
En 2017, nous avons remporté le concours pour le développement du cœur de transaction des activités d'investissement d'Alfa-Bank et avons commencé à travailler immédiatement. (Vladimir Drynkin, responsable de l'équipe de développement pour Investment Business Transaction Core d'Alfa-Bank, a
parlé du secteur des investissements à HighLoad ++ 2018.) Ce système était censé agréger les données de transaction dans différents formats à partir de diverses sources, unifier les données, les enregistrer et lui donner accès.
En cours de développement, le système a évolué et étendu ses fonctions. À un moment donné, nous avons réalisé que nous avons créé bien plus qu'un simple logiciel d'application conçu pour un éventail de tâches bien défini: nous avons créé un système pour créer des applications distribuées avec un stockage persistant. Notre expérience a servi de base au nouveau produit,
Tarantool Data Grid (TDG).
Je veux parler de l'architecture TDG et des solutions que nous avons élaborées pendant le développement. Je présenterai les fonctions de base et montrerai comment notre produit pourrait devenir la base de la construction de solutions clé en main.
En termes d'architecture, nous avons divisé le système en
rôles distincts. Chacun d'eux est responsable d'une gamme spécifique de tâches. Une instance en cours d'exécution d'une application implémente un ou plusieurs types de rôles. Il peut y avoir plusieurs rôles du même type dans un cluster:
Connecteur
Le connecteur est responsable de la communication avec le monde extérieur; il est conçu pour accepter la requête, l'analyser et s'il réussit, il envoie les données pour traitement au processeur d'entrée. Les formats suivants sont pris en charge: HTTP, SOAP, Kafka, FIX. L'architecture nous permet d'ajouter la prise en charge de nouveaux formats (la prise en charge d'IBM MQ arrive bientôt). Si l'analyse de la demande échoue, le connecteur renvoie une erreur. Sinon, il répond que la demande a été traitée avec succès, même si une erreur s'est produite lors du traitement ultérieur. Ceci est fait exprès afin de travailler avec les systèmes qui ne savent pas répéter les requêtes, ou vice versa, le faire de manière trop agressive. Pour s'assurer qu'aucune donnée n'est perdue, la file d'attente de réparation est utilisée: l'objet rejoint la file d'attente et n'y est supprimé qu'après un traitement réussi. L'administrateur reçoit des notifications sur les objets restant dans la file d'attente de réparation et peut réessayer le traitement après avoir géré une erreur logicielle ou une défaillance matérielle.
Processeur d'entrée
Le processeur d'entrée classe les données reçues par caractéristiques et appelle les gestionnaires correspondants. Les gestionnaires sont du code Lua qui s'exécute dans un bac à sable, ils ne peuvent donc pas affecter le fonctionnement du système. À ce stade, les données peuvent être transformées selon les besoins et, si nécessaire, un certain nombre de tâches peuvent s'exécuter pour implémenter la logique nécessaire. Par exemple, lors de l'ajout d'un nouvel utilisateur dans MDM (Master Data Management construit sur la base de Tarantool Data Grid), un enregistrement d'or serait créé en tant que tâche distincte afin que le traitement des demandes ne ralentisse pas. Le bac à sable prend en charge les demandes de lecture, de modification et d'ajout de données. Il vous permet également d'appeler une fonction pour tous les rôles du type de stockage et d'agréger le résultat (mapper / réduire).
Les gestionnaires peuvent être décrits dans des fichiers:
sum.lua local x, y = unpack(...) return x + y
Puis déclaré dans la configuration:
functions: sum: { __file: sum.lua }
Pourquoi Lua? Lua est une langue simple. D'après notre expérience, les gens commencent à écrire du code qui résoudrait leur problème quelques heures seulement après avoir vu la langue pour la première fois. Et ce ne sont pas seulement des développeurs professionnels, mais par exemple des analystes. De plus, grâce au compilateur JIT, Lua est sppedy.
