-delà du sprint et a fait plus de tâches que prévu.
Et puis Scrum et XP du Trenches PM, qui vient de terminer la lecture, apparaissent et disent: «Tout est clair !!! Il faut emmener plus de storpoints pour le prochain sprint et puis tout ira bien et plus aucun support ne me fuira plus, prenant le scoping avec moi !! "
Nous prévoyons un nouveau sprint ....
Super! A pris 10 points de stockage de plus !!! Maintenant, nous avons tout calculé à coup sûr !!
Encore 2 semaines passent vite et il est temps de faire le point.
Mais au regret de tous, le sprint s’est terminé d’une manière complètement différente de ce que nous souhaiterions.
Pour une raison quelconque, l'arrière a de nouveau tiré de l'avant, et le front n'a pas eu le temps de faire ce qu'il avait prévu (la possibilité que le front ne soit qu'un juin inexpérimenté, et nous allons abaisser le dos intouchable sénateur et imaginer que le tout n'est que dans une mauvaise planification).
Un autre sprint a été un échec !!! Mais pourquoi, nous avons pris un peu plus de storypots et cela, uniquement à de bonnes fins - pour donner la quantité de travail nécessaire pour le côté serveur ??!?
Comment est-ce possible? La réponse est tout au sujet du système d'évaluation lui-même. Revenons à nos sprints.

Que voyons-nous? Il s'avère qu'en prenant plus de storpoints sur le nouveau sprint pour charger l'arrière, nous venons de charger l'avant.
Après avoir compris cela, la première pensée dans la tête folle de PM est de savoir combien de points d'histoire le front a pris sur lui-même et combien de soutien. Mais regarder la note globale à Jira n'est tout simplement pas possible, car tout ce que vous pouvez découvrir est la note globale (bien ou moyenne) pour chaque histoire, et rappelez-vous qui donne quelle note n'est plus possible.

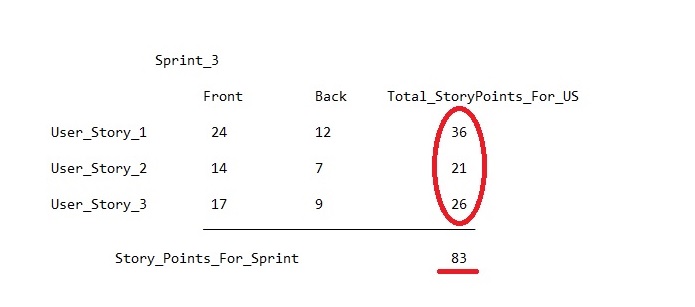
Et puis la solution vient d'elle-même. Afin de réguler avec succès la charge de l'équipe, il est nécessaire de conserver non seulement un enregistrement commun dans les points d'historique, mais également un enregistrement séparé dans le contexte de la charge avant et arrière. Cela vous permettra de découvrir la quantité optimale de travail pour chaque domaine et de vous y fier pour combler l'arriéré de sprint. Jusqu'à présent, cette approche ne peut pas être mise en œuvre dans Jira sans notes distinctes dans MS Excel, mais cela ne signifie pas qu'elle ne doit pas être utilisée.
Je suis sûr que les développeurs Atlassian trouveront une solution à ce problème, mais pour l'instant, ne répétez pas nos erreurs!
PS Ces conclusions sont applicables uniquement pour le développement d'applications client-serveur, où il y a une séparation claire du travail sur le front et le backend. Un tel problème ne devrait pas survenir dans l'équipe de développeurs Full-Stack, qui évaluent immédiatement le travail dans deux directions.