Stockage
Le stockage stocke des données persistantes. Avant l'enregistrement, les données sont validées pour la conformité avec le schéma de données. Pour décrire le schéma, nous utilisons le format étendu
Apache Avro . Exemple:
{ "name": "User", "type": "record", "logicalType": "Aggregate", "fields": [ { "name": "id", "type": "string" }, { "name": "first_name", "type": "string" }, { "name": "last_name", "type": "string" } ], "indexes": ["id"] }
Sur la base de cette description, le DDL (Data Definition Language) pour Tarantool DBMS et le schéma
GraphQL pour l'accès aux données sont générés automatiquement.
La réplication de données asynchrone est prise en charge (nous prévoyons également d'ajouter une réplication synchrone).
Processeur de sortie
Parfois, il est nécessaire d'informer les consommateurs externes des nouvelles données. C'est pourquoi nous avons le rôle de processeur de sortie. Après avoir enregistré les données, elles peuvent être transférées dans le gestionnaire approprié (par exemple, pour les transformer selon les besoins du consommateur), puis transférées vers le connecteur pour l'envoi. La file d'attente de réparation est également utilisée ici: si personne n'accepte l'objet, l'administrateur peut réessayer plus tard.
Mise à l'échelle
Les rôles Connecteur, Processeur d'entrée et Processeur de sortie sont sans état, ce qui nous permet de faire évoluer le système horizontalement en ajoutant simplement de nouvelles instances d'application avec le rôle activé nécessaire. Pour la mise à l'échelle du stockage horizontal, un cluster est organisé à l'aide de l'
approche des compartiments virtuels. Après avoir ajouté un nouveau serveur, certains compartiments des anciens serveurs sont déplacés vers un nouveau serveur en arrière-plan. Ce processus est transparent pour les utilisateurs et n'affecte pas le fonctionnement de l'ensemble du système.
Propriétés des données
Les objets peuvent être énormes et contenir d'autres objets. Nous assurons l'ajout et la mise à jour des données de manière atomique, et l'enregistrement de l'objet avec toutes les dépendances sur un seul compartiment virtuel. Ceci est fait pour éviter ce que l'on appelle le "maculage" de l'objet sur plusieurs serveurs physiques.
La gestion des versions est également prise en charge: chaque mise à jour de l'objet crée une nouvelle version, et nous pouvons toujours créer une tranche de temps pour voir à quoi tout ressemblait à l'époque. Pour les données qui n'ont pas besoin d'un long historique, nous pouvons limiter le nombre de versions ou même stocker uniquement la dernière, c'est-à-dire que nous pouvons désactiver la gestion des versions pour un type de données spécifique. Nous pouvons également définir les limites historiques: par exemple, supprimer tous les objets d'un type spécifique datant de plus d'un an. L'archivage est également pris en charge: nous pouvons télécharger des objets au-delà d'un certain âge pour libérer de l'espace de cluster.
Tâches
Les fonctionnalités intéressantes à noter incluent la possibilité d'exécuter des tâches à temps, à la demande de l'utilisateur ou automatiquement à partir du bac à sable:
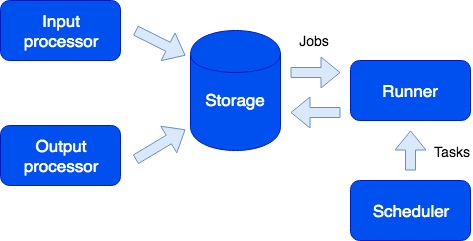
Ici, nous pouvons voir un autre rôle appelé Runner. Ce rôle n'a pas d'État; si nécessaire, d'autres instances d'application avec ce rôle pourraient être ajoutées au cluster. Le coureur est responsable de l'exécution des tâches. Comme je l'ai déjà mentionné, de nouvelles tâches pourraient être créées à partir du bac à sable; ils rejoignent la file d'attente sur le stockage puis s'exécutent sur le coureur. Ce type de tâches s'appelle un Job. Nous avons également un type de tâche appelé Tâche, c'est-à-dire une tâche définie par l'utilisateur qui s'exécuterait à temps (en utilisant la syntaxe cron) ou à la demande. Pour exécuter et suivre ces tâches, nous avons un gestionnaire de tâches pratique. Le rôle de planificateur doit être activé pour utiliser cette fonction. Ce rôle a un état, il n'est donc pas évolutif, ce qui n'est pas nécessaire de toute façon. Cependant, comme tout autre rôle, il peut avoir une réplique qui commence à fonctionner si le maître échoue soudainement.
Enregistreur
Un autre rôle est appelé Logger. Il collecte les journaux de tous les membres du cluster et fournit une interface pour les télécharger et les visualiser via l'interface Web.
Les services
Il convient de mentionner que le système facilite la création de services. Dans le fichier de configuration, vous pouvez spécifier les demandes à envoyer au gestionnaire écrit par l'utilisateur s'exécutant dans le sandbox. Un tel gestionnaire peut, par exemple, exécuter une sorte de requête analytique et renvoyer le résultat.
Le service est décrit dans le fichier de configuration:
services: sum: doc: "adds two numbers" function: sum return_type: int args: x: int y: int
L'API GraphQL est générée automatiquement et le service est disponible pour les appels:
query { sum(x: 1, y: 2) }
Cela appelle le gestionnaire de
sum qui renvoie le résultat:
3
Demander le profilage et les métriques
Nous avons implémenté la prise en charge du protocole OpenTracing pour apporter une meilleure compréhension des mécanismes du système et du profilage des demandes. Sur demande, le système peut envoyer des informations sur la façon dont la demande a été exécutée aux outils prenant en charge ce protocole (par exemple Zipkin):
Inutile de dire que le système fournit des métriques internes qui peuvent être collectées à l'aide de Prometheus et visualisées à l'aide de Grafana.
Déploiement
Tarantool Data Grid peut être déployé à partir de packages RPM ou d'archives à l'aide de l'utilitaire intégré ou d'Ansible. Kubernetes est également pris en charge (
Tarantool Kubernetes Operator ).
Une application qui implémente la logique métier (configuration, gestionnaires) est chargée dans le cluster Tarantool Data Grid déployé dans l'archive via l'interface utilisateur ou en tant que script à l'aide de l'API fournie.
Exemples d'applications
Quelles applications pouvez-vous créer avec Tarantool Data Grid? En fait, la plupart des tâches commerciales sont en quelque sorte liées au traitement, au stockage et à l'accès aux flux de données. Par conséquent, si vous avez des flux de données volumineux qui nécessitent un stockage sécurisé et une accessibilité, notre produit pourrait vous faire gagner beaucoup de temps dans le développement et vous aider à vous concentrer sur votre logique métier.
Par exemple, vous souhaitez recueillir des informations sur le marché immobilier pour rester à jour sur les meilleures offres du futur. Dans ce cas, nous distinguons les tâches suivantes:
- Les robots collectant des informations à partir de sources ouvertes seraient vos sources de données. Vous pouvez résoudre ce problème en utilisant des solutions toutes faites ou en écrivant du code dans n'importe quelle langue.
- Ensuite, Tarantool Data Grid accepte et enregistre les données. Si le format de données provenant de diverses sources est différent, vous pouvez écrire du code en Lua qui convertirait tout en un seul format. Au stade du prétraitement, vous pouvez également, par exemple, filtrer les offres récurrentes ou mettre à jour les informations de la base de données sur les agents opérant sur le marché.
- Maintenant, vous avez déjà une solution évolutive dans le cluster qui pourrait être remplie de données et utilisée pour créer des échantillons de données. Ensuite, vous pouvez implémenter de nouvelles fonctions, par exemple, écrire un service qui créerait une demande de données et retournerait l'offre la plus avantageuse par jour. Il ne faudrait que plusieurs lignes dans le fichier de configuration et du code Lua.
Quelle est la prochaine étape?
Pour nous, une priorité est d'augmenter la facilité de développement avec
Tarantool Data Grid . (Par exemple, il s'agit d'un IDE avec prise en charge du profilage et du débogage des gestionnaires qui fonctionnent dans le sandbox.)
Nous accordons également une grande attention aux problèmes de sécurité. À l'heure actuelle, notre produit est certifié par le FSTEC de Russie (Service fédéral pour la technologie et le contrôle des exportations) afin de reconnaître le haut niveau de sécurité et de répondre aux exigences de certification des produits logiciels utilisés dans les systèmes d'information sur les données personnelles et les systèmes d'information fédéraux.